文章目录
- 1.状态的基本认识
- 2.观察线程的所有状态
- 3.线程状态和状态转移
- 4.多线程的意义
1.状态的基本认识
- NEW 创建了 Thread 对象,但是还没调用 start(内核里还没有创建对应的PCB)
- TERMINATED 表示内核中的 PCB 已经执行完毕了,但是 Thread 对象还在。
- RUNNABLE 可运行的。(叫做RUNNALBE,而不是RUNNING)
又可以分为:
- 正在 CPU 上执行。
- 在就绪队列里,随时可以去CPU上执行。
- WAITING
- TIMED_WAITING
- BLOCKED
4、5、6都是阻塞(都是表示线程PCB正在阻塞队列中),只不过是不同原因的阻塞。
2.观察线程的所有状态
package thread;
public class ThreadDemo12 {
public static void main(String[] args) {
for (Thread.State state : Thread.State.values()) {
System.out.println(state);
}
}
}

线程的状态是一个枚举类型 Thread.State。
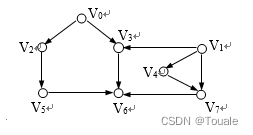
3.线程状态和状态转移
线程的状态转换图

NEW 和 TERMINATED 状态的演示:
package thread;
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException{
Thread thread = new Thread(() -> {
for (int i = 0; i < 10000000; i++) {
}
});
//启动之前获取thread的状态,就是NEW状态
System.out.println("start之前:" + thread.getState());
thread.start();
thread.join();
//执行结束之后,就是 TERMINATED状态
System.out.println("thread 结束之后:" + thread.getState());
}
}

一旦内核里的线程 PCB 消亡了,此时代码中的 thread 对象也就没什么用了。
之所以存在,是因为java中的对象的生命周期自有其规则。
这个生命周期和系统内核里的线程并非完全一致。
内核的线程释放的时候,无法保证java代码中的thread对象也立即释放。
因此,势必会存在,内核的PCB没了,但是代码中的thread还在的情况。
此时就需要通过特定的状态来把thread对象标识成 “无效”。
RUNNABLE 和 TIMED_WAITING状态的演示:
package thread;
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException{
Thread thread = new Thread(() -> {
for (int i = 0; i < 10000000; i++) {
}
});
//启动之前获取thread的状态,就是NEW状态
System.out.println("start之前:" + thread.getState());
thread.start();
System.out.println("执行中的状态:" + thread.getState());
thread.join();
//执行结束之后,就是 TERMINATED状态
System.out.println("thread 结束之后:" + thread.getState());
}
}

之所以可以看到 RUNNABLE 主要就是因为当前线程run里面,没写任何的sleep之类的方法。
当然也可以看到TIMED_WAITING。
设置一个循环打印执行中的状态。
package thread;
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException{
Thread thread = new Thread(() -> {
for (int i = 0; i < 10000000; i++) {
}
});
//启动之前获取thread的状态,就是NEW状态
System.out.println("start之前:" + thread.getState());
thread.start();
for (int i = 0; i < 1000; i++) {
System.out.println("执行中的状态:" + thread.getState());
}
thread.join();
//执行结束之后,就是 TERMINATED状态
System.out.println("thread 结束之后:" + thread.getState());
}
}

package thread;
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException{
Thread thread = new Thread(() -> {
for (int i = 0; i < 100; i++) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
});
//启动之前获取thread的状态,就是NEW状态
System.out.println("start之前:" + thread.getState());
thread.start();
for (int i = 0; i < 100; i++) {
System.out.println("执行中的状态:" + thread.getState());
}
thread.join();
//执行结束之后,就是 TERMINATED状态
System.out.println("thread 结束之后:" + thread.getState());
}
}

通过这里的循环获取,就可以看到这里的交替状态了。
当前获取的状态,到底是什么,完全取决于系统里的调度操作。
获取这一状态的瞬间,到底 thread 线程是处在什么样的状态。(sleep、还是正在执行)
当前只演示这四个状态,剩下的 WAITING 和 BLOCKED 后面再演示。
4.多线程的意义
写一个代码,来感受一下单线程和多线程的执行速度的差别。
程序分成 CPU 密集和 IO 密集。
- CPU 密集,包含了大量的加减乘除等算术运算。
- IO密集,涉及到了读写文件,读写控制台,读写网络。
写一个代码来执行一个算量很大的任务,来比较一下单线程和多线程的执行速度差异。
public class ThreadDemo14 {
public static void main(String[] args) {
//现在有两个变量,把两个变量自增加100亿次(典型的CPU密集型场景
//可以一个线程,先针对a自增,在针对b自增
//还可以两个线程分别对a和b自增
serial();
concurrency();
}
//串行执行,一个线程完成
public static void serial() {
//为了衡量带没带的速度。加上一个计时的操作。
//curretTimeMillis 获取当前系统的 ms 级时间戳
long beg = System.currentTimeMillis();//得到开始的时间戳
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
long b = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
b++;
}
long end = System.currentTimeMillis();//得到结束的时间戳
System.out.println("单线程执行时间:" + (end - beg) + "ms");
}
//使用两个线程来完成
public static void concurrency() {
Thread t1 = new Thread(() -> {
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
long b = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
b++;
}
});
//开始的时间戳
long beg = System.currentTimeMillis();
t1.start();
t2.start();
try {
//等待两个线程都结束了以后才开始统计时间
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
//结束的时间戳
long end = System.currentTimeMillis();
System.out.println("多线程执行的时间:" + (end - beg) + "ms");
}
}
main 线程先调用t1.start,启动 t1 开始计算 t1 的同时,
main再调用 t2.start,启动 t2 的同时,t1 仍然在继续计算。
同时,main 线程就进入 t1.join,此时,main阻塞等待了,t1 和 t2 还是要继续执行。
等到t1执行结束了,main线程从t1.join返回,再进入 t2.join。
再来等待,等到 t2 执行完了,main 从 t2.join 返回,继续执行计时操作。
main 调用的是 t1.join 就是 main 来等待 t1
如果是 t2 调用 t1.join,就是 t2 等待 t1。
join 只是限制了 main 最后结束,并不知道 t1 和 t2 谁先结束。
对于上面的代码执行3次后取中间值。



两个线程就像是两个人同时执行一个任务,按说速度应该是单线程的一半才对。
可是观察结果会发现,三次多线程的速度都不是单线程的一半。
原因:
t1 和 t2 才执行的过程中,会经历许多调度。
这些次调度,有些是并发执行的(在一个核心上),有些事并行执行的(在两个核心上)
另一方面,线程调度自身也是有时间消耗的。
虽然缩短的不是百分之五十,但是仍然是很明显的,仍然很有意义。
多线程在这种 CPU 密集型的任务中,有非常大的作用,可以充分利用 CPU 的多核资源,
从而加快程序的运行效率。
不是说使用多线程就一定可以提高效率。
还要考虑:
- 是否是多核(现在的CPU基本上都是多核了)
- 当前核心是否是空闲的。(如果 CPU 的核心都满载了,这个时候启动更多的线程也没什么作用)