目录
一、MySQL索引简介
二、索引的作用
1、优点
2、缺点
三、创建索引的原则依据
四、索引的分类和创建
1、普通索引
2、唯一索引(创建唯一键即创建唯一索引)
3、主键索引(和创建主键的方式一样)
4、组合索引(单列索引与多列索引)
5、全文索引
五、删除索引
1、删除主键索引(即删除主键)
2、删除其他索引
六、总结
1、索引的作用
2、创建索引
3、删除索引
一、MySQL索引简介
索引是MySQL数据库为了加快数据查询的速度,给表中的某一个或者是某几个列添加的一种“目录”。MySQL的索引是一个特殊的文件,但是InnoDB类型引擎(关于MySQL的引擎我们会在今后的文章中进行讲解)的表的索引是表空间的一个组成部分。
MySQL数据库一共支持5种类型的索引,分别是普通索引、唯一性索引、主键索引、复合索引和全文索引,下面,我将对这四种类型的索引一一介绍。
二、索引的作用
1、优点
- 设置了合适的索引之后,数据库利用各种快速定位技术,能够大大加快查询速度,这是创建索引的最主要的原因。
- 当表很大或查询涉及到多个表时,使用索引可以成千上万倍地提高查询速度。
- 可以降低数据库的I/O成本,并且索引还可以降低数据库的排序成本。
- 通过创建唯一性索引,可以保证数据表中每一行数据的唯一性。
- 可以加快表与表之间的连接。
- 使用分组和排序时,可大大减少分组和排序的时间。
- 建立索引在搜索和恢复数据库中的数据时能显著提高性能。
2、缺点
-
索引需要占用额外的磁盘空间。
- 对于 MyISAM 引擎而言,索引文件和数据文件是分离的,索引文件用于保存数据记录的地址。
- 而 InnoDB 引擎的表数据文件本身就是索引文件。(索引文件和数据文件是同一个)
-
在插入和修改数据时要花费更多的时间、消耗更多性能,因为索引也要随之变动。
三、创建索引的原则依据
- 选择唯一性索引:唯一性索引一般基于Hash算法实现,可以快速、唯一地定位某条数据
- 为经常需要分组、排序和联合的字段建立索引
- 为常作为查询条件的字段建立索引
- 限制索引的数量:索引越多,数据更新表越慢,因为在数据更新时会不断计算和添加索引
- 尽量使用数据量少的索引:如果索引值很长,则占用磁盘变大,会影响查询速度
- 尽量使用前缀来索引:如果索引字段的值过长,则不但影响索引的大小,而且会降低索引的执行效率,这时需要使用字段的部分前缀来作为索引
- 删除不再使用或使用很少的索引
- 尽量选择区分度搞的列作为索引:区分度表示字段值不重复的比例
- 索引列不能参与计算:带函数的查询不建议参与索引
- 尽量扩展现有索引:联合索引的查询效率比多个独立索引搞
四、索引的分类和创建
先创建一个数据表week
create table week(id int(10) ,name varchar(10) ,cardid int(18) ,phone int(11) ,address varchar(50),remark text);

1、普通索引
普通索引是最基本的索引类型,没有唯一性之类的限制。
方法一:直接创建索引
CREATE INDEX 索引名 ON 表名 (列名(length));
- (列名(length)):length是可选项,下同。如果忽略length 的值,则使用整个列的值作为索引。如果指定,使用列的前length个字符来创建索引,这样有利于减小索引文件的大小。在不损失精确性的情况下,长度越短越好。
- 索引名建议以“index"结尾。
示例:
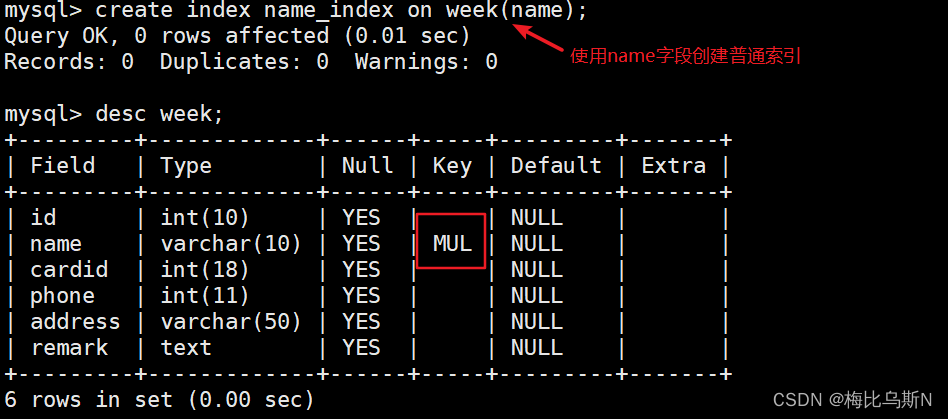
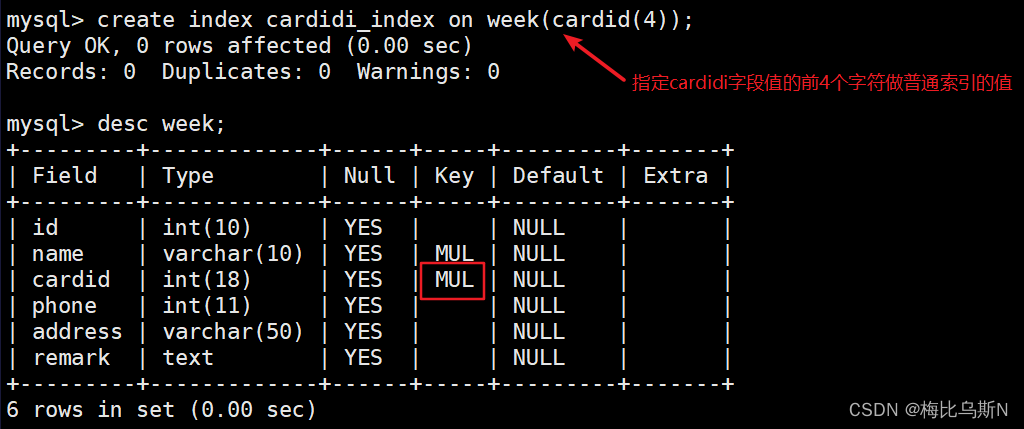
create index name_index on week(name); #以name字段创建普通索引
create index cardid_index on week(cardid(4)); #指定cardid字段值的前4个字符做普通索引的值
 方法二:修改表方式创建索引
方法二:修改表方式创建索引
ALTER TABLE 表名 ADD INDEX 索引名(列名);
示例:
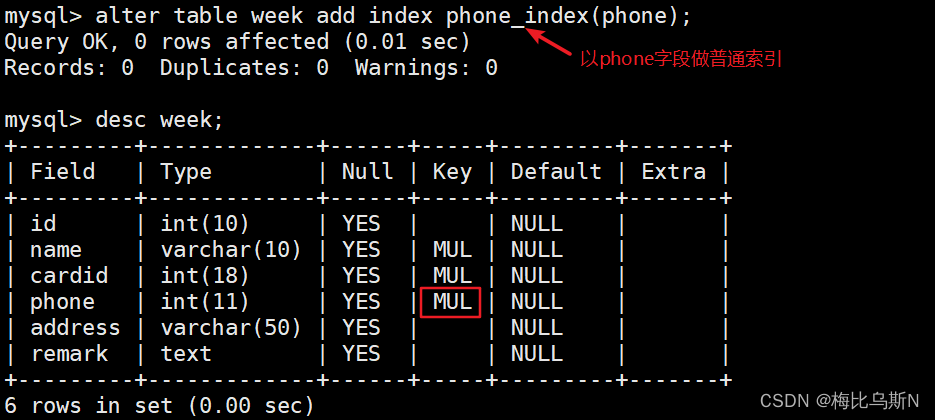
ALTER TABLE week ADD INDEX phone_index(phone); #以phone字段创建普通索引
方法三:创建表时指定索引
CREATE TABLE 表名(字段1数据类型,字段2数据类型[,...],INDEX 索引名 (列名));
示例:
create table week2(id int(10) ,name varchar(10) ,cardid int(18), phone int(11) ,address varchar(50),remark text,INDEX name_index(name));
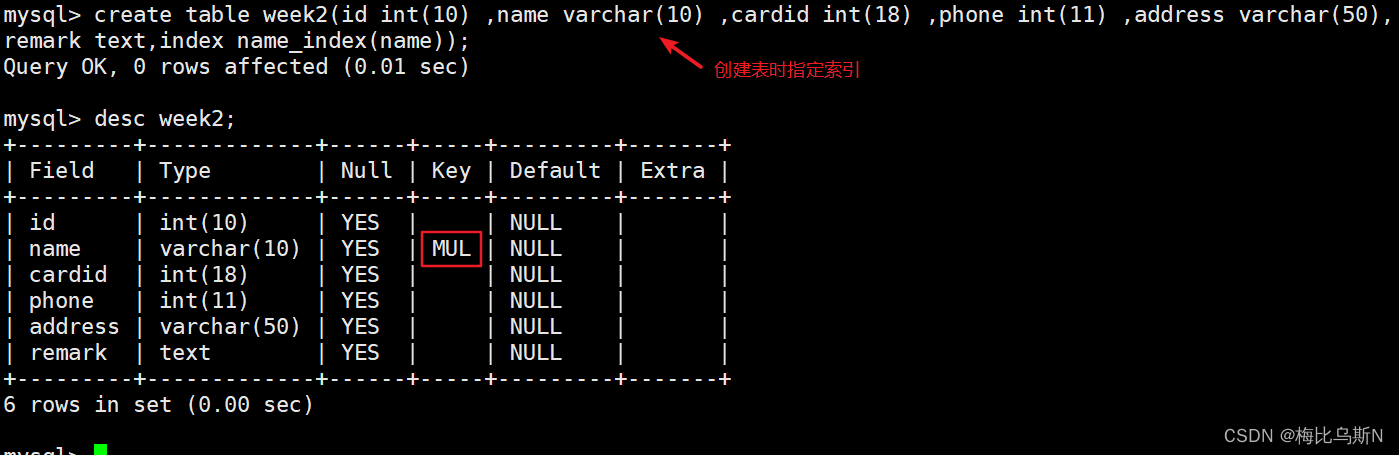
删除索引:
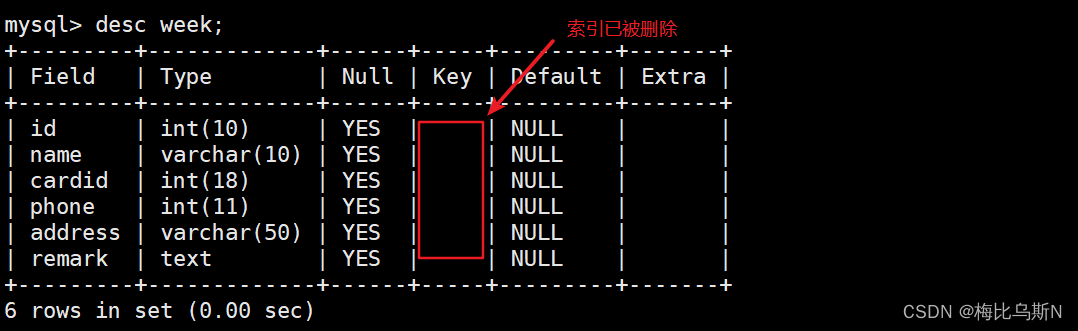
drop index name_index on week; #直接删除索引
drop index cardidi_index on week; #直接删除索引
alter table week DROP index phone_index; #以修改表的方式删除索引
2、唯一索引(创建唯一键即创建唯一索引)
唯一索引:与普通索引类似,但区别是唯一索引列的每个值都唯一。 唯一索引允许有空值(注意和主键不同)。如果是用组合索引创建,则列值的组合必须唯一。添加唯一键将自动创建唯一索引。
方法一:直接创建唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(字段名);
示例:
create unique index card_index on week(cardid);
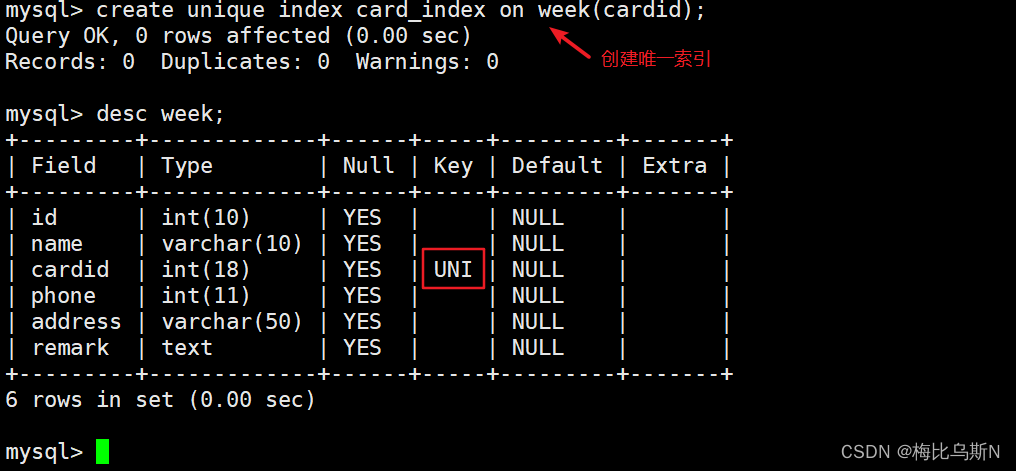
方法二: 以修改表的方式创建
ALTER TABLE 表名 ADD UNIQUE 索引名(字段名);
示例:
alter table week add unique phone_index(phone);

方法三: 创建表时指定索引
CREATE TABLE 表名(字段1 数据类型,字段2 数据类型[...],UNIQUE 索引名(字段名));
示例:
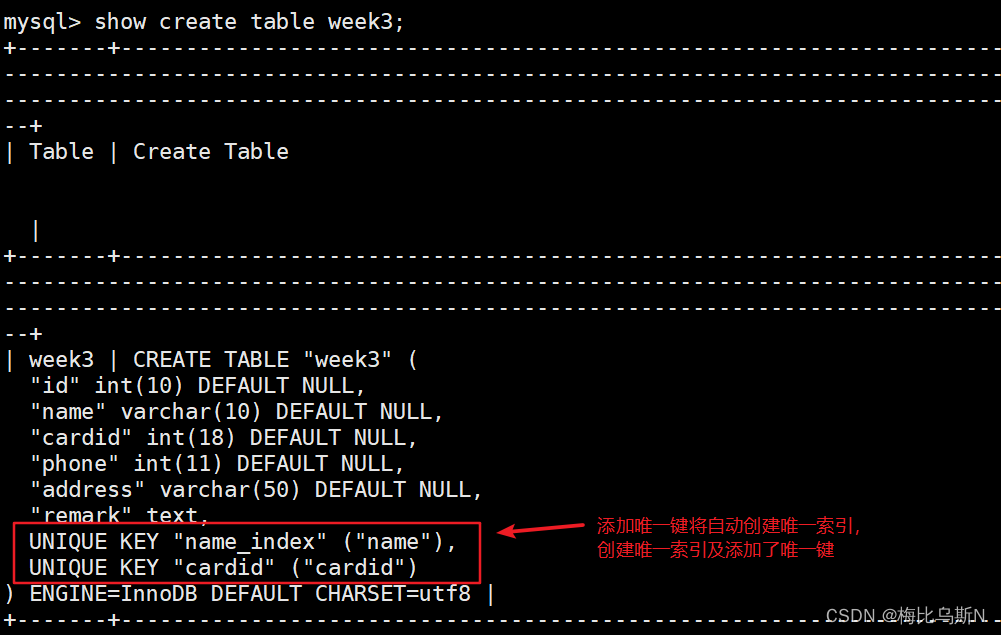
create table week3(id int(10) ,name varchar(10) ,cardid int(18) ,phone int(11) ,address varchar(50),remark text, unique name_index(name));

方法四:添加唯一键
添加唯一键将自动创建唯一索引。
CREATE TABLE 表名(字段1 数据类型,字段2 数据类型[...],unique key(字段名));
CREATE TABLE 表名(字段1 数据类型 unique key,字段2 数据类型[...]);
ALTER TABLE 表名 ADD unique key(字段);

3、主键索引(和创建主键的方式一样)
主键索引是一种特殊的唯一索引,必须指定为“PRIMARY KEY”。一个表只能有一个主键,不允许有空值。 添加主键将自动创建主键索引。
方法一:创建表时添加主键
create table 表名(字段1 XXX, 字段2 XXX, ...primary key(字段));
create table 表名(字段1 XXX primary key, ...); #将主键作为字段1的属性
示例:
create table queen(id int(10),name varchar(10),primary key(id));
create table queen2(id int(10) primary key,name varchar(10));
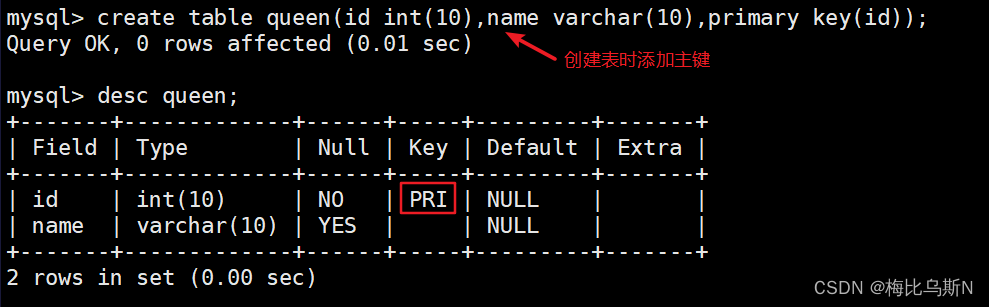
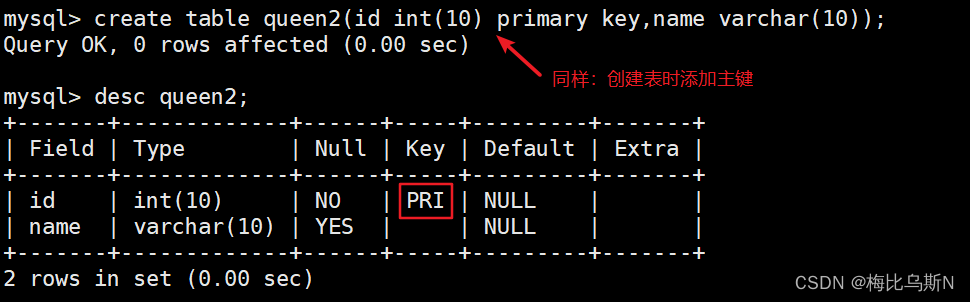
方法二:在现有表中添加主键
ALTER TABLE 表名 add primary key(字段名);
示例:
ALTER TABLE week add primary key(id); #将id字段添加为主键
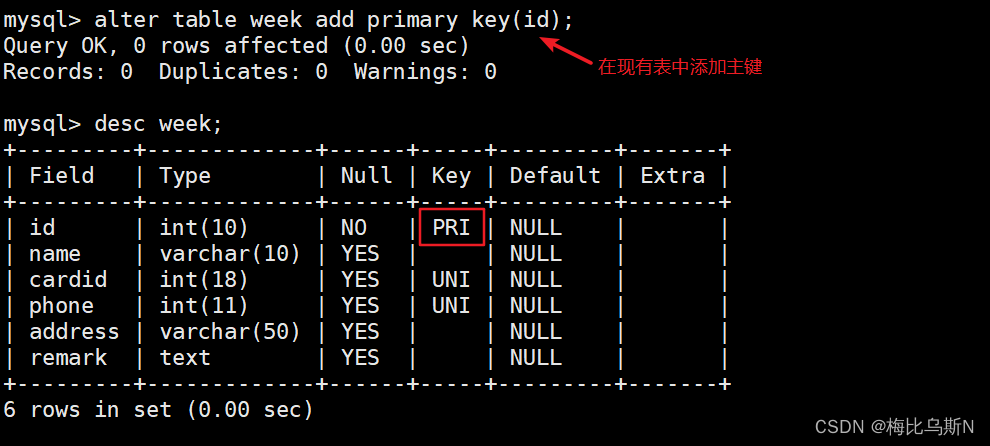
4、组合索引(单列索引与多列索引)
组合索引(单列索引与多列索引):可以是单列上创建的索引,也可以是在多列上创建的索引。
需要满足最左原则,因为select 语句的where条件是依次从左往右执行的,所以在使用select 语句查询时where 条件使用的字段顺序必须和组合索引中的排序一致,否则索引将不会生效。
方法一:直接创建索引
CREATE INDEX 索引名 on 表名(字段1,字段2,字段3);
示例:
create index name_cardid_phone_index on week2(name,cardid,phone); #使用3个字段创建组合索引
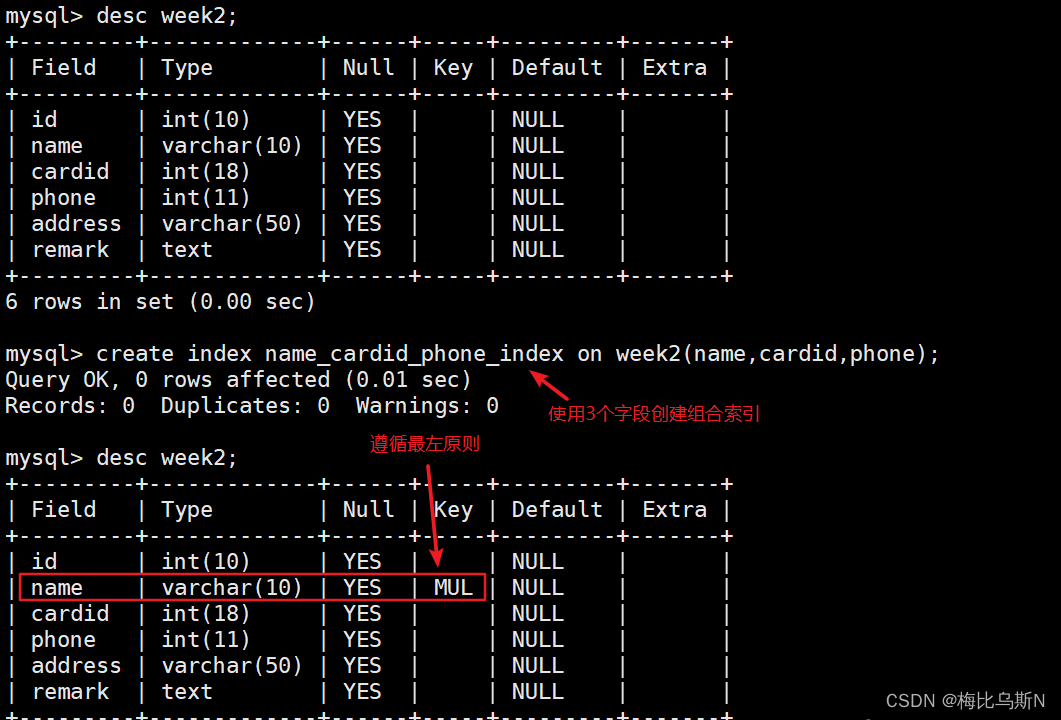
方法二:修改表的方式创建索引
alter table 表名 add index 索引名(字段1,字段2, ..., 字段n);
示例:
alter table week2 add index phone_name_cardid_index(phone,name,cardid);

方法三:创建表的时候指定索引
CREATE TABLE 表名(列名1 数据类型,列名2 数据类型,列名3 数据类型, INDEX 索引名(字段1,字段2,字段3));
示例:
create table queen3(id int(10),name varchar(10),phone int(11),index name_phone_index(name,phone));

5、全文索引
全文索引:适合在进行模糊查询的时候使用,可用于在一篇文章中检索文本信息。
方法一:直接创建索引
create fulltext index 索引名 on 表名 (字段);
示例:
create fulltext index remark_index on week(remark);

方法二:修改表的方式创建索引
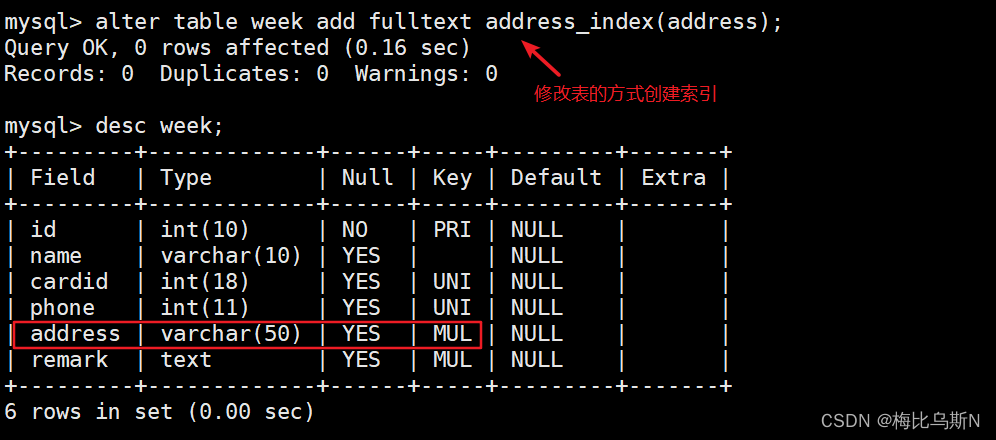
alter table 表名 add fulltext 索引名 (字段);
示例:
alter table week add fulltext address_index(address);
方式三: 创建表时指定索引
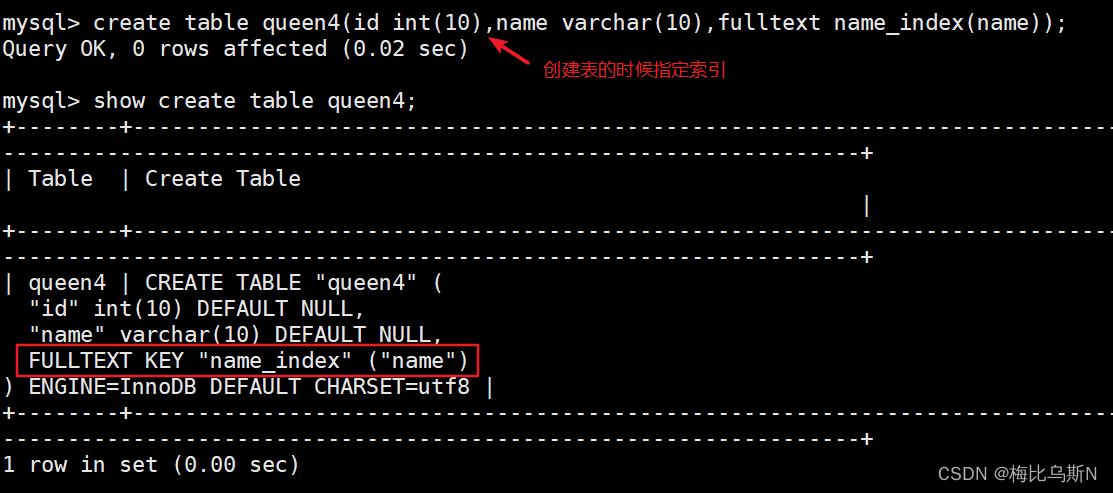
create table 表名 (字段.... , fulltext 索引名 (字段));
示例:
create table queen4(id int(10),name varchar(10),fulltext name_index(name));
全文索引的创建限制:
全文索引只能在char、varchar和text类型的字段上创建:

五、删除索引
除了删除主键索引,删除其他索引的方式是一样的。
1、删除主键索引(即删除主键)
alter table 表名 drop primary key;

2、删除其他索引
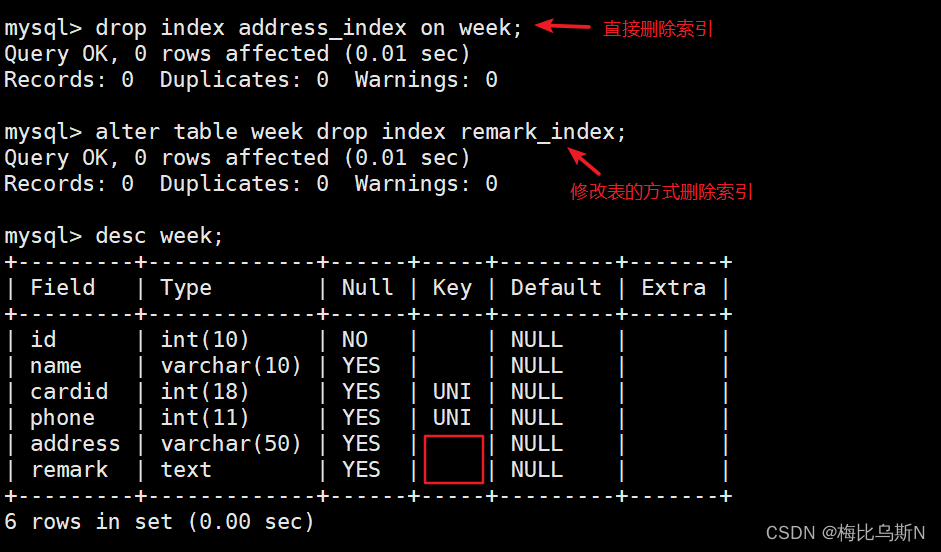
drop index 索引名 on 表名; #直接删除索引
alter table 表名 drop index 索引名; #修改表的方式删除索引
示例:
drop index address_index on week; #直接删除索引
alter table 表名 drop index 索引名; #修改表的方式删除索引
六、总结
1、索引的作用
优点: 加快查询速度,对字段进行排序。
缺点:
-
索引需要占用额外的磁盘空间。
- 对于 MyISAM 引擎而言,索引文件和数据文件是分离的,索引文件用于保存数据记录的地址。
- 而 InnoDB 引擎的表数据文件本身就是索引文件。(索引文件和数据文件是同一个)
-
在插入和修改数据时要花费更多的时间、消耗更多性能,因为索引也要随之变动。
2、创建索引
1)普通索引:
create index 索引名 on 表名 (字段);
alter table 表名 add index 索引名 (字段(4));
create table 表名 (字段.... , index 索引名(字段));
2)唯一索引:
create unique index 索引名 on 表名 (字段);
alter table 表名 add unique 索引名(字段);
create table 表名 (字段.... , unique 索引名(字段));
3)主键索引:
alter table 表名 add primary key (字段);
create table 表名 (字段.... , primary key (字段));
create table 表名 (字段 primary key, ... );
4)组合索引:
create index XXX_index on 表名 (字段1,字段2, ... , 字段n);
alter table 表名 add index XXX_index (字段1,字段2, ... , 字段n);
create table 表名(列名1 数据类型,列名2 数据类型,列名3 数据类型, INDEX 索引名(字段1,字段2,字段3));
5)全文索引:
create fulltext index 索引名 on 表名 (字段);
alter table 表名 add fulltext 索引名 (字段);
create table 表名 (字段.... , fulltext 索引名(字段));
3、删除索引
删除主键索引的方法:
alter table 表名 drop primary key;
删除其他索引:
drop index 索引名 on 表名;
alter table 表名 drop index 索引名;







![[附源码]Python计算机毕业设计SSM流浪猫狗救助站(程序+LW)](https://img-blog.csdnimg.cn/18cbe3eb6baa4b1e9eb0a81b5f9dae51.png)