好奇 Milvus 读链路的演进?不知如何优化 Milvus?提到 Milvus 的业务场景只能靠想象?想获得其他人的部署经验?困惑于 Zilliz Cloud?
不藏了,摊牌了,对于上述的所有问题,你都可以在今天的文章中找到答案!
近期,Milvus 社区 2023 线下 Meetup 北京站圆满结束。本次活动,我们共邀请了 5 位来自内部和外部的社区大佬进行分享。

前方干货值超标预警⚠️⚠️⚠️:
01:Milvus 读链路的演进与未来
02: 从背景到应用:汽车之家的完整调优实践
03: 智慧树:用 Milvus 进行试题查重是一种怎样的体验?
04: 震惊!BOSS 直聘的部署运维心得竟毫无保留
05: 复盘与展望——你必须要知道的 Milvus & Zilliz Cloud
目录在此,各位按需自行手动“跳转”。同时,现场完整版秘籍(PPT)可关注 Zilliz 微信公众号回复【0415】获取。

01.Milvus 读链路的演进与未来
Zilliz 高级研发工程师夏琮祺主要从 Milvus 的读链路从 2.0 到 2.3 Beta 版本的演进路程进行分享。
从 Milvus 2.0 版本开始,读链路的定位便面向云原生架构,因此从架构开始就希望它是一个可扩展的、各个组件之间能够相互解耦合的设计。
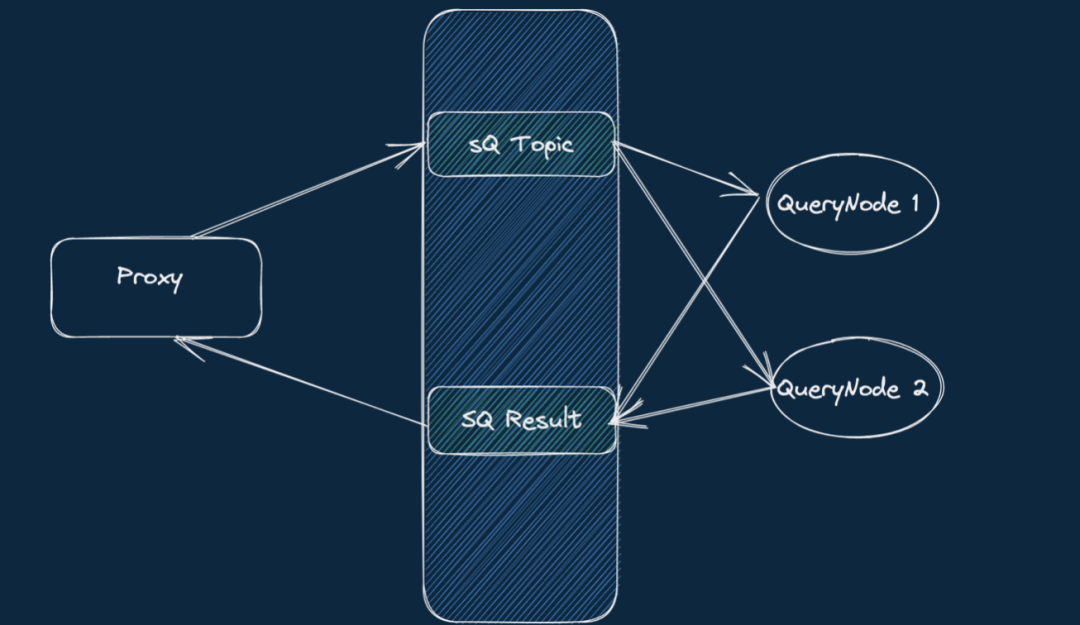
2.0 版本的时候,Milvus 的读链路是经过 MQ 的,对于一个 Collection 的查询,需要获得全体 QueryNodes 的执行结果:
-
Proxy 广播 Search/Query 请求
-
QueryNode 订阅 SQ Topic,处理读请求,Produce 到 SQ Result Topic
-
Proxy 订阅 SQ Result Topic,收到所有的结果后合并、返回
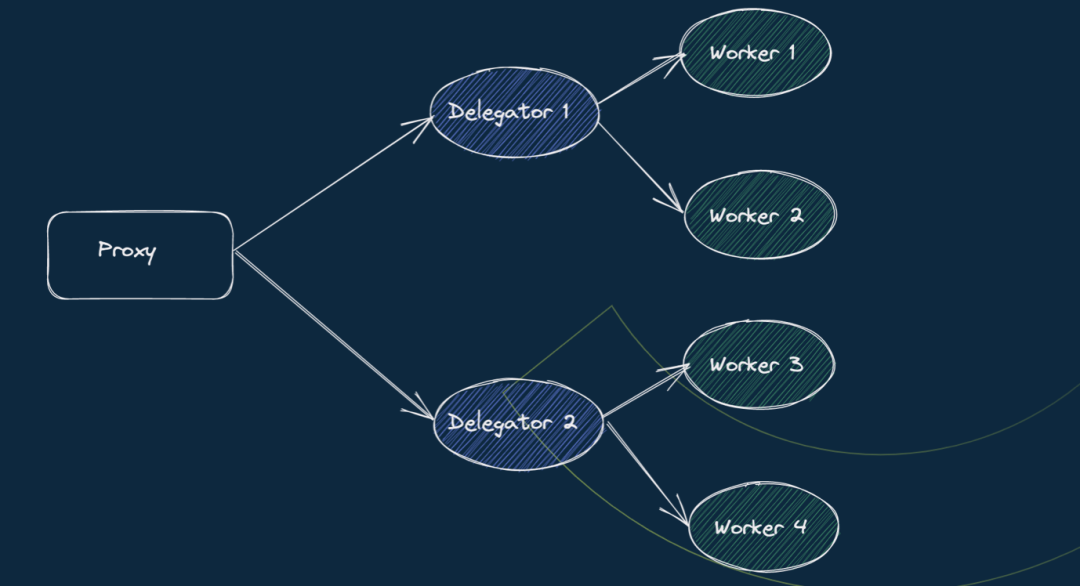
Milvus 2.1 版本的时候,Milvus 引入了通过 Grpc 发起读链路。Proxy 获取 Collection 所有 Channel 对应的 ShardDelegator 列表,通过 Grpc 访问服务:
-
Proxy 通过 QueryCoord 访问获取可用 ShardDelegator 列表
-
Proxy 调用 ShardDelegator 的 Search/Query 接口
-
ShardDelegator 执行请求后返回
此外,Milvus 还进行了一些其他架构的调整,在 2.0 版本的时候,QueryCoord(v1) 所有的操作均进入一个调度器(scheduler)统一调度执行:
-
Load/Release 操作会进入队列排队
-
对应的 Segment 分布会记录在元数据内,所有的 load/release/balance task 也会被记录
Milvus 2.2.3 版本时,QueryCoord V2 通过 Target Driven Load 的方式实时更新 Collection/Partition 的 segment、channel 列表,通过 Checker 来完成数据的正确加载和调整:
-
Load/Release 仅变更 collection/partition 级别的元数据状态
-
通过 Checker 检查 query 集群的 segment 分布来生成 Load/Release task
-
通过 Target 迭代完成“handoff”
目前,Milvus master 版本对 QueryNode 进行重构,移除了开销巨大的 Delta Channel。自从 Milvus 开始支持 Delete 操作后,部分 QueryNode 需要 delta channel 来获取 delete 数据,原因无外乎三点:需要额外的转发操作;MQ 的 topic 数量*2、代价昂贵;一致性等级受到 2 个 channel 的影响。
最后,夏琮祺分享了 Milvus 关于在读链路上相关的规划和展望:
首先是对于 Growing Segment 的优化。Growing segment 作为流式数据,在 2.2.x 版本内无法构建索引,作为木桶效应中较短的那块木板,如果系统中存在大量的 Growing Segments,会严重影响查询效率和吞吐。为此,Milvus 在 2.2.4 版本已经增加了 Ignore Growing 选项,未来会支持对 Growing segments 的索引。
其次是优化 Load。QueryNode 对于 segment 的查询目前为纯内存操作,硬件高昂。对于离线分析场景,颇有“杀鸡用牛刀”的意味。为此,Milvus 计划优化 Load 的内存使用;引入 mmap,能够自定义 buffer manager;实现 Auto Load。
02.从背景到应用:汽车之家的完整调优实践
汽车之家的高级数据工程师王刚进行了《向量检索平台实践》的主题分享。
他提到,汽车之家使用 Milvus 有这样一个背景:
在调研向量检索平台之前,汽车之家的平台用户在搜广推等业务方面,已经基于 Vearch 广泛地使用了向量检索方面的技术,包括推荐召回、视频图片去重、文本检索。不过,这也带来了一些问题,例如维护困难、性能问题、资源浪费、向量数据接入效率低等。
在此情况下,汽车之家选择了 Milvus。原因在于,Milvus 拥有先进的架构思路,例如读、写、建索引不会互相影响;其次,Milvus 社区非常活跃,社区用户提出的问题会有专门的人去跟进、解决,能够及时得到反馈。
在基础建设方面,汽车之家结合 Milvus 的优势与汽车之家向量检索平台本身的需求进行适配和调整,最终搭建出一套流畅、好用的基础设施:
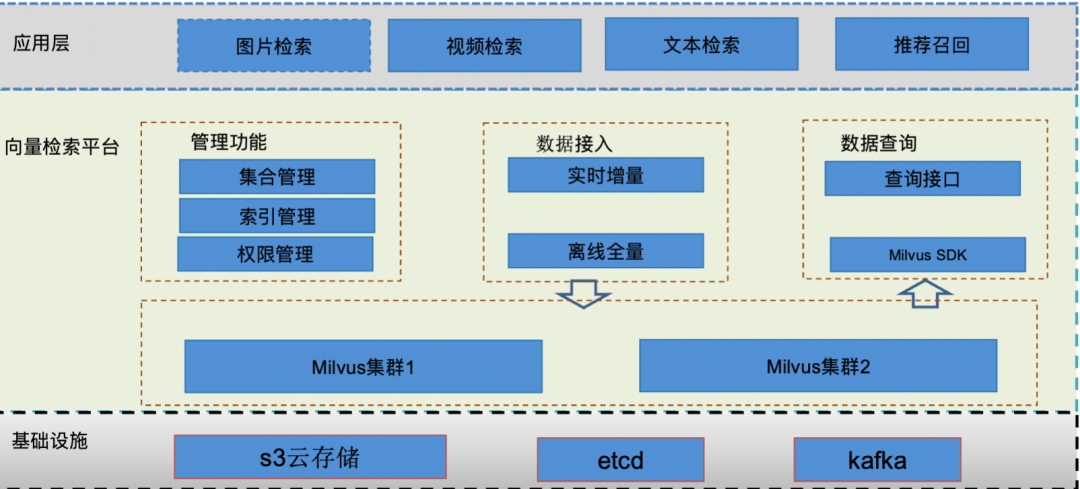
王刚表示,平台的基础设施为 s3 云存储、etcd、kafka,平台支持多个 Milvus 集群,并建了一些管理功能(集合管理、索引管理、权限管理)。再者,汽车之家统一了数据接入的入口,可以通过配置的方式直接把数据接入到 Milvus 中。同时还配置了统一的查询入口,适配了 vearch 的查询语法。在部署层面,汽车之家改造了 Milvus 的原生镜像,使其支持汽车之家流水线。此外,还将 Milvus 部署汽车之家的云 K8S 上。
后续,汽车之家根据自身需求做出的相应调整:
在接入效率方面,规范了接入方式,平台支持通过配置将数据从 Hive 直接导入 Milvus;支持 AB 表的接入模式,思路很简单,每次更新的时候都会建一张新的表,之后会通知平台的查询接口,让其切换到新的表进行查询。
在性能方面,针对网络抖动,汽车之家进行了相应的优化,避免其带来的影响。首先是弱一致性查询的时候不会再请求全局时间戳;其次,将同一副本的 segment 分配在相同的 Query Node 上。
在稳定性方面,在使用 Milvus 2.1 版本时遇到 Datacoord 合并 Segment 卡住、Proxy 偶发性重启、DML Channel 记录位点错误等问题在升级至 Milvus 2.2 版本便得到解决。
03.智慧树:用 Milvus 进行试题查重是一种怎样的体验?
智慧树 AI 能力平台负责人张宇则从偏工程化方面分享了 Milvus 如何在智慧树进行应用落地的过程。
智慧树的定位是全球大型的学分课程运营服务平台,平台的题库拥有亿万级别的海量试题。每学期开学都有很多老师需要将不同课程不同题型的试题导入到题库中去,
由于之前没有做试题去重以及去重的方式效率比较低,题库中存在大量的重复试题,导致数据库中存在大量的冗余数据。
随着数据量的不断增加,平台急需一个试题查重的服务,可以离线处理现有的冗余数据,还能够提供实时服务来能够在导入试题的时候就可以提升给老师有哪些题是重复的,在数据来源就解决重复试题的问题。
但试题查重谈何容易,其中涉及准确率、复杂度和效率问题。首先是准确率的问题,能否尽可能有效地找到重复的题目,不单单是字面意思的相似,还要有题目语义的相似判断。复杂度问题,不同学科课程,需要针对各自的特点采取不同的相似度查重判断的规则。效率问题,批量导入题目的时候,不但需要跟题库里的海量试题比较,还需要跟本次导入的题目做比较,还要保证查重的效率性能足够高,不影响用户体验。
在此情况下,智慧树选用了基于 AI 算法向量+ Milvus 的方案进行题库试题去重:工程服务处理业务逻辑将题目的文本信息调用 AI 算法服务将题目文本转换成向量,然后在 Milvus 中通过向量去搜索相似度大于阈值的向量,将对应向量的题目 id 返回。
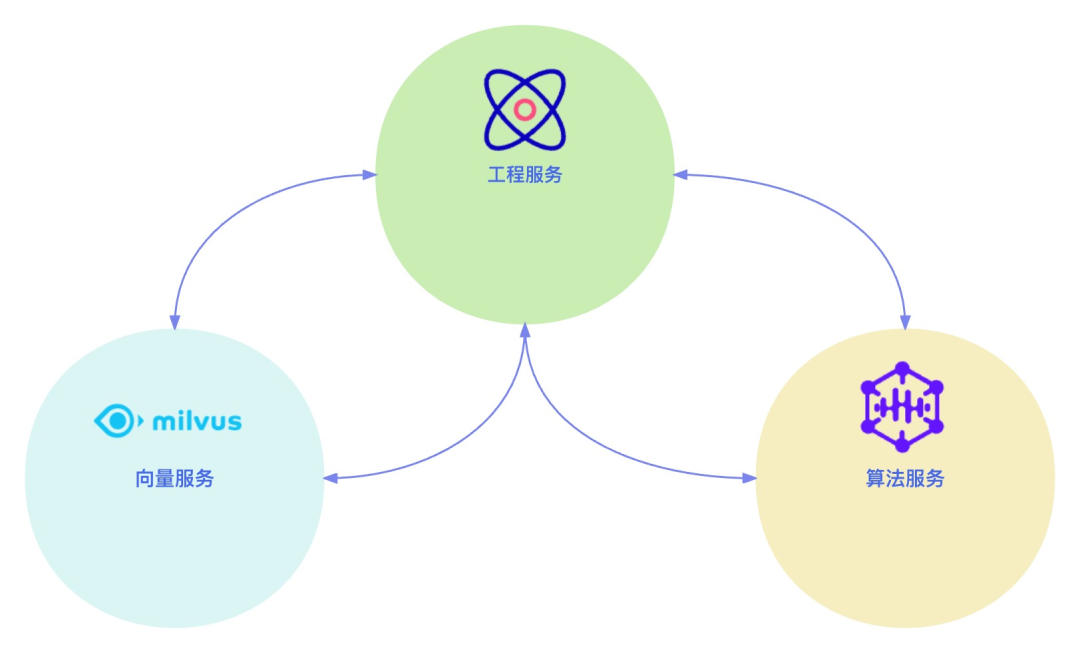
有了题库试题去重的成功业务落地之后,智慧树对向量数据的使用量也是与日俱增。随着其 AI 业务的不断增加,更多的业务需求也随之而来,例如视频、教材、知识图谱等资源的搜索推荐,都会大量使用到向量化的数据来检索相似度,且需要通过使用的不同的模型训练和不同的业务匹配规则。为了更好地支持业务和提升效率,一个通用向量生产平台就变得非常重要。
张宇提到,智慧树通过不同的实时推理集群产生的实时向量和离线训练集群结合数据平台产生的离线向量数据,存储到 Milvus 的集群里,并且利用配置好的规则引擎,来处理向量的生产和相似度检索工作,大大提升了公司的向量生产性能和效率,更好地支持了业务的使用。
04.震惊!BOSS 直聘的部署运维心得竟毫无保留
BOSS 直聘的 AI 研发工程师马秉政分享主要从 Milvus 的部署运维方面进行了经验分享。
BOSS 直聘 Arsenal 算法平台,是面向 BOSS 直聘全厂数据/算法工作者的一站式 AI 开发平台,包括数据处理、模型训练、推理服务、MLOps、运行监控、平台管理和产品体验。平台在向量检索的主要使用场景是相似图片召回、相似文本召回和推荐召回。
马秉政表示,在目前公司的众多算法部分中,实现向量检索的手段各不相同,包括:在内存中暴力计算;基于 Faiss 实现索引,自建服务;使用平台提供的向量检索系统。不过,这也带来一些存在计算瓶颈、资源浪费、服务稳定性不足的问题。
选择 Milvus 的原因也很简单,包括云原生特性、存算分离、有多样索引支持、简单易用。
随后,马秉政又从集群部署、业务指标调优以及稳定性建设方面进行了分享。
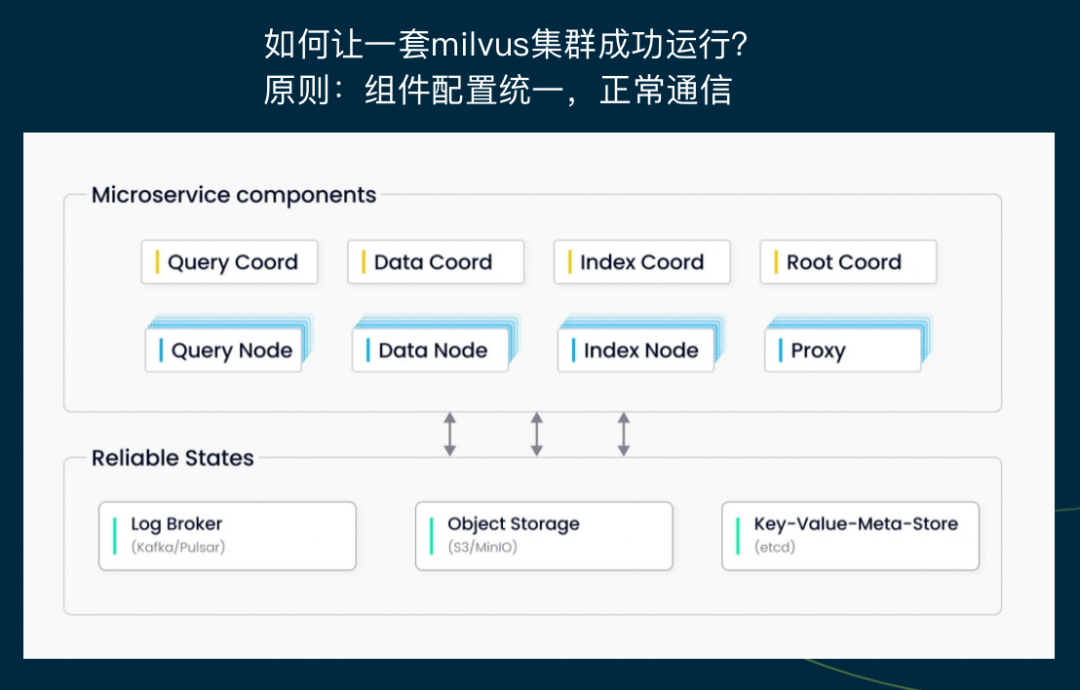
首先是集群部署。在进行部署方案的选择时,BOSS 结合 Docker compose 、Helm chart 进行部署、拆解。
那么,有没有好的部署经验?马秉政表示,让一套 Milvus 集群成功运行的原则就是组件配置统一、正常通信。解释一下这句话的意思,Milvus 的内部无状态组件共 8 个,依赖 3 个外部服务/中间件,以经验来看,Milvus 的部署原则只有一个,即只要能保证各个组件的配置统一,且能够正常通信,就能使一套 Milvus 集群运行。
其次是业务指标调优。通常对于业务来讲,最关注的就是 QPS 与 TP99,根据不同的业务场景的调优方案也不同。
例如 TP99,首先直接影响查询延迟的变量就是数据量了。在不考虑索引的情况下,1000w 128 维的检索耗时一般在 100ms 以下,更高的数据量可以通过数据分区来降低耗时。
又如 QPS,增加 querynode 的 CPU 资源是提升 QPS 的直接手段。另一个手段是增加副本数,Milvus 最多支持等同于 querynode 数量的副本数,用内存换 QPS,需要进行取舍。在部署 querynode 时,BOSS 通过 cpuset 绑核 + single numa 限制 CPU 在单一的 numa node 上,保证 querynode 的资源可用性,提升内存的访问效率,达到提升性能 + 查询耗时的稳定性的效果。
在稳定性建设方面,Milvus 的 backup 工具提供了 collection 的跨集群备份恢复能力。此外,团队会为每一个集群分别创建读写两个域名,这样增加了一层操作空间,当一个集群出现写入问题时,可以先将写域名切到新集群以供数据更新,待所有数据恢复后切换读域名,这样可以让查询端无感知。而对于稳定性要求高的业务,会采取主备集群的方法,来确保出现问题时,有一定的缓冲空间。
此外,马秉政也提示,Birdwatcher 是运维管理 Milvus 集群非常重要的工具。
05.复盘与展望——你必须要知道的 Milvus & Zilliz Cloud
Zilliz 合伙人、产品总监郭人通从 Zilliz 最近的重要进展、Milvus 关键的功能特性以及 Zilliz Cloud 的产品蓝图三个方面进行了分享。
郭人通表示,过去 3 个月的时间,Zilliz 成果颇丰,包括:
-
和英伟达 GPU 的索引算法库进行深度集成,与 CPU 相比,HNWS 的性能大幅提升;
-
Milvus 从 2.0 版本升级至 2.2.3 后,性能提升 4.5 倍;
-
扩展性方面,Milvus 能够处理 10 亿级别的 768 维向量;
-
Milvus 关键功能方面新增支持 Range Search、Upsert 和 Bulk Insert;
-
目前 Milvus 已经能够支持 Resource Group、Rolling Upgrade、Quota protection、Dynamic config update;
-
-针对今年来大火的 AIGC,Zilliz 在生态上做了集成,包括 OpenAI、 Hugging Face、 Langchain、LLaMA-Index、Nvidia Merlin。
随后,郭人通介绍了 Milvus 最近的关键功能特性。除了最近新增的特性(包括加速混合过滤的速度、新增磁盘索引)外,他着重介绍了未来 Milvus 2.3 和 2.4 版本的重要变化。
首先是 Milvus 2.3 将支持 Json 数据类型,在此基础上亦会支持 Schemaless。此前,用户在使用 Milvus 的过程中会先定一个静态 Schema,此时,如果在实际业务层面如果多了几个 feature 或者 Metadata,就意味着数据需要重新来过。经此变化后,Milvus 2.3 便可实现动态部分通过 Json 列支持。

其次,Milvus 2.3 也会支持 vector list。在实践过程中,团队发现很多用户的业务并不非以一个向量为单位,例如视频或者长页文档,可能每段都会对应一个向量,然而进行查询业务时却需要将整篇文档或整个视频作为查询对象。以视频为例,有了 vector list 以后,一个数据实例可以拥有一个属性列。在这个属性列中,一个视频对应一个主键,视频连续关键帧的 vector list 对应该行的一个属性。由此便可支持这一组向量的近似查询。
Multi vector embeddings 是 Milvus 2.3 版本的另一个重要特性。同样以视频为例,视频帧的特性会有一个 embedding,而视频的标题可能还有另外的 embedding。这两套 embedding 各行其道,实际进行查询时不仅需要标题近似,内容部分也要相契合。当然,这一点与后续提及的混合查询也是强相关。
提及 Milvus 2.4 的重要特性,郭人通强调,该版本的重要特性之一便是混合查询。正如之前所言,在数据 Schema 中包含传统的静态 Schema 和动态 Schema,其中包含密集向量、稀疏向量、文本相关、标签数值等。各列可以进行混合查询及属性过滤,随后会进行融合的 ranking。这个过程有点类似推荐系统中的粗排精排。目前团队实现了一种比较简单的线性加权的方式做融合,后续会根据社区需求选择其他处理方案。
最后一部分是 Zilliz Cloud。整体而言,Zilliz Cloud 的规划分为三个阶段,第一个阶段的主要任务是支持维护好基本的数据库操作。目前,Zilliz 已经完成了第一阶段的规划,在云上有超过 1000 位用户,支持两朵云(AWS GCP),使用 Cluster 的部署方式,性能方面与 Milvus 2.0-2.2.3 一致,吞吐为 4.5 倍,延时降低 2.5 倍。第二阶段是实现 Zilliz Cloud 与 Milvus 关键特性的持平及稳定,覆盖阿里云,提供 Serverless 支持;第三阶段将支持微软云,实现面向云服务的 GPU 版本的资源优化。

此外,近期 AIGC 开发者的需求增长迅速,针对这部分用户对于上游大模型、模型服务提供商的生态对接需求,郭人通表示,团队正计划于 2023 年 7 月底前集成完毕,包括 OpenAI、Google、国内中文大模型等。
🌟相关链接🌟
1. OSSChat:艾瑞巴蒂看过来!OSSChat 上线:融合 CVP,试用通道已开放
-
GPTCache: 我决定给 ChatGPT 做个缓存层 >>> Hello GPTCache
GPTCache:LLM 应用必备的【省省省】利器
-
Zilliz Cloud: LLM 快人一步的秘籍 —— Zilliz Cloud,热门功能详解来啦!
本文由 mdnice 多平台发布