大白话chatGPT & GPT的发展区别
- 从GPT名字理解chatGPT
- chatGPT三步曲
- GPT-1到GPT-4
- GPT-1~GPT-4的相同点
- GPT-1~GPT-4的区别
- GPT-1——pre-training + fine-tune,自监督学习=无监督预训练+有监督微调
- GPT-2——zero-shot,无监督学习,多任务学习
- GPT-3——zero-shot+few-shot,海量参数
- GPT-4——多模态模型,海量参数
- 相关参考文献积推荐阅读的文献
chatGPT今年年初的时候是非常火爆的,现在也有很多相关的应用和插件。当然现在也有很多新的技术出现,比如autoGPT,它实际上就是嵌套chatGPT。所以这里笔者我希望通过通俗易懂的语言描述一下chatGPT的原理。当然这里笔者是根据自己看的知识进行快速的印象中的总结,如果有不对的地方,非常欢迎指正,也欢迎大家互相学习与交流。
从GPT名字理解chatGPT
chatGPT它是基于GPT3的。GPT也就是Generative Pre-training Transformer模型。从名字上来看,其实也可以知道GPT模型其实有三个核心点:
- 一个是Generative生成式,也就是说GPT它其实是一个生成模型,而且这个生成模型它是基于NLP领域的,所以chatGPT就可以看成一个文字接龙的生成式模型(从外观上看,像前端的流式输出)。
- 第二个是Pre-train预训练,也就是说GPT是一个基于预训练微调的模型,而且GPT是基于大语言模型(LLM)的,因为需要有足够多的数据才能保证更好的语义理解和上文理解。
- 第三个是Trasformer,也就是说GPT模型都使用了Transformer的架构,这就意味着它们都有编码器和解码器来处理输入输出并且都基于多头自注意力机制来实现的,这样子可以使模型关注会话中的不同部分,从而来推断出会话本身的含义和上下文。因为句子中不同词的重要性是不一样的。除此之外,GPT的解码器利用了掩码来进一步构建训练的数据集,这样子其实就像挖词填空,更加有利于模型学习文字跟文字的关系,更有利于文字接龙的准确性。
如果对Transformer不是很理解,可以看我的另外一篇博客《从前端角度快速理解Transformer》。
chatGPT三步曲
因为chatGPT是基于GPT的嘛,所以它的原理其实跟GPT是有些类似的,但它引入评分反馈的训练机制来进行强化学习【人类反馈强化学习RLHF】。主要实现的流程也一样是三部曲:
- 第 1 步:监督微调 (SFT) 模型,利用海量的问答式样本数据集对GPT模型的输出方向进行监督训练,引导GPT采用问答对话的形式进行内容输出。通过微调策略得到GPT-3.5模型。
- 第 2 步:训练一个奖励模型(RM)。训练一个奖励模型对GPT-3.5模型的输出进行一个排序评分,就相当于一个老师,当给出一个问题和四个答案,老师负责按照人类的偏好给这些答案进行打分,将答案进行排序。所以这里的设计跟以往的模型不太一样,因为这里是对输出结果进行排序而不是取值或者取分布。【这里也是有监督数据集的】,基于对比的数据训练建立模型。
- 第 3 步:利用强化学习最大化奖励。基于上面的两步,就可以拥有一个具备对话的GPT和一个能够按照人类偏好进行打分的奖励模型,因此到这里我们就可以利用强化学习来进行一步的自我训练,从而最大化第二步里面的评分。
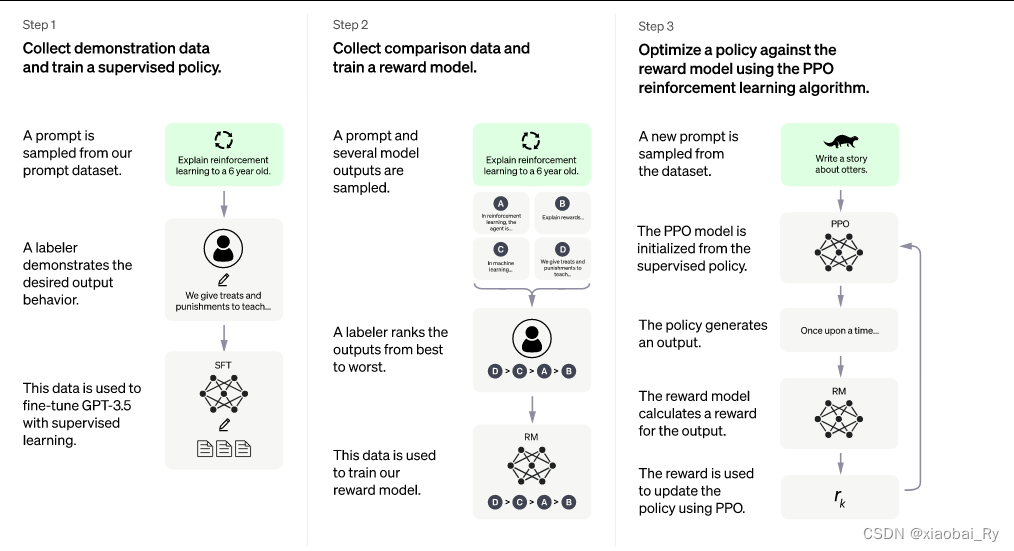
通过上面的训练就可以得到最后的chatGPT模型。
GPT-1到GPT-4
GPT-1~GPT-4的相同点
GPT-1到GPT-4,包括chatGPT的结构其实都是大语言模型,都是基于Transformer的Decoder层,都秉承着不断堆叠Trasnformer的思想,通过不断替身训练的预料规模和质量,提升网络的参数量来完成进一步的迭代更新和性能优化,所以我们也可以看到GPT发展到现在它的参数量从以前GPT-1的1点多个亿的参数量到现在GPT-4的100万亿的参数量,增长速度我认为是堪比指数的😂。迭代速度也非常快。它们之间的区别主要在于它们的核心改进要点的不同(为什么是改进要点,因为它是继承发展的)。

GPT-1~GPT-4的区别
GPT-1——pre-training + fine-tune,自监督学习=无监督预训练+有监督微调
📎 论文:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
📎 代码:GitHub - karpathy/minGPT: A minimal PyTorch re-implementation of the OpenAI GPT (Generative Pretrained Transformer) training
首先,GPT-1出现的背景原因有两个:一个是大量且高质量的标注数据是难以获取的,而且标签label并不一定唯一,存在界限模糊的现象;另外一个是以往的NLP模型大多是领域专家,也就是说它很难泛化到其他任务中,这也是它基于固定任务有监督学习所导致的。

所以GPT-1为了改善上面所说的两个局限性,提出了一种半监督(后面也普遍称之为自监督)的方法,也就是现在没有标注的数据上无监督地训练一个预训练模型,再在特定的任务上利用少量标注数据上有监督地训练一个分辨的微调模型。通过无监督预训练和有监督微调的结合的生成预训练模式来提高语言模型的泛化性同时也解决无大量标注数据的情况。

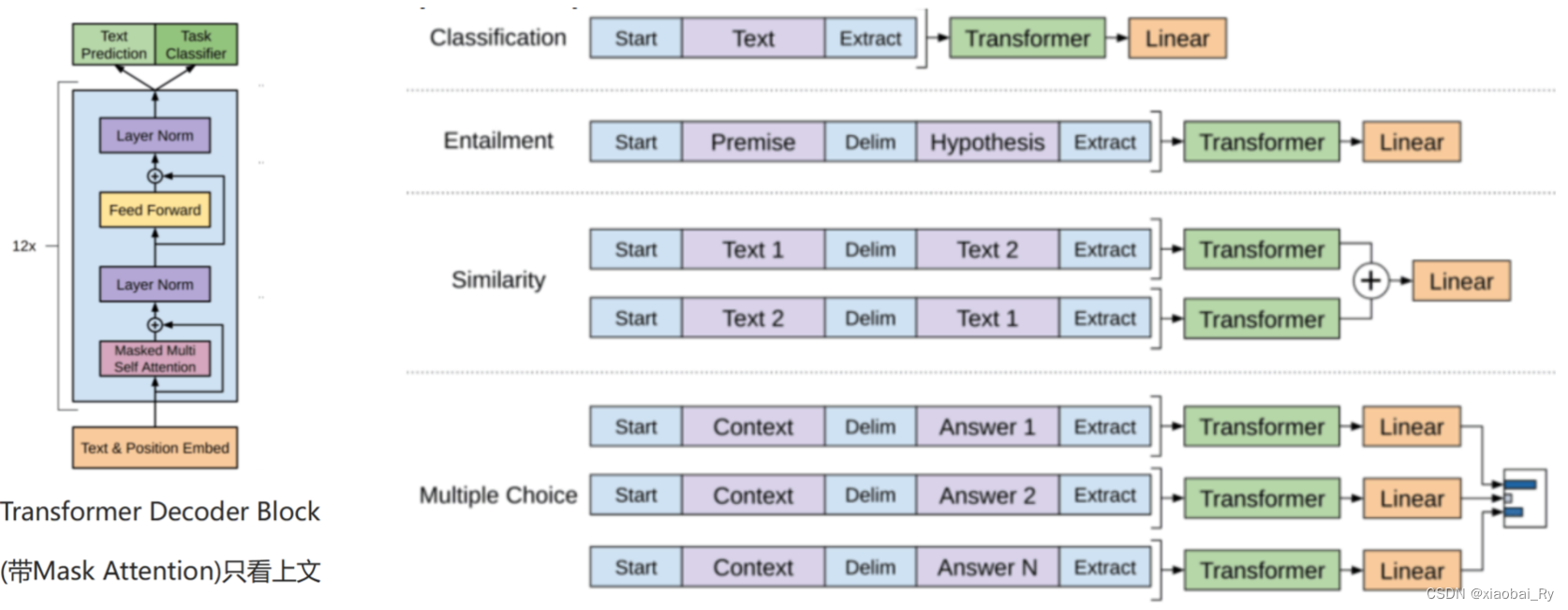
- 与BERT的比较:是否带有Mask的Attention(GPT只看上问),在同等参数条件下 效果不如Bert-Base
- GPT-1中:Decoder部分采用Masked-Attention(有遮盖的注意力机制,每个词只能看到它的上文)Encoder部分采用的是普通Attention(每个词可以同时看到上下文),
为什么只看到上文,其实也可以理解,因为GPT是一个文字接龙的模型。而且长远来看,Masked-Attention是push模型更好理解文字的重要手段,毕竟在现实中,我们更希望培养模型知上文补下文,而不是单纯地做完形填空。
GPT-2——zero-shot,无监督学习,多任务学习
📎 论文:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
📎 代码:GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
与GPT-1相比,GPT-2主要面向的是多任务的场景。GPT-2去掉了GPT-1中有监督的微调fine-tune阶段,也就是去掉根据特定任务微调的策略,使模型成为完全的无监督模型,能更多的去执行多样性的任务。所以,GPT-2也就相当于无监督的预训练阶段+zero-shot的下游任务。
🤔 什么是zero-shot?
这个概念其实来源于元学习,而且一般提到zero-shot,我们都会跟one-shot,few-shot进行对比。
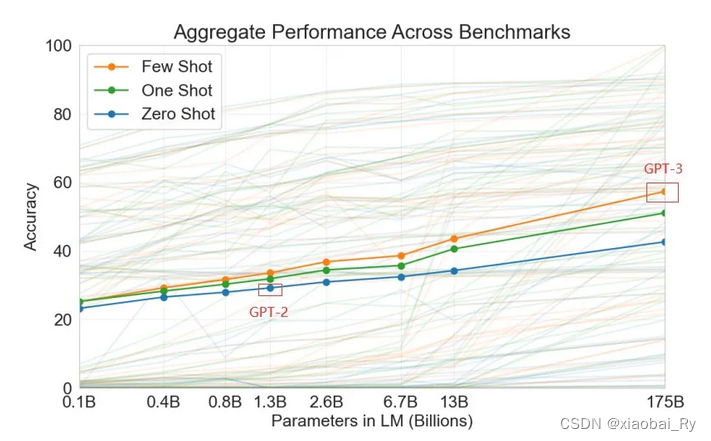
• Zero-shot:只给出任务描述(description)和任务提示(prompt)
• One-shot:给出任务描述,给出一个例子(example),给出任务提示
• Few-shot:给出任务描述,给出若干个例子,给出任务提示
因此,GPT-2希望利用Zero-shot这种类型的数据,让模型自己去学习怎么做,做什么,从而训练一个通用的模型。从上面样本的构建也可以看出来,利用zero-shot构建的样本模板更加符合人的一个输入输出(日常表达)。但如果后期还是不做微调的话,很难有较高的精度。
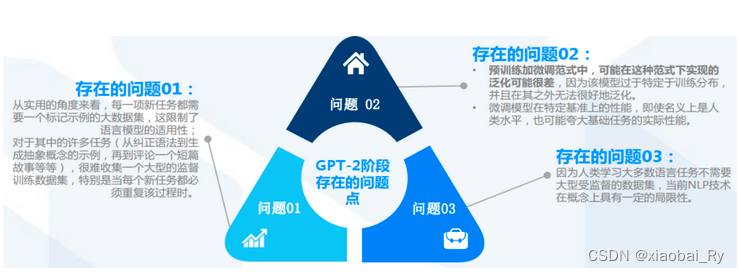
GPT-2的局限性:
GPT-3——zero-shot+few-shot,海量参数
📎 论文:[2005.14165] Language Models are Few-Shot Learners
📎 代码:GitHub - openai/gpt-3: GPT-3: Language Models are Few-Shot Learners
与GPT-2相比,GPT-3同样沿用去除微调的策略,继续沿用zero-shot来训练一个通用模型的思路。同时,为了解决zero-shot带来的问题,GPT-3引入了few-shot,用少量的文本来提升模型的有效性。
GPT-4——多模态模型,海量参数
GPT-4的重点可以其实就是工程化的一个过程——模块化(充分利用小模型),安全化(做了相关的安全保护措施),通用化(多模态模型使其可以接收多样化的数据,在更多的领域得以应用)。
GPT-4 的重点是提供更强大的功能和更有效的资源使用。它不是依赖大型模型,而是经过优化以充分利用较小的模型。通过足够的优化,小模型可以跟上甚至超越最大模型。此外,较小模型的实施允许创建更具成本效益和环境友好的解决方案。
而且因为GPT-3的泄漏问题,GPT-4其实也做了相应的措施。在内部评估中,与GPT-3.5相比,GPT-4对不允许内容做出回应的可能性降低82%,给出事实性回应的可能性高40%。

相关参考文献积推荐阅读的文献
-
从GPT-1到GPT-4,再到未来的GPT-5,一文带你了解GPT的前世今生和未来! -腾讯云开发者社区-腾讯云
-
Chatgpt 里面gpt 代表什么? - 知乎
-
GPT系列:GPT, GPT-2, GPT-3精简总结(模型结构+训练范式+实验)gpt3模型结构#苦行僧的博客-CSDN博客
-
GPT/GPT2/GPT3/ChatGPT梳理
-
GPT-1,GPT-2和GPT-3发展历程及核心思想,GTP-4展望-CSDN博客
-
GPT系列学习笔记:GPT、GPT2、GPT3GPT系列学习笔记:GPT、GPT2、GPT3_格日乐图~璇的博客-CSDN博客
-
聊聊Chat GPT-1到GPT-4的发展历程-36氪