安装jdk
版本选择:最好是java 8、java11或者java14
jdk兼容性:https://www.elastic.co/cn/support/matrix#matrix_jvm
操作系统兼容性:https://www.elastic.co/cn/support/matrix
自身兼容性:https://www.elastic.co/cn/support/matrix#matrix_compatibility
安装elasticsearch
下载elasticsearch-7.10.0
https://www.elastic.co/cn/downloads/elasticsearch
https://elasticsearch.cn/download/
下载之后解压到一个位置
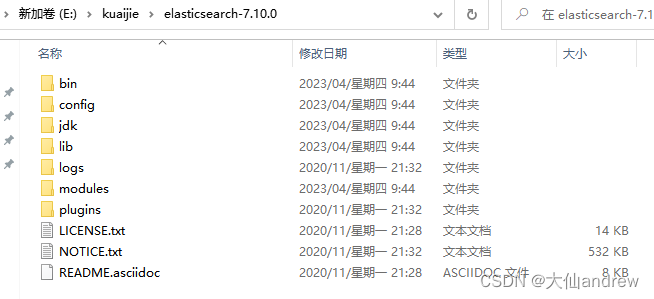
| 目录名称 | 描述 |
|---|---|
| bin | 可执行脚本文件,包括启动elasticsearch服务、插件管理、函数命令等。 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| lib | elasticsearch所依赖的java库。 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境要求必须修改。不建议放在elasticsearch目录。 |
| logs | 默认的日志文件存储路径,生产环境务必修改。不建议放在elasticsearch目录。 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 已经安装的插件的目录。 |
| jdk/jdk.app | 7.0以后才有,自带的java环境。 |
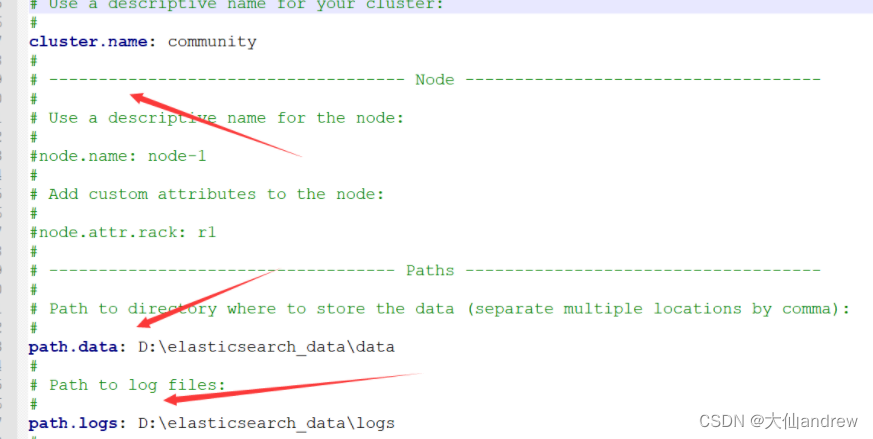
修改elasticsearch.yml
修改config目录下的elasticsearch.yml配置文件cluster.name、path.data、path.logs等(可以参照后边的启动参数)
当然也可以不用修改,在后边的启动的时候进行设置启动参数。
贴个常见的配置文件,可以认识配置。
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称,没有配置的话,默认是当前主机名
node.name: node-1
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-1/data
# log目录
path.logs: /usr/local/node-1/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200
http.port: 9200
# 内部节点之间沟通端⼝
transport.tcp.port: 9300
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
修改 jvm.options 配置
## 修改内存大小 ,内存小我就设置成这样了
-Xms512m
-Xmx512m
启动elasticsearch
进入到bin目录下
# 没有修改配置文件的启动
.\elasticsearch.bat -E path.data=E:\kuaijie\elasticsearch-7.10.0\el_data\node1 -E path.logs=E:\kuaijie\elasticsearch-7.10.0\el_logs\node1 -E node.name=node1 -E cluster.name=my_teach
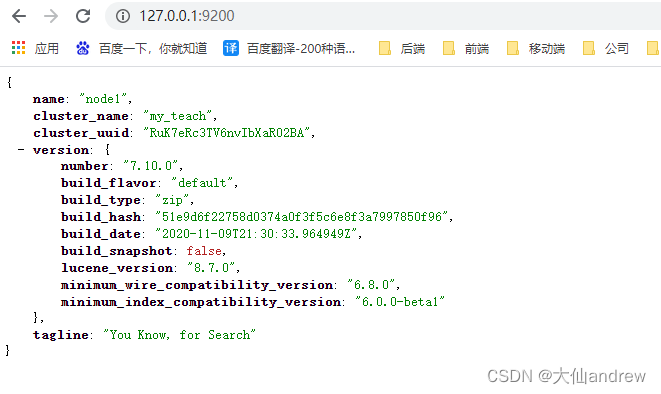
访问
http://127.0.0.1:9200/
http://127.0.0.1:9200/_cat/health
http://127.0.0.1:9200/_cat/nodes?pretty
这样,一个简易版的elasticsearch服务就启动成功了。
多节点启动
多节点启动有两种方式:
-
单个项目启动多节点,就是通过在启动的时候配置参数的方式(生产环境不推荐)
-
多个项目启动多节点,就是配置好的elasticsearch项目程序,复制好几份的方式进行启动
安装Kibana
下载kibana-7.10.0
注意:
在配置文件kibana.yml中,已经配置了elasticsearch服务的地址:
#elasticsearch.hosts: ["http://localhost:9200"]
启动Kibana
进入到bin目录下,启动kibana.bat。

访问
http://127.0.0.1:5601
在左侧的菜单栏中,打开Deb Tools,进行简单的测试。
关于“Kibana server is not ready yet” 问题的原因及解决办法
-
Kibana和Elasticsearch的版本不兼容。
解决办法:保持版本一直
-
Elasticsearch的服务地址和Kibana中配置的elasticsearch.hosts不同
解决办法:修改kibana.yml中的elasticsearch.hosts配置
-
Elasticsearch中禁止跨域访问
解决办法:在elasticsearch.yml中配置允许跨域
-
服务器中开启了防火墙
解决办法:关闭防火墙或者修改服务器的安全策略
-
Elasticsearch所在磁盘剩余空间不足90%
解决办法:清理磁盘空间,配置监控和报警
安装head插件
下载elasticsearch-head项目方式
-
安装依赖:
(1) 下载node:
① 下载地址:https://nodejs.org/en/download/
② 检查是否安装成功:Win+R CMD输入“node -v”命令检查,如果输出了版本号,则node安装成功。
(2) 安装grunt:
① CMD中执行“npm install -g grunt-cli”命令等待安装完成
② 输入:grunt -version命令检查是否安装成功
-
下载Head插件
(1) 下载:git clone https://github.com/mobz/elasticsearch-head
(2) 下载完成后,解压,修改Gruntfile.js文件,在connect–server–options下,添加hostname:‘*’。
connect: { server: { options: { hostname: '*', port: 9100, base: '.', keepalive: true } } }(3) 输入 cd elasticsearch-head npm install
(4) 输入 npm run start 启动服务
(5) 验证:http://localhost:9100/ 安装成功
(6) 如果无法发现ES节点,尝试在ES配置文件中设置允许跨域
http.cors.enabled: true http.cors.allow-origin: "*"或者使用下载下来的项目的crx目录下的插件。
Chrome网上应用店下载插件方式
需要先下载elasticsearch head的插件,安装到浏览器中,使用的时候点击它,就会出现可视化的页面。
仔细观察,elasticsearch-head项目里边也有这个插件的。
安装ik分词器
下载es对应版本
https://github.com/medcl/elasticsearch-analysis-ik/releases
解压到 es目录下的plugins下 命名为ik
重启es