背景
在以torch为基础的很多框架下有一些集成的数据集,数据集往往自带已经划分好的mask。但是如何能够把框架给出的mask再次划分?比如按比例划分出来80%的train mask。
解决
新生成一个每个元素都是0-1分布的与mask2的true位置相同的矩阵,用0.7作为threshold分别把数字转化成True或者False。
以转化后的mask2作为划分的mask。
这样大概率是train mask的70%被选取出来。
于是,
1)先生成一个0.7概率的每个位置都是伯努利分布的tensor
2)
train_mask=dataset['train_mask']
p=0.7*torch.ones(3,4)
mask70=torch.bernoulli(p).bool()
new_mask=train_mask & mask70
(有没有更好的办法?)
结果
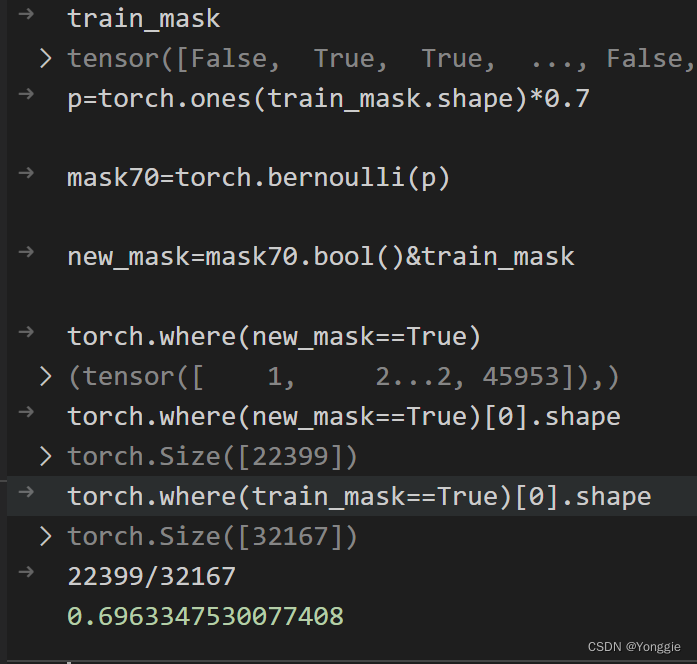
最后试了一下,还是比较稳定的能够把70%的原先train的数据取出来。
另torch的三种mask操作
torch中对mask有三种操作。
mask_fill是把mask为true位置的地方赋一个值:
import torch
mask = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]]).bool()
# tensor([[ True, False, False],
# [False, True, False],
# [False, False, True]])
a = torch.randn(3,3)
a.masked_fill(mask, 0)
# tensor([[ 0.0000, 0.6781, 0.6532],
# [-1.2078, 0.0000, 0.4964],
# [ 0.2192, -0.6276, 0.0000]])
a.masked_fill(~mask, 0)#可以对mask取反
# tensor([[-0.4438, 0.0000, 0.0000],
# [ 0.0000, 1.3907, 0.0000],
# [ 0.0000, 0.0000, 2.2462]])
mask_selected是产生mask并且按照true false位置选取,这个其实就是最基本的用法a[mask]或者a[~mask],只不过显式写出来就是了。
import torch
x = torch.randn(3,4)
# tensor([[ 0.2914, -0.1056, 0.4946, 0.2926],
# [-1.0920, -0.2156, 3.0989, -0.9067],
# [-0.1522, 1.9527, 0.1660, 0.8310]])
mask = x > 0.5
# tensor([[ 0.2914, -0.1056, 0.4946, 0.2926],
# [-1.0920, -0.2156, 3.0989, -0.9067],
# [-0.1522, 1.9527, 0.1660, 0.8310]])
torch.masked_select(x, mask)
# tensor([3.0989, 1.9527, 0.8310])
mask_scatter是把mask位置的元素从b取出来并且在相同位置赋值给a
import torch
mask = torch.BoolTensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]])
# tensor([[ True, False, False],
# [False, True, False],
# [False, False, True]])
a = torch.randn(2,3,3)
b = torch.ones_like(a)
a.masked_scatter(mask, b)
# tensor([[[ 1.0000, -0.1560, -0.7760],
# [-0.5192, 1.0000, -0.1709],
# [ 0.2091, 0.5650, 1.0000]],
# [[ 1.0000, 0.0623, -0.1447],
# [-1.2910, 1.0000, -1.2722],
# [-0.7864, -0.1118, 1.0000]]])
参考:https://blog.csdn.net/weixin_41102519/article/details/121337359以及torch文档











![[附源码]计算机毕业设计springboot行程规划app](https://img-blog.csdnimg.cn/5c26791d1a1d4049b56b42efd21e1b05.png)