ChatGLM-6B-PT
一、前言
近期,清华开源了其中文对话大模型的小参数量版本 ChatGLM-6B(GitHub地址:https://github.com/THUDM/ChatGLM-6B)。其不仅可以单卡部署在个人电脑上,甚至 INT4 量化还可以最低部署到 6G 显存的电脑上,当然 CPU 也可以。
随着大语言模型的通用对话热潮展开,庞大的参数量也使得这些模型只能在大公司自己平台上在线部署或者提供 api 接口。所以 ChatGLM-6B 的开源和部署在个人电脑上,都具有重要的意义。
二、下载
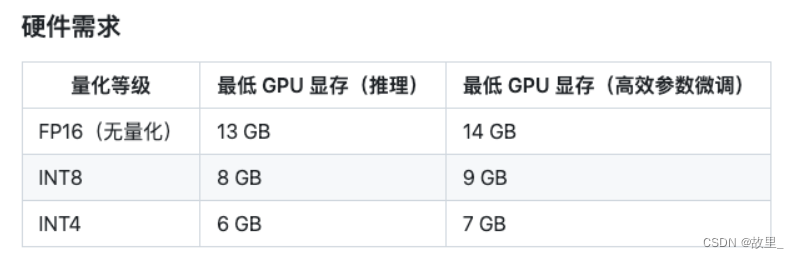
本仓库实现了对于 ChatGLM-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
下面以 ADGEN (广告生成) 数据集为例介绍代码的使用方法。
软件依赖
运行微调需要4.27.1版本的transformers。除 ChatGLM-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
使用方法
下载数据集
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)。
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
Google Drive:https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view
Tsinghua Cloud:https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
三. 训练
运行以下指令进行训练:
bash train.sh
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
四. 推理
将 evaluate.sh 中的 CHECKPOINT 更改为训练时保存的 checkpoint 名称,运行以下指令进行模型推理和评测:
bash evaluate.sh
评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在:./output/adgen-chatglm-6b-pt-8-1e-2/generated_predictions.txt
- 例子
示例1
Input: 类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞
Label: 简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。
Output[微调前]:这件上衣的材质是牛仔布,颜色是白色,风格是简约,图案是刺绣,衣样式是外套,衣款式是破洞。
Output[微调后]: 这是一款简约的牛仔外套,破洞设计,将牛仔布破洞,带来一种随意与个性。破洞的牛仔外套,展现出时尚气息,带来一种休闲感。同时,刺绣图案,让整件外套更加立体。
示例2
Input: 类型#裙*版型#显瘦*风格#文艺*风格#简约*图案#印花*图案#撞色*裙下摆#压褶*裙长#连衣裙*裙领型#圆领
Label: 文艺个性的印花连衣裙,藏青色底蕴,低调又大气,撞色太阳花分布整个裙身,绚丽而美好,带来时尚减龄的气质。基础款的舒适圆领,简约不失大方,勾勒精致脸庞。领后是一粒包布扣固定,穿脱十分方便。前片立体的打褶设计,搭配后片压褶的做工,增添层次和空间感,显瘦又有型。
Output[微调前]: 类型#裙版型#显瘦风格#文艺风格#简约图案#印花图案#撞色裙下摆#压褶裙长#连衣裙裙领型#圆领 1. 连衣裙:简约风格,裙长为膝盖以上,裙领型为圆领。2. 裙下摆:压褶设计,使裙摆呈现出流畅的褶皱效果。3. 裙领型:裙领型为圆领,使穿上连衣裙后更加有型。4. 版型:采用显瘦设计,让连衣裙看起来更加苗条。5. 风格:文艺风格,让连衣裙更加有内涵和品味。6. 图案:印花设计,在连衣裙上印有独特的图案。7. 撞色:采用撞色设计,让连衣裙在色彩上更加鲜明、富有层次感。
Output[微调后]: 这是一款文艺范的连衣裙,以印花为元素,采用简约的印花,既能够突出文艺气质,又能够展现简约风。在印花的同时又有领子和裙摆的压褶设计,更加凸显文艺气质。简约而不会过于单调,搭配出街,穿着十分舒适。
复现过程
AI对话
执行 python 文件即可,可以在命令行终端输入:
python cli_demo.py
即可启动 demo,开始使用了!
 自己写代码调用模型来运行
自己写代码调用模型来运行
用如下几行代码,就能启动模型运行,并输出结果。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
ques = '''
下面这段代码的功能是什么?
# QSort
nus = [4, 5, 1, 2, 3, 5, 4, 1]
# left,right分别为子数组中第一个元素和最后一个元素在原数组中的位置
def QSort(left, right):
# 边界条件
if left >= right:
return
# 初始化左右指针的初始值
l, r, key = left, right, nus[left]
# 调整元素的位置
while l < r:
while l < r and nus[r] >= key:
r -= 1
nus[l] = nus[r]
while l < r and nus[l] <= key:
l += 1
nus[r] = nus[l]
# 把基准值赋给左右指针共同指向的位置
nus[r] = key
# 对左侧数组排序
QSort(left, l-1)
# 对右侧数组排序
QSort(l+1, right)
QSort(0, len(nus) - 1)
print(nus)
'''
response, history = model.chat(tokenizer, ques, history=[])
print(response)
效果图

微调
运行训练截图,数据集huggingface 下载
 微调前的效果
微调前的效果

微调后的效果