1 前言
图数据结构,能够很自然地表征现实世界。比如用户、门店、骑手这些实体可以用图中的点来表示,用户到门店的消费行为、骑手给用户的送餐行为可以用图中的边来表示。使用图的方式对场景建模,便于描述复杂关系。在美团,也有比较多的图数据存储及多跳查询需求,概括起来主要包括以下 4 个方面:
- 图谱挖掘: 美团有美食图谱、商品图谱、旅游图谱、用户全景图谱在内的近 10 个领域知识图谱,数据量级大概在千亿级别。在迭代、挖掘数据的过程中,需要一种组件对这些图谱数据进行统一的管理。
- 安全风控: 业务部门有内容风控的需求,希望在商户、用户、评论中通过多跳查询来识别虚假评价;在支付时进行金融风控的验证,实时多跳查询风险点。
- 链路分析: 包括代码分析、服务治理、数据血缘管理,比如公司数据平台上有很多 ETL Job,Job 和 Job 之间存在强弱依赖关系,这些强弱依赖关系形成了一张图,在进行 ETL Job 的优化或者故障处理时,需要对这个图进行实时查询分析。
- 组织架构: 公司组织架构的管理,实线汇报链、虚线汇报链、虚拟组织的管理,以及商家连锁门店的管理。比如,维护一个商家在不同区域都有哪些门店,能够进行多层关系查找或者逆向关系搜索。
总体来说,美团需要一种组件来管理千亿级别的图数据,解决图数据存储以及多跳查询问题。海量图数据的高效存储和查询是图数据库研究的核心课题,如何在大规模分布式场景中进行工程落地是我们面临的痛点问题。传统的关系型数据库、NoSQL 数据库可以用来存储图数据,但是不能很好处理图上多跳查询这一高频的操作。
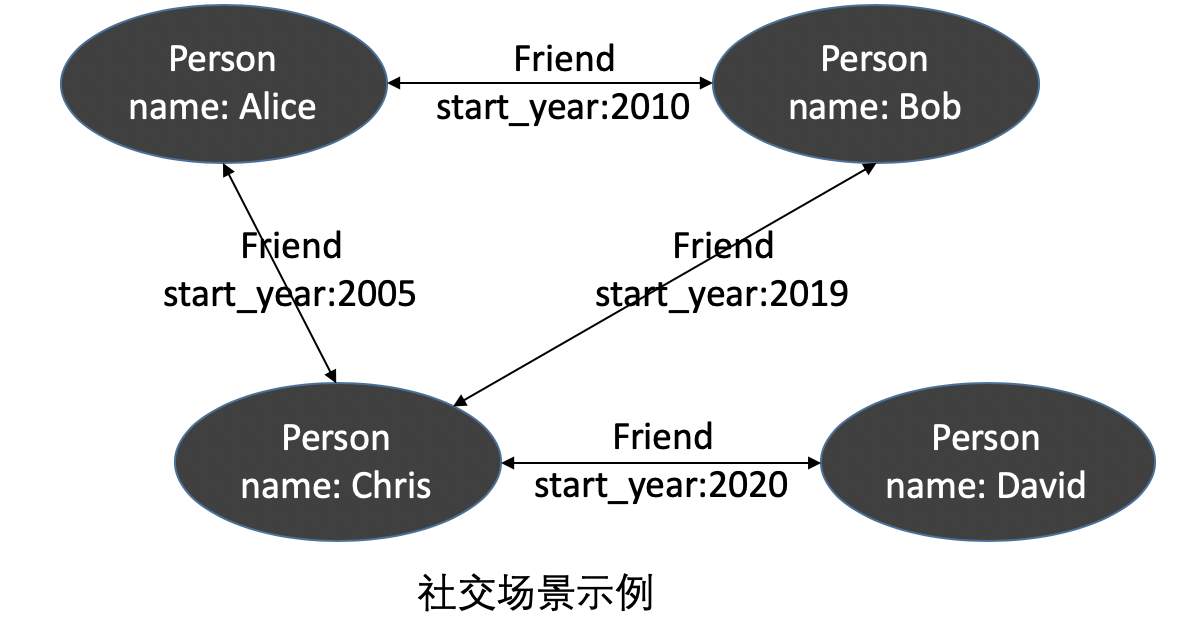
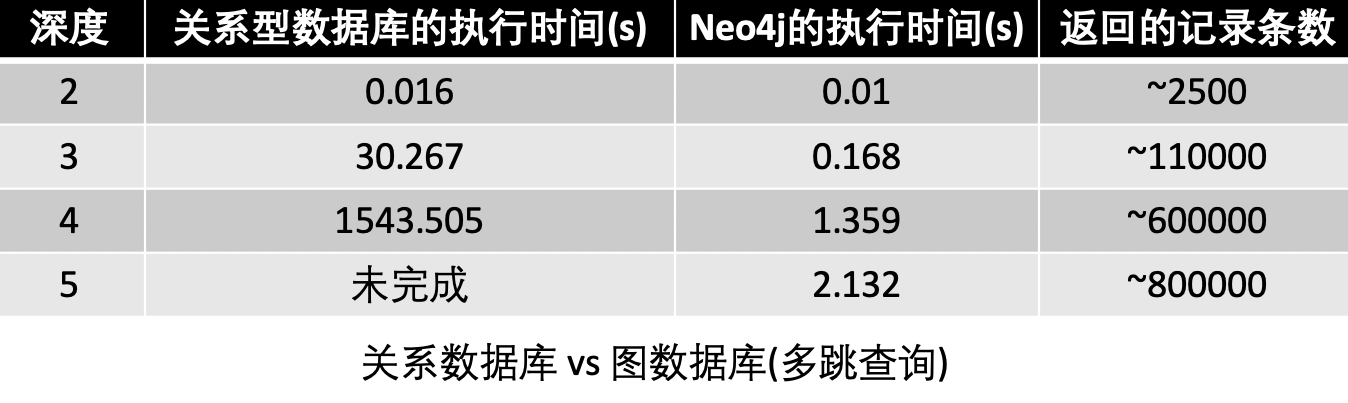
Neo4j 公司在社交场景(见图1)里做了传统关系型数据库 MySQL 跟图数据库 Neo4j 的查询性能对比 [1],在一个包含 100 万人、每人约有 50 个朋友的社交网络里找最大深度为 5 的朋友的朋友,实验结果表明多跳查询中图数据库优势明显(见图 2)。然而选取或者自主研发一款高吞吐、低查询延时、能存储海量数据且易用的图数据库非常困难。下面将介绍美团在图数据库选型及平台建设方面的一些工作
2 图数据库选型
在图数据库的选型上我们主要考虑了以下 5 点:(A) 项目开源,暂不考虑需付费的图数据库;(B) 分布式架构设计,具备良好的可扩展性;© 毫秒级的多跳查询延迟;(D) 支持千亿量级点边存储;(E) 具备批量从数仓导入数据的能力。
分析 DB-Engines[2] 上排名前 30 的图数据库,剔除不开源的项目,我们将剩余的图数据库分为三类:
- 第一类:Neo4j[3]、ArangoDB[4]、Virtuoso[5]、TigerGraph[6]、RedisGraph[7]。 此类图数据库只有单机版本开源可用,性能优秀,但不能应对分布式场景中数据的规模增长,即不满足选型要求(B)、(D)。
- 第二类:JanusGraph[8]、HugeGraph[9]。 此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求,即不满足选型要求(C)。
- 第三类:DGraph[10]、NebulaGraph[11]。 此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们的选型要求。
DGraph 是由前 Google 员工 Manish Rai Jain 离职创业后,在 2016 年推出的图数据库产品,底层数据模型是 RDF[12],基于 Go 语言编写,存储引擎基于 BadgerDB[13] 改造,使用 RAFT 保证数据读写的强一致性。
NebulaGraph 是由前 Facebook 员工叶小萌离职创业后,在 2019年 推出的图数据库产品,底层数据模型是属性图,基于 C++ 语言编写,存储引擎基于 RocksDB[14] 改造,使用 RAFT 保证数据读写的强一致性。
这两个项目的创始人都在互联网公司图数据库领域深耕多年,对图数据库的落地痛点有深刻认识,整体的架构设计也有较多相似之处。在图数据库最终的选型上,我们基于 LDBC-SNB 数据集[15]对 NebulaGraph、DGraph、HugeGraph 进行了深度性能测评,测试详情见文章:主流开源分布式图数据库 Benchmark,从测试结果看 NebulaGraph 在数据导入、实时写入及多跳查询方面性能均优于竞品。此外,NebulaGraph 社区活跃,问题响应速度快,所以团队最终选择基于 NebulaGraph 来搭建图数据库平台
来源: