一、引言
深度学习模型在计算机视觉、自然语言处理等领域取得了显著的成果。为了获得泛化性能良好的模型,研究者需要在模型复杂度和训练数据量之间找到合适的平衡。本文将探讨这两者之间的关系以及如何在实际应用中实现最佳效果。
二、模型复杂度与训练数据量的关系
模型复杂度和训练数据量是深度学习中两个关键概念,它们在训练过程中发挥着重要作用。以下是对这两个概念的简要介绍:
1.模型复杂度
模型复杂度是指模型表达能力的度量。简单来说,模型复杂度越高,意味着模型能够捕捉和学习更多的数据特征。在深度学习中,模型复杂度通常与模型参数量(即神经网络中的权重和偏置)相关。一个具有更多参数的模型通常具有更高的复杂度,从而能够表示更复杂的函数和特征。然而,过高的模型复杂度可能导致过拟合,因为模型可能过度拟合训练数据中的噪声。
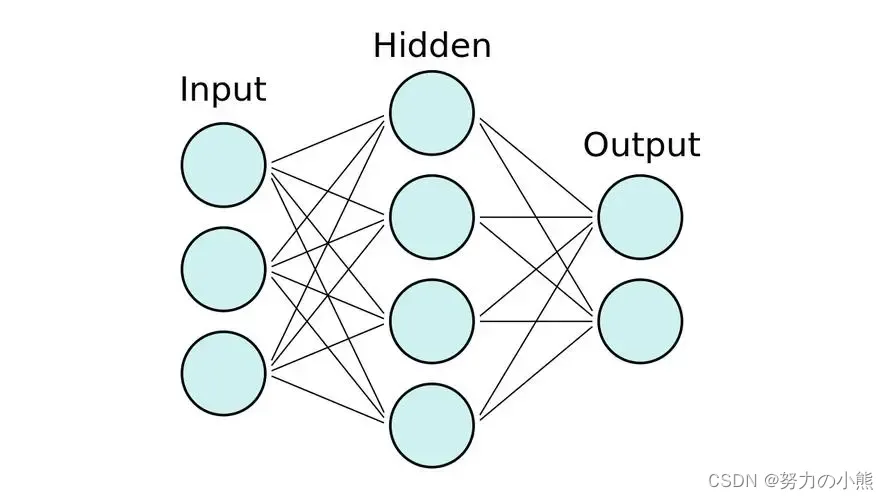
2.训练数据量
训练数据量是指用于训练模型的数据样本的数量。在深度学习中,通常需要大量的训练数据以便模型能够学习到足够的特征,从而提高泛化性能。数据量的多少对模型泛化性能有很大影响。数据量较大时,模型能够学到更多的特征,降低过拟合的风险。然而,收集和处理大量数据可能会带来计算和存储方面的挑战。

在深度学习中,模型复杂度和训练数据量之间需要保持适当的平衡。这主要是因为模型复杂度和训练数据量之间的关系对模型的泛化性能产生重要影响。当训练数据量较小时,选择一个较简单的模型可以避免过拟合;当训练数据量较大时,可以考虑使用更复杂的模型以捕捉更多的数据特征。要实现良好的泛化性能,研究者需要根据具体问题和数据集特点,在模型复杂度和训练数据量之间找到合适的平衡。
x = linspace(0, 2 * pi, 20);
y = sin(x) + 0.3 * randn(1, numel(x));
underfit_order = 1;
goodfit_order = 5;
overfit_order = 15;
underfit_p = polyfit(x, y, underfit_order);
goodfit_p = polyfit(x, y, goodfit_order);
overfit_p = polyfit(x, y, overfit_order);
x_fit = linspace(0, 2 * pi, 100);
underfit_y = polyval(underfit_p, x_fit);
goodfit_y = polyval(goodfit_p, x_fit);
overfit_y = polyval(overfit_p, x_fit);
figure;
subplot(1, 3, 1);
plot(x, y, 'bo', x_fit, underfit_y, 'r-');
title('欠拟合');
xlabel('x');
ylabel('y');
subplot(1, 3, 2);
plot(x, y, 'bo', x_fit, goodfit_y, 'r-');
title('良好拟合');
xlabel('x');
ylabel('y');
subplot(1, 3, 3);
plot(x, y, 'bo', x_fit, overfit_y, 'r-');
title('过拟合');
xlabel('x');
ylabel('y');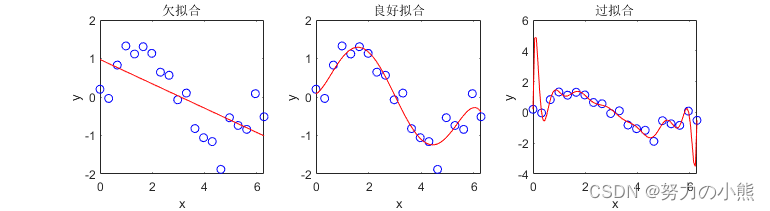
3.两者关系
模型复杂度和训练数据量之间没有固定的关系,但它们之间的平衡对于实现良好的泛化性能非常重要。以下是一些建议:
1)当数据量较小时,过大的模型参数量可能导致过拟合。为避免过拟合,可以使用更简单的模型或添加正则化项限制模型复杂度。
2)当数据量较大时,可以使用更复杂的模型。更多的数据可以提供更多的信息,有助于模型捕捉数据中的复杂特征。
3)选择合适的模型复杂度是关键。过于简单的模型可能导致欠拟合,过于复杂的模型可能导致过拟合。可以通过交叉验证、学习曲线等方法评估和调整模型复杂度。
三、据增强与正则化技术
1)数据增强:在数据量有限的情况下,可以通过数据增强方法(如加噪等)增加训练数据的多样性,从而提高模型的泛化性能。
2)正则化:通过正则化技术(如 L1、L2 正则化或 Dropout)可以限制模型的复杂度,降低过拟合的风险。
结论
要实现一个泛化性能良好的深度学习模型,研究者需要在模型复杂度、数据量和正则化之间找到合适的平衡。实现这一平衡通常需要反复尝试和调整超参数。为了找到最佳模型,研究者可以采用交叉验证、学习曲线等方法来评估模型在未知数据上的表现,并根据评估结果对模型进行优化。
此外,利用数据增强技术可以在有限的数据量下提高模型的泛化性能。正则化技术则有助于限制模型的复杂度,降低过拟合的风险。通过综合考虑这些因素并进行适当的调整,研究者可以训练出具有较好泛化性能的深度学习模型,为实际应用提供更强大的预测能力。
总之,深度学习模型的泛化性能取决于许多因素,其中模型复杂度与训练数据量的平衡至关重要。在实际应用中,研究者需要根据具体问题和数据集特点,灵活地调整模型参数、采用适当的技术,以实现最佳的泛化性能。