背景:
在为用户的新机房环境Oracle 19.18版本数据库检查时,发现smon进程后台日志不断出现事务恢复报错Serial Transaction recovery caught exception 30319,进一步检查发现存在事务恢复失败报ORA-00600[4137]
问题:
smon进程后台日志不断出现事务恢复报错Serial Transaction recovery caught exception 30319

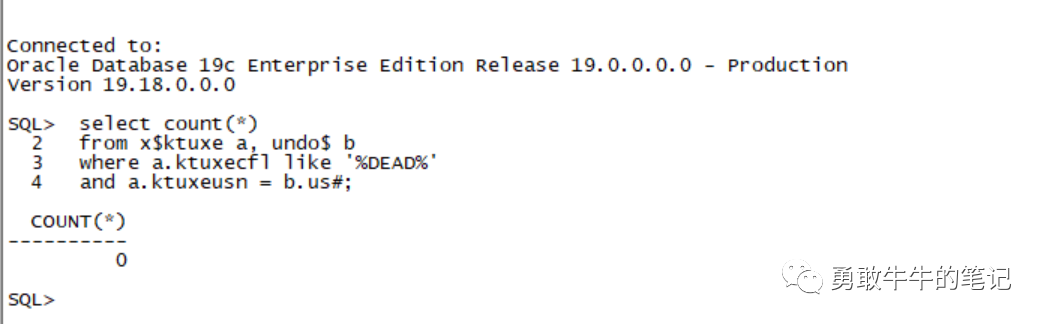
查看发现当前数据库存在死事务XID:2043,3,15714202
select b.name useg, b.inst# instid, b.status$ status, a.ktuxeusn
xid_usn, a.ktuxeslt xid_slot, a.ktuxesqn xid_seq, a.ktuxesiz undoblocks,
a.ktuxesta txstatus
from x$ktuxe a, undo$ b
where a.ktuxecfl like '%DEAD%'
and a.ktuxeusn = b.us#
USEG INSTID STATUS XID_USN XID_SLOT XID_SEQ UNDOBLOCKS TXSTATUS
------------------------------ ---------- ---------- ---------- ---------- ---------- ---------- ----------------
_SYSSMU2043_2627544207$ 2 3 2043 3 15714202 1 ACTIVE进一步检查发现是该事务xid:2043.3.15714202恢复出现报错ORA-00600-[4137]

问题分析:
分析报错的错误信息ORA-00600: internal error code, arguments: [4137], [2043.3.15714202],错误类型4137是指在进行事务回滚或者恢复时出现undo段头的XID与undo块里面的XID不一致的情况,参数2043.3.15714202是报错的事务XID号
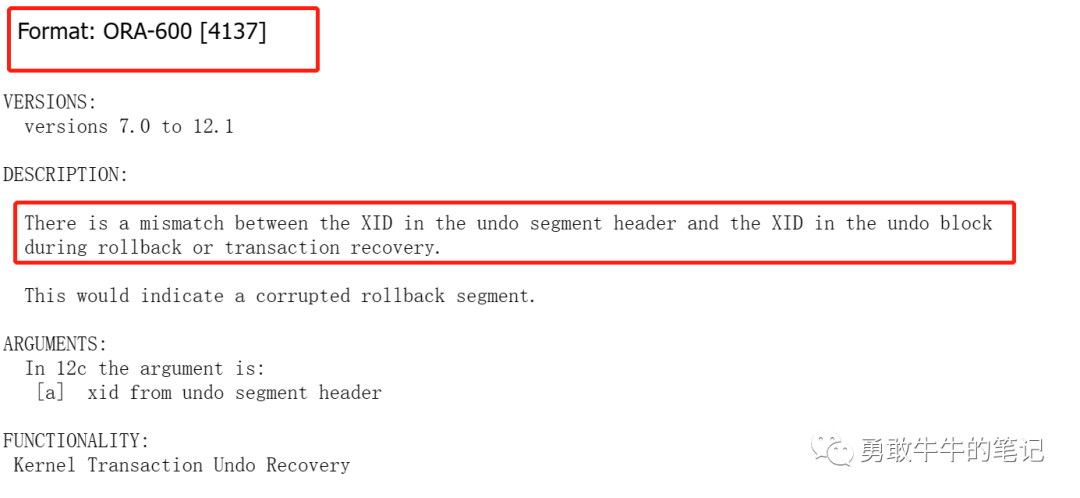
分析ORA-600的trc文件信息,可以看到从block(71/928)里面解析出来的xid为0x07fb.003.00efc79a(2403,3,15714202),XID的第一位为事务所在的undo段ID:2403
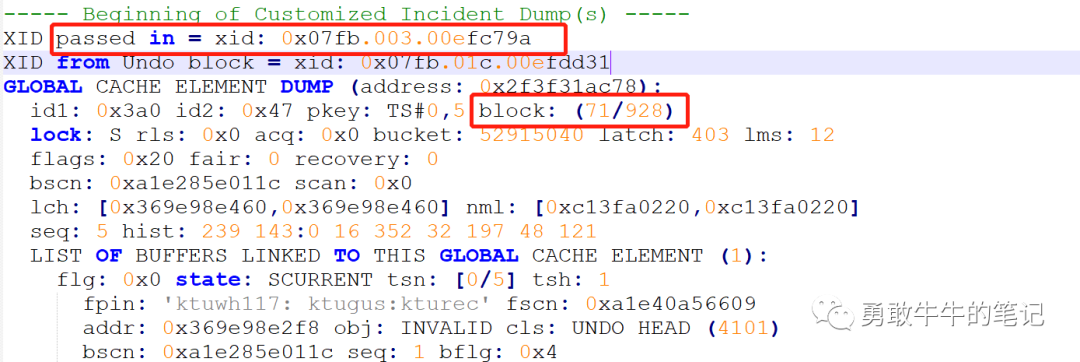
通过undo段ID:2403的段头,可以发现block(71/928)就是undo段头所在的块,即从undo段头里面解析出来的xid为0x07fb.003.00efc79a
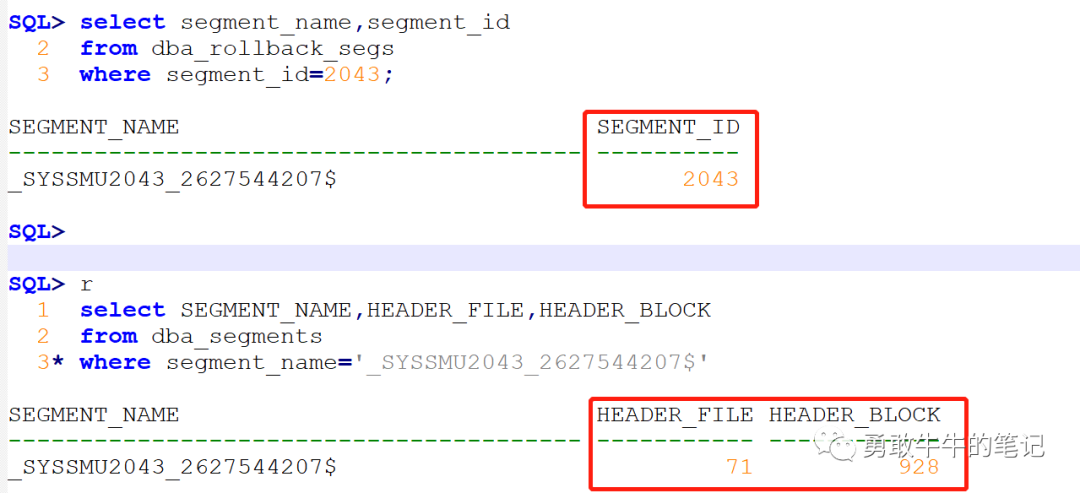
继续往下看trc文件里面udno段头的信息,可以看到xid:0x07fb.003.00efc79a指向的undo块地址为0x11c14fb1

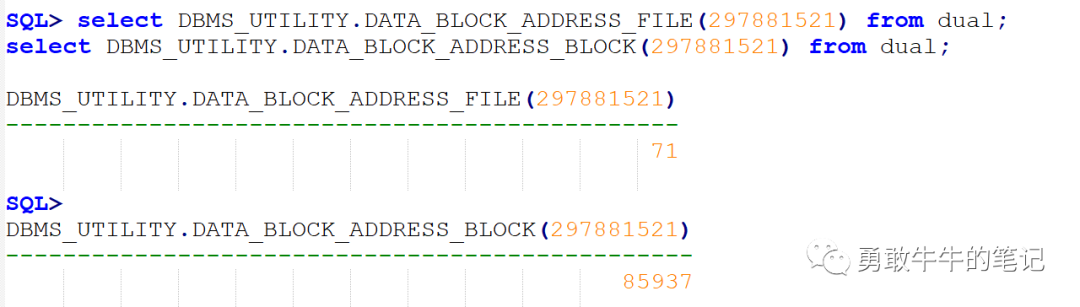
将undo块地址换成10进制11c14fb1-->297881521,查找对应的块文件号file为71,块BLOCK_ID为85937
在trc文件里面,可以看到ORA-00600也dump出了该undo块(71/85937)的信息,undo块里面包含的xid为0x07fb.01c.00efdd31,这里undo块的xid与undo段头xid:0x07fb.003.00efc79a出现了不一致的情况
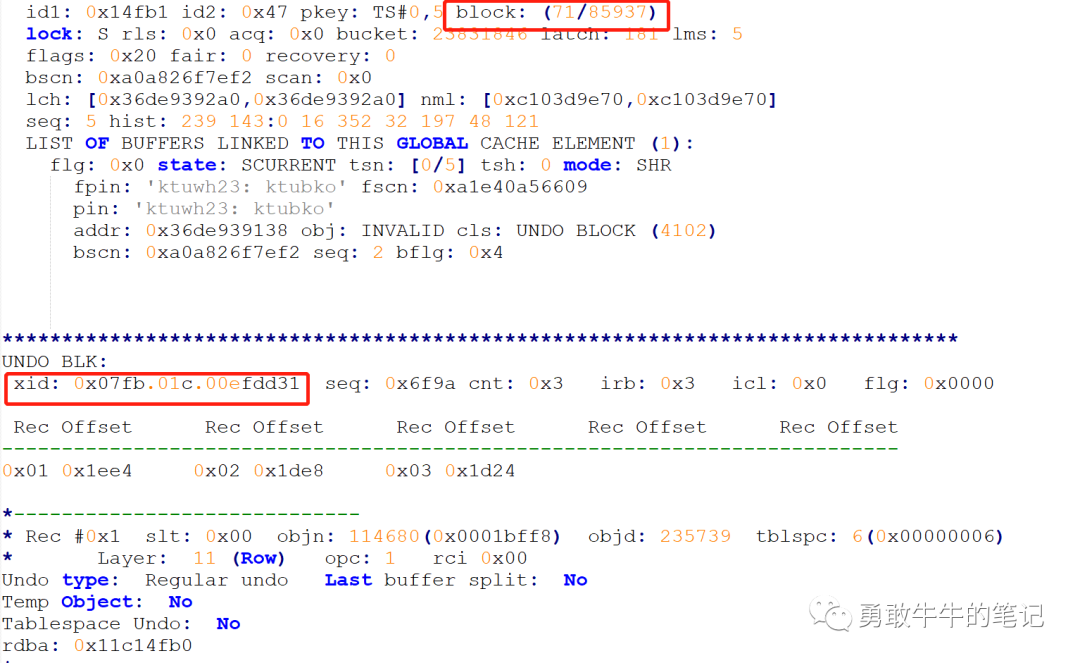
通过dump undo block方式,从trc里面也同样可以看到出现xid不一致的情况
oradebug setmypidAlter system dump undo block '_SYSSMU2043_2627544207$' xid 2043 3 15714202;oradebug tracefile_name
继续分析出现undo段头的XID与undo块里面的XID不一致的,通过查看SMON的trc文件,发现最早出现ORA-600[4137]的时间为2023-04-10T20:16:29

进一步检查alert日志发现在出现ORA-600报错之前2023-04-10T20:08:45,数据库进行了主备切换的操作,进一步了解到,当晚新环境的数据库通过failover方式激活了数据库以进行应用测试工作
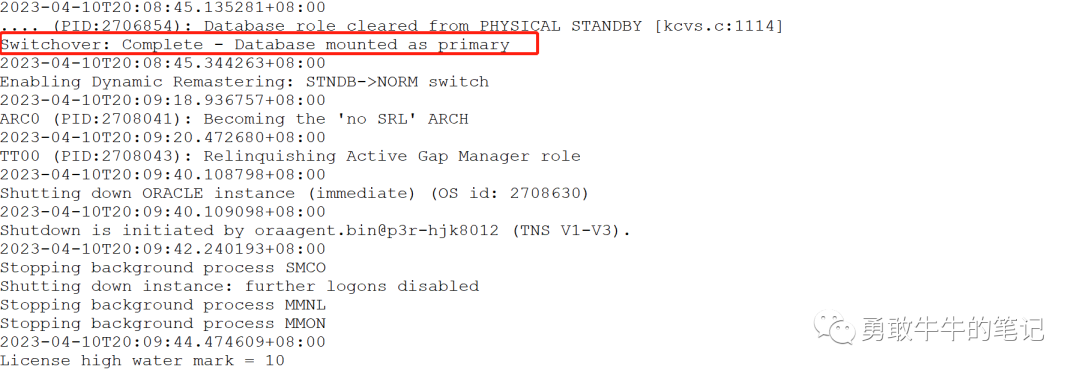
综上,我们可以确认出现事务恢复失败的原因是因为数据库进行了failover方式的主备切换,导致数据库出现了undo段头的XID与undo块里面的XID不一致的问题
问题解决:
对于undo段头的XID与undo块里面的XID不一致的问题,最好的恢复方式是通过备份重新进行恢复,但当前这个环境还是测试环境,可以选择通过重建undo表空间的方式进行恢复
创建一个临时的undo表空间undotbs2_temp,并将报错所在的数据库节点二的默认表空间切换为undotbs2_temp
create undo tablespace undotbs2_temp datafile size 10G;
alter system set undo_tablespace=undotbs2_temp sid='xxxx2';但由于undo段_SYSSMU2043_2627544207$存在的事务没办法正常恢复,所以一直处于online状态

尝试通过设置事件10513禁用事务恢复,重启数据库
SQL> alter system set event ='10513 trace name context forever, level 2' sid='xxxx2' scope=spfile;
System altered. 重启数据库之后,看见undo段_SYSSMU2043_2627544207$的状态变为PARTLY AVAILABLE,这种情况下,依然不能进行undo的重建

只能通过隐含参数_corrupted_rollback_segments忽略该回滚段
alter system set "_corrupted_rollback_segments"='_SYSSMU2043_2627544207$' scope=spfile;设置参数后再一次重启数据库,undo段_SYSSMU2043_2627544207$成功忽略,这次终于可以对undo表空间进行重建
--查询不到undo端_SYSSMU2043_2627544207$的信息
SQL> select segment_name,tablespace_name,status
2 from dba_rollback_segs
3 where tablespace_name='UNDOTBS2' and status='_SYSSMU2043_2627544207$';
no rows selected
--重建undo表空间
SQL> drop tablespace UNDOTBS2 including contents and datafiles;
SQL> create undo tablespace UNDOTBS2 datafile size 30g;
SQL> alter tablespace UNDOTBS2 add datafile size 30g;重建undo表空间之后,问题得以解决,smon进程的trc日志不再输出事务恢复失败的信息,死事务的信息也查询不到。