Python 查看数据常用函数(以 iris 数据集为例)
- 1、查看前后几行数据:head 和 tail
- 2、查看数据基本信息:info
- 3、查看数据统计信息:describe
查看数据可以用很多函数,这里就挑选几个最常用的进行简单展示,先导入数据
import pandas as pd
df = pd.read_csv('iris.csv')
1、查看前后几行数据:head 和 tail
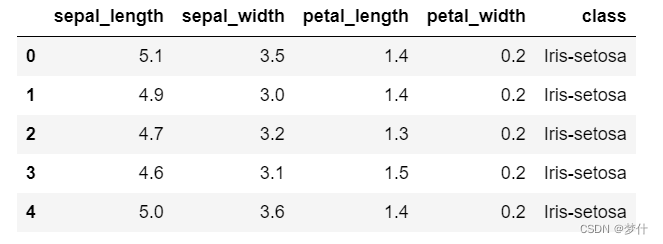
查看前五行数据
df.head()
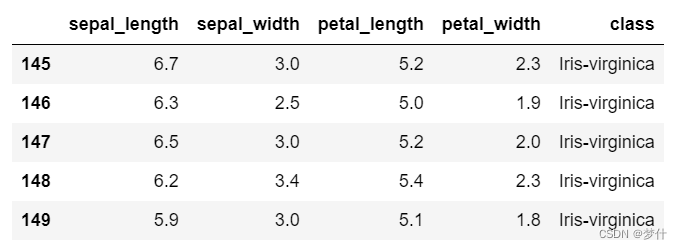
查看最后五行数据
df.tail()
2、查看数据基本信息:info
查看数据有几行几列,每列的数据类型,有没有缺失值
df.shape # 只能看几行几列
df.info()

计算每列的缺失值
df.isnull().sum()

3、查看数据统计信息:describe
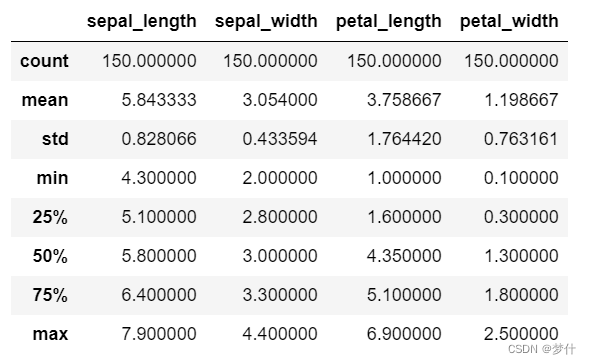
用 describe 函数进行查看,若直接对表数据用就会出现定量数据才有的描述性统计量。其中, c o u n t count count 是有效值的个数, m e a n mean mean 是平均值, s t d std std 是标准差, m i n min min 是最小值, m a x max max 是最大值。中间的 25%,50%,75%是对应的分位数,50%就是中位数。
df.describe()
对定性数据要单独用。其中,
c
o
u
n
t
count
count 是该列有效值个数,
u
n
i
q
u
e
unique
unique 是该列的类别数,
t
o
p
top
top 是该列类别数最多最先出现的类别,
f
r
e
q
freq
freq 是对应
t
o
p
top
top 类别的数量。
df['class'].describe()

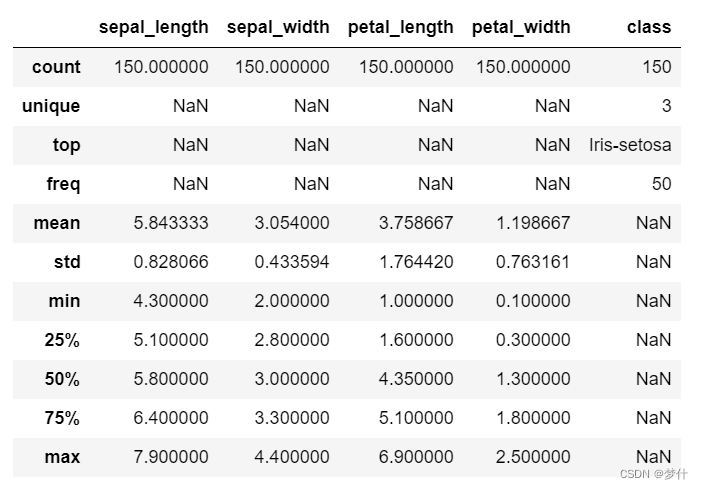
若不想区分定性和定量数据,则用如下代码
df.describe(include = 'all')
将数据转为浮点型
df[''] = df[''].astype(float)
将数据转为字符型
df[''] = df[''].astype(str)