OFA(One-For-All)
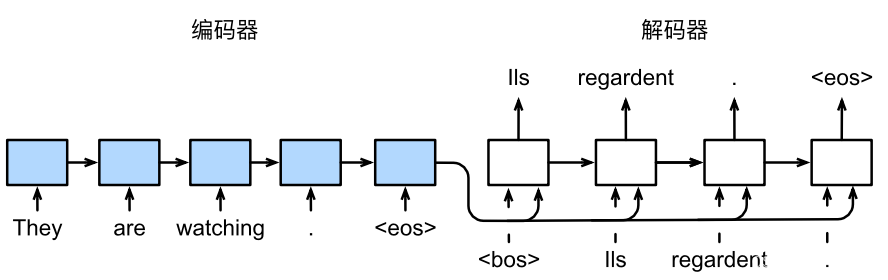
通用多模态预训练模型,使用简单的序列到序列的学习框架统一模态(跨模态、视觉、语言等模态)和任务(如图片生成、视觉定位、图片描述、图片分类、文本生成等)
-
架构统一:使用统一的transformer encoder decoder进行预训练和微调,不再需要针对不同任务设计特定的模型层,用户不再为模型设计和代码实现而烦恼。
-
模态统一:将NLP、CV和多模态任务统一到同一个框架和训练范式,即使你不是CV领域专家,也能轻松接入图像数据,玩转视觉、语言以及多模态AI模型。
-
任务统一:将任务统一表达成Seq2Seq的形式,预训练和微调均使用生成范式进行训练,模型可以同时学习多任务,让一个模型通过一次预训练即可获得多种能力,包括文本生成、图像生成、跨模态理解等。
本文聚焦于OFA的使用并且尽可能做了详细的注释
只需要输入任意1张你的图片,3秒内就能收获一段精准的描述
一 Image Captioning(图像字幕)
以下将展示如何使用OFA对图像字幕生成进行推理
你需要构建环境并且clone相关的code与checkpoints后,提供带有一些简单图像预处理的图像,构建模型和生成器并且获得结果
Environment
!git clone --single-branch --branch feature/add_transformers https://github.com/OFA-Sys/OFA.git
!pip install OFA/transformers/
!git lfs install
# !git clone https://huggingface.co/OFA-Sys/OFA-tiny
!git clone https://huggingface.co/OFA-Sys/OFA-tiny
Library
from PIL import Image
from torchvision import transforms
from transformers import OFATokenizer, OFAModel
from transformers.models.ofa.generate import sequence_generator
cfg
mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]
resolution = 256
#图像预处理
patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
#BICUBIC 插值是一种高质量的图像缩放算法
transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
tokenizer
ckpt_dir='./OFA-huge'
tokenizer = OFATokenizer.from_pretrained(ckpt_dir)
# 定义输入的文本
txt = " what does the image describe?"
# 使用 tokenizer 对输入文本进行编码,返回 PyTorch tensor 格式的输入 ID
inputs = tokenizer([txt], return_tensors="pt").input_ids
# 使用 !wget 命令从指定 URL 下载图像,保存为 test.jpg
!wget http://farm4.staticflickr.com/3539/3836680545_2ccb331621_z.jpg
!mv 3836680545_2ccb331621_z.jpg test.jpg
img = Image.open('./shigong-neg.png')
# 使用 patch_resize_transform 对图像进行裁剪和缩放,然后转换为 PyTorch tensor 格式,并在第 0 维增加一个维度,用于模型输入
patch_img = patch_resize_transform(img).unsqueeze(0)
加载预训练模型
#use_cache=False表示不使用缓存
model = OFAModel.from_pretrained(ckpt_dir, use_cache=False)
Choice of Generators
# 使用sequence_generator.SequenceGenerator类来生成文本序列
generator = sequence_generator.SequenceGenerator(
tokenizer=tokenizer, # 分词器
beam_size=5, # beam search算法中的beam size,控制生成的文本数量
max_len_b=16, # beam search算法中的最大生成长度,控制生成的文本长度
min_len=0, # beam search算法中的最小生成长度,控制生成的文本长度
no_repeat_ngram_size=3, # 控制生成的文本中重复n-gram(连续n个词)的数量,避免生成过于重复的文本
)
import torch
data = {}
data["net_input"] = {
"input_ids": inputs, # 表示模型的文本输入序列,
"patch_images": patch_img, # 表示模型的图像输入
"patch_masks": torch.tensor([True]) # 表示模型的图像掩码,其值为一个张量,其中只包含一个布尔值 `True`
}
# 使用 `generator` 对象的 `generate` 方法生成文本序列
gen_output = generator.generate([model], data)
# 提取生成的文本序列
gen = [gen_output[i][0]["tokens"] for i in range(len(gen_output))]
display(img)
# 打印生成的文本序列
print(tokenizer.batch_decode(gen, skip_special_tokens=True)[0].strip())

a truck travels on a road in wuhan, hubei province
gen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3)
display(img)
print(tokenizer.batch_decode(gen, skip_special_tokens=True)[0].strip())

a herd of highland cattle graze in a field in scotland.