忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录
系列文章目录
一、实验综述
1.实验工具及内容
2.实验数据
3.实验目标
4.实验步骤
二、循环神经网络综述
1.循环神经网络简介
1.1 循环神经网络背景
1.2 循环神经网络概念与原理
1.3 循环神经网络发展历程
2.循环神经网络相关知识导入
2.1 序列模型
2.2 文本预处理
2.3 语言模型
2.4 数据集
三、经典循环神经网络原理、实现与优化
1.RNN
1.1 原理
1.2 代码实现(自购建)
1.3 代码实现(API)
1.4 消融实验
1.4.2 num_steps
1.4.3 batch_size
1.4.4 lr
1.4.5 epoch
1.4.6 综述
2.LSTM
2.1 原理
2.2 代码实现
2.3 消融实验
3.GRU
3.1 原理
3.2 代码实现
3.3 消融实验
4.对比分析
四、高级循环神经网络架构介绍与选择实现
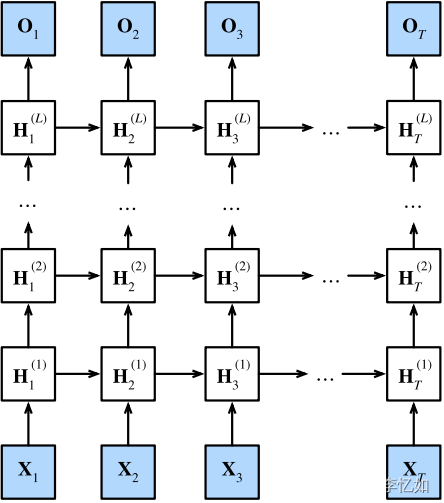
1.深度循环神经网络
1.1 原理
1.2 代码实现
1.3 消融实验
2.双向循环神经网络
3.稠密连接网络
4.机器翻译与数据集
5.编码器-解码器架构
6.序列到序列学习
五、总结
1.实验结论
2. 参考资料
系列文章目录
本系列博客重点在深度学习相关实践(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 深度学习实战——不同方式的模型部署(CNN、Yolo)_如何部署cnn_@李忆如的博客
第二章 深度学习实战——卷积神经网络/CNN实践(LeNet、Resnet)_@李忆如的博客-CSDN博客
第三章 深度学习实战——循环神经网络(RNN、LSTM、GRU)
梗概
本篇博客主要介绍几种循环神经网络的原理,并进行了代码实践与优化(内含代码与数据集)。
一、实验综述
本章主要对实验思路、环境、步骤进行综述,梳理整个实验报告架构与思路,方便定位。
1.实验工具及内容
本次实验主要使用Pycharm完成几种循环神经网络的代码Pytorch架构实现与优化,并通过不同参数的消融实验采集数据分析后进行性能对比。另外,通过论文与资料研读了高级循环神经网络,并尝试完成其训练/推理的实现与对比,并给出了一定优化思路。
2.实验数据
本次实验大部分数据来自循环神经网络模型官方数据集,部分测试数据来源于网络。
3.实验目标
本次实验目标主要是深度剖析循环神经网络的原理与模型定义,并了解不同参数的意义与对模型的贡献度(性能影响),通过实践完成不同模型、参数情况的性能对比,指导真实项目开发中应用。
4.实验步骤
本次实验大致流程如表1所示:
表1 实验流程
| 1.实验思路综述 |
| 2.循环神经网络综述 |
| 3.经典循环神经网络原理、实现与优化 |
| 4.高级循环神经网络架构介绍与选择实现 |
二、循环神经网络综述
本实验无论是实践RNN还是其他高级/现代架构,都属于循环神经网络,故本章先对循环神经网络的概念与原理做一定综述,并简述其发展历程。
1.循环神经网络简介
1.1 循环神经网络背景
通过实验1和实验2,我们主要处理的都是两种类型的数据:表格数据或图像数据。对于图像数据,我们设计了专门的卷积神经网络架构来为这类特殊的数据结构建模,即可以有效利用图像的像素位置/标签等信息,在之前的实验中对CNN的原理、实现、训练评估、部署全流程都有涉及,在此不赘述。
但到目前为止我们默认数据都来自于某种分布,并且所有样本都是独立同分布的,即没有太关注数据的顺序/上下文。然而,大多数的数据并非如此。例如,文章中的单词是按顺序写的,如果顺序被随机地重排,就很难理解文章原始的意思。同样,视频中的图像帧、对话中的音频信号以及网站上的浏览行为都是有顺序的。
我们以一个NLP的命名实体识别例子论证上面所说,见表2,网络对比如图1:
表2 命名实体识别样例
| 第一句话:I like eating apple!(我喜欢吃苹果!) 第二句话:The apple is a great company!(苹果真是一家很棒的公司!) |
分析:任务是要给apple打Label,我们都知道两个apple分别是水果、公司,假设现在有大量的已经标记好的数据以供训练模型,当我们使用全连接神经网络/卷积神经网络,做法是把apple这个单词的特征向量输入到我们的模型中,在输出结果时,让我们的label里,正确的label概率最大,但我们的语料库中,有的apple的label是水果,有的是公司,这将导致预测的准确程度,取决于训练集中哪个label多一些,这样的模型是没有意义的。问题就出在了我们没有结合上下文去训练模型,而是单独的在训练apple这个单词的label。
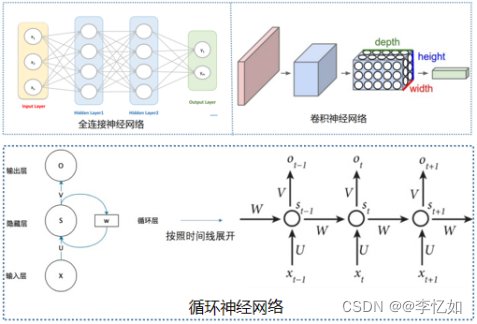
图1 网络架构对比(FCN vs CNN vs RNN)
另一个问题来自这样一个事实:我们不仅可以接收一个序列作为输入,而是还可能期望继续猜测这个序列的后续。这在时间序列分析中是相当常见的,可以用来预测股市的波动、 患者的体温曲线或者赛车所需的加速度。同理,我们需要能够处理这些数据的特定模型。
1.2 循环神经网络概念与原理
Tips:循环神经网络类似CNN,是一类网络,具体原理在后面两章详解。
根据1.1及过往实验分析,CNN可以有效地处理空间信息,但对于数据间的关联性与数据预测的表现仍有局限,而本实验中主要解析的循环神经网络(recurrent neural network,RNN为经典代表)应运而生,可以更好地处理序列信息及语义信息。
循环神经网络的核心原理通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。即拥有记忆的能力,并且会根据这些记忆的内容来进行推断,这也是它能利用上下文去处理序列信息的重要原因。
1.3 循环神经网络发展历程
1982年,美国加州理工学院物理学家John hopfield 发明了一种单层反馈神经网络 Hopfield network,用来解决组合优化问题。这是最早的RNN的雏形。1986年随着recurrent,提出 Jordan network,1990年对Jordan network简化,并采用BP算法进行训练,便有了如今最简单的包含单个自连接节点的RNN模型。
在此之后,为解决梯度爆炸和梯度消失的问题,LSTM出现了,针对其他问题,还有GRU、双向循环神经网络、seq2seq等现代循环神经网络架构出现,具体发展见图2与图3:
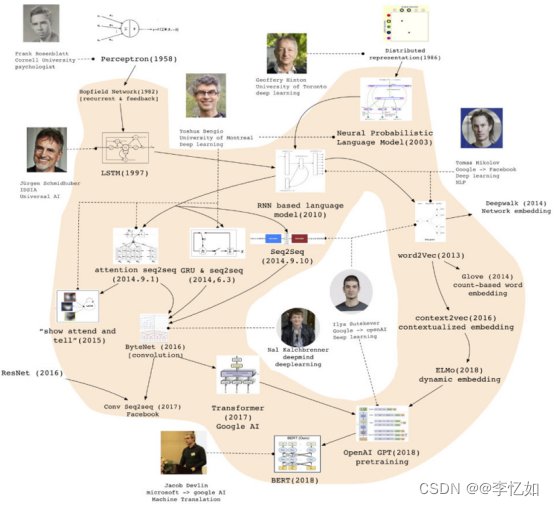
图2 循环神经网络发展历程 - 图形式
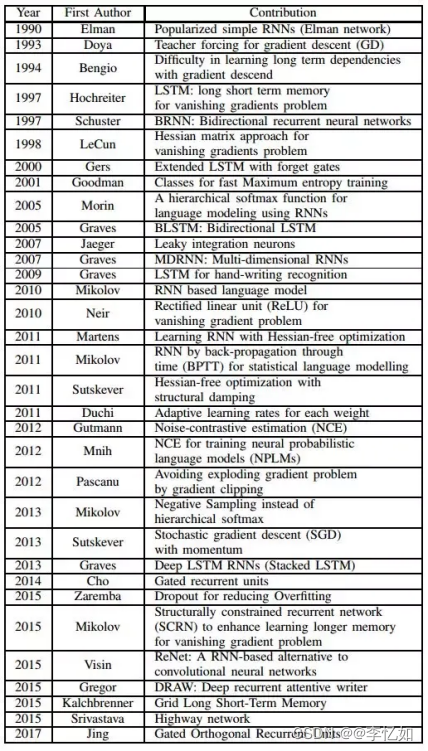
图3 循环神经网络发展历程 - 表形式
2.循环神经网络相关知识导入
在正式进入循环神经网络的架构与实现前,我们还要对相关知识进行一些引入。
许多使用循环网络的例子都是基于文本数据的,因此我们将在本实验中重点介绍语言模型。在对序列数据进行更详细的回顾之后,我们将介绍文本预处理的实用技术。然后,我们将讨论语言模型的基本概念,并将此讨论作为循环神经网络设计的灵感。最后,我们描述了循环神经网络的梯度计算方法,以探讨训练此类网络时可能遇到的问题。
2.1 序列模型
根据1.1与1.2我们知道循环神经网络是为了更好处理序列数据而存在的,对序列数据/模型的定义我们在本部分做一下补充。
序列数据我们在上文简介中有提到,本质上是有一定上下文/随时间变化的数据,比如用户评价、股票价格。以用户评价为例,比如电影评价与时间可能会出现锚定(anchoring)效应、享乐适应、季节性等现象,一些其他场景总结如表3:
表3 不同场景的序列数据样例
|
所以和RNN的背景保持一致,如何使用序列数据/数据相关性去构建模型(如使用时间动力学)即“序列模型”的核心问题。而构建一个序列模型,核心是统计工具+模型选择。以股票预测为例,统计案例如图4所示:
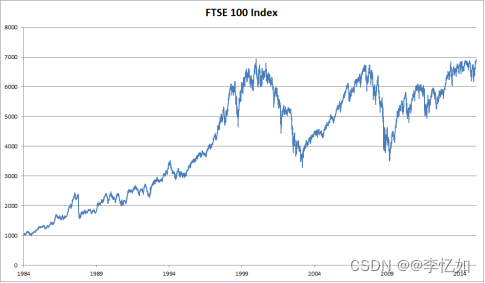
图4 序列数据统计样例(富时100指数价格)
而我们输入模型需要转换为数理的表达,即用xt表示价格。 请注意,t对于本文中的序列通常是离散的,并在整数或其子集上变化。假设一个交易员想在t日的股市中表现良好,于是通过以下式1途径预测:
式1 股票预测样例式
而为了实现这个预测,我们常需要引入模型或策略,常见的有隐变量自回归模型、马尔可夫模型、因果关系等,如图5所示:
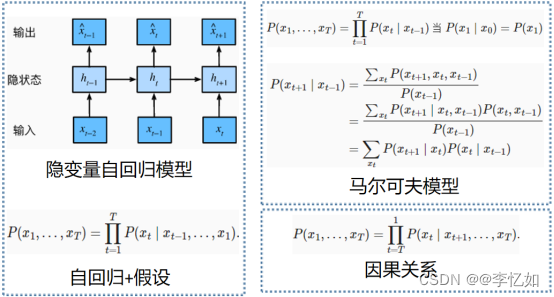
图5 序列模型常见选择与核心定义
Tips:对于直到时间步t的观测序列,其在时间步t+k的预测输出是“k步预测”。随着我们对预测时间t值的增加,会造成误差的快速累积和预测质量的极速下降。
2.2 文本预处理
对于序列数据处理问题,我们在2.1节中评估了所需的统计工具和预测时面临的挑战。 这样的数据存在许多种形式,文本是最常见例子之一。 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。本部分,我们将解析文本的常见预处理步骤如表4:
表4 文本预处理步骤
| 1、读取数据集: 将文本作为字符串加载到内存中。 |
| 2、词元化: 将字符串拆分为词元(如单词和字符,例:['the', 'time', 'machine', 'by', 'h', 'g', 'wells'])。 |
| 3、构建词表: 为方便模型使用,建立词表(string->num,例:[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8)]),将拆分的词元映射到数字索引(分list)。 |
| 4、功能整合: 将文本转换为数字索引序列,且打包所有函数,通过load_corpus_time_machine返回corpus(词元索引列表)和vocab(语料库的词表),例:(170580, 28)。 |
2.3 语言模型
2.2中我们了解了如何将文本数据映射为词元,本质上它们还是序列数据,所以可以使用2.1的方法对其进行预测,仅仅只能得到一个“合理”的预测。仍未让模型真正“理解”文本。但这仍是有意义的(如语义歧义判别),故我们需要在本节对语言模型和数据集的核心概念做一定补充,也便于后续平滑地过渡到循环神经网络的原理。
首先语言模型的核心问题与序列数据/模型保持一致,即“如何对一个文档, 甚至是一个词元序列进行建模?”,基本概率模型与“自回归+假设”保持一致,如图5所示。为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。常见的一些方法如图6:

图6 单词概率/条件概率常见计算方法
但这样的模型很容易无效,主要因为我们需要存储所有计数,且没有考虑单词的意思。
补充:序列建模的近似公式由马尔可夫模型与n元语法推导,如式2:
式2 马尔可夫模型与n元语法->序列建模的近似公式
Tips:通常,涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram)和三元语法(trigram)模型。这可以指导我们如何设计更好的模型。
接下来我们通过真实数据上的自然语言统计来说一说其他核心知识。经一元、二元、三元语法的词元频率统计(样例如图7),我们可以发现词频以一种明确的方式迅速衰减。将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。这意味着单词的频率满足齐普夫定律,即第i个最常用单词的频率ni如式3:
Tips:其中是a刻画分布的指数,c是常数。
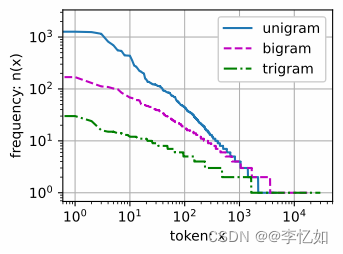
图7 词元频率统计样例
同时根据图7,我们可以归纳出几个特点(循环神经网络的核心背景):
- 除了一元语法词,单词序列似乎也遵循齐普夫定律,尽管式3中的指数a更小(指数的大小受序列长度的影响)。
- 词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构,这些结构给了我们应用模型的希望。
- 很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。作为代替,我们将使用基于深度学习的模型。
最后还有一个问题,如何读取长序列数据?
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题,一个样例问题(如何分割文本)如图8,常见的解决方案是随机采样(每个样本都是在原始的长序列上任意捕获的子序列)与顺序分区(在基于小批量的迭代过程中保留了拆分的子序列的顺序)。

图8 长序列数据读取/处理问题
那如何去度量语言模型的质量呢,这是后续部分中用于评估基于循环神经网络模型的关键,答案是困惑度(Perplexity)。
一个好的语言模型能够用高度准确的词元来预测我们接下来会看到什么,比如我们要用语言模型对“It is raining …”续写,几个样例如表5:
表5 语言模型预测样例
| “It is raining outside”(外面下雨了) “It is raining banana tree”(香蕉树下雨了) “It is raining piouw;kcj pwepoiut”(piouw;kcj pwepoiut下雨了) |
显然,第一个回答是最合理的,如果量化地去度量这种合理性判别指标呢,核心是计算序列的似然概率+softmax回归,即我们可以通过一个序列中所有的n个词元的交叉熵损失的平均值来衡量,困惑度即其的指数,如式4所示,故困惑度的本质即“下一个词元的实际选择数的调和平均数”。
至此,循环神经网络的核心前置知识引入完成。
2.4 数据集
在本部分我们对后文实验用到的主要数据集做一下介绍,本实验以文字数据集为样例探究不同循环神经网络的效果,主要使用的是H.G.Wells的时光机器数据集,本质上是一本书,详情可见:时间机器 The Time Machine (豆瓣) (douban.com),导入方式见Code1:
| Code1 数据集导入(时光机器 - 文字) |
| from d2l import torch as d2l train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) |
三、经典循环神经网络原理、实现与优化
上一章中我们对循环神经网络的背景、概念、发展历程做了梳理,并将序列模型、文本预处理、语言模型与数据集等核心前置知识做了补充,本章即将进入经典循环神经网络的原理详解、代码实现、参数与网络优化,本章主要以RNN(经典)、LSTM、GRU为例。
1.RNN
1.1 原理
参考论文:Finding Structure in Time - 1990 (wiley.com)
参考资料:The Unreasonable Effectiveness of Recurrent Neural Networks
第一章铺垫了那么多,让我们正式进入最经典的循环神经网络。RNN最重要、最核心的创新是循环,正是因为循环才可以利用数据的相关性/上下文,从而在序列数据中表现优秀。我们来看这么一个展开/迭代例子(标准结构)如图9:
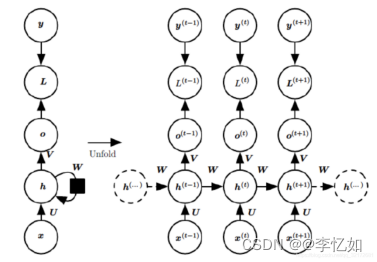
图9 RNN标准结构-循环本质/迭代推导
分析:CNN中我们知道神经网络是分层顺序激活的,而RNN通过循环将训练“学”到的东西蕴藏在权值W中。
补充:左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。图中O代表输出,y代表样本给出的确定值,L代表损失函数。
泛化一点讲,RNN的核心结构如图10所示:
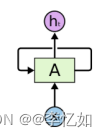
图10 RNN核心结构
Tips:神经网络A(包含若干层)输入向量为xt,输出向量为ht,它允许网络将这一步的输出传递到下一步作为输入,堆叠/展开后与图9保持一致。
把神经网络看作函数f,其中的权重为w,那RNN 本质上是循环/递推函数,如式5:
式5 RNN本质函数
根据RNN简介与核心定义,总结其特点如下:
- (1)权值共享,图中的W全是相同的,U和V也一样
- (2)前面的输出会影响后面的输出,适合处理序列数据
- (3)损失也是随着序列的推荐而不断积累的
而根据RNN的不同堆叠形式/数据的不同输入输出,产生了多种变体(非优化),如图11所示:
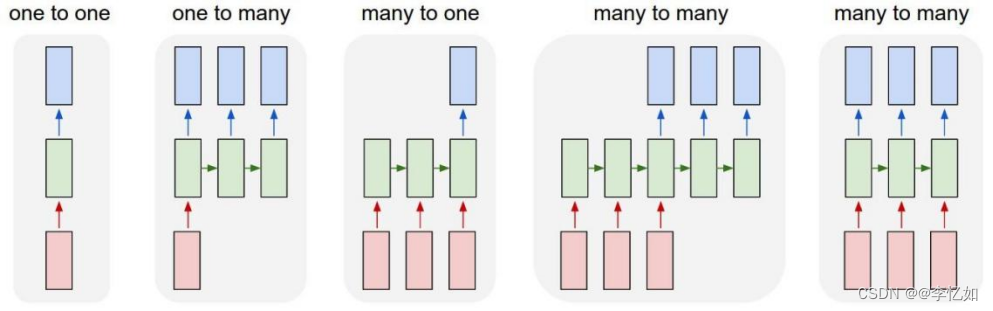
图11 常见RNN变体汇总
Tips:上图中每个正方形代表一个向量,箭头代表函数。输入向量是红色,输出向量是蓝色,绿色向量装的是RNN的状态,总结如表6:
表6 不同变体中RNN状态(对应图11左至右)
| 1、one to one: 非RNN的普通过程,从固定尺寸的输入到固定尺寸的输出(比如图像分类),也即输入是x,经过变换Wx+b和激活函数f得到输出y。 |
| 2、one to many: 输出是序列(例如图像标注:输入是一张图像,输出是单词的序列),同时还有一种结构是把输入信息X作为每个阶段的输入。 |
| 3、many to one: 输入是序列(例如情绪分析:输入是一个句子,输出是对句子属于正面还是负面情绪的分类)。 |
| 4、many to many(n to n): 输入输出都是序列(比如机器翻译:RNN输入一个英文句子输出一个法文句子)。或同步的输入输出序列(比如视频分类中,我们将对视频的每一帧都打标签)。 |
Tips:当然除了图11,还有Encoder-Decoder(n to m,Seq2Seq)等重要RNN变体这里没有全部体现。
而以上主要是从概念、结构部分的原理解析,接下来让我们进入数理推导部分。对于神经网络最重要的是前向传播/反向传播的部分(如何更新参数),RNN也是如此。
同样先展开一个典型的RNN,如图12所示:
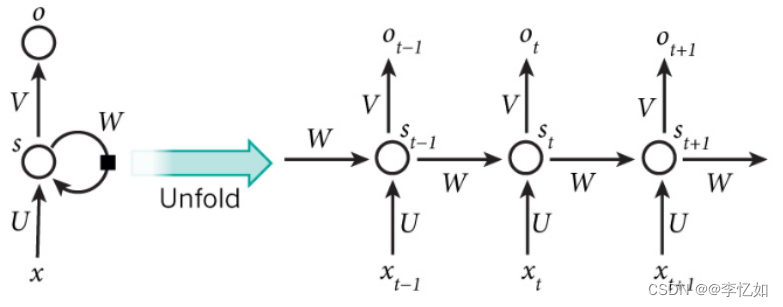
图12 典型RNN展开
图12中,有一条单向流动的信息流是从输入单元到达隐藏单元的,同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。(这实际上就是LSTM,后文详解)
右侧为计算时便于理解记忆而产开的结构。简单说,x为输入层,o为输出层,s为隐含层,而t指第几次的计算;V,W,U为权重,其中计算第t次的隐含层状态时如式6:
式6 隐含层状态计算
即通过此实现当前输入结果与之前的计算挂钩的目的,更直观的表达可见图13:
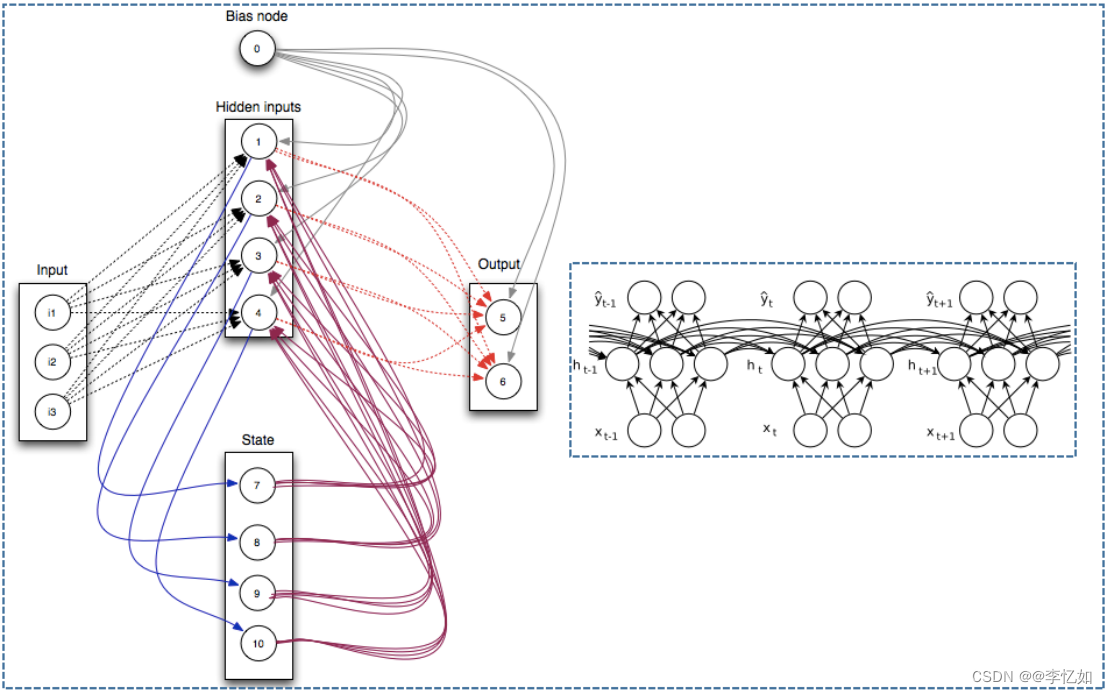
图13 RNN“记忆”核心
根据上述描述与图13,我们可以推理RNN前向传播条件如式7,loss常用重构误差或交叉熵,如式8和式9:
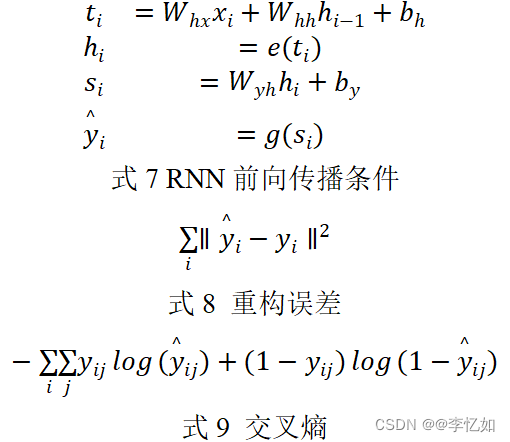
同理根据RNN展开去推理反向传播,常出现梯度消失问题,同样因激活函数产生,在此不展开,详见:循环神经网络RNN论文解读_循环神经网络论文_纸上得来终觉浅~的博客-CSDN博客。
最后我们从是否有隐状态与基于RNN的字符级语言模型作为RNN原理部分的结尾,核心知识总结如图14所示:
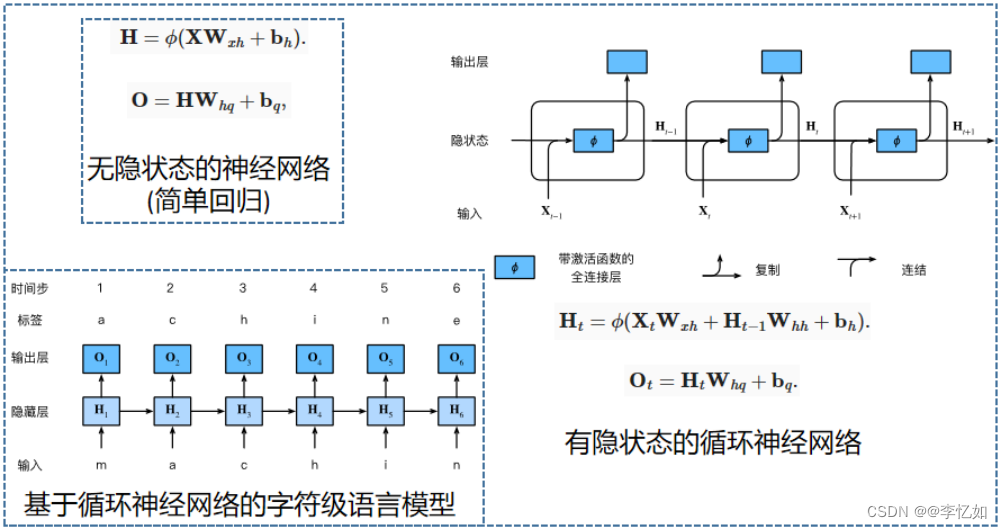
图14 RNN网络架构总结及字符级语言模型样例
1.2 代码实现(自购建)
Tips:RNN及其变体是非常经典且有意义的工作,故代码实现有多种方式,总体来说分为自购建与API调用,本实验RNN分别采用自购建和API调用作为双实现样例,其他架构基本均使用API单实现,参考代码来自李沐老师,详见:8.5. 循环神经网络的从零开始实现 — 动手学深度学习 2.0.0 documentation (d2l.ai)。
根据1.1中对RNN原理/架构的解析,以及基于RNN的字符级语言模型的定义,我们在本部分实现从0到1的RNN实现,代码文件为RNN(0to1).py,在此仅作核心代码的解析。其中,RNN的自购建步骤总结如表7,输入输出编码如图15所示:
表7 RNN自购建流程
| 输入:数据集(本实验基本均为H.G.Wells的时光机器数据集 - 文字) |
| 1、独热编码: 即NLP中的基本操作one-hot encoding,将文本预处理(string->num),并将索引映射为互补相同的单位向量,方便后续模型读入。 |
| 2、初始化模型参数: 需要定义隐藏层参数(重要)、输出层参数、附加梯度等模型参数。 |
| 3、模型/网络定义: 根据需求与RNN定义去搭建模型,包括隐状态返回(初始化时)、计算与输出,以及模型的激活与迭代。 |
| 4、预测: 定义预测函数来生成prefix(一个用户提供的包含多个字符的字符串)之后的新字符。 |
| 5、梯度裁剪: 根据1.1中的论述,正常的RNN反向传播会产生O(T)的矩阵乘法链,T较大时可能导致梯度爆炸或消失,故需要进行梯度裁剪。 |
| 6、训练: 将处理后数据“喂”给模型,进行迭代训练(顺序分区/随机抽样),以困惑度或epoch作为停止训练指标。 |
| 输出:训练好的模型/文本预测结果 |

图15 RNN输入/输出编码形式
本部分主要解析RNN模型代码与梯度裁剪代码,网络模型及解析如Code2:
# 初始化时返回隐状态(张量,形状为(批量大小,隐藏单元数))
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
# 定义如何在一个时间步内计算隐状态和输出(函数作为激活函数)
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
# 定义类去包装函数(并存储从零开始实现的循环神经网络模型的参数)
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
# 模型样例定义类去包装函数(检查输出是否具有正确的形状)
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params, init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shapeTips:我们可以看到输出形状是(时间步数x批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
而关于梯度裁剪,从数理逻辑来说它的常见方案如式10(通过将梯度g投影回给定半径 (例如θ)的球来裁剪梯度g),一个代码样例如Code3:
式10 梯度裁剪常见方案
分析:通过这样做,我们知道梯度范数永远不会超过θ, 并且更新后的梯度完全与g的原始方向对齐,有一定的稳定性。
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm其他部分代码详见附件,在完成代码的编写后我们进入实验/RNN的测试,本实验用到的默认样例参数总结于表8中,作为后续对比实验与消融实验的baseline。
表8 RNN模型默认参数样例(本实验)
| 参数名 | 取值 |
| batch_size | 32 |
| num_steps(小批量数据时间步) | 35 |
| num_hiddens | 512 |
| vocab(词元数) | 10000 |
| num_epoch | 500 |
| lr | 1 |
| optimizer | SGD |
| 激活函数 | Tanh |
万事俱备,让我们正式开始自购建模型的训练与测试,数据集加载/初始化与训练过程如图16所示,单次测试结果如图17所示:

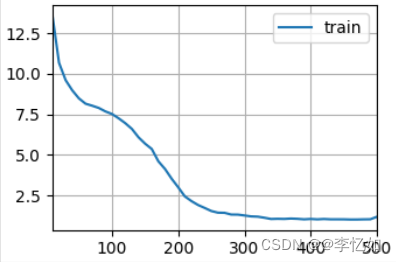
图18 自购建RNN结果样例
分析:根据图18,处理后的数据能正常进入RNN模型,经过500次epoch,最终困惑度为1.2,在个人cpu上速度为24505.1词元/秒,验证了自购建模型设计与代码实现的合理性与正确性。
根据第一章2.3我们知道RNN是有顺序分区和随机抽样两种策略的,上面的样例是顺序分区的,我们再来测一个随机抽样方案的RNN,代码部分只要在训练函数中加入“use_random_iter=True”,如Code4,测试结果样例如图19所示:
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),
use_random_iter=True) # 随机
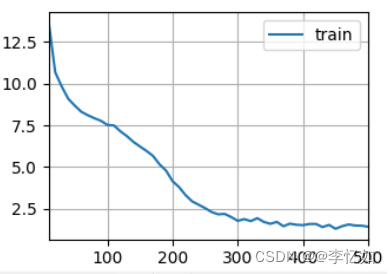
图19 自购建RNN结果样例(随机抽样)
分析:根据图19,经过500次epoch,RNN随机抽样模型的最终困惑度为1.4,在个人cpu上速度为22995.0词元/秒,速度与性能均略低于顺序分区(本参数组合样例中)。
为了验证自购建RNN不同方案的速度与性能对比,使用两种RNN均做20次实验,取平均词元/秒与平均困惑度分别作为度量指标,结果数据汇总于表9,效果对比如图20所示:
表9 顺序分区RNN vs 随机抽样RNN(数据汇总)
| 困惑度 | 词元/秒 | |
| 顺序分区 | 1.26 | 24701.5 |
| 随机抽样 | 1.43 | 23078.2 |
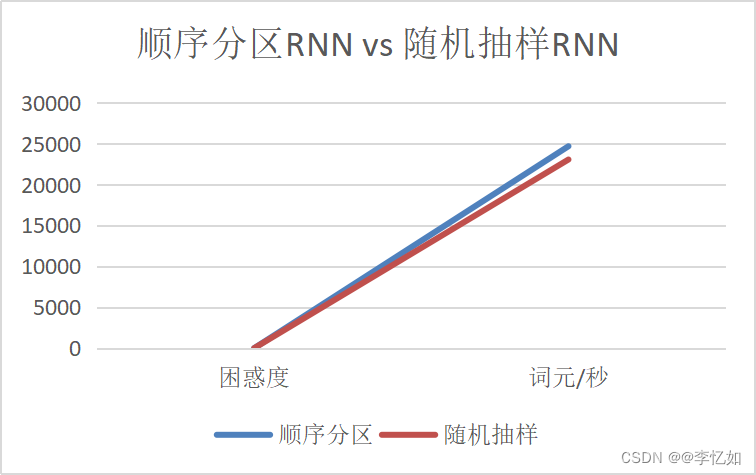
图20 顺序分区RNN vs 随机抽样RNN(效果对比)
分析:根据表9与图20,我们可以看到顺序分区RNN的平均困惑度小于随机抽样RNN,且词元/秒前者大于后者,故在本数据集&本参数组合下可验证顺序分区RNN速度与性能均优于随机抽样RNN。
而对于梯度爆炸或消失的问题,本实验同样可以尝试去删除梯度裁剪这一步去探究。一个简单方法是“把train_epoch_ch8里的gradient_clip函数打成注释,并打印loss”,经测试,本样例中顺序分区出现问题的概率远远大于随机采样(约99% vs 1%),而由于本样例只是tiny example,而其他很多情况下没有gradient_clip 会导致loss变成nan,原因不赘述。
1.3 代码实现(API)
通过1.2自购建的方式可以实现不同方案/策略的RNN,但无论是代码实现难度、效率/性能都不是最优选择,由于RNN类模型是经典模型,故Tensorflow、Pytorch等主流框架中均做了定义(API)与优化,便于我们快速搭建模型并应用,在本部分做一下探究。
通过API的代码实现非常简洁,全流程为数据集读入->模型定义/引入(通过API)->训练与预测。代码核心即模型的引入,如Code5所示,而用于控制与管理函数的RNNModel类定义与自购建RNN中的RNNModelScratch类似,这里不赘述,完整代码见RNN(API).py。
rnn_layer = nn.RNN(len(vocab), num_hiddens)Tips:这里只包含隐藏的循环层,输出层需要单独创建。
完成代码编写后,进入模型测试,数据集和参数与表8一致,结果样例如图21所示:

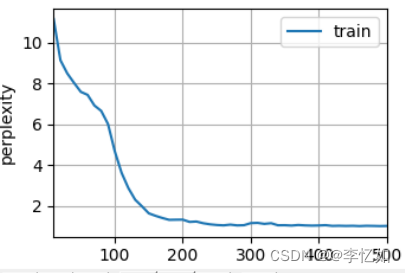
图21 RNN(API)结果样例
分析:如图21,经过500次epoch,最终困惑度为1.0,在个人cpu上速度为28759.6词元/秒,验证了API模型设计与代码实现的合理性与正确性。且比较表9,API实现在实现难度、速度与性能上均优于自购建RNN。
为验证RNN(API)与自购建RNN的速度与性能对比,使用两种RNN均做20次实验,取平均词元/秒与平均困惑度分别作为度量指标,结果数据汇总于表10,效果对比如图22:
表10 RNN(API) vs 自购建RNN(数据汇总)
| 困惑度 | 词元/秒 | |
| 自购建RNN(顺序) | 1.26 | 24701.5 |
| 自购建RNN(随机) | 1.43 | 23078.2 |
| RNN(API) | 1.03 | 28992.3 |
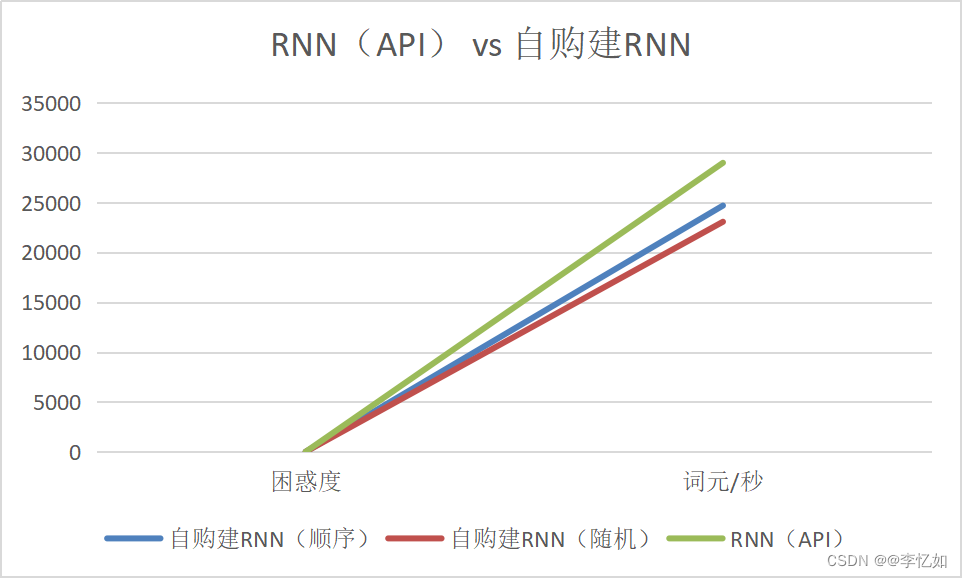
图22 RNN(API) vs 自购建RNN(效果对比)
分析:根据表10与图22,我们可以看到RNN(API)的困惑度均低于两种自购建RNN,且词元/秒也是最高,故在本数据集&本参数组合下可验证RNN(API)全方位相对与自购建RNN的优越性。
至此,不同方案、不同实现的RNN代码解析与测试结束,总体来说,使用API提供的RNN是省时省力的较优选择,但除了表8中的默认参数选择(自拟)与RNN的基本实现,仍有较大的探索和优化空间,在下两部分着重解析。
1.4 消融实验
前面两部分无论是自购建RNN(顺序分区与随机抽取)还是RNN(API),均是基于表8的参数,但根据实验2我们知道参数的选择对同样的模型在同样数据集的效果有很大影响,常见的超参数总结于表11:
表11 重要/常见超参数总结
| 1、损失函数: 损失可以衡量模型的预测值和真实值的不一致性,由一个非负实值函数损失函数定义 |
| 2、优化器: 为使损失最小,定义loss后可根据不同优化方式定义对应的优化器 |
| 3、epoch: 学习回合数,表示整个训练过程要遍历多少次训练集 |
| 4、学习率: 学习率描述了权重参数每次训练之后以多大的幅度(step)沿梯下降的方向移动 |
| 5、归一化: 在训练神经神经网络中通常需要对原始数据进行归一化,以提高网络的性能 |
| 6、Batchsize: 每次计算损失loss使用的训练数据数量 |
| 7、网络超参数: 包括输入图像的大小,各层的超参数(卷积核数、尺寸、步长,池化尺寸、步长、方法,激活函数等) |
而对于循环神经网络则主要关注num_hiddens。接下来我们进行一些消融实验来探究参数选择对RNN的影响。
Tips:消融实验构造的RNN全部基于API。
1.4.1 num_hiddens
num_hiddens即隐藏层数量,是影响RNN效果的重要超参数,我们保持表8中其他参数不变,仅改变num_hiddens,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表12,效果对比如图23:
表12 num_hiddens对RNN的影响(数据汇总)
| num_hiddens | 32 | 64 | 128 | 256 | 512 | 1024 |
| 困惑度 | 5.21 | 3.69 | 1.98 | 1.28 | 1.03 | 1.02 |
| 词元/秒 | 289066.5 | 182857.1 | 160003.4 | 84529.1 | 28992.3 | 9542.2 |
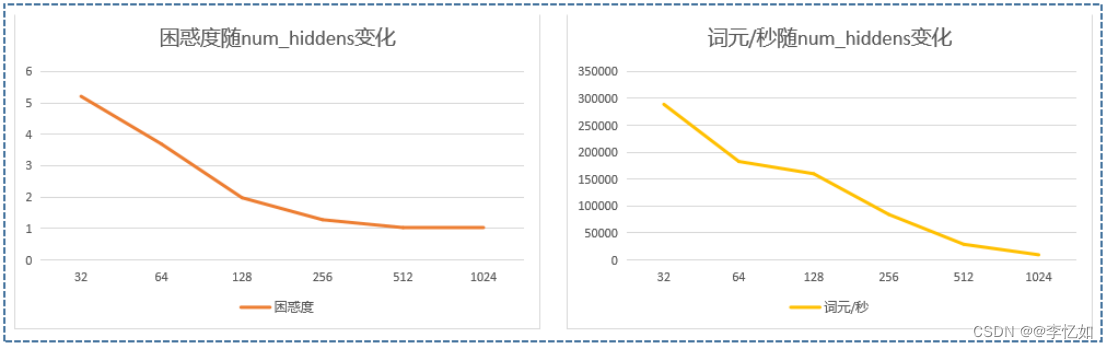
图23 num_hiddens对RNN的影响(效果对比)
分析:如表12与图23,我们可以发现随着困惑度随num_hiddens增大不断减少至较稳定(效果变好),而词元/秒则逐渐减小(效率降低),故如何做好速度和性能的平衡或取舍可通过num_hiddens的选择来决定,而表8中512的num_hiddens是一个不错的选择。
1.4.2 num_steps
num_hiddens即小批量数据时间步,我们保持表8中其他参数不变,仅改变num_steps,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表13,效果对比如图24:
表13 num_steps对RNN的影响(数据汇总)
| num_steps | 15 | 20 | 25 | 30 | 35 | 40 |
| 困惑度 | 1.5 | 1.42 | 1.3 | 1.21 | 1.03 | 1.02 |
| 词元/秒 | 28070.8 | 21622.1 | 24836.2 | 23272.4 | 28992.3 | 26157.7 |
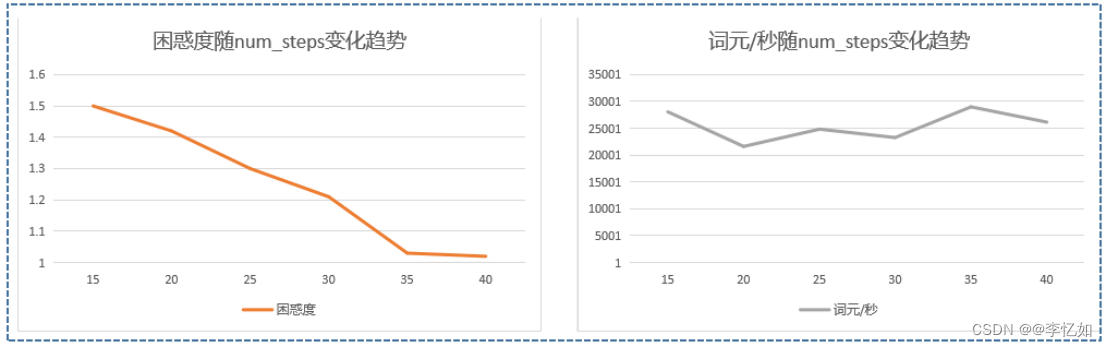
图24 num_steps对RNN的影响(效果对比)
分析:如表13与图24,我们可以发现随着困惑度随num_steps增大不断减少至较稳定(效果变好),而词元/秒则比较波动,没有明显规律,故选择一个较高的num_steps可以取得比较好的性能,而表8中25的num_steps是一个不错的选择。
1.4.3 batch_size
batch_size与num_steps类似,即同时处理数据的RNN数,我们保持表8中其他参数不变,仅改变batch_size,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表14,效果对比如图25:
表14 batch_size对RNN的影响(数据汇总)
| batch_size | 16 | 32 | 64 | 128 | 256 |
| 困惑度 | 13.7 | 1.03 | 1.1 | 1.38 | 6.11 |
| 词元/秒 | 14027.9 | 28992.3 | 31438.9 | 53808.4 | 47510.8 |
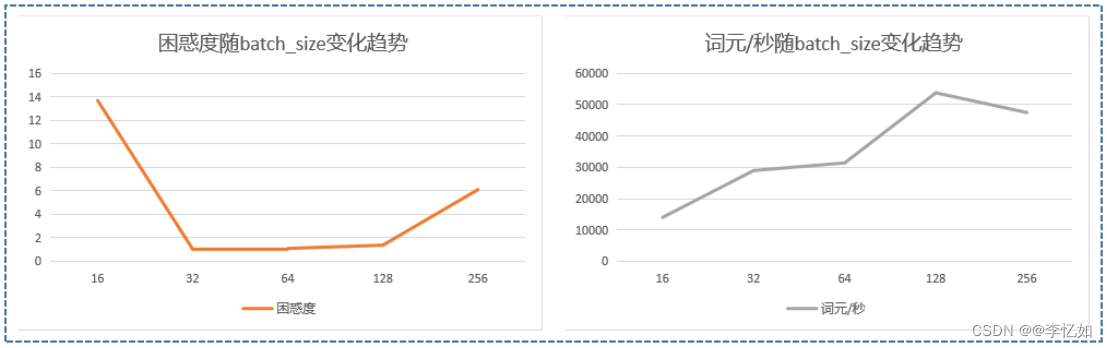
图25 batch_size对RNN的影响(效果对比)
分析:如表14与图25,我们发现随着困惑度随batch_size增大不断减少再增加(效果变好再变差),而词元/秒则是上升后再下降,故batch_size的选择对速度和性能都有很大影响,实际情况下一般要经过多轮测试选择,而表8中32的batch_size是一个性能最优选。
1.4.4 lr
lr即学习率,决定模型的收敛/迭代速度,我们保持表8中其他参数不变,仅改变lr,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表15,效果对比如图26:
表15 lr对RNN的影响(数据汇总)
| lr | 0.01 | 0.1 | 0.25 | 0.5 | 1 |
| 困惑度 | 13.3 | 3.52 | 1.19 | 1.11 | 1.03 |
| 词元/秒 | 27826.5 | 27234.4 | 28626.6 | 27655.1 | 28992.3 |
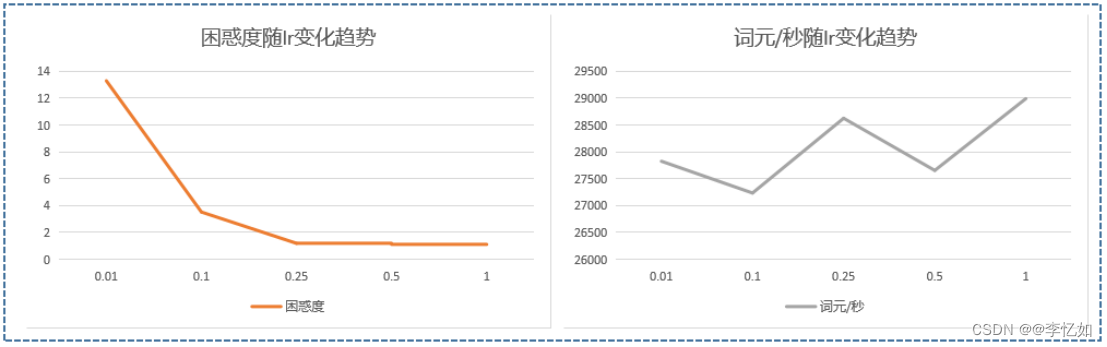
图26 lr对RNN的影响(效果对比)
分析:如表5与图26,我们可以发现随着困惑度随lr增大不断减少至稳定(效果变好,但小lr很有可能是因为未收敛),而词元/秒则是较为波动,无明显规律,但lr的选择是一门“玄学”,本消融实验也仅作思路的参考,而表8中1的lr是一个较优选。
1.4.5 epoch
epoch即整个训练过程要遍历多少次训练集,在以上四个消融实验中大部分模型已收敛(困惑度/loss无明显变化),困惑度随epoch的变化如图27所示,而对于lr中较大的困惑度取值去测试原因,选取lr=0.01,将epoch改为1500,效果如图28所示:
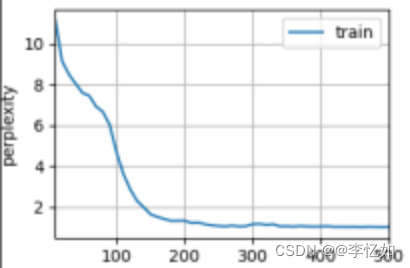
图27 epoch对困惑度的影响
分析:如图27所示,困惑度随着epoch增加而不断降低至稳定(收敛),与其他深度模型保持一致。
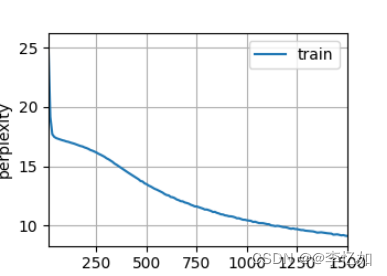
图28 lr=0.01,epoch=1500测试样例
分析:如图28,在测试样例中,epoch=1500困惑度仍维持在9.1,可见lr对收敛速度的影响,也侧面证实了lr的选择对模型效果的影响。
1.4.6 综述
前5部分我们分别对不同的五个超参做了消融实验,除此之外我们还可以改变vacab、激活函数(如变成ReLU)等去探究该参数对RNN的影响,方法类似就不展开了。根据分析结果再回顾表8中的参数组合,总体来说还是兼顾了速度与性能的一组参数。
调参的理由与本身对模型的影响有关,如学习率/Batch_size决定了迭代求解的速度与步幅,需要多次测试取较优值,而num_hiddens与模型原理息息相关,需要结合对应架构选择。但总的来说,没有永恒合适的最优参数组合,需根据数据集、任务、模型动态测试与调节。
2.LSTM
在本章第一节我们从原理、代码实现(自购建与API)、参数调节与优化三方面深度剖析了RNN的经典网络,但正如LeNet基于CNN,只了解最经典的架构意义有限,创新性高但存在较大局限性(在各种如今的现实应用场景下),故接下来我们要进行现代循环神经网络的解析与代码实现,首先是LSTM(长短期记忆网络)。
2.1 原理
参考论文:LST-1997(baulab.info)
参考论文:LSTM.pdf (arxiv.org)
参考博客:Understanding LSTM Networks -- colah's blog
我们在前一节一直在谈“梯度爆炸与梯度消失”的问题,同时长期以来隐变量模型存在着长期信息保存和短期输入缺失的问题,最早的解决方案就是长短期存储器LSTM。
首先让我们从LSTM的角度回顾RNN,它是一种短期记忆的模型,一个例子如图29,即:
- RNN中梯度更新小的layer停止学习
- 比如较早的层
- 序列越长,丢失的记忆越多

图29 RNN局限(短期记忆)
故LSTM顾名思义,引入了长期记忆,在架构方面添加了记忆元(单元)、几种用于控制状态的门(输入、忘记、输出),设计灵感来源于计算机的逻辑门,RNN与LSTM的架构对比可见图30:
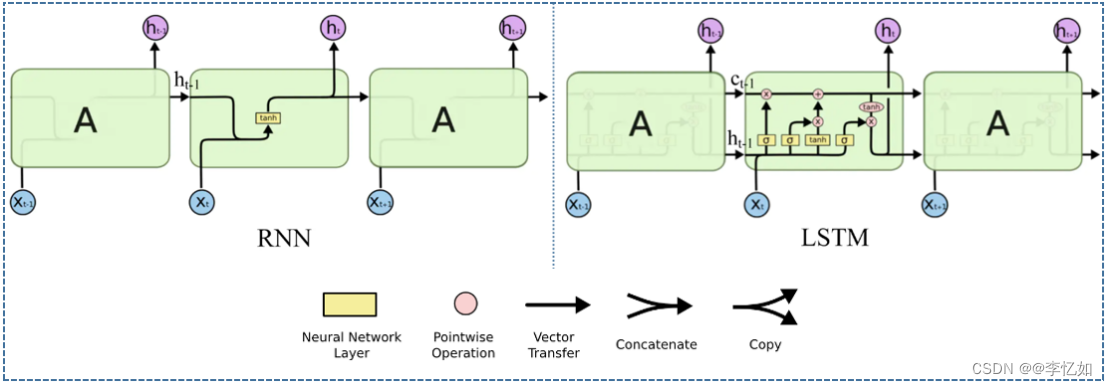
图30 RNN vs LSTM(架构对比)
分析:根据图30,我们可以看出:
- 传统 RNN 神经元默认接受上一时刻的隐藏状态 ht-1 和当前输入 xt。
- LSTM的神经元在此基础上还输入了一个 cell 状态 ct-1,cell 状态 c 和RNN中的隐藏状态 h 类似,都保存了历史的信息,从ct-2 ~ ct-1 ~ ct。LSTM 中的 h 更多地是保存上一时刻的输出信息。
让我们聚焦LSTM的模型,首先其核心思想是记忆元(单元),也称细胞状态,类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。同时如上文所述,通过精心设计的称作为“门”结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作,如图31所示:
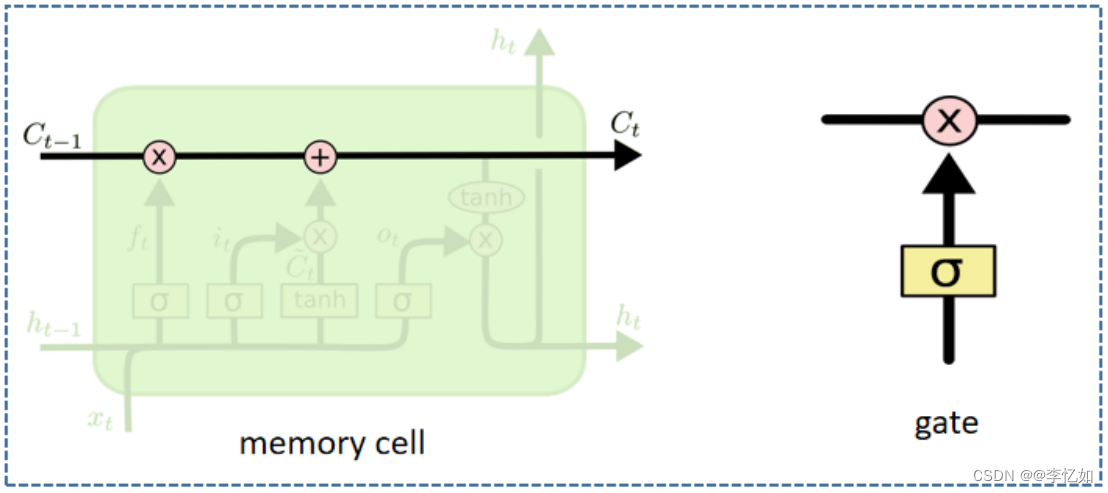
图31 LSTM核心思想与结构
而LSTM的总体流程与门设计简介总结于图表1:
图表1 LSTM总体流程及门设计简介
| 输入:将数据集导入模型 |
| 1、Sigmiod层: 输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。通过三个门来保护和控制细胞状态 |
| 2、遗忘门(LSTM-1): 决定我们从“细胞”中丢弃什么信息。该层读取当前输入x和前神经元信息h,由ft来决定丢弃的信息。输出结果1表示“完全保留”,0 表示“完全舍弃”。
|
| 3、输入门(LSTM-2): 确定细胞状态所存放的新信息,这一步由两层组成。sigmoid层作为“输入门层”,决定我们将要更新的值i;tanh层来创建一个新的候选值向量ct~加入到状态中。在语言模型的例子中,我们希望增加新的主语到细胞状态中,来替代旧的需要忘记的主语。
|
| 4、输出门(LSTM-3): 更新旧细胞的状态,将ct-1更新为ct。我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*ct~。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的信息并添加新的信息的地方。
|
| 5、输出确定/候选记忆元: 最后一步要确定输出,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。在语言模型的例子中,因为语境中有一个代词,可能需要输出与之相关的信息。例如,输出判断是一个动词,那么我们需要根据代词是单数还是负数,进行动词的词形变化。
|
| 输出:处理后的数据/预测数据 |
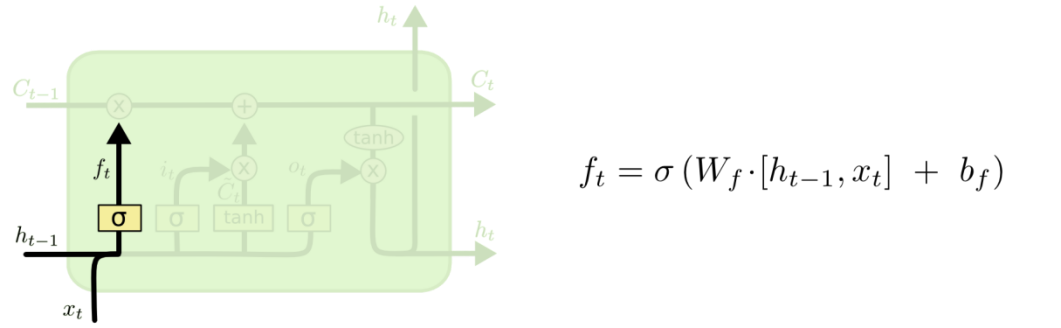
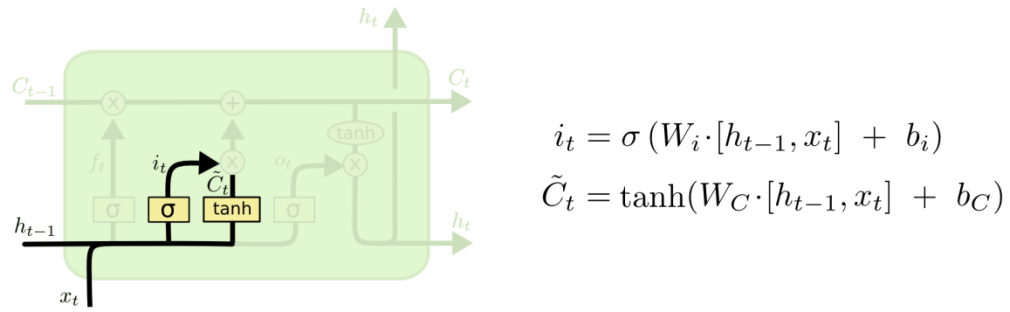
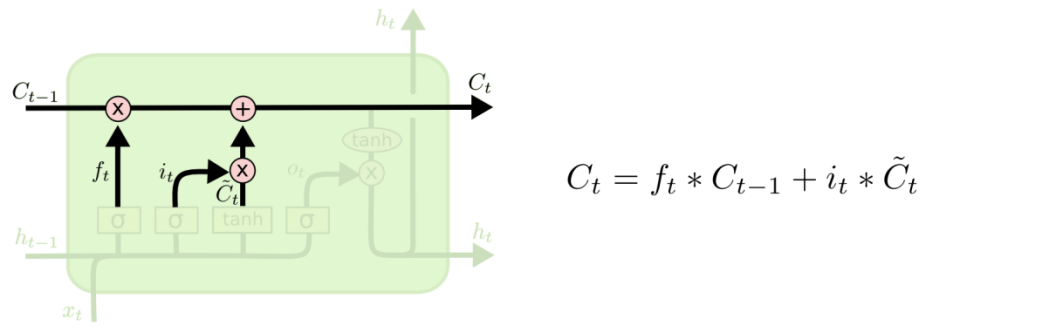
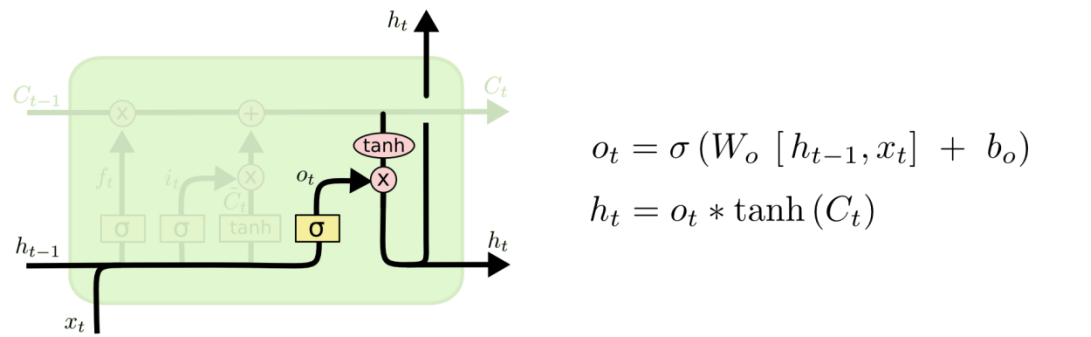
至此,我们对LSTM的原理/结构实现就比较清楚了,当然LSTM有很多变体,常见的几个总结于图32(GRU后续详解,其他不展开):
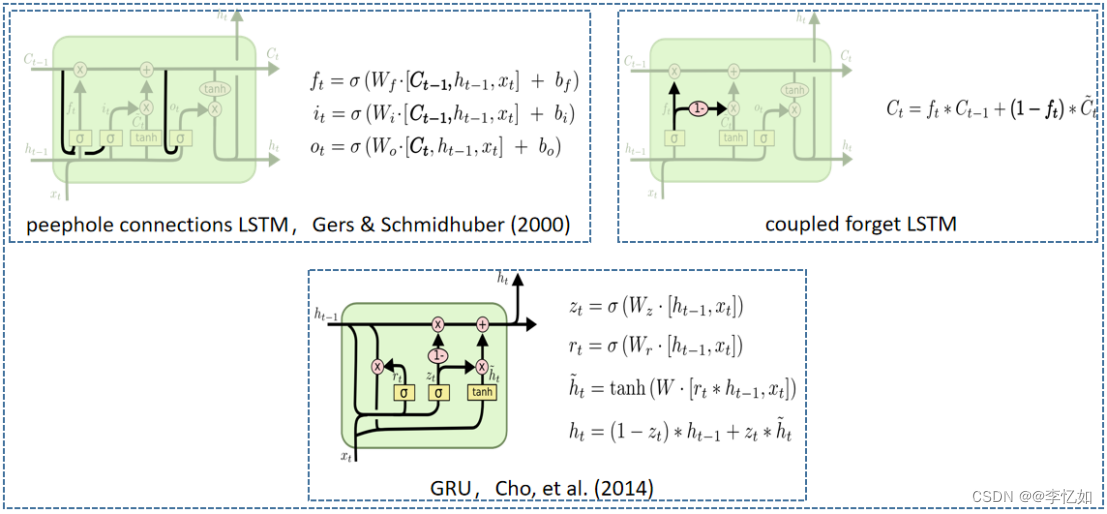
图32 LSTM常见变体架构
通过图表1我们很容易知道LSTM的长记忆引入解决了RNN的短期局限。而对于梯度消失或爆炸的缓解原因在这里做一定补充,通过对RNN的数理推导我们知道梯度消失的原因主要是梯度函数中包含一个连乘项,LSTM去除的方法是通过门的作用使其约等于0或1,如式11,详细来说即:
门的梯度接近1时,连乘项能够保证梯度很好地在 LSTM 中传递,避免梯度消失。
- 门的梯度接近0时,即上一时刻的信息对当前时刻并没有作用,此时没必要梯度回传。
式11 LSTM梯度问题缓解策略
而关于LSTM数理部分的推导,详细可见论文,在这里给出用误差信号的FULL BPTT推导,网络结构总览如图33,推导集合可见式集1与式集2:
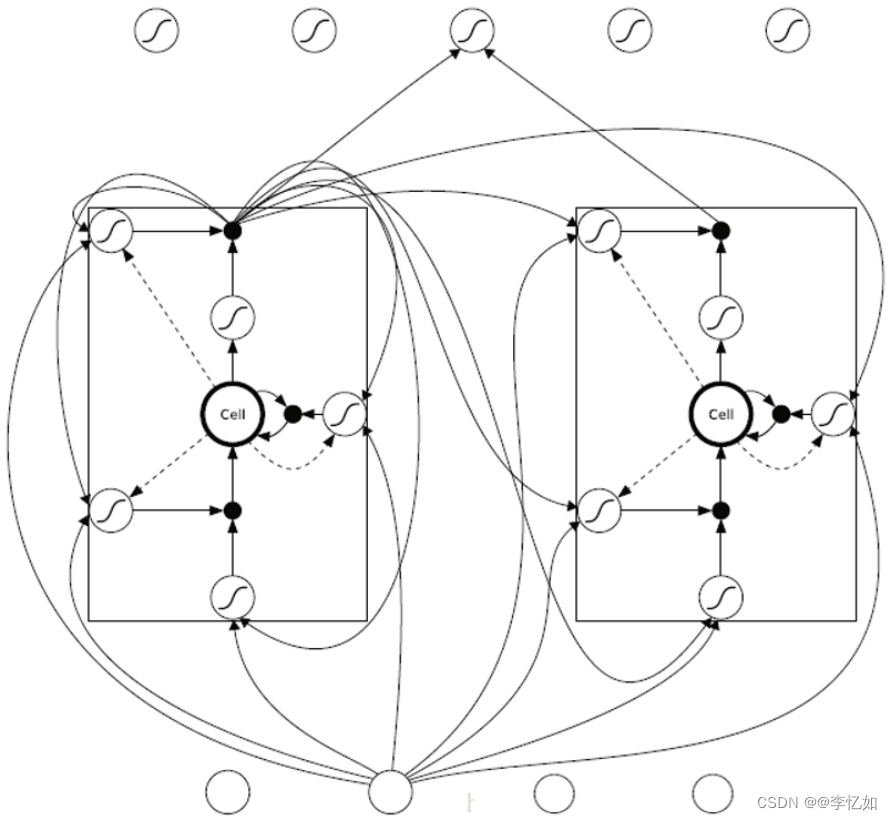
图33 LSTM网络结构总览


至此,LSTM的架构与数理逻辑部分均解析完成。
2.2 代码实现
本部分我们进入LSTM的代码实现,根据2.1中对LSTM原理/架构的解析,我们编写代码文件为LSTM.py,在此仅作核心代码的解析。其中,LSTM实现的核心流程即数据集导入->参数初始化->模型定义->训练和预测,同样是有自购建与API两种方法,自购建模型定义部分代码可见Code6(但实验使用API构建):
# 模型状态初始化
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
#模型定义
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)代码编写完成后我们进入实验/LSTM的测试,用到的参数组合与baseline(表8)基本保持一致,结果样例如图35所示:

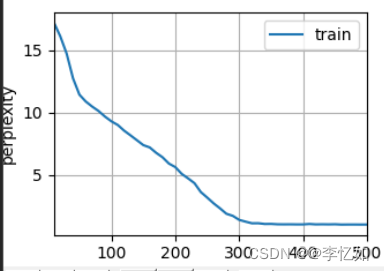
图35 LSTM结果样例
分析:根据图34与图35,处理后的数据能正常进入LSTM模型,经过500次epoch,最终困惑度为1.0,在个人cpu上速度为2401.5词元/秒,验证了LSTM模型设计与代码实现的合理性与正确性。
2.3 消融实验
类似RNN,我们也可以对LSTM的参数进行消融实验以探究不同选择对模型速度与性能的影响,本部分以num_hiddens的消融实验为例,其他探究与1.4的逻辑和步骤保持一致,在此不赘述。
我们保持其他参数不变,仅改变num_hiddens,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表16,效果对比如图36:
表16 num_hiddens对LSTM的影响(数据汇总)
| num_hiddens | 32 | 64 | 128 | 256 | 512 | 1024 |
| 困惑度 | 4.2 | 2.2 | 1.17 | 1.11 | 1.02 | 1.02 |
| 词元/秒 | 99672.4 | 47770 | 43921.7 | 14154.9 | 2408.6 | 1989.9 |
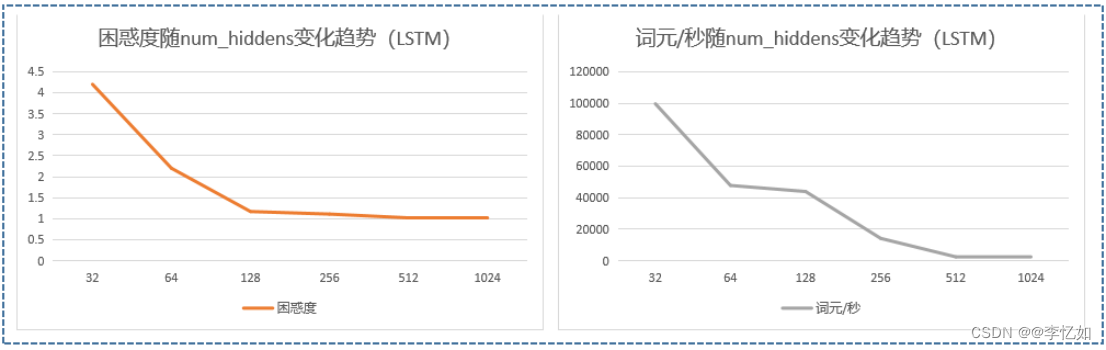
图36 num_hiddens对LSTM的影响(效果对比)
分析:如表16与图36,我们可以发现随着困惑度随num_hiddens增大不断减少至较稳定(效果变好),而词元/秒则逐渐减小(效率降低),故如何做好速度和性能的平衡或取舍可通过num_hiddens的选择来决定,而表8中512的num_hiddens是一个不错的选择。
至此,LSTM的理论与实验部分均已解析完成。
3.GRU
3.1 原理
参考论文:RNN Encoder–Decoder.pdf (arxiv.org)
参考论文:GRU.pdf (arxiv.org)
LSTM是对RNN的经典优化,较好地缓解了梯度爆炸或消失问题,且解决了隐模型长期信息保存和短期输入缺失的问题,但LSTM也存在结构复杂、效率低下的问题,故一个经典变体GRU(门控循环单元)出现了,架构对比如图37所示:

图37 LSTM vs GRU(架构对比)
简单来说,它组合了遗忘门和输入门到一个单独的“更新门”中,也合并了cell state和hidden state,并且做了一些其他的改变,形成了一个更加简化的模型,核心流程即重置门->更新门->候选隐状态->隐状态,详细的计算可见图表1和图32,在此不赘述。
总的来说,GRU有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系
- 更新门有助于捕获序列中的长期依赖关系
3.2 代码实现
本部分我们进入GRU的代码实现,根据3.1中对GRU原理/架构的解析,我们编写代码文件为GRU.py,在此仅作核心代码的解析。其中,GRU实现的核心流程即数据集导入->参数初始化->模型定义->训练和预测,同样是有自购建与API两种方法,自购建模型定义部分代码可见Code7(但实验使用API构建):
# 模型状态初始化
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
#模型定义
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)代码编写完成后我们进入实验/GRU的测试,用到的参数组合与baseline(表8)基本保持一致,结果样例如图39所示:

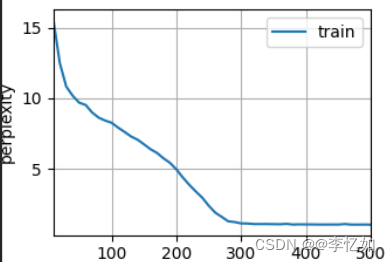
图39 GRU结果样例
分析:根据图38与图39,处理后的数据能正常进入GRU模型,经过500次epoch,最终困惑度为1.0,在个人cpu上速度为4538.1词元/秒,验证了GRU模型设计与代码实现的合理性与正确性。
3.3 消融实验
类似RNN与LSTM,我们也可以对GRU的参数进行消融实验以探究不同选择对模型速度与性能的影响,本部分以num_hiddens的消融实验为例,其他探究与1.4的逻辑和步骤保持一致,在此不赘述。
我们保持其他参数不变,仅改变num_hiddens,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表17,效果对比如图40:
表17 num_hiddens对GRU的影响(数据汇总)
| num_hiddens | 32 | 64 | 128 | 256 | 512 | 1024 |
| 困惑度 | 3.7 | 1.7 | 1.1 | 1.08 | 1 | 1 |
| 词元/秒 | 82965.5 | 57806.2 | 47659.9 | 24216.3 | 4692.1 | 1764.5 |
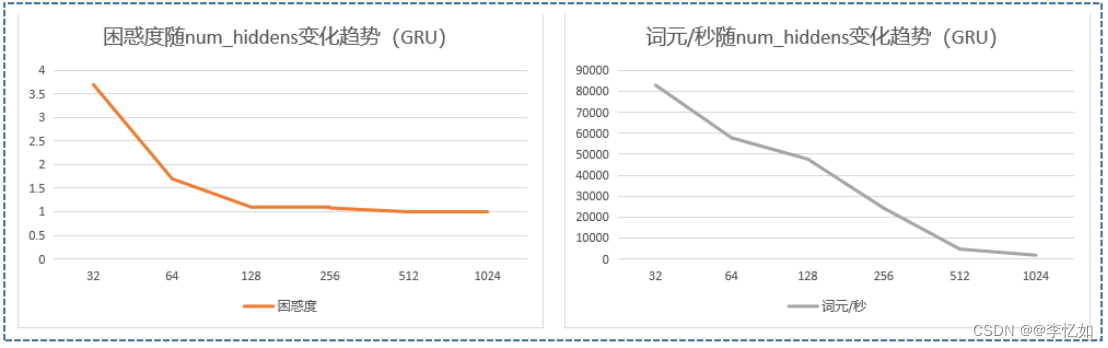
图40 num_hiddens对GRU的影响(效果对比)
分析:如表17与图40,我们可以发现随着困惑度随num_hiddens增大不断减少至较稳定(效果变好),而词元/秒则逐渐减小(效率降低),故如何做好速度和性能的平衡或取舍可通过num_hiddens的选择来决定,而表8中512的num_hiddens是一个不错的选择。
至此,GRU的理论与实验部分均已解析完成。
4.对比分析
在前三节我们使用了不同方案(自购建、API)与不同参数组合(消融实验测试)构建了RNN、LSTM、GRU三种模型,在本节我们通过对前三节消融实验的数据抽取,去对比分析三种模型的困惑度(性能)与词元/秒(速度),以num_hiddens作为聚合维度(样例,可换其他,逻辑一致这里不展开),数据汇总于表18与表19(分别对应困惑度对比与词元/秒对比),效果对比如图41与图42所示(逻辑同理):
Tips:对比模型均由API构建,数据集为时光机器书籍,其他参数与表8基本一致。
表18 模型困惑度对比分析(数据汇总)
| num_hiddens | 32 | 64 | 128 | 256 | 512 | 1024 |
| RNN | 5.21 | 3.69 | 1.98 | 1.28 | 1.03 | 1.02 |
| LSTM | 4.2 | 2.2 | 1.17 | 1.11 | 1.02 | 1.02 |
| GRU | 3.7 | 1.7 | 1.1 | 1.08 | 1 | 1 |
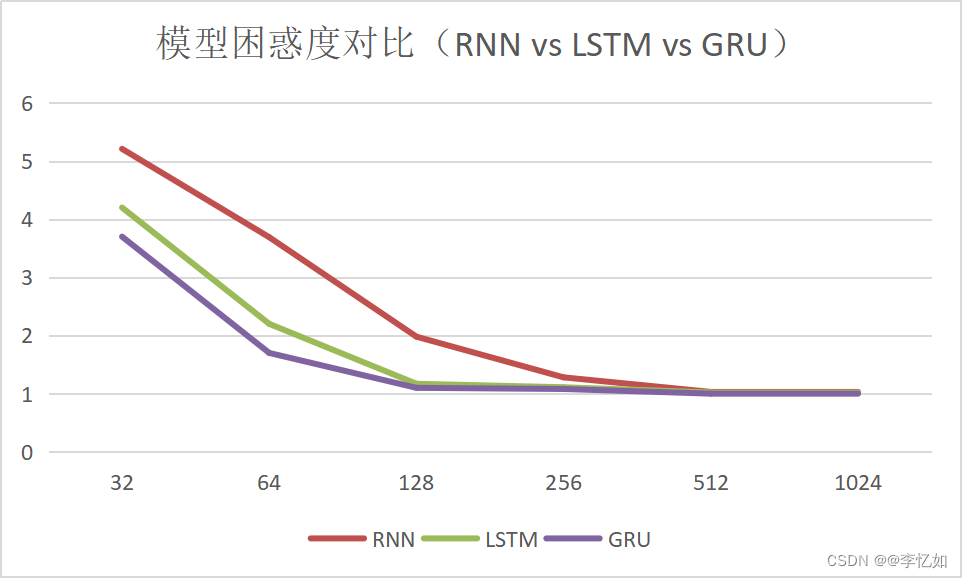
图41 模型困惑度效果对比
表19 模型词元/秒对比分析(数据汇总)
| num_hiddens | 32 | 64 | 128 | 256 | 512 | 1024 |
| RNN | 289066.5 | 182857.1 | 160003 | 84529.1 | 28992.3 | 9542.2 |
| LSTM | 99672.4 | 47770 | 43921.7 | 14154.9 | 2408.6 | 1989.9 |
| GRU | 82965.5 | 57806.2 | 47659.9 | 24216.3 | 4692.1 | 1764.5 |
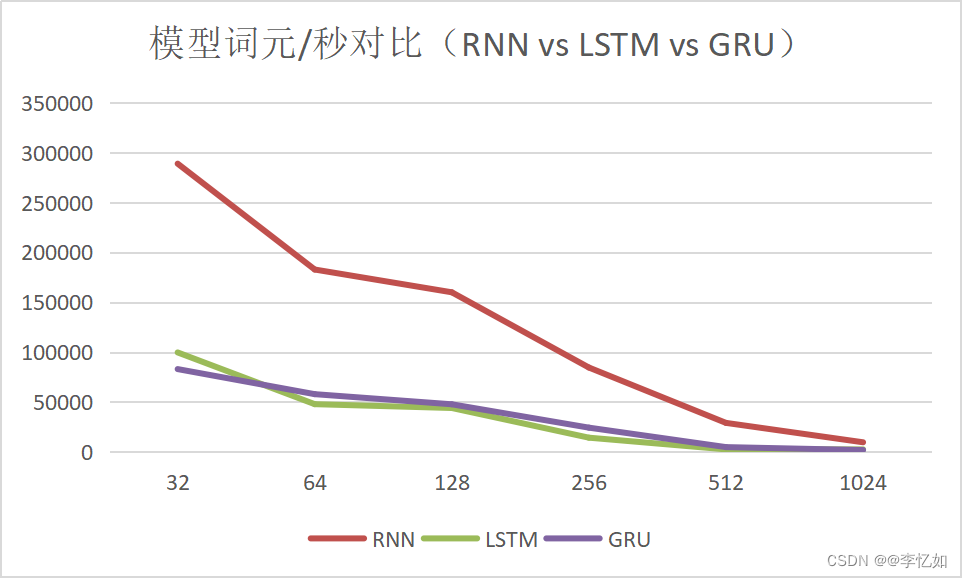
图42 模型词元/秒效果对比
分析:根据图41、42与表18、19,我们可以从速度与性能两方面得出对比结论如下:
- 性能:在本实验条件下,每个num_hiddens下性能均是GRU > LSTM > RNN(困惑度相反),而随着num_hiddens增大,三个模型的表现均越来越好,且性能差距越来越小。
- 速度:在本实验条件下,每个num_hiddens下速度均是GRU 与 LSTM < RNN(大部分情况下GRU速度优于LSTM),而随着num_hiddens增大,三个模型的速度均越来越低,且差距越来越小。
综述:故并不是说GRU在任何情况下都是优于传统RNN的选择(且本实验只以num_hiddens作为了聚合维度),真实情况下要结合任务、数据集、算力资源等实际情况去择优选择合适的模型。
四、高级循环神经网络架构介绍与选择实现
上一章中我们对几种经典的循环神经网络(RNN、LSTM、GRU)做了架构设计与数理推导的详解,且用了不同方式实现了几种循环神经网络,并通过消融实验的方式探究了几种超参数对模型速度与性能的影响,另外还对比分析了三种模型的优劣。
而本章我们来介绍一些高级循环神经网络(本实验命名,非官方),以深度循环神经网络/双向循环神经网络/编码器-解码器结构/序列到序列学习为例,并选择一种实现。
1.深度循环神经网络
1.1 原理
前面主要讨论的都是只有一个单向隐藏层的循环神经网络,而实际上循环神经网络是可堆叠的,这就是深度循环神经网络的本质/核心,一个样例如图43所示,这对层的添加、非线性的补充都是有指导意义的。而将函数依赖关系形式化,如式12,最后,输出层的计算仅基于第l个隐藏层最终的隐状态,如式13:
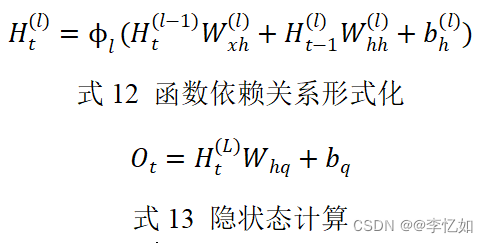
Tips:式子含义与网络迭代推理时保持一致,在此不赘述。
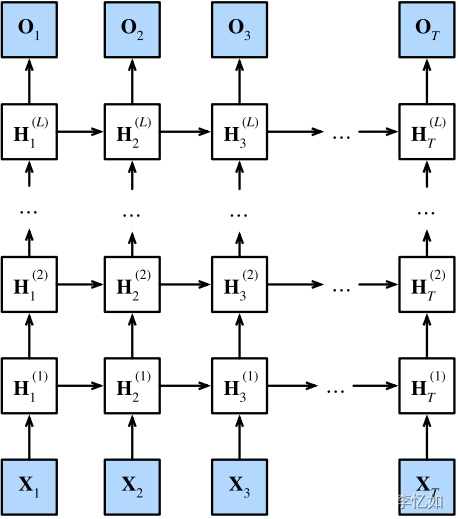
图43 深度循环神经网络样例
1.2 代码实现
实现多层循环神经网络所需的许多逻辑细节在高级API中都是现成的。以LSTM为例,与第二章2.2类似,唯一的区别是我们指定了层的数量,而不是使用单一层这个默认值,核心代码可见Code8,完整代码可见DeepLSTM.Py:
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_sizedevice = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)代码编写完我们进入实验/多层LSTM的测试,用到的参数组合与baseline(表8)基本保持一致(num_hiddens由512改为32),结果样例如图45所示:

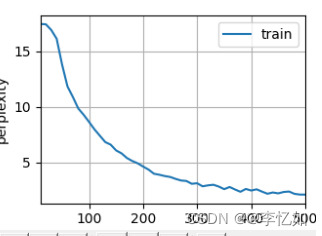
图45 双层LSTM结果样例
分析:根据图44与图45,处理后的数据能正常进入双层LSTM模型,经过500次epoch,最终困惑度为2.1,在个人cpu上速度为56000.6词元/秒,验证了GRU模型设计与代码实现的合理性与正确性。
1.3 消融实验
类似第二章的模型,我们也可以对深度循环神经网络的参数进行消融实验以探究不同选择对模型速度与性能的影响,而最重要的即num_layers的影响,故本部分以其消融实验为例,其他探究与第二章1.4的逻辑和步骤保持一致,在此不赘述。
我们保持其他参数不变,仅改变num_layers,每个取值进行20组实验取平均值,探究困惑度与词元/秒的变化趋势,数据汇总于表20,效果对比如图46:
表20 num_layers对LSTM的影响(数据汇总)
| num_layers | 1 | 2 | 3 | 4 | 5 |
| 困惑度 | 4.2 | 2.09 | 2.54 | 17.4 | 17.5 |
| 词元/秒 | 99672.4 | 55921.8 | 38788.8 | 28000.5 | 23579.3 |
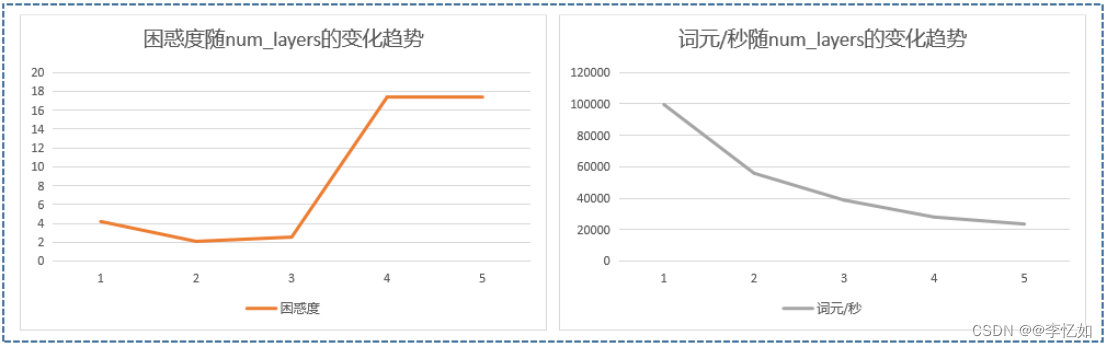
图46 num_layers对LSTM的影响(效果对比)
分析:如表20与图46,可以发现随着困惑度随num_layers先减小再增大再稳定,而词元/秒则逐渐减小(效率降低),故num_layers的选择并不是越大越好,与其他超参数的选择也息息相关,需多次测试选出最优值,本实验中中2的num_layers是一个不错的选择。
至此,深度循环神经网络的理论与实验部分均已解析完成。
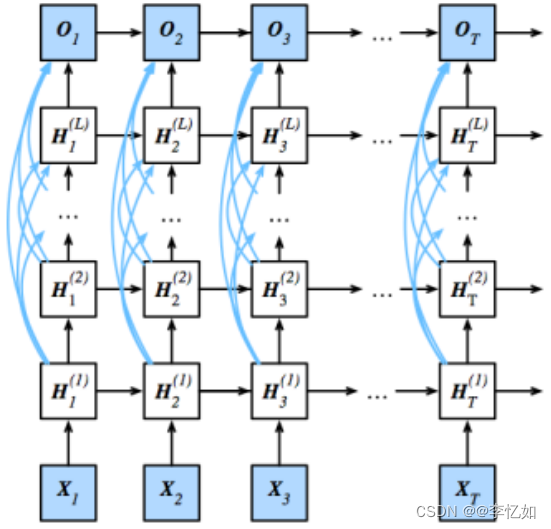
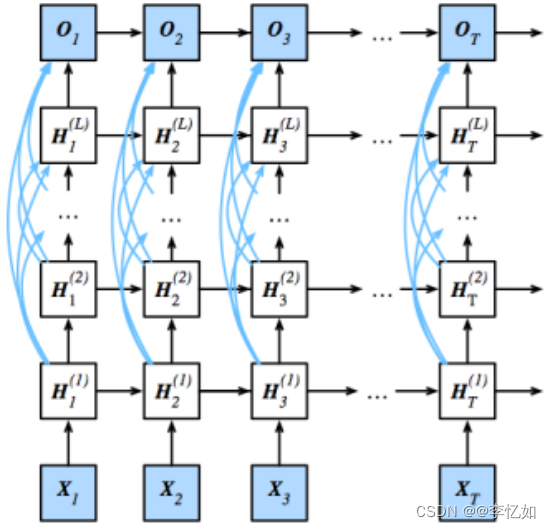
2.双向循环神经网络
参考论文:Bidirectional Recurrent Neural Networks - (cmu.edu)
首先来看一个例子感受一下“未来”的重要性,如表21所示:
表21 文本序列填空样例
| 我 饿 。 我 不是 非常饿。 我 非常 非常饿,我可以吃下一只猪。 |
根据可获得的信息量,我们可以用不同的词填空,在本样例中,下文(“未来”)传达了重要信息/做了限制,而RNN是只关注上文的,在本部分存在局限,故BRNN(双向循环神经网络)出现了,架构样例如图47所示,前/反向传播更新如式14,输出如式15:
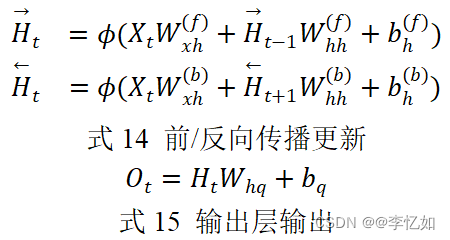
Tips:式子含义与网络迭代推理时保持一致,在此不赘述。
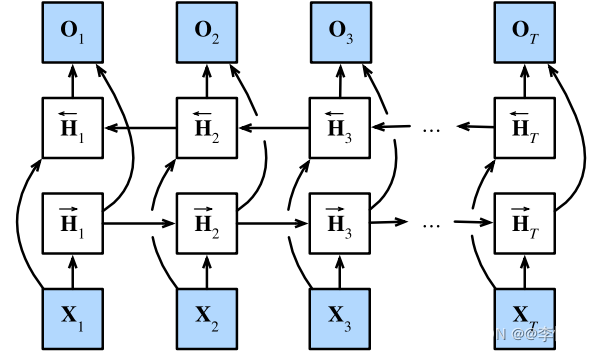
图47 BRNN架构样例
故BRNN的关键特征是使用来自序列两端的信息来估计输出,但在预测下一个词元时这步的意义有限,且会大大降低计算速度,故双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)。
BRNN的代码实现如Code9所示,结果样例如图48:
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)Tips:本样例为双向循环神经网络的错误应用,即用其进行序列预测。

图48 双向LSTM结果样例
分析:根据图48,我们可以看到最终预测输出的不合理性,验证了双向循环神经网络在序列预测等任务上的局限性。
3.稠密连接网络
我们在第一节使用深度循环神经网络的时候难免会有一个问题:添加层是否可以提高准确性?如图49所示,也通过消融实验做了简单测试。在实验2中我们研究CNN的时候解析了ResNet(在此不赘述),实际上深度循环神经网络是可以与残差网络组合的,即稠密连接网络,架构样例如图50所示:
图49 准确性与层数关系
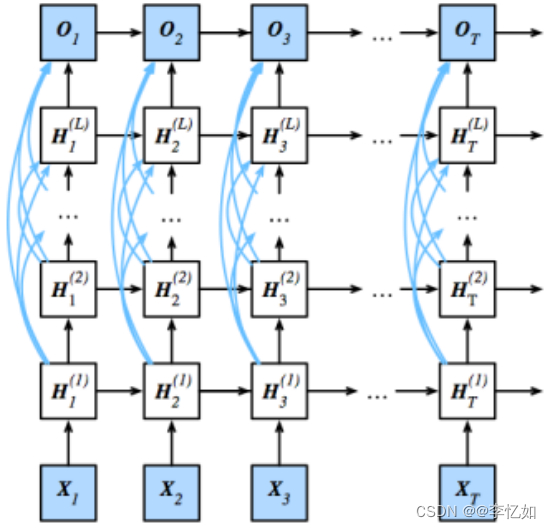
图50 稠密连接网络架构样例
根据图50与两种相关网络定义,我们可以总结稠密连接网络主要特点如下:
- 将前一层的输出连接为下一层的输入
- 偶尔添加过渡层以减少维度
4.机器翻译与数据集
前面的模型我们一直在以序列预测为基准任务,实际上是有点局限且乏味的,NLP作为计算机领域高速发展的领域,实际上还有许多经典的任务,比如机器翻译任务,其为语言模型最成功的基准测试。 因为机器翻译正是将输入序列转换成输出序列的序列转换模型的核心问题,故我们引入一下相关概念与数据集,后面的几个架构介绍都会基于机器翻译任务。
机器翻译,顾名思义即指的是将序列从一种语言自动翻译成另一种语言,一般分为统计机器翻译(基于统计学方法)与神经机器翻译(基于神经网络)。
机器翻译的数据集是由源语言和目标语言的文本序列对组成的。因此,我们需要一种完全不同的方法来预处理机器翻译数据集,而不是复用语言模型的预处理程序。一个样例流程总结于表22(如何将预处理后的数据加载到小批量中用于训练):
Tips:本实验以Tatoeba项目的双语句子对 组成的“英-法”数据集为例,详情可见:Tab-delimited Bilingual Sentence Pairs from the Tatoeba Project(manythings.org)
表22 机器翻译数据集预处理
| 输入:数据集 数据集中的每一行都是制表符分隔的文本序列对, 序列对由英文文本序列和翻译后的法语文本序列组成。 请注意,每个文本序列可以是一个句子, 也可以是包含多个句子的一个段落,例如: Go. Va ! Hi. Salut ! Run! Cours ! |
| 1、预处理: 下载导入数据集后,需要经过几个预处理步骤,例如用空格代替不间断空格, 使用小写字母替换大写字母,并在单词和标点符号之间插入空格等。 |
| 2、词元化: 与前面的词元化不同,在机器翻译中,一般更喜欢单词级词元化(最先进的模型可能使用更高级的词元化技术),例如: ([['go', '.'], [['ça', 'alors', '!']]) |
| 3、词表构建与加载数据集: 分别为源语言和目标语言构建两个词表,并通过截断和填充方式实现一次只处理一个小批量的文本序列。 |
| 输出:将处理好的数据输出到模型,进行训练。 |
5.编码器-解码器架构
Encoder-Decoder(编码器-解码器)是深度学习模型的抽象概念,一般认为很多模型均起源/共同表征于这个架构,包括但不限于CNN、RNN、Transformer,广义架构如图51:

图51 编码器-解码器广义架构
根据图51,很容易归纳出其架构的两个核心:
- 编码器(Encoder):负责将输入(Input)转化为特征(Feature)
- 解码器(Decoder):负责将特征(Feature)转化为目标(Target)
而我们提到很多模型可以在这个架构下共同表征,以CNN和RNN为例,如图52所示,它们的简单理解如下:
- CNN可以认为是解码器可以不接受输入的情况
- RNN可以认为是解码器同时接受输入的情况
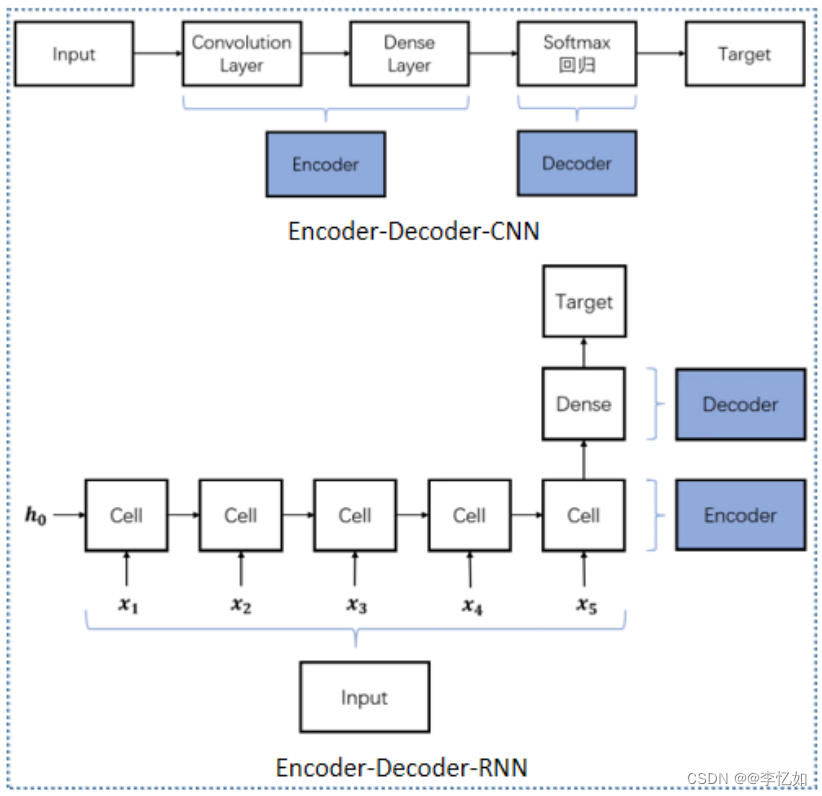
图52 CNN vs RNN(Encoder-Decoder)
让我们的视角聚焦回RNN,第四节我们说到,机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列,故编码器-解码器架构是一个不错的选择,编码器接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。解码器将固定形状的编码状态映射到长度可变的序列。代码实现分别如Code10与Code11所示:
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedErrorclass Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
model = model.to(device)6.序列到序列学习
参考论文:Sequence to Sequence Learning with Neural Networks 14 Dec 2014
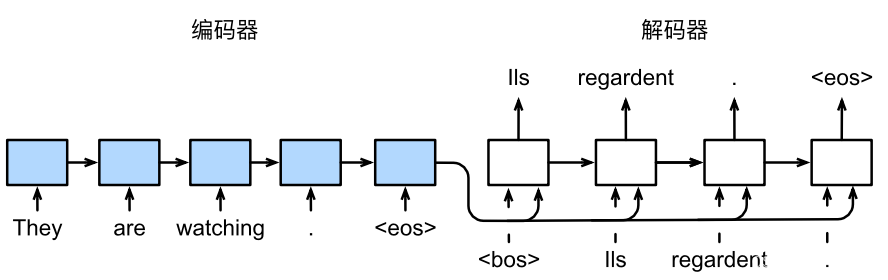
上一节我们解析了编码器-解码器架构,其会启发人们使用具有状态的神经网络。本节我们来讲讲一个使用循环神经网络设计基于“编码器-解码器”架构的序列转换模型——seq2seq(序列到序列学习)。样例架构如图53所示,其中的层如图54所示:
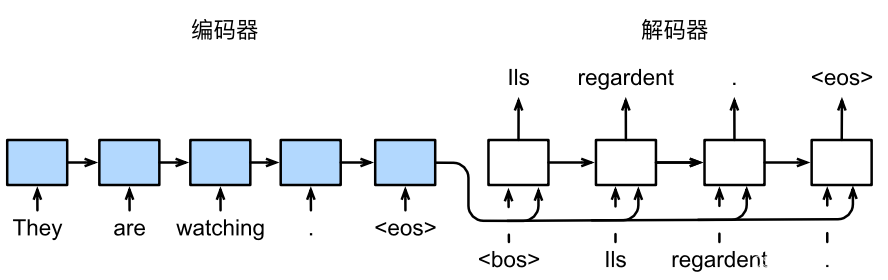
图53 RNN编码器-解码器的序列到序列学习架构样例
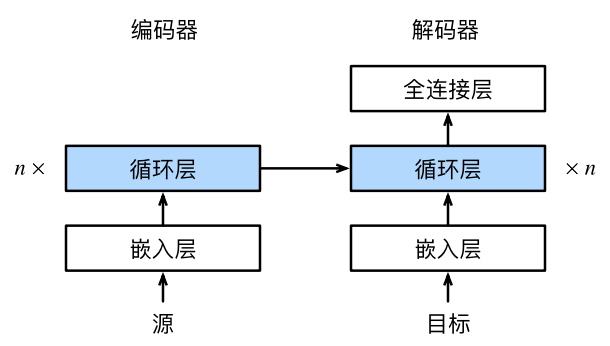
图54 循环神经网络编码器-解码器模型中的层
如图54,序列到序列学习的核心是一旦输出序列生成此词元,模型就会停止预测。对于训练效果的度量,可以引入常规的loss(softmax来获得分布,并通过计算交叉熵损失函数来进行优化)而对于预测序列的评估,我们可以通过与真实的标签序列进行比较来评估预测序列,即使用BLEU测量许多应用的输出序列的质量。原则上说,对于预测序列中的任意n元语法, BLEU的评估都是这个n元语法是否出现在标签序列中,如式16:
式16 BLEU定义
Tips:其中lenlabel表示标签序列中的词元数和lenpred表示预测序列中的词元数,k是用于匹配的最长的n元语法。 另外,用pn表示n元语法的精确度。
在代码实现方面,详情可见seq2seq.py,本部分仅作核心代码解析。首先是编码器与解码器的设计,核心与Code10、Code11保持一致(需扩展),而在训练与模型初始化部分,代码如Code12,两个结果样例分别如图55与图56(训练与预测):
#@save 训练
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
#模型初始化
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)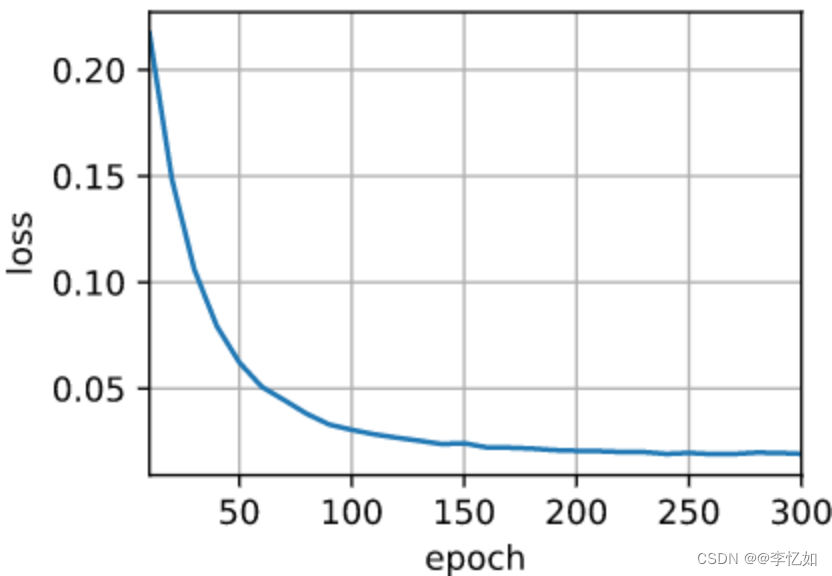
图55 seq2seq用于机器翻译的结果样例(训练)
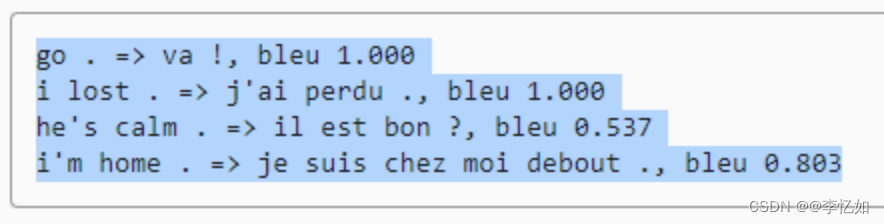
图56 seq2seq用于机器翻译的结果样例(预测)
类似前面所有RNN模型,seq2seq同样可以进行消融实验探究不同参数组合对模型效果的影响,逻辑与步骤在上文已详细分析,在此不赘述。
至此,大部分主流RNN模型架构均已解析完成。
五、总结
1.实验结论
本次实验完成任务梳理如表23,不同RNN简介与对比如图表2所示:
表23 实验3完成任务梳理
| 1、理论梳理: 第一章进行了循环神经网络的综述(背景、概念、原理、发展历程)与RNN训练的基本原理与流程介绍,在第二章中按时间线从架构与数理两部分对RNN(tanh)、LSTM、GRU进行了解析。在第三章总结介绍了一些其他的循环神经网络及其优化。 |
| 2、多种RNN实践与优化: 从自构建与API两种方式对比实现了RNN,并对RNN、LSTM、GRU均进行了不同参数的消融实验,定量探究对应参数与架构设计对模型速度与性能的影响,并对比分析了三种模型效果。在高级循环神经网络中,提出了多种优化策略,并分别选择了深度循环神经网络、双向循环神经网络、序列到序列学习进行了实践探究。 |
| 3、方案补充: 对于RNN的高级架构实现与优化,除了给定的要求,均作了相关的拓展,比如在原理侧,详细解析了语言模型的核心前置知识(序列模型/预测、文本预处理、机器翻译等)。 |
图表2 不同RNN简介与对比
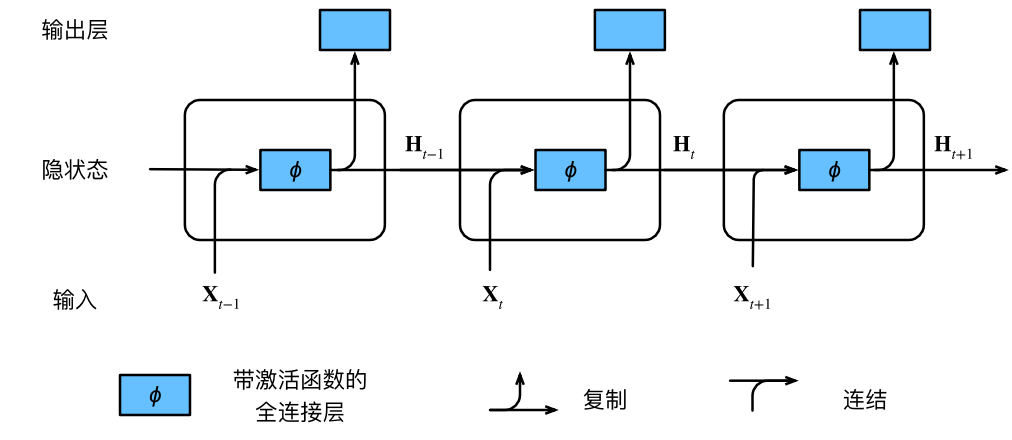
| 1、经典RNN(tanh): 广义上RNN的开山之作,通过循环将训练“学”到的东西蕴藏在权值W中,本质上是循环/递推函数。
|
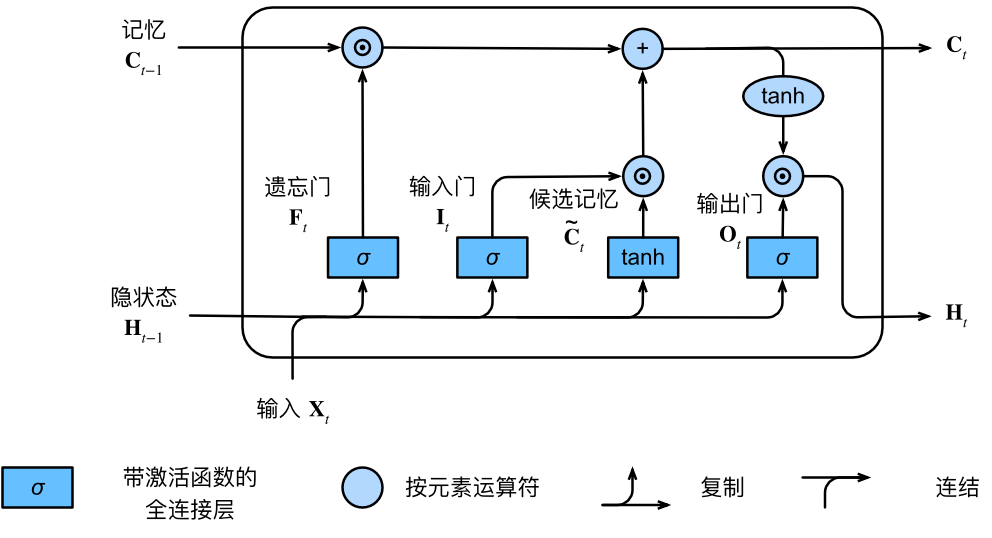
| 2、LSTM: 在RNN(tanh)的基础上引入了记忆元,并通过遗忘门、输入门、输出门进行状态控制,实现了长短期记忆共用,也缓解了梯度爆炸/梯度消失的问题。
|
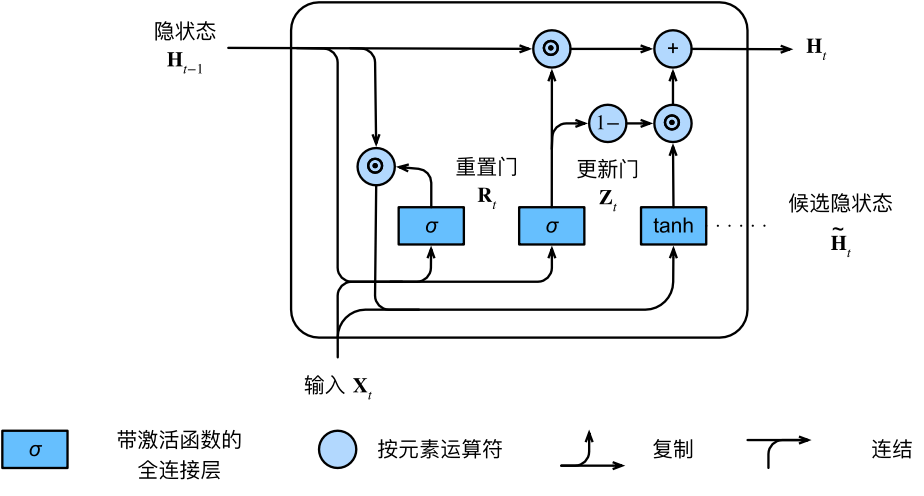
| 3、GRU: GRU主要是对LSTM的简化,组合了遗忘门和输入门到一个单独的“更新门”中,也合并了cell state和hidden state,并且做了一些其他的改变。
|
| 4、深度循环神经网络: 深度循环神经网络的核心即堆叠RNN(改变隐藏层的数量)。
|
| 5、稠密连接网络: 稠密连接网络即深度循环神经网络与残差网络的组合。
|
| 6、双向循环神经网络: 双向循环神经网络即同时关注上下文的RNN(使用来自序列两端的信息来估计输出),但在预测下一个词元时这步的意义有限,且会大大降低计算速度,故双向层的使用在实践中非常少,并且仅仅应用于部分场合。
|
| 7、编码器-解码器结构: 编码器-解码器是深度学习模型的抽象概念,一般认为很多模型均起源/共同表征于这个架构,对RNN即编码器接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。解码器将固定形状的编码状态映射到长度可变的序列。
|
| 8、序列到序列学习: 序列到序列学习即用循环神经网络设计基于“编码器-解码器”架构的序列转换模型。
|

补充:RNN的选择需要和实际需求紧密结合,并不存在某种模型/算法适用于各种数据集、任务、算力资源中。
2. 参考资料
1.8. 循环神经网络 — 动手学深度学习 2.0.0 documentation (d2l.ai)
2.史上最详细循环神经网络讲解(RNN/LSTM/GRU) - 知乎 (zhihu.com)
3.RNN的研究发展过程 - 简书 (jianshu.com)
4.从90年代的SRNN开始,纵览循环神经网络27年的研究进展 - 知乎 (zhihu.com)
5.深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
6.循环神经网络RNN论文解读_循环神经网络论文_纸上得来终觉浅~的博客-CSDN博客
7.RNN详解(Recurrent Neural Network)_bestrivern的博客-CSDN博客
8.LSTM简介以及数学推导(FULL BPTT)_lstm的数学表达_a635661820的博客-CSDN博客
9.循环神经网络 RNN、LSTM、GRU - 简书 (jianshu.com)
10.一份详细的LSTM和GRU图解 - 知乎 (zhihu.com)
11.深度学习:编码器-解码器架构 - 知乎 (zhihu.com)