泛化能力
模型泛化是指机器学习模型对新的、未见过的数据的适应能力。在机器学习中,我们通常会将已有的数据集划分为训练集和测试集,使用训练集训练模型,然后使用测试集来评估模型的性能。模型在训练集上表现得好,并不一定能在测试集或实际应用中表现得好。因此,我们需要保证模型具有良好的泛化能力,才能确保其在实际场景中的效果。
为了提高模型的泛化能力,我们通常需要采取一系列措施,例如增加数据集的大小、特征选择、特征缩放、正则化、交叉验证等。通过这些方法可以减少模型的过拟合,提高对新数据的预测能力。
总之,模型泛化是机器学习中非常重要的一个概念。它直接关系到模型在实际应用中的效果,并且也是评估机器学习算法和模型的重要指标之一。
模型评价与选择
差错分析
机器预测时就好像在投飞镖,越接近靶心则预测越准。可以把差错分为两类:偏差(bias)和方差(variance)。可以用下图来形象描绘:
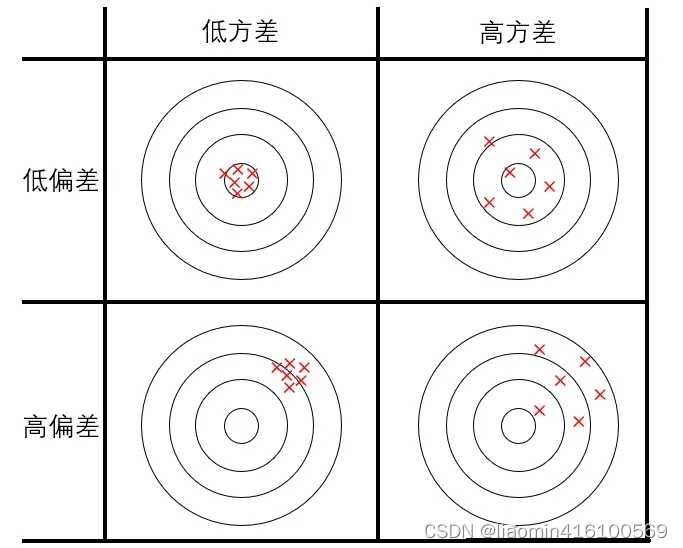
具体到学习任务上,若假设函数取得不够好,拟合结果可能会出现两种问题:
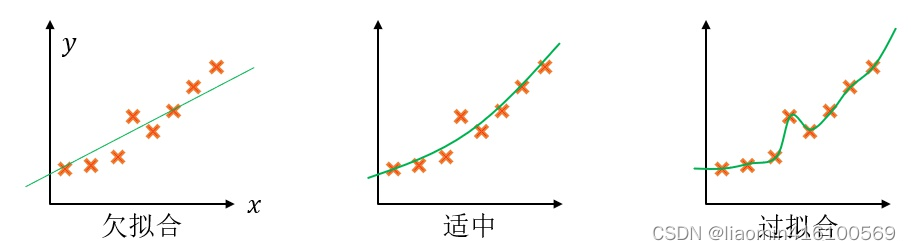
- 欠拟合(underfit):参数过少,假设函数太不自由,过于简单,连样本集都拟合不好,预测时容易偏向一侧,偏差大。
- 过拟合(overfit):参数过多,假设函数太自由,不抗干扰,对样本集拟合得很好,但是假设函数过于畸形,预测时忽左忽右,方差大。
欠拟合与过拟合可用下图来形象地说明:
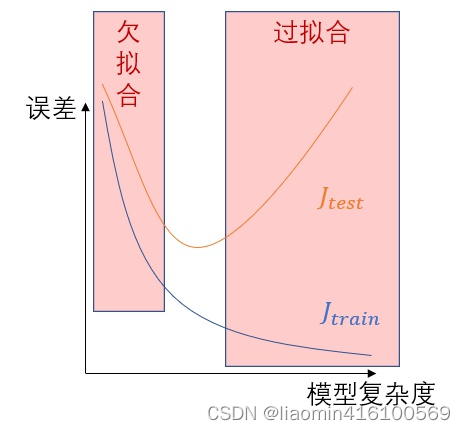
在改变模型的复杂度和训练集大小时,训练集和测试集的误差的函数图(改变模型复杂度时的误差):
改变数据集时的误差
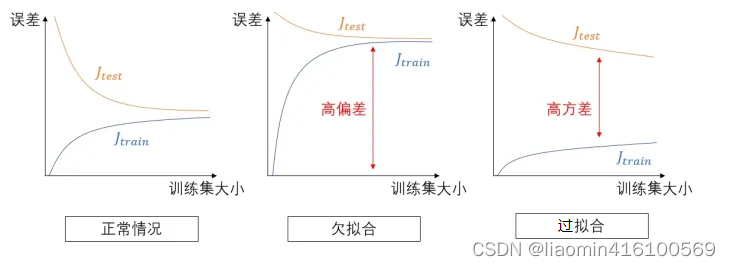
解决欠拟合比较简单,增加参数或增加特征就行了,麻烦的是过拟合。
解决过拟合的办法有:
- 减少该模型的参数,或者改为更简单的模型。
- 正则化。
- 增大训练集,减少噪音成分等。
泛化误差
θ \theta θ代表超参数, J 未知 J_{未知} J未知 { \{ { θ \theta θ } \} }代表训练出模型 θ \theta θ参数后对于未知数据的误差,越小泛化能力越强, J t e s t J_{test} Jtest { \{ { θ \theta θ } \} }代表模型对测试机的误差,越小泛化能力越强。
我们希望我们的模型有泛化能力,即面对未训练到的、未知的情景也能发挥作用。泛化误差(generalization error)指的是模型在处理未知数据时的代价函数:
J
未知
J_{未知}
J未知
{
\{
{
θ
\theta
θ
}
\}
}
的值,它可以量化模型的泛化能力。
然而,我们训练和测试模型时,并没有未知的数据。我们会根据模型在训练集上的表现改进模型,再进行训练与测试。但在测试集上最终算出的:
J
t
e
s
t
J_{test}
Jtest
{
\{
{
θ
\theta
θ
}
\}
}已经对测试集进行优化了,它明显对泛化误差的估计过于乐观,会偏低。也就是说,把模型放在实际应用中的效果,会比预想的差很多。
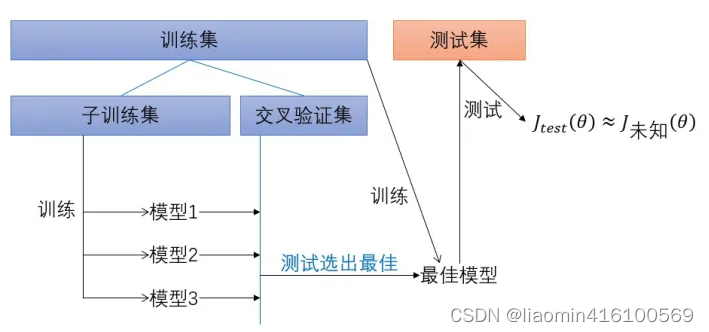
为了解决这个问题,人们提出了交叉验证(cross validation)的方法
交叉验证
交叉验证的步骤
- 把训练集进一步分为子训练集与交叉验证集。把测试集藏好,先不用它。(测试集是对未知数据的模拟)
- 使用各种不同的模型在子训练集上训练,并测出各模型在交叉验证集上的 J c v J_{cv} Jcv { \{ { θ \theta θ } \} }
- 选择 J c v J_{cv} Jcv { \{ { θ \theta θ } \} }最小的模型,认为它最佳。把子训练集和交叉验证集合并为训练集,训练出最终的模型。
交叉验证的改进方法是K折(K-fold)交叉验证(图6):把训练集分为许多小块,每一种情况取其中一小块作为交叉验证集,其余部分合并作为子训练集,求出该模型的
J
c
v
J_{cv}
Jcv
{
\{
{
θ
\theta
θ
}
\}
},把每一种情况算遍,求出该模型的平均
J
c
v
J_{cv}
Jcv
{
\{
{
θ
\theta
θ
}
\}
},认为平均最小的模型为最佳模型。最终仍然是用整个训练集训练最佳模型,在测试集上估计泛化误差。
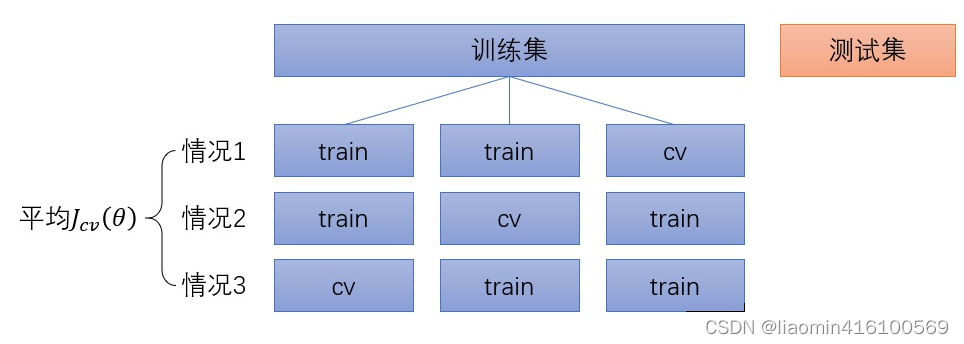
K折交叉验证的优点是进一步确保交叉验证集没有特殊性,对泛化误差的估计更为准确。
KFold拆分
在sklearn中,我们可以使用KFold类来实现k折交叉验证。
在进行k折交叉验证时,KFold对象会将原始数据集随机分成k个近似大小的子集,每个子集称为“折”(fold)。,比如10个元素数组,k=5的话会拆分为5个数据集,每个折数据集就是2个,5个折数据集都会被作为一次测试机,所以会有5个组合。
from sklearn.model_selection import KFold
import numpy as np
# 创建一个包含10个元素的数组作为样本数据
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 定义K值
k = 5
# 创建KFold对象,并指定n_splits参数为K
kf = KFold(n_splits=k)
# 遍历KFold对象中的每一组训练集和测试集
for train_index, test_index in kf.split(X):
print("train_index:", train_index, "test_index:", test_index)
输出结果如下:
train_index: [2 3 4 5 6 7 8 9] test_index: [0 1]
train_index: [0 1 4 5 6 7 8 9] test_index: [2 3]
train_index: [0 1 2 3 6 7 8 9] test_index: [4 5]
train_index: [0 1 2 3 4 5 8 9] test_index: [6 7]
train_index: [0 1 2 3 4 5 6 7] test_index: [8 9]
fold的值也就决定了最后使用cv数据集验证的得分个数。
cross_val_score实战
cross_val_score函数是Scikit-learn库中用于评估模型性能的快速方法之一。它计算基于交叉验证的模型评分,并返回每个fold的测试性能得分。与KFold不同,cross_val_score不需要显示拆分数据集。您只需提供模型和数据集即可进行评估,该函数将自动处理交叉验证过程,从而使代码更加简洁和易于理解。
数据集和模型
load_digits 是 Scikit-learn 库中的一个函数,用于加载手写数字图像数据集。这个数据集包含 8x8 像素大小的 1797 张手写数字图像,每张图像都对应一个 0 到 9 的数字标签。
from sklearn.datasets import load_digits
digits = load_digits()
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=1, ncols=5, figsize=(10, 3))
for i, ax in enumerate(axes):
ax.imshow(digits.images[i], cmap='gray')
ax.set_title(digits.target[i])
plt.show()

在Scikit-learn库中的KNeighborsClassifier实现了k近邻算法,其中的超参数k和p影响着模型的性能。
- n_neighbors(即k):指定要考虑的最近邻居的个数。默认情况下,它为5,表示预测一个新样本时将使用数据集中距离其最近的5个数据点的标签,5个中最多的那个标签就是当前数据的标签。
- p:用于计算距离的指标。默认情况下,使用Minkowski距离,p 为2,表示使用欧几里得距离。不同的 p 值对应不同的距离度量方式,例如,p=1 表示曼哈顿距离,p=3 可以使用一种更为复杂的曼哈顿距离度量方式。
使用数据集和测试集获取最佳k,p
将数据集拆分为训练集和测试集,然后k从1到11,p从1到6,测试训练集的得分,得到最佳的k和p。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=666)
best_score, best_p, best_k = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
knn_clf.fit(x_train, y_train)
score = knn_clf.score(x_test, y_test)
if score > best_score:
best_score, best_p, best_k = score, p, k
print("Best K=", best_k)
print("Best P=", best_p)
print("Best score=", best_score)
输出结果:
Best K= 3
Best P= 4
Best score= 0.9860917941585535
使用交叉验证获取最佳k,p
cross_val_score函数默认使用的交叉验证方法是3-Fold交叉验证,即将数据集分为3个相等的部分,其中2个部分用于训练,1个部分用于测试。在每个fold迭代中,使用测试集得到性能度量得分,然后将所有fold的结果平均并返回。
需要注意的是,cross_val_score还有一个名为cv的参数,可以用来指定交叉验证的折叠数量,即k值。例如,cv=5表示5-Fold交叉验证,将数据集拆分为5个相等的部分,其中4个部分用于训练,1个部分用于测试。对于分类问题和回归问题,通常选择 3, 5 或 10 折交叉验证。通常,交叉验证的折叠数量越多,模型的评估结果越可靠,但计算成本也会增加。
总之,在没有显式设置cv参数时,默认情况下cross_val_score使用的是3-Fold交叉验证,即默认的k值是3。
best_score, best_p, best_k = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
scores = cross_val_score(knn_clf, x_train, y_train)
score = np.mean(scores)
if score > best_score:
best_score, best_p, best_k = score, p, k
print("Best K=", best_k)
print("Best P=", best_p)
print("Best score=", best_score)
输出
Best K= 2
Best P= 2
Best score= 0.9823599874006478
对比第一种情况,我们发现得到的最优超参数是不一样的,虽然score会稍微低一些,但是一般第二种情况更加可信。但是这个score只是说明这组参数最优,并不是指的是模型对于测试集的准确率,因此接下来看一下准确率。
best_knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=2, p=2)
best_knn_clf.fit(x_train, y_train)
best_knn_clf.score(x_test, y_test)
输出结果:0.980528511821975,这才是模型的准确度。
正则化(regularization)
原理
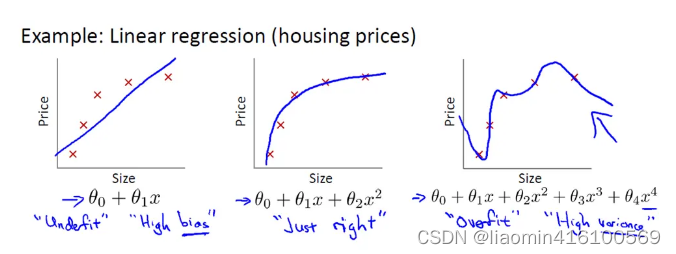
想要理解什么是正则化,首先我们先来了解上图的方程式。当训练的特征和数据很少时,往往会造成欠拟合的情况,对应的是左边的坐标;而我们想要达到的目的往往是中间的坐标,适当的特征和数据用来训练;但往往现实生活中影响结果的因素是很多的,也就是说会有很多个特征值,所以训练模型的时候往往会造成过拟合的情况,如上图所示。
以图中的公式为例,往往我们得到的模型是:
θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 \theta_{0}+\theta_{1}x+\theta_{2}x^2+\theta_{3}x^3+\theta_{4}x^4 θ0+θ1x+θ2x2+θ3x3+θ4x4
为了能够得到中间坐标的图形,肯定是希望θ3和θ4越小越好,因为这两项越小就越接近于0,就可以得到中间的图形了。
对于损失函数:
(
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
]
)
({1\over2m}[\sum_{i=1}^{m}{(h_\theta(x^i)-y^i)^2}])
(2m1[i=1∑m(hθ(xi)−yi)2])
在线性回归中,就是通过最小二乘法计算损失函数的最小值
m
i
n
(
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
]
)
min({1\over2m}[\sum_{i=1}^{m}{(h_\theta(x^i)-y^i)^2}])
min(2m1[i=1∑m(hθ(xi)−yi)2])
而计算出每个特征的
θ
\theta
θ值。
如果损失函数加上一个数求最小值,那个这个数肯定越趋近于0,最小是肯定越小
那么这个值加什么了,我们是希望
θ
\theta
θ趋近于0对于损失函数的影响越小越好,也就是减少特征。
把公式通用化得:
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
]
)
+
λ
∑
j
=
1
n
θ
j
2
{1\over2m}[\sum_{i=1}^{m}{(h_\theta(x^i)-y^i)^2}])+\lambda\sum_{j=1}^{n}\theta_{j}^2
2m1[i=1∑m(hθ(xi)−yi)2])+λj=1∑nθj2
为了损失函数求得最小值,使θ值趋近于0,这就达到了我们的目的。
相当于在原始损失函数中加上了一个惩罚项(λ项)
这就是防止过拟合的一个方法,通常叫做L2正则化,也叫作岭回归。
我们可以认为加入L2正则项后,估计参数长度变短了,这在数学上被称为特征缩减(shrinkage)。
shrinkage方法介绍:指训练求解参数过程中考虑到系数的大小,通过设置惩罚系数,使得影响较小的特征的系数衰减到0,只保留重要特征的从而减少模型复杂度进而达到规避过拟合的目的。常用的shinkage的方法有Lasso(L1正则化)和岭回归(L2正则化)等。
Lasso(L1正则化)公式:
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
]
+
λ
∑
j
=
1
n
∣
θ
j
∣
{1\over2m}[\sum_{i=1}^{m}{(h_\theta(x^i)-y^i)^2}]+\lambda\sum_{j=1}^{n}|\theta_{j}|
2m1[i=1∑m(hθ(xi)−yi)2]+λj=1∑n∣θj∣
上面的逻辑可能看出是拉格朗日乘子法的应用
采用shrinkage方法的主要目的包括两个:
- 一方面因为模型可能考虑到很多没必要的特征,这些特征对于模型来说就是噪声,shrinkage可以通过消除噪声从而减少模型复杂度;
- 另一方面模型特征存在多重共线性(变量之间相互关联)的话可能导致模型多解,而多解模型的一个解往往不能反映模型的真实情况,shrinkage可以消除关联的特征提高模型稳定性。
对应图形
我们可以简化L2正则化的方程:
J
=
J
0
+
λ
∑
w
w
2
J=J_{0}+\lambda\sum_ww^2
J=J0+λ∑ww2
J0表示原始的损失函数,咱们假设正则化项为:
假设是2个特征w有两个值w1和w2
L
=
λ
(
w
1
2
+
w
2
2
)
L=\lambda(w_{1}^2+w_{2}^2)
L=λ(w12+w22)
我们不妨回忆一下圆形的方程:
(
x
−
a
)
2
+
(
y
−
b
)
2
=
r
2
(x-a)^2+(y-b)^2=r^2
(x−a)2+(y−b)2=r2
其中(a,b)为圆心坐标,r为半径。那么经过坐标原点的单位元可以写成:
正和L2正则化项一样,同时,机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。
此时我们的任务变成在L约束下求出J0取最小值的解(拉格朗日乘子法)。
求解J0的过程可以画出等值线。同时L2正则化的函数L也可以在w1w2的二维平面上画出来。如下图:
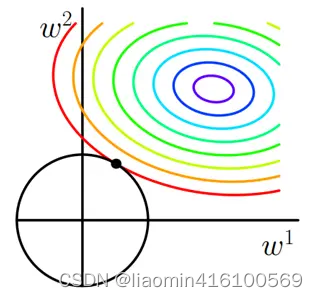
L表示为图中的黑色圆形,随着梯度下降法的不断逼近,与圆第一次产生交点,而这个交点很难出现在坐标轴上。
这就说明了L2正则化不容易得到稀疏矩阵,同时为了求出损失函数的最小值,使得w1和w2无限接近于0,达到防止过拟合的问题。
岭回归(Ridege Regression)
就是L2正则化
测试用例:
import numpy as np
import matplotlib.pyplot as plt
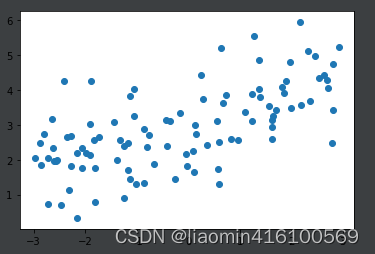
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3 + np.random.normal(0, 1, size=100)
plt.scatter(x, y)
plt.show()
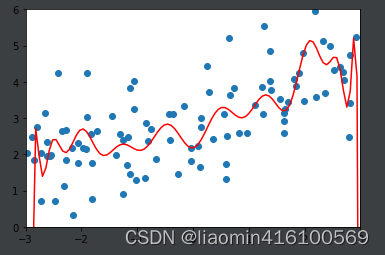
使用20项式来进行拟合(模拟过拟合)
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def PolynomiaRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scale', StandardScaler()),
('lin_reg', LinearRegression()),
])
np.random.seed(666)
x_train, x_test, y_train, y_test = train_test_split(X, y)
poly_reg = PolynomiaRegression(degree=20)
poly_reg.fit(x_train, y_train)
y_poly_predict = poly_reg.predict(x_test)
print(mean_squared_error(y_test, y_poly_predict))
# 167.9401085999025
import matplotlib.pyplot as plt
x_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = poly_reg.predict(x_plot)
plt.scatter(x, y)
plt.plot(x_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
封装一个函数生成测试集并测试模型
def plot_model(model):
x_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(x_plot)
plt.scatter(x, y)
plt.plot(x_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
使用岭回归:
from sklearn.linear_model import Ridge
def RidgeRegression(degree, alpha):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scale', StandardScaler()),
('lin_reg', Ridge(alpha=alpha)),
])
ridege1_reg = RidgeRegression(20, alpha=0.0001)
ridege1_reg.fit(x_train, y_train)
y1_predict = ridege1_reg.predict(x_test)
print(mean_squared_error(y_test, y1_predict))
# 跟之前的136.相比小了很多
plot_model(ridege1_reg)
输出误差:1.3233492754136291
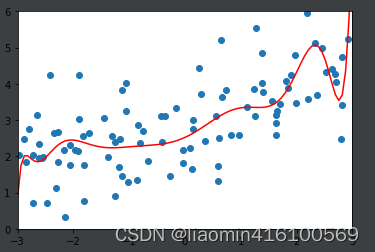
调整
α
\alpha
α=1
ridege2_reg = RidgeRegression(20, alpha=1)
ridege2_reg.fit(x_train, y_train)
y2_predict = ridege2_reg.predict(x_test)
print(mean_squared_error(y_test, y2_predict))
plot_model(ridege2_reg)
输出:1.1888759304218461

调整
α
\alpha
α=100
ridege2_reg = RidgeRegression(20, alpha=100)
ridege2_reg.fit(x_train, y_train)
y2_predict = ridege2_reg.predict(x_test)
print(mean_squared_error(y_test, y2_predict))
# 1.3196456113086197
plot_model(ridege2_reg)
输出:1.3196456113086197
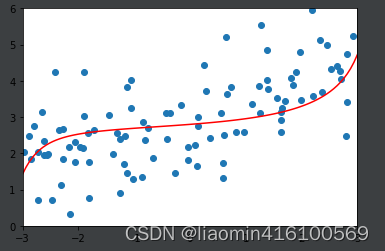
调整
α
\alpha
α=1000000
ridege2_reg = RidgeRegression(20, alpha=1000000)
ridege2_reg.fit(x_train, y_train)
y2_predict = ridege2_reg.predict(x_test)
print(mean_squared_error(y_test, y2_predict))
# 1.8404103153255003
plot_model(ridege2_reg)
输出:1.8404103153255003
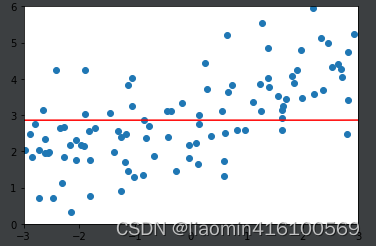
通过上面几种alpha的取值可以看出我们可以在1-100进行更加细致的搜索,找到最合适的一条相对比较平滑的曲线去拟合。这就是L2正则。
LASSO Regularization
封装
#%%
import numpy as np
import matplotlib.pyplot as plt
from skimage.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3 + np.random.normal(0, 1, size=100)
np.random.seed(666)
x_train, x_test, y_train, y_test = train_test_split(X, y)
plt.scatter(x, y)
plt.show()
#%%
from sklearn.linear_model import Lasso
def plot_model(model):
x_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(x_plot)
plt.scatter(x, y)
plt.plot(x_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
def LassoRegression(degree, alpha):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scale', StandardScaler()),
('lin_reg', Lasso(alpha=alpha)),
])
def TestRegression(degree, alpha):
lasso1_reg = LassoRegression(degree, alpha)
#这里相比Ridge的alpha小了很多,这是因为在Ridge中是平方项
lasso1_reg.fit(x_train, y_train)
y1_predict = lasso1_reg.predict(x_test)
print(mean_squared_error(y_test, y1_predict))
# 1.149608084325997
plot_model(lasso1_reg)
使用lasso回归:
调整
α
\alpha
α=0.01
TestRegression(20,0.01)
输出:1.149608084325997
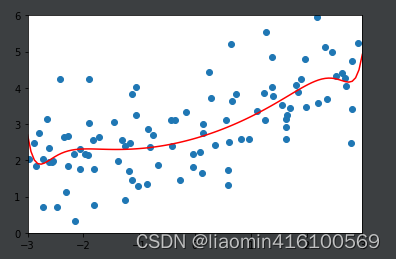
调整 α \alpha α=0.1
TestRegression(20,0.1)
输出:1.1213911351818648
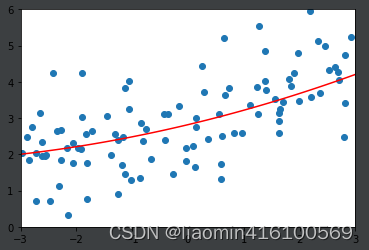
调整
α
\alpha
α=1
TestRegression(20,1)
输出:1.8408939659515595
解释Ridge和LASSO
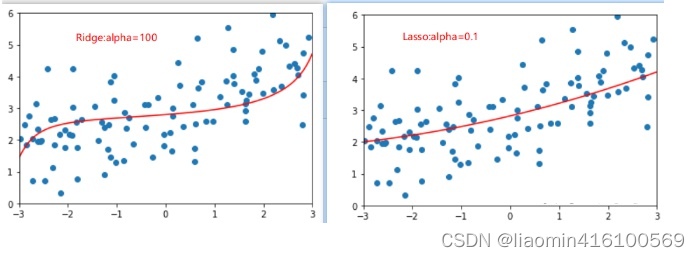
通过这两幅图进行对比发现,LASSO拟合的模型更倾向于是一条直线,而Ridge拟合的模型更趋向与一条曲线。这是因为两个正则的本质不同,Ridge是趋向于使所有
的加和尽可能的小,而Lasso则是趋向于使得一部分
的值变为0,因此可作为特征选择用,这也是为什么叫Selection Operation的原因。