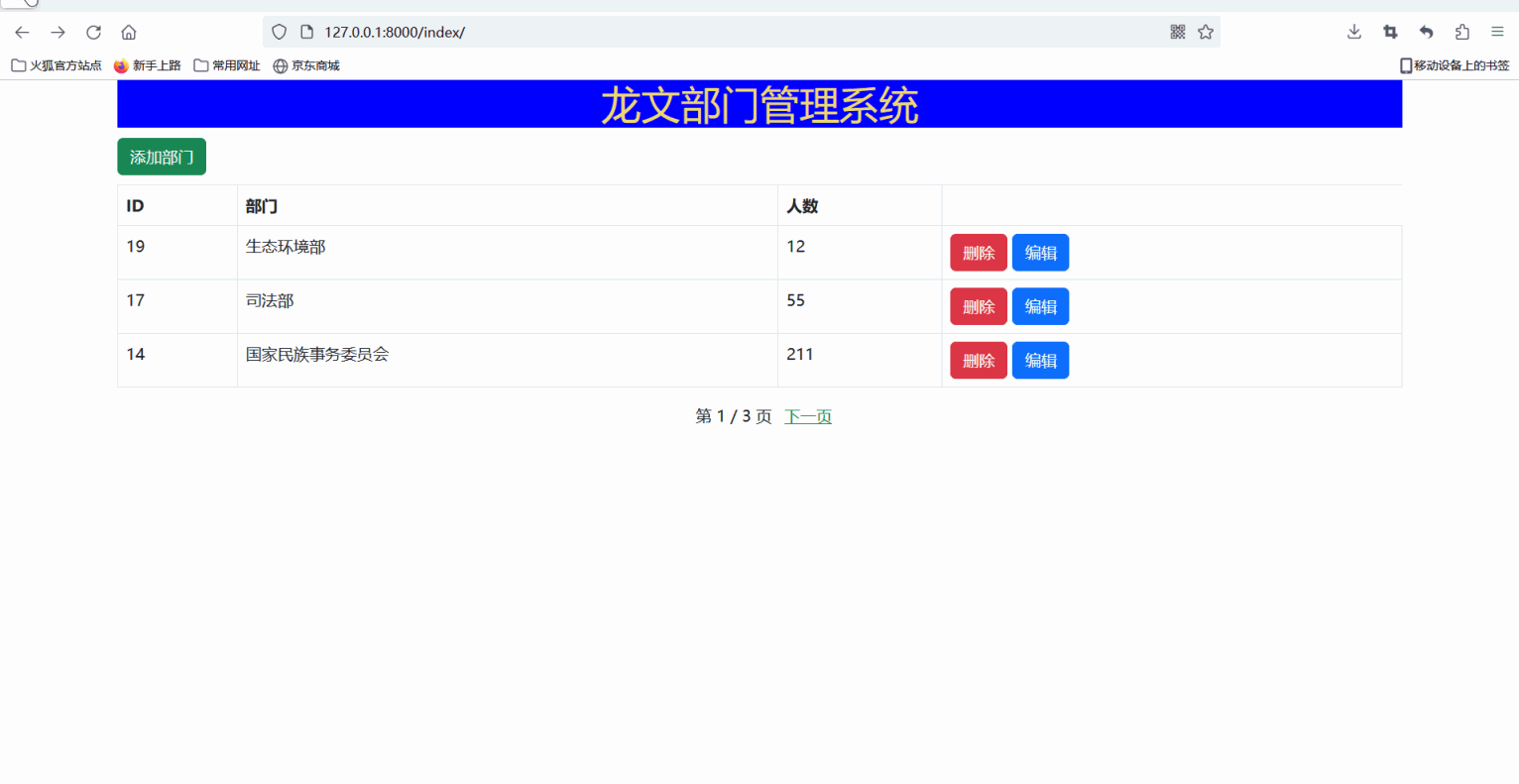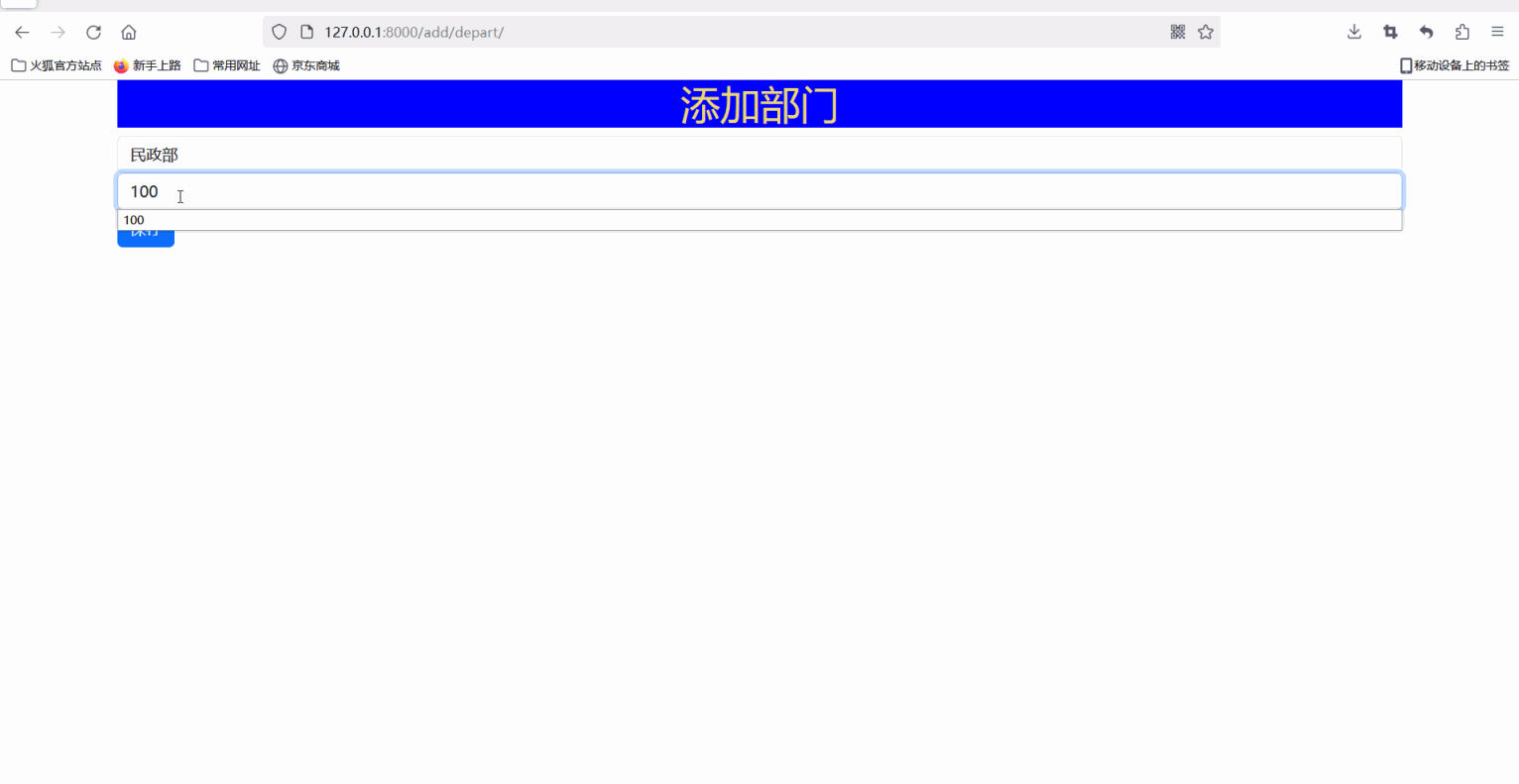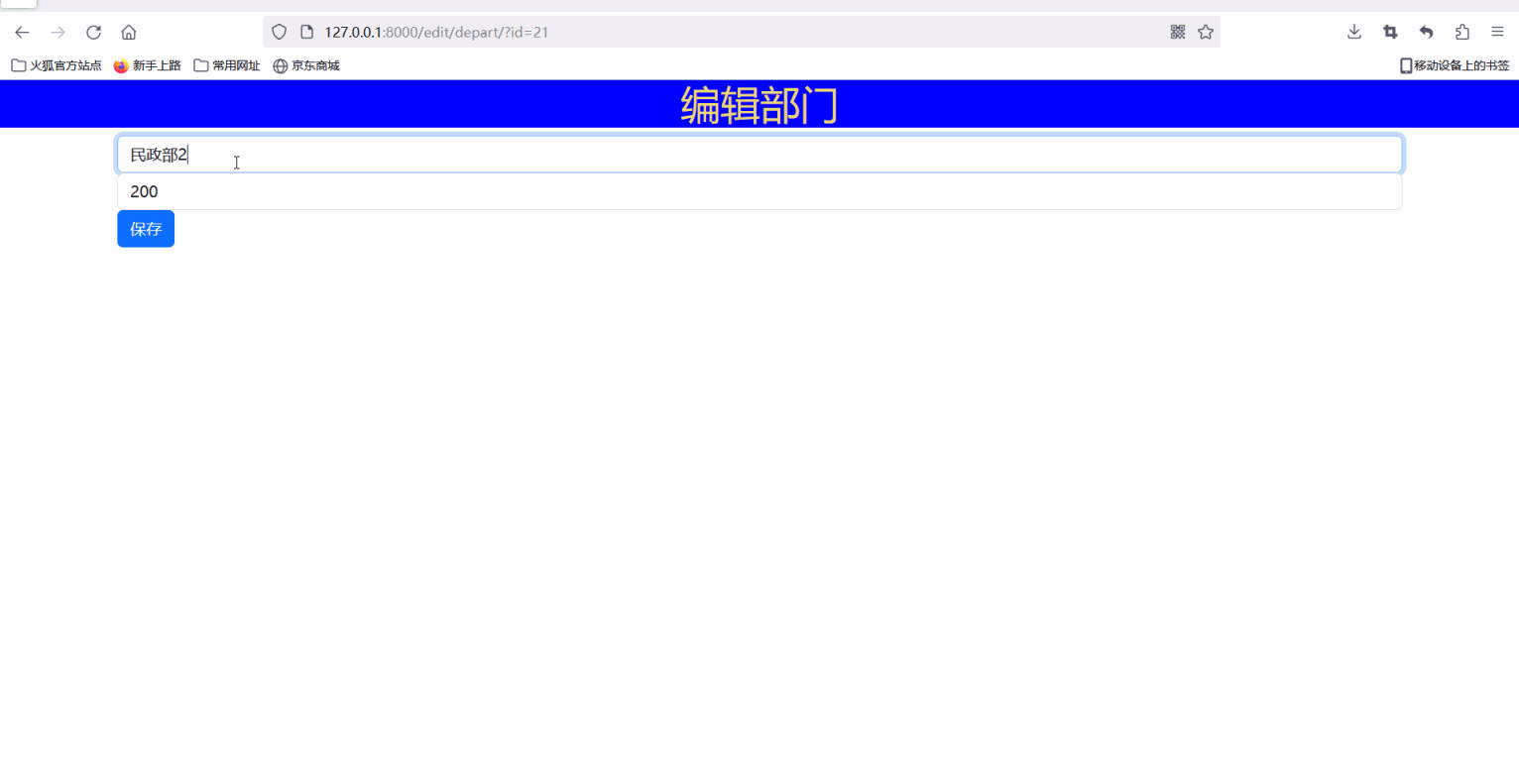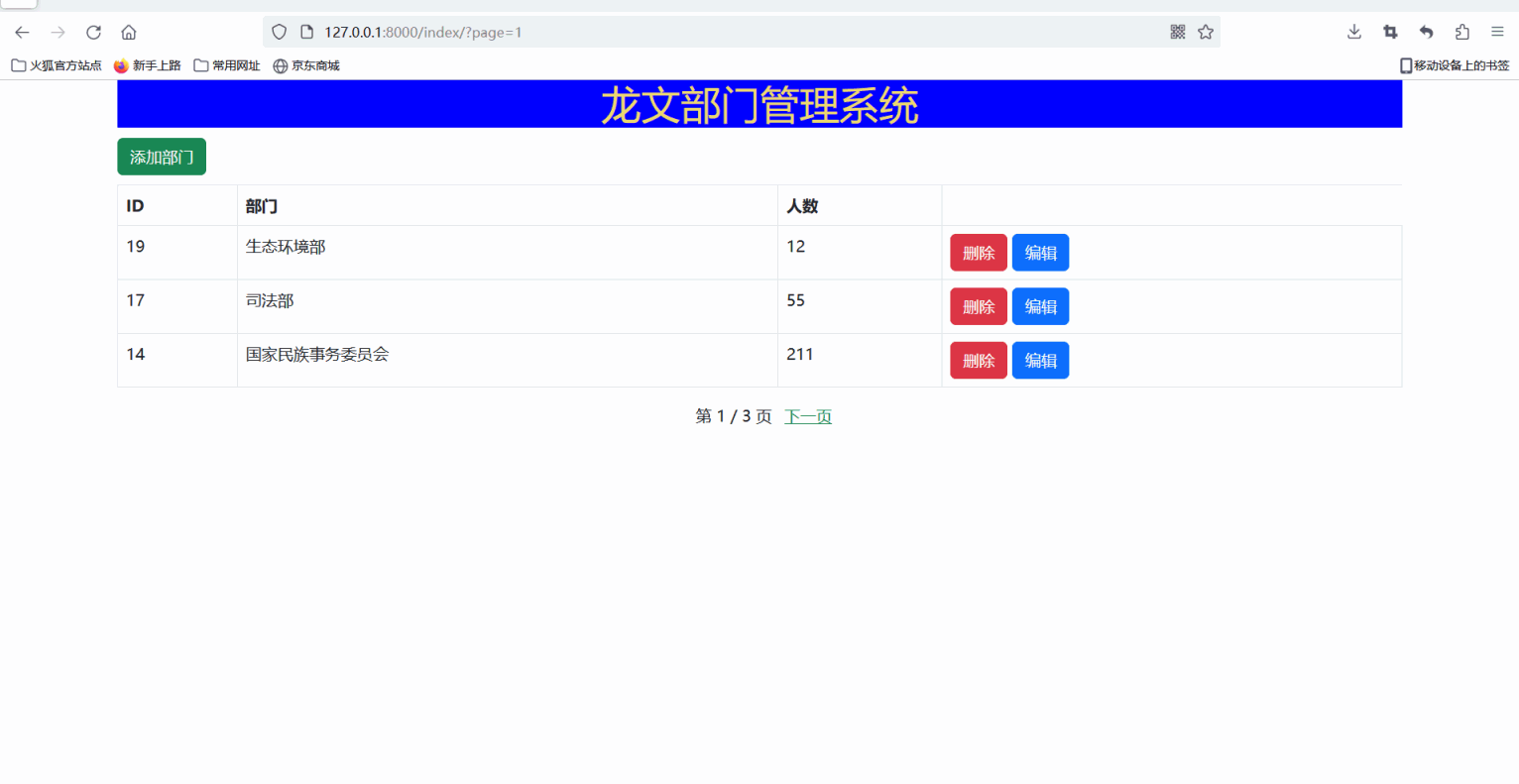
我们知道很早之前java8对于之前的版本更新了许多 新的支持,比如lamda函数式接口的支持,支持更多函数式接口的使用,对链表,数组,队列,集合等实现了Collectio接口的数据结构提供了StreamSupport.stream()支持转换为Stream<T> 的方法。

基于它的原类型返回一个集合流序列:例如最简单的链表转Stream的方式:
List<String> list = new LinkedList<>();
Stream<String> stream = list.stream();如下就是Stream接口的方法:
Stream<T> filter(Predicate<? super T> predicate);
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper);
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper);
Stream<T> distinct();
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> peek(Consumer<? super T> action);
Stream<T> limit(long maxSize);
Stream<T> skip(long n);
void forEach(Consumer<? super T> action);
void forEachOrdered(Consumer<? super T> action);
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
long count();
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
Optional<T> findFirst();
Optional<T> findAny();
剩下的方法就是java8之后带来的新特性 接口中可以写方法体内容了(之前仅支持接口含有抽象方法)通过字面意思,我们可以大致的了解熟悉的接口方法:
1、filter(顺带的思考一下mvc过滤器的实现原理与方法):这里的filter可不是过滤的意思,更像是查询,在filter语句里可以采用lamda的方式书写你的查询条件,满足条件的元素将会被留在流中,不满足条件的将会被过滤掉。
示例:
查询出列表中元素的jobName不为null的元素链表(一定要注意其是查询不是屏蔽!否则在开发中极其容易出现npe)
2、map(图):这里的图就是将你给定的条件返回一个临时的流,这个流中将会仅仅包含你给定的方法获取的数据(返回的流支持流接口提供的全部接口方法):

这里我们直接将jobName单独组成一个流,方便后续只用这些数据对业务进行输入。
3、之后的一系列数据类型转换map的流操作大家自己去实验。
4、distinct(去重,思考数据库对查询的结果进行去重的方法):这里的去重也很简单,仅仅是对结果进行去重。

5、sorted(排序,这里也联想一下数据库排序的方法):这里的排序有两种实现,第一种是你的元素类型实现了可比较,如果不可比较就需要你指定排序条件:

6、peek(流操作过程的端点监视方法,类似于debug但是不会停止流):其实就是动态的在流操作进行时不使其停止而获取每一个过程流的变化:

7、limit(截断,类似于数据库的limit限制结果的数量):此接口可以规定返回数据的数量:

基本先说这么些。