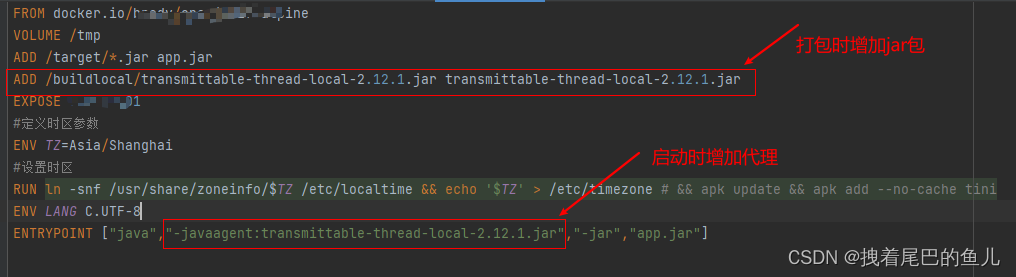
原文:OpenCV with Python Blueprints
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、学习识别交通标志
本章的目的是训练一个多类分类器以识别交通标志。 在本章中,我们将介绍以下主题:
- 监督学习概念
- 德国交通标志识别基准(GTSRB)数据集特征提取
- 支持向量机(SVM)
先前我们已经研究了如何通过关键点和特征来描述对象,以及如何在同一物理对象的两个不同图像中找到对应点。 但是,在识别现实环境中的对象并将其分配给概念类别时,我们以前的方法相当有限。 例如,在第 2 章“使用 Kinect 深度传感器进行手势识别”,图像中所需的对象是手,必须将屏幕很好地放置在手掌的中央。 如果我们可以取消这些限制,那岂不是很好吗?
在本章中,我们将训练支持向量机(SVM)来识别各种交通标志。 尽管 SVM 是二分类器(也就是说,它们最多可用于学习两类:正负项,动物和非动物等),但它们可以扩展以用于多类分类。 为了获得良好的分类表现,我们将探索许多颜色空间以及定向梯度直方图(HOG)特征。 然后,将基于准确率,精度和召回来判断分类表现。 以下各节将详细解释所有这些术语。
为了获得这样的多类分类器,我们需要执行以下步骤:
- 预处理数据集:我们需要一种加载数据集,提取兴趣区域并将数据拆分为适当的训练和测试集的方法。
- 提取特征:可能是原始像素值不是数据的最有信息的表示。 我们需要一种从数据中提取有意义的特征的方法,例如基于不同颜色空间和 HOG 的特征。
- 训练分类器:我们将以两种不同的方式对训练数据进行多分类器训练:一对多策略(我们为每个类别训练单个 SVM,该类别的样本为正面样本,所有其他样本为负例),以及一对一策略(我们为每对类别训练一个 SVM) ,其中第一类样本为正面样本,第二类样本为负面样本)。
- 为分类器评分:我们将通过计算不同的表现指标(例如准确率,准确率和召回率)来评估经过训练的集成分类器的质量。
最终结果将是一个整体分类器,在对 10 个不同的路牌类别进行分类时,其得分接近完美:
规划应用
最终的应用将解析数据集,训练集成分类器,评估其分类表现,并可视化结果。 这将需要以下组件:
main:用于启动应用的main函数例程(在chapter6.py中)。datasets.gtsrb:用于解析德国交通标志识别基准(GTSRB)数据集的脚本。 该脚本包含以下函数:load_data:用于加载 GTSRB 数据集,提取所选特征并将数据分为训练集和测试集的函数。_extract_features:load_data调用此函数以从数据集中提取所选特征。
classifiers.Classifier:一个抽象基类,为所有分类程序定义公共接口。classifiers.MultiClassSVM:使用以下公共方法为多类分类实现 SVM 集成的类:MultiClassSVM.fit:一种用于将 SVM 的集合适合训练数据的方法。 它以训练数据矩阵作为输入,其中每一行是训练样本,列中包含特征值和标签向量。MultiClassSVM.evaluate:一种用于通过在训练后将 SVM 应用于某些测试数据来评估 SVM 整体的方法。 它以测试数据矩阵作为输入,其中每一行都是测试样本,各列包含特征值和标签向量。 该函数返回三种不同的表现指标:准确率,准确率和召回率。
在以下各节中,我们将详细讨论这些步骤。
监督学习
机器学习的重要子领域是监督学习。 在监督学习中,我们尝试从一组标记的训练数据中学习; 也就是说,每个数据样本都具有所需的目标值或真实的输出值。 这些目标值可以对应于函数的连续输出(例如y = sin(x)中的y),也可以对应于更抽象和离散的类别(例如猫或狗) 。 如果处理连续输出,则该过程称为回归;如果处理离散输出,则该过程称为分类。 根据房屋大小预测房价是回归的一个例子。 从鱼的颜色预测物种将是分类。 在本章中,我们将重点介绍使用 SVM 进行分类。
训练过程
例如,我们可能想学习猫和狗的模样。 为了使它成为有监督的学习任务,我们将必须创建一个猫和狗的图片数据库(也称为训练集),并在数据库中为每张图片加上相应的标签标注:猫或狗。 该程序的任务(在文献中,通常称为学习器)将为这些图片中的每张图片推断正确的标签(即,针对每张图片,预测是否是猫或狗的照片)。 基于这些预测,我们得出学习器表现良好的分数。 分数然后用于更改学习器的参数,以便随着时间的推移提高分数。
下图概述了此过程:
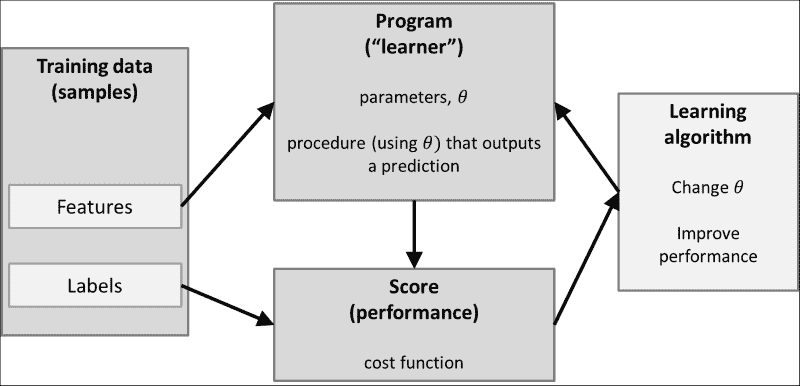
训练数据由一组特征表示。 对于现实生活中的分类任务,这些特征很少是图像的原始像素值,因为它们往往无法很好地表示数据。 通常,寻找最能描述数据的特征的过程是整个学习任务的重要组成部分(也称为特征选择或特征工程)。 这就是为什么在考虑建立分类器之前深入研究正在使用的训练集的统计数据和外观始终是一个好主意的原因。
您可能已经知道,这里有整个学习器,成本函数和学习算法的动物园。 这些构成了学习过程的核心。 学习器(例如,线性分类器,支持向量机或决策树)定义如何将输入特征转换为得分或成本函数(例如,均方误差,铰链损失或熵),而学习算法 (例如,神经网络的梯度下降和反向传播)定义了学习器的参数如何随时间变化。
分类任务中的训练过程也可以认为是找到合适的决策边界,这是一条将训练集最好地分为两个子集的线,每个子集一个。 例如,考虑训练样本仅具有两个特征(x和y值)和相应的类别标签(正+或负-)。 在训练过程的开始,分类器尝试画一条线以将所有正词与所有负词分开。 随着训练的进行,分类器看到越来越多的数据样本。 这些用于更新决策边界,如下图所示:
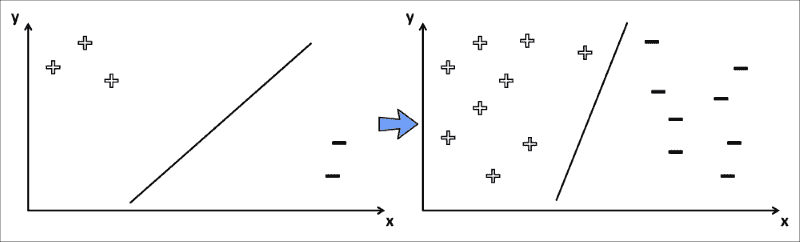
与相比,此 SVM 试图在高维空间中找到最佳决策边界,因此决策边界可能比直线更复杂。
测试过程
为了使训练有素的分类器具有任何实际价值,我们需要知道将其应用于从未见过的数据样本时的表现(也称为泛化)。 继续前面显示的示例,我们想知道分类器在向其提供先前看不见的猫或狗的图片时预测的类别。
一般而言,我们想知道属于哪个类,下图中的符号对应于我们在训练阶段中学到的决策边界:
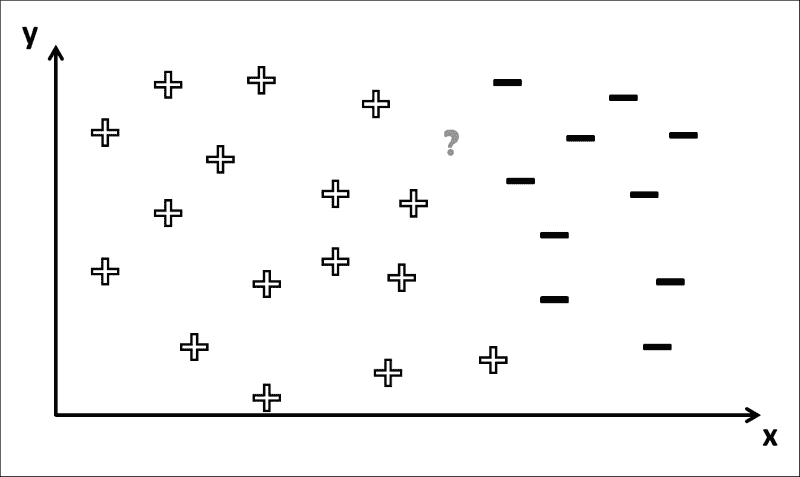
您可以看到为什么这是一个棘手的问题。 如果问号的位置位于左侧,则可以确定相应的类别标签为+。 但是,在这种情况下,有几种方法可以绘制决策边界,以使所有+符号位于其左侧,而所有-符号均位于其右侧 ,如下图所示:
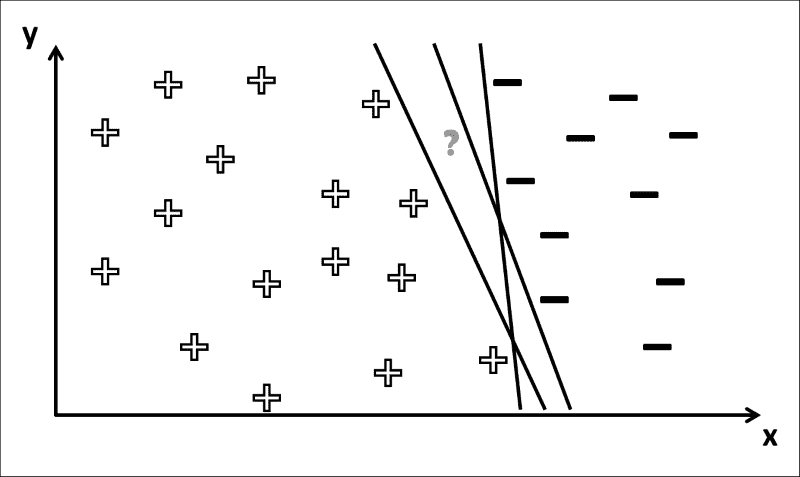
因此,?的标签取决于训练过程中得出的确切决策边界。 如果上图中的?符号实际上是-,然后只有一个决策边界(最左边)会得到正确的答案。 一个常见的问题是,训练导致决策边界在训练集上工作得“太好”(也称为过拟合),但是在应用于看不见的数据时会犯很多错误。 在那种情况下,学习器很可能在决策边界上烙印了特定于训练集的细节,而不是揭示关于数据的一般属性,这对于看不见的数据也可能适用。
注意
减少过拟合影响的常用技术称为正则化。
长话短说,问题总是回到寻找最佳分割的边界上,不仅是训练,还包括测试集。 这就是为什么分类器最重要的指标是其泛化表现(即,如何分类训练阶段未看到的数据)。
分类器基类
从前面的内容中获得的见解,您现在可以编写一个适用于所有可能分类器的简单基类。 您可以将此类视为适用于我们尚未设计的所有分类器的蓝图或秘籍(我们使用第 1 章,“过滤器的乐趣”)。 为了在 Python 中创建抽象基类(ABC),我们需要包含ABCMeta模块:*
from abc import ABCMeta
这使我们可以将类注册为metaclass:
class Classifier:
"""Abstract base class for all classifiers"""
__metaclass__ = ABCMeta
回想一下,抽象类至少具有一个抽象方法。 抽象方法类似于指定某种方法必须存在,但我们尚不确定它的外观。 我们现在知道,分类器以其最通用的形式应该包含一种训练方法,其中模型适合训练数据,以及测试方法,其中训练后的模型通过将其应用于测试数据进行评估:
@abstractmethod
def fit(self, X_train, y_train):
pass
@abstractmethod
def evaluate(self, X_test, y_test, visualize=False):
pass
此处,X_train和X_test分别对应于训练和测试数据,其中每一行代表一个样本,每一列是该样本的特征值。 训练和测试标签分别作为y_train和y_test向量传递。
GTSRB 数据集
为了将分类器应用于交通标志识别,我们需要一个合适的数据集。 一个很好的选择可能是德国交通标志识别基准(GTSRB),其中包含超过 50,000 个属于 40 多个类别的交通标志图像。 这是一个极富挑战性的数据集,专业人士在国际神经网络联合会议(IJCNN) 2011 期间进行了分类挑战。 从这个页面获得。
GTSRB 数据集非常大,有条理,开放源代码并带有注释,因此非常适合我们的目的。 但是,出于本书的目的,我们将分类限制为总共 10 个类别的数据样本。
尽管实际交通标志不一定在每个图像中都是正方形或居中的,但数据集附带了一个标注文件,该文件指定每个标志的边界框。
在进行任何形式的机器学习之前,一个好主意通常是对数据集,其质量和挑战有所了解。 如果数据集的所有示例都存储在列表X中,则可以使用以下脚本绘制一些示例,我们从中选择固定数量(sample_size)的随机索引(sample_idx)并在单独的子图中显示每个示例(X[sample_idx[sp-1]]):
sample_size = 15
sample_idx = np.random.randint(len(X), size=sample_size)
sp = 1
for r in xrange(3):
for c in xrange(5):
ax = plt.subplot(3,5,sp)
sample = X[sample_idx[sp-1]]
ax.imshow(sample.reshape((32,32)), cmap=cm.Greys_r)
ax.axis('off')
sp += 1
plt.show()
以下屏幕截图显示了此数据集的一些示例:

即使从这个小的数据样本中,也很明显这对于任何种类的分类器来说都是一个挑战性的数据集。 标志的外观会根据视角(方向),观看距离(模糊)和照明条件(阴影和亮点)而发生巨大变化。 对于其中一些标志,例如第二行中最右边的标志,即使对于人类(至少对我而言),也很难立即分辨出正确的类别标签。 好东西,我们是有抱负的机器学习专家!
解析数据集
幸运的是,所选的数据集带有用于解析文件的脚本(更多信息可以在这个页面)。
我们对其进行了一些调整,并针对我们的目的进行了调整。 特别是,我们需要一个不仅加载数据集,而且还提取感兴趣的特定特征的函数(通过feature输入参数),将样本裁剪到手工标记的兴趣区域(ROI)仅包含样本(cut_roi),并自动将数据拆分为训练集和测试集(test_split)。 我们还允许指定随机种子数(seed),并绘制一些样本以进行视觉检查(plot_samples):
import cv2
import numpy as np
import csv
from matplotlib import cm
from matplotlib import pyplot as plt
def load_data(rootpath="datasets", feature="hog", cut_roi=True,
test_split=0.2, plot_samples=False, seed=113):
尽管完整的数据集包含超过 50,000 个属于 43 个类的示例,但出于本章的目的,我们将限于 10 个类。 为了便于访问,我们将对类标签进行硬编码以在此处使用,但是包含更多的类很简单(请注意,您必须为此下载整个数据集):
classes = np.array([0, 4, 8, 12, 16, 20, 24, 28, 32, 36])
然后,我们需要遍历所有类,以读取所有训练样本(存储在X中)及其相应的类标签(存储在labels中)。 每个类都有一个 CSV 文件,其中包含该类中每个样本的所有标注信息,我们将使用csv.reader进行解析:
X = [] # images
labels = [] # corresponding labels
# subdirectory for class
for c in xrange(len(classes)):
prefix = rootpath + '/' + format(classes[c], '05d') + '/'
# annotations file
gt_file = open(prefix + 'GT-'+ format(classes[c], '05d')+ '.csv')
gt_reader = csv.reader(gt_file, delimiter=';')
文件的每一行都包含一个数据样本的标注。 我们跳过第一行(标题)并提取样本的文件名(row[0]),以便我们可以在图像中读取:
gt_reader.next() # skip header
# loop over all images in current annotations file
for row in gt_reader:
# first column is filename
im = cv2.imread(prefix + row[0])
有时,这些样本中的对象没有被完美切出,而是被嵌入其周围。 如果设置了cut_roi输入参数,我们将忽略背景,并使用标注文件中指定的边界框将对象切出:
if cut_roi:
im = im[np.int(row[4]):np.int(row[6]),
np.int(row[3]):np.int(row[5]), :]
然后,我们准备将图像(im)及其类别标签(c)附加到样本列表(X)和类别标签(labels)中:
X.append(im)
labels.append(c)
gt_file.close()
通常,希望执行某种形式的特征提取,因为原始图像数据很少是数据的最佳描述。 我们将把这项工作推迟到另一个函数,我们将在下一节中详细讨论:
if feature is not None:
X = _extract_feature(X, feature)
如前一小节所述,必须将用于训练分类器的样本与用于测试分类器的样本分开。 为此,我们将数据进行混洗并将其分成两个单独的集合,以使训练集包含所有样本的一部分(1-test_split),其余样本属于测试集:
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(labels)
X_train = X[:int(len(X)*(1-test_split))]
y_train = labels[:int(len(X)*(1-test_split))]
X_test = X[int(len(X)*(1-test_split)):]
y_test = labels[int(len(X)*(1-test_split)):]
最后,我们可以返回提取的数据:
return (X_train, y_train), (X_test, y_test)
特征提取
正如我们已经在第 3 章,“通过特征匹配和透视变换查找对象”中所认识的那样,原始像素值不是表示数据的最有用的方式。 。 相反,我们需要导出数据的可测量属性,以便为分类提供更多信息。
但是,通常不清楚哪些特征会表现最佳。 取而代之的是,通常有必要试验建模者认为合适的不同特征。 毕竟,特征的选择可能在很大程度上取决于要分析的特定数据集或要执行的特定分类任务。 例如,如果您必须区分停车标志和警告标志,那么最具说服力的特征可能就是标志的形状或配色方案。 但是,如果您必须区分两个警告标志,那么颜色和形状根本无法帮助您,并且您将需要提供更复杂的特征。
为了演示特征的选择如何影响分类表现,我们将重点关注以下方面:
- 一些简单的颜色转换,例如灰度,RGB 和 HSV。 基于灰度图像的分类将为分类器提供一些基线表现。 由于某些交通标志的颜色方案不同,RGB 可能会给我们带来更好的表现。 HSV 有望提供更好的表现。 这是因为它代表的颜色甚至比 RGB 更坚固。 交通标志往往具有非常明亮,饱和的颜色(理想情况下)与周围环境完全不同。
- 加速鲁棒特征(SURF),现在应该对您来说非常熟悉。 我们以前已经认识到 SURF 是一种从图像中提取有意义的特征的有效且鲁棒的方法,因此我们不能在分类任务中利用这一技术来获得优势吗?
- 定向梯度直方图(HOG),它是迄今为止本章要考虑的最高级特征描述符。 该技术可以计算沿图像上排列的密集网格出现的梯度方向,非常适合与 SVM 一起使用。
特征提取由gtsrb._extract_features函数执行,该函数由gtsrb.load_data隐式调用。 它提取feature输入参数指定的不同特征。
最简单的情况是不提取任何特征,而只是将图像调整为合适的大小:
def _extract_feature(X, feature):
# operate on smaller image
small_size = (32, 32)
X = [cv2.resize(x, small_size) for x in X]
注意
对于以下大多数函数,我们将在 OpenCV 中使用(已经合适的)默认参数。 但是,这些值并不是一成不变的,即使在现实世界中的分类任务中,通常也有必要在称为超参数探索的过程中搜索可能值的范围,以用于特征提取和学习参数。
通用预处理
共有三种预处理的常见形式,几乎总是应用于分类之前的任何数据:均值减法,归一化和主成分分析(PCA)。 在本章中,我们将重点介绍前两个。
均值减法是最常见的预处理形式(有时也称为零中心或去均值),其中每个特征维的平均值是对数据集中的所有样本进行计算的。 然后,从数据集中的每个样本中减去此按特征平均值。 您可以认为此过程将数据的点云集中在原点上。 归一化是指数据维度的缩放比例,以便它们具有大致相同的缩放比例。 这可以通过以下方式实现:将每个维度除以其标准差(一旦它已为零中心),或者将每个维度缩放到[-1, 1]的范围内。 仅当您有理由相信不同的输入特征具有不同的比例或单位时,才应应用此步骤。 在图像的情况下,像素的相对比例已经大约相等(并且在[0, 255]的范围内),因此不必严格执行此附加预处理步骤。
在本章中,我们的想法是增强图像的局部强度对比度,以使我们不再关注图像的整体亮度:
# normalize all intensities to be between 0 and 1
X = np.array(X).astype(np.float32) / 255
# subtract mean
X = [x - np.mean(x) for x in X]
灰度特征
最容易提取的特征可能是每个像素的灰度值。 通常,灰度值不能很好地表示它们描述的数据,但出于说明目的(即为了达到基准表现),我们将在此处包括它们:
if feature == 'gray' or feature == 'surf':
X = [cv2.cvtColor(x, cv2.COLOR_BGR2GRAY) for x in X]
色彩空间
或者,您可能会发现颜色包含一些原始灰度值无法捕获的信息。 交通标志通常具有不同的配色方案,并且可能表示正在尝试传递的信息(即,红色表示停车标志和禁止的行为,绿色表示信息标志,等等)。 我们可以选择使用 RGB 图像作为输入,在这种情况下我们不必做任何事情,因为数据集已经是 RGB。
但是,即使 RGB 可能也无法提供足够的信息。 例如,在光天化日之下的停车标志可能看起来非常明亮清晰,但是在下雨或有雾的日子中,其颜色可能显得不那么活跃。 更好的选择可能是 HSV 颜色空间,它沿着色相,饱和度和值(或亮度)的轴在圆柱坐标空间中重新排列 RGB 颜色值 。 在这个颜色空间中,交通标志最明显的特征可能是色相(颜色或色度在感知上的相关描述),可以更好地区分不同标志类型的配色方案。 但是,饱和度和值可能同样重要,因为交通标志往往会使用相对明亮和饱和的颜色,这些颜色通常不会出现在自然场景(即周围环境)中。
在 OpenCV 中,HSV 颜色空间仅是对cv2.cvtColor的一次调用:
if feature == 'hsv':
X = [cv2.cvtColor(x, cv2.COLOR_BGR2HSV) for x in X]
加速鲁棒性
但是请稍等! 在第 3 章,“通过特征匹配和透视变换查找对象”中,您了解了 SURF 描述符是最好和最可靠的描述图像的方式,与旋转或者缩放无关。 我们可以在分类任务中利用这一技术吗?
很高兴你问! 为此,我们需要调整 SURF,以使每个图像返回固定数量的特征。 默认情况下,SURF 描述符仅应用于图像中一小部分有趣的关键点,每个关键点的数量可能有所不同。 这不适合我们当前的目的,因为我们想为每个数据样本找到固定数量的特征值。
相反,我们需要将 SURF 应用于图像上方的固定密集网格,这可以通过创建密集特征检测器来实现:
if feature == 'surf':
# create dense grid of keypoints
dense = cv2.FeatureDetector_create("Dense")
kp = dense.detect(np.zeros(small_size).astype(np.uint8))
然后就有可能获得网格上每个点的 SURF 描述符并将该数据样本附加到我们的特征矩阵中。 我们像以前一样使用minHessian值为 400 初始化 SURF,并且:
surf = cv2.SURF(400)
surf.upright = True
surf.extended = True
然后可以通过以下代码获取关键点和描述符:
kp_des = [surf.compute(x, kp) for x in X]
因为surf.compute有两个输出参数,所以kp_des实际上将是的关键点和描述符的连接。 kp_des数组中的第二个元素是我们关心的描述符。 我们从每个数据样本中选择第一个num_surf_features并将其添加回训练集中:
num_surf_features = 36
X = [d[1][:num_surf_features, :] for d in kp_des]
定向梯度的直方图
考虑的最后一个特征描述符是定向梯度直方图(HOG)。 先前已证明 HOG 特征与 SVM 结合使用时效果特别好,尤其是在应用于行人识别等任务时。
HOG 特征背后的基本思想是,图像中对象的局部形状和外观可以通过边缘方向的分布来描述。 图像被划分为较小的连接区域,在该区域中会编译梯度方向(或边缘方向)的直方图。 然后,通过连接不同的直方图来组装描述符。 为了提高表现,可以对局部直方图进行对比度归一化,从而更好地保持照明和阴影变化的不变性。 您会看到为什么这种预处理可能恰好适合于在不同视角和光照条件下识别交通标志。
可以通过cv2.HOGDescriptor在 OpenCV 中完全访问 HOG 描述符,它采用检测窗口大小(32 x 32),块大小(16 x 16),像元大小(8 x 8)和像元跨度(8 x 8),作为输入参数。 然后,对于这些单元格中的每个单元格,HOG 描述符使用九个面元计算定向梯度的直方图:
elif feature == 'hog':
# histogram of oriented gradients
block_size = (small_size[0] / 2, small_size[1] / 2)
block_stride = (small_size[0] / 4, small_size[1] / 4)
cell_size = block_stride
num_bins = 9
hog = cv2.HOGDescriptor(small_size, block_size, block_stride, cell_size, num_bins)
将 HOG 描述符应用于每个数据样本为,然后就像调用hog.compute一样容易:
X = [hog.compute(x) for x in X]
提取完所需的所有特征后,我们应该记住要让gtsrb._extract_features返回数据样本的组合列表,以便可以将它们分为训练和测试集:
X = [x.flatten() for x in X]
return X
现在,我们终于准备好在预处理的数据集上训练分类器了。
支持向量机
支持向量机(SVM)是一种用于二分类(和回归)的学习器,它试图通过决策边界将两个不同类标签中的示例分离开来,以使两个类之间的余量最大化。
让我们回到正负数据样本的示例,每个样本都具有两个特征(x和y),以及两个可能的决策边界,如下所示:
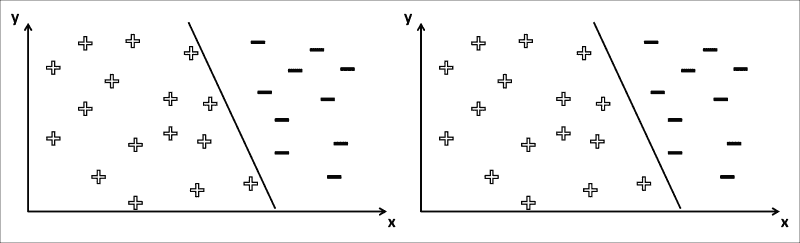
这两个决策边界都可以完成工作。 他们用零错误分类对所有正样本和负样本进行划分。 但是,其中之一似乎在直观上更好。 我们如何量化“更好”,从而学习“最佳”参数设置?
这就是 SVM 出现的地方。SVM 也被称为最大余量分类器,因为它们可以用来做这些。 他们定义了决策边界,以便使+和-的这两朵云尽可能地分开。
对于前面的示例,SVM 将找到两条穿过类边距上数据点的线(下图中的虚线),然后使穿过边距中心的线(决策边界) 下图中的黑色粗线):
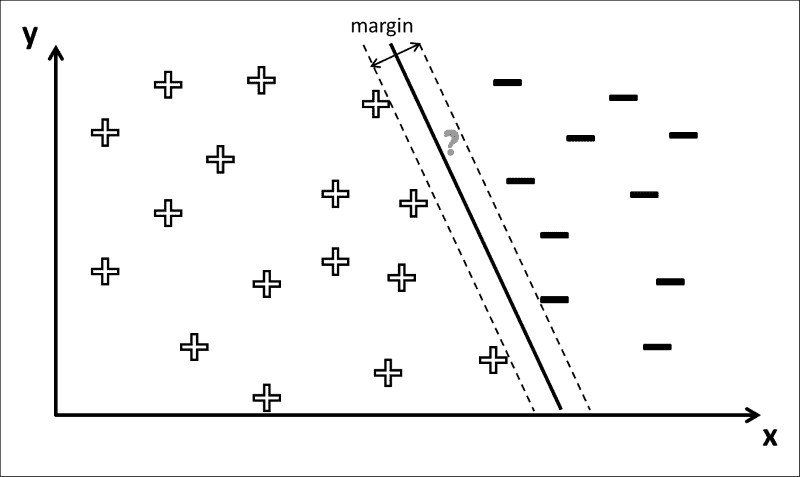
事实证明,要找到最大余量,仅考虑位于类余量上的数据点很重要。 这些点有时也称为支持向量。
注意
除了执行线性分类(即决策边界为直线时)之外,SVM 还可以使用核技巧隐式映射其输入来执行非线性分类。 到高维特征空间。
使用 SVM 进行多类别分类
尽管某些分类算法(例如神经网络)自然可以使用两个以上的类,但 SVM 本质上是二分类器。 但是,它们可以变成多类分类器。
在这里,我们将考虑两种不同的策略:
- 一对多:一对多策略涉及每个类别训练一个分类器,该类别的样本为正面样本,所有其他样本为负例。 因此,对于
k类,此策略需要训练k不同的 SVM。 在测试期间,所有分类器都可以通过预测未见样本属于其类别来表示+1投票。 最后,集成将看不见的样本分类为投票最多的类别。 通常,此策略与置信度分数结合使用,而不是与预测标签结合使用,以便最终可以选择置信度分数最高的类。 - 一对一:一对一策略涉及每类对训练一个分类器,第一类样本为正样本,第二类样本为负样本。 对于
k类,此策略需要训练k*(k-1)/2分类器。 但是,分类器必须解决一个非常简单的任务,因此在考虑使用哪种策略时需要权衡取舍。 在测试期间,所有分类器都可以对第一或第二个类别表示+1投票。 最后,集成将看不见的样本分类为投票最多的类别。
用户可以通过MutliClassSVM类的输入参数(mode)由用户指定使用哪种策略:
class MultiClassSVM(Classifier):
"""Multi-class classification using Support Vector Machines (SVMs) """
def __init__(self, num_classes, mode="one-vs-all", params=None):
self.num_classes = num_classes
self.mode = mode
self.params = params or dict()
如前所述,根据分类策略,我们将需要k或k*(k-1)/2 SVM 分类器,为此我们将在self.classifiers中维护一个列表:
# initialize correct number of classifiers
self.classifiers = []
if mode == "one-vs-one":
# k classes: need k*(k-1)/2 classifiers
for i in xrange(numClasses*(numClasses-1)/2):
self.classifiers.append(cv2.SVM())
elif mode == "one-vs-all":
# k classes: need k classifiers
for i in xrange(numClasses):
self.classifiers.append(cv2.SVM())
else:
print "Unknown mode ",mode
一旦正确地初始化了分类器,我们就准备好进行训练了。
训练 SVM
遵循Classifier基类定义的要求,我们需要以fit方法执行训练:
def fit(self, X_train, y_train, params=None):
""" fit model to data """
if params is None:
params = self.params
训练将根据所使用的分类策略而有所不同。 一对一策略要求我们为每对课程训练一个 SVM:
if self.mode == "one-vs-one":
svm_id=0
for c1 in xrange(self.numClasses):
for c2 in xrange(c1+1,self.numClasses):
在这里,我们使用svm_id来跟踪我们使用的 SVM 的数量。 与“一对多”策略相反,我们需要在此处训练大量的 SVM。 但是,每个 SVM 要考虑的训练样本仅包括c1或c2类别的样本:
y_train_c1 = np.where(y_train==c1)[0]
y_train_c2 = np.where(y_train==c2)[0]
data_id = np.sort(np.concatenate((y_train_c1, y_train_c2), axis=0))
X_train_id = X_train[data_id,:]
y_train_id = y_train[data_id]
由于 SVM 是二分类器,因此我们需要将整数类标签转换为 0 和 1。 再次使用方便的np.where函数,我们将标签1分配给c1类的所有样本,并将标签0分配给c2类的所有样本:
y_train_bin = np.where(y_train_id==c1, 1, 0).flatten()
然后我们准备训练 SVM:
self.classifiers[svm_id].train(X_train_id, y_train_bin, params=self.params)
在这里,我们将训练参数字典self.params传递到 SVM。 目前,我们仅考虑(已经合适的)默认参数值,但可以尝试使用不同的设置。
不要忘记更新svm_id,以便您可以继续使用列表中的下一个 SVM:
svm_id += 1
另一方面,“一对多”策略要求我们训练总数为self.numClasses的 SVM,这使索引编制变得容易得多:
elif self.mode == "one-vs-all":
for c in xrange(self.numClasses):
同样,我们需要将整数标签转换为二进制标签。 与一对一策略相反,这里的每个 SVM 都考虑所有训练样本。 我们将标签1分配给c类的所有样本,并将标签0分配给所有其他样本,然后将数据传递给分类器的训练方法:
y_train_bin = np.where(y_train==c,1,0).flatten()
self.classifiers[c].train(X_train, y_train_bin, params=self.params)
OpenCV 将负责其余的工作。 实际情况是,SVM 训练使用拉格朗日乘数来优化一些约束,这些约束会导致最大利润的决策边界。 通常会执行优化过程,直到满足某些终止条件为止,这些条件可以通过 SVM 的可选参数指定:
params.term_crit = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 1e-6)
测试 SVM
评估分类器的方法有很多,但是最常见的是,我们只对准确率指标感兴趣,也就是说,对测试集中有多少数据样本进行了正确分类。
为了得出此指标,我们需要让每个单独的 SVM 预测测试数据的标签,并在 2D 投票矩阵(Y_vote)中组装它们的共识:
def evaluate(self, X_test, y_test, visualize=False):
"""Evaluates model performance"""
Y_vote = np.zeros((len(y_test), self.numClasses))
对于数据集中的每个样本,投票矩阵将包含样本被投票属于某个类别的次数。 根据分类策略,填充投票矩阵将采取略有不同的形式。 在一对一策略的情况下,我们需要遍历所有k*(k-1)/2分类器,并获得一个名为y_hat的向量,该向量包含所有属于c1类或c2类的测试样本的预测标签:
if self.mode == "one-vs-one":
svm_id = 0
for c1 in xrange(self.numClasses):
for c2 in xrange(c1+ 1, self.numClasses):
data_id = np.where((y_test==c1) + (y_test==c2))[0]
X_test_id = X_test[data_id,:],:],:]
y_test_id = y_test[data_id]
# predict labels
y_hat = self.classifiers[svm_id].predict_all( X_test_id)
每当分类器认为样本属于c1类时,y_hat向量将包含 1;而当分类器认为样本属于c2类时,y_hat向量将包含 0。 棘手的部分是如何为Y_vote矩阵中的正确单元格 +1。 例如,如果y_hat中的第i项是1(意味着我们认为第个样本属于c1类),我们想增加Y_vote矩阵中第i行和第c1列的值。 这将表明本分类器已投票赞成将样本i归为c1类。
因为我们知道属于c1或c2类(存储在data_id中)的所有测试样本的索引,所以我们知道要访问Y_vote的哪些行。 因为data_id用作Y_vote的索引,所以我们只需要在data_id中找到与y_hat为1的条目相对应的索引:
# we vote for c1 where y_hat is 1, and for c2 where
# y_hat is 0
# np.where serves as the inner index into the
# data_id array, which in turn serves as index
# into the Y_vote matrix
Y_vote[data_id[np.where(y_hat==1)[0]],c1] += 1
同样,我们可以对c2类表示投票:
Y_vote[data_id[np.where(y_hat==0)[0]],c2] += 1
然后我们增加svm_id并转到下一个分类器:
svm_id += 1
“一对多”策略提出了一个不同的问题。 在Y_vote矩阵中建立索引的难度较小,因为我们始终考虑所有测试数据样本。 我们为每个数据样本重复预测标签的过程:
elif self.mode == "one-vs-all":
for c in xrange(self.numClasses):
# predict labels
y_hat = self.classifiers[c].predict_all(X_test)
无论y_hat的值为1,分类器都会表示该数据样本属于c类的投票,我们将更新投票矩阵:
# we vote for c where y_hat is 1
if np.any(y_hat):
Y_vote[np.where(y_hat==1)[0], c] += 1
现在最棘手的部分是,“如何处理具有0值的y_hat条目?” 由于我们将“一对多”分类,因此我们只知道样本不是c类(也就是说,它属于“其余”),但是我们不知道确切的类标签应该是什么 。 因此,我们不能将这些样本添加到投票矩阵中。
由于我们忽略了包括始终被归类为“其余”的样本,因此Y_vote矩阵中的某些行可能全为 0。 在这种情况下,只需随机选择一个班级(除非您有更好的主意):
# find all rows without votes, pick a class at random
no_label = np.where(np.sum(y_vote,axis=1)==0)[0]
Y_vote[no_label,np.random.randint(self.numClasses, size=len(no_label))] = 1
现在,我们已经准备好来计算所需的表现指标,这将在后面的部分中详细介绍。 就本章而言,我们选择计算准确率,精确度和召回率,它们以自己专用的私有方法实现:
accuracy = self.__accuracy(y_test, Y_vote)
precision = self.__precision(y_test, Y_vote)
recall = self.__recall(y_test, Y_vote)
return (accuracy,precision,recall)
注意
scikit-learn机器学习包支持即开即用的三个指标:准确率,准确率和召回率(以及其他) ,还附带了各种其他有用的工具。 出于教育目的(并最大程度地减少软件依赖项),我们将自己得出这三个指标。
混淆矩阵
混淆矩阵是大小为(self.numClasses, self.numClasses)的 2D 矩阵,其中行对应于预测的类别标签,列对应于实际的类别标签。 然后,[r,c]矩阵元素包含预测为具有标签r,但实际上具有标签c的样本数。 访问混淆矩阵将使我们能够计算精度和召回率。
混淆矩阵可以从真实标签y_test和投票矩阵Y_vote的向量中计算得出。 我们首先通过选择获得最多投票的列索引(即类标签)将投票矩阵转换为预测标签的向量:
def __confusion(self, y_test, Y_vote):
y_hat = np.argmax(Y_vote, axis=1)
然后,我们需要在所有类别上循环两次,并计算预测c_true真实类别的数据样本具有c_pred类别的次数:
conf = np.zeros((self.numClasses, self.numClasses)).astype(np.int32)
for c_true in xrange(self.numClasses):
# looking at all samples of a given class, c_true
# how many were classified as c_true? how many as others?
for c_pred in xrange(self.numClasses):
因此,每次迭代中所有感兴趣的元素都是在y_test中具有c_true标签和在y_hat中具有c_pred标签的样本:
y_this = np.where((y_test==c_true) * (y_hat==c_pred))
置信矩阵中相应的单元格就是y_this中非零元素的数量:
conf[c_pred,c_true] = np.count_nonzero(y_this)
嵌套循环完成后,我们将混淆矩阵进行进一步处理:
return conf
您可能已经猜到了,一个好的分类器的目标是使混淆矩阵对角线化,这意味着每个样本的真实级别(c_true)和预测级别(c_pred)相同 。
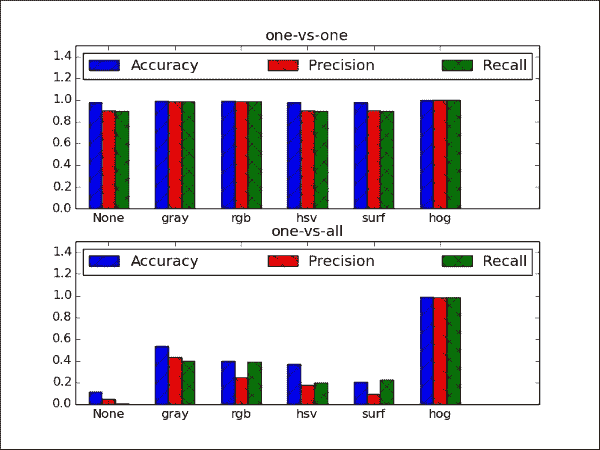
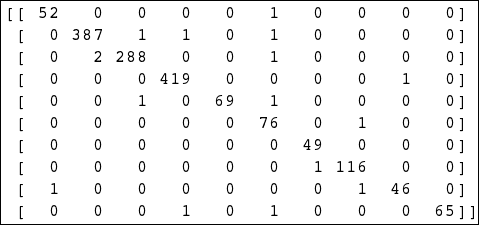
一对一策略与 HOG 特征相结合,实际上效果非常好,这从由此产生的混淆矩阵中可以明显看出,其中大多数非对角元素为零:
准确率
要计算的最简单的指标可能是准确率。 此度量标准仅计算已正确预测的测试样本数,然后将其返回为测试样本总数的一部分:
def __accuracy(self, y_test, y_vote):
""" Calculates the accuracy based on a vector of ground-truth labels (y_test) and a 2D voting matrix (y_vote) of size (len(y_test),numClasses). """
可以通过找出哪个类别获得最多投票的方式从投票矩阵中提取分类预测(y_hat):
y_hat = np.argmax(y_vote, axis=1)
可以通过将样本的预测标签与其实际标签进行比较来验证预测的正确性:
# all cases where predicted class was correct
mask = (y_hat == y_test)
然后,通过计算正确的预测数(即mask中的非零条目)并通过测试样本总数对该数字进行归一化来计算准确率:
return np.count_nonzero(mask)*1./len(y_test)
精度
二分类的精度是一种有用的度量标准,用于测量所检索的相关实例的比例(也称为正例预测值)。 在分类任务中,真正例的数量定义为正确标记为属于正例类别的项目的数量。 精度定义为真正例数除以正例总数。 换句话说,在测试集中分类器认为包含猫的所有图片中,精度是实际包含猫的图片的比例。
正例总数也可以计算为真正例和假正例的总和,后者是被错误地标记为属于特定类别的样本数。 这是混淆矩阵派上用场的地方,因为它将使我们能够快速计算误报的数量。
同样,我们首先将投票矩阵转换为预测标签的向量:
def __precision(self, y_test, Y_vote):
""" precision extended to multi-class classification """
# predicted classes
y_hat = np.argmax(Y_vote, axis=1)
根据分类策略,该过程将略有不同。 一对一策略要求我们使用混淆矩阵进行操作:
if True or self.mode == "one-vs-one":
# need confusion matrix
conf = self.__confusion(y_test, y_vote)
# consider each class separately
prec = np.zeros(self.numClasses)
for c in xrange(self.numClasses):
由于真正例是被预测为实际上具有标签c且也具有标签c的样本,因此它们对应于混淆矩阵的对角元素:
# true positives: label is c, classifier predicted c
tp = conf[c,c]
同样,假正例与混淆矩阵的对角线元素相对应,它们与真正例在同一列中。 计算该数字的最快方法是对c列中的所有元素求和,但减去真实的正数:
# false positives: label is c, classifier predicted
# not c
fp = np.sum(conf[:,c]) - conf[c,c]
精度是真实肯定的数量除以真实肯定和错误肯定的总和:
if tp + fp != 0:
prec[c] = tp*1./(tp+fp)
一对多策略使数学运算变得容易一些。 由于我们始终使用完整的测试集,因此只需要查找在y_test中具有c真实标签而在y_hat中具有c预测标签的样本:
elif self.mode == "one-vs-all":
# consider each class separately
prec = np.zeros(self.numClasses)
for c in xrange(self.numClasses):
# true positives: label is c, classifier predicted c
tp = np.count_nonzero((y_test==c) * (y_hat==c))
同样,假正例在y_test中具有c的真实标签,而在y_hat中其预测的标签不是c:
# false positives: label is c, classifier predicted
# not c
fp = np.count_nonzero((y_test==c) * (y_hat!=c))
同样,精度是真正例的数量除以真正例和假正例的总和:
if tp + fp != 0:
prec[c] = tp*1./(tp+fp)
之后,我们传递精度向量以进行可视化:
return prec
召回
召回在某种意义上与精度类似,因为它会测量所检索的相关实例的比例(与所检索的相关实例的比例相对)。 在分类任务中,假负例的数量是未标记为属于正例类别但应标记的项目数量。 召回率是真实肯定的数量除以真实肯定和错误否定的总和。 换句话说,在世界上所有猫的图片中,召回率是被正确识别为猫的图片的一部分。
再次,我们首先将投票矩阵转换为预测标签的向量:
def __recall(self, y_test, Y_vote):
""" recall extended to multi-class classification """
# predicted classes
y_hat = np.argmax(Y_vote, axis=1)
该过程几乎与计算精度相同。 一对一策略再次需要一些涉及混淆矩阵的算法:
if True or self.mode == "one-vs-one":
# need confusion matrix
conf = self.__confusion(y_test, y_vote)
# consider each class separately
recall = np.zeros(self.numClasses)
for c in xrange(self.numClasses):
真正值再次对应于混淆矩阵中的对角元素:
# true positives: label is c, classifier predicted c
tp = conf[c,c]
要获得假负例数,我们将c行中的所有列求和,然后减去该行的真正例数。 这将为我们提供分类器预测其类别为c但实际上具有c以外的真实标签的样本数:
# false negatives: label is not c, classifier
# predicted c
fn = np.sum(conf[c,:]) - conf[c,c]
回想一下,是真正例的数量除以真正例和假负例的总和:
if tp + fn != 0:
recall[c] = tp*1./(tp+fn)
同样,“一对多”策略使数学运算更加容易。 由于我们始终在完整的测试集上进行操作,因此我们只需要查找那些在y_test中的地面标签不是c且在y_hat中的预测标签是c的样本:
elif self.mode == "one-vs-all":
# consider each class separately
recall = np.zeros(self.numClasses)
for c in xrange(self.numClasses):
# true positives: label is c, classifier predicted c
tp = np.count_nonzero((y_test==c) * (y_hat==c))
# false negatives: label is not c, classifier
# predicted c
fn = np.count_nonzero((y_test!=c) * (y_hat==c))
if tp + fn != 0:
recall[c] = tp*1./(tp+fn)
之后,我们传递召回向量以进行可视化:
return recall
全部放在一起
要运行我们的应用,我们需要执行main函数例程(在chapter6.py中)。 它加载数据,训练分类器,评估其表现并可视化结果。
但是首先,我们需要导入所有相关模块并设置一个main函数:
import numpy as np
import matplotlib.pyplot as plt
from datasets import gtsrb
from classifiers import MultiClassSVM
def main():
然后,目标是比较设置和特征提取方法之间的分类表现。 这包括使用一对多和一对多两种分类策略运行任务,以及使用一系列不同的特征提取方法预处理数据:
strategies = ['one-vs-one', 'one-vs-all']features = [None,
'gray', 'rgb', 'hsv', 'surf', 'hog']
对于这些设置中的每一个,我们需要收集三个表现指标—准确率,精度和召回率:
accuracy = np.zeros((2,len(features)))
precision = np.zeros((2,len(features)))
recall = np.zeros((2,len(features)))
嵌套的for循环将使用所有这些设置来运行分类器,并填充表现指标矩阵。 外循环遍历features向量中的所有元素:
for f in xrange(len(features)):
(X_train,y_train), (X_test,y_test) = gtsrb.load_data( "datasets/gtsrb_training", feature=features[f], test_split=0.2)
在将训练数据(X_train,y_train)和测试数据(X_test,y_test)传递给分类器之前,我们要确保它们符合分类器期望的格式; 也就是说,每个数据样本都存储在X_train或X_test的行中,其中的列与特征值相对应:
X_train = np.squeeze(np.array(X_train)).astype(np.float32)
y_train = np.array(y_train)
X_test = np.squeeze(np.array(X_test)).astype(np.float32)
y_test = np.array(y_test)
我们还需要知道类标签的数量(因为我们没有加载完整的 GTSRB 数据集)。 这可以通过连接y_train和y_test并提取组合列表中的所有唯一标签来实现:
labels = np.unique(np.hstack((y_train,y_test)))
接下来,内部循环遍历strategies向量中的所有元素,该向量当前包括“一对多”和“一对一”两种策略:
for s in xrange(len(strategies)):
然后,我们使用正确数量的唯一标签和相应的分类策略实例化MultiClassSVM类:
MCS = MultiClassSVM(len(labels),strategies[s])
现在我们已经准备好将集成分类器应用于训练数据并在训练后提取三个表现指标:
MCS.fit(X_train, y_train)
(accuracy[s,f],precision[s,f],recall[s,f]) = MCS.evaluate(X_test, y_test)
这样就结束了嵌套的for循环。 剩下要做的就是可视化结果。 为此,我们选择 Matplotlib 的条形图功能。 目标是显示提取的特征和分类策略的所有组合的三个表现指标(准确率,准确率和召回率)。 我们将为每个分类策略使用一个绘图窗口,并在堆叠的条形图中排列相应的数据:
f,ax = plt.subplots(2)
for s in xrange(len(strategies)):
x = np.arange(len(features))
ax[s].bar(x-0.2, accuracy[s,:], width=0.2, color='b', hatch='/', align='center')
ax[s].bar(x, precision[s,:], width=0.2, color='r', hatch='\\', align='center')
ax[s].bar(x+0.2, recall[s,:], width=0.2, color='g', hatch='x', align='center')
为了可见, y轴限制在相关范围内:
ax[s].axis([-0.5, len(features) + 0.5, 0, 1.5])
最后,我们添加一些绘图装饰:
ax[s].legend(('Accuracy','Precision','Recall'), loc=2, ncol=3, mode="expand")
ax[s].set_xticks(np.arange(len(features)))
ax[s].set_xticklabels(features)
ax[s].set_title(strategies[s])
现在数据已准备好绘制!
plt.show()
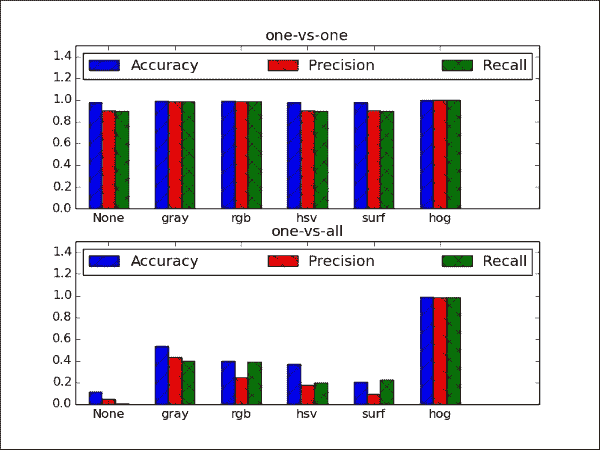
此屏幕快照包含很多信息,因此我们将其逐步分解:
- 最直接的观察是,HOG 特征似乎强大! 无论分类策略是什么,此特征都优于其他所有特征。 同样,这凸显了特征提取的重要性,这通常需要对所研究数据集的统计数据有深刻的了解。
- 有趣的是,使用一对多策略时,所有方法的准确率都在 0.95 以北,这可能是由于二分类任务(带有两个可能的类别标签)有时比 10 容易学习的事实。 级分类任务。 不幸的是,对于“一对多”方法不能说相同的话。 但公平地说,“一对多”方法只能使用 10 个 SVM,而“一对多”方法只能使用 45 个 SVM。 仅当我们添加更多对象类别时,这种差距才可能增加。
- 通过将
None的结果与rgb的结果进行比较,可以看到去语义的影响。 这两个设置是相同的,除了rgb下的样本已标准化。 成效上的差异是显而易见的,尤其是一对多策略。 - 令人失望的发现是,没有任何一种颜色转换(RGB 和 HSV)都比简单的灰度转换表现要好得多。 SURF 也没有帮助。
总结
在本章中,我们训练了一个多类分类器来识别来自 GTSRB 数据库的交通标志。 我们讨论了监督学习的基础知识,探索了特征提取的复杂性,并扩展了 SVM,以便可以将它们用于多类分类。
值得注意的是,我们在此过程中遗漏了一些细节,例如尝试微调学习算法的超参数。 当我们将交通标志数据集限制为仅 10 个类别时,此过程中各种函数参数的默认值似乎足以表现出色(仅查看通过 HOG 特征获得的完美得分,以及一种策略)。 通过此特征设置以及对基础方法的充分理解,您现在可以尝试对整个 GTSRB 数据集进行分类! 绝对值得一看他们的网站,在这里您可以找到各种分类器的分类结果。 也许,您自己的方法很快就会添加到列表中。
在下一章(也是最后一章)中,我们将更深入地研究机器学习领域。 具体来说,我们将重点研究使用卷积神经网络识别人脸中的情感表情。 这次,我们将分类器与用于对象检测的框架相结合,这将使我们能够在图像中定位(在何处)人脸,然后着重于识别(什么?)该人脸中包含的情感表达。 这将结束我们对机器学习的深入探索,并为您提供使用计算机视觉原理和概念来开发自己的高级 OpenCV 项目所需的所有必要工具。
七、学习识别面部表情
我们之前已经熟悉了对象检测和对象识别的概念,但是我们从未将它们组合在一起来开发可以同时实现端到端的应用。 对于本书的最后一章,我们将做到这一点。
本章的目的是开发一种结合了人脸检测和人脸识别的应用,重点是识别被检测人脸中的情绪表情。
为此,我们将介绍与 OpenCV 捆绑在一起的其他两个经典算法:Haar 级联分类器和多层感知机(MLP)。 前者可用于快速检测(或定位,回答问题:在哪里?)图像中各种大小和方向的对象,而后者可用于识别它们(或识别,回答问题:什么?)。
该应用的最终目标是在网络摄像头实时流的每个捕获帧中检测到您自己的脸并标记您的情感表情。 为了使这项任务可行,我们将限于以下几种可能的情感表达方式:中立,快乐,悲伤,惊讶,愤怒和恶心。
为了实现这样一个应用,我们需要解决以下两个挑战:
- 人脸检测:我们将使用 Viola 和 Jones 流行的 Haar 级联分类器,为此 OpenCV 提供了一系列预训练的样本。 我们将利用面部叶栅和眼睛叶栅来可靠地检测并对齐各个框架中的面部区域。
- 面部表情识别:我们将训练多层感知器,以识别每张检测到的面部中较早列出的六种不同的情绪表情。 这种方法的成功关键取决于我们组装的训练集,以及我们选择应用于该集中每个样本的预处理。 为了提高我们自记录训练集的质量,我们将确保使用仿射变换对齐所有数据样本,并通过应用减少特征空间的维数[ 主成分分析(PCA)。 有时将所得表示形式也称为 EigenFace。
对面部和面部表情的可靠识别对于人工智能来说是一项艰巨的任务,而人类却能够轻松地执行这些任务。 当今最先进的模型范围很广,从适用于卷积神经网络的 3D 变形人脸模型到深度学习算法。 当然,这些方法比我们的方法复杂得多。 但是,MLP 是帮助改变机器学习领域的经典算法,因此出于教育目的,我们将坚持使用与 OpenCV 捆绑在一起的一组算法。
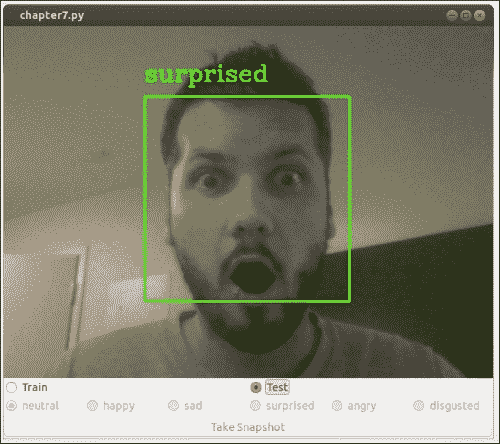
我们将在单个端到端应用中结合前面提到的算法,该应用在视频直播流的每个捕获帧中为检测到的面部和相应的面部表情标签添加标注。 最终结果可能类似于下图,捕获了我在第一次编译代码时的反应:
规划应用
最终的应用将包含一个主脚本,该脚本将端到端的流程从端到端集成到从面部检测到面部表情识别,以及一些工具函数来提供帮助。
因此,最终产品将需要几个组件:
chapter7:本章的主要脚本和入口点。chapter7.FaceLayout:基于gui.BaseLayout的自定义布局,可在两种不同模式下运行:- 训练模式:在训练模式下,应用将收集图像帧,检测其中的脸部,根据面部表情分配标签,并在退出时将所有收集的数据样本保存在文件中,以便可以通过解析
datasets.homebrew。 - 测试模式:在测试模式下,应用将检测每个视频帧中的人脸,并使用预训练的 MLP 预测相应的类别标签。
- 训练模式:在训练模式下,应用将收集图像帧,检测其中的脸部,根据面部表情分配标签,并在退出时将所有收集的数据样本保存在文件中,以便可以通过解析
chapter3.main:启动 GUI 应用的main函数例程。detectors.FaceDetector:用于面部检测的类。detect:一种用于检测灰度图像中人脸的方法。 可选地,将图像缩小以提高可靠性。 成功检测后,该方法将返回提取的头部区域。align_head:一种使用仿射变换对提取的头部区域进行预处理的方法,以使生成的脸部居中并直立。
classifiers.Classifier:一个抽象基类,它定义所有分类器的公共接口(与第 6 章,“学习识别交通标志”中的相同)。classifiers.MultiLayerPerceptron:通过使用以下公共方法来实现 MLP 的类:fit:一种将 MLP 拟合到训练数据的方法。 它以训练数据矩阵作为输入,其中每行是训练样本,列包含特征值和标签向量。evaluate:一种通过在训练后将 MLP 应用于某些测试数据来评估 MLP 的方法。 它以测试数据矩阵作为输入,其中每行是测试样本,每列包含特征值和标签向量。 该函数返回三种不同的表现指标:准确率,准确率和召回率。predict:一种预测某些测试数据的类标签的方法。 我们向用户公开此方法,以便可以将其应用于任意数量的数据样本,这在测试模式下非常有用,当我们不想评估整个数据集而只预测单个数据样本的标签时 。save:一种将经过训练的 MLP 保存到文件的方法。load:一种从文件加载预训练的 MLP 的方法。
train_test_mlp:通过将 MLP 应用于我们的自记录数据集来训练和测试 MLP 的脚本。 该脚本将探索不同的网络架构,并将具有最佳泛化表现的网络架构存储在文件中,以便可以在以后加载经过预先训练的分类器。datasets.homebrew:解析自记录训练集的类。 与上一章类似,该类包含以下方法:load_data:一种加载训练集,通过extract_features函数对其执行 PCA 并将数据拆分为训练集和测试集的方法。 可选地,可以将预处理后的数据存储在文件中,这样我们以后就可以加载它,而不必再次解析数据。load_from_file:一种加载先前存储的预处理数据集的方法。extract_features:一种提取所选特征的方法(在本章中:对数据执行 PCA)。 我们将此函数公开给用户,以便可以将其应用于任意数量的数据样本,这在测试模式下非常有用,当我们不想解析整个数据集而只预测单个数据样本的标签时。
gui:一个模块,提供一个 wxPython GUI 应用来访问捕获设备并显示视频提要。 这与我们在前面各章中使用的模块相同。gui.BaseLayout:可以从中构建更复杂布局的通用布局。 本章不需要对基本布局进行任何修改。
在以下各节中,我们将详细讨论这些组件。
人脸检测
OpenCV 预装了系列复杂分类器,用于通用对象检测。 也许,最广为人知的检测器是用于面部检测的基于 Haar 级联的特征检测器,这是由 Paul Viola 和 Michael Jones 发明的。
基于 Haar 级联的分类器
每本关于 OpenCV 的书都应至少提及 Viola–Jones 面部检测器。 该级联分类器于 2001 年发明,它最终实现了实时面部检测和面部识别,从而中断了计算机视觉领域。
分类器基于类似 Haar 的特征(类似于 Haar 基函数),可对图像的小区域中的像素强度进行汇总,并捕获相邻图像区域之间的差异。 下图显示了相对于封闭的(浅灰色)检测窗口的一些示例矩形特征:
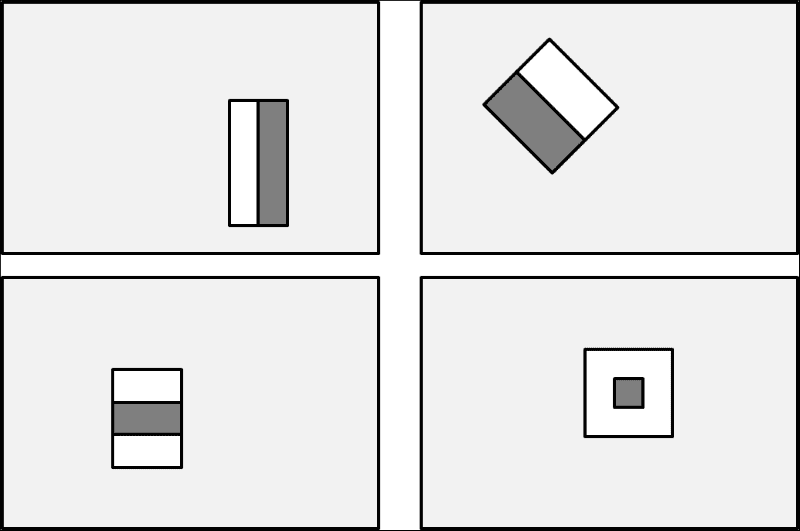
此处,顶部的行显示了边缘特征的两个示例,即垂直定向(左)或以 45 度角定向(右)。 底行显示线特征(左)和中心环绕特征(右)。 然后,通过将暗灰色矩形中的所有像素值相加,然后从白色矩形中的所有像素值之和中减去该值,来计算每个特征值。 此过程允许算法捕获人脸的某些质量,例如眼睛区域通常比脸颊周围的区域更暗的事实。
因此,常见的 Haar 特征将在明亮的矩形(代表脸颊区域)上方有一个黑色的矩形(代表眼睛区域)。 Viola 和 Jones 将这一特征与旋转的且稍微复杂一些的小波结合在一起,得出了一个强大的人脸特征描述符。 这些天才的另一个行为是,这些家伙想出了一种有效的方法来计算这些特征,从而首次实现了实时检测人脸。
预训练级联分类器
更好的是,此方法不仅对脸部有效,而且对眼睛,嘴巴,全身,公司徽标也有效。 在data文件夹的 OpenCV 安装路径下可以找到许多经过预训练的分类器:
| 级联分类器类型 | XML 文件名称 |
|---|---|
| 人脸检测器(默认) | haarcascade_frontalface_default.xml |
| 脸部检测器(ALT) | haarcascade_frontalface_alt2.xml |
| 眼睛探测器 | haarcascade_lefteye_2splits.xml``haarcascade_righteye_2splits.xml |
| 嘴部检测器 | haarcascade_mcs_mouth.xml |
| 鼻子探测器 | haarcascade_mcs_nose.xml |
| 全身探测器 | haarcascade_fullbody.xml |
在本章中,我们将使用haarcascade_frontalface_default.xml,haarcascade_lefteye_2splits.xml和haarcascade_righteye_2splits.xml。
注意
如果戴眼镜,请确保两只眼睛都使用haarcascade_eye_tree_eyeglasses.xml。
使用预训练的级联分类器
可以使用以下代码加载级联分类器并将其应用于(灰度!)图像frame:
import cv2
frame = cv2.imread('example_grayscale.jpg', cv2.CV_8UC1)face_casc = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
faces = face_casc.detectMultiScale(frame, scaleFactor=1.1,
minNeighbors=3)
detectMultiScale函数带有许多选项:
minFeatureSize:要考虑的最小脸部尺寸(例如 20×20 像素)。searchScaleFactor:要重新缩放图像的比例(缩放金字塔)。 例如,值 1.1 会逐渐将输入图像的尺寸减小 10%,从而比更大的值更有可能找到人脸。minNeighbors:每个候选矩形必须保留的邻居数。 通常,选择 3 或 5。flags:旧级联的选项(较新的级联将忽略)。 例如,要查找所有面孔还是仅查找最大面孔(cv2.cv.CASCADE_FIND_BIGGEST_OBJECT)。
如果检测成功,该函数将返回包含检测到的面部区域坐标的边界框列表(faces):
for (x, y, w, h) in faces:
# draw bounding box on frame
cv2.rectangle(frame, (x, y), (x + w, y + h), (100, 255, 0), 2)
注意
如果您的预训练的面部层叠没有检测到任何东西,通常的原因通常是找不到预训练的层叠文件的路径。 在这种情况下,CascadeClassifier将静默失败。 因此,始终最好通过检查casc.empty()来检查返回的分类器casc = cv2.CascadeClassifier(filename)是否为空。
FaceDetector类
可在detectors模块中的FaceDetector类的类的一部分中找到本章的所有相关面部检测代码。 实例化后,此类将加载预处理所需的三个不同的层叠分类器:面部层叠和两个眼睛层叠。
import cv2
import numpy as np
class FaceDetector:
def __init__(
self, face_casc='params/haarcascade_frontalface_default.xml',left_eye_casc='params/haarcascade_lefteye_2splits.xml',right_eye_casc='params/haarcascade_righteye_2splits.xml',scale_factor=4):
因为我们的预处理需要一个有效的面部层叠,所以我们确保可以加载该文件。 如果没有,我们将输出一条错误消息并退出程序:
self.face_casc = cv2.CascadeClassifier(face_casc)
if self.face_casc.empty():
print 'Warning: Could not load face cascade:',
face_casc
raise SystemExit
由于很快就会明白的原因,我们还需要两个眼睛级联,为此我们以类似的方式进行:
self.left_eye_casc = cv2.CascadeClassifier(left_eye_casc)
if self.left_eye_casc.empty():
print 'Warning: Could not load left eye cascade:', left_eye_casc
raise SystemExit
self.right_eye_casc =
cv2.CascadeClassifier(right_eye_casc)
if self.right_eye_casc.empty():
print 'Warning: Could not load right eye cascade:', right_eye_casc
raise SystemExit
人脸检测在低分辨率灰度图像上效果最佳。 这就是为什么还要存储缩放因子(scale_factor)的原因,以便在必要时可以对输入图像的缩小版本进行操作:
self.scale_factor = scale_factor
在灰度图像中检测人脸
然后可以使用detect方法检测到脸部。 在这里,我们确保在缩小的灰度图像上运行:
def detect(self, frame):
frameCasc = cv2.cvtColor(cv2.resize(frame, (0, 0), fx=1.0 / self.scale_factor, fy=1.0 / self.scale_factor), cv2.COLOR_RGB2GRAY)
faces = self.face_casc.detectMultiScale(frameCasc,
scaleFactor=1.1, minNeighbors=3,
flags=cv2.cv.CV_HAAR_FIND_BIGGEST_OBJECT) * self.scale_factor
如果找到人脸,我们继续从边界框信息中提取头部区域,并将结果存储在head中:
for (x, y, w, h) in faces:
head = cv2.cvtColor(frame[y:y + h, x:x + w], cv2.COLOR_RGB2GRAY)
我们还将边界框绘制到输入图像上:
cv2.rectangle(frame, (x, y), (x + w, y + h), (100, 255, 0), 2)
如果成功,该方法应返回一个指示成功的布尔值(True),带标注的输入图像(frame)和提取的头部区域(head):
return True, frame, head
否则,如果未检测到脸部,则该方法使用布尔值(False)指示失败,并返回头部区域的不变输入图像(frame)和None:
return False, frame, None
预处理检测到的脸部
在检测到人脸之后,我们可能需要对提取的头部区域进行预处理,然后再对其进行分类。 尽管脸部级联相当准确,但是对于识别而言,重要的是所有脸部都必须直立并居于图像中心。 最好用图像说明这个想法。 考虑一棵树下悲伤的程序员:

由于他的情绪状态,程序员倾向于在低头的同时保持头部稍微向侧面倾斜。 通过脸部级联提取的脸部区域显示为右侧最左侧的灰度缩略图。 为了补偿头部的方向,我们旨在旋转和缩放面部,以使所有数据样本完美对齐。 这是FaceDetector类中align_head方法的工作:
def align_head(self, head):
height, width = head.shape[:2]
幸运的是,OpenCV 带有一些可以同时检测出睁眼和闭眼的眼睛级联,例如haarcascade_lefteye_2splits.xml和haarcascade_righteye_2splits.xml。 这使我们能够计算连接两只眼睛的中心的线与水平线之间的角度,以便我们可以相应地旋转面部。 另外,添加眼睛检测器将减少在我们的数据集中出现误报的风险,从而使我们仅在成功检测到头部和眼睛的情况下才添加数据样本。
从FaceDetector构造器中的文件加载这些眼睛级联后,将它们应用于输入图像(head):
left_eye_region = head[0.2*height:0.5*height, 0.1*width:0.5*width]
left_eye = self.left_eye_casc.detectMultiScale(left_eye_region, scaleFactor=1.1, minNeighbors=3, flags=cv2.cv.CV_HAAR_FIND_BIGGEST_OBJECT)
在此,重要的是,我们仅将一个较小的相关区域(left_eye_region;将上图右上角的小缩略图进行比较)传递给眼睛级联。 为简单起见,我们使用集中在面部区域上半部分的硬编码值,并假设左眼在左半部分。
如果检测到眼睛,我们将提取其中心点的坐标:
left_eye_center = None
for (xl, yl, wl, hl) in left_eye:
# find the center of the detected eye region
left_eye_center = np.array([0.1 * width + xl + wl / 2, 0.2 * height + yl + hl / 2])
break # need only look at first, largest eye
然后,我们对右眼进行相同的操作:
right_eye_region = head[0.2*height:0.5*height, 0.5*width:0.9*width]
right_eye = self.right_eye_casc.detectMultiScale(right_eye_region, scaleFactor=1.1, minNeighbors=3,flags=cv2.cv.CV_HAAR_FIND_BIGGEST_OBJECT)
right_eye_center = None
for (xr, yr, wr, hr) in right_eye:
# find the center of the detected eye region
right_eye_center = np.array([0.5 * width + xr + wr / 2, 0.2 * height + yr + hr / 2])
break # need only look at first, largest eye
如前面的所述,如果我们没有检测到两只眼睛,则会将样本丢弃为假正例:
if left_eye_center is None or right_eye_center is None:
return False, head
现在,这就是魔术发生的地方。 无论我们检测到的面部有多弯曲,在将其添加到训练集中之前,我们都希望眼睛精确地位于图像宽度的 25% 和 75%(以使面部位于中心)和 20 图像高度的百分比:
desired_eye_x = 0.25
desired_eye_y = 0.2
desired_img_width = 200
desired_img_height = desired_img_width
这可以通过使用cv2.warpAffine扭曲图像来实现(请记住第 3 章,“通过特征匹配和透视变换查找对象”)。 首先,我们计算连接两只眼睛的线和一条水平线之间的角度(以度为单位):
eye_center = (left_eye_center + right_eye_center) / 2
eye_angle_deg = np.arctan2(
right_eye_center[1] – left_eye_center[1],
right_eye_center[0] – left_eye_center[0]) *
180.0 / cv2.cv.CV_PI
然后,我们得出一个缩放因子,它将两只眼睛之间的距离缩放为图像宽度的 50%:
eye_size_scale = (1.0 - desired_eye_x * 2) * desired_img_width / np.linalg.norm(right_eye_center – left_eye_center)
有了这两个参数(eye_angle_deg和eye_size_scale),我们现在可以提出一个合适的旋转矩阵来转换图像:
rot_mat = cv2.getRotationMatrix2D(tuple(eye_center), eye_angle_deg, eye_size_scale)
我们确保的眼睛中心在图像中居中:
rot_mat[0,2] += desired_img_width*0.5 – eye_center[0]
rot_mat[1,2] += desired_eye_y*desired_img_height – eye_center[1]
最后,我们获得了面部区域的直立缩放版本,看起来像先前图像的右下方缩略图:
res = cv2.warpAffine(head, rot_mat, (desired_img_width, desired_img_height))
return True, res
面部表情识别
面部表情识别管道由chapter7.py封装。 该文件包含一个交互式 GUI,该 GUI 在两种模式下(训练和测试)运行,如前所述。
为了到达我们的端到端应用,我们需要涵盖以下三个步骤:
- 在训练模式下加载
chapter7.pyGUI,以组装训练集。 - 通过
train_test_mlp.py在训练集上训练 MLP 分类器。 由于此步骤可能需要很长时间,因此该过程将以其自己的脚本进行。 成功训练后,将训练后的权重存储在文件中,以便我们可以在下一步中加载预训练的 MLP。 - 在测试模式下加载
chapter7.pyGUI,以实时对实时视频流上的面部表情进行分类。 此步骤涉及加载几个预训练的级联分类器以及我们的预训练的 MLP 分类器。 然后,这些分类器将应用于每个捕获的视频帧。
组装训练套件
在训练 MLP 之前,我们需要组装适当的训练集。 因为有可能您的脸还不属于任何数据集(NSA 的私人收藏不算在内),所以我们必须组装我们自己的脸。 通过返回上一章的 GUI 应用,可以最轻松地完成此操作,该应用可以访问网络摄像头并在视频流的每个帧上进行操作。
GUI 将为用户提供记录以下六个情感表达之一的选项:中立,快乐,悲伤,惊讶,生气和恶心。 单击按钮后,该应用将对检测到的面部区域进行快照,并在退出时将所有收集的数据样本存储在文件中。 然后,可以从文件中加载这些样本,并将其用于训练train_test_mlp.py中的 MLP 分类器,如先前在第二步中所述。
运行屏幕截图
为了运行此应用(chapter7.py),我们需要使用cv2.VideoCapture设置屏幕截图,并将句柄传递给FaceLayout类:
import time
import wx
from os import path
import cPickle as pickle
import cv2
import numpy as np
from datasets import homebrew
from detectors import FaceDetector
from classifiers import MultiLayerPerceptron
from gui import BaseLayout
def main():
capture = cv2.VideoCapture(0)
if not(capture.isOpened()):
capture.open()
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
# start graphical user interface
app = wx.App()
layout = FaceLayout(None, -1, 'Facial Expression Recognition', capture)
layout.init_algorithm()
layout.Show(True)
app.MainLoop()
if __name__ == '__main__':
main()
注意
如果刚安装了某些非规范的 OpenCV 版本,则帧宽度和帧权重参数的名称可能会稍有不同(例如cv3.CAP_PROP_FRAME_WIDTH)。 但是,在较新的发行版中,访问旧的 OpenCV1 子模块cv及其变量cv2.cv.CV_CAP_PROP_FRAME_WIDTH和cv2.cv.CV_CAP_PROP_FRAME_HEIGHT是最容易的。
GUI 构造器
与前面的章节相似,该应用的 GUI 是通用BaseLayout的自定义版本:
class FaceLayout(BaseLayout):
我们将训练样本和标签初始化为空列表,并确保在关闭窗口时调用_on_exit方法,以便将训练数据转储到文件中:
def _init_custom_layout(self):
# initialize data structure
self.samples = []
self.labels = []
# call method to save data upon exiting
self.Bind(wx.EVT_CLOSE, self._on_exit)
我们还必须加载几个分类器以进行预处理和(随后)进行实时分类。 为了方便起见,提供了默认文件名:
def init_algorithm(
self, save_training_file='datasets/faces_training.pkl',load_preprocessed_data='datasets/faces_preprocessed.pkl',load_mlp='params/mlp.xml',
face_casc='params/haarcascade_frontalface_default.xml',left_eye_casc='params/haarcascade_lefteye_2splits.xml',right_eye_casc='params/haarcascade_righteye_2splits.xml'):
在这里,save_training_file表示在完成数据采集后将所有训练样本存储在其中的泡菜文件的名称:
self.dataFile = save_training_file
如上一节所述,这三个级联将传递给FaceDetector类:
self.faces = FaceDetector(face_casc, left_eye_casc, right_eye_casc)
顾名思义,其余两个参数(load_preprocessed_data和load_mlp)与使用预训练的 MLP 分类器对检测到的面部进行实时分类有关:
# load preprocessed dataset to access labels and PCA
# params
if path.isfile(load_preprocessed_data):
(_, y_train), (_, y_test), self.pca_V, self.pca_m =homebrew.load_from_file(load_preprocessed_data)
self.all_labels = np.unique(np.hstack((y_train,
y_test)))
# load pre-trained multi-layer perceptron
if path.isfile(load_mlp):
self.MLP = MultiLayerPerceptron( np.array([self.pca_V.shape[1], len(self.all_labels)]), self.all_labels)
self.MLP.load(load_mlp)
如果缺少测试模式所需的任何部件,我们将打印警告并完全禁用测试模式:
else:
print "Warning: Testing is disabled"
print "Could not find pre-trained MLP file ",
load_mlp
self.testing.Disable()
else:
print "Warning: Testing is disabled"
print "Could not find preprocessed data file ", loadPreprocessedData
self.testing.Disable()
GUI 布局
的布局创建又被推迟到_create_custom_layout的方法中。 我们使布局尽可能简单:我们为获取的视频帧创建一个面板,并在其下方绘制一行按钮。
这个想法是,然后单击六个单选按钮之一以指示您要记录的面部表情,然后将您的头部放在边界框中,然后单击Take Snapshot按钮。
在当前摄像机框架下方,我们放置两个单选按钮以选择训练或测试模式,并通过指定style=wx.RB_GROUP来告诉 GUI 两者是互斥的:
def _create_custom_layout(self):
# create horizontal layout with train/test buttons
pnl1 = wx.Panel(self, -1)
self.training = wx.RadioButton(pnl1, -1, 'Train', (10, 10), style=wx.RB_GROUP)
self.testing = wx.RadioButton(pnl1, -1, 'Test')
hbox1 = wx.BoxSizer(wx.HORIZONTAL)
hbox1.Add(self.training, 1)
hbox1.Add(self.testing, 1)
pnl1.SetSizer(hbox1)
另外,我们希望按钮单击事件分别绑定到self._on_training和self._on_testing方法:
self.Bind(wx.EVT_RADIOBUTTON, self._on_training, self.training)
self.Bind(wx.EVT_RADIOBUTTON, self._on_testing, self.testing)
第二行应包含六个面部表情按钮的类似安排:
# create a horizontal layout with all buttons
pnl2 = wx.Panel(self, -1 )
self.neutral = wx.RadioButton(pnl2, -1, 'neutral', (10, 10), style=wx.RB_GROUP)
self.happy = wx.RadioButton(pnl2, -1, 'happy')
self.sad = wx.RadioButton(pnl2, -1, 'sad')
self.surprised = wx.RadioButton(pnl2, -1, 'surprised')
self.angry = wx.RadioButton(pnl2, -1, 'angry')
self.disgusted = wx.RadioButton(pnl2, -1, 'disgusted')
hbox2 = wx.BoxSizer(wx.HORIZONTAL)
hbox2.Add(self.neutral, 1)
hbox2.Add(self.happy, 1)
hbox2.Add(self.sad, 1)
hbox2.Add(self.surprised, 1)
hbox2.Add(self.angry, 1)
hbox2.Add(self.disgusted, 1)
pnl2.SetSizer(hbox2)
快照按钮置于单选按钮下方,并将绑定到_on_snapshot方法:
pnl3 = wx.Panel(self, -1)
self.snapshot = wx.Button(pnl3, -1, 'Take Snapshot')
self.Bind(wx.EVT_BUTTON, self.OnSnapshot, self.snapshot)
hbox3 = wx.BoxSizer(wx.HORIZONTAL)
hbox3.Add(self.snapshot, 1)
pnl3.SetSizer(hbox3)
如下所示:

为了使这些更改生效,需要将创建的面板添加到现有面板的列表中:
# display the button layout beneath the video stream
self.panels_vertical.Add (pnl1, flag=wx.EXPAND | wx.TOP, border=1)
self.panels_vertical.Add(pnl2, flag=wx.EXPAND | wx.BOTTOM, border=1)
self.panels_vertical.Add(pnl3, flag=wx.EXPAND | wx.BOTTOM, border=1)
可视化管道的其余部分由BaseLayout类处理。 现在,每当用户单击self.testing按钮时,我们就不再想要记录训练样本,而是切换到测试模式。 在测试模式下,不应启用与训练相关的按钮,如下图所示:

这可以通过以下禁用所有相关按钮的方法来实现:
def _on_testing(self, evt):
"""Whenever testing mode is selected, disable all training-related buttons"""
self.neutral.Disable()
self.happy.Disable()
self.sad.Disable()
self.surprised.Disable()
self.angry.Disable()
self.disgusted.Disable()
self.snapshot.Disable()
类似地,当我们切换回训练模式时,应该再次启用按钮:
def _on_training(self, evt):
"""Whenever training mode is selected, enable all
training-related buttons"""
self.neutral.Enable()
self.happy.Enable()
self.sad.Enable()
self.surprised.Enable()
self.angry.Enable()
self.disgusted.Enable()
self.snapshot.Enable()
处理当前帧
可视化管道的其余部分由BaseLayout类处理。 我们只需要确保提供_process_frame方法即可。 此方法首先在当前帧的缩小灰度版本中检测面部,如上一节所述:
def _process_frame(self, frame):
success, frame, self.head = self.faces.detect(frame)
如果找到面部,则success为True,并且该方法可以访问当前帧的标注版本(frame)和提取的头部区域(self.head)。 请注意,我们存储提取的头部区域以供进一步参考,以便可以在_on_snapshot中访问它。
当我们谈论测试模式时,我们将返回此方法,但是现在,这是我们需要知道的全部内容。 不要忘记传递经过处理的帧:
return frame
将训练样本添加到训练集中
单击Take Snapshot按钮时,将调用_on_snapshot方法。 此方法通过检查所有单选按钮的值来检测我们尝试记录的情感表达,并相应地分配一个类别标签:
def _on_snapshot(self, evt):
if self.neutral.GetValue():
label = 'neutral'
elif self.happy.GetValue():
label = 'happy'
elif self.sad.GetValue():
label = 'sad'
elif self.surprised.GetValue():
label = 'surprised'
elif self.angry.GetValue():
label = 'angry'
elif self.disgusted.GetValue():
label = 'disgusted'
接下来,我们需要查看检测到的当前帧的面部区域(由_process_frame存储在self.head中),并将其与所有其他收集的帧对齐。 也就是说,我们希望所有的脸都直立并且眼睛对齐。 否则,如果我们不对齐数据样本,则会冒使分类器将眼睛与鼻子进行比较的风险。 由于此计算可能会很昂贵,因此我们不会将其应用于所有帧,而只会在拍摄快照时应用。 对齐通过以下方法进行:
if self.head is None:
print "No face detected"
else:
success, head = self.faces.align_head(self.head)
如果此方法返回success的True,表明样本已与所有其他样本成功对齐,则将样本添加到数据集中:
if success:
print "Added sample to training set"
self.samples.append(head.flatten())
self.labels.append(label)
else:
print "Could not align head (eye detection failed?)"
现在剩下要做的就是确保我们在退出时保存训练集。
将完整的训练集转储到文件中
退出应用后(例如,通过单击窗口的关闭按钮),将触发事件EVT_CLOSE,该事件绑定到_on_exit方法。 此方法只是将收集的样本和相应的类标签转储到文件中:
def _on_exit(self, evt):
"""Called whenever window is closed"""
# if we have collected some samples, dump them to file
if len(self.samples) > 0:
但是,我们要确保我们不会意外覆盖以前存储的训练集。 如果提供的文件名已经存在,我们将添加一个后缀并将数据保存到新文件名中:
# make sure we don't overwrite an existing file
if path.isfile(self.data_file):
filename, fileext = path.splitext(self.data_file)
offset = 0
while True: # a do while loop
file = filename + "-" + str(offset) + fileext
if path.isfile(file):
offset += 1
else:
break
self.data_file = file
一旦创建了未使用的文件名,就可以通过使用 Pickle 模块将数据转储到文件中:
f = open(self.dataFile, 'wb')
pickle.dump(self.samples, f)
pickle.dump(self.labels, f)
f.close()
退出后,我们会通知用户已创建了文件,并确保正确释放了所有数据结构:
print "Saved", len(self.samples), "samples to", self.data_file
self.Destroy()
这是来自组合训练集 I 的一些示例:

特征提取
我们先前曾提出的观点,即发现最能描述数据的特征通常是整个学习任务的重要组成部分。 我们还研究了常用的预处理方法,例如均值减法和归一化。 在这里,我们将研究在面部识别方面具有悠久传统的另一种方法:主成分分析(PCA)。
预处理数据集
与第 6 章,“学习识别交通标志”相似,我们在dataset/homebrew.py中编写了一个新的数据集解析器,将解析我们的自组装训练集。 我们定义了一个load_data函数,该函数将解析数据集,执行特征提取,将数据分为训练和测试集并返回结果:
import cv2
import numpy as np
import csv
from matplotlib import cm
from matplotlib import pyplot as plt
from os import path
import cPickle as pickle
def load_data(load_from_file, test_split=0.2, num_components=50,
save_to_file=None, plot_samples=False, seed=113):
"""load dataset from pickle """
在这里,load_from_file指定了我们在上一节中创建的数据文件的路径。 我们还可以指定另一个名为save_to_file的文件,该文件将包含特征提取后的数据集。 这将在以后执行实时分类时有所帮助。
因此,第一步是尝试打开load_from_file。 如果文件存在,则使用 Pickle 模块加载samples和labels数据结构; 否则,我们抛出一个错误:
# prepare lists for samples and labels
X = []
labels = []
if not path.isfile(load_from_file):
print "Could not find file", load_from_file
return (X, labels), (X, labels), None, None
else:
print "Loading data from", load_from_file
f = open(load_from_file, 'rb')
samples = pickle.load(f)
labels = pickle.load(f)
print "Loaded", len(samples), "training samples"
如果文件已成功加载,我们将对所有样本执行 PCA。 num_components变量指定我们要考虑的主要成分的数量。 该函数还返回集合中每个样本的基础向量列表(V)和平均值(m):
# perform feature extraction
# returns preprocessed samples, PCA basis vectors & mean
X, V, m = extract_features(samples, num_components=num_components)
如前所述,必须将用于训练分类器的样本与用于测试分类器的样本分开。 为此,我们将数据进行混洗并将其分成两个单独的集合,以使训练集包含所有样本的一部分(1 - test_split),而其余样本属于测试集:
# shuffle dataset
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(labels)
# split data according to test_split
X_train = X[:int(len(X)*(1-test_split))]
y_train = labels[:int(len(X)*(1-test_split))]
X_test = X[int(len(X)*(1-test_split)):]
y_test = labels[int(len(X)*(1-test_split)):]
如果指定,我们要将预处理的数据保存到文件中:
if save_to_file is not None:
# dump all relevant data structures to file
f = open(save_to_file, 'wb')
pickle.dump(X_train, f)
pickle.dump(y_train, f)
pickle.dump(X_test, f)
pickle.dump(y_test, f)
pickle.dump(V, f)
pickle.dump(m, f)
f.close()
print "Save preprocessed data to", save_to_file
最后,我们可以返回提取的数据:
return (X_train, y_train), (X_test, y_test), V, m
主成分分析
PCA 是一种降维缩减技术,在处理高维数据时会很有用。 从某种意义上讲,您可以将图像视为高维空间中的一个点。 如果将高度为m和宽度为n的 2D 图像展平(通过合并所有行或所有列),我们将获得长度为m × n的(特征)向量。 该向量中的第i个元素的值是图像中第i个像素的灰度值。 为了描述具有这些确切尺寸的每个可能的 2D 灰度图像,我们将需要一个m × n维向量空间,其中包含 256 个提升为m × n向量的幂的向量。 哇! 考虑这些数字时想到的一个有趣的问题如下:是否可以有一个较小,更紧凑的向量空间(使用少于m × n特征)来很好地描述所有这些图像? 毕竟,我们之前已经意识到灰度值并不是内容的最有用信息。
这就是 PCA 的用武之地。考虑一个数据集,我们从中准确地提取了两个特征。 这些特征可能是x和y位置的像素的灰度值,但它们可能比这更复杂。 如果沿这两个特征轴绘制数据集,则数据可能位于某个多元高斯范围内,如下图所示:
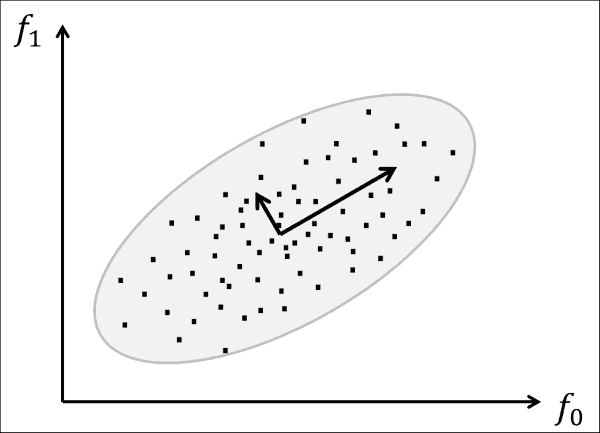
PCA 的作用是旋转所有数据点,直到数据与两个轴(两个插图向量)对齐,这两个轴解释了大多数扩散的数据。 PCA 认为这两个轴是最有用的,因为如果沿着它们走动,可以看到大多数数据点是分开的。 用更专业的术语来说,PCA 旨在通过正交线性变换将数据变换为新的坐标系。 选择新坐标系时,如果将数据投影到这些新轴上,则第一个坐标(称为第一主成分)观察到最大方差。 在前面的图像中,绘制的小向量与协方差矩阵的特征向量相对应,这些向量发生了偏移,因此它们的尾部位于分布的均值处。
幸运的是,其他人已经想出了如何在 Python 中完成所有这些工作。 在 OpenCV 中,执行 PCA 就像调用cv2.PCACompute一样简单。 嵌入在我们的特征提取方法中,该选项的内容如下:
def extract_feature(X, V=None, m=None, num_components=50):
在这里,该函数可用于从头开始执行 PCA 或使用先前计算的一组基础向量(V)和均值(m),这在我们想要进行实时分类的测试中很有用。 通过num_components指定要考虑的主要组件数。 如果我们未指定任何可选参数,则将对X中的所有数据样本从头开始执行 PCA:
if V is None or m is None:
# need to perform PCA from scratch
if num_components is None:
num_components = 50
# cols are pixels, rows are frames
Xarr = np.squeeze(np.array(X).astype(np.float32))
# perform PCA, returns mean and basis vectors
m, V = cv2.PCACompute(Xarr)
PCA 的优点在于,根据定义,第一个主要成分解释了大部分数据差异。 换句话说,第一个主成分是数据的最有用的信息。 这意味着我们不需要保留所有组件就可以很好地表示数据! 我们可以将自己限制在num_components信息最丰富的国家:
# use only the first num_components principal components
V = V[:num_components]
最后,通过将以零为中心的原始数据投影到新坐标系上,来实现数据的压缩表示:
for i in xrange(len(X)):
X[i] = np.dot(V, X[i] - m[0, i])
return X, V, m
多层感知器
多层感知器(MLP)出现了一段时间。 MLP 是人工神经网络(ANN),用于将一组输入数据转换为一组输出数据。 MLP 的核心是和感知器,它类似于(但过于简化)生物神经元。 通过在多层中组合大量感知器,MLP 能够对其输入数据做出非线性决策。 此外,可以通过反向传播来训练 MLP,这使得它们对于监督学习非常有趣。
感知器
感知器是由 Frank Rosenblatt 于 1950 年代发明的一种二分类器。 感知器计算其输入的加权总和,如果该总和超过阈值,则输出1。 否则,输出0。 从某种意义上讲,感知器正在整合证据,表明其传入信号表明某个对象实例的存在(或不存在),如果该证据足够强大,则感知器将处于活动状态(或保持沉默)。 这与研究人员认为生物神经元在大脑中正在做(或可以用来做)的事情松散地联系在一起,因此,这个术语称为人工神经网络。
下图描绘了感知器的草图:
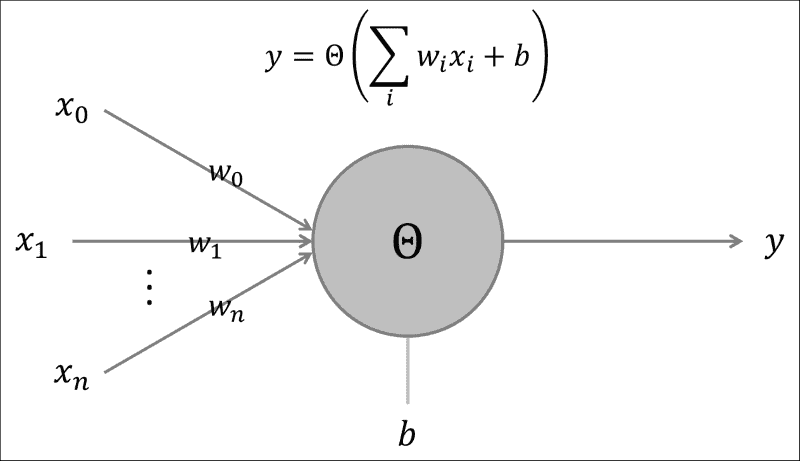
在这里,感知器计算其所有输入(x_i)的加权(w_i)和,并加上一个偏置项(b)。 该输入被输入到非线性激活函数(θ)中,该函数确定感知器的输出(y)。 在原始算法中,激活函数是 Heaviside 阶跃函数。 在 ANN 的现代实现中,激活函数可以是从 Sigmoid 到双曲正切函数的任何函数。 下图显示了 Heaviside 函数和 Sigmoid 函数:
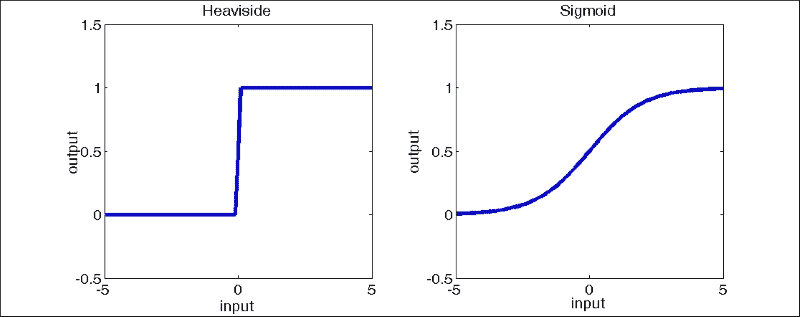
根据的激活函数,这些网络可能能够执行分类或回归。 传统上,仅在节点使用 Heaviside 步进函数时谈论 MLP。
深度架构
一旦确定了感知器,就可以将多个感知器组合成一个更大的网络。 多层感知器通常至少由三层组成,其中第一层为数据集的每个输入特征提供一个节点(或神经元),最后一层为每个类标签提供一个节点。 中间的层称为隐藏层。 下图显示了此前馈神经网络的示例:
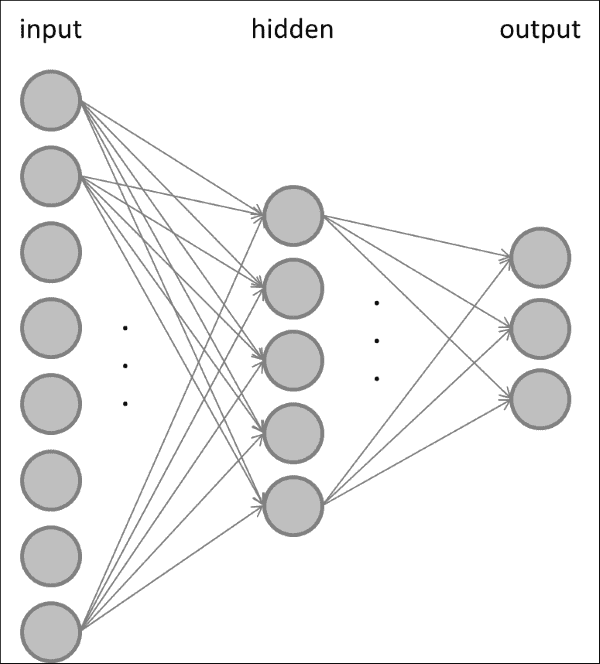
在前馈神经网络中,输入层中的某些或所有节点都连接到隐藏层中的所有节点,而隐藏层中的某些或所有节点都连接到输出层中的一些或全部节点。 您通常会选择输入层中的节点数等于数据集中的特征数,以便每个节点代表一个特征。 类似地,输出层中的节点数通常等于数据中的类数,因此,当显示类c的输入样本时,输出层中的第c个节点处于活动状态,而所有其他节点都保持沉默。
当然也可以有多个隐藏层。 通常,事先不清楚网络的最佳规模应该是多少。
通常,当您向网络中添加更多神经元时,您会看到训练集上的错误率降低,如下图所示(细的红色曲线):
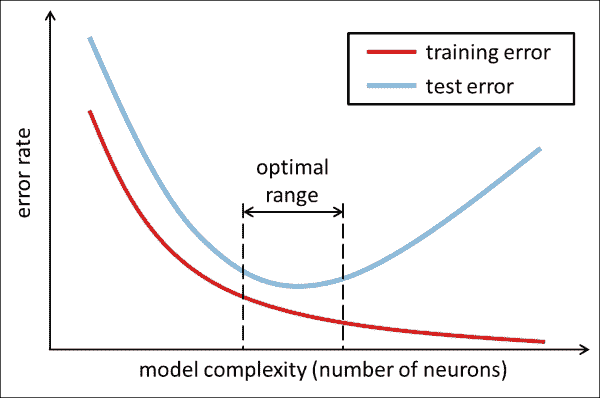
这是因为模型的表达能力或复杂性(也称为 Vapnik–Chervonenkis 或 VC 尺寸)随网络神经元大小的增加而增加。 但是,测试集的错误率(较厚的蓝色曲线)不能说相同! 取而代之的是,您会发现随着模型复杂度的增加,测试误差会降到最低,并且向网络中添加更多的神经元将不再改善泛化表现。 因此,您需要将神经网络的大小控制到上图中标记的最佳范围,这是网络实现最佳泛化表现的地方。
您可以这样想。 复杂性较弱的模型(位于图的最左侧)可能太小而无法真正理解要尝试学习的数据集,因此在训练集和测试集上都会产生较大的错误率。 这通常被称为欠拟合。 另一方面,图最右边的模型可能是如此复杂,以致于它开始在训练数据中记住每个样本的细节,而没有注意使样本与其他样本分开的一般属性。 因此,当模型必须预测以前从未见过的数据时,该模型将失败,从而在测试集上产生较大的错误率。 这通常称为过拟合。
相反,您要开发的模型既不适合也不适合。 通常,这只能通过反复试验才能实现; 也就是说,通过将网络规模视为需要根据要执行的确切任务进行调整和调整的超参数。
MLP 通过调整其权重进行学习,以便在显示类别为c的输入样本时,输出层中第c个节点处于活动状态,而其他所有节点均处于静默状态。 MLP 通过反向传播进行训练,这是一种计算损失函数相对于神经突触权重或神经元偏置的偏导数的算法。 网络。 然后,这些偏导数可用于更新网络中的权重和偏差,以逐步减少总体损失。
通过向网络呈现训练样本并观察网络的输出,可以获得损失函数。 通过观察哪些输出节点是活动的,哪些是静默的,我们可以计算出输出层在做什么与应该在做什么之间的相对误差(即损失函数)。 然后,我们对网络中的所有权重进行校正,以使误差随时间减小。 事实证明,隐藏层中的错误取决于输出层,输入层中的错误取决于隐藏层和输出层中的错误。 因此,从某种意义上讲,错误(反向)通过网络传播。 在 OpenCV 中,通过在训练参数中指定cv3.ANN_MLP_TRAIN_PARAMS_BACKPROP来使用反向传播。
注意
梯度下降有两种常见的方式:在随机梯度下降中,我们在每次演示训练示例后更新权重,而在批量学习中,我们分批训练示例,并仅在每批演示后更新权重。 在这两种情况下,我们都必须确保仅对每个样本调整权重(通过调整学习率),以使网络随着时间的流逝逐渐收敛到稳定的解决方案。
用于面部表情识别的 MLP
类似于第 6 章,“学习识别交通标志”一样,我们将开发一个基于分类器基本类建模的多层感知器类。 基本分类器包含一种用于训练的方法(其中模型适合于训练数据)和用于测试的方法(其中通过将训练后的模型应用于测试数据来对其进行评估):
from abc import ABCMeta, abstractmethod
class Classifier:
"""Abstract base class for all classifiers"""
__metaclass__ = ABCMeta
@abstractmethod
def fit(self, X_train, y_train):
pass
@abstractmethod
def evaluate(self, X_test, y_test, visualize=False):
pass
在此,X_train和X_test分别对应于训练数据和测试数据,其中每行代表一个样本,每列代表该样本的特征值。 训练和测试标签分别作为y_train和y_test向量传递。
因此,我们定义了一个新类MultiLayerPerceptron,它从分类器基类派生而来:
class MultiLayerPerceptron(Classifier):
此类的构造方法接受一个名为layer_sizes的数组,该数组指定网络各层中神经元的数量;另一个名为class_labels的数组,该数组拼出所有可用的类标签。 第一层将为输入中的每个特征包含一个神经元,而最后一层将为每个输出类包含一个神经元:
def __init__(self, layer_sizes, class_labels, params=None):
self.num_features = layer_sizes[0]
self.num_classes = layer_sizes[-1]
self.class_labels = class_labels
self.params = params or dict()
构造器通过称为cv2.ANN_MLP的 OpenCV 模块初始化多层感知器:
self.model = cv2.ANN_MLP()
self.model.create(layer_sizes)
为了方便用户,MLP 类允许对通过class_labels枚举的字符串标签进行操作(例如中性,高兴和悲伤)。 在后台,该类将从字符串到整数以及从整数到字符串来回转换,因此cv2.ANN_MLP仅暴露给整数。 这些转换由以下两个私有方法处理:
def _labels_str_to_num(self, labels):
""" convert string labels to their corresponding ints """
return np.array([int(np.where(self.class_labels == l)[0]) for l in labels])
def _labels_num_to_str(self, labels):
"""Convert integer labels to their corresponding string names """
return self.class_labels[labels]
加载和保存方法为基础cv2.ANN_MLP类提供了简单的包装器:
def load(self, file):
""" load a pre-trained MLP from file """
self.model.load(file)
def save(self, file):
""" save a trained MLP to file """
self.model.save(file)
训练 MLP
遵循Classifier基类定义的要求,我们需要以fit方法执行训练:
def fit(self, X_train, y_train, params=None):
""" fit model to data """
if params is None:
params = self.params
在这里,params是一个可选词典,其中包含许多与训练相关的选项,例如在训练期间要使用的终止标准(term_crit)和学习算法(train_method)。 例如,要使用反向传播并在 300 次迭代后或当损失达到小于 0.01 的值时终止训练,请指定params,如下所示:
params = dict(
term_crit = (cv2.TERM_CRITERIA_COUNT, 300, 0.01), train_method = cv2.ANN_MLP_TRAIN_PARAMS_BACKPROP)
由于cv2.ANN_MLP模块的train方法不允许使用整数值的类标签,因此我们需要先将y_train转换为仅包含零和一的“单热”代码,然后再将其输入train方法:
y_train = self._labels_str_to_num(y_train)
y_train = self._one_hot(y_train).reshape(-1, self.num_classes)
self.model.train(X_train, y_train, None, params=params)
在_one_hot中处理了单热代码:
def _one_hot(self, y_train):
"""Convert a list of labels into one-hot code """
需要将y_train中的每个类标签c转换为零和一的self.num_classes长向量,其中所有条目都是零,除了第c个数字(即c)是 1。 我们通过分配零向量来准备此操作:
num_samples = len(y_train)
new_responses = np.zeros(num_samples * self.num_classes, np.float32)
然后,我们确定与所有第c个类标签相对应的向量的索引:
resp_idx = np.int32(y_train +
np.arange(num_samples) self.num_classes)
然后需要将这些索引处的向量元素设置为一个:
new_responses[resp_idx] = 1
return new_responses
测试 MLP
遵循Classifier基类定义的要求,我们需要以evaluate方法执行训练:
def evaluate(self, X_test, y_test, visualize=False):
""" evaluate model performance """
与上一章类似,我们将在准确率,准确率和查全率方面评估分类器的表现。 要重用我们先前的代码,我们再次需要提供一个 2D 投票矩阵,其中每一行代表测试集中的数据样本,而第c列包含第c类的投票数。
在感知器世界中,投票矩阵实际上有一个简单的解释:输出层中第c个神经元的活动越高,第c类的投票越强。 因此,我们所需要做的就是读出输出层的活动并将其插入我们的准确率方法中:
ret, Y_vote = self.model.predict(X_test)
y_test = self._labels_str_to_num(y_test)
accuracy = self._accuracy(y_test, Y_vote)
precision = self._precision(y_test, Y_vote)
recall = self._recall(y_test, Y_vote)
return (accuracy, precision, recall)
此外,我们向用户提供了预测方法,因此甚至可以预测单个数据样本的标签。 当我们执行实时分类时,这是有用的,其中我们不想遍历所有测试样本,而只考虑当前帧。 此方法只是预测任意数量样本的标签,并将类标签作为人类可读的字符串返回:
def predict(self, X_test):
""" predict the labels of test data """
ret, Y_vote = self.model.predict(X_test)
# find the most active cell in the output layer
y_hat = np.argmax(Y_vote, 1)
# return string labels
return self._labels_num_to_str(y_hat)
运行脚本
可以使用train_test_mlp.py脚本对 MLP 分类器进行训练和测试。 该脚本首先解析自制数据集并提取所有类标签:
import cv2
import numpy as np
from datasets import homebrew
from classifiers import MultiLayerPerceptron
def main():
# load training data
# training data can be recorded using chapter7.py in training
# mode
(X_train, y_train),(X_test, y_test) =
homebrew.load_data("datasets/faces_training.pkl", num_components=50, test_split=0.2, save_to_file="datasets/faces_preprocessed.pkl", seed=42)
if len(X_train) == 0 or len(X_test) == 0:
print "Empty data"
raise SystemExit
# convert to numpy
X_train = np.squeeze(np.array(X_train)).astype(np.float32)
y_train = np.array(y_train)
X_test = np.squeeze(np.array(X_test)).astype(np.float32)
y_test = np.array(y_test)
# find all class labels
labels = np.unique(np.hstack((y_train, y_test)))
我们还确保提供上述一些有效的终止条件:
params = dict( term_crit = (cv2.TERM_CRITERIA_COUNT, 300, 0.01), train_method=cv2.ANN_MLP_TRAIN_PARAMS_BACKPROP, bp_dw_scale=0.001, bp_moment_scale=0.9 )
通常,先验未知神经网络的最佳大小,但是需要调整超参数。 最后,我们希望网络能够为我们提供最佳的泛化表现(即在测试集上具有最佳准确率度量的网络)。 由于我们不知道答案,因此我们将在循环中运行许多不同大小的 MLP,并将最好的 MLP 存储在名为saveFile的文件中:
save_file = 'params/mlp.xml'
num_features = len(X_train[0])
num_classes = len(labels)
# find best MLP configuration
print "1-hidden layer networks"
best_acc = 0.0 # keep track of best accuracy
for l1 in xrange(10):
# gradually increase the hidden-layer size
layer_sizes = np.int32([num_features,
(l1 + 1) * num_features / 5,
num_classes])
MLP = MultiLayerPerceptron(layer_sizes, labels)
print layer_sizes
MLP 在X_train上受过训练,并在X_test上进行过测试:
MLP.fit(X_train, y_train, params=params)
(acc, _, _) = MLP.evaluate(X_train, y_train)
print " - train acc = ", acc
(acc, _, _) = MLP.evaluate(X_test, y_test)
print " - test acc = ", acc
最后,最好的 MLP 保存到文件中:
if acc > best_acc:
# save best MLP configuration to file
MLP.save(saveFile)
best_acc = acc
然后,可以通过将loadMLP='params/mlp.xml'传递给FaceLayout类的init_algorithm方法,将包含网络配置和学习权重的保存的params/mlp.xml文件加载到主 GUI 应用(chapter7.py)中。 本章中的默认参数将确保所有内容都可以直接使用。
全部放在一起
为了使运行我们的应用,我们需要执行main函数例程(在chapter7.py中),该例程会加载预训练的级联分类器和预训练的多层感知器,并将它们应用于网络摄像头实时流。
但是,这一次,我们将选择显示测试的单选按钮,而不是收集更多的训练样本。 这将触发一个EVT_RADIOBUTTON事件,该事件绑定到FaceLayout._on_testing,禁用 GUI 中的所有与训练相关的按钮,并将应用切换到测试模式。 在这种模式下,将预训练的 MLP 分类器应用于实时流的每一帧,以尝试预测当前的面部表情。
如前所述,我们现在返回FaceLayout._process_frame:
def _process_frame(self, frame):
""" detects face, predicts face label in testing mode """
与我们之前讨论的内容相同,该方法从检测当前帧的缩小灰度版本中的面部开始:
success, frame, self.head = self.faces.detect(frame)
但是,在测试模式下,该函数还有更多:
# in testing mode: predict label of facial expression
if success and self.testing.GetValue():
为了将我们的训练后的 MLP 分类器应用于当前帧,我们需要像对整个训练集那样对当前帧应用相同的预处理。 对齐头部区域后,我们通过使用预加载的基向量(self.pca_V)和平均值(self.pca_m)应用 PCA:
# if face found: preprocess (align)
success, head = self.faces.align_head(self.head)
if success:
# extract features using PCA (loaded from file)
X, _, _ = homebrew.extract_features([head.flatten()], self.pca_V, self.pca_m)
然后,我们准备预测当前帧的类标签:
# predict label with pre-trained MLP
label = self.MLP.predict(np.array(X))[0]
由于predict方法已经返回了字符串标签,剩下要做的就是将其显示在当前帧的边框上方:
# draw label above bounding box
cv2.putText(frame, str(label), (x,y-20), cv2.FONT_HERSHEY_COMPLEX, 1, (0,255,0), 2)
break # need only look at first, largest face
最后,我们完成了!
return frame
最终结果如下所示:

尽管分类器仅在(大约)100 个训练样本上进行了训练,但是无论当前我的脸看起来有多失真,它都可以可靠地检测到实时流每一帧中的各种面部表情。 这很好地表明,学习到的神经网络既不会拟合数据,也不会拟合数据,因为即使是新数据样本,它也能够预测正确的类别标签。
总结
本书的最后一章真正地总结了我们的经验,使我们结合了各种技能,以开发出包括对象检测和对象识别在内的端到端应用。 我们熟悉 OpenCV 必须提供的一系列预训练的级联分类器,收集了我们自己的训练数据集,了解了多层感知器,并训练了它们来识别面部表情。 好吧,至少我的脸。
毫无疑问,分类器能够受益于我是数据集中唯一的主题的事实,但是借助您从本书中学到的所有知识和经验,现在该克服这些限制了! 您可以从小处着手,然后在夏季和冬季的白天和黑夜,在室内和室外的图像上训练分类器。 或者,也许您急于解决现实世界的数据集,并成为 Kaggle 面部表情识别挑战的一部分(请参阅这个页面。
如果您正在学习机器学习,您可能已经知道那里有各种可访问的库,例如 pylearn,scikit-learn 和 pycaffe。 深度学习爱好者可能希望研究 Theano 或 Torch。 最后,如果您发现自己受所有这些算法的困扰,并且没有适用于它们的数据集,请确保停在 UC Irvine 机器学习存储库。
恭喜你! 您现在是 OpenCV 专家。