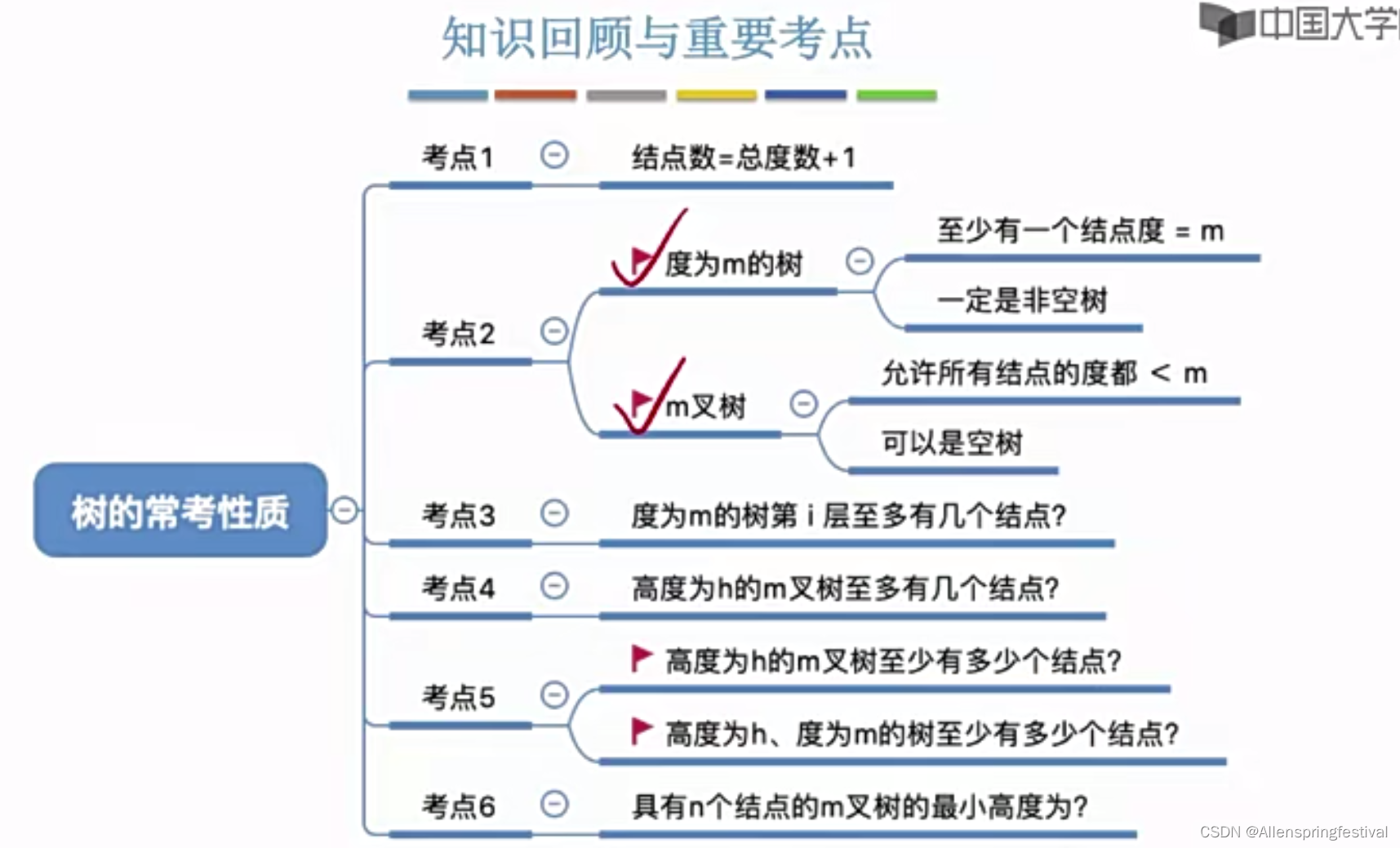
8. 优先队列
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在某些情况下,我们可能需要找出队列中的最大值或者最小值,例如使用一个队列保存计算机的任务,一般情况下计算机的任务都是有优先级的,我们需要在这些计算机的任务中找出优先级最高的任务先执行,执行完毕后就需要把这个任务从队列中移除。普通的队列要完成这样的功能,需要每次遍历队列中的所有元素,比较并找出最大值,效率不是很高,这个时候,我们就可以使用一种特殊的队列来完成这种需求,优先队列。

优先队列按照其作用不同,可以分为以下两种:
最大优先队列:
可以获取并删除队列中最大的值
最小优先队列:
可以获取并删除队列中最小的值
8.1 最大优先队列
我们之前学习过堆,而堆这种结构是可以方便的删除最大的值,所以,接下来我们可以基于堆去实现最大优先队列。
8.1.1 最大优先队列API设计

8.1.2 代码实现
package com.ynu.Java版算法.U8_优先队列.T1_最大优先队列;
//最大优先队列代码
public class MaxPriorityQueue<T extends Comparable<T>> {
//存储堆中的元素
private T[] items;
//记录堆中元素的个数
private int N;
public MaxPriorityQueue(int capacity) {
items = (T[]) new Comparable[capacity+1];
N = 0;
}
// 判断堆中的索引i处的元素是否小于索引j处的元素
private boolean less(int i,int j){
return items[i].compareTo(items[j]) < 0;
}
// 交换索引i,j处的元素
private void exch(int i,int j){
T temp = items[i];
items[i] = items[j];
items[j] = temp;
}
// 插入节点
public void insert(T t){
items[++N] = t; // ++N 保证是索引从1开始的
swim(N);
}
// 每次删除最大值
public T deleteMax(){
T max = items[1];
exch(1,N);
items[N--] = null;
sink(1);
return max;
}
// swim上浮算法,使索引k处的元素上浮到正确位置
private void swim(int k){
while (k > 1){
if (less(k,k/2)){ // 父节点大于当前节点 退出循环
break;
}
exch(k,k/2);
k = k/2;
}
}
// sink下沉算法,使索引k处的元素能够处于正确位置
private void sink(int k){
while (2*k <= N){
// 找到子节点的较大者
int max = 2*k;
if (2*k + 1 <= N){ // 存在右子节点
if (less(2*k,2*k+1)){
max = 2*k+1;
}
}
//比较当前结点和子结点中的较大者,如果当前结点不小,则结束循环
if (!less(k,max)){
break;
}
exch(k,max);
k = max;
}
}
public int size(){
return N;
}
public boolean isEmpty(){
return N==0;
}
}
package com.ynu.Java版算法.U8_优先队列.T1_最大优先队列;
public class Main {
public static void main(String[] args) {
MaxPriorityQueue<String> queue = new MaxPriorityQueue<>(20);
queue.insert("A");
queue.insert("D");
queue.insert("C");
queue.insert("E");
queue.insert("G");
queue.insert("H");
queue.insert("I");
while (!queue.isEmpty()){
String max = queue.deleteMax();
System.out.println(max);
}
// 输出剩余大小 应该是0了
System.out.println(queue.size());
}
}
8.2 最小优先队列
最小优先队列实现起来也比较简单,我们同样也可以基于堆来完成最小优先队列。
我们前面学习堆的时候,堆中存放数据元素的数组要满足都满足如下特性:
1.最大的元素放在数组的索引1处。
2.每个结点的数据总是大于等于它的两个子结点的数据。
其实我们之前实现的堆可以把它叫做最大堆,我们可以用相反的思想实现最小堆,让堆中存放数据元素的数组满足
如下特性:
1.最小的元素放在数组的索引1处。
2.每个结点的数据总是小于等于它的两个子结点的数据。
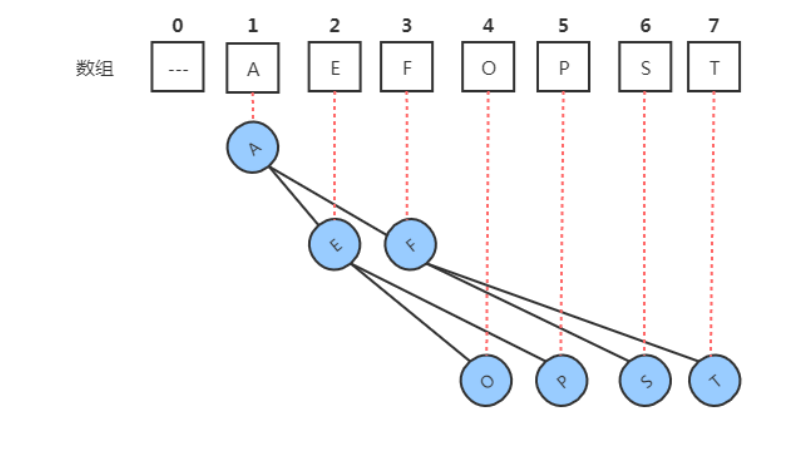
这样我们就能快速的访问到堆中最小的数据。
8.2.1 最小优先队列API设计

8.2.2 最小优先队列代码实现
package com.ynu.Java版算法.U8_优先队列.T2_最小优先队列;
public class MinPriorityQueue<T extends Comparable> {
private T[] items;
private int N;
public MinPriorityQueue(int capacity) {
items = (T[]) new Comparable[capacity+1];
}
// 判断索引i处的元素是否小于索引j处的元素
private boolean less(int i,int j){
return items[i].compareTo(items[j])<0;
}
public boolean isEmpty(){
return N==0;
}
// 交换索引i和索引j处的元素
private void exch(int i,int j){
T temp = items[i];
items[i] = items[j];
items[j] = temp;
}
//往堆中插入一个元素
public void insert(T t){
items[++N] = t;
swim(N);
}
// 删除队列中的最小值
public T delMin(){
T min = items[1];
exch(1,N);
items[N] = null;
N--;
sink(1);
return min;
}
// swim(k)
private void swim(int k){
while (k>1){
if (less(k,k/2)){
exch(k,k/2);
}
k = k/2;
}
}
// sink(k)
private void sink(int k){
while (2*k <= N){
int min = 2*k;
if (2*k+1 <= N){
if (!less(2*k,2*k+1)){
min = 2*k+1;
}
}
if (less(k,min)){
break;
}
exch(k,min);
k = min;
}
}
public int size() {
return N;
}
}
package com.ynu.Java版算法.U8_优先队列.T2_最小优先队列;
public class Main {
public static void main(String[] args) {
MinPriorityQueue<String> minPriorityQueue = new MinPriorityQueue<>(20);
minPriorityQueue.insert("D");
minPriorityQueue.insert("H");
minPriorityQueue.insert("I");
minPriorityQueue.insert("K");
minPriorityQueue.insert("A");
minPriorityQueue.insert("B");
minPriorityQueue.insert("C");
System.out.println(minPriorityQueue.size());
while (!minPriorityQueue.isEmpty()){
System.out.println(minPriorityQueue.delMin());
}
}
}
8.3 索引优先队列
在之前实现的最大优先队列和最小优先队列,他们可以分别快速访问到队列中最大元素和最小元素,但是他们有一个缺点,就是没有办法通过索引访问已存在于优先队列中的对象,并更新它们。为了实现这个目的,在优先队列的基础上,学习一种新的数据结构,索引优先队列。接下来我们以最小索引优先队列举列。
8.3.1 索引优先队列实现思路
步骤一:
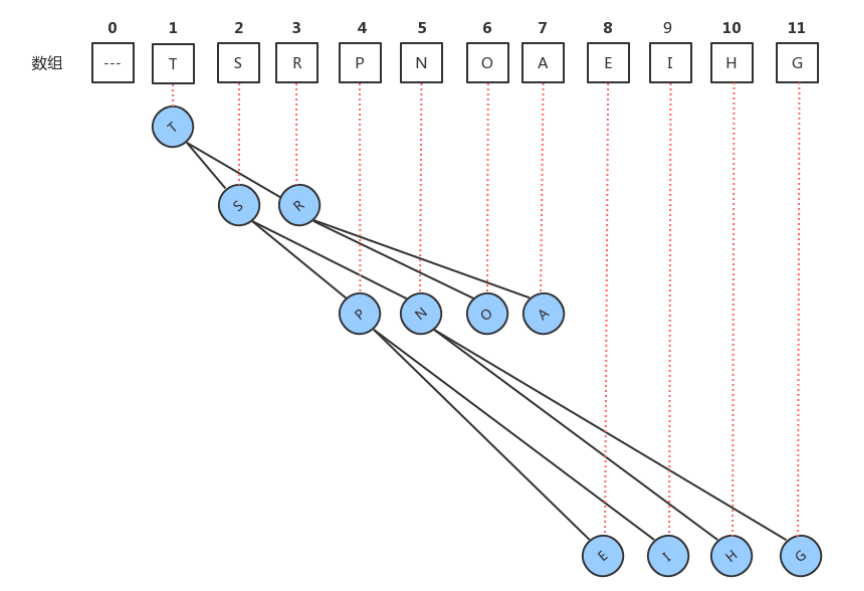
存储数据时,给每一个数据元素关联一个整数,例如insert(int k,T t),我们可以看做k是t关联的整数,那么我们的实现需要通过k这个值,快速获取到队列中t这个元素,此时有个k这个值需要具有唯一性。 最直观的想法就是我们可以用一个T[] items数组来保存数据元素,在insert(int k,T t)完成插入时,可以把k看做是 items数组的索引,把t元素放到items数组的索引k处,这样我们再根据k获取元素t时就很方便了,直接就可以拿到items[k]即可。
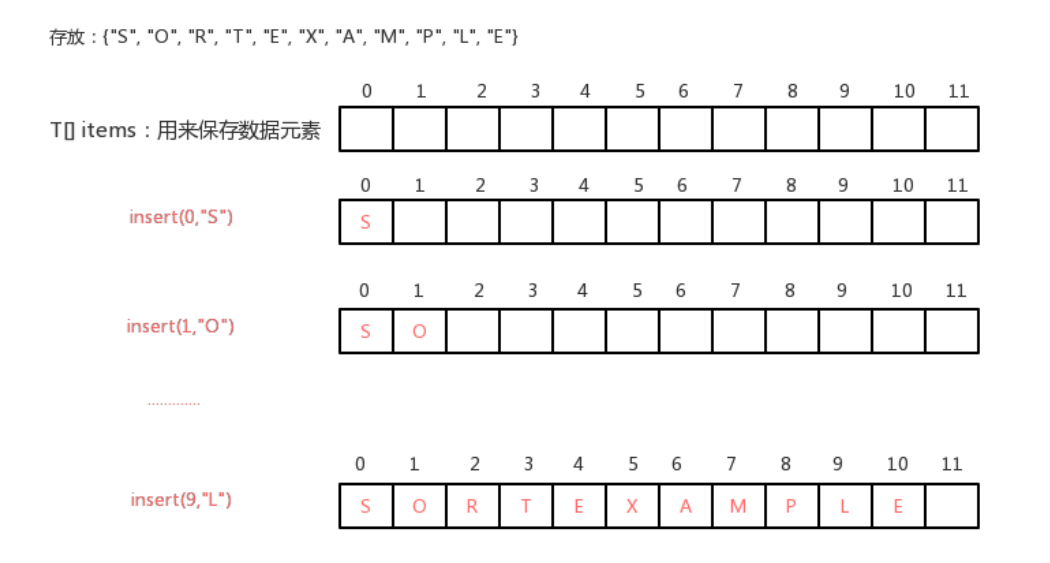
步骤二:
步骤一完成后的结果,虽然我们给每个元素关联了一个整数,并且可以使用这个整数快速的获取到该元素,但是, items数组中的元素顺序是随机的,并不是堆有序的,所以,为了完成这个需求,我们可以增加一个数组int[]pq,来保存每个元素在items数组中的索引,pq数组需要堆有序,也就是说,pq[1]对应的数据元素items[pq[1]]要小于等于pq[2]和pq[3]对应的数据元素items[pq[2]]和items[pq[3]]。
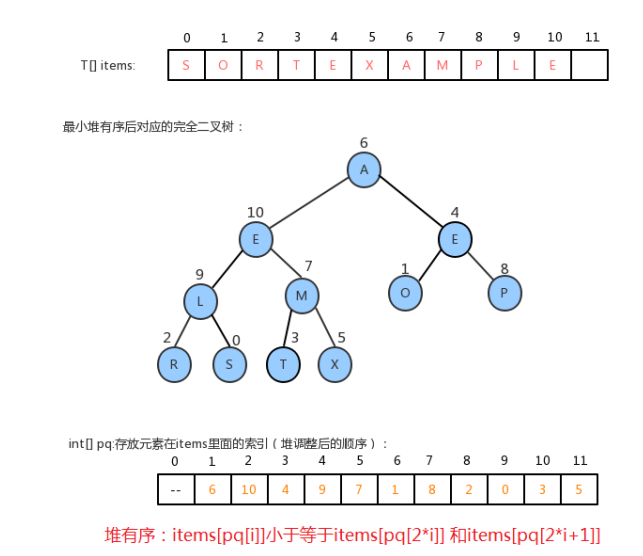
步骤三:
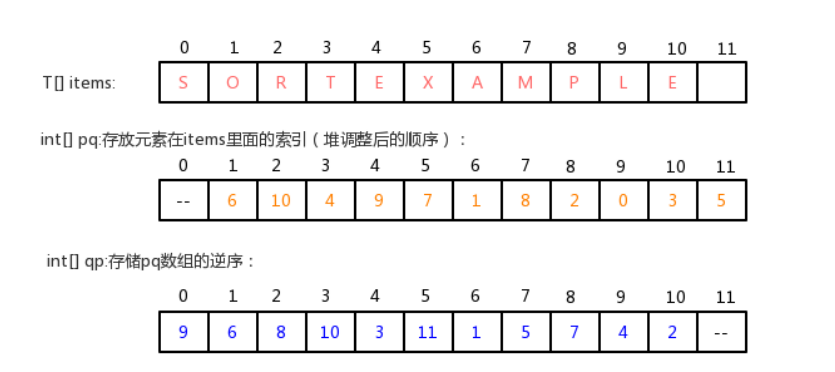
通过步骤二的分析,我们可以发现,其实我们通过上浮和下沉做堆调整的时候,其实调整的是pq数组。如果需要对items中的元素进行修改,比如让items[0]=“H”。那么很显然,我们需要对pq中的数据做堆调整,而且是调整 pq[9]中元素的位置。但现在就会遇到一个问题,我们修改的是items数组中0索引处的值,如何才能快速的知道需要挑中pq[9]中元素的位置呢?
最直观的想法就是遍历pq数组,拿出每一个元素和0做比较,如果当前元素是0,那么调整该索引处的元素即可, 但是效率很低。
我们可以另外增加一个数组,int[] qp,用来存储pq的逆序。例如:
在pq数组中:pq[1]=6;
那么在qp数组中,把6作为索引,1作为值,结果是:qp[6]=1;
8.3.2 索引优先队列API设计

8.3.3 索引优先队列代码实现
package com.ynu.Java版算法.U8_优先队列.T3_索引优先队列;
public class IndexMinPriorityQueue<T extends Comparable<T>> {
// 存储堆中的元素
public T[] items;
//保存每个元素在items数组中的索引,pq数组需要堆有序
private int[] pq;
//保存qp的逆序,pq的值作为索引,pq的索引作为值
private int[] qp;
// 记录堆中元素的个数
private int N;
// 获取索引index处的值
public T get(int index){
return items[index];
}
public IndexMinPriorityQueue(int capacity) {
items = (T[]) new Comparable[capacity+1];
pq = new int[capacity + 1]; // 因为是从索引为1处开始存储 所以需要capacity + 1
qp = new int[capacity + 1];
N = 0;
for (int i = 0; i < qp.length; i++) {
//默认情况下,qp逆序中不保存任何索引
qp[i] = -1;
}
}
//获取队列中元素的个数
public int size() {
return N;
}
//判断队列是否为空
public boolean isEmpty() {
return N == 0;
}
//判断堆中索引i处的元素是否小于索引j处的元素
private boolean less(int i, int j) {
//先通过pq找出items中的索引,然后再找出items中的元素进行对比
return items[pq[i]].compareTo(items[pq[j]]) < 0;
}
//交换堆中i索引和j索引处的值
private void exch(int i,int j){
// 先交换pq数组中的值
int temp = pq[i];
pq[i] = pq[j];
pq[j] = temp;
// 更新qp数组中的值
qp[pq[i]] = i;
qp[pq[j]] = j;
}
//判断k对应的元素是否存在
public boolean contains(int k){
return qp[k] != -1;
}
//最小元素关联的索引 minIndex items[minIndex]的值就是最小值
public int minIndex(){
return pq[1];
}
//使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置
private void swim(int k){
while (k > 1){
if (less(k,k/2)) {
exch(k,k/2);
}
k = k/2;
}
}
//使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置
private void sink(int k){
//如果当前结点已经没有子结点了,则结束下沉
while (2*k <= N){
int min = 2*k;
if (2*k +1 <=N && less(2*k+1,2*k)){
min = 2*k+1;
}
//如果当前结点的值比子结点中的较小值小,则结束下沉
if (less(k,min)){
break;
}
exch(k,min);
k = min;
}
}
//往队列中插入一个元素,并关联索引i
public void insert(int i,T t){
//如果索引i处已经存在了元素,则不让插入
if (contains(i)){
throw new RuntimeException("该索引已经存在");
}
// 个数加一
N++;
// 把元素放进items数组
items[i] = t;
// 使用pq存放i这个索引
pq[N] = i;
qp[i] = N;
//上浮items[pq[N]],让pq堆有序
swim(N);
}
//删除队列中最小的元素,并返回该元素关联的索引
public int delMin(){
int minIndex = pq[1];
// 交换pq索引1处的值和N处的值
exch(1,N);
//删除pq中索引N处的值
qp[pq[N]] = -1;
//删除items中的最小元素
items[minIndex] = null;
// 元素数量减一
N--;
//对pq[1]做下沉,让堆有序
sink(1);
return minIndex;
}
//删除索引i关联的元素
public void delete(int i){
// 找出i在pq中的索引
int k = qp[i];
// 把pq中索引k处的值和索引N处的值交换
exch(i,N);
// 删除qp中索引pq[N]处的值
qp[pq[N]] = -1;
// 删除索引pq中索引N处的值
pq[N] = -1;
//删除items中索引i处的值
items[i] = null;
//元素数量-1
N--;
//对pq[k]做下沉,让堆有序
sink(k);
//对pq[k]做上浮,让堆有序
swim(k);
}
//把与索引i关联的元素修改为为t
public void changeItem(int i, T t) {
//修改items数组中索引i处的值为t
items[i] = t;
//找到i在pq中的位置
int k = qp[i];
//对pq[k]做下沉,让堆有序
sink(k);
//对pq[k]做上浮,让堆有序
swim(k);
}
}
package com.ynu.Java版算法.U8_优先队列.T3_索引优先队列;
public class Main {
public static void main(String[] args) {
String[] arr = {"S", "O", "R", "T", "E", "X", "A", "M", "P", "L", "E"};
IndexMinPriorityQueue<String> indexMinPQ = new IndexMinPriorityQueue<>(20);
//插入
for (int i = 0; i < arr.length; i++) {
indexMinPQ.insert(i,arr[i]);
}
System.out.println(indexMinPQ.size());
//获取最小值的索引
System.out.println(indexMinPQ.minIndex());
//测试修改
indexMinPQ.changeItem(0,"Z");
// 从小到大遍历
while(!indexMinPQ.isEmpty()){
System.out.print(indexMinPQ.get(indexMinPQ.minIndex())+" ");
indexMinPQ.delMin();
}
}
}