CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
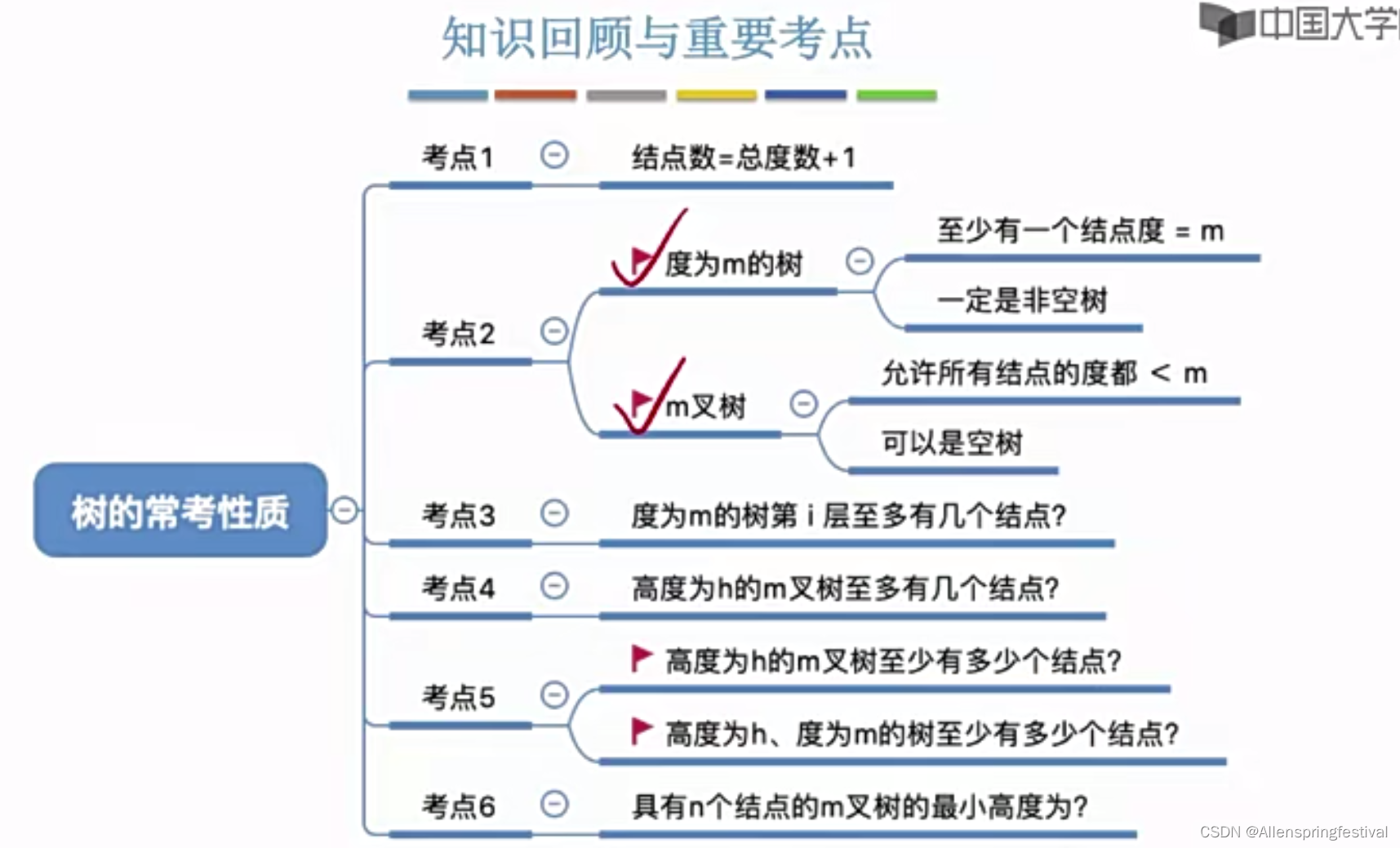
1.Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model(CVPR 2023)

标题:化身长腿:使用扩散模型从稀疏跟踪输入生成平滑的人体运动
作者:Yuming Du, Robin Kips, Albert Pumarola, Sebastian Starke, Ali Thabet, Artsiom Sanakoyeu
文章链接:https://arxiv.org/abs/2304.08577
项目代码:https://dulucas.github.io/agrol/
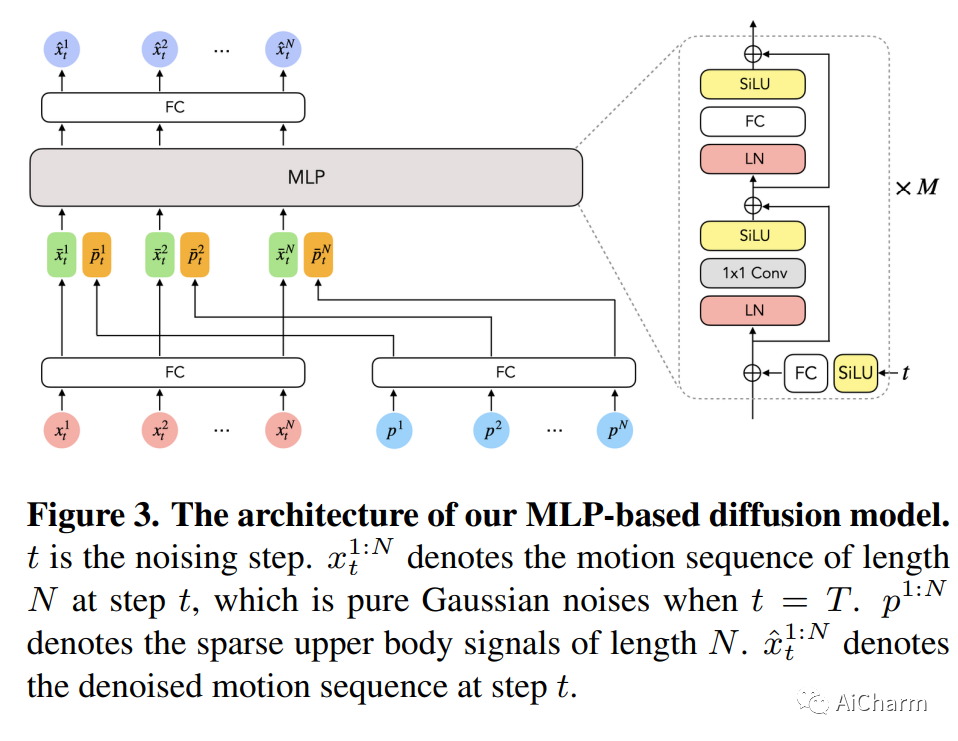
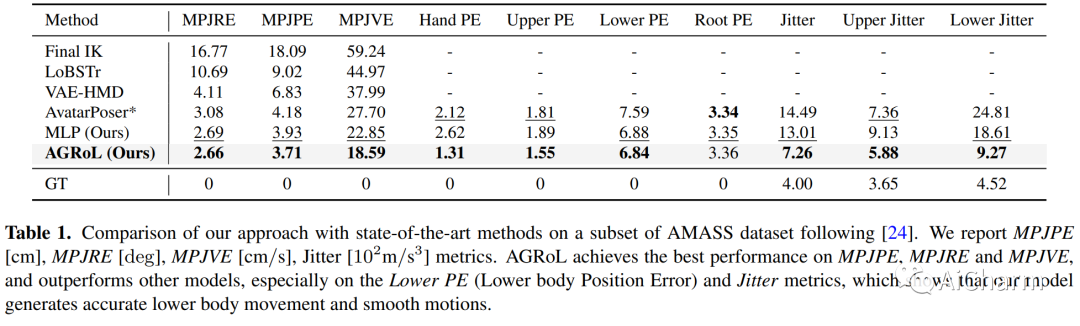
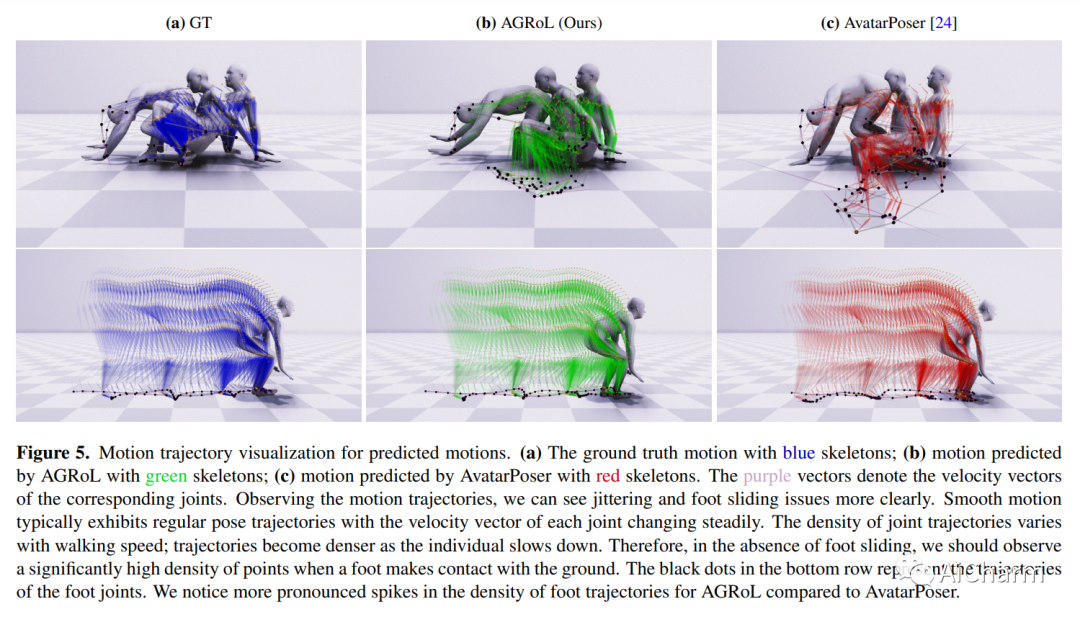
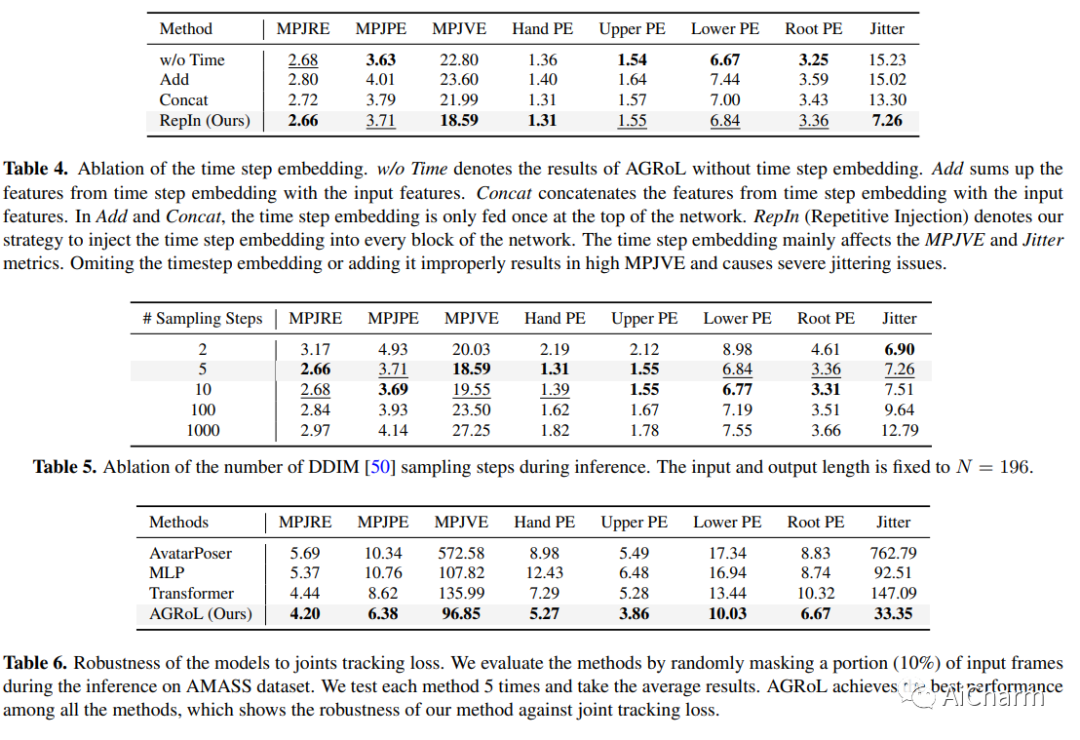
摘要:
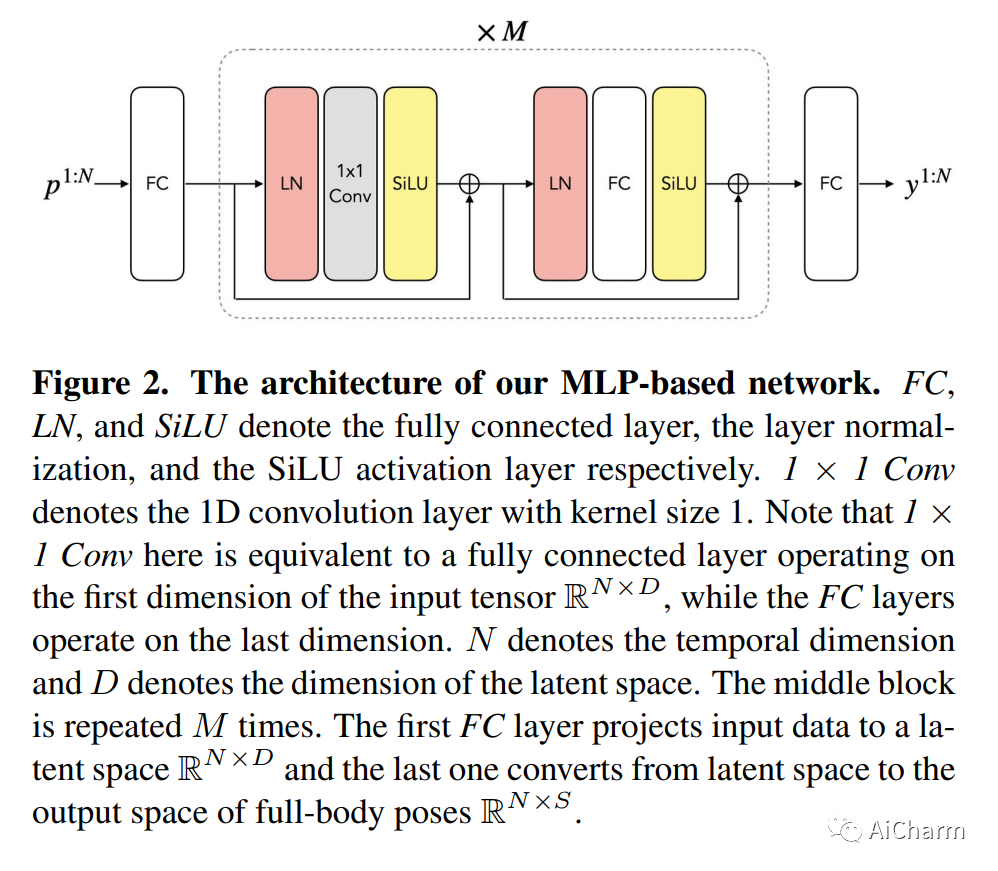
随着近期 AR/VR 应用程序的流行,对 3D 全身化身的逼真和准确控制已成为人们迫切需要的功能。一个特殊的挑战是,独立的 HMD(头戴式设备)只能提供稀疏的跟踪信号,通常仅限于跟踪用户的头部和手腕。虽然此信号对于重建上半身运动非常有用,但下半身未被跟踪,必须从上半身关节提供的有限信息中合成。在本文中,我们提出了 AGRoL,这是一种新型条件扩散模型,专门设计用于在给定稀疏上半身跟踪信号的情况下跟踪全身。我们的模型基于一个简单的多层感知器 (MLP) 架构和一种新颖的运动数据调节方案。它可以预测准确而流畅的全身运动,尤其是具有挑战性的下半身运动。与常见的扩散架构不同,我们的紧凑架构可以实时运行,使其适用于在线身体跟踪应用程序。我们在 AMASS 运动捕捉数据集上训练和评估我们的模型,并证明我们的方法在生成的运动精度和平滑度方面优于最先进的方法。我们通过广泛的实验和消融研究进一步证明了我们的设计选择。
2Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models(CVPR 2023)

标题:对齐你的潜在:高分辨率视频合成与潜在扩散模型
作者:Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, Karsten Kreis
文章链接:https://arxiv.org/abs/2304.08818
项目代码:https://research.nvidia.com/labs/toronto-ai/VideoLDM/
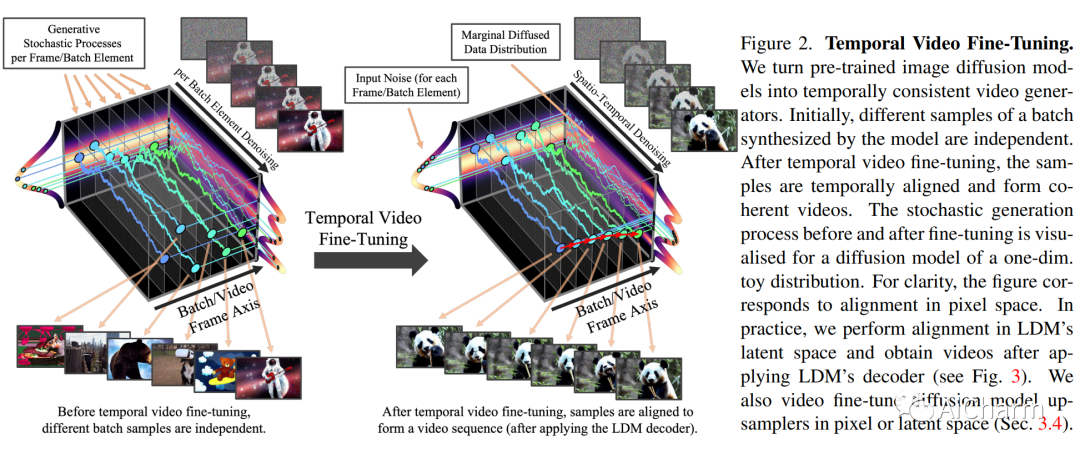
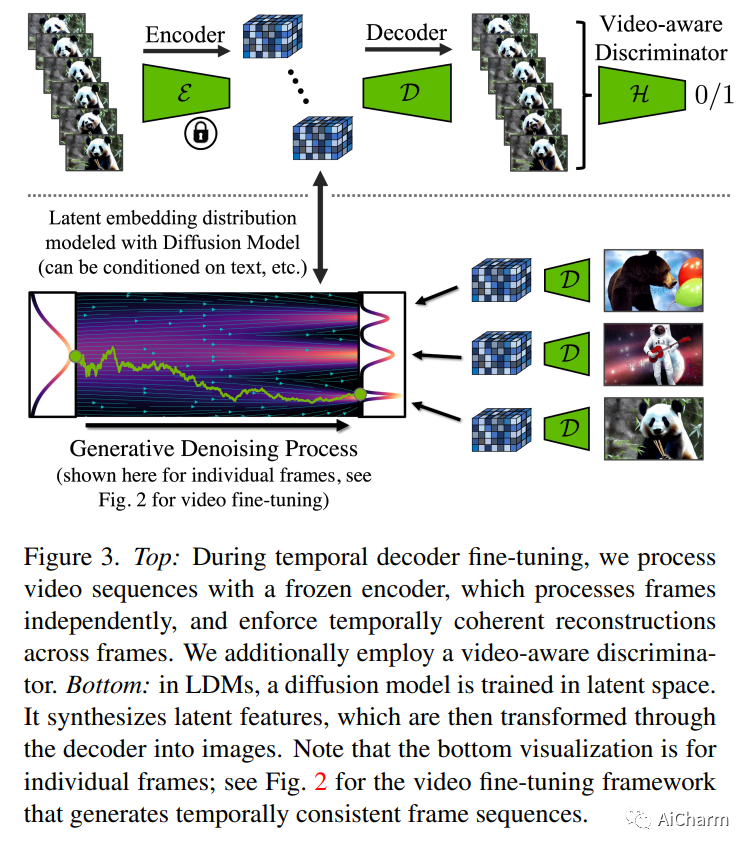
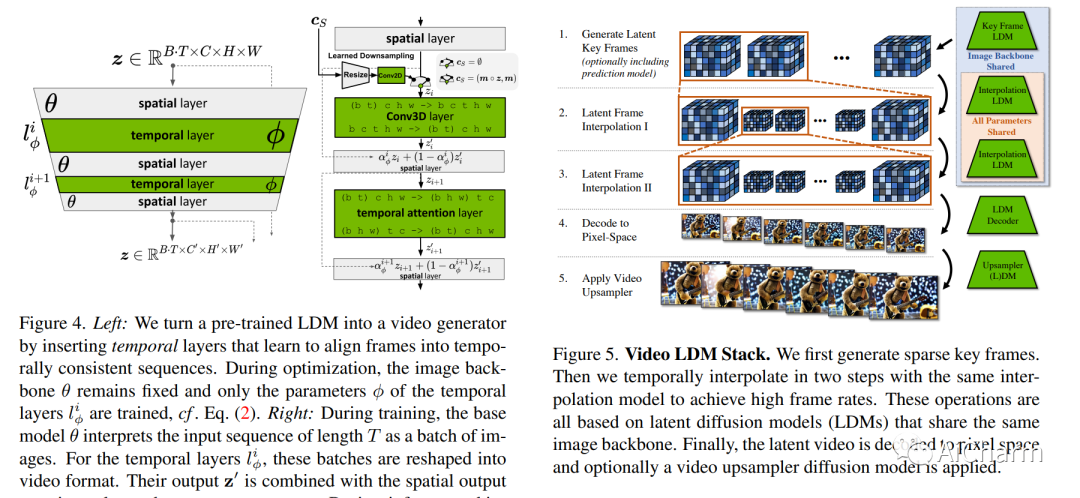
摘要:
潜在扩散模型 (LDM) 可实现高质量图像合成,同时通过在压缩的低维潜在空间中训练扩散模型来避免过多的计算需求。在这里,我们将 LDM 范例应用于高分辨率视频生成,这是一项特别耗费资源的任务。我们首先仅在图像上预训练 LDM;然后,我们通过在潜在空间扩散模型中引入时间维度并对编码图像序列(即视频)进行微调,将图像生成器转变为视频生成器。同样,我们在时间上对齐扩散模型上采样器,将它们变成时间一致的视频超分辨率模型。我们专注于两个相关的现实世界应用:模拟野外驾驶数据和使用文本到视频建模的创意内容创建。特别是,我们在分辨率为 512 x 1024 的真实驾驶视频上验证了我们的视频 LDM,实现了最先进的性能。此外,我们的方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练时间对齐模型。这样做,我们将公开可用的、最先进的文本到图像 LDM 稳定扩散转变为分辨率高达 1280 x 2048 的高效且富有表现力的文本到视频模型。我们表明,时间层经过训练以这种方式推广到不同的微调文本到图像 LDM。利用此属性,我们展示了个性化文本到视频生成的第一个结果,为未来的内容创建开辟了令人兴奋的方向。
Subjects: cs.RO
3.ImAffordances from Human Videos as a Versatile Representation for Robotics

标题:人类视频的可供性作为机器人技术的多功能表示
作者:Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, Deepak Pathak
文章链接:https://arxiv.org/abs/2304.08488
项目代码:https://robo-affordances.github.io/
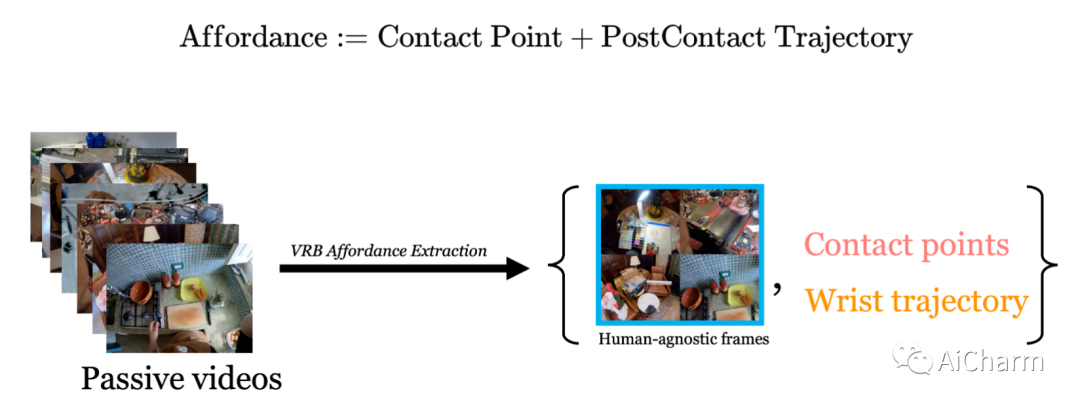
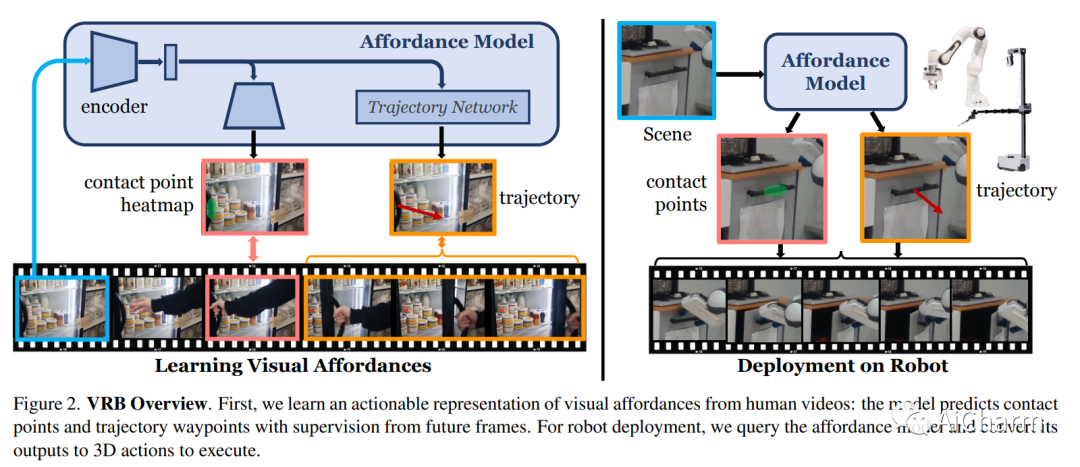
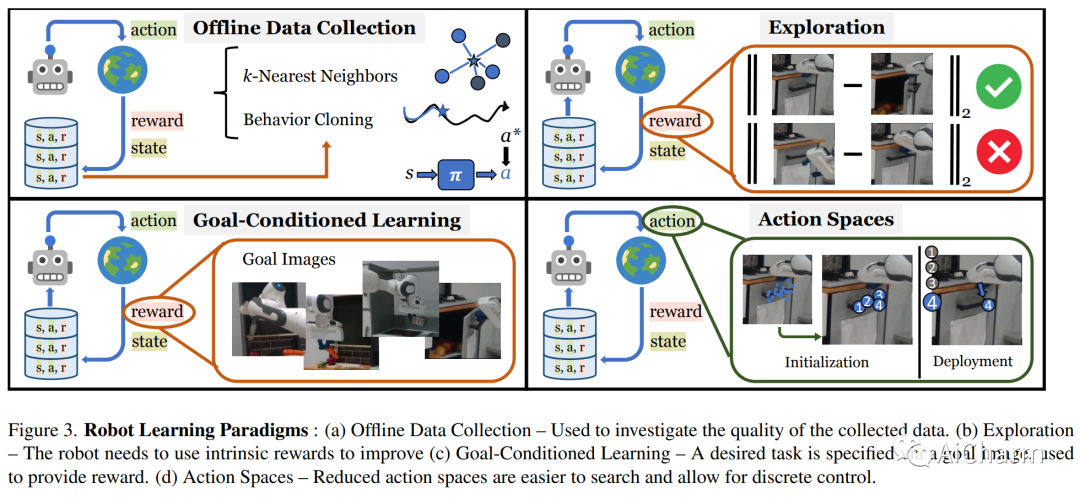
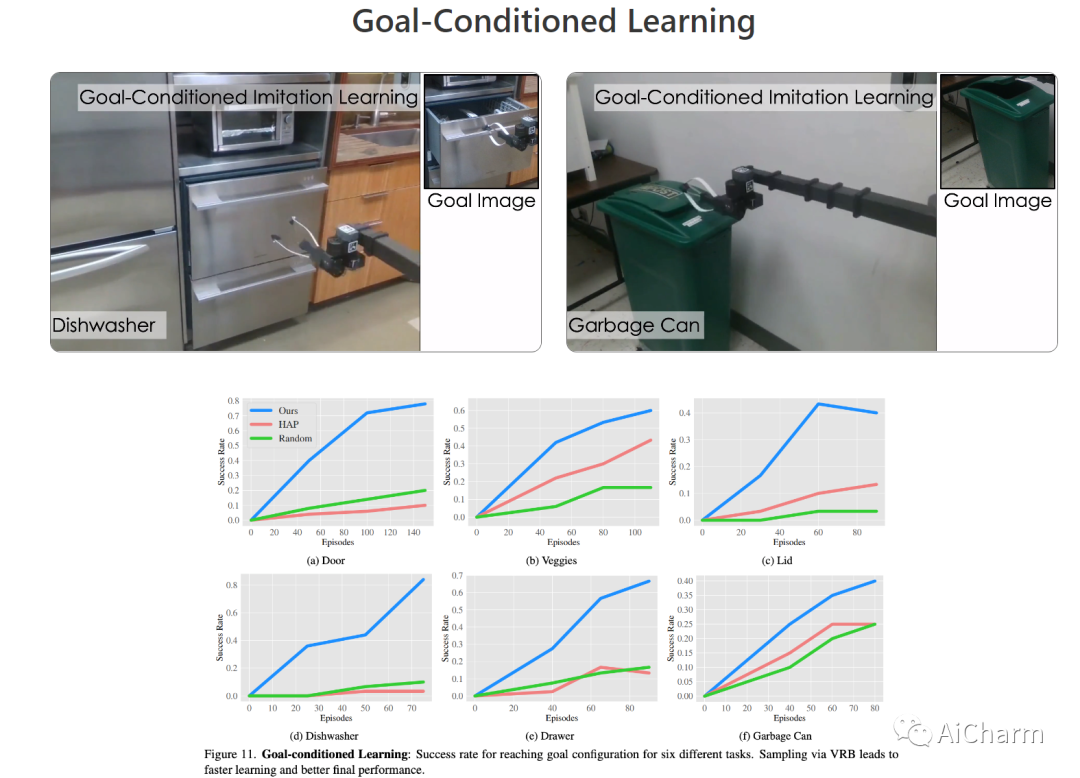
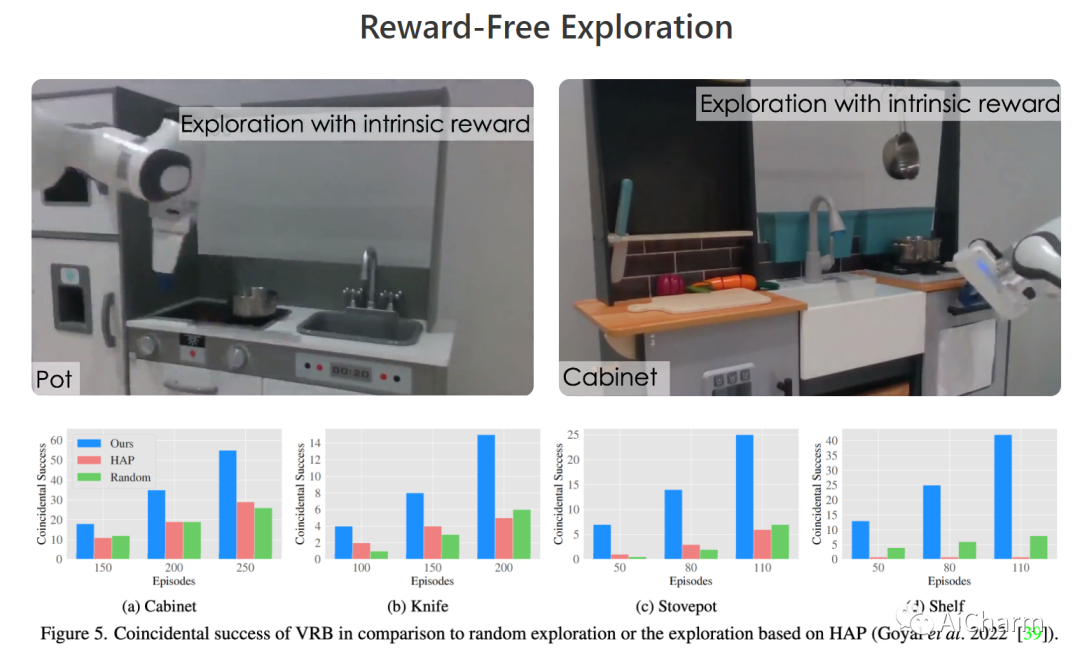
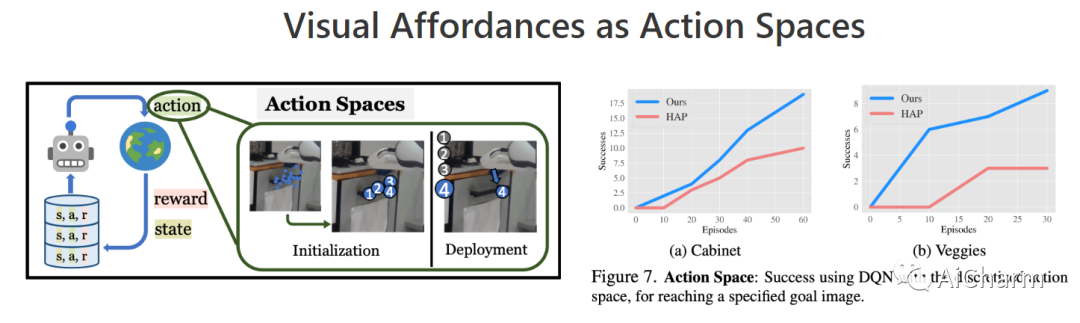
摘要:
建造一个可以通过观察人类来理解和学习互动的机器人激发了几个视觉问题。然而,尽管在静态数据集上取得了一些成功的结果,但目前的模型如何直接用在机器人上仍然不清楚。在本文中,我们旨在通过以环境为中心的方式利用人类互动视频来弥合这一差距。利用人类行为的互联网视频,我们训练了一个视觉可供性模型,该模型估计人类可能在场景中的位置和方式进行交互。这些行为可供性的结构直接使机器人能够执行许多复杂的任务。我们展示了如何将我们的可供性模型与四种机器人学习范式无缝集成,包括离线模仿学习、探索、目标条件学习和强化学习的动作参数化。我们展示了我们称为 VRB 的方法在 4 个真实世界环境、10 多个不同任务和 2 个在野外运行的机器人平台上的有效性。此 https URL 上的结果、可视化和视频
更多Ai资讯:公主号AiCharm