文章目录
- 1.到底什么是协同过滤
- 2.协同过滤的一般步骤
- 3.基于用户的CF (User-CF)
- 3.1 基本介绍
- 3.2 用户相似度
- 3.2.1 用户相似度基本介绍
- 3.2.2 用户相似度改进:ICU
- 3.3 User-CF的缺点
- 4.基于项目的CF (Item-CF)
- 4.1 基本介绍
- 4.2 用户相似度
- 4.2.1 用户相似度基本介绍
- 4.2.2 用户相似度改进
- 5.协同过滤:基于邻域的评分预测
该系列历史文章:
- 1.推荐系统最通俗介绍
- 2.推荐系统常见算法分类
资料整理,来源于北大刘宏志教授讲座内容。
1.到底什么是协同过滤
-
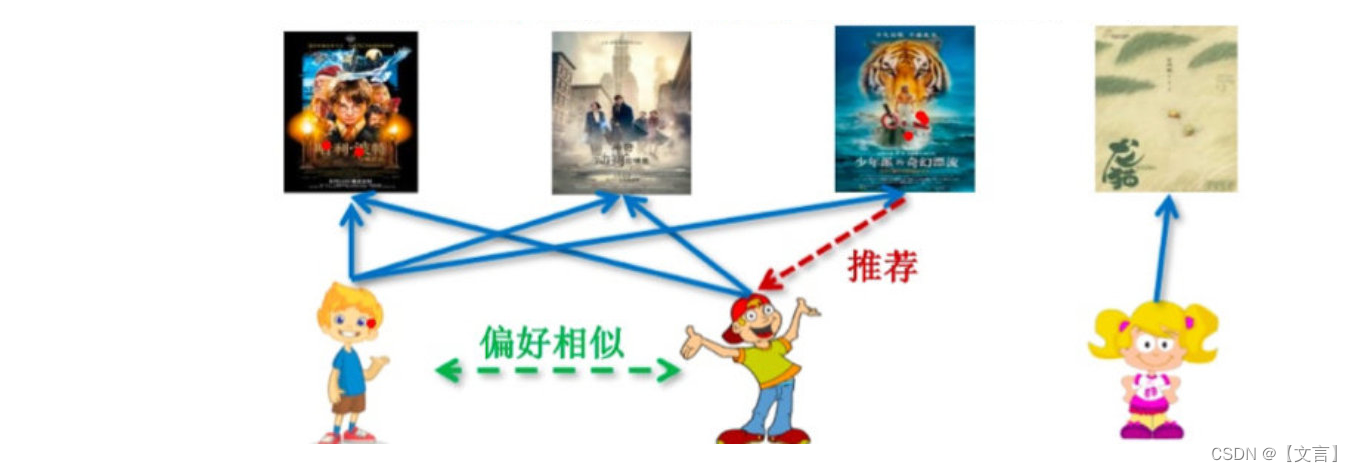
协同过滤(Collaborative Filtering, CR):利用集体智慧,借鉴相关人群的观点进行推荐。
-
基本假设:
- 过去兴趣相似的用户在未来的兴趣也会相似(由古及今)
- 相似的用户会产生相似的(历史)行为数据(由表及里)
-
协同过滤优缺点
- 优点:
- 发现新的兴趣点;不需要领域知识;个性化、自动化程度高
- 缺点:
- 协同失效,即基本假设失效
- 优点:
2.协同过滤的一般步骤
- 收集数据:收集能反映用户偏好的数据
- 寻找邻域:相似的用户(或项目)
- 计算推荐结果:根据邻域信息计算推荐结果
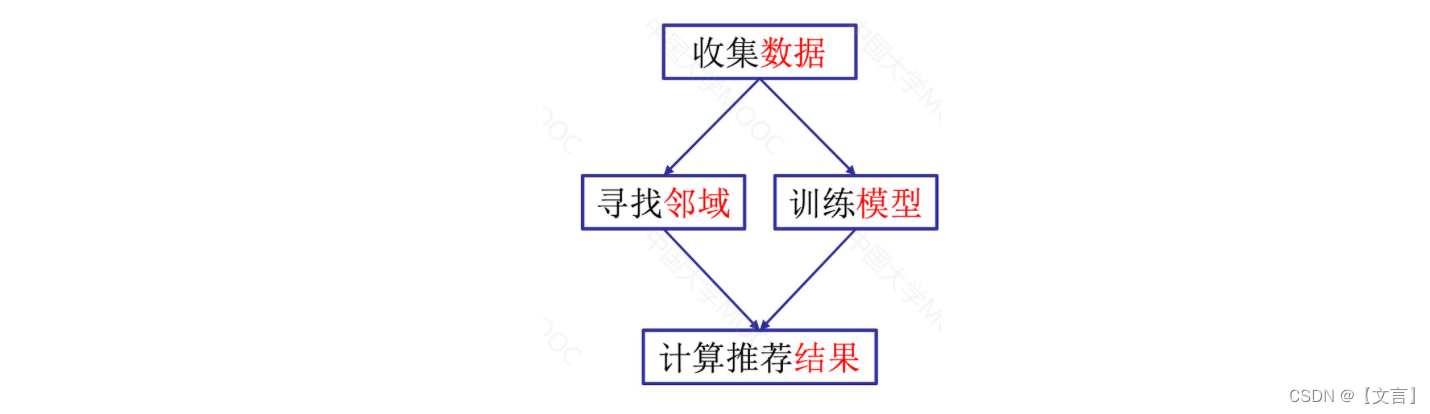
- 举例:
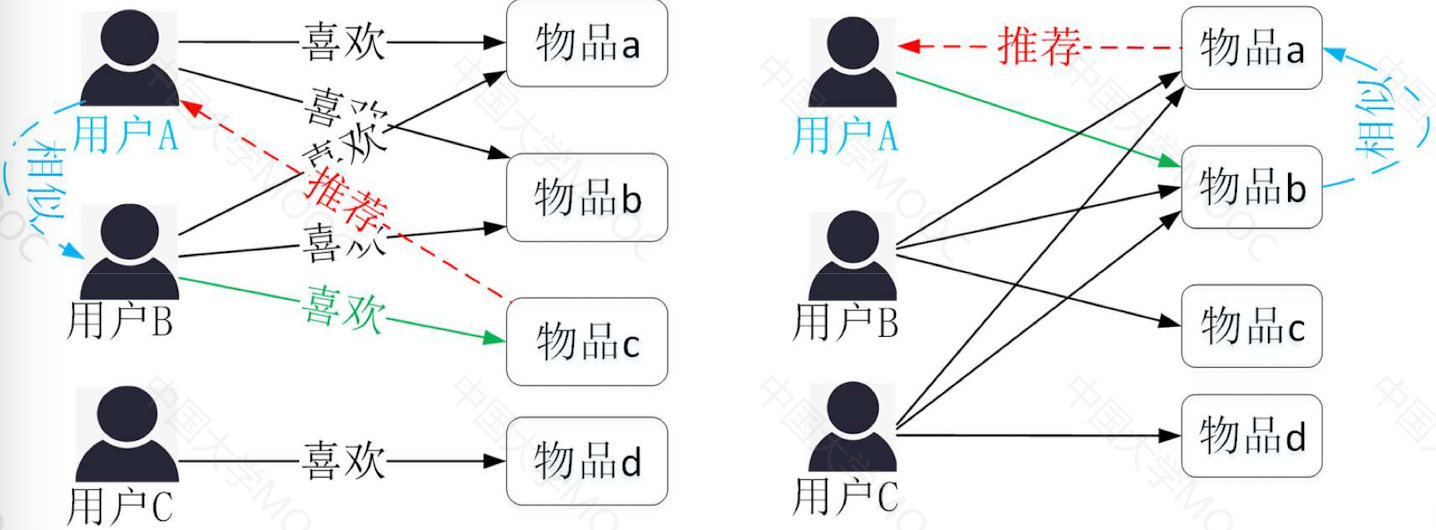
- 收集数据说明
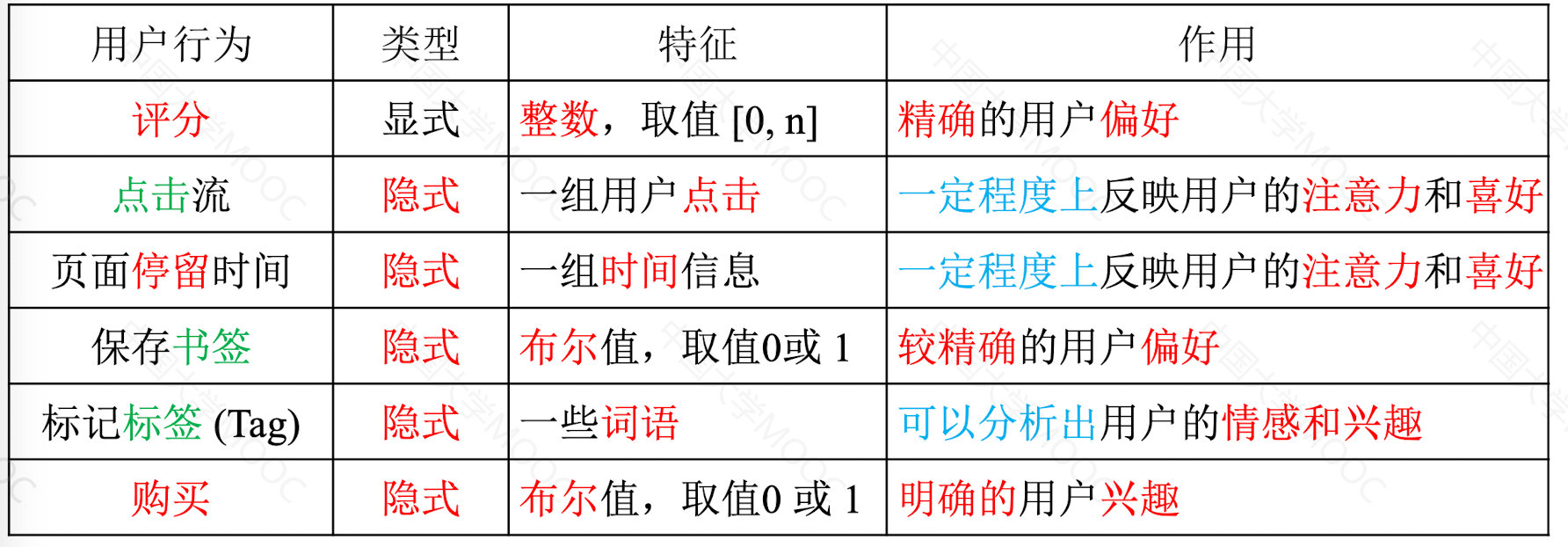
显式反馈:用户主动地向系统表达其偏好,一般需要用户在消费完项目后进行额外反馈;
隐式反馈:隐含用户对项目偏好的行为数据,是用户在探索或消费项目过程中正常操作。
3.基于用户的CF (User-CF)
3.1 基本介绍
基本思想:
-
基于用户对项目的历史偏好找到相邻(相似)的用户
-
将邻居(相似)用户喜欢的项目推荐给当前用户

- 假设:
- 与我兴趣相似的用户喜欢的项目,我也会喜欢
- 关键:
- 寻找相似用户
- 用户相似度度量
基于 User-CF 的推荐系统整体流程:
-
离线预处理:
-
计算用户之间的相似度
-
并据此确定每个用户的邻域(K近邻)
-
-
在线推荐:针对当前活跃(目标)用户,计算推荐列表
-
确定候选项目集
-
预测兴趣度并生成推荐列表
-
3.2 用户相似度
3.2.1 用户相似度基本介绍
用户相似度计算方法:

用户相似度的问题:
-
下面哪一组用户更相似?
-
用户A和B都买过《新华字典》
-
用户C和D都买过《 Recommender Systems Handbook》
-
-
【思考】热门项目对我们推荐的影响,如何解决?
3.2.2 用户相似度改进:ICU
逆用户频率(Inverse User Frequency)
-
基本思想:惩罚热门项目
-
两个用户对冷门项目有过同样行为更能说明他们兴趣相似

3.3 User-CF的缺点
-
难以形成有意义的邻域集合
-
很多用户两两之间只有很少的共同反馈
-
而仅有的共同反馈的项目,往往是热门项目(缺乏区分度)
-
-
随着用户行为数据的增加,用户间相似度可能变化很快
- 离线(offline)算法难以瞬间更新推荐结果
4.基于项目的CF (Item-CF)
4.1 基本介绍
基本思想:
- 基于用户对项目的反馈(偏好)寻找相似(相关)的项目
- 根据用户的历史反馈(偏好)行为,给他推荐相似的项目

-
假设:
- 我过去喜欢某类项目,将来还会喜欢类似(相关)项目
-
关键:
- 寻找相似(相关)项目
- 项目相似(相关)度度量
基于 Item-CF 的推荐系统整体流程:
和前面基于用户的非常类似,在此不做展开
- 离线预处理、在线推荐
4.2 用户相似度
4.2.1 用户相似度基本介绍
用户相似度计算方法:
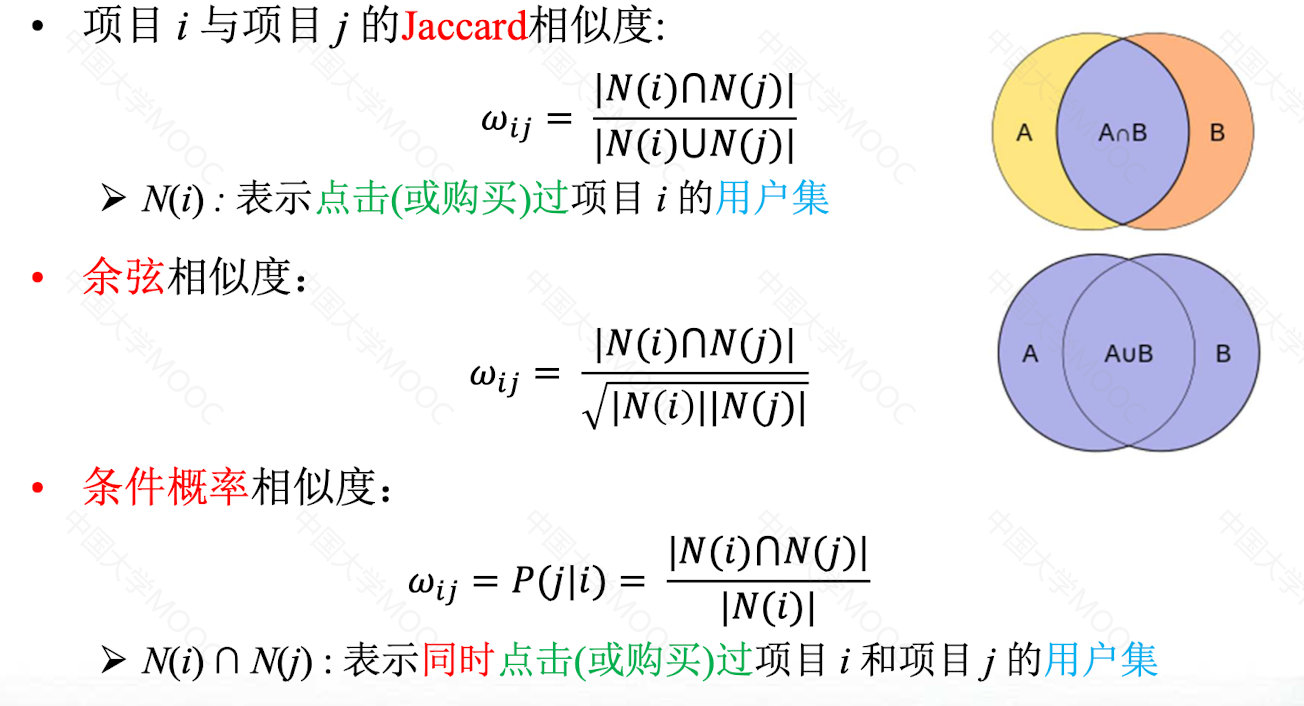
4.2.2 用户相似度改进

5.协同过滤:基于邻域的评分预测
基于领域的协同过滤算法的关键在于相似度度量的构造。主要有:
-
余弦相似度
-
皮尔逊相似度
-
杰卡德相似度
除此之外,还有通过距离度量来构造相似度:
- 欧式距离
- 曼哈顿距离
- 闵可夫斯基距离
这部分内容都比较常规,或者前面讲过,在此不再展开。
本文主要介绍了协同过滤基本内容,协同过滤,即利用集体智慧,借鉴相关人群的观点进行推荐。其后又介绍了基于用户、项目的协同过滤。