文章目录
- 0. 前言
- 1. 理解
- 1.1 整体框架
- 1.2 网络结构
- 1.3 细节
- 2. 亮点
- 3. 总结
0. 前言
LTMNet这篇文章借鉴了CLAHE算法,所有步骤与CLAHE一致,不同之处在于LTMNet中局部映射曲线是通过CNN预测得到,而CLAHE中是通过直方图均衡化而得。关于CLAHE,【数字图像处理】直方图均衡化这篇博客有简单介绍。
论文:Learning Tone Curves for Local Image Enhancement
代码:https://github.com/samsunglabs/ltmnet
1. 理解
所谓看文先看图,这里选择关键的几张图来理解文章的思想。
1.1 整体框架
LTMNet的整体pipline如下:
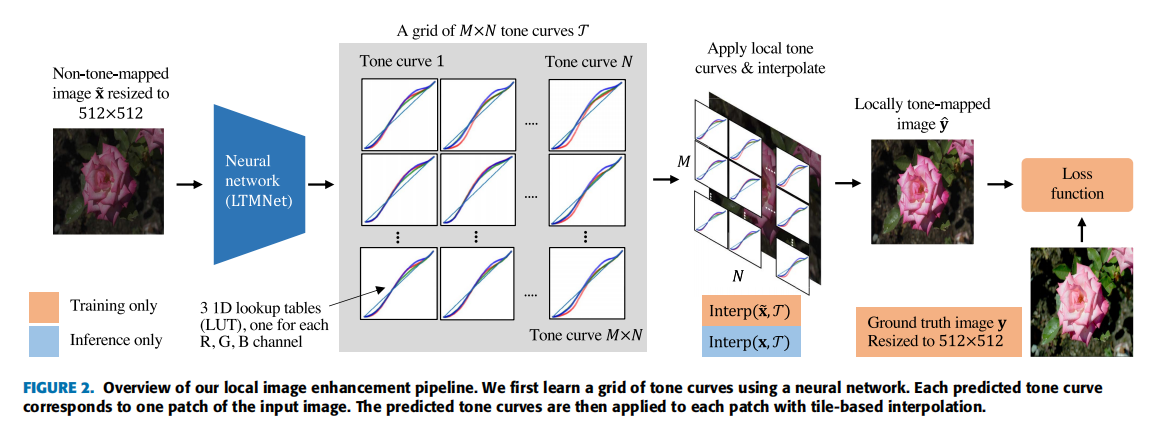
输入一张图像,resize到512×512,输入到网络中,输出M*N个RGB三通道的映射曲线,每个通道的映射曲线是一维的查找表;然后将得到的映射曲线应用到图像并进行插值,得到色调映射后的图像。以上就是完整的推理过程,训练时仅仅多了一个求loss的步骤。
为什么要插值:如果每个块使用对应的曲线进行映射,那么在块与块的交界处会产生不自然的过渡,因此需要通过插值使得交界处过渡平滑。
上图看下来,一般会有两个地方比较疑惑:① 网络是如何预测映射曲线的?② 插值是如何操作的?下面会进行解释。
1.2 网络结构
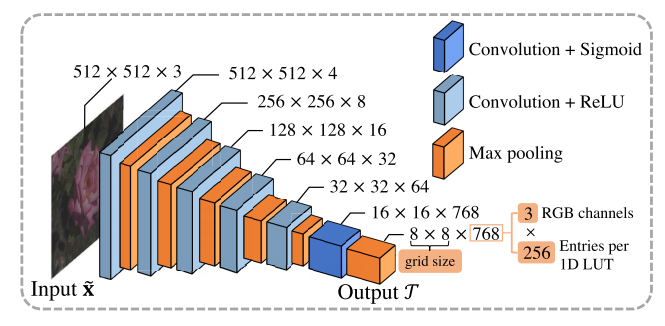
首先,网络是如何预测映射曲线的呢?网络的结构如下图所示,输入512×512×3的图像,经过卷积和池化后得到8×8×768的输出,其中8×8表示grid size,即将图像划分为8×8块;768表示RGB三通道的查找表,由于像素值的范围为0~255,因此查找表的长度为256。
1.3 细节
得到网络输出的映射曲线后,如何应用到输入图像上以实现对比度增强呢?文章中给出的图中解释的比较清楚。
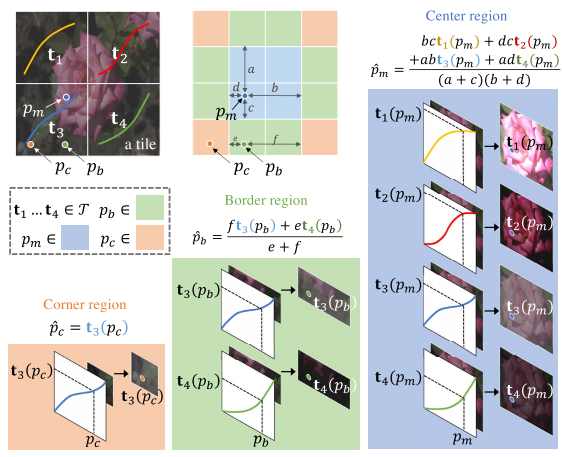
以2×2的grid size为例,即将输入图像分为4块,每块对应着3×256的映射曲线,分别记为
t
1
t_1
t1、
t
2
t_2
t2、
t
3
t_3
t3、
t
4
t_4
t4。论文中的后处理方式与CLAHE一致,将每一小块继续划分为2×2个小块,所以2×2的图像就变成了4×4的图像,如下:

将图像划分为角落区域(橙黄色)、边界区域(绿色)和中心区域(蓝色),每个区域使用不同的映射规则。
- 对于角落区域(Corner region):直接使用所在大块的映射曲线。
p
c
p_c
pc是位于左下角的一个像素,因此使用
t
3
t_3
t3进行映射即可,得到输出
p
^
c
=
t
3
(
p
c
)
\hat{p}_c=t_3(p_c)
p^c=t3(pc)

- 对于边界区域(Border region):选择所在块和相邻块的映射曲线对像素进行映射,然后通过插值计算最终的结果,插值的权重根据像素到块边界的距离来衡量。
p
b
p_b
pb是位于下边界区域的像素,因此使用
t
3
t_3
t3和
t
4
t_4
t4两条映射曲线对其进行映射,然后通过插值得到映射后的像素值
p
^
b
\hat{p}_b
p^b

- 对于中心区域(Center region):使用中心四个块的映射曲线
t
1
t_1
t1、
t
2
t_2
t2、
t
3
t_3
t3、
t
4
t_4
t4分别对像素
p
m
p_m
pm进行映射,然后通过插值获取结果
p
^
m
\hat{p}_m
p^m

2. 亮点
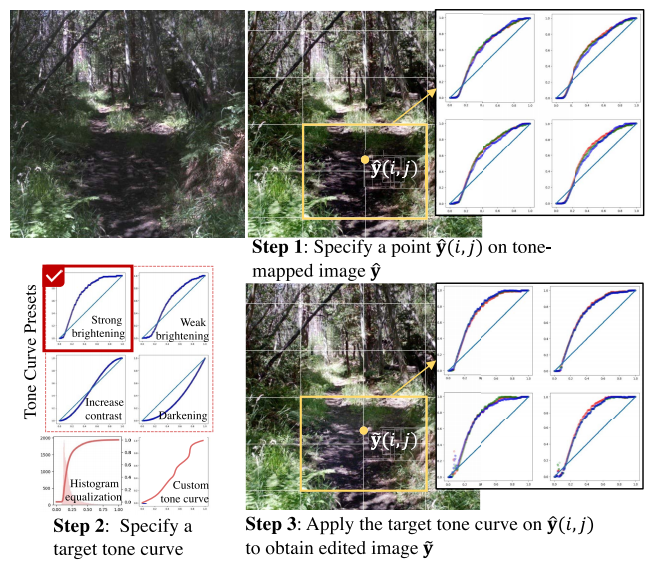
由于网络输出的是查找表,即映射曲线,因此可以交互式地对图像的局部区域进行调整,以达到想要的效果。例如下图中图像暗区过暗,通过调整曲线将亮度拉起来,使得暗区细节可见。
3. 总结
- 传统算法与神经网络结合,神经网络拟合色调映射函数
- 设计算法时要考虑到实际应用环境,如ISP pipline中,一个很重要的点就是算法需要具备可调性,因为用户需要针对自己的偏好以及使用环境的不同对算法的效果进行调整