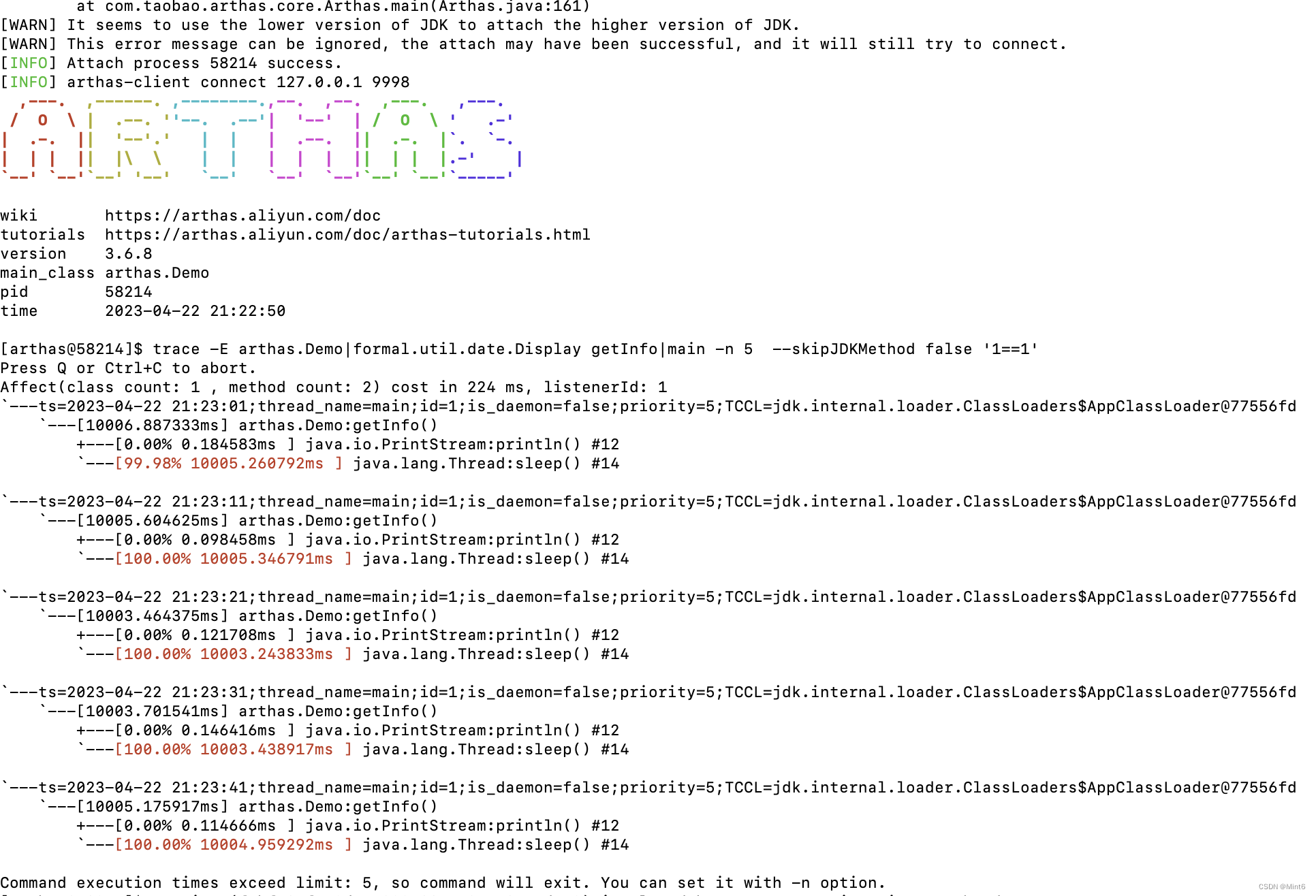
**摘要:**当前基于深度迁移学习的故障诊断的大多数成功需要两个假设:1)源机器的健康状态集合应当与目标机器的健康状态集合重叠;2)目标机器样本的数量跨健康状态平衡。然而,这样的假设在工程场景中是不现实的,其中目标机器遭受在源机器中看不到的故障类型,并且目标机器大多处于健康状态,仅偶尔发生故障。因此,来自源机器的诊断知识可能不覆盖目标机器的所有故障类型,也不解决不平衡的目标样本。因此,我们提出了一个框架,称为多源转移学习网络(MSTLN),聚合和转移诊断知识从多个源机器结合多个部分分布自适应子网络(PDA子网)和多源诊断知识融合模块。前者通过平衡因子对目标样本进行加权,以联合适应源和目标对的局部分布;后者释放多个源机器之间的差异所带来的负面影响,并进一步融合多个PDA-Subnets的诊断决策输出。两个实例研究表明,MSTLN方法能降低误诊率,对不平衡的目标样本具有更好的传输性能。
一.问题背景
迁移学习是一种很有前途的技术,可以解决丢失标签的问题,并允许将源机器的诊断知识转移到不同但相关的目标机器。常见的有三种方法,即基于实例的、基于特征的和基于参数的。基于特征的方法因其纠正严重差异的能力而特别受欢迎,这种方法构造非线性函数来将来自源机器和目标机器的样本映射到一个共同的特征空间中,其中可转移特征的分布差异被抑制。因此,应用于源机器的诊断模型可以在目标机器上重用。
两个常见的假设:1)源机器的健康状态集合应当与目标机器的健康状态集合重叠; 2)目标机器样本的数量跨健康状态平衡。然而,在现实世界的应用中,这样的假设很难被证明是合理的。首先,目标机器不可避免地遭受在源机器中从未经历过的故障类型。因此,来自各个源机器的诊断知识不足以识别从所有健康状态提取的目标机器样本。其次,目标机器大部分时间都在健康阶段运行,偶尔会出现故障。因此,收集的目标机器数据集由大量健康样本和偶尔的错误样本组成,导致标准的基于特征的迁移学习方法使可迁移特征的分布不一致。
虽然单个源机器可能无法提供足够的诊断知识,但源机器的某些组合可能会提供足够的诊断知识[20]。因此,我们提出了一个多源迁移学习网络(MSTLN),以利用多个源机器。
二.本文贡献
- 提出了一种部分分布自适应子网络(PDA-Subnet),它在分类层中加入一个神经元来处理源机中未发现的故障。此外,它有一个域鉴别器,用加权Wasserstein损失训练来计算平衡目标机器不平衡样本的因子。
- 提出了一种诊断知识融合模块,用于联合收割机多个PDA子网的诊断决策。该模块通过多源-目标自适应正则化联合训练多个PDA-子网络,以减轻多个源机器之间的差异所带来的负面影响。进一步实现了一种决策融合策略,利用源目标对的相似度对多个决策进行加权,得到最终的诊断结果
三.基础知识
3.1.问题描述
- 给定多个源域 S = { s 1 , s 2 , . . . , s m } S=\{s_{1},s_{2},...,s_{m}\} S={s1,s2,...,sm},其中诊断知识从 M M M个源机器中收集;
- 第 k k k个源域 s k s_{k} sk包括 n s k n_{s_{k}} nsk个标记样本 X s k = { ( x i s k , y i s k ) ∣ i = 1 , 2 , . . . , n s k , x i s k ∼ P s k , y i s k ∈ Y s k , k ∈ ∣ S ∣ } X^{s_{k}}=\{(x^{s_{k}}_{i},y^{s_{k}}_{i})| i=1,2,...,n_{s_{k}},x^{s_{k}}_{i}∼ P_{s_{k}},y^{s_{k}}_{i} ∈Y^{s_{k}},k∈|S|\} Xsk={(xisk,yisk)∣i=1,2,...,nsk,xisk∼Psk,yisk∈Ysk,k∈∣S∣},其中 Y s k = 1 , 2 , . . . , R s k Y^{s_{k}}={1,2,...,R^{s_{k}}} Ysk=1,2,...,Rsk代表源域 s k s_{k} sk的健康状态集合并且有 ∣ Y s k ∣ |Y^{s_{k}}| ∣Ysk∣个健康状态;
- 目标域有 n t n_{t} nt个未标记的样本 X t = { x i t ∣ i = 1 , 2 , n t , x i t ∼ P t } X^{t}=\{x^{t}_{i}|i=1,2,n_{t},x^{t}_{i}∼P_{t}\} Xt={xit∣i=1,2,nt,xit∼Pt};
- 目标域样本的标签来自 Y t = { 1 , 2 , . . . , R t } Y^{t}=\{1,2,...,R^{t}\} Yt={1,2,...,Rt};
- 注意由于源机器和目标机器以及多个源机器之间的差异,则有分布差异 P s k ≠ P t P_{s_{k}}≠P_{t} Psk=Ptand P s i ≠ P s j ( i , j ∈ ∣ S ∣ P_{s_{i}}≠P_{s_{j}}(i,j∈|S| Psi=Psj(i,j∈∣S∣ and i ≠ j ) i≠j) i=j);
- 在许多现实世界的情况下,目标域样本可以跨健康状态不平衡,这与来自通常在受控环境中设置的源域的平衡样本相反;
- 假设任何单个源域 s k ∈ S s_{k} ∈ S sk∈S不覆盖目标域所需的知识,即 Y s k ⊈ Y t Y^{s_{k}}\not\subseteq{Y^{t}} Ysk⊆Yt,但结合诊断知识可以覆盖。交集 Y s k ∩ Y t Y^{s_{k}} ∩Y^{t} Ysk∩Yt是指源域 s k s_{k} sk和目标域 t t t的共享健康状态集合,而差值 Y s k Y^{s_{k}} Ysk\ Y t Y^{t} Yt是仅可从目标域观察到的健康状态集合
多元迁移学习用于集成多个诊断模型 f S ( ⋅ ) : = { X s k → Y s k ∣ k ∈ ∣ S ∣ } f_{S}(·):=\{X^{s_{k}}\rightarrow Y^{s_{k}}|k\in|S|\} fS(⋅):={Xsk→Ysk∣k∈∣S∣}并且最小化目标期望风险 R t = E x t ~ P t [ f S ( x i t ) ≠ y i t ] R_{t}=E_{x^{t}~P_{t}}[f_{S}(x^{t}_{i})\neq{y^{t}_{i}}] Rt=Ext~Pt[fS(xit)=yit]
首先将多源迁移学习任务分成多个部分迁移学习子任务
{
s
k
→
t
∣
k
∈
∣
S
∣
}
\{s_{k} → t| k ∈|S|\}
{sk→t∣k∈∣S∣},然后融合多个诊断决策。
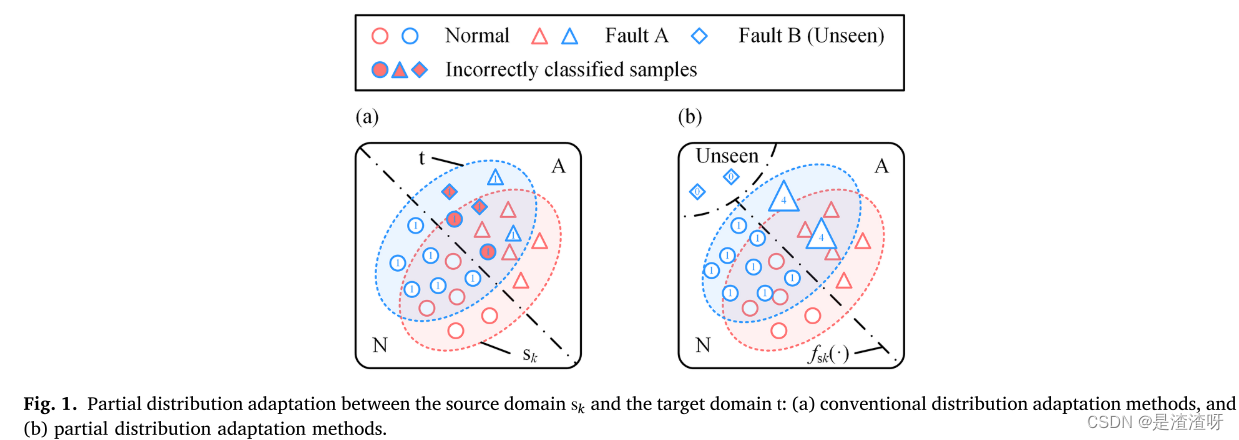
需要克服两个重大挑战:1)在源和目标域对之间部分分布的适应,2)多源诊断知识的融合。
第一个挑战是由于:在源域中看不见的故障类型可能出现在不平衡的目标域中,如图1(a)所示。来自不可见故障的目标域样本将被错误分类,并且来自共享健康状态的目标域样本可能被错误地识别。作为一种补救措施,目标域样本在分布自适应过程中加权,挑选出看不见的故障的样本,并调整来自共享健康状态样本的重要性。如图1(b)所示,目标域样本的部分分布可以与源域样本对齐。
使共享健康状态样本的重要性更大,来防止该类型的被错分?
第二个挑战是因为:多个源域为单个目标域提供了不同的诊断知识。融合机制将较大的权重应用于与目标域更相似的源域。该机制还融合了来自多个源域的诊断知识,以识别目标域中的不可见故障。具体而言,在图2中,通过遵循跨域相似性来融合共享的诊断结果,并且扩展互补结果。
3.2.MMD
MMD是一种非参数距离度量,用于估计两个数据集之间的分布差异。给定集合
X
=
{
x
i
∣
x
i
~
p
,
i
=
1
,
2
,
.
.
.
,
n
}
X=\{x_{i}|x_{i}~p,i=1,2,...,n\}
X={xi∣xi~p,i=1,2,...,n} and
Y
=
{
y
j
∣
y
j
~
q
,
j
=
1
,
2
,
.
.
.
,
m
}
Y=\{y_{j}|y_{j}~q,j=1,2,...,m\}
Y={yj∣yj~q,j=1,2,...,m},MMD定义如下:

其中sup(·)是输入集合的上确界,H表示再生核希尔伯特空间(RKHS),Φ(⋅)是映射函数。如果通过使用特征核来构造RKHS,则集合X和Y之间的MMD可以被估计为:
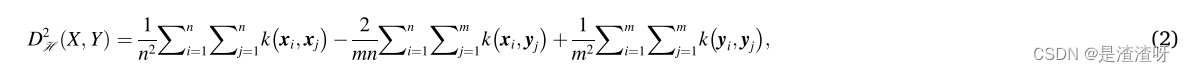
四.本文方法
所提出的MSTLN可以被划分为多个PDA子网和多源诊断知识融合模块,如图3所示。多个PDA-子网被单独地应用于源-目标域对(一个用于一对)以适应源和目标域样本的部分分布。然后,通过知识融合模块将来自多个PDA子网的诊断决策进行融合。每个元素在以下小节中详细介绍。
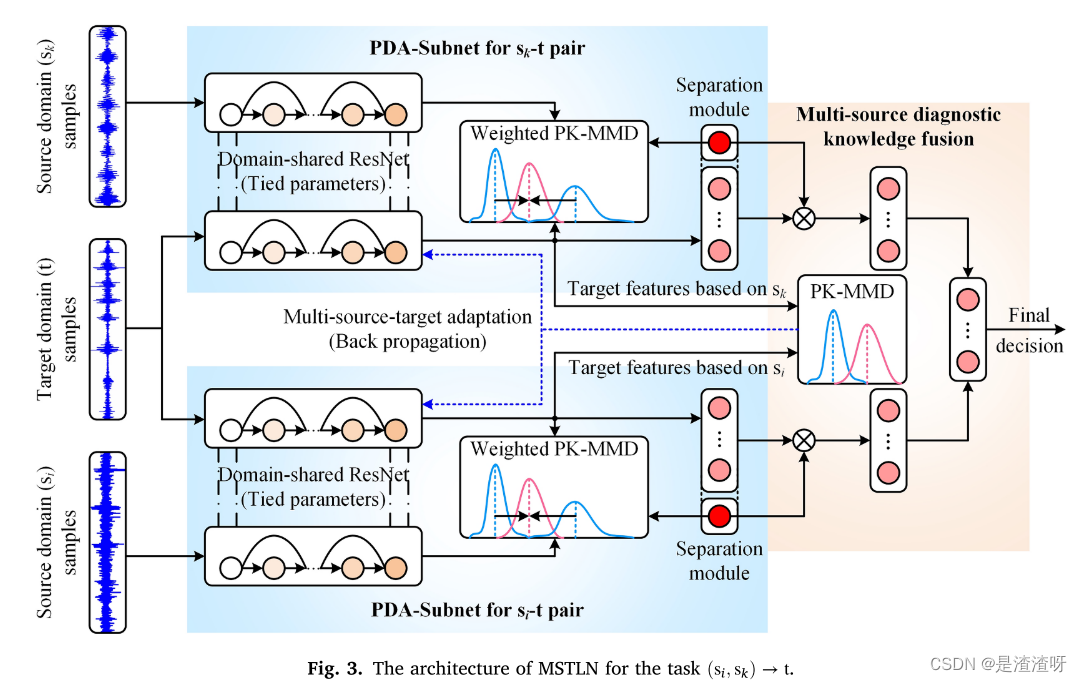
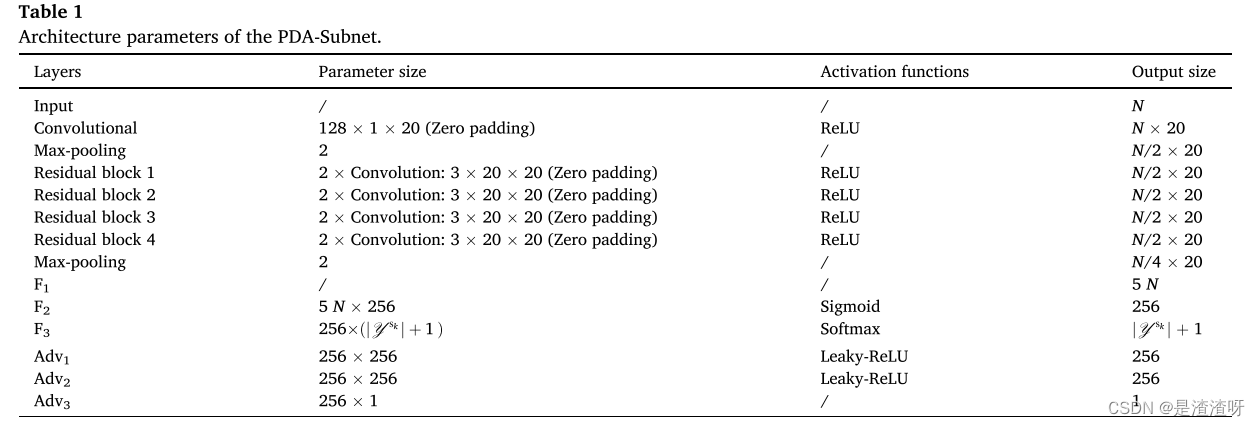
4.1.PDA-子网
多个PDA子网形成MSTLN的核心。每个PDA子网具有相同的架构参数,如表1所示。图4呈现了用于源域
s
k
s_{k}
sk和目标域
t
t
t的PDA子网的架构。该网络由一个域共享的深度残差网络(ResNet),一个看不见故障的分离模块和一个重要性加权分布自适应模块组成。各部分详述如下。
4.1.1.域共享ResNet
域共享的ResNet由两个单独的网络组成,但它们共享源域 s k s_{k} sk和目标域 t t t中样本的训练参数。它包括输入层、堆叠的残差块和全连接层。
在输入层中,我们在训练批中给出了第 k k k对源-目标域样本 { ( x s k , x i t ) ∣ x s k , x i t ∈ R N , i = 1 , 2 , . . . , m } 。 \{(x^{s_{k}},x^{t}_{i})|x^{s_{k}},x^{t}_{i}∈R^{N},i = 1,2,...,m\}。 {(xsk,xit)∣xsk,xit∈RN,i=1,2,...,m}。源-目标域样本首先由卷积层处理以表示可转移特征,并且注意,采用零填充来维持卷积过程之前和之后的特征的维度。然后添加最大池化层以降低由先前卷积层学习的可转移特征的维度。
之后,将多个残差块堆叠以提取高级别的可传递特征。在每个残差块中,使用两个零填充卷积层来处理来自前一层的特征,然后智能短连接输出卷积过程前后的特征之和。如图4所示,高级可转移特征在被展平为作为全连接网络的输入的一维向量之前通过另一个最大池化层。注意全连接网络具有单个隐藏层,并且网络将学习到的高级可转移特征映射到源域的健康状态集合中。
假设
G
k
(
⋅
)
G_{k}(·)
Gk(⋅)表示第k个源-目标域对
D
k
D_{k}
Dk(即源域
s
k
s_{k}
sk和目标域
t
t
t) 的特征提取器(包括输入层、堆叠的残差块以及全连接层F1和F2)。在层
F
2
F_{2}
F2中的高维可迁移特征
v
i
D
k
=
(
v
i
s
k
,
v
i
t
)
v^{D_{k}}_{i}=(v^{s_{k}}_{i},v^{t}_{i})
viDk=(visk,vit)可表示为:

其中
x
i
D
k
=
(
x
s
k
,
x
i
t
)
x^{D_{k}}_{i}=(x^{s_{k}},x^{t}_{i})
xiDk=(xsk,xit)是第k个源目标域对样本,且
θ
D
k
,
F
E
\theta^{D_{k},FE}
θDk,FE是特征提取器的训练参数。
层F3使用Softmax函数来预测属于健康状态的样本的概率分布,可表示为:

其中
F
k
(
⋅
)
F_{k}(·)
Fk(⋅)被视为第k个源目标域对的健康状态预测器,
σ
s
m
(
⋅
)
\sigma_{sm}(·)
σsm(⋅)表示等式(5)中所示的Softmax函数,并且
θ
D
k
,
P
R
=
{
ω
D
k
,
P
R
,
b
D
k
,
P
R
}
\theta^{D_{k},PR}=\{\omega^{D_{k},PR},b^{D_{k},PR}\}
θDk,PR={ωDk,PR,bDk,PR}是健康状态预测器的训练参数。
4.1.2.不可见故障分离模块
由源域样本训练的分类边界将可能对未看见故障的目标域样本进行错误分类。为了避免这样的错误分类,将神经元添加到层F3,使得第k个源域
s
k
s_{k}
sk的健康状态集合的维度从
∣
Y
s
k
∣
|Y^{s_{k}}|
∣Ysk∣增加到
∣
Y
s
k
∣
+
1
|Y^{s_{k}}|+1
∣Ysk∣+1。添加的神经元专注于预测目标域样本属于不可见故障的概率,并将其分类为未知的健康状态。层F3的输出可以具体表示如下:
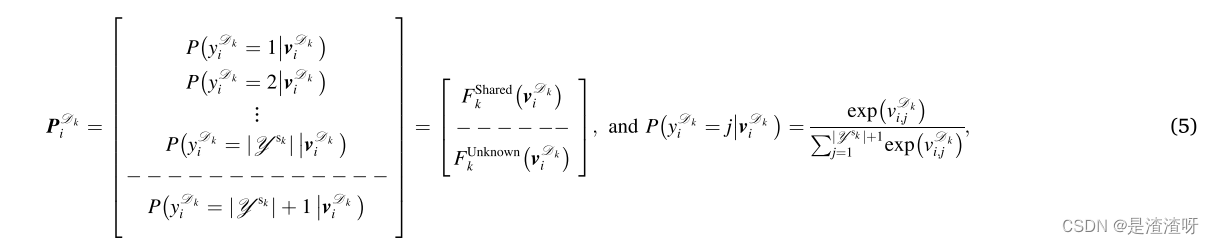
其中
v
i
,
j
D
k
=
v
i
D
k
ω
j
D
k
,
F
3
+
b
j
D
k
,
F
3
v^{D_{k}}_{i,j}=v^{D_{k}}_{i}\omega^{D_{k},F3}_{j}+b^{D_{k},F3}_{j}
vi,jDk=viDkωjDk,F3+bjDk,F3是在F3层中第
j
j
j个神经元的输出,
j
=
1
,
2
,
.
.
.
,
∣
Y
s
k
∣
+
1
j=1,2,...,|Y^{s_{k}}|+1
j=1,2,...,∣Ysk∣+1,
F
k
S
h
a
r
e
d
(
⋅
)
F^{Shared}_{k}(·)
FkShared(⋅)输出预测的源目标域样本属于共享健康状态的概率分布,并且
F
k
U
n
k
n
o
w
n
(
⋅
)
F^{Unknown}_{k}(·)
FkUnknown(⋅)生成跨域样本属于未知健康状态的预测概率。
所有目标域样本未被标记,而源域样本被标记。因此,域共享ResNet用标记的源域样本进行训练以确定分类边界。对于第
k
k
k个源-目标域对,源域样本的交叉熵损失为:

其中
I
(
⋅
)
I(·)
I(⋅)是指示函数,m是小批大小,且
F
k
S
h
a
r
e
d
(
v
i
s
k
)
F^{Shared}_{k}(v^{s_{k}}_{i})
FkShared(visk)是第
i
i
i个源域样本特征
v
i
s
k
v^{s_{k}}_{i}
visk属于共享健康状态的预测概率。
可以从源域中尚未看到的健康状态中提取一些目标域样本。在此情况下,将所述第
i
i
i个目标域样本特征
v
i
t
v^{t}_{i}
vit分类到未知健康状态的预测概率
F
k
U
n
k
n
o
w
n
(
v
i
t
)
F^{Unknown}_{k}(v^{t}_{i})
FkUnknown(vit)大于将来自共享健康状态的样本分类到未知健康状态的概率。因此,可以如下生成这样的目标域样本的二进制健康状态:

其中
y
i
t
−
s
k
,
U
n
k
n
o
w
n
=
1
y^{t-s_{k},Unknown}_{i}=1
yit−sk,Unknown=1表示第
i
i
i个目标域样本来自基于包含在源域
s
k
s_{k}
sk中的诊断知识的未知健康状态。从等式(5)以及(7),对于第k个源-目标域对,来自未知健康状态的目标域样本的交叉熵损失如下给出:
F
k
U
n
k
n
o
w
n
(
v
i
t
)
F^{Unknown}_{k}(v^{t}_{i})
FkUnknown(vit)表示第i个目标域样本属于未知健康状态的预测概率。
此外,来自共享健康状态的目标域样本的熵被优化以减少类内距离并增加类间距离,这使得分类边界能够通过低密度样本区域。结果,可以容易地分离来自未知健康状态的目标域样本。对于第k个源-目标域对,如下计算目标域样本的熵:
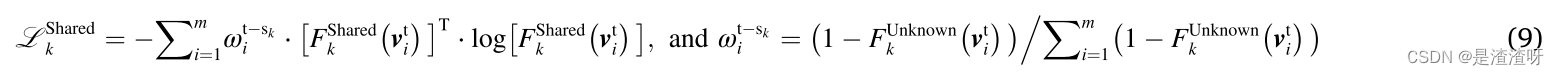
其中
F
k
S
h
a
r
e
d
(
v
i
t
)
F^{Shared}_{k}(v^{t}_{i})
FkShared(vit)是基于来自源域sk的知识的第i个目标域样本属于共享健康状态的预测概率。
4.1.3.重要性加权分布适配模块
目标域样本在健康状态之间是不平衡的,而源域样本是平衡的。为了有效地传输,我们使用域鉴别器来估计不平衡的程度,并相应地对目标域样本进行加权。鉴别器是具有表1中所示的架构参数的多层感知器
H
k
(
⋅
)
H_{k}(·)
Hk(⋅),并且将层F2的可转移特征映射到域标签空间中。鉴别器的输出表示如下:

其中
φ
D
k
φ^{D_{k}}
φDk是用于第k个源-目标域对的鉴别器的训练参数。感知器包括两个隐藏层。在
A
d
v
1
Adv_{1}
Adv1和
A
d
v
2
Adv _{2}
Adv2中使用Leaky-ReLU激活函数来去除稀疏梯度,以便可以稳定地训练鉴别器。下面描述的加权Wasserstein损失被用于优化域鉴别器:

其中正则化项保证了作为Wasserstein距离的约束的Lipschitz连续性,μ = 10是折衷参数,且
v
^
D
k
=
ϵ
v
s
k
+
(
1
−
ϵ
)
v
t
\widehat{v}^{D_{k}}=\epsilon{}v^{s_{k}}+(1-\epsilon)v^{t}
v
Dk=ϵvsk+(1−ϵ)vt沿着跨域特征分布和
ε
ε
ε ~
U
[
0
,
1
]
U[0,1]
U[0,1]之间的直线均匀采样。优化目标最大化来自共享健康状态的跨域样本的Wasserstein距离。根据式子(11),最佳鉴别器可以被推断为:

其中
v
∈
{
(
v
s
k
,
v
i
t
)
∣
i
=
1
,
2
,
.
.
.
,
m
}
v ∈\{(v^{s_{k}},v^{t}_{i})|i=1,2,...,m\}
v∈{(vsk,vit)∣i=1,2,...,m},
P
s
k
(
⋅
)
P_{s_{k}}(·)
Psk(⋅)and
P
t
S
h
a
r
e
d
(
⋅
)
P_{t}^{Shared}(·)
PtShared(⋅)分别是来自共享健康状态的源域样本和目标域样本的概率密度函数,并且由于K-Lipschitz连续性的条件,
H
k
(
v
)
H_{k}(v)
Hk(v)是有界的。
目标域特征 { v i t ∣ i = 1 , 2 , . . . , m } \{ v^{t}_{i}| i = 1,2,...,m \} {vit∣i=1,2,...,m}是从共享健康状态中提取的,所述共享健康状态可以具有有限的或大量的目标域样本。如果它们是从具有有限目标域样本的共享健康状态中提取的,则很可能 P s k ( v ) > P t S h a r e d ( v ) P_{s_{k}}(v)>P^{Shared}_{t}(v) Psk(v)>PtShared(v),在这种情况下,输出 H k ∗ ( v ) H^{*}_{k}(v) Hk∗(v)将足够大并且可能接近 H k ( v ) H_{k}(v) Hk(v)的上限。如果它们是从具有大量目标域样本的共享健康状态中提取的,则很可能 P s k ( x ) < P t S h a r e d ( x ) P_{s_{k}}(x)<P^{Shared}_{t}(x) Psk(x)<PtShared(x),并且输出 H k ∗ ( v ) H^{*}_{k}(v) Hk∗(v)将更接近 H k ( v ) H_{k}(v) Hk(v)的下限。可以通过使用Sigmoid函数将 H k ∗ ( v ) H^{*}_{k}(v) Hk∗(v)进一步映射到(0,1),使得因子 σ s ( H k ∗ ) σ_{s}(H^{*}_{k}) σs(Hk∗)应该指示目标域样本在平衡源域的基线下的不平衡程度。 σ s ( H k ∗ ) σ_{s}(H^{*}_{k}) σs(Hk∗)越大(即 σ s ( H k ∗ ) σ_{s}(H^{*}_{k}) σs(Hk∗) → 1),目标域特征越可能来自具有有限目标域样本的共享健康状态。 σ s ( H k ∗ ) σ_{s}(H^{*}_{k}) σs(Hk∗)越小,特征越可能来自具有充足样本的状态。
在假设目标域样本在健康状态之间不平衡并且它们中的一些是从未知健康状态中提取的情况下,第
i
i
i个目标域样本的平衡因子可以计算为:

应注意,来自未知健康状态的目标域样本将得到非常小的因子(接近零),而来自具有大量样本的状态的目标域样本将得到小因子(不像零那么小)。结合E式子(2),层F2的可转移特征之间的重要性加权MMD被估计如下:
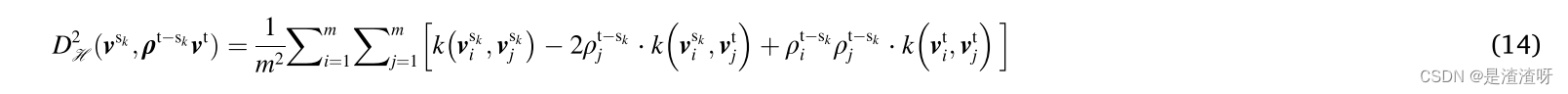
其中
ρ
t
−
s
k
=
{
ρ
i
t
−
s
k
∣
i
=
1
,
2
,
.
.
.
,
m
}
\rho^{t-s_{k}}=\{\rho^{t-s_{k}}_{i}|i=1,2,...,m\}
ρt−sk={ρit−sk∣i=1,2,...,m}。根据[29,30]中的研究,高斯内核-MMD具有三个弱点:1)时间复杂度高; 2)忽略了高阶矩的分布差异; 3)结果对高斯核宽度敏感。因此,在这项工作中,使用多项式核来构造RKHS,这已被证明可以提高诊断模型的传输性能(更多讨论请参见[29])。给定多项式核
k
(
x
,
y
)
=
(
a
x
T
+
b
)
c
k(x,y)=(ax^{T}+b)^{c}
k(x,y)=(axT+b)c,重要性加权多项式核-MMD(PK-MMD)可以推断为:
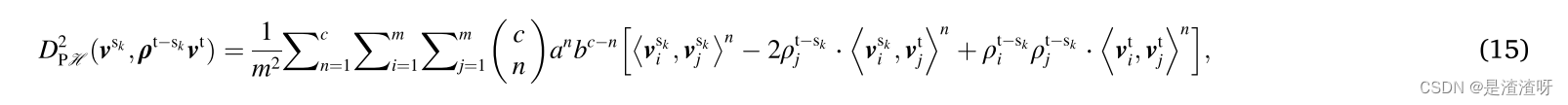
其中a、b、c分别是多项式核的斜率、截距和阶数。
对于第k个源-目标域对,通过最小化以下损失函数来适应所学习的可转移特征的部分分布:

4.2.多源诊断知识融合
诊断知识融合模块包括多源目标联合自适应和多诊断决策融合策略。
4.2.1.多源目标联合自适应
从多个源域抽取的样本存在分布差异。受源域样本分布基线不同的影响,目标域特征的分布在通过相同配置的PDA-Subnets学习时发生偏移。对于目标域样本与多个源域联合的分布适配,每个子网必须仔细配置,否则其中的一些可能会陷入欠适配。代替配置每个子网的参数的努力,由多个PDA子网分别学习的目标域特征之间的分布差异如下所示:

其中
D
P
H
2
[
G
i
(
X
t
)
,
G
j
(
X
t
)
]
D^{2}_{PH}[G_{i}(X^{t}),G_{j}(X^{t})]
DPH2[Gi(Xt),Gj(Xt)]表示基于分别用于第
i
i
i个和第
j
j
j个源-目标域对的特征提取器学习的目标域特征之间的PK-MMD。如果多个PDA子网中的一个充分地适配源域特征和目标域特征的分布,则所学习的目标域特征的分布可以被视为其他源-目标对的基线。这有助于提高其他子网的分布适应性。因此,单个目标域的样本分布可以与多个源域充分地联合适配,尽管被配置有相同的架构参数。
4.2.2.多诊断决策融合策略
预测概率
{
F
k
U
n
k
n
o
w
n
(
v
i
t
)
∣
i
=
1
,
2
,
.
.
.
,
m
}
\{F^{Unknown}_{k}(v^{t}_{i})|i=1,2,...,m\}
{FkUnknown(vit)∣i=1,2,...,m}不仅表示目标域样本是否来自未知健康状态,而且表示目标域
t
t
t和源域
s
k
s_{k}
sk之间的相似性。该概率越小,目标域样本与源域样本越相似。因此,可以设计一种策略来融合多个诊断决策,如下所示:

其中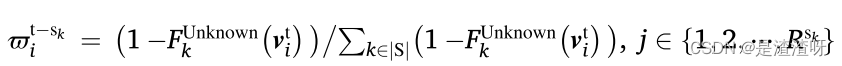 是
F
k
S
h
a
r
e
d
(
v
i
t
)
F^{Shared}_{k}(v^{t}_{i})
FkShared(vit)中概率元素的索引,argmax(⋅)返回具有第i个目标域样本的加权概率的最大和的预测健康状态的索引。在式子(18)中有两种情况。第一种情况是当每个PDA-子网相信目标域样本来自未知健康状态时,导致目标域样本实际上来自未知健康状态的结论。第二种情况是当多个PDA-子网中的至少一个认为目标域样本来自共享健康状态时,导致通过使用预测概率
{
F
k
U
n
k
n
o
w
n
(
v
i
t
)
∣
i
=
1
,
2
,
.
.
.
,
m
}
\{ F^{Unknown}_{k}(v^{t}_{i})|i=1,2,...,m\}
{FkUnknown(vit)∣i=1,2,...,m}加权多个诊断决策的最终决策。具有大相似性的源和目标对将对最终决策贡献很大,而具有小相似性的对可能提供具有低置信度的结果
是
F
k
S
h
a
r
e
d
(
v
i
t
)
F^{Shared}_{k}(v^{t}_{i})
FkShared(vit)中概率元素的索引,argmax(⋅)返回具有第i个目标域样本的加权概率的最大和的预测健康状态的索引。在式子(18)中有两种情况。第一种情况是当每个PDA-子网相信目标域样本来自未知健康状态时,导致目标域样本实际上来自未知健康状态的结论。第二种情况是当多个PDA-子网中的至少一个认为目标域样本来自共享健康状态时,导致通过使用预测概率
{
F
k
U
n
k
n
o
w
n
(
v
i
t
)
∣
i
=
1
,
2
,
.
.
.
,
m
}
\{ F^{Unknown}_{k}(v^{t}_{i})|i=1,2,...,m\}
{FkUnknown(vit)∣i=1,2,...,m}加权多个诊断决策的最终决策。具有大相似性的源和目标对将对最终决策贡献很大,而具有小相似性的对可能提供具有低置信度的结果
4.3.训练过程
提出的MSTLN的训练分为三个步骤。在第一步中,多个PDA子网中的域共享ResNet由下面的优化目标训练,以挑选出看不见的故障的目标域样本,并将它们阻塞到未知的健康状态中。

其中
θ
D
k
=
{
θ
D
k
,
F
E
,
θ
D
k
,
P
R
}
\theta^{D_{k}}=\{\theta^{D_{k},FE},\theta^{D_{k},PR}\}
θDk={θDk,FE,θDk,PR}是用于源-目标域对
D
k
D_{k}
Dk的域共享ResNet的训练参数。
在第二步中,基于源域样本的不同分布基线,优化多个域鉴别器以学习目标域样本的抵消因子。优化目标如下所示:

最后,下面的损失函数被最小化以联合训练多个域共享的ResNet,其单独地适应所学习的可转移特征的部分分布,但共同地学习可转移特征的足够知识。结果,多个诊断模型可以从多个源域转移到单个目标域。

其中
λ
、
β
和
γ
λ、β和γ
λ、β和γ是折衷参数。第一项是通过使用来自多个源域的标记样本来训练多个诊断模型。第二项是在存在不平衡的目标域样本的情况下,校正来自共享健康状态的所学习的可转移特征的分布差异。第三项集中于最小化目标域样本的熵。最后一个适应基于多个源域样本的不同分布基线学习的目标域特征的分布。使用Adam优化算法分别实现公式(19)-(21),训练参数依次更新为:

其中
η
η
η是学习率。MSTLN的训练过程详见表2。

五.实验
略




![[Golang实战] 带你入手gin框架使用,以项目为例](https://img-blog.csdnimg.cn/0cfbe8f3cb9c4d82b8bb787a08e811e3.png)