PartA2数据和源码配置调试过程请参考上一篇博文:【三维目标检测】Part-A2(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍PartA2网络结构及其运行中间状态。
1 PointRCNN模型总体过程
Part-A2的整体结构如下图所示,主要包括Part-Aware stage 和Part-aggregation stage两个阶段。Part-Aware stage主要是提取点云中各个点的特征,包括语义分割特征和目标内部点的特征,提取特征的方法是一个采用三维稀疏卷积的UNET结构。UNET是二维图像语义分割中比较常见的一个主干网络结构,Part-A2沿用了这个结构,并且将二维卷积相应地替换成三维稀疏卷积。Part-Aggregation stage阶段主要是根据上一阶段的特征和候选框proposal生成最终的目标分类、置信度和位置预测特征,这个功能与SECOND等三维目标检测网络基本一致,但进行了语义特征和Part 特征的融合。
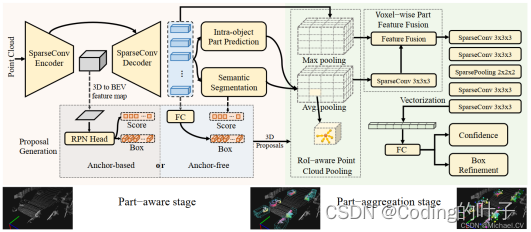

2 主要模块解析
2.1 体素化
源码中用于实现体素化的入口函数为self.voxelize(points),具体实现函数为Voxelization(voxel_size=[0.05, 0.05, 0.1], point_cloud_range=[0, -40, -3, 70.4, 40, 1], max_num_po ints=5, max_voxels=16000, deterministic=True)。函数输入分别为:
(1)points,Nx4,原始点云,N表示点云数量,4表示特征维度,特征为坐标x、y、z与反射强度r。
(2)voxel_size:单位体素的尺寸,x、y、z方向上的尺度分别为0.05m、0.05m、0.1m。
(3)point_cloud_range:x、y、z方向的距离范围,结合(2)中体素尺寸可以得到总的体素数量为1408x1600x41,即92364800(41x1600x1408)。
(4)max_num_points:定义每个体素中取值点的最大数量,默认为5,在voxelnet中T=35。
(5)max_voxels:表示含有点云的体素最大数量,默认为16000。当数量超过16000时,仅保留16000,当数量不足16000时,则保留全部体素。
(6)deterministic:取值为True时,表示每次体素化的结果是确定的,而不是随机的。
体素化结果输出字典类型结果voxel_dict,主要包含以下内容:
(1)voxels:Mx5x4,体素中各个点的原始坐标和反射强度,M(M≤16000)个体素,每个体素最多5个点。
(2)num_points:Mx1,每个体素中点的数量,最小数量为1,最大数量为5。
- coors:体素自身坐标,坐标值为整数,表示体素的按照单位尺度得到的坐标,Mx4,[batch_id, x, y, z]
- voxel_centers:体素中心坐标,坐标值为实际物理尺度,Mx3。
下图中为输出结果,由于测试代码batch size为2,所以32000是两个样本总体体素数量,因而会大于16000,但不超过32000。接下来的讲解中我们用M来表示体素数量。

2.2 体素特征提取VFE(voxel_encoder)
在voxelnet中,体素特征通过SVFE层提取,即连续两层VFE,其中VFE层提取体素特征用的是PointNet网络。而在该源码中,VFE层被进行了简化HardSimpleVFE(voxel_encoder),即对每个体素中的点求平均值,用平均值作为体素特征,取平均时点的数量由num_points决定。Mx5x4的voxels经过VFE后的维度为Mx4(voxel_features),即在第二个维度点的数量上进行了平均。体素特征提取相当于用新的4个维度特征来表示体素内一组点的共同特征。体素特征提取的入口函数为self.voxel_encoder(voxel_dict['voxels'], voxel_dict['num_points'], voxel_dict['coors'])
2.3 Unet稀疏卷积特征提取 middle_encoder
类比VoxelNet中的CML(Convolutional Middle Layer)层,voxelnet中直接用三维卷积进行特征提取,而PartA2采用了连续Unet稀疏卷积进行特征提取。PartA2是一个两阶段目标检测网络,那么其做法是在第一阶段通过特征图生成候选框,这一点仍然可以参考前面介绍的VoxelNet。作者在进行网络设计的时候重点在于考虑物体内部各点分类的准确性,从这一点上来说,可以通过语义分割网络来对个点类别进行分类判断。
输出特征可以用包括两部分。第一部分是空间特征spatial_features,来源于Unet编码层,对应到稀疏网格,维度为(CxD)xHxW,即 256x200x176。第二部分是语义分割特征seg_features,来源于Unet解码层,对应每一个点的分类,维度为MxC,即Mx16。
PartA2的Unet语义分割的入口函数为self.middle_encoder(voxel_features, voxel_dict['coors'], batch_size),输出空间特征spatial_features (256x200x176)和语义分割特征seg_features(Mx16)。
Unet编码层:
三维稀疏卷积:voxel_features(30920x4) -> 30920x16,x
1个三维稀疏卷积:Mx16,x -> M1x16,x1
3个三维稀疏卷积:M1x16,x1 -> M2x32,x2
3个三维稀疏卷积:M2x32,x2 -> M3x64,x3
3个三维稀疏卷积:M3x64,x3 -> M4x64,x4
encode_features = [x1, x2, x3, x4]
out = self.conv_out(encode_features[-1])
spatial_features = out.dense()
N, C, D, H, W = spatial_features.shape
# 256x200x176,编码层提取深层特征图
spatial_features = spatial_features.view(N, C * D, H, W)
Unet解码层:
解码层1:x4(M4x64)、x4(M4x64)-> M3x64,x5
解码层2:x3(M3x64)、x5(M3x64)-> M2x32,x6
解码层3:x2(M2x32)、x6(M2x32)-> M1x16,x7
解码层4:x1(M1x16)、x7(M1x16)-> Mx16,x8,seg_features
2.4 主干网络特征提取
PartA2的主干网络采用的是SECOND结构,通过两条同类提取两种不同尺度的特征图。第一条通路是2.3中的空间特征spatial_features 256x200x176经连续6个3x3卷积得到128x200x176维度的特征,记为out1。第二条通路是out1继续经过连续6个3x3卷积(其中第一个步长为2)得到256x100x88维度的特征,记为out2。out1和out2为主干网络输出结果。主干网络关键入口函数为self.backbone(feats_dict['spatial_features']) 。
输入:x = self.backbone(feats_dict['spatial_features'])
out1:256x200x176 -> 128x200x176
Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
Out2:128x200x176 -> 256x100x88
Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True
)
Out = [out1, out2] [128x200x176, 256x100x88]2.5 上采样拼接 self.neck
Neck网络分别对out1、out2进行上采样,out1的维度从128x200x176转换为256x200x176,out2的维度也从256x2100x88转换为256x200x176,两者维度完全相同。out1和out2拼接后得到Neck网络的输出结果,即neck_feats,维度为512x200x176。
分别对out1、out2进行上采样:
out1:128x200x176 -> 256x200x176
out2:256x100x88 -> 256x200x176
拼接out:256x200x176、256x200x176 -> 512x200x176 (neck_feats)
2.6 RPN Head与Loss
RPN head主要目的是用于生成候选框,其输入为2.5节中的neck_feats,维度为512x200x176。与前面讲解的PointPillars类似,PartA2的RPN Head包含了候选框的分类、位置和方向预测,分别对应分类head、位置head和方向head。
分类head:512x200x176特征经过conv_cls(512,18)得到18x200x176个预测结果cls_score,每个位置6个anchor,共3个类别。
位置head:512x200x176特征经过conv_reg(512,42)得到42x200x176个预测结果bbox_pred。在Second中每个位置有3个anchor,每个anchor有7个参数,相比之下,这里每个位置有6个不同的anchor。
方向head:512x200x176特征经过conv_reg(512,12)得到12x200x176个预测结果dir_cls_preds,针对6个不同anchor,每个anchor两种方向。
与VoxelNet不同之处在于,PartA2增加了对方向的预测,更有利于模型的训练,特别是更加适用于方向预测相反的情况。如果仅采用位置head,那么在方向正好相反时,前6个参数的损失会非常小,而最后一个角度参数的损失会非常大。
关键程序如下所示。
输入:neck_feats 512x200x176
rpn_outs = self.rpn_head(feats_dict['neck_feats'])
PartA2RPNHead(
(loss_cls): FocalLoss()
(loss_bbox): SmoothL1Loss()
(loss_dir): CrossEntropyLoss()
(conv_cls): Conv2d(512, 18, kernel_size=(1, 1), stride=(1, 1))
(conv_reg): Conv2d(512, 42, kernel_size=(1, 1), stride=(1, 1))
(conv_dir_cls): Conv2d(512, 12, kernel_size=(1, 1), stride=(1, 1))
)PartA2模型的损失函数由三部分组成。第一部分是RPN loss,包含目标分类损失、三位目标框回归损失和方向损失,对应的损失函数分别为FocalLoss、SmoothL1Loss和CrossEntropyLoss。
2.7 分割损失
PartA2模型损失的第二部分是分割损失,包括语义分割损失和Part分割损失。计算步骤如下:
(1)确定标签的前景点和背景点,前景点用0~2表示,背景点用3表示,处于真实框外节相邻的点定义为临界点,不参与损失计算。
(2)在三维Unet中得到seg_features语义分割特征(Mx16),经过seg_cls_layer-Linear(16, 1)和seg_reg_layer-Linear(16,3)分别得到最终语义分割结果和Part位置结果。
(3)Part位置的真实标签为真实框内体素点相对于真实框中心的偏移比例。程序中将真实框的底部中心作为参考,并将体素中心坐标减去中心点坐标后按照真实框的偏航角进行旋转,最后除以真实框的尺寸进行归一化。最终Part的位置范围被限定在0~1之间。
(4)计算损失函数。仅对(1)中的前景点进行损失计算,其中语义分割损失采用FocalLoss。Part因其取值范围处于0~1之间,作者采用了交叉熵损失,即CrossEntropyLoss。
分割损失的关键函数如下所示。
semantic_results = self.semantic_head(x)
PointwiseSemanticHead(
(seg_cls_layer): Linear(in_features=16, out_features=1, bias=True)
(seg_reg_layer): Linear(in_features=16, out_features=3, bias=True)
(loss_seg): FocalLoss()
(loss_part): CrossEntropyLoss()
)2.8 ROI损失
PartA2第三部分损失是ROI损失。由于PartA2是一个典型的两阶段三维目标检测模型,因此损失函数基本包括RPN和ROI损失。但PartA2本身增加了一个分割损失。
ROI损失计算步骤包括再采样、正负样本选取、特征提取和损失计算等步骤,具体过程可参考PointRCNN中ROI损失计算部分。 最终roi损失包含分类损失和回归损失,其中回归损失用位置损失和角点损失,即loss_cls、loss_bbox、loss_corner。在计算分类损失loss时,roi的真实标签label根据iou重叠比列大大小转换为0~1之间的数值。ROI分类损失loss_cls的损失函数为CrossEntropyLoss,bbox位置损失loss_bbox损失函数为SmoothL1Loss,角点损失loss_corner函数为 HuberLoss。
2.9 总体损失
总体损失包括rpn损失、分割损失、roi损失。rpn分类损失loss_rpn_cls的损失函数为 FocalLoss。rpn位置损失loss_rpn_bbox的损失函数为SmoothL1Loss。rpn方向损失loss_rpn_dir的损失函数为CrossEntropyLoss。语义分割损失loss_seg的损失函数为FocalLoss。Part位置损失loss_part的损失函数为CrossEntropyLoss。roi分类损失loss_cls的损失函数为CrossEntropyLoss,bbox位置损失loss_bbox损失函数为SmoothL1Loss,角点损失loss_corner函数为 HuberLoss。
总体损失类型如下所示。
loss_rpn_cls: FocalLoss
loss_rpn_bbox: SmoothL1Loss
loss_rpn_dir: CrossEntropyLoss
loss_seg: FocalLoss
loss_part: CrossEntropyLoss
loss_cls: CrossEntropyLoss
loss_bbox: SmoothL1Loss
loss_corner: HuberLoss2.10 顶层结构
顶层结构主要包含以下三部分:
(1)特征提取:self.extract_feat,包含了体素化、体素特征提取、Unet编解码、主干网络和Neck网络,输出空间特征spatial_features、语义分割特征seg_features和neck特征。
(2)ROI特征提取:包括筛选候选框、提取分割特征和ROI特征等。
(3)损失函数:见2.10节。
def forward_train(self, points, img_metas, gt_bboxes_3d, gt_labels_3d, gt_bboxes_ignore=None, proposals=None):
feats_dict, voxels_dict = self.extract_feat(points, img_metas)
losses = dict()
if self.with_rpn:
rpn_outs = self.rpn_head(feats_dict['neck_feats'])
rpn_loss_inputs = rpn_outs + (gt_bboxes_3d, gt_labels_3d, img_metas)
rpn_losses = self.rpn_head.loss(*rpn_loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
losses.update(rpn_losses)
proposal_cfg = self.train_cfg.get('rpn_proposal', self.test_cfg.rpn)
proposal_inputs = rpn_outs + (img_metas, proposal_cfg)
proposal_list = self.rpn_head.get_bboxes(*proposal_inputs)
else:
proposal_list = proposals
roi_losses = self.roi_head.forward_train(feats_dict, voxels_dict, img_metas, proposal_list, gt_bboxes_3d, gt_labels_3d)
losses.update(roi_losses)
return losses3 训练命令
python tools/train.py configs/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class.py4 运行结果