论文题目:Legal Judgment Prediction via Event Extraction with Constraints
论文来源:ACL2022
论文链接:https://aclanthology.org/2022.acl-long.48.pdf
代码链接:GitHub - WAPAY/EPM
0 摘要
近年来,虽然法律判断预测任务(LJP)取得了重大的进展,错误的预测SOTA LJP模型可以部分归因于他们未能(1)定位关键事件信息决定判断,和(2)利用跨任务一致性约束存在的子任务LJP。为了解决这些弱点,我们提出了EPM,一个具有约束的基于事件的预测模型,它在标准LJP数据集上的性能超过了现有的SOTA模型。
1 引言
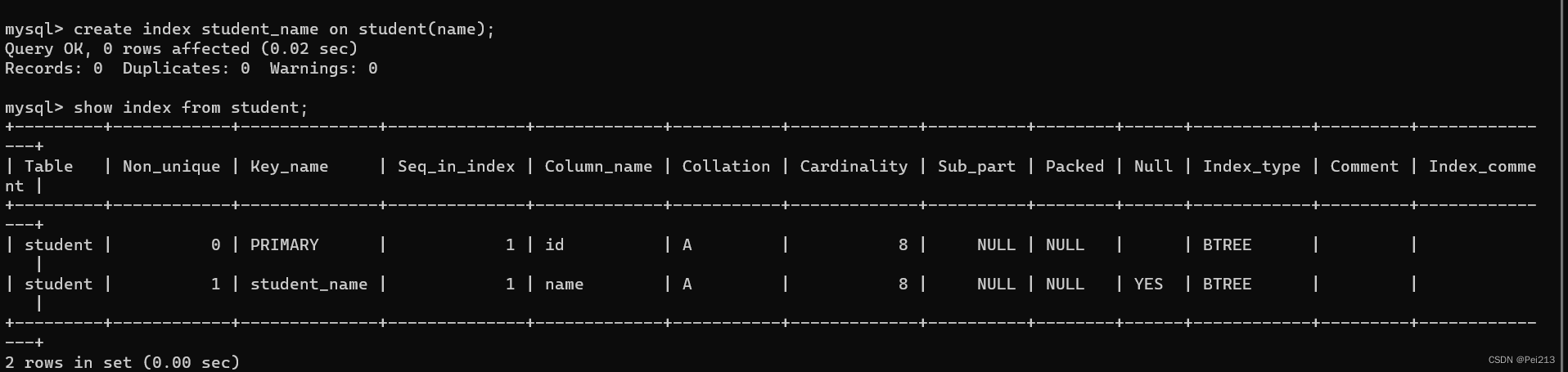
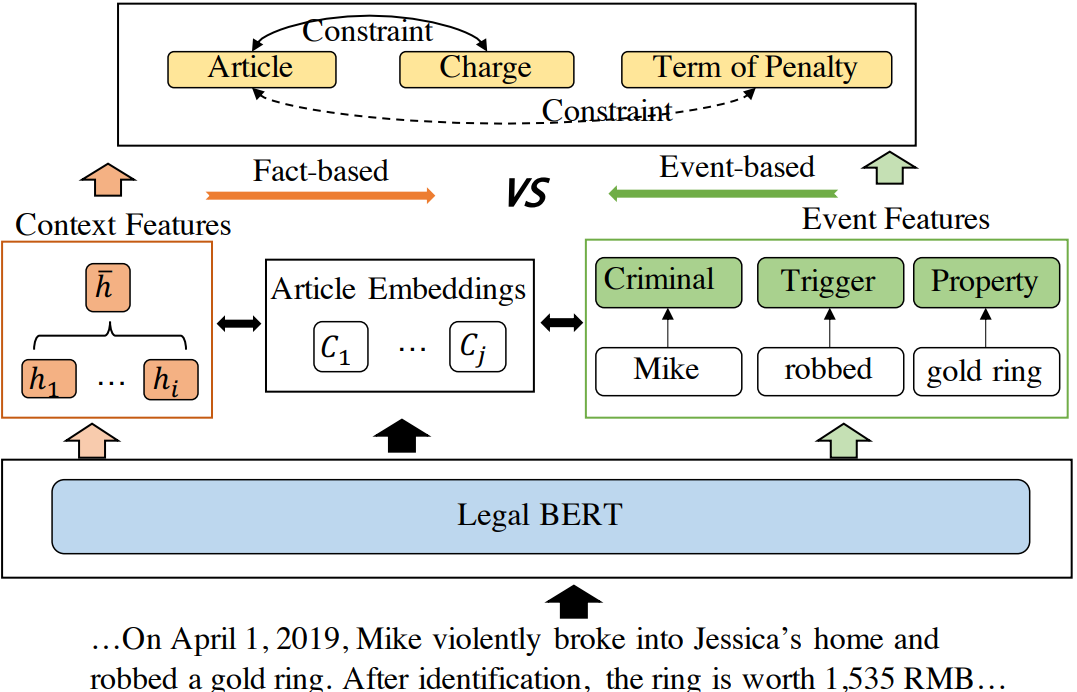
法律判断预测(LJP)是法律判断决策过程中的一个关键任务。鉴于一个法律案件的事实,其目的是预测法院的结果。到目前为止,英语LJP专注于预测法律文章和法院判决,而French LJP专注于预测法院裁决。在本文中,我们通过广泛使用的CAIL数据集,其中涉及三个子任务:预测(1)法律文章,(2)收费和(3)处罚条款,如图1所示。
虽然最先进的(SOTA)LJP模型有几个基本的局限性(Binns,2019),但它们面临的技术问题之一是,它们未能定位到决定判断结果的关键事件信息。考虑图2,其中一个抢劫案件的事实陈述涉及到非法闯入的描述。现有的模型错误地预测了法律上的文章是关于非法搜查的,因为许多词描述了入室盗窃的过程,即使主要的观点是关于抢劫的。

我们如何解决这个问题?回想一下,在大陆司法系统中,一条法律条款包括两部分:(1)事件模式,它规定了违法行为的行为;(2)该判决,其中描述了相应的处罚。在图1中与抢劫有关的法律文章中,事件模式为Anyone robs public或private property,判决是 be sentenced to imprisonment of not less than three years and not more than ten years。每条法律文章所定义的事件模式和相应的判断可以视为一个因果对:如果检测到一个事件模式,则可以从该因果对中推断出相应的判断。换句话说,案件的推理判断所基于的事件信息是案件中描述的事件信息。如果我们使用从事实中提取的细粒度的关键事件信息来匹配法律条款中定义的事件模式,就可以准确地检索到适用于该案件的法律条款,并可以通过法律条款中的判断来推断出刑罚。例如,如果我们可以将图1中的fact语句压缩为表1中的细粒度事件,我们就可以很容易地将它与第263条中定义的事件模式进行匹配(参见图1)。然后,可以将本文中定义的惩罚作为预测的判断。

受此观察结果的启发,我们试图利用事件信息来改善LJP,具体方法是:(1)提取案件的细粒度关键事件,然后(2)根据提取的事件信息(而不是整个事实陈述)预测判决。为此,我们提出了一个参照法律条款的层次结构的层次结构事件定义。由于没有用事件信息进行注释的公共LJP数据集,所以我们在CAIL(一个被SOTA方法广泛使用的公共LJP数据集)的顶部手动注释了一个合法的事件数据集。然而,事件抽取仍然具有挑战性。因此,为了指导学习过程,我们设计了事件抽取的输出约束(例如,给定的触发类型是必需的),并在我们的模型中使用它们。
与SOTA方法相关的另一个缺点是,它们未能利用三个LJP子任务之间的一致性约束。具体来说,每条法律条款都对可能的收费和期限惩罚施加了限制。然而,SOTA方法通常将LJP框架为一个多任务学习问题,其中三个任务通过共享表示在模型中共同学习,而不保证上述跨任务约束得到满足。为了解决这个问题,我们引入了一致性约束。
我们的贡献
首先,我们提出了第一个关于利用从案例事实中提取事件来解决LJP任务的研究。
其次,我们为法律案例定义一个层次事件结构,并收集一个带有事件注释的新LJP数据集。最后,我们提出了一个在两种约束条件下共同学习LJP和事件抽取的模型。实验结果表明,该模型在性能上优于现有的SOTA模型。
2 相关工作
Legal judgment prediction.
LJP已经在不同的司法管辖区进行了调查,比如中国,美国,欧洲,法国,印度。而早期的工作则依赖于基于规则的方法,后来的方法使用分类技术。最近,神经模型通过在一个统一的框架中共享参数来共同预测判断结果,应用预训练过的语言模型,利用标签-注意力机制或者注入法律知识。与我们的工作不同,这些工作并没有探讨LJP的案例事件的使用。虽然现有的工作利用了子任务之间的依赖关系,它们只是利用子任务的预测结果作为辅助特征来相互影响,因此仍然可能预测不一致的结果。相反,我们的跨任务一致性约束可以保证预测是一致的。
法律领域中的事件抽取
一些工作已经定义了法律事件,并建立了模型,以使用这些定义从事实陈述中自动提取法律事件。然而,我们不能使用这些事件注释的法律数据集,原因有两个。首先,这些数据集中的法律文档不包含法律判断预测,因此我们不能使用它们来联合提取事件并做出法律判断预测。第二,有一个关键的区别和以前的工作的法律事件(即触发类型和论元角色)定义:虽然现有工作定义法律事件仅仅从事件抽取的角度,我们定义法律事件,触发类型和论元角色LJP是有用的。
3 数据集和任务定义
数据集
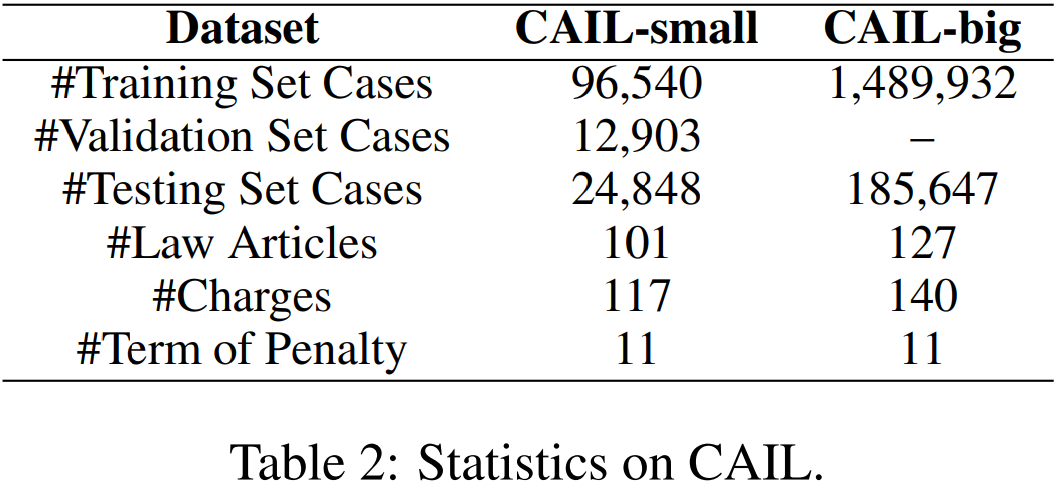
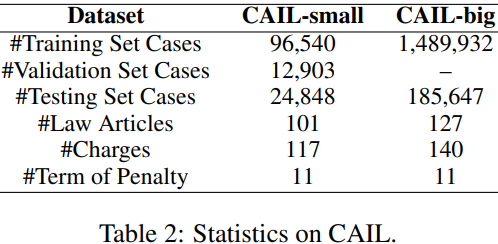
我们使用CAIL作为我们的数据集,这是一个已被广泛使用的大型公开获取的中国法律文件数据集。在CAIL中,每一份判决文件都包含一份事实陈述和判决结果(法律条款、指控和处罚期限)。我们遵循之前的工作对CAIL进行预处理。CAIL由两个子数据集组成: CAIL-big和CAIL-small,其统计数据如表2所示。CAIL上的LJP绝不是微不足道的:CAIL-big上的文章、收费和处罚分别有127、140和11个类别。
任务定义
根据事实陈述,CAIL上的LJP涉及三个预测子任务,分别对应于法律条款、指控和处罚条款。根据之前的工作,我们将每个子任务
形式化为多类分类问题,并为每个∈预测相应的结果
,其中
是t的标签集。
4 基线LJP模型
我们首先设计一个多任务的法律判断预测模型,我们将使用它作为基线,并在随后的章节中增加事件抽取和约束。我们的模型的框架如图3所示。
token表示层
给定一个以字符序列表示的事实语句D = {x1,x2,…xlf},我们首先将每个字符传递到一个预训练的BERT编码器
![]()
其中![]() 是事实陈述的隐藏向量序列,
是事实陈述的隐藏向量序列,![]() 是事实陈述的长度。
是事实陈述的长度。
生成上下文功能
接下来,我们通过对![]() 应用最大池化层来生成事实陈述的上下文表示
应用最大池化层来生成事实陈述的上下文表示
![]()
结合了法律文章的语义
使用上述上下文表示来预测判断本质上是将每条定律文章视为一个原子标签,而不利用其语义信息。受以前工作的启发,我们采用了一种注意机制来将文章的语义合并到模型中。具体来说,我们将¯h与所有候选法律条款进行匹配。为此,我们首先使用相同的编码器对每条定律的字符序列进行编码,得到隐向量序列![]() ,其中,
,其中,![]() 是一篇法律文章文本的长度。然后我们对
是一篇法律文章文本的长度。然后我们对![]() 应用一个最大池化层来得到上下文表示c。接下来,我们使用事实语句的上下文表示,
应用一个最大池化层来得到上下文表示c。接下来,我们使用事实语句的上下文表示,,来查询所有候选文章,以便挖掘文章文本中最相关的语义。具体来说,我们首先得到
和第j篇文章cj之间的相关性得分:
![]()
其中Wc是一个可训练的矩阵。然后,将最相关的语义以一种加权的方式进行总结,以表示文章文本中的特征:
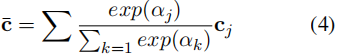
其中,包含了集成的文章语义。法律判断预测层。为了预测法律判断,我们将
和
输入三个任务特定分类器如下:
![]()
其中Wt和bt为可学习参数,为任务 t 的预测分布。
训练
对于每个法律判断预测任务t,我们使用交叉熵作为损失函数来测量预测的ˆyt与地面真实yt之间的距离。
![]()
最终损失由三个子任务的损失组成,定义如下:
![]()
其中,超参数λ决定了所有子任务损失之间的权衡。该模型被训练为最小化L(Θ)。
5 通过事件抽取来改进LJP
在本节中,我们提出了一种利用事件抽取来改进LJP的新方法。
5.1 分级法律事件的定义
事件定义
每条法律条款都规定了什么事件违反了本文,因此根据法律条款对法律事件的定义很容易。中国的法律条款都是按等级制度组织起来的。例如,抢劫相关物品属于财产侵权,是抢劫和盗窃相关物品的总称。我们按照这个层次结构来定义法律事件。如图4所示,财产侵权被视为上级事件类型,而抢劫和盗窃被视为从属事件类型。这个层次结构可以表达不同的法律事件之间的联系。
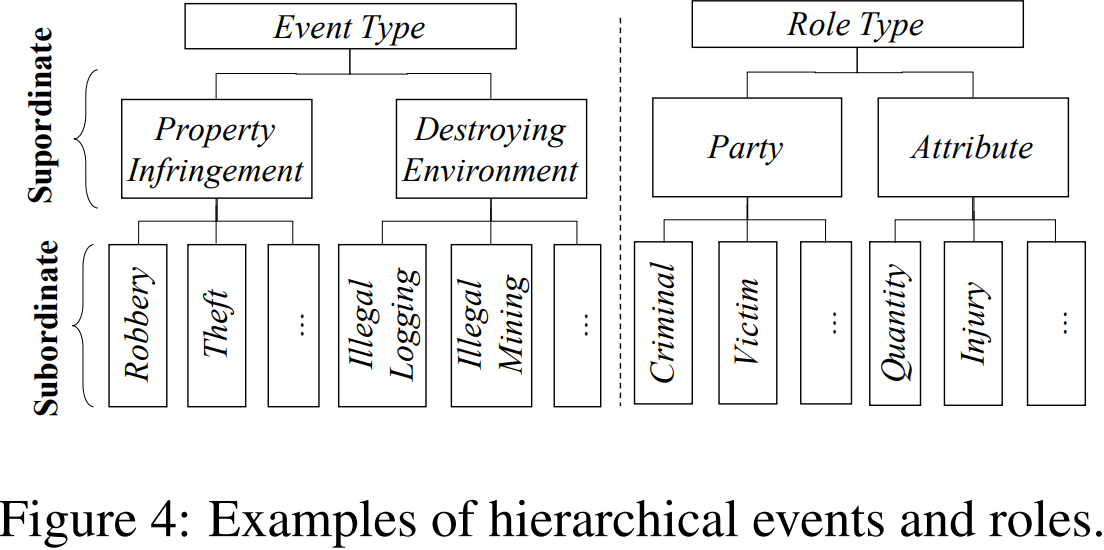
触发词和角色定义
事件触发词是一个实现事件发生并具有类型的词。在事件类型和触发词类型之间存在一对一的对应关系。例如,Robbery事件具有触发词类型Trigger-Rob。
接下来,我们为每个事件定义角色,使它们反映出对做出法律判断有用的事件的关键元素。例如,Criminal和Victim角色指定了案件中涉及的各方,而Quantity角色衡量的是loot的价值,并以此为基础衍生出penalty。我们以一种分层的方式来定义角色。如图4所示,当事人的争论是参与案件的人,其下属角色包括Criminal和Victim。
5.2 数据集收集
为了研究事件抽取对LJP的使用,我们手动创建了一个事件注释的LJP数据集,因为没有这样的数据集是公开可用的。
步骤1:判断文件收集
我们基于CAIL构建了我们的事件注释数据集LJP-E。具体来说,我们首先分析了SOTA模型的性能对CAIL-small的验证部分,识别其性能不佳的15篇法律文章,然后选择这15篇法律文章可以判断的案例子集进行注释。这个子集由1367个文档组成(957个作为训练集,136个作为验证集,274个作为测试集)。此后,我们将这组判决文件称为。
步骤2:事件触发词和论元角色注释
接下来,我们在在给他们三个小时的如何注释事件的教程之后,雇佣了两个注释者来为中的每个情况手动生成事件触发词和论元角色。注释者的母语为中文,他们是自然语言处理专业的研究生,在处理法律问题方面有丰富的工作经验(他们都不是作者)
注释过程
根据案例的事实陈述和金法条款,要求每个注释者独立突出事实陈述中反映案例核心事件的显著词,并与法律条款的事件模式很好地相关性。然后要求每个人(1)选择一个触发词并为其分配一个从属触发类型,(2)为预定义角色列表中的每个论元分配一个从属角色类型。触发词类型和角色类型清单是由作者在阅读了大量的事实陈述和相应的文章后设计的。注释者间的协议编号可在附录E中找到。
在上述步骤之后,中的每种情况都用触发词、类型、论元和角色进行注释。每个事件的平均参数数为4.13。有16种不同的从属角色和15种不同的从属触发类型。注释者之间的每一个分歧都通过讨论来解决。
5.3 层次结构的事件抽取
为了使用事件注释,我们使用分层事件抽取层来增强我们的基线模型,该层可以检测事件触发词和论元,并确定触发词类型和论元角色(参见图3)。所得到的模型同时学习事件抽取和LJP。
我们将事件抽取形式化为一个token标记问题。给定事实token的隐藏向量,我们分配每个token一个从属触发词(如果它是触发词的一部分)或从属角色类型(如果它是论元的一部分)。
分层事件抽取层由两个模块组成: (1)一个上级模块,根据每个隐藏向量处理所有上级类型/角色,以获得它们的相关性;(2)一个下级模块,基于分层信息计算下属类型/角色概率分布,如下所述。
对于特定的上级类型/角色j,我们用可训练向量pj表示其语义特征。我们采用全连接层来计算隐藏向量hi与上级类型/角色pj之间的相关性得分。
![]()
其中,uij表示相关性得分,[;]表示两个向量的连接。然后,我们应用一个softmax来得到每个token xi的上级类型/角色特征。
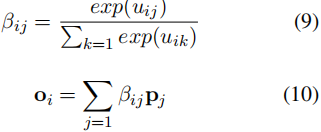
其中,oi是集成的上级类型/角色特征,它提供了用于预测下级类型/角色的面向上级的信息。接下来,我们将每个hi与oi作为触发类型和论元角色分类器的输入特征,并估计token xi属于下属类型/角色rj的概率如下:
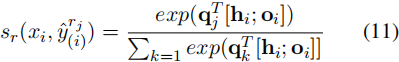
其中qj是rj的可训练向量。在获得xi的类型/角色概率分布后,我们应用CRF生成得分最高的类型/角色序列,其中一个类型/角色序列的得分![]() 计算为:
计算为:
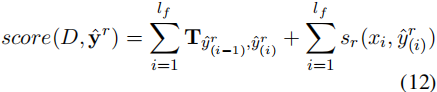
这里,T是从一个标签转换到另一个标签的分数。
我们不是基于上下文事实表示特征来预测LJP,而是用检测到的事件特征来代替它。具体来说,我们将提取的触发词和论元及其类型/角色嵌入输入到三个特定于任务的分类器中。将提取的跨度表示为
。我们对每个跨度应用一个最大池化层,并与相应的从属类型/角色嵌入q进行连接:
![]()
其中表示span i的表示,它同时包含语义和从属类型/角色特征。基于
,我们可以计算上下文跨度表示
如下:
![]()
它被用于代替公式2中的上下文事实表示。
训练
事件抽取损失的定义为:
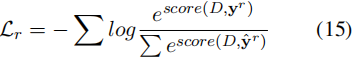
其中yr是黄金标签序列。我们将Lr纳入公式7中的总损失如下:
![]()
6 利用约束
为了提高模型的性能,我们探索了两种类型的约束,如下所述。
6.1 基于事件的约束
基于事件的约束是对事件的输出约束。我们提出了两个这样的约束条件。
绝对约束
对于一个法律事件,触发词必须只出现一次,并且某些角色是强制性的(例如,从属角色罪犯应该至少出现一次)。如果触发词缺失,我们将施加以下惩罚:
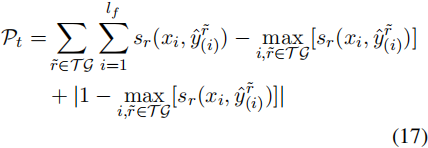
其中TG是触发词库存。如果缺少所需的角色r,我们将处以以下惩罚:
![]()
基于事件的一致性约束
如果检测到触发词类型,则应仅检测其所有相关角色。例如,如果检测到非法日志记录事件,则不应预测与非法日志记录相关的角色。如果预测到触发r,我们施加以下惩罚:
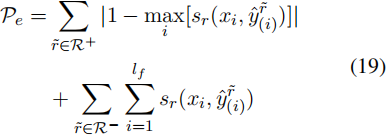
其中,R+是预测R时应该发生的角色集,而R−是不能发生的角色集。我们将所有罚款条款相加,并将其纳入总损失如下:
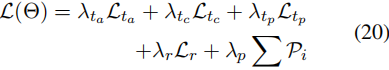
6.2 跨任务一致性约束
虽然我们的模型所采用的多任务学习设置允许LJP的子任务通过共享表示层相互受益,但它没有明确地利用它们之间存在的依赖关系。下面我们利用了两种这样的依赖关系,一种是在法律条款和收费之间,另一种是在法律条款和刑罚期限之间。
每条法律条文都规定了允许的收费和处罚期限的范围。因此,我们可以利用这些依赖关系来约束(并有希望改进)使用预测的法律文章对指控和刑罚期限的预测。更具体地说,我们让模型在训练过程中通过修改交叉熵损失来学习如何预测电荷和惩罚项。如果模型正确地预测了法律项,那么在计算Ltc(即与电荷预测任务相关的交叉熵损失)时,我们掩盖了根据预测项不允许的电荷对应的损失中的每一项:
![]()
其中,如果根据预测的条款不允许充电,则掩码等于0,否则为1。但是,如果模型对文章的预测不正确,则Ltc是标准的交叉熵损失。直观地说,通过掩码,模型被迫根据预测的文章预测一个允许的电荷。在测试过程中,由于我们不知道法律文章的预测是否正确,我们总是根据预测的文章来掩盖电荷概率分布。在强制执行法律条款预测与惩罚预测项之间的一致性约束时,我们采用相同的策略来计算Ltp。
7 评价
7.1 实验设置
我们使用预训练和微调策略来训练我们的模型EPM。具体来说,我们在CAIL的训练部分(表2)上对没有事件组件的EPM进行预训练,然后在我们的事件注释的LJP数据集LJP-E的训练部分上对EPM进行微调,以从事件注释中学习。
对于编码器,最大事实长度设置为512。对于训练,我们使用Adam优化器,学习率为10−4,批处理大小为32。预热步骤是3000步。对于超参数,λ,在损失函数中,对于{λta、λtc、λtp、λr、λp}的最佳设置为{0.5、0.5、0.4、0.2、0.1}。模型最多要训练20个时代。4 LJP报告结果包括精度(Acc)、宏精度(MP)、宏召回(MR)和宏F1(F1)。
7.2 与SOTA的比较
因为LJP-E只包含15例类型的CAIL,当应用EPM CAIL测试集我们使用预训练版本的EPM(即没有微调)预测样本不属于15类型和使用的EPM微调版本预测样本属于15类型之一。为了确定一个样本是否属于这15种类型中的一种,我们在CAIL的训练集上使用合法的BERT来训练一个二元分类器。我们将这个模型称为开关模型。
我们将EPM与四种SOTA神经模型进行了比较:
- MLAC(Luo et al.,2017),它们联合建模电荷预测和相关文章提取任务。在这里,我们添加了一个全连接层来预测惩罚项
- TOPJUDGE(Zhong et al.,2018),将LJP联合框架中的子任务形式化为有向无环图,其中子任务共享参数
- MPBFN(Yang et al.,2019),提出了一个多视角的正和向后预测框架,使不同子任务有效共享参数,以及一种惩罚预测项的数字嵌入方法
- LADAN (Xu et al., 2020),它开发了一个图网络来学习法律条文之间的细微差异,以便从事实陈述中提取引人注目的判别特征
- NeurJudge(Yue et al.,2021),利用中间子任务的结果将事实陈述分为不同的情况,并利用它们对其他子任务进行预测。
我们在表3中注释的数据集LJP-E的测试部分对EPM和SOTA模型进行了比较,CAIL数据集的官方测试部分,见表4和表5。
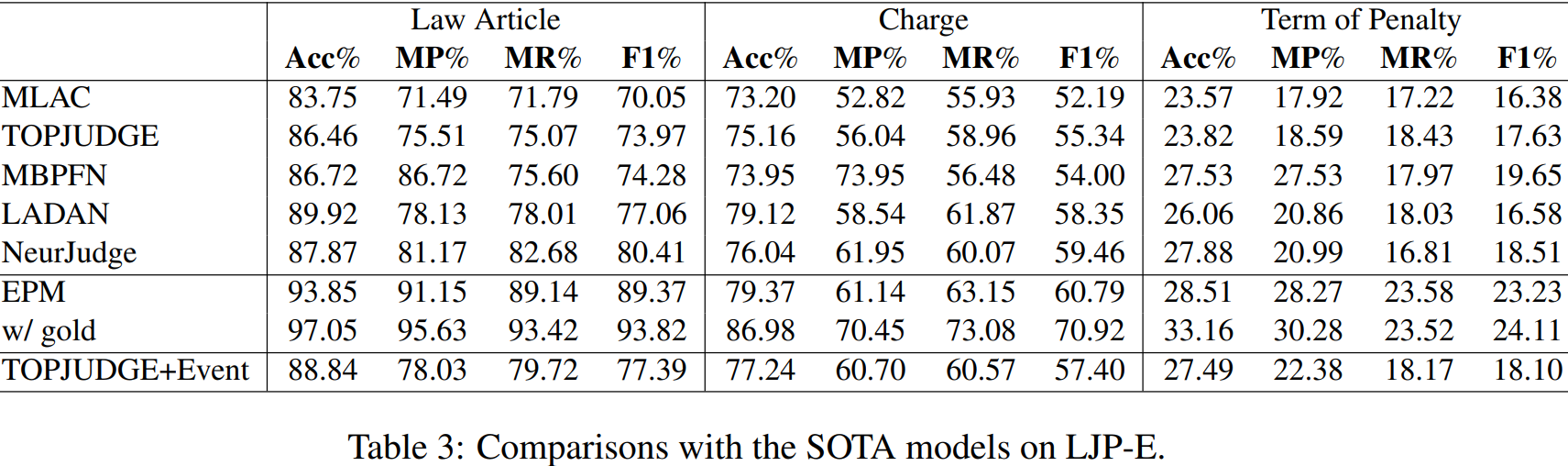
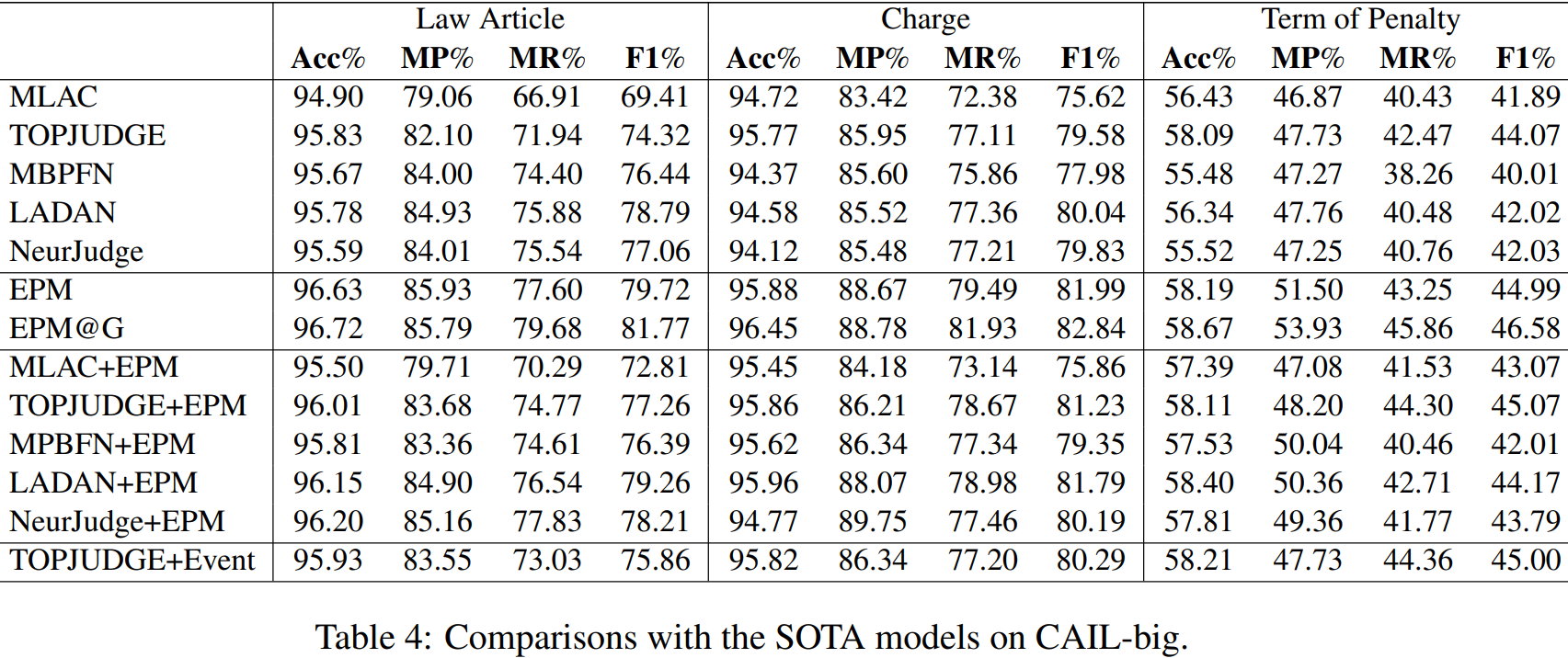
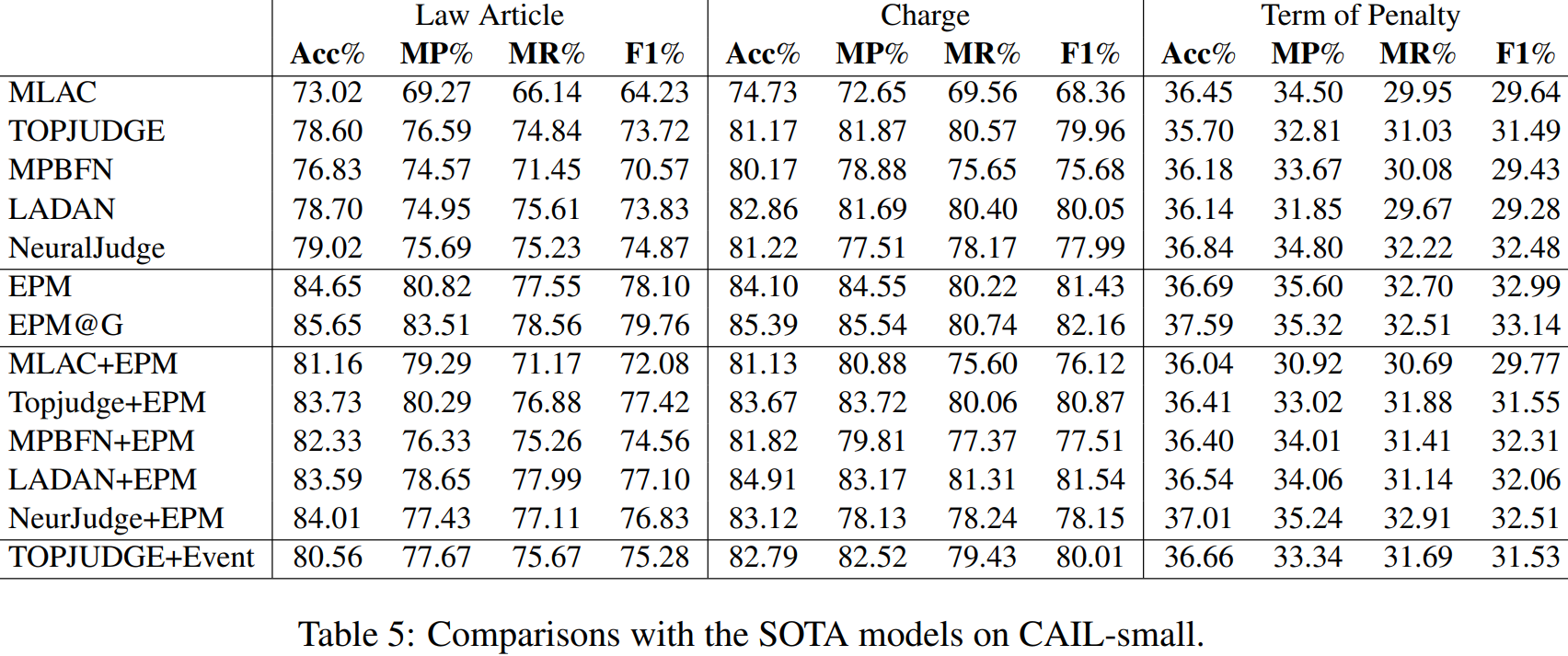
如表3、4和5所示,EPM(第6行)取得了最好的结果,不仅优于MLAC,也优于MLAC、MPBFN、LADAN和NeurJudge,它们进一步利用了数字嵌入和图网络等扩展,特别是在法律文章预测方面。
接下来,我们进行了两个涉及EPM的oracle实验。首先,我们使用gold事件注释而不是预测的事件注释来对这三个子任务进行预测。如表3的第7行所示的结果表明,当使用gold事件注释时,可以获得相当多的更好的结果。这些结果表明,现有的LJP结果可以通过改进事件抽取来显著改善。接下来,我们假设当在CAIL上获得EPM结果时,该开关是完美的。也许并不奇怪,表4和表5的第7行所显示的结果是更好的w.r.t.所有的子任务。
进一步,我们应用EPM MLAC,TOPJUDGE,MPBFN,LADAN和NeurJudge on CAIL,五个SOTA模型遵循相同的方案(即使用微调EPM分类时开关说样本属于15类型和使用SOTA模型分类),显示结果在行8到12表4和5。我们可以看到,EPM也可以提高四种SOTA模型的性能,产生新的SOTA结果。最后,我们研究了修改SOTA模型,拓判断,通过联合执行事件抽取和LJP任务是否可以提高其性能。为此,我们用一个LSTM替换了它的CNN编码器,并以提取的事件提供给LJP分类器,而不是像在EPM中一样的案例事实。我们可以看到,TOPJUDGE-Event优于TOPJUDGE,这显示了事件信息的有用性。然而,TOPJUDGE+EPM优于TOPJUDGE-Event,这表明,通过将TOPJUDGE视为黑盒(通过使用Switch利用事件信息)而不是玻璃盒(通过修改模型以从事件注释中学习),可以获得更好的LJP结果。
7.3 事件和约束条件的有用性
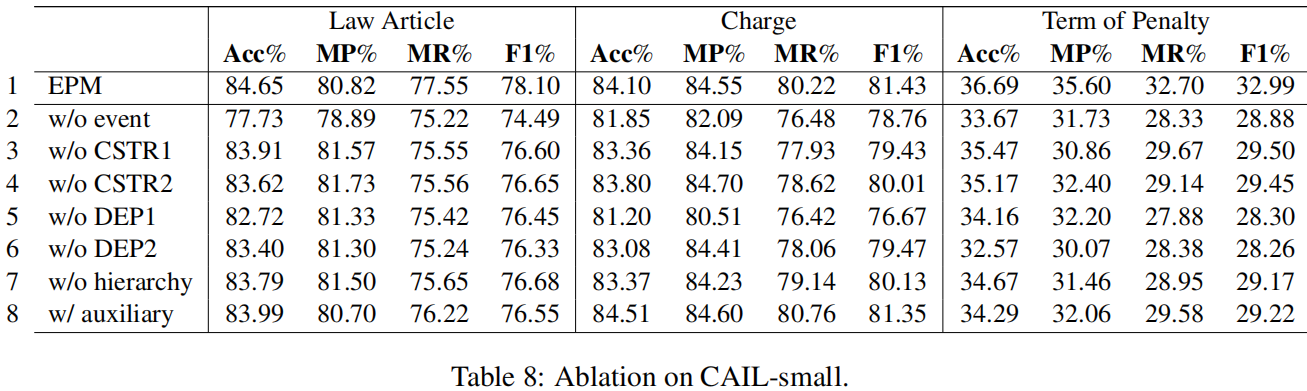
我们对EPM的消融版本进行了实验。LJP-E和CAIL的消融结果见表6和表7、8。
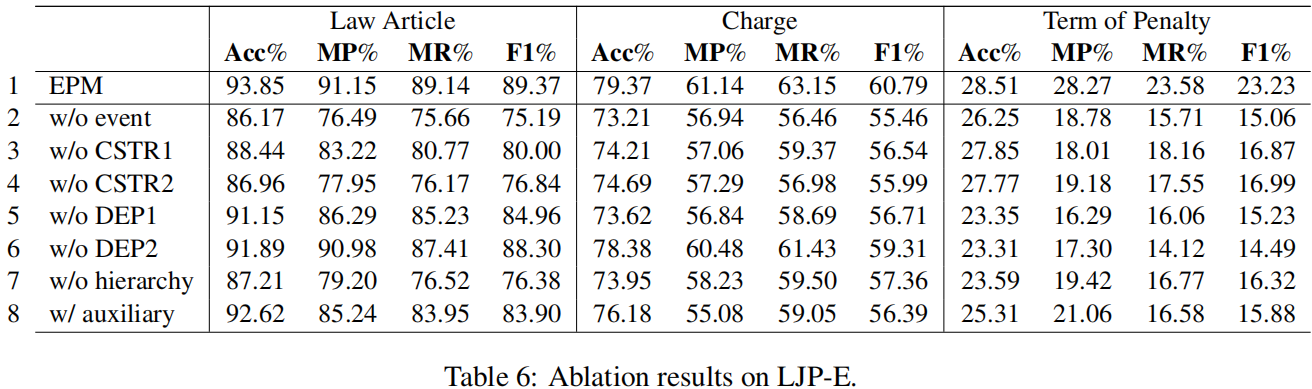
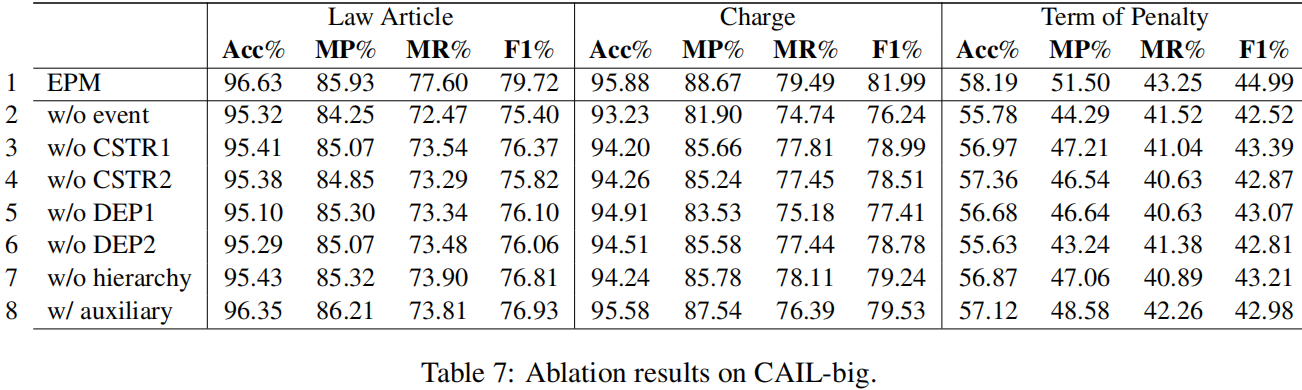
事件抽取
为了测试事件抽取的有效性,我们从EPM中删除了所有的事件组件。结果显示在第2行中。正如我们所看到的,在Acc和F1方面,所有三个子任务的性能都显著下降。
基于事件的约束
接下来,我们评估这两个基于事件的约束(第6.1节)对事件抽取输出的有用性。删除绝对约束(w/o CSTR1,第3行)或基于事件的一致性约束(w/o CSTR2,第4行)通常会在Acc和F1方面产生更差的结果。特别是,删除一致性约束通常比绝对约束提供更大的恶化。
跨任务的一致性约束
我们还评估了跨任务的一致性约束。去除物品电荷约束(DEP1第5行)或物品项约束(DEP2第6行)会对性能产生负面影响,其中对电荷预测的负面影响最大。虽然这些约束条件是为了利用预测的法律文章的结果来改进电荷预测和项预测,但我们看到法律文章的性能也会下降。
上级类型
到目前为止,我们已经假设分层事件抽取将有利于LJP。为了更好地理解这个层次结构是否确实有用,我们评估了一个不使用上级特征的EPM版本。换句话说,该模型直接预测下属类型/角色。结果显示在第7行中。通过比较第1行和第7行,我们可以发现,当不使用上级特征时,它们的Acc和F1在所有子任务中的得分都会下降,这表明了它们的有用性。
事件抽取作为一个辅助任务
在EPM中,我们使用预测的事件特征作为三个LJP任务分类器的输入。另一种利用事件信息的方法是将事件抽取作为模型中的一个辅助任务,通过让它与LJP任务共享编码器。
将事件抽取作为辅助任务处理的结果如第8行所示。正如我们所看到的,这些结果比EPM的结果差(第1行),这意味着EPM利用事件信息的方式更好,但它们比不使用事件信息的方式更好(第2行),这意味着使用预测事件进行LJP仍然比不使用它们要好。
7.4 定性分析
接下来,我们对EPM进行定性分析,以更好地理解事件信息和约束所起的作用。在CAIL中,同一法律文章的惩罚数据分布偏向于较大的惩罚值,因此当不使用跨任务一致性约束时,EPM在惩罚惩罚预测时继承了这种偏差。然而,当使用约束时,EPM被迫只预测预测法律文章允许的术语惩罚,因此对偏态数据分布更稳健。至于事件,事件信息的使用阻止了EPM在一个可能触发对错误的法律文章的预测的案例事实中关注某些单词。
8 结论
我们提出了第一个使用事件抽取和手工约束来改进LJP的模型,实现了SOTA的结果。