【Hadoop-CosDistcp】通过CosDistcp的方式迁移Cos中的数据至HDFS
- 1)功能说明
- 2)使用环境
- 3)下载与安装
- 4)原理说明
- 5)参数说明
- 6)使用示例
- 7)迁移 Cos 中的数据至 HDFS 及数据校验
- 7.1.数据迁移
- 7.2.数据校验
- 7.3.数据补充
- 7.4.总结
1)功能说明
COSDistCp 是一款基于 MapReduce 的分布式文件拷贝工具,主要用于 HDFS 和 COS 之间的数据拷贝,它主要具有以下功能点:
- 根据长度、CRC 校验和,进行文件的增量迁移、数据校验
- 对源目录中的文件进行正则表达式过滤
- 对源目录中的文件进行解压缩 ,并转换为预期的压缩格式
- 基于正则表达式,对文本文件进行聚合
- 保留源文件和源目录的用户、组、扩展属性和时间
- 配置告警和 Prometheus 监控
- 统计文件大小分布
- 对读取带宽进行限速
2)使用环境
(1)系统环境:
支持 Linux 系统。
(2)软件依赖:
Hadoop-2.6.0及以上版本、Hadoop-COS 插件 5.9.3 及以上版本。
3)下载与安装
(1)获取 COSDistCp jar 包
Hadoop 2.x 用户可下载 cos-distcp-1.13-2.8.5.jar 包,根据 jar 包的 MD5 校验值 确认下载的 jar 包是否完整。
Hadoop 3.x 用户可下载 cos-distcp-1.13-3.1.0.jar 包,根据 jar 包的 MD5 校验值 确认下载的 jar 包是否完整。
下载地址:https://cloud.tencent.com/document/product/436/50272

(2)安装说明
在 Hadoop 环境下,安装 Hadoop-COS 后,即可直接运行 COSDistCp 工具。
对于环境中未安装和配置 Hadoop-COS 插件的用户,根据 Hadoop 版本,下载对应版本的 COSDistCp jar、Hadoop-COS jar 和 cos_api-bundle jar 包后(相关 jar 包下载地址见上文),指定 Hadoop-COS 相关参数执行拷贝任务,其中 jar 包地址需填本地 jar 所在地址:
hadoop jar cos-distcp-${version}.jar \
-libjars cos_api-bundle-${version}.jar,hadoop-cos-${version}.jar \
-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \
-Dfs.cosn.userinfo.secretId=COS_SECRETID \
-Dfs.cosn.userinfo.secretKey=COS_SECRETKEY \
-Dfs.cosn.bucket.region=ap-guangzhou \
-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \
-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \
--src /data/warehouse \
--dest cosn://examplebucket-1250000000/warehouse
下载地址:https://cloud.tencent.com/document/product/436/6884

4)原理说明
COSDistCp 基于 MapReduce 框架实现,为多进程+多线程的架构,可以对文件进行拷贝、数据校验、压缩、文件属性保留以及拷贝重试等工作。COSDistCp 默认会覆盖目标端已经存在的同名文件,当文件迁移或校验失败的时候,对应的文件会拷贝失败,并会在临时目录下记录迁移失败的文件信息。当您的源目录有文件新增或文件内容发生变化时,您可通过 skipMode 或 diffMode 模式,通过对比文件的长度或 CRC 校验值,进行数据校验和进行文件的增量迁移。
5)参数说明
您可在hadoop用户下,使用命令 hadoop jar cos-distcp-version.jar --help 查看 COSDistCp 支持的参数选项,其中 version 为版本号,以下为当前版本 COSDistCp 的参数说明:
| 属性键 | 说明 | 默认值 | 是否必填 |
|---|---|---|---|
| –help | 输出 COSDistCp 支持的参数选项 示例:–help | 无 | 否 |
| –src=LOCATION | 指定拷贝的源目录,可以是 HDFS 或者 COS 路径 示例:–src=hdfs://user/logs/ | 无 | 是 |
| –dest=LOCATION | 指定拷贝的目标目录,可以是 HDFS 或者 COS 路径 示例:–dest=cosn://examplebucket-1250000000/user/logs | 无 | 是 |
| –srcPattern=PATTERN | 指定正则表达式对源目录中的文件进行过滤 示例:--srcPattern='.*\.log$' 注意:您需要将参数使用单引号包围,以避免符号\*被 shell 解释 | 无 | 否 |
| –taskNumber=VALUE | 指定拷贝进程数,示例:–taskNumber=10 | 10 | 否 |
| –workerNumber=VALUE | 指定拷贝线程数,COSDistCp 在每个拷贝进程中创建该参数大小的拷贝线程池 示例:–workerNumber=4 | 4 | 否 |
| –filesPerMapper=VALUE | 指定每个 Mapper 输入文件的行数 示例:–filesPerMapper=10000 | 500000 | 否 |
| –groupBy=PATTERN | 指定正则表达式对文本文件进行聚合 示例:–groupBy=‘.group-input/(\d+)-(\d+).’ | 无 | 否 |
| –targetSize=VALUE | 指定目标文件的大小,单位:MB,与 --groupBy 一起使用 示例:–targetSize=10 | 无 | 否 |
| –outputCodec=VALUE | 指定输出文件的压缩方式,可选 gzip、lzo、snappy、none 和 keep,其中: 1. keep 保持原有文件的压缩方式 2. none 则根据文件后缀对文件进行解压, 示例:–outputCodec=gzip 注意:如果存在文件 /dir/test.gzip 和 /dir/test.gz,指定输出格式为 lzo,最终只会保留一个文件 /dir/test.lzo | keep | 否 |
| –deleteOnSuccess | 指定源文件拷贝到目标目录成功时,立即删除源文件 示例:–deleteOnSuccess, 注意:1.7 及以上版本不再提供该参数,建议数据迁移成功并使用 --diffMode 校验后,再删除源文件系统的数据 | false | 否 |
| –multipartUploadChunkSize=VALUE | 指定 Hadoop-COS 插件传输文件到 COS 时分块的大小,COS 支持的最大分块数为 10000,您可根据文件大小,调整分块大小,单位:MB,默认为8MB 示例:–multipartUploadChunkSize=20 | 8MB | 否 |
| –cosServerSideEncryption | 指定文件上传到 COS 时,使用 SSE-COS 作为加解密算法 示例:–cosServerSideEncryption | false | 否 |
| –outputManifest=VALUE | 指定拷贝完成的时候,在目标目录下生成本次拷贝的目标文件信息列表(GZIP 压缩) 示例:–outputManifest=manifest.gz | 无 | 否 |
| –requirePreviousManifest | 要求指定 --previousManifest=VALUE 参数,以进行增量拷贝 示例:–requirePreviousManifest | false | 否 |
| –previousManifest=LOCATION | 前一次拷贝生成的目标文件信息 示例:–previousManifest=cosn://examplebucket-1250000000/big-data/manifest.gz | 无 | 否 |
| –copyFromManifest | 和 --previousManifest=LOCATION 一起使用,可将 --previousManifest 中的文件,拷贝到目标文件系统 示例:–copyFromManifest | false | 否 |
| –storageClass=VALUE | 指定对象存储类型,可选值为 STANDARD、STANDARD_IA、ARCHIVE、DEEP_ARCHIVE、INTELLIGENT_TIERING,关于更多支持的存储类型和介绍,请参见 存储类型概述 | 无 | 否 |
| –srcPrefixesFile=LOCATION | 指定本地文件,该文件中每行包含一个需要拷贝的源目录 示例:–srcPrefixesFile=file:///data/migrate-folders.txt | 无 | 否 |
| –skipMode=MODE | 拷贝文件前,校验源文件和目标文件是否相同,相同则跳过,可选 none(不校验)、length (长度)、checksum(CRC值)、length-mtime(长度+mtime值)和 length-checksum(长度 + CRC 值) 示例:–skipMode=length | length-checksum | 否 |
| –checkMode=MODE | 当文件拷贝完成的时候,校验源文件和目标文件是否相同,可选 none(不校验)、 length (长度)、checksum(CRC值)、length-mtime(长度+mtime值)和 length-checksum(长度 + CRC 值) 示例:–checkMode=length-checksum | length-checksum | 否 |
| –diffMode=MODE | 指定获取源和目的目录的差异文件列表,可选 length (长度)、checksum(CRC 值)、length-mtime(长度+mtime值)和 length-checksum(长度 + CRC 值) 示例:–diffMode=length-checksum | 无 | 否 |
| –diffOutput=LOCATION | 指定 diffMode 的 HDFS 输出目录,该输出目录必须为空 示例:–diffOutput=/diff-output | 无 | 否 |
| –cosChecksumType=TYPE | 指定 Hadoop-COS 插件使用的 CRC 算法,可选值为 CRC32C 和 CRC64 示例:–cosChecksumType=CRC32C | CRC32C | 否 |
| –preserveStatus=VALUE | 指定是否将源文件的 user、group、permission、xattr 和 timestamps 元信息拷贝到目标文件,可选值为 ugpxt(即为 user、group、permission、xattr 和 timestamps 的英文首字母) 示例:–preserveStatus=ugpt | 无 | 否 |
| –ignoreSrcMiss | 忽略存在于文件清单中,但拷贝时不存在的文件 | false | 否 |
| –promGatewayAddress=VALUE | 指定 MapReduce 任务运行的 Counter 数据推送到的 Prometheus PushGateway 的地址和端口 | 无 | 否 |
| –promGatewayDeleteOnFinish=VALUE | 指定任务完成时,删除 Prometheus PushGateway 中 JobName 的指标集合 示例:–promGatewayDeleteOnFinish=true | true | 否 |
| –promGatewayJobName=VALUE | 指定上报给 Prometheus PushGateway 的 JobName 示例:–promGatewayJobName=cos-distcp-hive-backup | 无 | 否 |
| –promCollectInterval=VALUE | 指定收集 MapReduce 任务 Counter 信息的间隔,单位:ms 示例:–promCollectInterval=5000 | 5000 | 否 |
| –promPort=VALUE | 指定将 Prometheus 指标暴露给外部的 Server 端口 示例:–promPort=9028 | 无 | 否 |
| –enableDynamicStrategy | 指定开启任务动态分配策略,使迁移速度快的任务迁移更多的文件。 注意:该模式存在一定局限性,例如任务计数器在进程异常的情况下计数不准确,请迁移完成后用 --diffMode 进行数据校验 示例:–enableDynamicStrategy | false | 否 |
| –splitRatio=VALUE | 指定 Dynamic Strategy 的切分比例,splitRatio 值越大,则任务粒度越小 示例:–splitRatio=8 | 8 | 否 |
| –localTemp=VALUE | 指定 Dynamic Strategy 生成的任务信息文件所在的本地文件夹 示例:–localTemp=/tmp | /tmp | 否 |
| –taskFilesCopyThreadNum=VALUE | 指定 Dynamic Strategy 任务信息文件拷贝到 HDFS 上的并发度 示例:–taskFilesCopyThreadNum=32 | 32 | 否 |
| –statsRange=VALUE | 指定统计的区间范围 示例:—statsRange=0,1mb,10mb,100mb,1gb,10gb,inf | 0,1mb,10mb,100mb,1gb,10gb,inf | 否 |
| –printStatsOnly | 只统计待迁移文件大小的分布信息,不迁移数据 示例:–printStatsOnly | 无 | 否 |
| –bandWidth | 限制读取每个迁移文件的带宽,单位为:MB/s,默认-1,不限制读取带宽。 示例:–bandWidth=10 | 无 | 否 |
| –jobName | 指定迁移任务的名称。 示例:–jobName=cosdistcp-to-warehouse | 无 | 否 |
| –compareWithCompatibleSuffix | 使用 --skipMode 和 --diffMode 参数时,是否将源文件的后缀 gzip 转换为 gz,lzop 文件后缀转换为 lzo,进行判断。 示例:–compareWithCompatibleSuffix | 无 | 否 |
| –delete | 保证源目录和目标目录文件的一致性,将源目录中没有而目标目录中有的文件,移动到独立的 trash 目录下,同时生成文件清单。 注意:不能同时使用 --diffMode 参数 | 无 | 否 |
| –deleteOutput | 指定 delete 的 HDFS 输出目录,该目录必须为空 示例: --deleteOutput=/dele-output | 无 | 否 |
6)使用示例
使用实例较多,这里就不一一说明了,详情可以参考官方文档:https://cloud.tencent.com/document/product/436/50272

7)迁移 Cos 中的数据至 HDFS 及数据校验
在企业中进行大规模数据量的迁移,会涉及到很多原因,比如资源队列,网络带宽,任务名称,数据校验,补充差异数据等操作。
-
网络带宽决定数据的传输速度,如果任务较多的情况下不能让一个任务占用过多带宽,需要合理分配网络资源
-
数据校验决定数据的准确性,所以对差异数据进行补充也至关重要
下面我将以企业中PB级别的数据迁移为例,进行相关举例演示。
7.1.数据迁移
参数说明:
-
-Dmapred.job.queue.name:队列名称 -
-bandWidth:带宽(每秒的传输速度,单位为M),默认为-1(不限制) -
jobName:在 yarn 上显示的任务名称
yarn jar /opt/corns/cos-distcp-1.12-3.1.0.jar -libjars /opt/corns/cos_api-bundle-5.6.69.jar,/opt/corns/hadoop-cos-3.1.0-8.1.7.jar \
-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \
-Dfs.cosn.userinfo.secretId=********************************* \
-Dfs.cosn.userinfo.secretKey=********************************* \
-Dfs.cosn.bucket.region=ap-guangzhou \
-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \
-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \
-Dmapred.job.queue.name=*** \
--bandWidth=-1 \
--jobName=cosdistcp-to-hdfs \
--src cosn://test-bucekt01/test/ \
--dest hdfs://nameserver/tmp/test/
7.2.数据校验
参数说明:
-
-Dmapred.job.queue.name:队列名称 -
-bandWidth:带宽(每秒的传输速度,单位为 M),默认为-1(不限制) -
jobName:在 yarn 上显示的任务名称 -
-diffMode:数据校验模式(详情参考上面表格) -
-diffOutput:数据校验结果输出到 HDFS 上的目录(输出目录必须为空)
判断数据校验结果:
1、如果目录中没有 failed 目录,则数据校验结果为完全一致。
2、如果目录中存在 failed 目录,则进入目录中查看异常数据清单,内容信息如下:
① 源和目的文件相同,记录为 SUCCESS
② 目标文件不存在,记录为 DEST_MISS
③ 存在源目录的清单中,但是校验时源文件不存在,记录为 SRC_MISS
④ 源文件和目标文件大小不同,记录为:LENGTH_DIFF
⑤ 源文件和目标文件 CRC 算法值不同,记录为:CHECKSUM_DIFF
⑥ 由于读取权限不够等因素导致 diff 操作失败,记录为:DIFF_FAILED
⑦ 源为目录,目的为文件,记录为:TYPE_DIFF
查看是否有 failed 目录:

进入目录查看存在异常数据清单文件:

查看异常数据清单文件内容:

yarn jar /opt/corns/cos-distcp-1.12-3.1.0.jar -libjars /opt/corns/cos_api-bundle-5.6.69.jar,/opt/corns/hadoop-cos-3.1.0-8.1.7.jar \
-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \
-Dfs.cosn.userinfo.secretId=********************************* \
-Dfs.cosn.userinfo.secretKey=********************************* \
-Dfs.cosn.bucket.region=ap-guangzhou \
-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \
-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \
-Dmapred.job.queue.name=*** \
--bandWidth=-1 \
--jobName=cosdistcp-to-hdfs-check \
--diffMode=length-checksum \
--diffOutput=/tmp/diff_output \
--src cosn://test-bucekt01/test/ \
--dest hdfs://nameserver/tmp/test/
7.3.数据补充
补充数据需要将上面校验结果中的差异数据清单拉取到 Linux 本地(如果有多个文件,可以先进行合并操作),并压缩成 gzip,然后补充命令指定此gzip文件即可完成数据补充。
合并文件到本地
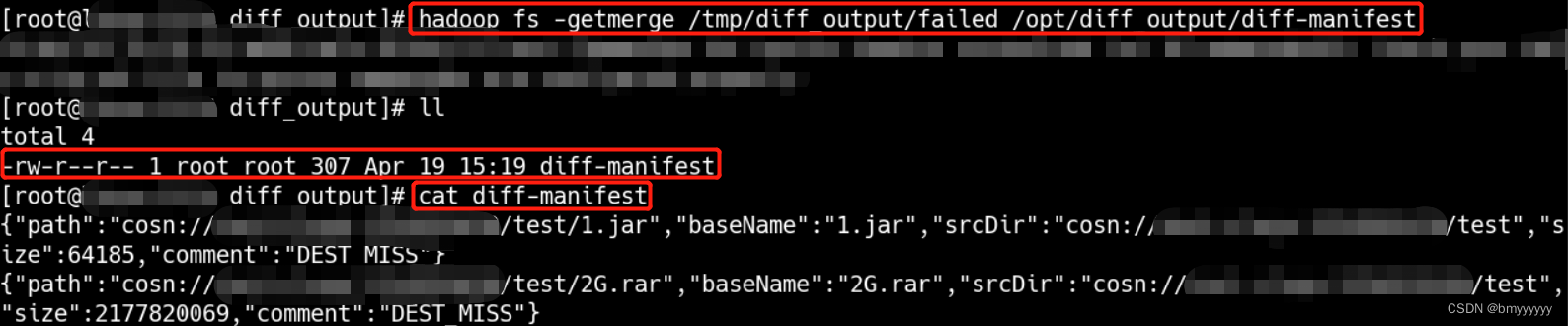
压缩文件

# 合并文件到 Linux 的/opt/diff_output/中,形成合并后的 diff-manifest文件
hadoop fs -getmerge /tmp/diff_output/failed /opt/diff_output/diff-manifest
# 过滤掉 SRC_MISS 清单信息后压缩成 gzip 文件
grep -v '"comment":"SRC_MISS"' /opt/diff_output/diff-manifest |gzip > /opt/diff_output/diff-manifest.gz
参数说明:
-
-Dmapred.job.queue.name:队列名称 -
-bandWidth:带宽(每秒的传输速度,单位为 M),默认为-1(不限制) -
jobName:在 yarn 上显示的任务名称 -
-previousManifest:指定需要补充数据的清单(详情参考上面表格) -
-copyFromManifest:按照清单补充数据(详情参考上面表格)
yarn jar /opt/corns/cos-distcp-1.12-3.1.0.jar -libjars /opt/corns/cos_api-bundle-5.6.69.jar,/opt/corns/hadoop-cos-3.1.0-8.1.7.jar \
-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \
-Dfs.cosn.userinfo.secretId=********************************* \
-Dfs.cosn.userinfo.secretKey=********************************* \
-Dfs.cosn.bucket.region=ap-guangzhou \
-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \
-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \
-Dmapred.job.queue.name=*** \
--bandWidth=-1 \
--jobName=cosdistcp-to-hdfs-bc \
--src cosn://test-bucekt01/test/ \
--dest hdfs://nameserver/tmp/test/ \
--previousManifest=file:///opt/diff_output/diff-manifest.gz \
--copyFromManifest
7.4.总结
1、如果已经迁移过的文件,重新启动程序后不会重复迁移,会继续迁移数据。
2、迁移完成后执行数据校验脚本,会在 HDFS 指定目录下产生校验清单,如果没有 failed 目录,则没有问题,如果有failed目录,此目录下会生成一个或多个文件,里面记录着校验结果。
3、将校验的结果文件进行 merge 操作后,会在 Linux 本地生成一个合并后的文件,将合并后的文件过滤 SRC_MISS 后压缩成 .gz 文件。
4、执行补充数据的 Shell 命令,指定此压缩文件(指向的压缩文件必须在 Linux 本地,且类型必须为 gzip),即可将未迁移的数据进行补充迁移。