1 IO模型
1.1 IO

IO (Input/Output,输入/输出)即数据的读取(接收)或写入(发送)操作,通常用户进程中的一个完整IO分为两阶段:用户进程空间<–>内核空间、内核空间<–>设备空间(磁盘、网络等)。IO有内存IO、网络IO和磁盘IO三种,通常我们说的IO指的是后两者。
LINUX中进程无法直接操作I/O设备,其必须通过系统调用请求kernel来协助完成I/O动作;内核会为每个I/O设备维护一个缓冲区。
对于一个输入操作来说,进程IO系统调用后,内核会先看缓冲区中有没有相应的缓存数据,没有的话再到设备中读取,因为设备IO一般速度较慢,需要等待;内核缓冲区有数据则直接复制到进程空间。
所以,对于一个网络输入操作通常包括两个不同阶段:
- 等待网络数据到达网卡 -> 读取到内核缓冲区,数据准备好;
- 从内核缓冲区复制数据到进程空间。
1.2 五种IO模型
《UNIX网络编程》说得很清楚,5种IO模型分别是阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型、异步IO模型;前4种为同步IO操作,只有异步IO模型是异步IO操作。
1.2.1 阻塞IO模型-同步阻塞
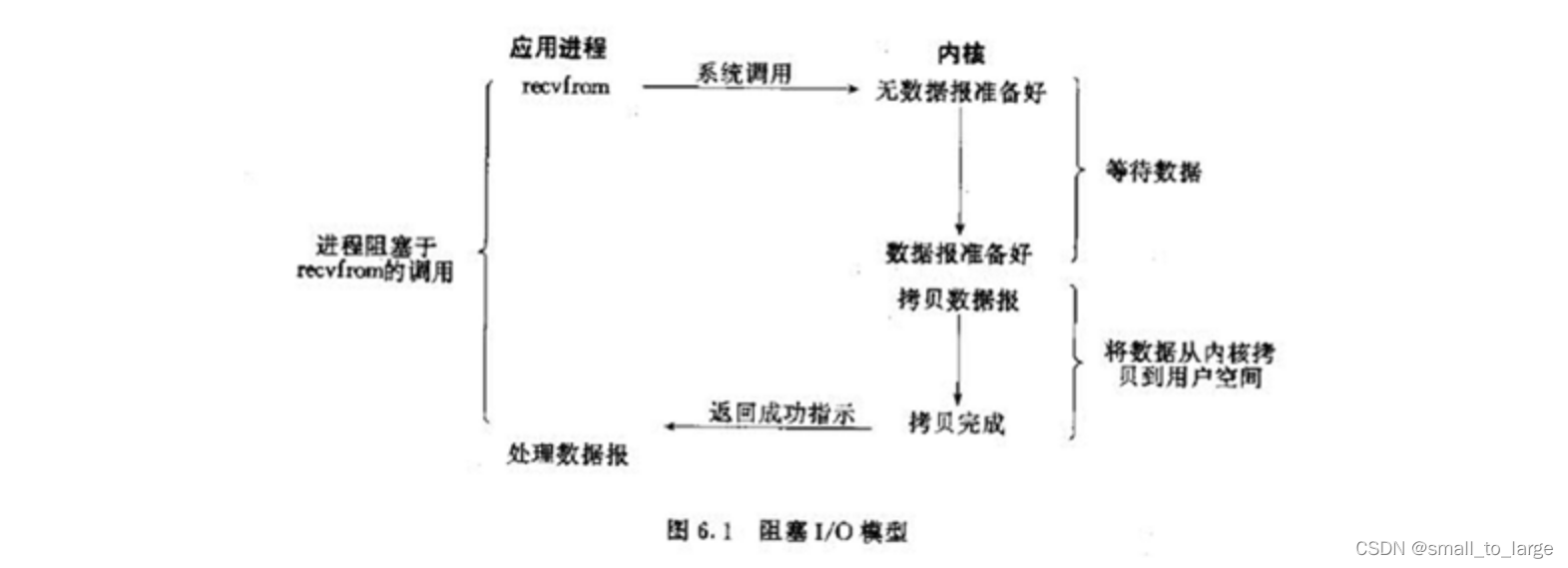
进程发起IO系统调用后,进程被阻塞,转到内核空间处理,整个IO处理完毕后返回进程。操作成功则进程获取到数据。
典型应用:阻塞socket、Java BIO;
特点:
- 进程阻塞挂起不消耗CPU资源,及时响应每个操作;
- 实现难度低、开发应用较容易;
- 适用并发量小的网络应用开发;
不适用并发量大的应用:因为一个请求IO会阻塞进程,所以,得为每请求分配一个处理进程(线程)以及时响应,系统开销大。
1.2.2 非阻塞IO模型-同步非阻塞
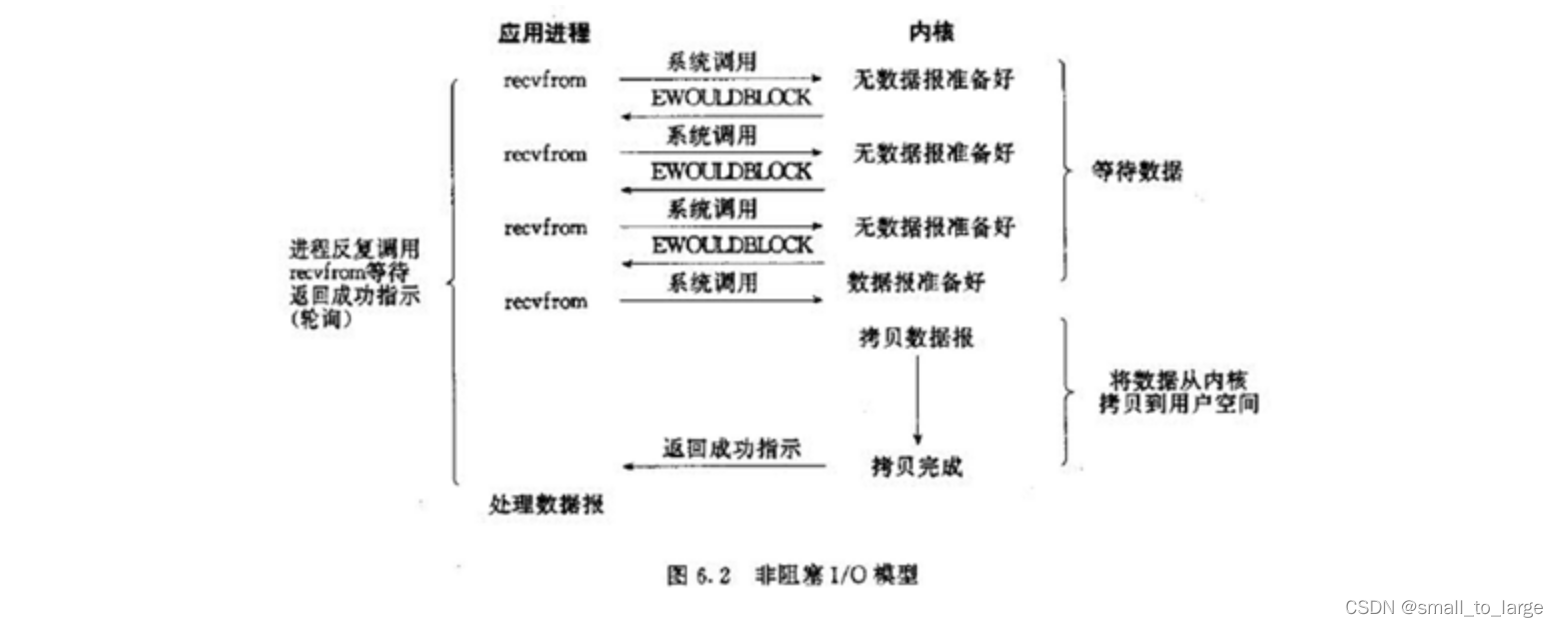
进程发起IO系统调用后,如果内核缓冲区没有数据,需要到IO设备中读取,进程返回一个错误而不会被阻塞;进程发起IO系统调用后,如果内核缓冲区有数据,内核就会把数据返回进程。
非阻塞IO是在应用调用
recvfrom读取数据时,如果该缓冲区没有数据的话,就会直接返回一个EWOULDBLOCK错误,不会让应用一直等待中。在没有数据的时候会即刻返回错误标识,那也意味着如果应用要读取数据就需要不断的调用recvfrom请求,直到读取到它数据要的数据为止。
**典型应用:**socket是非阻塞的方式(设置为NONBLOCK)
特点:
- 进程轮询(重复)调用,消耗CPU的资源;
- 实现难度低、开发应用相对阻塞IO模式较难;
- 适用并发量较小、且不需要及时响应的网络应用开发;
非阻塞IO在大量并发下问题
思考一个问题:
应用B从TCP缓冲区中读取数据,在并发的环境下,可能会N个人向应用B发送消息,这种情况下我们的应用就必须创建多个线程去读取数据,每个线程都会自己调用recvfrom去读取数据。那么此时情况可能如下图:
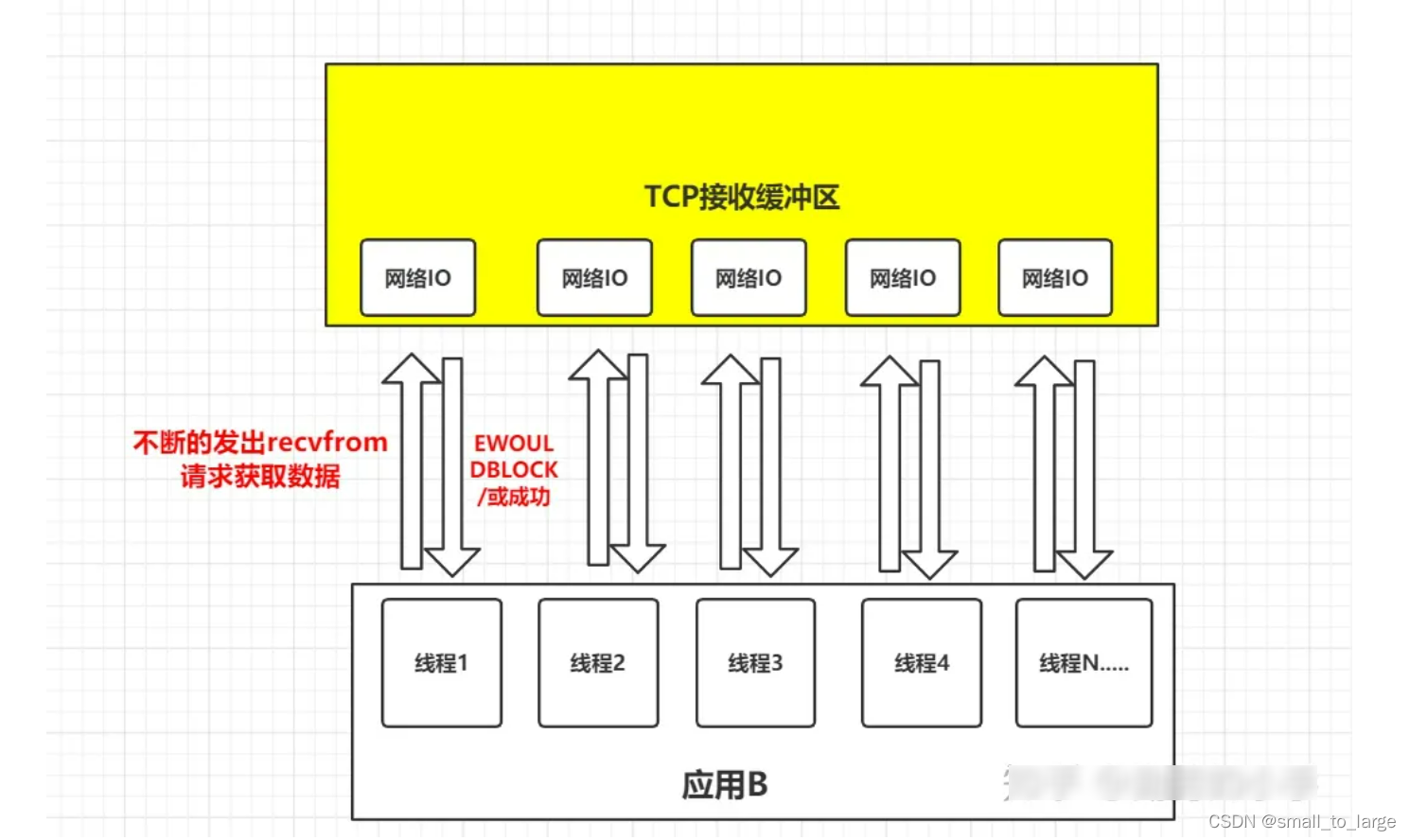
如上图一样,并发情况下服务器很可能一瞬间会收到大量的请求,这种情况下应用B就需要创建大量的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送recvfrom请求来读取数据;
那么问题来了,这么多的线程不断调用recvfrom请求数据,先不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了,线程是我们操作系统的宝贵资源,大量的线程用来去读取数据了,那么就意味着能做其它事情的线程就会少。
所以,有人就提出了一个思路,能不能提供一种方式,可以由一个线程监控多个网络请求(我们后面将称为fd文件描述符,linux系统把所有网络请求以一个fd来标识),这样就可以只需要一个或几个线程就可以完成数据状态询问的操作,当有数据准备就绪之后再分配对应的线程去读取数据,这么做就可以节省出大量的线程资源出来,这个就是IO复用模型的思路。
1.2.3 多路IO复用模型-同步阻塞
IO复用模型的思路就是系统提供了一种函数可以同时监控多个fd的操作,这个函数就是我们常说到的select、poll、epoll函数,有了这个函数后,应用线程通过调用select函数就可以同时监控多个fd,select函数监控的fd中只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时询问线程再去通知处理数据的线程,对应线程此时再发起recvfrom请求去读取数据。
什么是多路复用:
- 多路: 指的是多个socket网络连接;
- 复用: 指的是复用一个线程;
- 多路复用主要有三种技术:select,poll,epoll。epoll是最新的, 也是目前最好的多路复用技术;
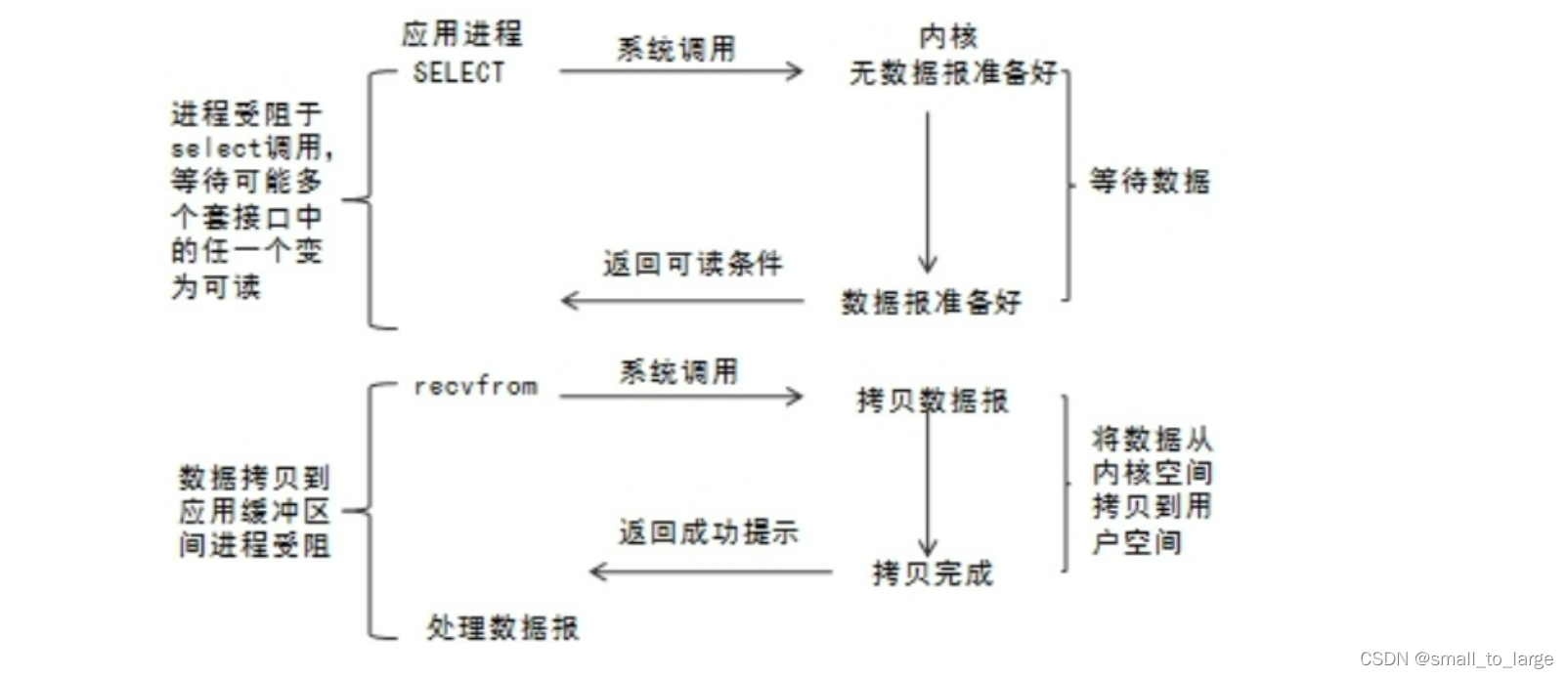
进程通过将一个或多个fd传递给select,阻塞在select操作上,select帮我们侦测多个fd是否准备就绪,当有fd准备就绪时,select返回数据可读状态,应用程序再调用recvfrom读取数据。
复用IO的基本思路就是通过slect或poll、epoll 来监控多fd ,来达到不必为每个fd创建一个对应的监控线程,从而减少线程资源创建的目的。
Java的NIO为例
NIO 属于同步非阻塞,收到的请求会先注册到多路复用器 Selector 上,多路复用器轮询直到连接有 I/O 请求时才启动一个线程进行处理。也就是前文中的多路复用 I/O 模型,虽然说多路复用模型是阻塞的,但在 NIO 这里,因为有Selector,read 和 write 操作都是非阻塞的,其中 Selector 其实就是 select/poll/epoll 的外包类。
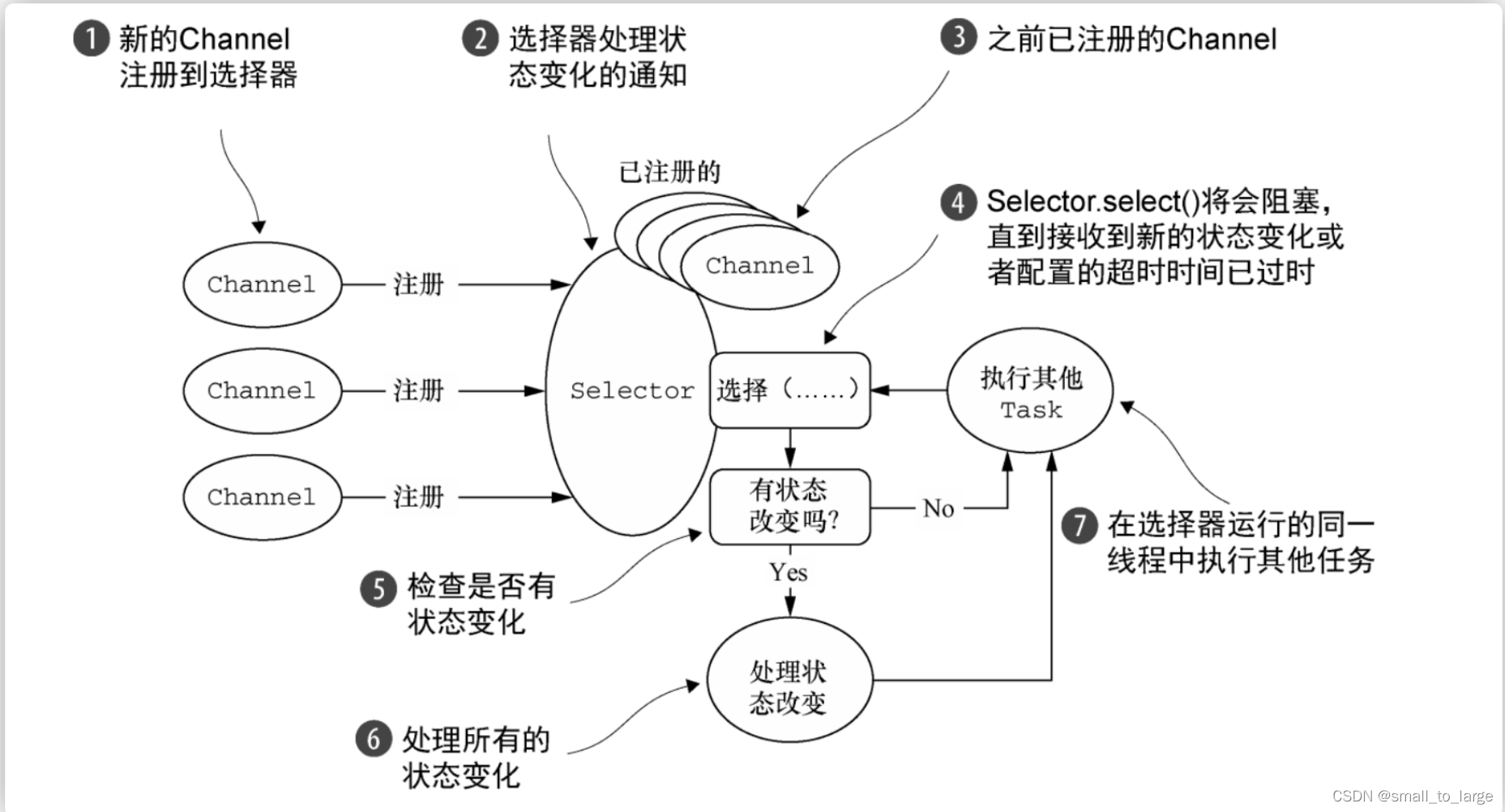
多路IO复用模型总结
多路IO复用也称事件驱动IO,在单个线程里同时监控多个套接字,通过 select 或 poll 轮询查看所负责的所有 socket,当某个 socket 有数据到达了,就通知用户进程。
多个进程的 IO 可以注册到同一个select上,当用户进程调用该select,select会监听所有注册好的 IO,如果所有被监听的 IO 需要的数据都没有准备好时,调用进程会阻塞,等待有套接字变为可读。当任意一个 IO 需要的数据准备好后,即当有套接字可读以后,select调用就会返回,然后进程再通过recvfrom来把对应的数据拷贝到用户进程缓冲区。
IO 复用模型,并没向内核注册信号处理函数,所以是阻塞的。进程在发出select后,要等到select监听的所有 IO 操作中的至少一个需要的数据准备好,才会返回,也需要再次发送请求去进行文件拷贝。整个用户进程其实是一直被阻塞的,但 IO 复用的优势在于可以等待多个描述符就绪。
IO 复用的特点是进行了两次系统调用,进程先是阻塞在 select 上,再阻塞在读操作的第二个阶段上。这是同步阻塞的。
多路复用机制重点: select/poll/epoll Linux系统函数,可以深入了解学习,这里只是简单介绍:
Linux中IO复用的实现方式主要有select、poll和epoll:
Select:注册IO、阻塞扫描,监听的IO最大连接数不能多于FD_SIZE(32位机默认1024个,64位默认2048);Poll:原理和Select相似,没有数量限制,但IO数量大扫描线性性能下降;Epoll:事件驱动不阻塞,mmap实现内核与用户空间的消息传递,数量很大,Linux2.6后内核支持;
1.2.4 信号驱动IO模型-同步非阻塞
信号驱动模型是同步非阻塞的,首先要开启 socket 的信号驱动式 IO 功能,应用进程通过 sigaction 系统调用注册 SIGIO 信号处理函数,该系统调用会立即返回。当数据准备好时,内核会为该进程产生一个 SIGIO 信号通知,之后再把数据拷贝到用户空间中。
虽然等待数据期间用户态进程不被阻塞,但当收到信号通知时(SIGIO)是阻塞并拷贝数据,所以还是同步的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KGwviNkb-1682146940749)(assets/image-20221212090234287.png)]](https://img-blog.csdnimg.cn/c517fe30dbc94620b0d65f41de06fb9c.png)
1.2.5 异步IO-异步非阻塞
用户进程在发起调用后,内核会立即返回。接着用户进程就干别的事去了。然后内核等待数据准备完毕,自动将数据拷贝到用户内存,接着给用户进程发了个信号,通知 IO 操作已完成,这才是五个 I/O 模型中唯一一个异步模型。
异步 IO 特点是 IO 执行的两个阶段(等待数据、拷贝数据)都由内核去完成,用户进程无需干预,也不会被阻塞。这就是异步非阻塞了。也就是 Java 中的 AIO。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I5TBVJdJ-1682146940750)(assets/image-20221212091723906.png)]](https://img-blog.csdnimg.cn/c84dc1fc40a44959891b0b3dc40b1370.png)
1.3 IO模型对比总结
阻塞/非阻塞:关心的是当前线程是否被挂起
异步/同步:关心的是调用结果是否随着请求结束而返回
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TGRY8FRH-1682146940751)(assets/image-20221212092854353.png)]](https://img-blog.csdnimg.cn/25a215308edb462b87c15cd6b33c3254.png)
对比可以看出异步IO的吞吐量是最大的,也是“最牛的”,单看性能而言,的确是AIO要比NIO更胜一筹,那为什么不适用AIO(异步IO),而大量使用多路IO复用模型?
-
在Linux系统上,AIO的底层实现仍使用EPOLL,与NIO相同,因此在性能上没有明显的优势;Windows的AIO底层实现良好,但是Redis、Netty等开发人员并没有把Windows作为主要使用平台考虑
-
AIO还有个缺点是接收数据需要预先分配缓存, 而不是NIO那种需要接收时才需要分配缓存, 所以对连接数量非常大但流量小的情况, 内存浪费很多。
-
Linux上AIO不够成熟,处理回调结果速度跟不上处理需求,比如外卖员太少,顾客太多,供不应求,造成处理速度有瓶颈(待验证)。比如:要吃饭的人是百万,千万级的,送餐员也就几百人。所以一般要吃到饭,是自己去取快呢,还是等着送的更快?
2 Reactor模式
前面我们介绍的IO多路复用是操作系统的底层实现,借助IO多路复用我们实现了一个线程就可以处理大量网络IO请求,那么接收到这些请求后该如何高效的响应,这就是reactor要关注的事情,reactor模式是基于事件的一种设计模式。
Reactor线程模型的思想就是基于IO复用和线程池的结合,在reactor中分为3中角色:
Reactor:负责监听和分发事件
Acceptor:负责处理连接事件
Handler:负责处理请求,读取数据,写回数据
从线程角度出发,reactor又可以分为单reactor单线程,单reactor多线程,多reactor多线程3种。
网络IO模型介绍:https://www.processon.com/view/link/61de8d4df346fb06cb936173
2.1 单reactor单线程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0bqg0Qyr-1682146940752)(assets/image-20221212110431120.png)]](https://img-blog.csdnimg.cn/c4572558336747a0a2c53811daa80f15.png)
处理过程:
1、reactor负责监听连接事件,当有连接到来时,通过acceptor处理连接,得到建立好的socket对象。
2、reactor监听scoket对象的读写事件,当有读写事件触发时,交由handler处理,handler负责读取请求内容,处理请求内容,响应数据。
特点:
模式比较简单,读取请求数据,处理请求内容,响应数据都是在一个线程内完成的,如果整个过程响应都比较快,可以获得比较好的结果。
缺点是请求都在一个线程内完成,无法发挥多核cpu的优势,如果处理请求内容这一块比较慢,就会影响整体性能。
2.2 单reactor多线程(Worker)
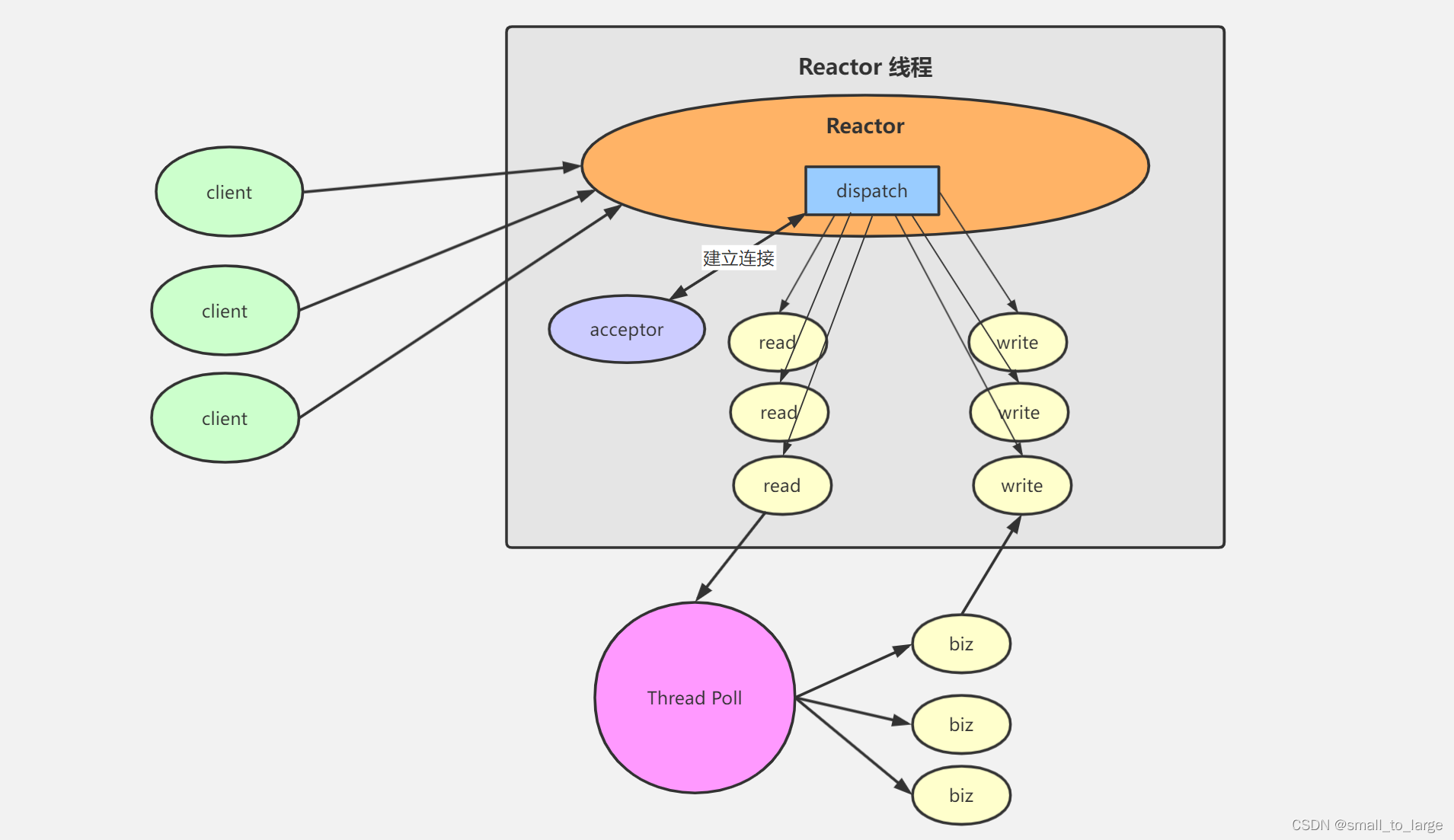
在单reactor单线程的基础上,既然处理请求可能由性能问题,那么这里可以开启一个线程池来处理,请求连接、读写还是由主线程(reactor线程)负责,处理请求内容交由线程池处理,相比之下,多线程模式可以利用cpu多核的优势。
处理过程:
1、reactor线程负责监听连接事件,当有连接到来时,通过acceptor处理连接,得到建立好的socket对象。
2、reactor监听scoket对象的读写事件,当有读写事件触发时,处理请求的数据的读写。
3、将业务处理交给worker线程池处理。
特点:
充分利用多核机器的资源、提高性能并且增加可靠性
缺点Reactor线程承担所有的事件,例如监听和响应,高并发场景下单线程存在性能问题
2.3 多reactor多线程
多reactor多线程又叫主从reactor+worker模型,这种模型下和第二种模型相比是把Reactor线程拆分了mainReactor和subReactor两个部分,mainReactor只处理连接事件,读写事件交给subReactor来处理,业务逻辑还是由线程池来处理。
由于mainRactor只处理连接事件,用一个线程来处理就好,subReactor处理读写事件,个数一般和CPU数量相等,一个subReactor对应一个线程。业务逻辑由线程池处理,具体线程池大小根据业务调节。
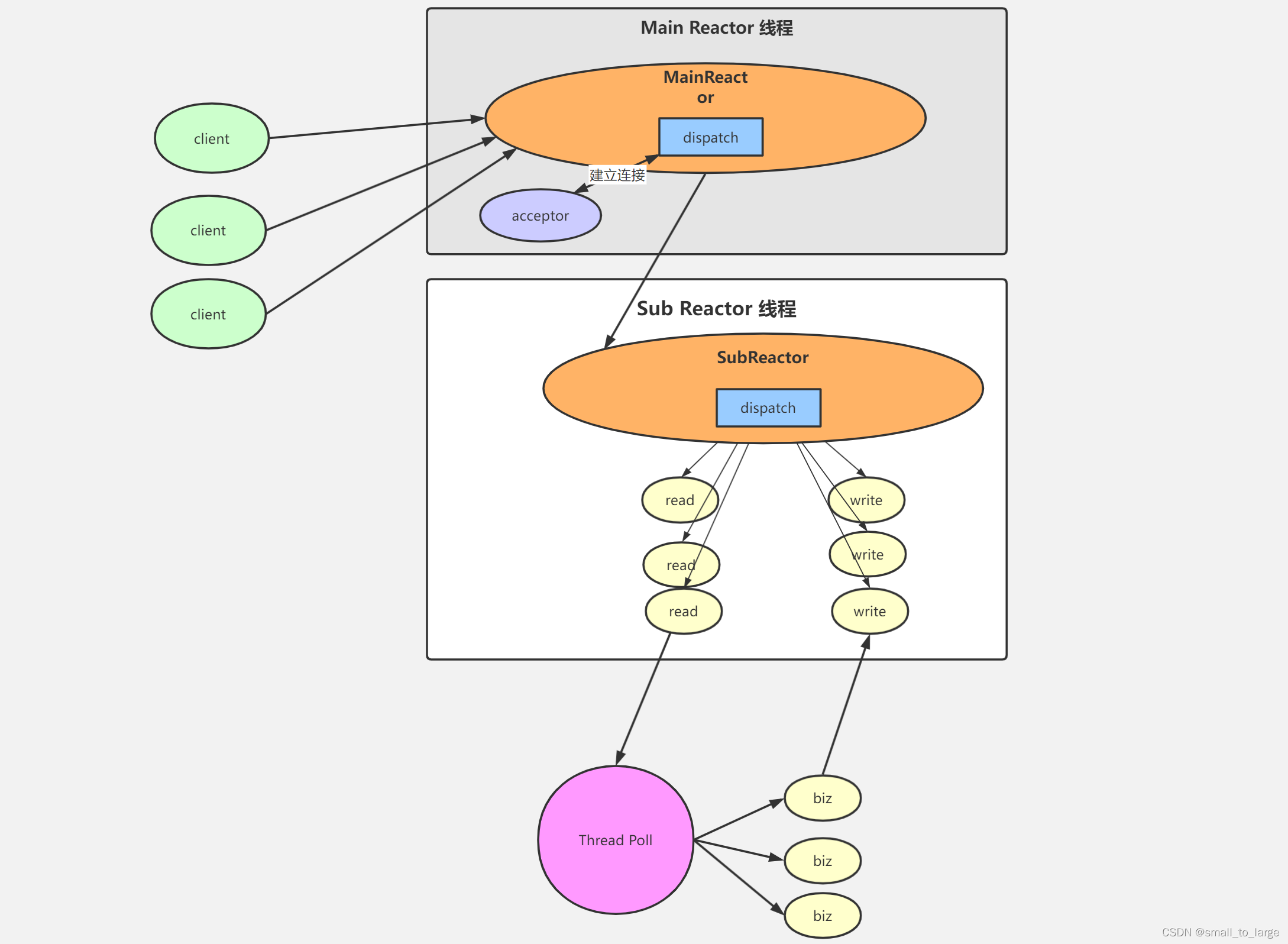
处理过程:
1、mainReactor线程负责监听连接事件,当有连接到来时,通过acceptor处理连接,得到建立好的socket对象。
2、subReactor线程负责监听scoket对象的读写事件,当有读写事件触发时,处理请求的数据的读写。
3、业务处理交给worker线程池处理。
特点:
充分利用多核机器的资源、提高性能并且增加可靠性
各个模块职责单一,降低耦合度,性能和稳定性都有提高
许多项目中广泛应用,比如Netty的主从线程模型等,缺点实现起来相对复杂一些
3 Redis IO模型
对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟。
在4.0版本之前使用的是 单线程+IO多路复用,然而随着时间的推移,单线程越来越不满足一些应用场景了,比如针对大key删除会造成主线程阻塞的问题,redis4.0出了一个异步线程。单线程由于无法利用多核cpu的特性而导致无法满足更高的并发,redis 6.0推出了多线程模式。
2.1 单线程+IO多路复用
在4.0版本之前,单线程+IO多路复用使得redis的性能已经达到一个非常高的高度了,而且单线程也不需要考虑多线程带来的锁开销问题。按照redis官方介绍,单个节点的redis qps可以达到10w+,已经非常优秀,如果有更高的要求,则可以通过部署主从、集群方式进一步提升。
redis整个服务不可能只用到一个线程完成所有工作,它还有持久化、key过期删除、集群管理等其它模块,redis会通过fork子进程或开启额外的线程去处理。
“redis是单线程的!” 所谓的单线程是指从网络连接(accept) -> 读取请求内容(read) -> 执行命令 -> 响应内容(write),这整个过程是由一个线程完成的,至于为什么redis要设计为单线程,主要有以下原因:
- 基于内存。redis命令操作主要都是基于内存,这已经足够快,不需要借助多线程。
- 高效的数据结构。redis底层提供了动态简单动态字符串(SDS)、跳表(skiplist)、压缩列表(ziplist)等数据结构来高效访问数据。
- 保持简单。引入多线程会使redis变得复杂,例如需要考虑多线程并发访问资源竞争问题,数据结构也会变得复杂,hash就不能是单纯的hash,需要像java一设计一个ConcurrentHashMap。还需要考虑线程切换带来的性能损耗,基于第一点,当程序执行已经足够快,多线程并不能带来正面收益。
redis网络IO模型底层使用IO多路复用,通过reactor模式实现的,在redis 6.0以前属于单reactor单线程模式。
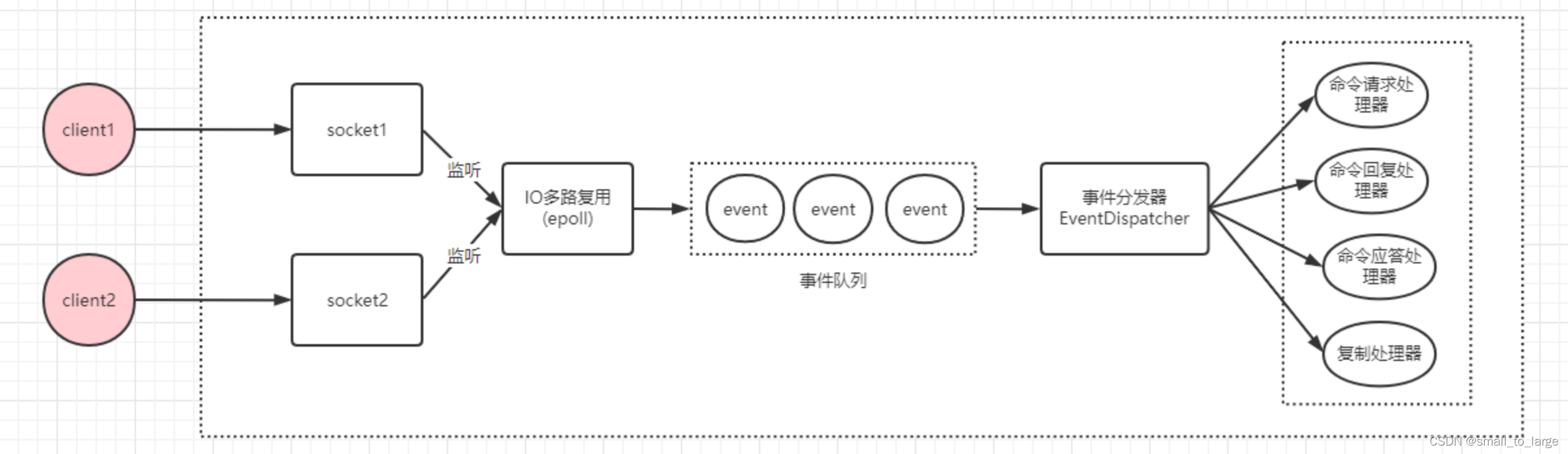
在linux下,IO多路复用程序使用epoll实现,负责监听服务端连接、socket的读取、写入事件,然后将事件丢到事件队列,由事件分发器对事件进行分发,事件分发器会根据事件类型,分发给对应的事件处理器进行处理。
2.1 单线程+IO多路复用+异步线程
在单线程模式下有这样一个问题,当执行删除某个很大的集合或者hash的时候会很耗时(不是连续内存),那么单线程的表现就是其他还在排队的命令就得等待。
于是redis4.0针对大key删除的情况,出了个异步线程。用unlink代替del去执行删除,这样当我们unlink的时候,redis会检测当删除的key是否需要放到异步线程去执行(比如集合的数量超过64个…),如果value足够大,那么就会放到异步线程里去处理,不会影响主线程。同样的还有flushall、flushdb都支持异步模式。
2.3 多线程模式
redis单线程+异步线程+分片已经能满足了绝大部分应用,redis在6.0还是推出了多线程模式。默认情况下,多线程模式是关闭的。
# io-threads 4 # work线程数,会启动 N - 1 个 IO 线程(主线程也算一个 IO 线程)
# io-threads-do-reads no # 是否开启
reids 6.0以前网络IO的读写和请求的处理都在一个线程完成,尽管redis在请求处理基于内存处理很快,不会称为系统瓶颈,但随着请求数的增加,网络读写这一块存在优化空间,为了提升执行命令前后的网络 I/O 性能,redis 6.0开始对网络IO读写提供多线程支持。
可以通过 io-threads 4 参数开启对网络写数据多线程支持,如果对于读也要开启多线程需要额外设置 io-threads-do-reads yes 参数,该参数默认是no,因为redis认为对于读开启多线程帮助不大,但如果你通过压测后发现有明显帮助,则可以开启。
redis 6.0多线程模型思想上类似单reactor多线程和多reactor多线程,但不完全一样,这两者handler对于逻辑处理这一块都是使用线程池,而redis命令执行依旧保持单线程。如下:
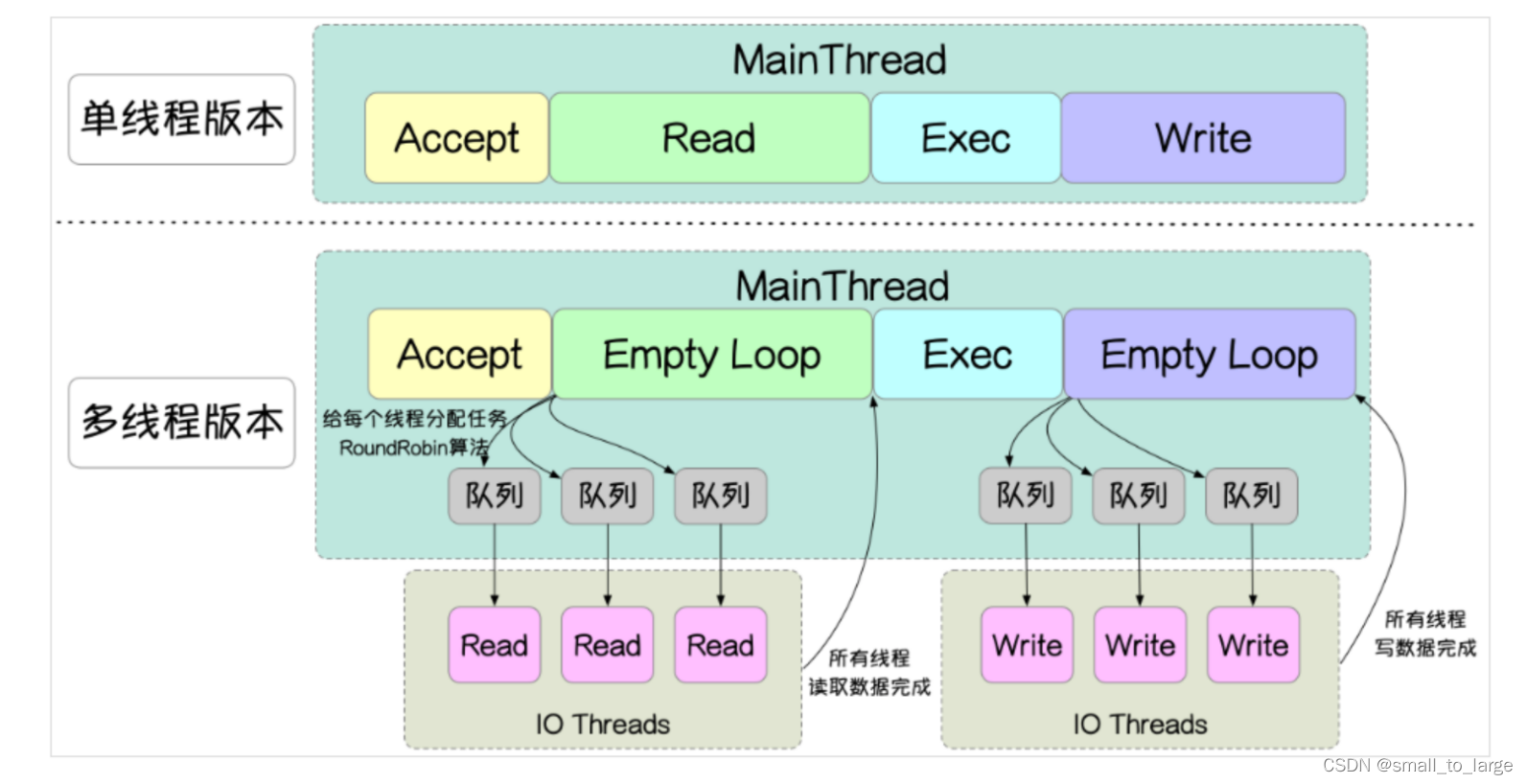
可以看到对于网络的读写都是提交给线程池去执行,这样多个socket的读写就可以并行化,充分利用了cpu多核优势,但Redis命令仍然在主线程中串行执行
2.4 性能对比
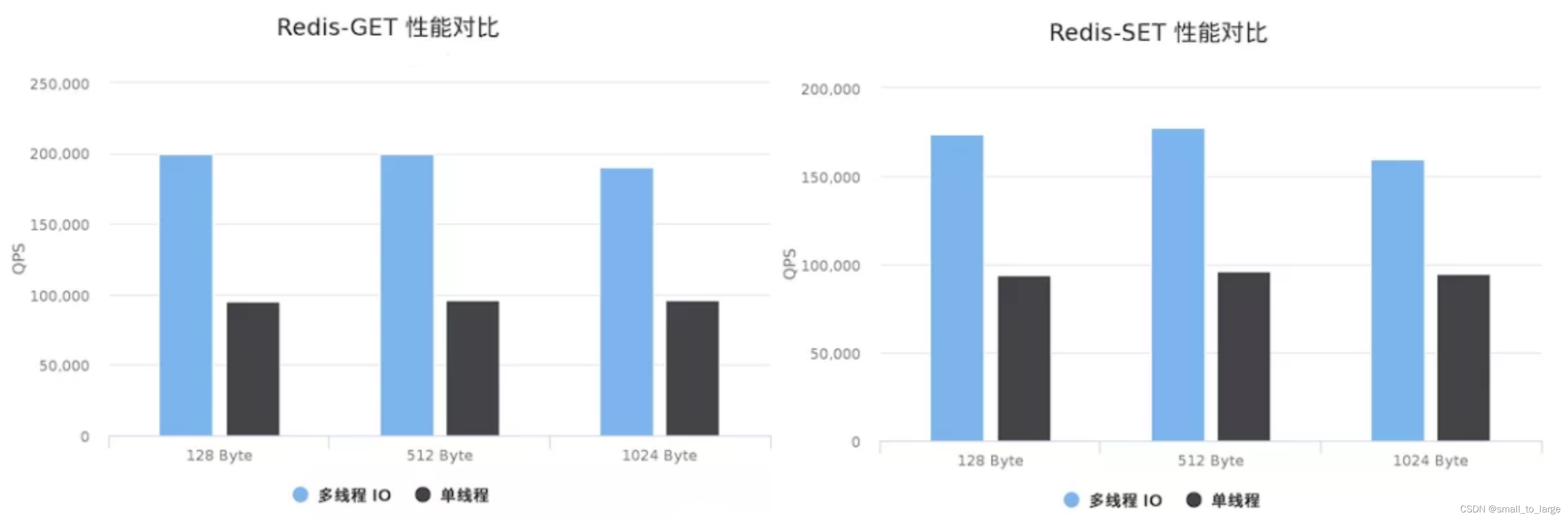
虽然多线程方案能提升1倍以上的性能,但整个方案仍然比较粗糙:
- 首先所有命令的执行仍然在主线程中进行,仍然可能存在性能瓶颈。
- 另外IO读写为
批处理读写,即所有 IO 线程先读取完请求数据并且解析为redis命令后,主线程才开始执行解析的命令;然后待主线程执行完所有的redis命令后,才让所有 IO 线程再一起回复所有响应;即所有的IO线程都是统一执行读或写事件,不会有部分线程执行读操作,部分执行写操作,也就是说不同请求需要相互等待,效率不高。 - 在 IO线程批处理读写和主线程处理时,使用线程自旋检测等待(如下代码),效率更是低下,即便任务很少,也很容易把 CPU 打满。
2.5 Redis事件循环源码浅析
在 Redis 6.0 版本的代码中,事件驱动框架同样是调用 aeMain 函数来执行事件循环流程,该循环流程会调用 aeProcessEvents 函数处理各种事件。而在 aeProcessEvents 函数实际调用 aeApiPoll 函数捕获 IO 事件之前,beforeSleep 函数会被调用。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dISU2zfM-1682146940758)(assets/image-20221212174049545.png)]](https://img-blog.csdnimg.cn/64bf1a2ef41d441a88646d50ab736866.png)
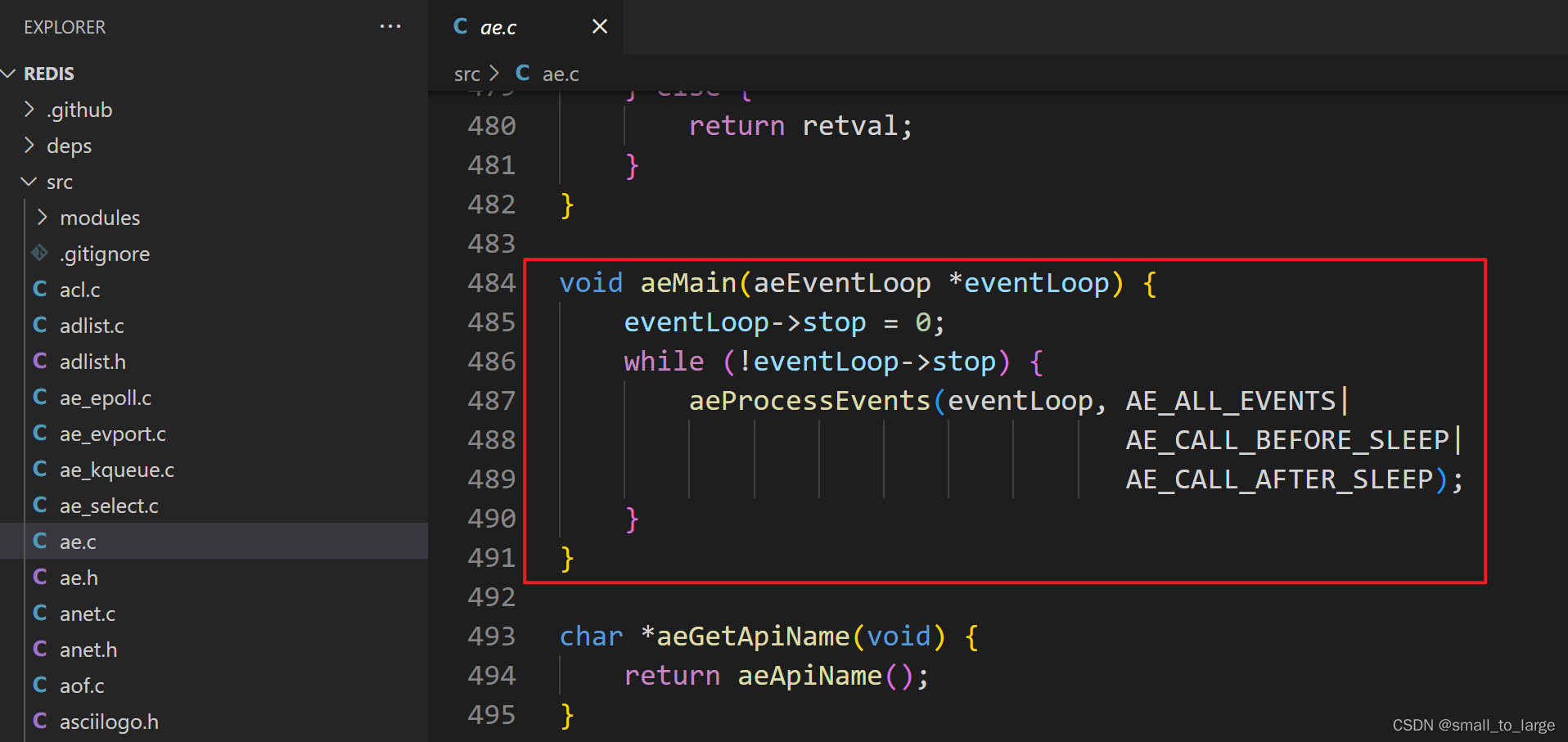
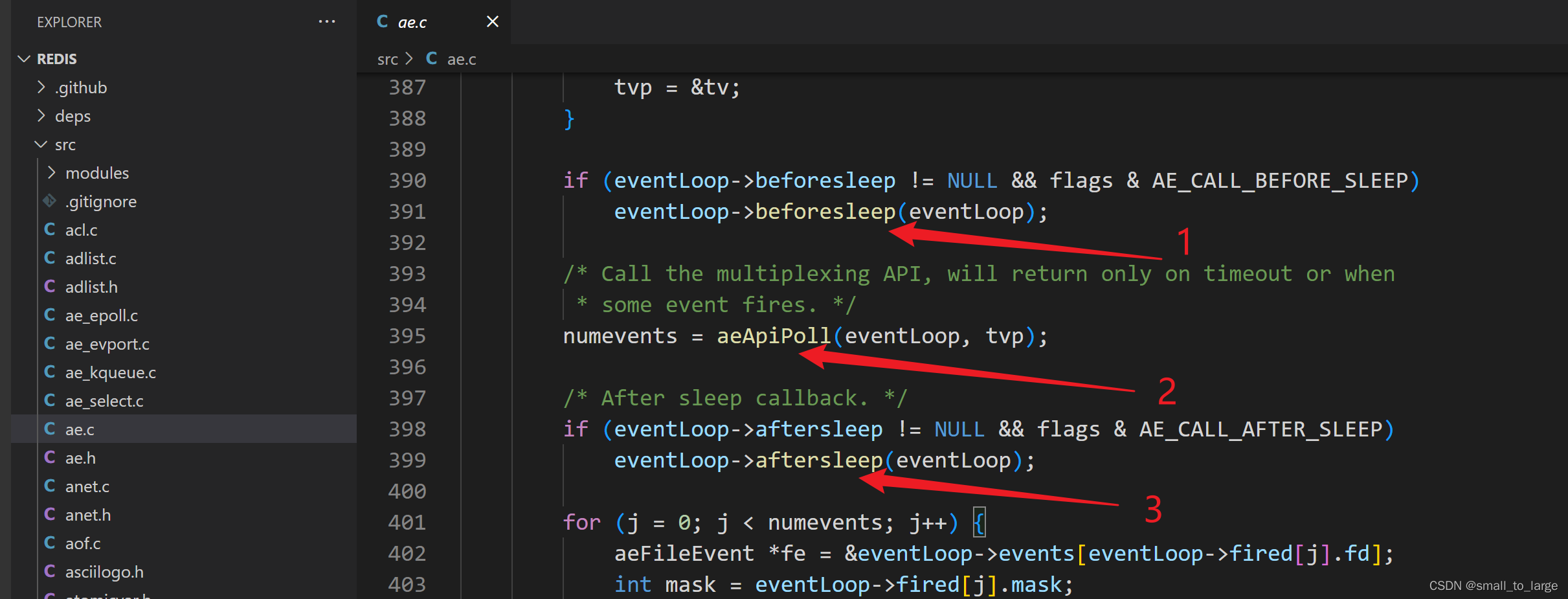
在beforeSleep函数中就会调用handleClientsWithPendingReadsUsingThreads和handleClientsWithPendingWritesUsingThreads 这两个函数:
//主线程执行逻辑:该函数主要负责将 clients_pending_read 列表中的客户端分配给 IO 线程进行处理;
int handleClientsWithPendingReadsUsingThreads(void) {
// 忙轮询,累加所有 I/O 线程的原子任务计数器,直到所有计数器的遗留任务数量都是 0。
// 表示所有任务都已经执行完成,结束轮询。
/* Wait for all the other threads to end their work. */
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
}
//主线程执行逻辑:该函数主要负责将 clients_pending_write 列表中的客户端分配给 IO 线程进行处理。
int handleClientsWithPendingWritesUsingThreads(void) {
/* Wait for all the other threads to end their work. */
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
...
}
在handleClientsWithPendingReadsUsingThreads中,不论是主线程还是IO线程都是调用readQueryFromClient函数进行操作,这个函数大体只干两件时间:
- 将客户端的数据全部读取到querybuf中;
- 调用processInputBuffer解析命令并执行;
在handleClientsWithPendingWritesUsingThreads,将所有客户端依次轮询分配给IO线程,IO线程也是调用writeToClient函数,把客户端缓冲区中的数据写回客户端
IO线程处理函数
每一个IO线程的处理函数都是 IOThreadMain ,也是在 networking.c 文件中定义的,它的主要执行逻辑是一个 while(1) 循环。在这个循环中,IOThreadMain 函数会把 io_threads_list 数组中,每个 IO 线程对应的待处理客户端列表读取出来,并依次取出要处理的客户端,然后根据线程要执行的操作标记进行不同的处理:
- io_threads_op 的值为宏定义
IO_THREADS_OP_WRITE:这表明该 IO 线程要做的是写操作,线程会调用writeToClient函数将数据写回客户端; - io_threads_op 的值为宏定义
IO_THREADS_OP_READ:这表明该 IO 线程要做的是读操作,线程会调用readQueryFromClient函数从客户端读取数据。
//IO线程逻辑
void *IOThreadMain(void *myid)
long id = (unsigned long)myid;
while(1) {
// 忙轮询100w 次循环,等待主线程分配 I/O 任务。
/* Wait for start */
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
...
}
}