MapReduce Counter 计数器
概念
在执行MapReduce程序的时候,控制台输出日志中通常下面片段,可以发现输出信息中的核心词是counter,中文叫做计数器

在执行MapReduce城西过程中,许多时候,用户希望了解程序的运行情况,Hadoop中内置的计数器可以手机、统计程序运行中核心信息,帮助用户理解程序运行的情况,辅助用户诊断故障

这条分段信息,表示Map有2条数据记录输入、4条数据记录输出
内置计数器
Hadoop为每个MapReduce作业维护了一些内置的计数器,报告程序执行时各种信息指标,用户可以根据这些信息进行判断程序:执行逻辑是否合理、执行结果是否正确
Hadoop内置计数器根据功能进行分组(counter group),每隔分组包括若干个不同的计数器
Hadoop计数器都是MapReduce程序中全局的计数器,根MapReduce分布式运算没有关系,不是所谓的局部信息统计
内置counter group包括:MapReduce任务计时器[Map-Reduce Framework] 、文件系统计数器[File System Counters]、作业计数器[Job Counter]、输入文件计数器[File Input Format Counter] 、输出文件计数器[File Output Format Counter]
Map-Reduce Framewor
MapReduce任务计时器
该组计时器主要统计MapReduce框架执行中各个阶段的输入输入信息
| 计数器名字 | 说明 |
|---|---|
| MAP_INPUT_RECORDS | 所有mapper已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有mapper产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有mapper产生的未压缩的输出数据字节数 |
| COMBINE_INPUT_RECORDS | 所有combiner(如果有) 已经处理的输入记录数 |
| COMBINE_OUT_RECORDS | 所有combiner(如果有) 已经产生的输入记录数 |
与Reduce相关的
| 计数器名字 | 说明 |
|---|---|
| REDUCE_INPUT_GROUPS | 所有reducer已处理分组的个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已经处理的输入记录的个数,每当某个reducer的迭代器读一个值时,该计数器的值就会增加 |
| REDUCE_OUTPUT_RECORDS | 所有reducer输出记录数 |
| REDUCE_SHUFFLE_BYTES | Shuffle时复制到reduce的字节数 |
File System Counters
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如HDFS、本地文件系统
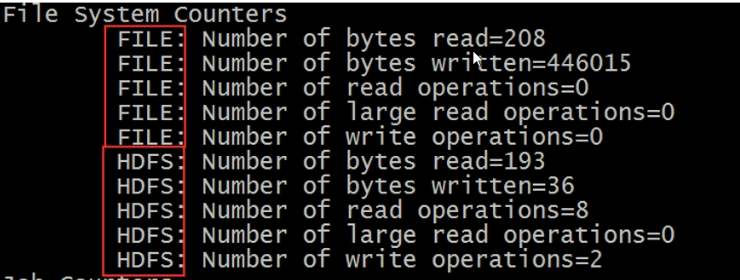
就比如说FILE指的就是本地文件系统,HDFS表示HDFS文件存储系统
相关说明:
| 计数器名字 | 说明 |
|---|---|
| BYTE_READ | 程序从文件系统中读取的字节数 |
| BYTES_WRITEN | 程序往文件系统中协入的字节数 |
| READ_OPS | 文件系统中进行的读操作的数量 |
| LARGE_READ_OPS | 文件系统中进行的大规模读操作的数量 |
| WRITE_OPS | 文件系统中进行写操作的数量(例如CREATE操作、append操作) |
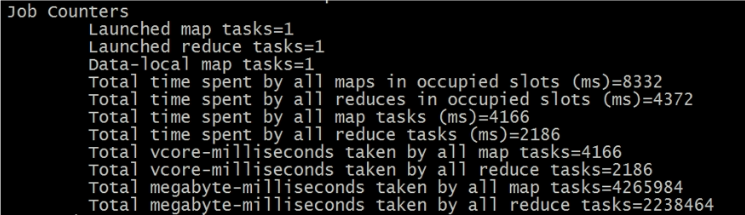
Job Counter
主要记录MapReduce任务启动的task情况,包括:个数、使用资源情况等
File Input/Output Format Counters
主要记录读了多少数据,写了多少数据

自定义计数器
Hadoop内置的计数器还是比较全面的,给作业运行过程的监控带来了方便,但是对于一些业务中的特定要求,比如统计程序执行中某种情况出现的次数统计,内置无法实现,因此MapReduce提供了用户编写自定义计数器的方法。最重要的是计数器是全局统计的,避免了用户自己维护全局变量的不利性。
自定义计数器的使用
通过context.getCounter方法获取一个全局计数器,创建的时候要指定计数器所属的组名核计数器的名字
package MapReduceTest;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
/**
* @author wxk
*/
public class WordMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
private Text keyOut =new Text();
private final LongWritable out=new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//自定义指针,组为wxk_counter 名称为 one_character Counter
Counter counter = context.getCounter("wxk_counter","one_character Counter");
String [] worlds = value.toString().split("\\s+");
System.out.println(Arrays.toString(worlds));
for (String word : worlds){
// 判断长度是否为1,如果为1则计数器就加1
if (word.length() == 1){
//Counter提供的增加方法
counter.increment(1);
}
keyOut.set(word);
context.write(keyOut,out);
}
}
}
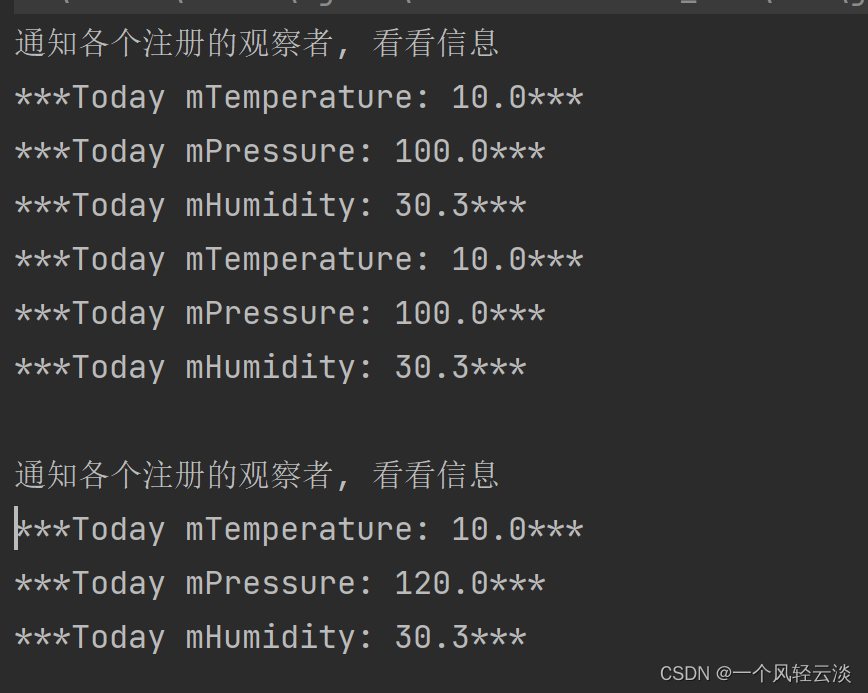
输出结果:

查看打印日志:

为了验证是否全局,这里将输入文件复制一份,如果是全局的,那么我们得到的one_chararcter Counter 的值应该为:

可见计数器在这个过程中是全局的