0. 引言
随着redis的普及,更多的同学对redis分布式缓存更加熟悉,但在一些实际场景中,其实并不需要用到redis,使用更加简单的本地缓存即可实现我们的缓存需求。
今天,我们一起来看看本地缓存组件ehcache
1. ehcache简介
1.1 简介
ehcache是基于java开发的本地缓存组件,无需单独安装部署,只要引入jar包就可利用它来实现缓存。
所谓本地缓存,就是指存储在JVM堆内存中的临时缓存数据,当然ehcache本身也支持Off-Heap Store机制来使用堆外内存,本地缓存相较于redis性能和响应速度更高。
Ehcache的本地缓存还支持过期时间、最大容量、持久化等特性,使得它可以适用于各种不同的缓存场景。
官方文档地址:https://www.ehcache.org/documentation/
1.2 本地缓存与redis的区别
本地缓存与redis的区别在于:
-
架构:
本地缓存基于单机架构,即数据仅本机可用,无法共享给其他服务。除非使用服务调用来获取。而redis本身基于分布式架构,支持跨服务调取。
所以当数据需要分布式调用时,则适用于redis,如果数据只需要本地获取,则可考虑本地缓存 -
性能:
本地缓存本身基于本机内存,没有网络IO消耗,所以性能上大大高于redis,但是如果数据量较大,则还是要考虑使用redis,本地缓存仅适用于数据量小、结构简单的数据场景,不适合复杂的业务数据
-
功能拓展:
redis支持持久化、订阅模式、集群、主从模式等,而ehcache更倾向于简单的缓存功能场景,虽然也支持持久化,但是本身并不建议用它来做大型或复杂场景的缓存。如果场景比较简单轻量,对延迟有较高要求,则可选择本地缓存
2. ehcache使用
1、创建一个springboot项目,这里我的springboot版本为2.6.13
2、引入ehcahe组件依赖
这里需要注意的是net.sf.ehcache是ehcache2.X 与 org.ehcache是echcache3.X,两个版本配置有区别
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
<version>2.6.13</version>
</dependency>
3、在启动类上添加@EnableCaching注解,开启缓存
@SpringBootApplication
@EnableCaching
public class LocalCacheDemoApplication {
public static void main(String[] args) {
SpringApplication.run(LocalCacheDemoApplication.class, args);
}
}
4、在配置文件application.yml中添加配置
spring:
profiles:
active: dev
cache:
type: ehcache
ehcache:
config: classpath:ehcache.xml
5、在resources文件夹下创建配置文件ehcache.xml,注意这里单独创建了一个name为user的缓存,用于后续保存用户信息缓存。如果有不同的缓存需要使用不同的name的,需要单独创建cache标签
标签介绍:
defaultCache: 默认缓存配置标签
cache 指定缓存标签,name表示缓存名称
diskStore 数据存储磁盘路径
属性介绍:
eternal: 缓存是否永久有效,如果为 true 则忽略timeToIdleSeconds 和 timeToLiveSeconds
maxElementsInMemory:最多缓存多少个key
overflowToDisk: 缓存超限时是否写入磁盘,默认为true
overflowToOffHeap: 堆内存超限时是否使用堆外内存,企业版功能,收费
diskPersistent:缓存是否持久化
timeToLiveSeconds:缓存多久过期
timeToIdleSeconds:缓存多久没有被访问就过期
diskExpiryThreadIntervalSeconds:磁盘缓存过期检查线程运行时间间隔
memoryStoreEvictionPolicy:缓存淘汰策略, LFU:最近最少使用的元素先移出; FIFO:最先进入的元素被移出; LRU:使用越少的元素被移出
maxBytesLocalHeap:缓存最大占用JVM堆内存,0表示不限制,单位支持K、M或G
maxBytesLocalOffHeap: 缓存最大占用堆外内存,0表示不限制,单位支持K、M或G,企业版功能,收费
maxBytesLocalDisk:缓存最大占用磁盘,0表示不限制,单位支持K、M或G
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToLiveSeconds="3600"
timeToIdleSeconds="0"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="user"
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToLiveSeconds="3600"
timeToIdleSeconds="0"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"/>
<!-- 存储到磁盘时的路径-->
<diskStore path="/Users/wuhanxue/Downloads/ehcache" />
</ehcache>
6、缓存使用,在获取方法中使用@Cacheable注解,在更新方法中使用@CachePut注解。
我这里模拟就没有访问数据库查询数据了,大家在实际书写的时候可以连接上数据源测试
@RestController
@RequestMapping("user")
public class UserController {
@GetMapping("get")
@Cacheable(cacheNames = "user", key = "#id")
public User getById(Integer id) {
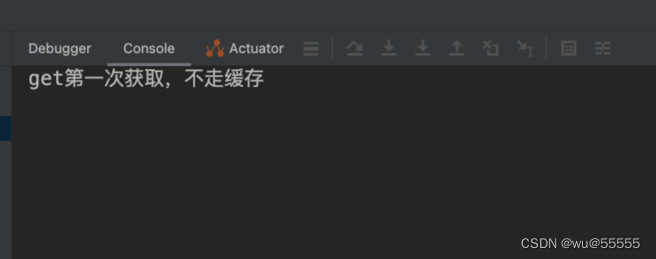
System.out.println("get第一次获取,不走缓存");
User user = new User();
user.setId(id);
user.setAge(18);
user.setName("benjamin_"+id);
user.setSex(true);
return user;
}
@PostMapping("update")
@CachePut(cacheNames = "user", key = "#search.id")
public User update(@RequestBody User search) {
System.out.println("update更新缓存");
User user = new User();
Integer id = search.getId();
user.setId(id);
user.setAge(search.getAge() != null ? search.getAge()+1 : 0);
user.setName("update_benjamin_"+id);
user.setSex(true);
return user;
}
}
3. 测试
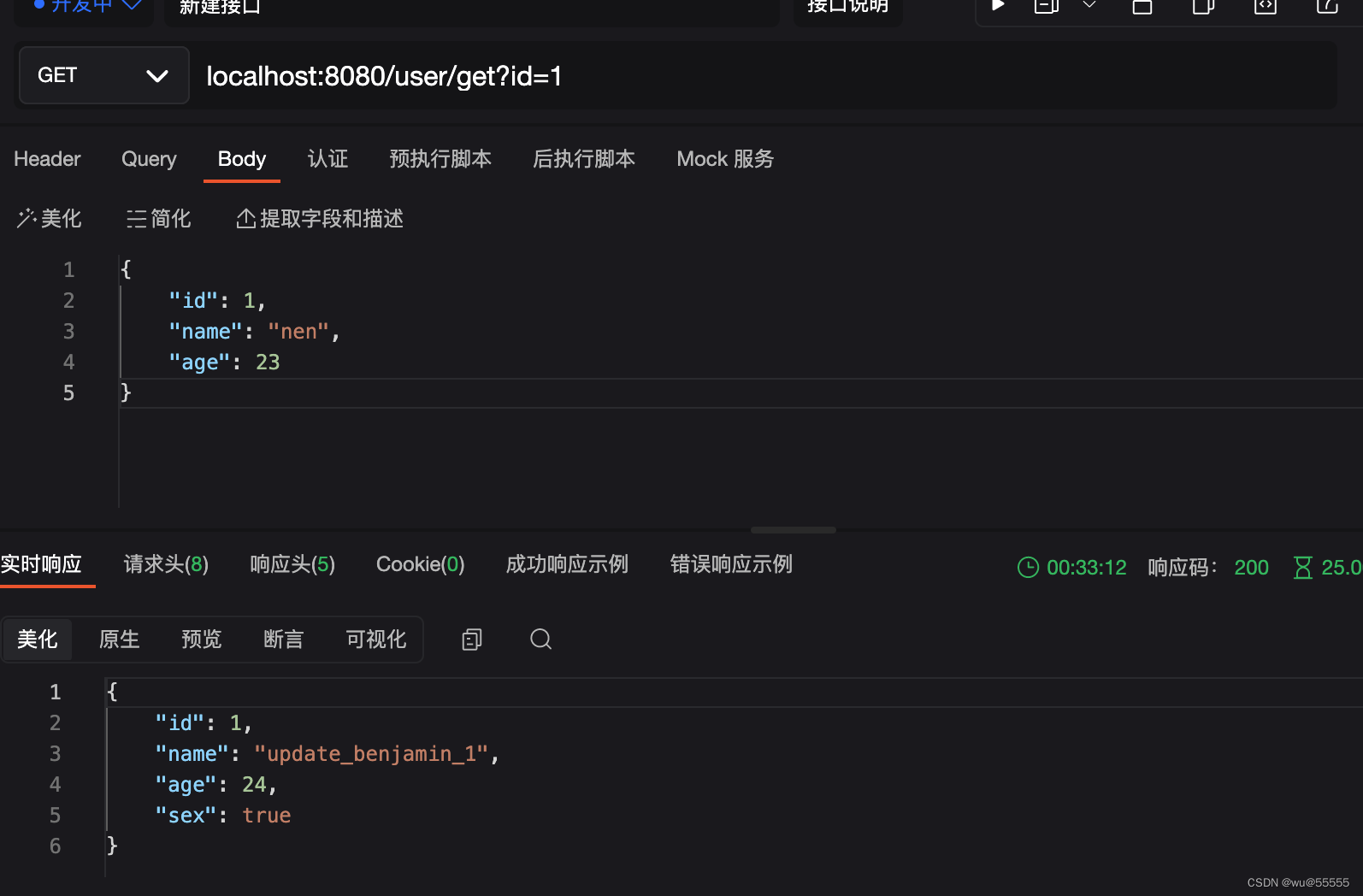
1、调用查询接口:localhost:8080/user/get?id=1
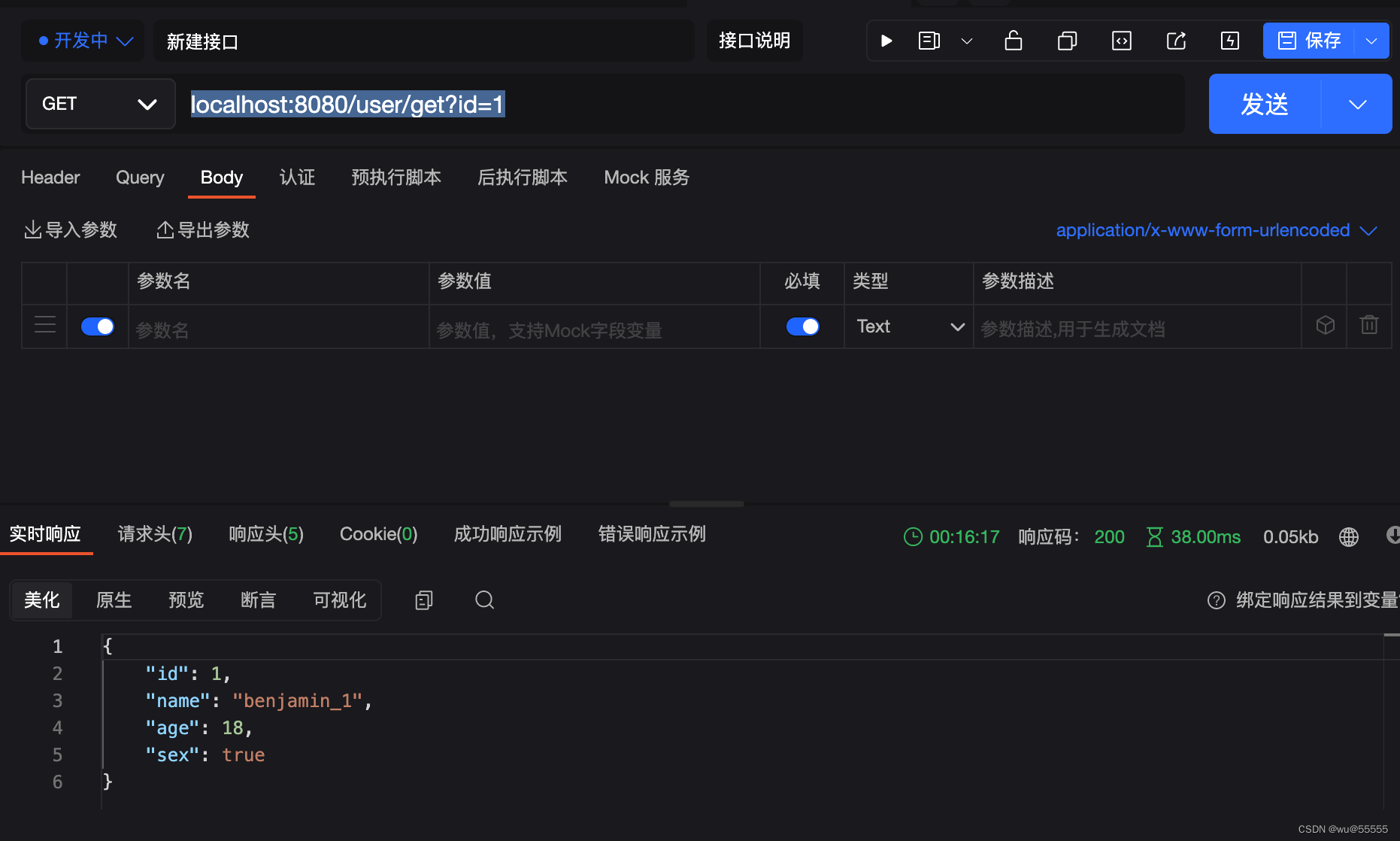
2、第一次调用,打印"get第一次获取,不走缓存"。再调用一次发现没有打印了,但是数据正常查询,说明走了缓存
3、调用更新接口
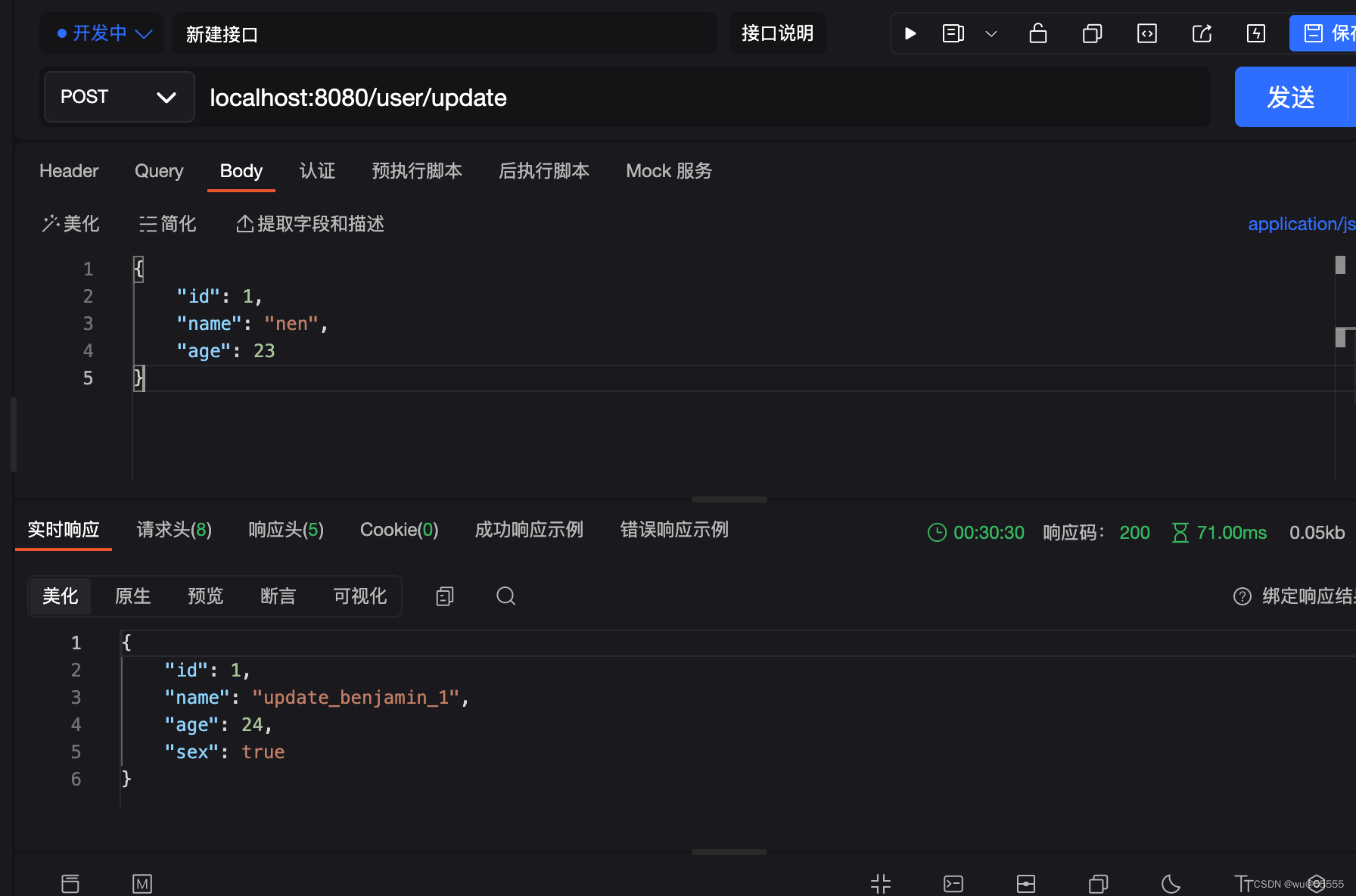
4、再调用查询接口,查询到的就是更新的数据,说明缓存更新成功
4. 注意事项
谨慎使用maxElementsInMemory
maxElementsInMemory表示的是最大缓存多少个key,这个配置项谨慎使用,一般我们应该根据占用多少内存空间来控制,而不是占用多少个key,如果出现某些key的数据量特别大时,就会导致key数量没超过,但内存占用超过导致的OOM了
这个我们通过一个生成大数据量的接口来模拟,其中generateMemoryString方法可以在文末的源码仓库中
1、书写接口
@GetMapping("build")
@Cacheable(cacheNames = "user", key = "#id")
public User build(Integer id) {
System.out.println("get第一次获取,不走缓存");
User user = new User();
user.setId(id);
user.setAge(18);
// 生成指定大小的字符串
user.setName(generateMemoryString(id));
user.setSex(true);
return user;
}
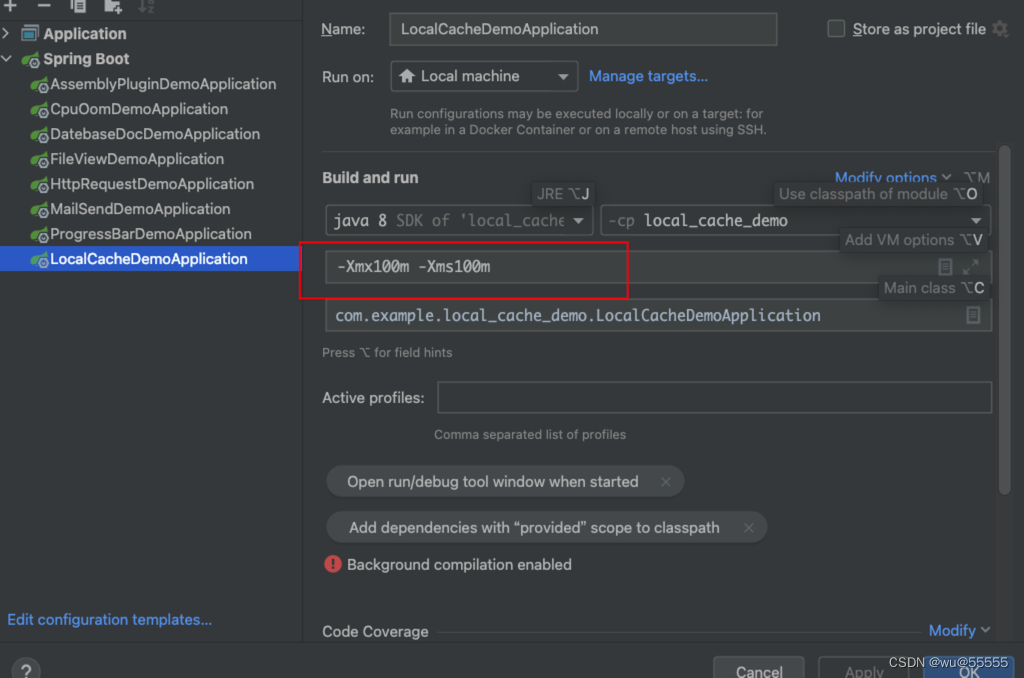
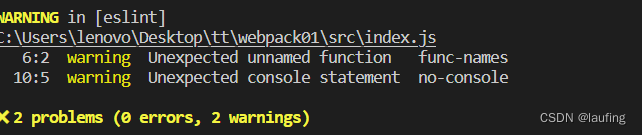
2、限制项目JVM内存为100m,方便更快模拟出报错
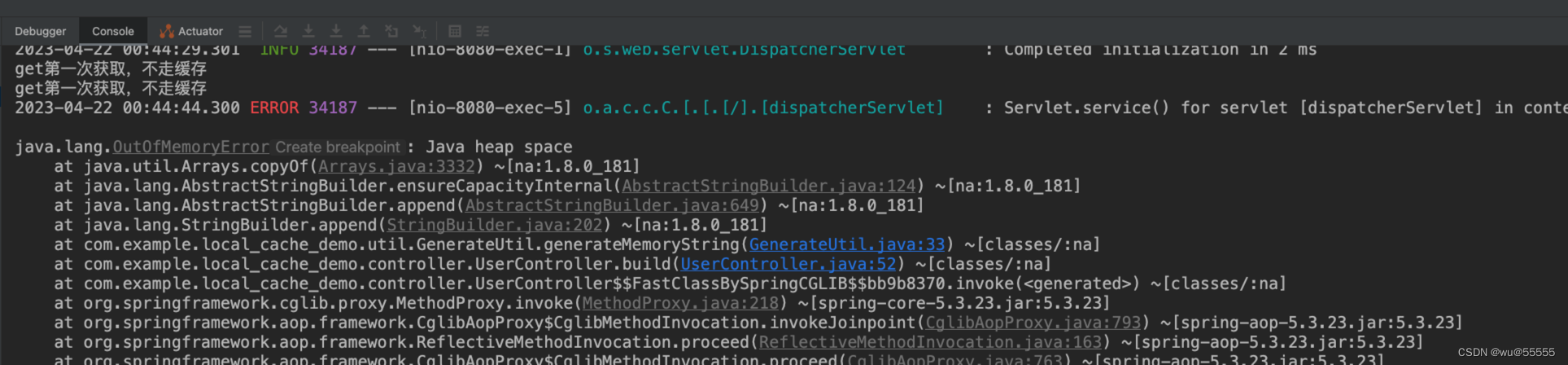
3、调用接口localhost:8080/user/build?id=100,因为该接口会生成大数据,占用本地缓存,而JVM缓存又给的100M,所以调用会报错堆内存溢出,如图所示
4、因此该配置项要谨慎使用,可以通过maxBytesLocalHeap,maxBytesLocalDisk设置占用多少内存、磁盘来替代
<cache
name="user"
eternal="false"
maxBytesLocalHeap="50M"
maxBytesLocalDisk="200M"
overflowToDisk="false"
diskPersistent="false"
timeToLiveSeconds="3600"
timeToIdleSeconds="0"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
如果maxBytesLocalHeap和maxElementsInMemory都配置了的,谁先达到配置的值,就触发
如果单个key值太大,仍然会导致OOM
虽然我们上面配置了maxBytesLocalHeap来限制最大使用的内存,比如我们限制了该值为100M,则如果我们有4个30M的数据进来,那么就会根据配置的淘汰策略去淘汰之前的key,以腾出空间来装新的数据
但如果新进来的数据很大,比如超过100M了,那么就会一下子装满内存,甚至淘汰之前的key也不行,所以这种情况下还是会导致OOM的
遇到这种情况,两种处理办法,一种是保证不会有大于这个阈值的数据产生,这个可以通过业务代码控制,二是设置一个全局错误捕捉,捕捉产生的OOM报错,然后返回一个兜底或者其他的状态码,以此标识




![C++ [模板]](https://img-blog.csdnimg.cn/img_convert/35edba3b72a0ab22f56bc7f5b0722a85.jpeg)