作者 | 太子长琴
整理 | NewBeeNLP
大家好,这里是NewBeeNLP。ChatGPT 的爆火让很多 NLPer 大吃一惊,焦虑感爆棚,它的思路和方法都不复杂,但效果却出奇的好。
我想任何研究成果的爆发都不可能是一蹴而就的,期间必然包含这一系列小的创新和优化。于是,重新把 GPT3 的 Paper 拉出来读了一遍,重点关注了实验结果之外的东西,果然发现不少细节。因此,本文还是以 GPT3 为主。
从微调到In-Context Learning
GPT3 的初衷再次一看,其实非常 make sense:预训练时代 NLP 的典型方法是在不同下游任务上进行微调(fine-tuning),但是,人类只需要几个示例或简单的说明就可以执行新的任务。
这里面潜在的意思是,大语言模型内部其实已经学到了所有这些能力,我们要做的是「合理」地去挖掘这些能力,而不是给一大批数据让它重新学习(fine-tuning)。这样做的原因和意义包括:
每个新任务需要一批标注数据,这就限制了语言模型应用范围。
预训练-微调机制本身的问题:预训练模型时在大范围内获取信息,微调时则在非常窄的任务上。这种虚假相关性随着模型表现力和训练分布的狭窄而增长。也就是说,模型能力很强,但被卡在特别窄的任务上,这种强其实是一种被放大的强,其泛化性可能很差【1】【2】。
人类不需要一大批监督数据学习大多数的语言任务,我们往往会将多个任务和技能无缝混合或自由切换。
这里有两个概念要先澄清一下:
Meta-Learning:训练时开发了一系列广泛的技能和模式识别能力,推理时使用这些能力快速适应或识别所需的任务。
In-Context Learning:使用预训练语言模型的文本输入作为任务范式的一种形式:以自然语言指令(instruction)或任务的一些样例为条件,期望通过预测接下来会发生什么来完成任务的下一个实例。
这里有个图片:

Meta-Learning 捕获通用方法的内循环/外循环结构,而 In-Context Learning 指代 Meta-Learning 的内循环。
而之所以有 GPT3 这篇 paper 就是因为这种 In-Context 的能力还比较差,离微调这种范式还有一段距离。但是他们又坚信这种 In-Context 的范式是值得探究的(上面提到的原因),这才一直沿着这条道一路走了下去。
还有个很重要的点需要强调——模型规模,有研究【3】表明,模型规模和效果有相关性(大模型有大智慧),GPT3 验证了这个假设。
对于 In-Context Learning 的验证,使用了三种不同的 condition:
Few-Shot Learning:10-100 个样例(N=2048)作为上下文
One-Shot Learning:一个样例
Zero-Shot Learning:没有样例,只有一个自然语言指令(instruction)
效果如下:
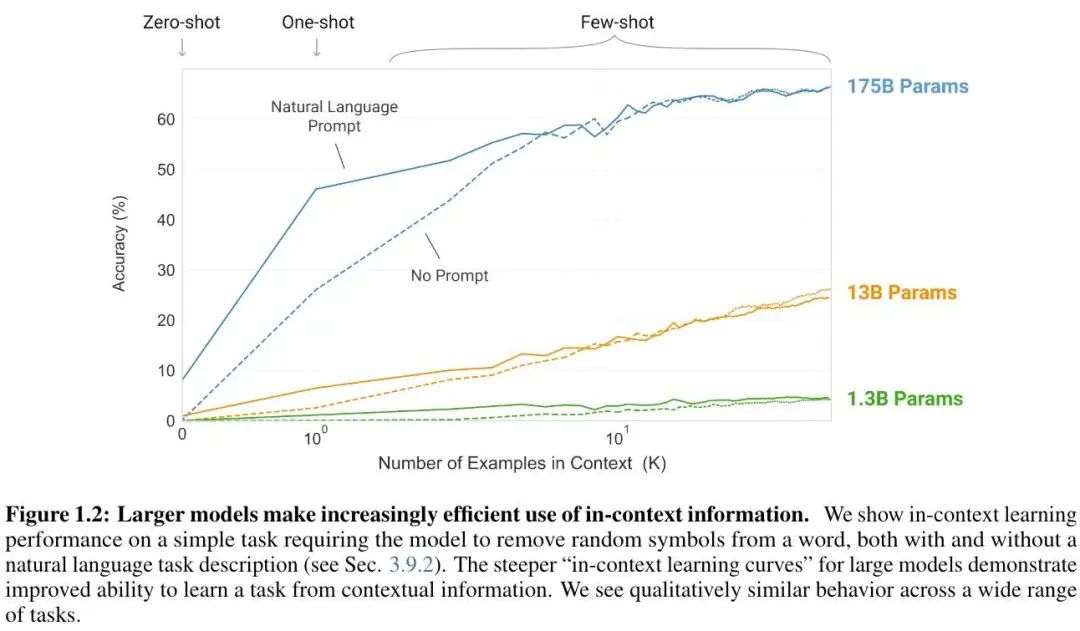
而且,模型大小和上下文中样例数量的一般趋势适用于大多数任务。更大的模型是更熟练的元学习者。
更加可喜的是,在 Zero-Shot 和 One-Shot 下效果都不错,Few-Shot 下甚至偶尔能超过 SOTA。One-Shot 和 Few-Shot 也显示出了快速的适应或即时推理能力。当然,也有一些 GPT3 + Few-Shot 都搞不定的情况,比如 NLI 和一些阅读理解任务。
除此之外,文章还研究了数据污染问题,偏见、公平性以及广泛的社会影响。
方法和数据
关于方法,主要是前面提到的三种设置,文章给了一个非常直观的样例:
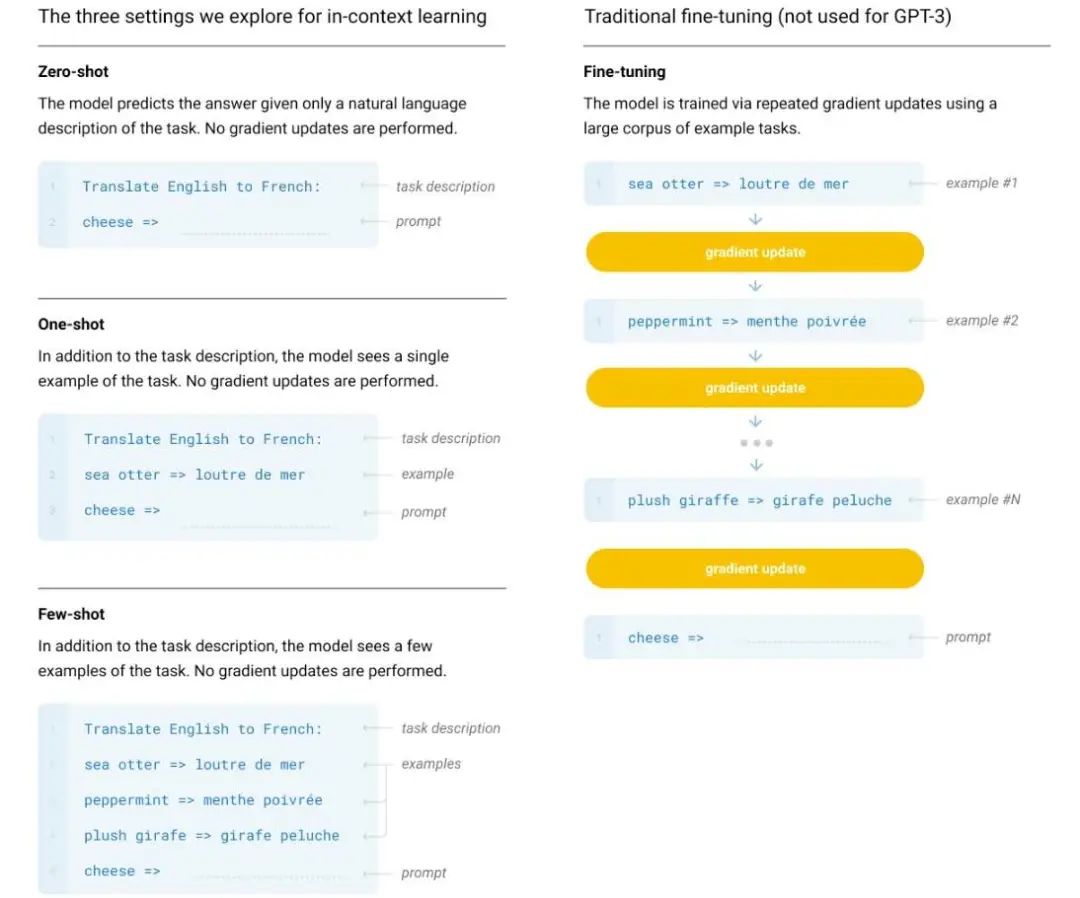
对此不再赘述,不过有一点比较有意思,就是与人类学习的细微差别:人一般会通过问一些问题来确认或进一步确认他们已经理解了要回答的问题,一般是以一种交互的方式;而 GPT3 是通过一些样例来指导模型(或者可以理解为让模型先了解再判断)。它们之间的根本区别可以简单的概括为:人类以理解(推理)为核心,而 GPT3 以表征为核心。当然,你也可以认为后者也是一种「理解」。
接下来是数据,这里最核心的是一个提高数据质量的操作,共包括三步:
根据一系列高质量参考语料库的相似性下载并过滤 CommonCrawl,结果就是 45TB 过滤到 570GB。
在数据集内和数据集之间的文档级别进行模糊重复数据删除(去掉了 10%),防止冗余,并保证衡量过拟合的验证集的真实性。
将已知的高质量参考语料库添加到训练数据集合中,增强 CommonCrawl 并增加多样性。
最终数据集如下:
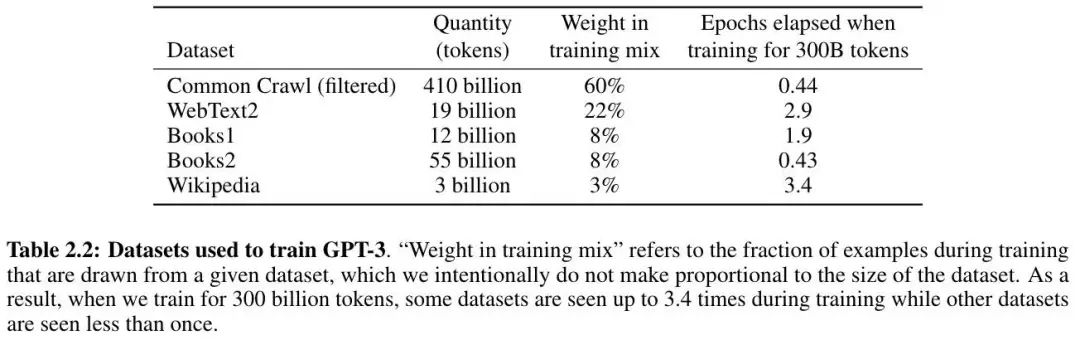
值得注意的是它的采样策略,并不是根据不同数据集的 size 进行采样,而是根据数据质量——数据质量越高的数据集越有可能被采样到。比如 CommonCrawl 和 Book2 的数据有可能采样不到一次(不一定全部被使用),但其他数据集可能被采样 2-3 次。
局限和影响
局限
局限这一部分篇幅不长但非常精彩,尤其是有了 ChatGPT 再回看时,建议阅读原文。
首先,就强调了它的不足性,尤其对「常识物理学」,比如:“如果把奶酪放到冰箱会不会融化?”事实上,这也是整个 AI 面临的难题。哲学家也对此进行过研究,比如维特根斯坦在《论确定性》中谈及的信念网分布问题,可以参考这篇笔记[1],大概意思是说,AI 擅长的是人类认为的复杂问题(也就是《思考,快与慢》中说的系统二),最不擅长的反而是人类看起来很简单,甚至没有意识到的问题(比如 “我有两只手”)。
第二,GPT3 在结构和算法上的局限性,主要是没有用到双向结构,或其他训练目标(如去噪)。
第三,受预训练目标的限制。即自监督预测已经到极限了,新的方法迫在眉睫。未来的方向包括:从人类学习目标函数【4】(这是 OpenAI 的文章)、强化学习微调或多模态(比如更好的世界模型)【5】。其实,OpenAI 在从人类学习这方面除了【4】还有不少研究,比如 2021 年的【6】和 WebGPT【7】,2022 年的 InstructGPT【8】和【9】。
第四,预训练时的低效率采样——相比人类,样本还是太多,尤其和人类学习相比。未来的一个重要方向是预训练采样的效率,可能来自物理世界的基础知识提供额外信息,或算法改进。
第五,不确定 Few-Shot 是不是在推理时学习到新的任务,还是识别出来了在训练时学到的任务。最终,甚至不清楚人类从零开始学习与从之前的样本中学习分别学到什么。准确理解 Few-Shot 的工作原理是一个未来的方向。
第六,贵而且不方便进行推理,在实际应用中可能是个问题。知识蒸馏在如此规模上进行也可能是新的挑战和机会。
最后,是深度学习的通病——结果不容易解释,而且还记住了训练数据上的偏见,这也是种瓜得瓜种豆得豆。
可以看出这部分内容提到的一些方向正是未来 ChatGPT 成功的关键,真的是看准一条道坚持走下去的典范。
影响
这部分内容主要包括三个:语言模型的滥用、偏见以及能耗,是 LLM 的通用问题了。
对于滥用,最突出的就是造假和欺骗,很多欺诈应用依赖人类写的高质量文本,现在这个瓶颈被 LLM 直接给填平了,这不知道算不算一个小小的潘多拉魔盒。这里面尤其是有组织的团体对 LLM 的恶意使用。
偏见主要包括:性别、种族和区域,小模型比大模型更严重。这里最主要的是要干预,这篇 Paper 未提及的去偏综述[2]可以略作参考。不过文章有一点强调值得注意:去偏不应以指标为导向,而应该以整体方式进行。关于如何分析偏见(以及对应的规范),可以参考【10】。
关于能耗,这里提供了另一个视角:不仅考虑预训练,还应该考虑模型生命周期内的摊销。这玩意儿训练时是比较费电,不过一旦训练好使用起来成本就非常低了(边际成本几乎为 0)。
小结和展望
本文主要回顾了一下 GPT3,当时看这篇 Paper 并没有意识到其中 In-Context 的威力(谁让它当时效果一般呢,看来以后看文章不能光看在公开数据集上的效果),而且这方面其实是有研究的,比如 Facebook 的 MetaICL[3],OpenAI 厉害的地方是坚持这条路并一直想方设法优化(上面的《局限》小节)。
除了 In-Context Learning,语料过滤和去重也是值得注意的两个点,具体参见论文附录 A。其中,过滤用了一个逻辑回归的二分类器,去重则用了 MinHashLSH,两个地方使用了相同的特征。再就是局限部分,体现了对 AI 认知的全面和深度,令读者受益匪浅。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

文献和参考
核心论文
Tom B. Brown, Language Models are Few-Shot Learners, 2020
相关文献
带※表示重要文献。
【1】Dani Yogatama, Learning and evaluating general linguistic intelligence, 2019
【2】R Thomas McCoy, Diagnosing syntactic heuristics in natural language inference, 2019
【3】Jared Kaplan, Scaling laws for neural language models, 2020
【4】※Daniel M. Ziegler, Fine-tuning language models from human preferences, 2019
【5】Yen-Chun Chen, Uniter: Learning universal image-text representations, 2019
【6】Jeff Wu, Recursively Summarizing Books with Human Feedback, 2021
【7】※Reiichiro Nakano, WebGPT: Browser-assisted question-answering with human feedback, 2021
【8】※Long Ouyang, Training language models to follow instructions with human feedback, 2022
【9】Nisan Stiennon, Learning to summarize from human feedback, 2022
【10】Su Lin Blodgett, Language (Technology) is Power: A Critical Survey of “Bias” in NLP, 2020
参考资料
Mingyu Zong, A SURVEY ON GPT-3, 2022
本文参考资料
[1]
笔记: https://yam.gift/2018/04/07/AI/2018-04-07-AI-Philosophy-Note/
[2]去偏综述: https://yam.gift/2021/11/18/Paper/2021-11-18-Debiasing/
[3]MetaICL: https://yam.gift/2021/11/01/Paper/2021-11-01-MetaICL/