动动发财的小手,点个赞吧!
自从最新的Large Language Models(LLaM)发布以来,如OpenAI的GPT系列、开源模型Bloom或谷歌发布的LaMDA等,Transformer展现出了巨大的潜力,成为了深度学习的前沿架构楷模。
尽管已经有几篇文章介绍了 transformer 及其背后的数学原理,但在本文[1]中,我想结合我认为最好的方法和我的观点,给出一个完整的概述。自己的观点和使用 Transformer 模型的个人经验。
本文试图对 Transformer 模型进行深入的数学概述,展示其强大的来源并解释其每个模块背后的原因。
自然语言处理(NLP)简介
在开始使用 Transformer 模型之前,有必要了解创建它们的任务,即处理文本。
由于神经网络使用 Tensor ,为了将文本输入神经网络,我们必须首先将其转换为数字表示。将文本(或任何其他对象)转换为数字形式的行为称为嵌入。理想情况下,嵌入式表示能够再现文本的特征,例如单词之间的关系或文本的情感。
有几种方法可以执行嵌入,本文的目的不是解释它们,而是我们应该了解它们的一般机制和它们产生的输出。如果您不熟悉嵌入,只需将它们视为模型架构中将文本转换为数字的另一层。
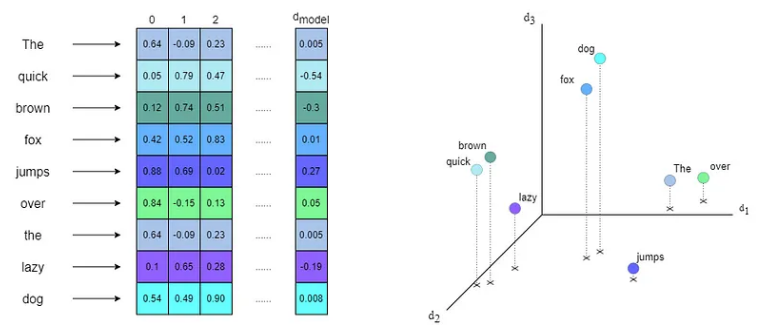
最常用的嵌入作用于文本的单词,将每个单词转换为一个真正高维度的向量(将文本划分为应用嵌入的元素称为标记)。在原始论文中,每个标记/单词的嵌入维度为 512。重要的是要注意向量模数也已归一化,因此神经网络能够正确学习并避免梯度爆炸。
嵌入的一个重要元素是词汇。这对应于可用于提供 Transformer 模型的所有标记(单词)的集合。词汇不一定只是句子中使用的词,而是与其主题相关的任何其他词。例如,如果 Transformer 将用于分析法律文件,则与官僚行话相关的每个词都必须包含在词汇表中。请注意,词汇表越大(如果它与 Transformer 任务相关),嵌入越能够找到标记之间的关系。
除了单词之外,词汇表和文本序列中还添加了一些其他特殊标记。这些标记标记文本的特殊部分,如开头 、结尾 或填充 (添加填充以使所有序列具有相同的长度)。特殊标记也作为向量嵌入。
在数学中,嵌入空间构成了一个归一化向量空间,其中每个向量对应一个特定的标记。向量空间的基础由嵌入层能够在标记之间找到的关系确定。例如,一个维度可能对应以-ing结尾的动词,另一个维度可能是具有积极意义的形容词等。此外,向量之间的角度决定了标记之间的相似性,形成具有语义关系的标记簇。
❝虽然只提到了文本处理的任务,但实际上 Transformer 是为处理任何类型的顺序数据而设计的。
❞
Transformer 的工作流程
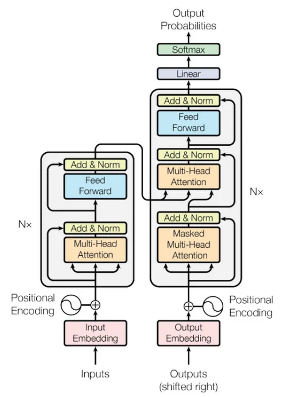
上图是近几年深度学习研究中被复制最多的图表之一。它总结了 Transformers 的完整工作流程,代表了流程中涉及的每个部分/模块。
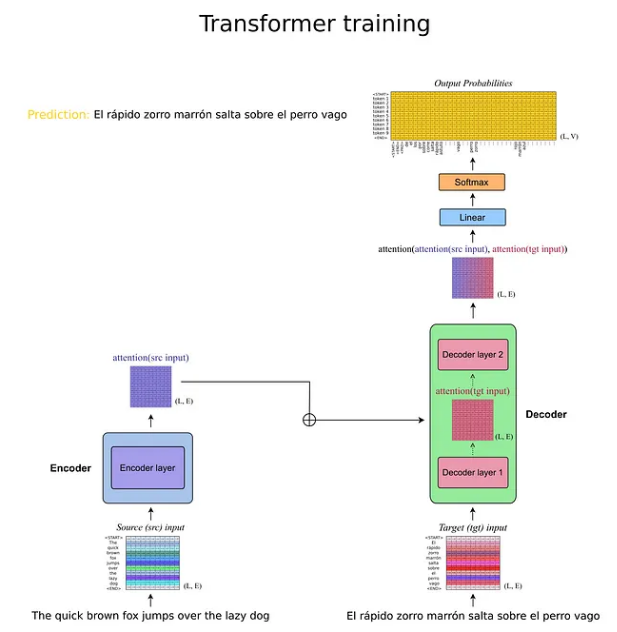
更高的透视图将 Transformers 分为 Encoder(图中左侧蓝色方块)和 Decoder(右侧蓝色方块)。
为了说明 Transformers 的工作原理,我将使用从西班牙语到英语的文本翻译示例任务。
-
编码器的目标是找到输入序列的标记之间的关系,即要翻译成西班牙语的句子。它获取西班牙语句子作为输入(在应用嵌入之后)并输出由注意力机制加权的相同序列。从数学上讲,编码器在西班牙语标记的嵌入空间中执行转换,根据向量在句子含义中的重要性对向量进行加权。
❝我还没有定义注意力是什么,但基本上可以将其视为一个函数,该函数返回一些系数,这些系数定义了句子中每个单词相对于其他单词的重要性。
❞
-
另一方面,解码器首先将翻译后的英文句子作为输入(原图中的输出),应用注意力,然后在另一个注意力机制中将结果与编码器的输出结合起来。直观地,解码器学习将目标嵌入空间(英语)与输入嵌入空间(西班牙语)相关联,以便它找到两个向量空间之间的基础变换。
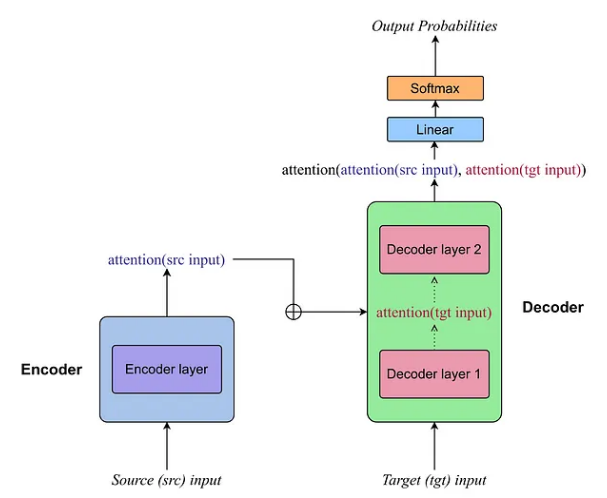
❝为清楚起见,我将使用符号源输入来指代编码器的输入(西班牙语的句子),使用目标输入来指代解码器中引入的预期输出(英语的句子)。该符号将在本文的其余部分保持一致。
❞
现在让我们仔细看看转换器的输入(源和目标)和输出:
正如我们所见,Transformer 输入文本被嵌入到高维向量空间中,因此输入的不是句子,而是向量序列。然而,存在更好的数学结构来表示向量序列,即矩阵!更进一步,在训练神经网络时,我们不会逐个样本地训练它,而是使用包含多个样本的批次。生成的输入是形状为 [N, L, E] 的张量,其中 N 是批量大小,L 是序列长度,E 是嵌入维度。
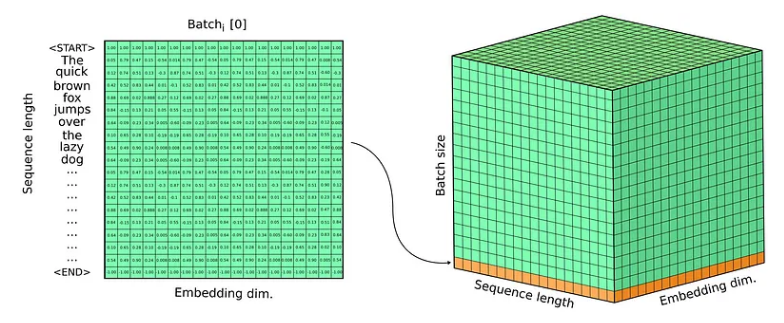
至于 Transformer 的输出,应用了一个 Linear + Softmax 层,它产生一些输出概率(回想一下,Softmax 层输出定义类的概率分布)。 Transformer 的输出不是翻译后的句子,而是词汇表的概率分布,它决定了概率最高的单词。请注意,对于序列长度中的每个位置,都会生成概率分布以选择具有更高概率的下一个标记。由于在训练期间 Transformer 一次处理所有句子,我们得到一个 3D 张量作为输出,它表示形状为 [N, L, V] 的词汇标记的概率分布,其中 N 是批量大小,L 是序列长度,并且V 词汇长度。
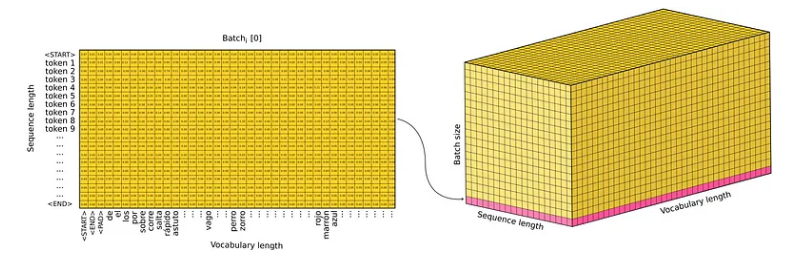
最后,预测的标记是概率最高的标记。
❝如 NLP 简介部分所述,嵌入后的所有序列都具有相同的长度,这对应于 Transformer 可以引入/产生的最长可能序列。
❞
训练与预测
对于本文第 1 部分的最后一节,我想强调一下 Transformer 的训练阶段与预测阶段。
如前一节所述,Transformer接受两个输入(源和目标)。在训练期间,Transformer 能够一次处理所有输入,这意味着输入张量仅通过模型一次。输出实际上是上图中呈现的 3 维概率张量。
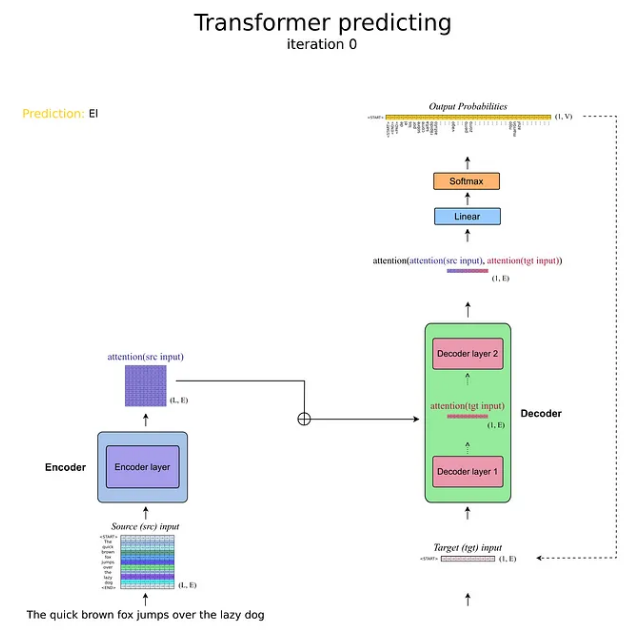
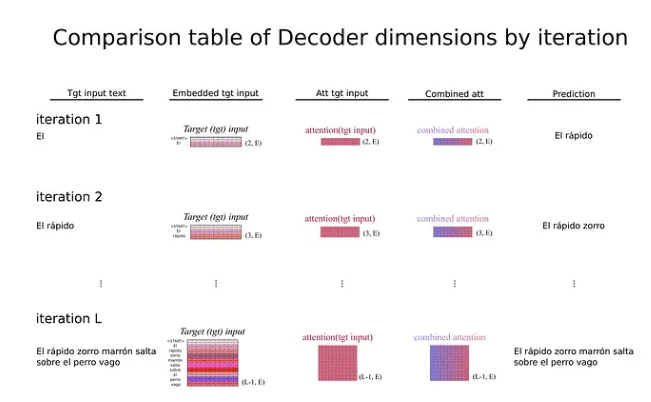
相反,在预测阶段,没有目标输入序列来提供给 Transformer(如果我们已经知道翻译的句子,我们就不需要深度学习模型来进行文本翻译)。那么,我们输入什么作为目标输入呢?
正是在这一点上,Transformer的自回归行为暴露无遗。 Transformer 可以在编码器中一次处理源输入序列,但对于解码器的模块,它会进入一个循环,在每次迭代中它只生成序列中的下一个标记(词汇标记上的行概率向量)。然后将具有较高概率的所选标记再次输入为目标输入,因此 Transformer 始终根据其先前的预测来预测下一个标记(因此具有自回归意义)。但是在第一次迭代时输入的第一个标记应该是什么?
还记得 NLP 简介部分的特殊标记吗?作为目标输入引入的第一个元素是标记句子开头的开始标记 。
总结
这部分介绍了更好地理解 Transformers 模型所必需的第一个概念和概念。在下一部分中,我将深入研究大部分数学所在的 Transformers 架构的每个模块。
本文背后的主要思想和概念是:
-
转换器在嵌入系统定义的归一化向量空间中工作,其中每个维度代表标记之间的特征。 -
Transformers 输入是形状为 [N, L, E] 的张量,其中 N 表示批量大小,L 是序列长度(由于填充,每个序列都是常数),E 表示嵌入维度。 -
当编码器在源嵌入空间中寻找标记之间的关系时,解码器的任务是学习从源空间到目标空间的投影。 -
Transformer 的输出是一个线向量,其长度等于词汇表的大小,其中每个系数代表相应索引标记被放置在序列中下一个的概率。 -
在训练期间,Transformer 一次处理所有输入,输出一个 [N, L, V] 张量(V 是词汇表长度)。但是在预测过程中,Transformer是自回归的,总是根据他们之前的预测逐个标记地预测。
Reference
Source: https://towardsdatascience.com/transformers-in-depth-part-1-introduction-to-transformer-models-in-5-minutes-ad25da6d3cca
本文由 mdnice 多平台发布