二叉树
递归算法的关键要明确函数的定义,相信这个定义,而不要跳进递归细节。
写二叉树的算法题,都是基于递归框架的,我们先要搞清楚
root节点它自己要做什么,然后根据题目要求选择使用前序,中序,后续的递归框架。二叉树题目的难点在于如何通过题目的要求思考出每一个节点需要做什么,这个只能通过多刷题进行练习了。
二叉树遍历框架:
/* 二叉树遍历框架 */
void traverse(TreeNode root) {
// 前序遍历
traverse(root.left)
// 中序遍历
traverse(root.right)
// 后序遍历
}
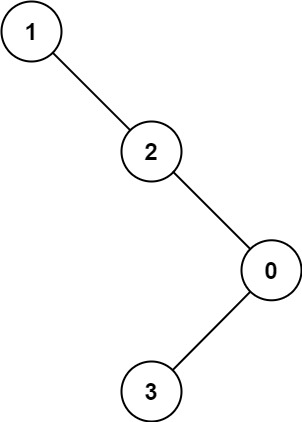
1,2,3,4,5,6,7
前序遍历:先输出父节点,再遍历左子树和右子树。1, 2, 4, 5, 3, 6, 7
中序遍历:先遍历左子树,在输出父节点,再遍历右子树。4, 2, 5, 1, 6, 3, 7
后序遍历:先遍历左子树,再遍历右子树,最后输出父节点。4, 5, 2, 6, 7, 3, 1
镜像翻转二叉树
剑指 Offer 27. 二叉树的镜像
这个函数的定义就是给我一个节点,我把他的左右子节点翻转
只去想一个节点翻转需要怎么做,这是一个二叉树的前序遍历
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return root;
}
//翻转
TreeNode tempNode = root.left;
root.left = root.right;
root.right = tempNode;
//子节点也去翻转
invertTree(root.left);
invertTree(root.right);
return root;
}
116. 填充每个节点的下一个右侧节点指针
我辅助函数定义就是将你传给我的两个节点,进行连接。
采用前序遍历,然后需要把这两个节点各自的左右节点连接&&这一个节点的左和一个节点的有连接。
// 主函数
Node connect(Node root) {
if (root == null) return null;
connectTwoNode(root.left, root.right);
return root;
}
// 辅助函数
void connectTwoNode(Node node1, Node node2) {
if (node1 == null || node2 == null) {
return;
}
/**** 前序遍历位置 ****/
// 将传入的两个节点连接
node1.next = node2;
// 连接相同父节点的两个子节点
connectTwoNode(node1.left, node1.right);
connectTwoNode(node2.left, node2.right);
// 连接跨越父节点的两个子节点
connectTwoNode(node1.right, node2.left);
}
114. 二叉树展开为链表
这个函数的定义是:以传给我的头节点的二叉树拉平成一个链表。
进行后序遍历
具体:把他的左右先进行拉平,然后把左树当做右树,左边为null,最后把原来的右树放到现在右树的下面。
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode root) {
// base case
if (root == null) return;
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
654. 最大二叉树
test函数的定义:返回给定的数组中的最大值new出的节点。
采用前序遍历,
public TreeNode constructMaximumBinaryTree(int[] nums) {
return test(nums, 0, nums.length - 1);
}
public TreeNode test(int[] nums, int start, int end){
if (start > end) {
return null;
}
int index = start;
int max = nums[start];
for (int i = start + 1; i <= end; i++) {
if (max < nums[i]) {
max = nums[i];
index = i;
}
}
TreeNode node = new TreeNode(max);
node.left = test(nums, start, index - 1);
node.right = test(nums, index +1, end);
return node;
}
105. 从前序与中序遍历序列构造二叉树
辅助函数的定义:通过给定的前序,中序数组找到根节点。
流程:根据前序遍历可以知道,根节点就是前序遍历的首位,根节点的下一位就是前序遍历数组的下一位,在通过中序遍历数组就可以确定是左右哪个节点。然后分开去求左右子树。
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
return test(preorder, 0, preorder.length -1 , inorder, 0 , inorder.length-1);
}
public TreeNode test(int[] preorder,int prestart, int preend, int[] inorder, int instart, int inend) {
if (prestart > preend) {
return null;
}
int index = 0;
for (int i = instart; i <= inend; i++) {
if (preorder[prestart] == inorder[i]) {
index = i;
break;
}
}
TreeNode node = new TreeNode(preorder[prestart]);
int size = index - instart;
node.left = test(preorder, prestart + 1, size + prestart, inorder, instart, index -1);
node.right = test(preorder, size +prestart + 1, preend, inorder, index + 1, inend);
return node;
}
}
106. 从中序与后序遍历序列构造二叉树
和上一题原理相同。
根节点的遍历从后序遍历的末尾开始。
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
return build(inorder, 0, inorder.length-1, postorder, postorder.length - 1, 0);
}
public TreeNode build(int[] inorder,int instart, int inend, int[] postorder, int postend, int poststart) {
if (postend < poststart) {
return null;
}
int index = 0;
for (int i = 0; i < inorder.length; i++) {
if (postorder[postend] == inorder[i]) {
index = i;
break;
}
}
int size = index - instart;
TreeNode node = new TreeNode(postorder[postend]);
node.left = build(inorder, instart, index - 1, postorder, poststart + size-1, poststart);
node.right = build(inorder, index + 1, inend, postorder, postend - 1, poststart +size);
return node;
}
}
652. 寻找重复的子树
思考:我想要查看有没有重复的子树,首先我要获取到所有的子树,在获取的途中,进行查看是否已经获取过了,获取过了我就放到集合里。
如何获取一个子树呢?
获取自己下面的所有节点,在加上自己不就是一个子树了(所以用后序遍历)。然后放到集合里。
怎样把一个子树串联起来呢,->序列化,用字符串拼接。
class Solution {
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
if (root == null) {
return null;
}
findMap(root);
return list;
}
Map<String, Integer> map = new HashMap<>();
List<TreeNode> list = new ArrayList<>();
public String findMap(TreeNode root){
if (root == null) {
return "#";
}
String s1 = findMap(root.left);
String s2 = findMap(root.right);
String s = root.val+"," + s1+"," + s2;
if (map.containsKey(s)) {
if (map.get(s) == 1) {
list.add(root);
}
map.put(s, map.get(s) + 1);
}else {
map.put(s, 1);
}
return s;
}
}
难理解236. 二叉树的最近公共祖先
遇到任何递归型的问题,无非就是灵魂三问:
1、这个函数是干嘛的?
2、这个函数参数中的变量是什么的是什么?
3、得到函数的递归结果,你应该干什么?
TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// base case
if (root == null) return null;
if (root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 情况 1
if (left != null && right != null) {
return root;
}
// 情况 2
if (left == null && right == null) {
return null;
}
// 情况 3
return left == null ? right : left;
}
有点难理解。。。
计算二叉树的总节点数(三种 )
/**
* 普通二叉树计算节点总数
* @param node
* @return
*/
public static int getCount1(TreeNode node) {
if (node == null) {
return 0;
}
return 1 + getCount1(node.left) + getCount1(node.right);
}
/**
* 满二叉树计算节点总数, 满二叉树就是每一层的节点数都是满的
* @param node
* @return
*/
public static int getCount2(TreeNode node) {
int high = 0;
while (node != null) {
high ++;
node = node.left;
}
return (int)Math.pow(2, high) - 1;
}
/**
* 计算完全二叉树的节点总数
* @param node
* @return
*/
public static int getCount3(TreeNode node) {
TreeNode lNode = node;
TreeNode rNode = node;
int l = 0;
while (lNode != null) {
l ++;
lNode = lNode.left;
}
int r = 0;
while (rNode != null) {
l ++;
rNode = rNode.left;
}
if (l == r) {
return (int)Math.pow(2, l) - 1;
}
return 1+getCount3(node.left) + getCount3(node.right);
}
二叉搜索树
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)。如果先进行右边的递归,就会是降序。(例题:寻找第k小的值,转化为累加树)
二叉搜索树衍生框架:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
98. 验证二叉搜索树
因为只有一个根节点只能判断左右孩子的是否符合,所以需要一个辅助函数。
辅助函数定义:验证当前节点是否是大于min小于max。
public boolean isValidBST(TreeNode root) {
return judge(root, null, null);
}
/**
* 要求:max.min > root.val > min.val
* @param root
* @param min
* @param max
* @return
*/
public boolean judge(TreeNode root, TreeNode min, TreeNode max) {
if (root == null) {
return true;
}
if (min != null && min.val >= root.val) {
return false;
}
if (max != null && max.val <= root.val) {
return false;
}
return judge(root.left, min, root) && judge(root.right, root, max);
}
450. 删除二叉搜索树中的节点
删除分为三种情况,1,要删除的节点是末尾节点。2,只有一个非空节点,3,有两个孩子。分别讨论。
第三种情况的时候:先找到要删除节点的右子树的最小值,记录下值,然后删掉,然后把值给要删除的节点。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) {
return null;
}
if (root.val == key) {
//删除 分为两种删除,在末尾直接删除,在中间(左右都存在和存在一个孩子)就要判断了
if (root.left == null && root.right == null) {
return null;
}
if (root.left == null || root.right == null) {
if (root.left == null) {
return root.right;
}else {
return root.left;
}
}
//左右孩子都存在
//首先找到右子树中最小的节点
TreeNode minNode = getMin(root.right);
//删除最小的节点
root.right = deleteNode1(root.right, minNode.val);
root.val = minNode.val;
}else if(root.val > key) {
root.left = deleteNode(root.left, key);
}else {
root.right = deleteNode(root.right, key);
}
return root;
}
public TreeNode getMin(TreeNode node) {
if (node.left == null) {
return node;
}
return getMin(node.left);
}
public TreeNode deleteNode1(TreeNode node, int val) {
if (node == null) {
return null;
}
if (node.val == val) {
if (node.right != null) {
return node.right;
}
return null;
}else if(node.val > val) {
node.left = deleteNode1(node.left, val);
}
return node;
}
}
剑指 Offer 36. 二叉搜索树与双向链表
说明:使用辅助指针记录上一个节点和头结点。
class Solution {
Node pre,head;
public Node treeToDoublyList(Node root) {
if(root == null){
return null;
}
dfs(root);
head.left = pre;
pre.right = head;
return head;
}
private void dfs(Node root) {
if(root == null){
return;
}
dfs(root.left);
if (pre == null){
head = root;
}else{
pre.right = root;
}
root.left = pre;
pre = root;
dfs(root.right);
}
}
二叉树的序列化
前序遍历实现
先进行序列化,然后在反序列化
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if (root == null) {
return "#";
}
String str = root.val+",";
String left = serialize(root.left);
String right = serialize(root.right);
str = str + left + "," + right;
return str;
}
// Decodes your encoded data to tree.
LinkedList<Integer> linkedList = new LinkedList<>();
public TreeNode deserialize(String data) {
String[] arr = data.split(",");
for (String string : arr) {
if (string.equals("#")) {
linkedList.add(null);
}else {
linkedList.add(Integer.parseInt(string));
}
}
return getTreeNode();
}
public TreeNode getTreeNode() {
if (linkedList.isEmpty()) {
return null;
}
Integer numInteger = linkedList.removeFirst();
if (numInteger == null) {
return null;
}
TreeNode rootNode = new TreeNode(numInteger);
rootNode.left = getTreeNode();
rootNode.right = getTreeNode();
return rootNode;
}
}
后序遍历实现道理相同,就不写代码了。
中序遍历可以序列化,但是序列化后的字符串不能反序列化。
层级遍历实现
层序遍历的代码框架
void traverse(TreeNode root) {
if (root == null) return;
// 初始化队列,将 root 加入队列
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
while (!q.isEmpty()) {
TreeNode cur = q.poll();
/* 层级遍历代码位置 */
System.out.println(root.val);
/*****************/
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
}
用层序遍历实现序列化:
public static String serialize(TreeNode root) {
if (root == null) {
return "#";
}
String str = "";
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode curNode = queue.poll();
if (curNode == null) {
str += "#,";
continue;
}
str += curNode.val + ",";
queue.offer(curNode.left);
queue.offer(curNode.right);
}
return str;
}
反序列化实现需要使用两个队列
static LinkedList<TreeNode> linkedList = new LinkedList<>();
public static TreeNode deserialize(String data) {
String[] arr = data.split(",");
for (String string : arr) {
if (string.equals("#")) {
linkedList.add(null);
}else {
linkedList.add(new TreeNode(Integer.parseInt(string)));
}
}
return getTreeNode();
}
public static TreeNode getTreeNode() {
Queue<TreeNode> queue1 = new LinkedList<>();
TreeNode node = linkedList.poll();
queue1.offer(node);
while (!queue1.isEmpty()) {
TreeNode root = queue1.poll();
root.left = linkedList.poll();
root.right = linkedList.poll();
if (root.left != null) {
queue1.offer(root.left);
}
if (root.right != null) {
queue1.offer(root.right);
}
}
return node;
}
N叉树
class NestedInteger {
Integer val;
List<NestedInteger> list;
}
/* 基本的 N 叉树节点 */
class TreeNode {
int val;
TreeNode[] children;
}
n叉树遍历框架
void traverse(TreeNode root) {
for (TreeNode child : root.children)
traverse(child);
341. 扁平化嵌套列表迭代器
解析地址
赫夫曼树
概念
给定n个权值作为n个叶子结点,构造一颗二叉树,若该树的带权路径长度(wpl达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。
赫夫曼树是带权路径长度最短的树,权值较大的节点离根较近。
路径和路径长度:在一棵数中,从一个节点往下可以达到的孩子或孙子节点之间的通路,称为路径。通路中分支的数目称为路径长度,若规定根节点的层数为1,则从根节点到第L层节点的路径长度为L-1;
节点的权和带权路径长度:若将树中节点赋给一个有着某种含义的数值,则这个数值称为该节点的权,节点的带权路径长度为:从根节点到改节点之间的路径长度与该节点的权的乘积。
树的带权路径长度:树的带权路径长度是所有叶子结点的带权路径长度之和,记为wpl,权值越大的节点离根节点越近的二叉树才是最优二叉树。wpl最小的就是赫夫曼树。
节点的带权路径之和就是该树的带权路径长度wpl。
构键赫夫曼树代码:

/**
* 构建赫夫曼树
* @param arr 要构建的赫夫曼树的叶子结点的权值数组
* @return 返回赫夫曼树的头结点
*/
public static TreeNode createHuffmanTree(int[] arr){
List<TreeNode> nodes = new ArrayList<>();
for (int i : arr) {
nodes.add(new TreeNode(i));
}
while (nodes.size() > 1){
//1,排序从小到大
nodes.sort(Comparator.comparingInt(x -> x.val));
//取出根节点最小的两颗树
TreeNode left = nodes.get(0);
TreeNode right = nodes.get(1);
//构建一个新的二叉树
TreeNode parent = new TreeNode(left.val + right.val);
parent.left = left;
parent.right = right;
//从list中删除处理过的二叉树
nodes.remove(left);
nodes.remove(right);
//将parent放入list中
nodes.add(parent);
}
System.out.println(nodes);
return nodes.get(0);
}
//输入:{32,2,42}
//结果:
/**
76
34 42
2 32
*/
赫夫曼编码
概念
赫夫曼编码也称 哈夫曼编码,又称霍夫曼编码,是一种编码方式,属于一种程序算法。
赫夫曼编码是赫夫曼树在电讯通信中的经典应用之一。
赫夫曼编码广泛的用于数据文件压缩,压缩率在20%-90%之间
赫夫曼码是可变字长编码(VLC)的一种。
彩蛋
加入我的知识星球,加入自学编程者的聚集地。