Ceph如何扩展到超过十亿个对象?-ceph部署多少个节点 (51cto.com)
越来越多的组织被要求管理数十亿个文件和几百上千PB的数据。无论是在公共云还是本地环境中,Ceph对象存储都是值得考虑的一个选项。本篇文章将通过七部分的精选内容为下面这些问题提供答案。
越来越多的组织被要求管理数十亿个文件和几百上千PB的数据。无论是在公共云还是本地环境中,Ceph对象存储都是值得考虑的一个选项。本篇文章将通过七部分的精选内容为下面这些问题提供答案。
- 每个RGW实例的最佳CPU /线程分配比率是多少?
- 建议的Rados网关(RGW)部署策略是什么?
- 固定大小的群集的最大性能是什么?
- 当集群接近10亿个对象时,集群性能和稳定性会受到哪些影响?
- 存储桶分片如何提高存储桶的可伸缩性,以及对性能有何影响?
- RGW的新Beast前端与Civetweb相比如何?
- RHCS 2.0 FileStore和RHCS 3.3 BlueStore之间的性能差异是多少?
- EC Fast_Read与常规读取的性能影响?
1、构建健壮的对象存储基础架构
本部分主要介绍如何结合使用Red Hat Ceph Storage,Dell EMC存储服务器和网络来构建健壮的对象存储基础架构。
环境搭建
本环境是Dell EMC实验室中使用其硬件以及英特尔提供的硬件进行的
硬件配置
正在上传…重新上传取消
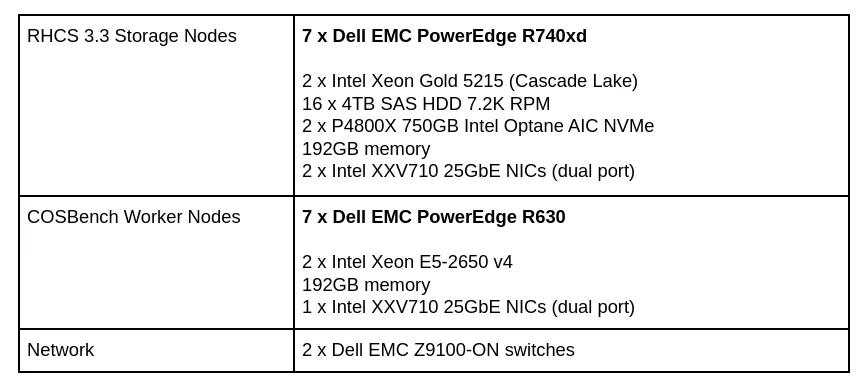
表1:硬件配置
正在上传…重新上传取消
表2:软件配置
正在上传…重新上传取消
表3:资源限制
机架设计
正在上传…重新上传取消
图1:实验室机架设计
正在上传…重新上传取消
图2:测试实验室逻辑设计
有效负载选择
对象存储的有效负载差异很大,有效负载大小是设计基准测试用例时的关键考虑因素。在理想的基准测试用例中,有效负载大小应代表实际的应用程序工作负载。与通常只读取或写入几千字节的块存储工作负载测试不同,其中对象存储工作负载进行测试需要涵盖各种有效负载大小。以下是本次实验对象有效负载的大小。
正在上传…重新上传取消
表4:经过测试的有效负载
数据处理应用程序倾向于在较大的文件上运行,根据我们的测试,我们发现32MB是COSBench在我们的测试范围内可以可靠处理的最大对象大小。
执行摘要
红帽Ceph Storage能够在多种行业标准的硬件配置上运行。对于那些不熟悉系统硬件和Ceph软件组件的人来说,这种灵活性可能会令人生畏。设计和优化Ceph集群需要仔细分析应用程序,它们所需的容量和工作负载配置文件。红帽Ceph存储集群通常在多租户环境中使用,承受着各种各样的工作负载。红帽,戴尔EMC和英特尔精心挑选了我们认为会对性能产生深远影响的系统组件。测试评估了三大类的工作负载:
- 大对象工作负载(吞吐量)
红帽测试显示,通过添加Rados Gateway(RGW)实例,可以实现读写吞吐量的近乎线性的可扩展性,直到由于OSD节点磁盘争用而达到峰值为止。因此,我们为读写工作负载测量了超过6GB/s的聚合带宽。
- 小对象工作负载(每秒操作数)
与大对象工作负载相比,元数据I/O对小对象工作负载的影响更大。客户端写操作按次线性扩展,最高为6.3K OPS,平均响应时间为8.8 ms,直到被OSD节点磁盘争用饱和为止。客户端读取操作达到3.9K OPS,这可能是由于BlueStore OSD后端缺少Linux页面缓存所致。
- 对象数量更多的工作负载(十亿个对象或更多)
随着存储桶中对象总数的增长,需要管理的索引元数据的数量也相应增加。索引元数据分布在许多分片上,以确保可以有效地访问它。当存储桶中的对象数量大于使用当前分片数量可以有效管理的数量时,Red Hat Ceph Storage将动态增加分片数量。在我们的测试过程中,我们发现动态分片事件对目的地为动态分片的存储桶的请求的吞吐量具有短暂有害的影响。如果开发人员具有将存储桶增长到给定数量的经验知识,则可以创建该存储桶或将其手动更新为能够有效容纳元数据量的多个分片。
在大型和小型对象大小的工作负载测试中,相对于以前的性能和规模分析,Red Hat Ceph Storage都显著提高了性能。我们认为,这些改进可以归因于BlueStore OSD后端,RGW的新Beast Web前端,BlueStore WAL和block.db使用Intel Optane SSD以及Intel Cascade Lake提供的最新一代处理能力的结合处理器。
体系结构
正在上传…重新上传取消
表5:体系结构摘要
Ceph基准性能测试
为了记录本机Ceph集群的性能,我们使用了Ceph基准测试工具(CBT),一种用于自动化Ceph群集基准测试的开源工具。目的是找到集群总吞吐量的高水位线。该水位线是吞吐量保持不变或降低的点。
使用Ceph-Ansible playbook部署了Ceph集群。Ceph-Ansible使用默认设置创建一个Ceph集群。因此,基线测试是使用默认的Ceph配置完成的,没有进行任何特殊调整。使用CBT,每个基准场景运行了7次迭代。第一次迭代从单个客户端执行基准测试,第二次从两个客户端执行基准测试,第三次从三个客户端并行执行,以此类推等等。
使用了以下CBT配置:
- 工作量:顺序写测试,然后顺序读测试
- 块大小:4MB
- 片长:300秒
- 每个客户端的并发线程数:128
- 每个客户端的RADOS基准实例:1
- 池数据保护:Ec 4 + 2删除或3x复制
- 客户总数:7
如表1和表2所示,随着客户端数量的增加,写入和读取工作负载的性能都呈线性下降。有趣的是,使用擦除编码数据保护方案的配置为读写吞吐量提供了几乎对称的8.4GBps。在以前的研究中没有观察到这种对称性,我们认为这可以归因于BlueStore和Intel Optane SSD的组合。在任何RADOS基准测试中,我们都无法确定任何系统级资源饱和。如果有其他客户端节点可用来进一步给现有群集施加压力,我们可能会观察到更高的性能,并有可能使基础存储介质饱和。
正在上传…重新上传取消
图1:Radosbench 100%写入测试
正在上传…重新上传取消
图2:Radosbench 100%读取测试
总结
在本文中,我们详细介绍了实验室体系结构,包括硬件和软件配置,分享了来自基础集群基准测试的一些结果,并提供了高级执行和体系结构的相关摘要。
2、Ceph RGW 部署策略和大小调整
从Red Hat Ceph Storage 3.0开始,Red Hat添加了对容器化存储守护程序(CSD)的支持,该支持使软件定义的存储组件(Ceph MON,OSD,MGR,RGW等)可以在容器中运行。CSD避免了具有专用于存储服务的节点的需求,因此通过并置存储容器化守护进程减少了CAPEX和OPEX。
Ceph-Ansible提供了将资源防护放入每个存储容器的必需机制,这对于在一个物理节点上运行多个存储守护程序容器很有用。在这部分内容中,我们将介绍部署RGW容器的策略及其资源调整指南。在探讨性能之前,让我们了解部署RGW的不同方法是什么。
并置的RGW
- 不需要用于RGW的专用节点(可以减少CAPEX和OPEX)。
- Ceph RGW容器的单个实例放置在与其他存储容器共存的存储节点上。
- 从Ceph Storage 3.0开始,这是部署RGW的首选方法。
正在上传…重新上传取消
图1:共同驻留的RGW部署策略
多主机RGW
- 不需要用于RGW的专用节点(可以帮助减少CAPEX和OPEX)。
- 与其他存储容器共存的多个Ceph RGW实例(每个存储节点当前测试2个实例)。
- 我们的测试表明,该选项可提供最高的性能,而不会产生额外的开销。
正在上传…重新上传取消
图2:多个共存(2个RGW实例)部署策略
独立RGW
- 需要用于RGW的专用节点。
- Ceph RGW组件被部署在专用的物理/虚拟节点上。
- 从Ceph Storage 3.0开始,这不再是部署RGW的首选方法。
正在上传…重新上传取消
图3:独立的RGW部署策略
表现摘要
(一)RGW部署和规模调整指南
在上一节中,我们研究了部署Ceph RGW的不同方法。我们将比较每种方法之间的性能差异。为了评估性能,我们通过调节RGW部署策略以及跨不同的读写和工作负载的RGW CPU内核数执行了多个测试。结果如下。
100%写入工作量
如图1和图2所示
- 并置(1x)RGW实例在小型和大型对象方面均优于独立RGW部署。
- 同样,多个共存(2x)RGW实例的性能优于共存(1x)RGW实例的部署。这样,多个共存(2x)RGW实例分别为小型和大型对象提供了 2328 Ops和1879 MBps的性能。
- 在多个测试中,发现 4 CPU Core / RGW实例是CPU资源与RGW实例之间的最佳比率。向RGW实例分配更多的CPU内核并不能提供更高的性能
正在上传…重新上传取消
图表1:小对象100%写测试
正在上传…重新上传取消
图表2:大对象100%写测试
100%读取工作负载性能
有趣的是,对于读取工作负载,每个RGW实例增加的CPU核心数量并不能提高不同大小对象的性能。因此,每个RGW实例1个CPU内核的结果与每个RGW实例10个CPU内核的结果几乎相似。
实际上,根据我们之前的测试,我们观察到类似的结果,即读取工作负载不会消耗大量CPU,这可能是因为Ceph使用了系统擦除编码,并且在读取过程中不需要解码块。因此,我们发现如果RGW工作负载是读取密集型的,则过度分配CPU并没有帮助。
比较独立RGW与共置(1x)RGW测试的结果非常相似。但是,仅添加一个并置的RGW(2x),在小对象的情况下,性能提高了约200%,在大对象的情况下,性能提高了约90%。
这样,如果工作负载是读取密集型的,则运行多个并置(2x)RGW实例可以显著提高整体读取性能。
正在上传…重新上传取消
图表3:小对象100%读取测试
正在上传…重新上传取消
图4:大对象100%读取测试
(二)RGW线程池大小调整准则
在决定将CPU内核分配给RGW实例时,非常相关的RGW调整参数之一rgw_thread_pool_size是负责由Beast生成的与HTTP请求相对应的线程数。这有效地限制了Beast前端可以服务的并发连接数。
为了确定此可调参数最合适的值,我们通过更改rgw_thread_pool_sizeRGW实例的CPU核心计数和CPU计数一起进行了测试。如图5和6所示,我们发现设置rgw_thread_pool_size为512可以在4个CPU内核预RGW实例上实现最高性能。同时增加CPU核心数rgw_thread_pool_size并没有任何改善。
我们确实承认,如果我们进行多轮rgw_thread_pool_size低于512 的测试,则本测试会更好。我们的假设是,由于Beast Web服务器基于异步c10k Web服务器,因此不需要每连接一个线程,因此应该在较低的线程上表现良好。不幸的是,我们无法测试,但将来会尝试解决这个问题。
因此,这样的多并置(2x)RGW实例(每个RGW实例具有4个CPU内核)和设置rgw_thread_pool_size为512个可以提供最大的性能。
正在上传…重新上传取消
图5:小对象100%写入测试
正在上传…重新上传取消
图6:大对象100%写入测试
总结
在这篇文章中,我们了解到,多并置(2x)RGW实例,每个RGW实例具有4个CPU核心,每个实例rgw_thread_pool_size有512个,可在不增加整体硬件成本的情况下提供最佳性能。
3、从ceph集群中获得最大性能
我们已经测试了各种配置,对象大小和客户端数量,以便针对小型和大型对象工作负载最大化七个节点的Ceph集群的吞吐量。如第一篇文章中所述,Ceph集群是使用每个HDD配置的单个OSD(对象存储设备)构建的,每个Ceph集群总共有112个OSD。在本文中,我们将了解不同对象大小和工作负载的顶级性能。
注意:在本文中,术语“读取”和HTTP GET可以互换使用,术语HTTP PUT和“写入”也可以互换使用。
大对象工作量
大对象顺序输入/输出(I / O)工作负载是Ceph对象存储最常见的用例之一。这些高吞吐量的工作负载包括大数据分析、备份和档案系统、图像存储以及流音频和视频。对于这些类型的工作负载,吞吐量(MB / s或GB / s)是定义存储性能的关键指标。
如图1所示,当增加RGW主机的数量时,大对象100%HTTP GET和HTTP PUT工作负载表现出亚线性可伸缩性。因此,我们为HTTP GET和HTTP PUT工作负载测量了约5.5 GBps的聚合带宽,有趣的是,我们没有注意到Ceph集群节点中的资源饱和。
如果我们可以将更多负载分配给该群集,则它可以产生更多的负载。因此,我们确定了两种方法。1)添加更多的客户端节点 2)添加更多的RGW节点。我们不能选择选项1,因为我们受此实验中可用的物理客户端节点的限制。因此,我们选择了选项2,并进行了另一轮测试,但这次有14个RGW。
如图2所示,与7个 RGW测试相比,14 RGW测试的写入性能提高了 14%,最高达到了6.3GBps,类似地,HTTP GET工作负载显示的读取性能提高了16%,最高达到6.5GBps。这是在此群集上观察到的最大聚合吞吐量,此后如图1所示,注意到了设备(HDD)饱和。根据结果,我们相信,如果我们向该集群添加了更多的Ceph OSD节点,则性能可能会进一步扩展,直到受到资源饱和的限制。
正在上传…重新上传取消
图1:大对象测试
正在上传…重新上传取消
图2:具有14个RGW的大型对象测试
正在上传…重新上传取消
图1:Ceph OSD(HDD)媒体利用率
小对象工作量
如图3所示,当增加RGW主机的数量时,小型对象100%HTTP GET和HTTP PUT工作负载表现出次线性可伸缩性。因此,我们测量了9ms应用程序写入延迟时HTTP PUT的6.2K Ops吞吐量,以及具有7个RGW实例的HTTP GET工作负载的3.2K Ops吞吐量。
直到7个RGW实例,我们才注意到资源饱和,因此我们将RGW实例扩展到14个,从而使RGW实例增加了一倍,并观察到HTTP PUT工作负载的性能下降,这归因于设备饱和,而HTTP GET性能则向上扩展并达到4.5万个,如果我们添加更多的Ceph OSD节点,写性能可能会更高。就读取性能而言,我们认为添加更多的客户端节点应该可以改善读取性能,但是我们在实验室中没有更多的物理节点可以验证这一假设。
从图3中可以看到的另一个有趣的观察结果是HTTP PUT工作负载的平均响应时间减少了9ms,而HTTP GET显示了从应用程序生成工作负载测得的平均延迟为17ms。我们认为,导致写入工作负载出现个位数的应用程序延迟的原因之一是BlueStore OSD后端的性能提高以及用于支持BlueStore元数据设备的高性能Intel Optane NVMe的结合。值得注意的是,从对象存储系统中实现一位数的写入平均延迟并非易事。如图3所示,将Ceph对象存储与BlueStore OSD后端和Intel Optane用于元数据一起部署时,可以在较低的响应时间实现写入吞吐量。
正在上传…重新上传取消
图3:小对象测试
总结
此测试中使用的固定大小群集分别为写入和读取工作负载提供了约6.3GBps和约6.5GBps的大对象带宽。相同的小对象集群分别为读写工作量提供了约6.5K Ops和约4.5K Ops。
结果还表明,BlueStore OSD与Intel Optane NVMe的结合使用实现了平均应用程序延迟个位数的好成绩,这对于对象存储系统而言是非常重要的。
4、RGW存储桶分片策略及其性能影响
在有关Ceph性能的系列文章的第4部分中,我们介绍了RGW存储桶分片策略及其性能影响。
Ceph RGW为每个存储桶维护一个索引,该索引保存存储桶包含的所有对象的元数据。RGW需要索引才能在请求时提供此元数据。例如,列出存储桶内容会拉出存储的元数据,维护用于对象版本控制、存储桶配额、多区域同步元数据等的日志。因此,概括地说,存储桶索引存储了一些有用的信息。存储区索引不会影响对对象的读取操作,但是会在写入和修改RGW对象时添加额外的操作。
大规模编写和修改存储桶索引具有某些含义。首先,可以存储在单个存储桶索引对象上的数据量有限,这是因为用于存储桶索引对象的基础RADOS对象键值接口不是无限的,并且默认情况下每个存储桶仅使用一个RADOS对象。其次,大索引对象可能会导致性能瓶颈,因为对已填充存储桶的所有写操作最终都会修改支持该存储桶索引的单个RADOS对象。
为了解决与非常大的存储桶索引对象相关的问题,RHCS 2.0中引入了存储桶索引分片功能。这样,每个存储桶索引现在都可以分布在多个RADOS对象上,通过允许存储桶可以容纳的对象数量与索引对象(碎片)的数量成比例,可以扩展存储桶索引元数据。
但是,此功能仅限于新创建的存储桶,并且需要对未来的存储桶对象进行预先规划。为了缓解此存储桶重新分片可以使用管理员命令,该命令可帮助修改现有存储桶的存储桶索引分片数量。但是,使用这种手动方法,通常会在群集中执行存储区重新分片看到性能下降的症状。同样,手动重新分片要求在重新分片过程中停止对存储区的写操作。
动态存储分区重新分片的意义
RHCS 3.0引入了动态存储区重新分片功能。利用此功能,存储桶索引现在将随着存储桶中对象数的增加而自动重新分片。重新分片发生时,您无需停止在存储桶中读取或写入对象。动态重新分片是RGW的本机功能,如果该存储桶中的对象数量超过100K,则RGW会自动识别需要重新分片的存储桶,RGW通过产生一个负责处理已调度的特殊线程来为该存储桶调度重新分片操作。动态重新分片现在是默认功能,管理员无需采取任何措施即可激活它。
在本文中,我们将深入探讨与动态重新分片功能相关的性能,并了解如何使用预分片的存储区将其中的某些内容最小化。
测试方法
为了研究在单个存储桶中存储大量对象以及动态存储桶重新分片所带来的性能影响,我们特意为每种测试类型使用单个存储桶。同样,使用默认的RHCS 3.3调整创建了存储桶。测试包括两种类型:
- 动态存储桶重新分片测试,单个存储桶最多可存储3000万个对象
- 预先进行存储桶测试,其中存储了大约2亿个对象
对于每种类型的测试,COSBench测试分为50个回合,其中每个回合写入1小时,然后分别进行15分钟的读取和RWLD(70Read,20Write,5List,5Delete)操作。因此,在整个测试周期中,我们在两个存储桶中写入了约2.45亿个对象。
动态存储桶重新分片:性能洞察
如上所述,动态存储区重新分片是RHCS中的默认功能,当存储区中存储的对象数量超过某个阈值时,该功能会启动。图1显示了性能变化,同时不断向桶中填充物体。第一轮测试交付了约5.4K Ops,同时在被测试的存储桶中存储了约80万个对象。
随着测试轮的进行,我们不断在桶中装满物品。第44轮测试交付了约3.9K Ops,而存储桶中的对象数量达到了约3000万。随着对象计数的增加,存储区分片计数也从第1轮的16(默认)增加到第44轮的512。如图1所示,吞吐量Ops的突然下降很可能归因于存储桶上的RGW动态重新分片活动。
正在上传…重新上传取消
图1:RGW动态存储桶重新分片
预共享存储桶:性能洞察
带有一个过度填充的bucket的非确定性性能(图1)引导我们进入下一个测试类型,在将任何对象存储在bucket中之前,我们预先对其进行了分片。这一次,我们在这个预切分的bucket中存储了超过1.9亿个对象,我们测量了性能,如图2所示。因此,我们观察到预切分的桶性能稳定,但是,在测试的第14和28小时,性能突然下降了两次,这是由于RGW动态桶切分。
正在上传…重新上传取消
图2:预共享桶
图3显示了预分片存储桶和动态分片存储桶的性能对比。根据测试后存储区统计数据,我们认为这两个类别的性能突然下降是由动态重新分片事件引起的。
因此,预分片存储有助于实现确定性性能,因此从架构的角度来看,以下是一些指导:
如果知道应用程序的对象存储消耗模式,特别是每个存储桶的预期对象数(数量),在这种情况下,对存储桶进行预分片通常会有所帮助。
如果每个存储桶中要存储的对象数未知,则动态存储桶重新分片功能将自动完成该工作。但是,在重新分片时会消耗少量的性能。
我们的测试方法夸大了这些事件在集群级别的影响。在测试期间,每个客户端都向不同的存储区写入数据,并且每个客户端都倾向于以相似的速率写入对象。其结果是,客户端正在写入的存储桶以相似的时序超过了动态分片阈值。在现实环境中,动态分片事件更有可能在时间上得到更好的分布。
正在上传…重新上传取消
图表3:动态存储桶重新分片和预分片存储桶性能比较:100%写入
发现动态重新分片的存储桶的读取性能比预共享的存储桶略高,但是预分片的存储桶具有确定的性能,如图4所示。
正在上传…重新上传取消
图表4:动态存储桶重新分片和预分片存储桶性能比较:100%读取
总结
如果我们知道应用程序将在一个存储桶中存储多少个对象,则对存储桶进行预分片通常有助于提高整体性能。另一方面,如果事先不知道对象数,则Ceph RGW的动态存储桶重新分片功能确实有助于避免与过载存储桶相关的性能下降。
5、Ceph Bluestore的压缩机制及性能影响
通过BlueStore OSD后端,Red Hat Ceph Storage获得了一项称为“实时数据压缩”的新功能,该功能有助于节省磁盘空间。可以在BlueStore OSD上创建的每个Ceph池上启用或禁用压缩。除此之外,无论池中是否包含数据,均可使用Ceph CLI随时更改压缩算法和模式。在此博客中,我们将深入研究BlueStore的压缩机制,并了解其对性能的影响。
BlueStore中的数据是否被压缩取决于压缩模式和与写操作相关的任何提示的组合。BlueStore提供的不同压缩模式是:
- none:从不压缩数据。
- passive:除非写操作具有可压缩的提示集,否则不要压缩数据。
- aggressive:压缩数据,除非写操作具有不可压缩的提示集。
- force:无论如何都尝试压缩数据。即使客户端暗示数据不可压缩,在所有情况下都使用压缩。
可以通过每个池属性或全局配置选项来设置compression_mode,compression_algorithm,compression_required_ratio,compression_min-blob_size和compresion_max_blob_size参数。可以通过以下方式设置“pool”属性:
复制
ceph osd pool set <pool-name> compression_algorithm <algorithm>
ceph osd pool set <pool-name> compression_mode <mode>
ceph osd pool set <pool-name> compression_required_ratio <ratio>
ceph osd poll set <pool-name> compression_min_blob_size <size>
ceph osd pool set <pool-name> compression_max_blob_size <size>
Bluestore压缩内部构件
Bluestore不会压缩任何等于或小于min_alloc_size配置的写入。在具有默认值的部署中,SSD的min_alloc_size为16KiB,而HDD为64 KiB。在我们的案例中,我们使用的是全闪存(SSD)介质,IO大小小于32KiB的Ceph不会进行任何压缩尝试。
为了能够在较小的块大小下测试压缩性能,我们以4KiB的min_alloc_size重新部署了Ceph集群,通过对Ceph配置的修改,我们能够以8KiB块大小实现压缩。
请注意,从Ceph集群中的默认配置修改min_alloc_size会对性能产生影响。在我们将大小从16 KiB减小到4KiB的情况下,我们正在修改8KiB和16KiB块大小IO的数据路径,它们将不再是延迟写入并首先进入WAL设备,任何大于4KiB的块将直接写入OSD配置的块设备中。
Bluestore Compression配置和测试方法
为了了解BlueStore压缩的性能方面,我们进行了如下测试:
1.在Red Hat Openstack Platform 10上运行40个实例,每个实例附加一个Cinder卷(40xRBD卷)。然后,我们使用随附的Cinder卷创建并安装了XFS文件系统。
2.使用FIO libRBD IOengine进行84xRBD卷。
Pbench-Fio用作首选的基准测试工具,具有3个新的FIO参数(如下所示),以确保FIO在测试期间将生成可压缩的数据集。
复制
refill_buffers
buffer_compress_percentage=80
buffer_pattern=0xdeadface
- 1.
- 2.
- 3.
我们使用aggressive的压缩模式运行测试,以便我们压缩所有对象,除非客户端提示它们不可压缩。测试期间使用了以下Ceph bluestore压缩全局选项
复制
bluestore_compression_algorithm:snappy
bluestore_compression_mode:aggressive
bluestore_compression_required_ratio:.875
- 1.
- 2.
- 3.
bluestore_compression_required_ratio是此处的关键可调参数,其计算公式为
复制
bluestore_compression_required_ratio = size_compressed/siz_original
- 1.
默认值为0.875,这意味着如果压缩未将大小减小至少12.5%,则将不压缩对象。由于净增益低,高于此比率的对象将不会压缩存储。
要知道我们在FIO综合数据集测试期间实现的压缩量,我们使用了四个Ceph性能指标:
- Bluestore_compressed_original。被压缩的原始字节的总和。
- Bluestore_compressed_allocated。分配给压缩数据的字节总数。
- Compress_success_count。有益压缩操作的总和。
- Compress_rejected_count。压缩操作的总和因空间净增益低而被拒绝。
要查询上述性能指标的当前值,我们可以对正在运行的一个osd使用Ceph perf dump命令:
复制
ceph daemon osd.X perf dumo | grep -E'(compress _.* _ count | bluestore_compressed_)'
- 1.
在压缩基准测试期间从客户端测量的关键指标:
- IOPS。每秒完成的IO操作总数
- Average lantency。客户端完成IO操作所需的平均时间。
- P95%。延迟的95%。
- P99%。延迟的99%。
测试实验室配置
该测试实验室由5个RHCS全闪存(NVMe)服务器和7个客户端节点组成,详细的硬件和软件配置分别如表1和2所示。请参阅此博客文章,以获取有关实验室设置的更多详细信息。
正在上传…重新上传取消
正在上传…重新上传取消
小块:FIO综合基准测试
重要的是要考虑到,使用Bluestore压缩可以节省的空间完全取决于应用程序工作负载的可压缩性以及所使用的压缩模式。因此,对于8KB的块大小和40个带有主动压缩的RBD卷,我们已经实现了以下 compress_success_count和compress_rejected_count。
复制
“ compress_success_count”:48190908,
“ compress_rejected_count”:26669868,
- 1.
- 2.
在我们的数据集执行的74860776个写请求总数(8KB)中,我们能够成功压缩48190908个写请求,因此在我们的综合数据集中成功压缩的写请求百分比为64%。
查看 bluestore_compressed_allocated和bluestore_comprperformance计数器,我们可以看到通过Bluestore压缩,成功压缩的64%的写操作已转换为每个OSD节省60Gb的空间。
复制
“ bluestore_compressed_allocated”:60988112896
“ bluestore_compressed_original”:121976225792
- 1.
- 2.
如图1 /表1所示,在比较“积极压缩”与“不压缩”时,我们观察到IOPS百分比下降,这不是很明显。同时,发现平均和尾部潜伏期略高。造成这种性能负担的原因之一是,Ceph BlueStore压缩每个对象blob以匹配compression_required_ratio,然后将确认发送回客户端。结果,当压缩设置为激进时,我们看到IOPS略有降低,平均和尾部延迟增加。
正在上传…重新上传取消
图表1:FIO 100%写测试-40个RBD卷
正在上传…重新上传取消
如图2所示,我们尝试通过对主动压缩池和非压缩池中的84个RBD卷运行FIO来增加群集上的负载。我们观察到了类似的性能差异,如图1所示。与没有压缩相比,BlueStore压缩消耗了少许性能。实际上,任何声称提供动态压缩功能的存储系统都可以期望这一点。
正在上传…重新上传取消
图表2:FIO 100%随机读取/随机写入测试-84 RBD卷
压缩还具有与之相关的计算成本。数据压缩是通过诸如snappy和zstd之类的算法完成的,它们需要CPU周期来压缩原始blob并将其存储。如图3所示,块大小较小(8K)时,主动压缩和无压缩之间的CPU利用率增量较低。随着将块大小增加到16K / 32K / 1M,此增量也会增加。原因之一可能是,对于更大的块大小,压缩算法需要做更多的工作才能压缩blob和存储,从而导致更高的CPU消耗。
正在上传…重新上传取消
图表3:FIO 100%随机写入测试-84个RBD卷(IOPS与CPU%利用率)
大块(1MB):FIO综合基准测试
与小块大小相似,我们还测试了具有不同压缩模式的大块大小工作负载。因此,我们已经测试了侵略性(aggressive),强制性和非压缩性模式。如图4所示,攻击模式和强制模式的总吞吐量非常相似,我们没有观察到明显的性能差异。除了随机读取工作负载以外,在随机读写和随机写入模式下,压缩(积极/强制)与非压缩模式之间的性能差异很大。
正在上传…重新上传取消
图表4:FIO 1MB-40 RBD卷
为了确定系统上的更多负载,我们使用了libRBD FIO IO引擎并生成了84个RBD卷。该测试的性能如图5所示
正在上传…重新上传取消
图表5:FIO 1MB-84 RBD卷
MySQL数据库池上的Bluestore压缩
到目前为止,我们已经讨论了由PBench-Fio自动化的基于FIO的综合性能测试。为了了解BlueStore压缩在接近实际的生产工作负载中的性能含义,我们在压缩和未压缩的存储池上测试了多个MySQL数据库实例的性能。
MySQL测试方法
Bluestore的配置与之前的测试相同,使用的是快速算法和主动压缩模式。我们在OpenStack上部署了20个VM实例,这些实例托管在5个计算节点上。在这20个VM实例中,有10个VM用作MySQL数据库实例,而其余10个实例是MySQL数据库客户端,因此在数据库实例和DB客户端之间创建了1:1关系。
正在上传…重新上传取消
通过Cinder为10xMariadb服务器配置了1x100GB RBD卷,并将其安装在上/var/lib/mysql。dd在创建文件系统并将其安装之前,通过使用该工具写入完整的块设备来对该卷进行预处理 。
复制
/dev/mapper/APLIvg00-lv_mariadb_data 99G 8.6G 91G 9% /var/lib/mysql
- 1.
测试过程中使用的MariaDB配置文件在本要点中可用。数据集是使用以下sysbench命令在每个数据库上创建的。
复制
sysbench oltp_write_only --threads=64 --table_size=50000000 --mysql-host=$i --mysql-db=sysbench --mysql-user=sysbench --mysql-password=secret --db-driver=mysql --mysql_storage_engine=innodb prepare
- 1.
创建数据集后,运行以下三种类型的测试:
- 读
- 写
- 读_写
在每次测试之前,必须重新启动mariadb实例以清除innodb缓存,每个测试均在900秒内运行并重复2次,捕获的结果是两次运行的平均值。
MySQL测试结果
Bluestore压缩所能节省的空间完全取决于应用程序工作负载的可压缩性以及所使用的压缩模式。
通过Mysql压缩测试,结合了Sysbench生成的数据集和经过积极压缩的bluestore默认compression_required_ratio(0.875),我们获得了以下计数。
复制
compress_success_count:594148,
compress_rejected_count:1991191,
- 1.
- 2.
在我们的数据集中运行的2585339个写入请求总数中,我们能够成功压缩594148个写入请求,因此在Mysql Sysbench数据集中成功压缩的写入请求百分比为22%。
查看 bluestore_compressed_allocated和bluestore_compressed_original性能计数器,我们可以看到成功压缩的22%的写操作通过压缩转换为每个OSD节省了20Gb的空间。
复制
bluestore_compressed_allocated:200351744,
bluestore_compressed_original:400703488,
- 1.
- 2.
借助Ceph-metrics,我们在MySQL测试期间监视了OSD节点上的系统资源。发现OSD节点的平均cpu使用率低于14%,磁盘利用率低于9%范围,发现磁盘延迟平均低于2 ms,且峰值保持在个位数。
如图6所示,BlueStore压缩未严重影响每秒MySQL事务(TPS)。与不压缩TPS和事务延迟相比,BlueStore主动压缩确实表现出较小的性能负担。
正在上传…重新上传取消
图6:MySQL数据库池上的BlueStore压缩
重要要点
- 与非压缩池相比,启用了BlueStore压缩功能的池与基于FIO的综合工作负载相比,性能仅降低10%,而对MySQL数据库工作负载仅降低7%。这种减少归因于执行数据压缩的基础算法。
- 使用较小的块大小(8K),发现主动压缩和无压缩模式之间的CPU利用率增量较低。随着我们增加块大小(16K / 32K / 1M),此增量也会增加
- 低管理开销,同时在Ceph池上启用压缩。Ceph CLI开箱即用,提供了启用压缩所需的所有功能。
6、Ceph 3.3与2.2前后端对比
这篇文章是我们两年前基于Red Hat Ceph Storage 2.0 FileStore OSD后端和Civetweb RGW前端进行的对象存储性能测试的续篇。在本文中,我们将比较(撰写本文时)最新可用的 Ceph Storage的性能,即3.3版(BlueStore OSD后端和Beast RGW前端)与Ceph Storage 2.0版(2017年中)(FileStore OSD后端和Civetweb RGW前端)。
我们意识到,这两个性能研究的结果在科学上都不具有可比性。但是,我们认为,将两者进行比较应该可以为您提供重要的性能见解,并使您能够在架构Ceph存储群集时做出明智的决定。
正如预期的那样,在我们测试的所有工作负载中,Ceph Storage 3.3的性能均优于Ceph Storage 2.0。我们认为Ceph Storage 3.3的性能改进归因于几件事的结合。BlueStore OSD后端,RGW的Beast Web前端,BlueStore WAL使用的Intel Optane SSD,block.db和最新一代的Intel Cascade Lake处理器。
让我们仔细看一下两个Ceph Storage版本的性能比较。
测试实验室配置
这是我们实验室环境的简要介绍。测试是在Dell EMC实验室中使用其硬件以及英特尔提供的硬件进行的。
Ceph Storage 3.3环境
正在上传…重新上传取消
表1:Ceph Storage 3.3测试实验室配置
Ceph Storage 2.0环境
正在上传…重新上传取消
表2:Ceph Storage 2.0测试实验室配置
小对象性能
在本节中,我们将研究小型对象的性能。
小对象100%的写入工作量
图表1比较了Ceph Storage 3.3和Ceph Storage 2.0版本的小对象100%写入工作负载的性能。如图所示,与Ceph Storage 2.0相比,Ceph Storage 3.3始终提供更高的数量级每秒操作(Ops)性能。因此,我们发现Ceph Storage 3.3的操作数提高了500%以上。
您可能想知道,Ceph Storage 3.3性能线出现2倍性能急剧下降的原因是什么?据称是因为由RGW动态桶重新分片事件导致的(参考上文内容)。
正在上传…重新上传取消
图表1:小对象大小100%写性能
小对象100%读取工作负载
与Ceph Storage 2.0相比,Ceph Storage 3.3的100%读取工作负载显示出近乎完美的性能,而Ceph Storage 2.0的性能在大约第18小时的测试中直线下降。对于Ceph Storage 2.0,读取OPS的下降是由于随着群集对象数量的增加,文件系统元数据查找所花费的时间增加所致。
当群集中包含较少的对象时,内核会在内存中缓存更大比例的文件系统元数据。但是,当群集增长到数百万个对象时,缓存了较小百分比的元数据。然后,磁盘被迫执行专门用于元数据查找的I / O操作,从而增加了额外的磁盘搜索,并导致读取的OPS降低。
Ceph Storage 3.3及更高版本的Bluestore OSD后端在读取操作期间不依赖Linux页面缓存。这样,Bluestore OSD会执行自己的内存管理,因此有助于实现读取工作负载的确定性性能,如图2所示。
正在上传…重新上传取消
图表2:小型物件100%的读取效能
大对象性能
接下来,我们将注意力转向大型对象性能基准测试。
大对象100%的写入工作量
对于大对象100%写入测试,Ceph Storage 3.3提供了次线性性能改进,而Ceph Storage 2.0显示了逆向性能,如图3所示。在Ceph Storage 2.0测试期间,我们缺少附加的RGW节点,而Containerized Storage Daemon也没有一个选项。因此,对于Ceph Storage 2.0测试,我们无法测试超过4个RGW。
除非子系统资源饱和,否则Ceph Storage 3.3的写入带宽约为5.5 GBps。另一方面,Ceph Storage 2.0的性能却下降了。
正在上传…重新上传取消
图表3:大对象大小100%的写入性能
大对象100%读取工作负载
大对象100%的读取工作负载显示了Ceph Storage 2.0和3.3测试的次线性性能。如上一节所述,在Ceph Storage 2.0测试时,我们没有用于RGW的其他物理节点,因此我们被限制为4个,无法进一步扩展RGW。
Ceph Storage 3.3显示5.5 GBps 100%的读取带宽,在7个RGW的情况下未发现瓶颈。我们的假设是,如果我们添加更多的RGW,Ceph Storage 3.3可能会提供更多的带宽。图表4比较了100%大对象工作负载下Ceph Storage 3.3和Ceph Storage 2.2的性能。
正在上传…重新上传取消
图4:大对象大小100%的读取性能
总结
我们承认,上面显示的性能比较并不完全相似的对比。我们相信这项研究应该为您提供不同Ceph Storage版本的关键性能见解,并帮助您做出明智的决定。
我们尽力在这两项研究中选择共同点。有趣的是,只有一半的磁盘轴(110 Ceph Storage 3.3 test vs 210 Ceph Storage 2.0 test)带有BlueStore OSD后端和Beast RGW前端web服务器的Ceph Storage 3.3为小对象提供了5倍高的操作,为大对象提供了2倍高的带宽100%的写入工作负载。在下一篇文章中,我们将揭示在Ceph集群中存储10亿多个对象的性能。
7、Ceph扩展到超过十亿个对象
这是Red Hat Ceph对象存储性能系列中的第六篇。在这篇文章中,我们将进行深入研究,学习如何将经过测试的Ceph扩展到超过十亿个对象,并分享在此过程中发现的性能秘密。为了更好地理解本文中显示的性能结果,建议阅文章的第一部分内容,其中详细介绍了实验室环境,性能工具包和所用方法。
执行摘要
- 读取:观察到一致的聚合吞吐量(Ops)和读取延迟。
- 写入:观察到一致的写入延迟,直到群集达到大约容量的90%。
- 在整个测试周期中,我们没有观察到CPU、内存、HDD、NVMe和网络上的任何瓶颈。我们也没有观察到Ceph守护进程的任何问题,这些问题表明集群在存储对象的数量上有困难。
- 此测试是在相对较小的集群上执行的。元数据溢出到较慢的设备上的组合效应以及集群容量的大量使用影响了整体性能。可以通过正确调整Bluestore元数据设备的大小并在集群中保持足够的可用容量来缓解这种情况。
表现摘要
- 成功摄取了超过十亿个对象(准确地说是1,014,912,090个对象),这些对象通过S3对象接口跨10K存储桶分布到Ceph集群中,而操作或数据一致性挑战为零。这证明了Ceph集群的可扩展性和健壮性。
- 当集群中的对象总数接近8.5亿时,我们的存储容量不足。当群集填充率达到约90%时,我们需要为更多的对象腾出空间,因此我们从以前的测试中删除了较大的对象,并激活了均衡器模块。他们共同创造了额外的负载,我们认为这会降低客户端吞吐量并增加延迟。
- 有害的写入性能反映了Bluestore元数据从闪存溢出到低速设备的情况。对于涉及存储数十亿个对象的用例,建议为Bluestore元数据(block.db)适当调整SSD的大小,以避免rocksDB级别溢出到速度较慢的设备上。
- 使用 bluestore_min_alloc_size = 64KB会导致小型擦除编码对象的空间显著放大。
- 减少 bluestore_min_alloc_size消除了空间放大问题,但是由于18KB未对齐4KB,导致对象创建速率降低。
- SSD 的默认 bluestore_min_alloc_size 在RHCS 4.1中将更改为4KB,并且使4KB也适合HDD的工作。
- 对于批量删除操作,发现S3对象删除API与Ceph Rados API相比要慢得多。因此,我们建议您使用“对象到期存储桶生命周期”,或使用radosgw-admin工具进行批量删除操作。
测试方法
要将十亿个对象存储到Ceph集群中,我们使用了COSBench并执行了数百次测试回合,其中每一回合包括
- 创建14个新的存储桶。
- 每个存储区可摄取(即写入)100,000个64KB有效负载大小的对象。
- 在300秒的时间内读取尽可能多的书面对象。
绩效结果
Ceph被设计为一个固有的可扩展系统。我们在此项目中进行的十亿个对象提取测试强调了Ceph可扩展性且非常重要的维度。在本节中,我们将分享在将10亿个对象存储到Ceph集群时捕获的相关发现。
读取表现
图1表示以聚合吞吐量(ops)指标衡量的读取性能。图2显示了平均读取延迟,以毫秒为单位(蓝线)。这两个图表均显示了从Ceph群集获得的强大且一致的读取性能,而测试套件吸收了超过十亿个对象。在整个测试过程中,读取吞吐量保持在15K Ops-10K Ops的范围内。这种性能差异可能与高存储容量消耗(约90%)以及在后台发生的旧的大对象删除和重新平衡操作有关。
正在上传…重新上传取消
图表1:对象计数与汇总读取吞吐量操作
图2比较了在读取对象时读写测试的平均延迟(以毫秒为单位)(从客户端测量)。在此测试规模的前提下,读取和写入延迟都保持非常一致,直到我们用尽存储容量并将大量Bluestore元数据溢出到速度较慢的设备上为止。
测试的前半部分显示,与读取相比,写入延迟保持较低。这可能是Bluestore效应。我们过去所做的性能测试显示了类似的行为,其中发现Bluestore写延迟比Bluestore读延迟略低,这可能是因为Bluestore不依赖Linux页面缓存进行预读和OS级缓存。
在测试的后半部分,读取延迟比写入延迟低,这可能与Bluestore元数据从闪存溢出到慢速HDD有关(在下一节中说明)。
正在上传…重新上传取消
图表2:读写延迟比较
写性能
图3表示通过其S3接口将十亿个64K对象提取(写入操作)到我们的Ceph集群。该测试从已经存储在Ceph集群中的大约2.9亿个对象开始。
该数据是由之前的测试运行创建的,我们选择不删除该数据,并从此时开始填充集群,直到达到10亿个对象为止。我们执行了600多次独特的测试,并在集群中填充了10亿个对象。在课程中,我们测量了指标,例如总对象数,读写吞吐量(Ops),读写平均延迟(ms)等。
在大约5亿个对象的情况下,群集达到了其可用容量的50%,我们观察到聚合写入吞吐量性能下降的趋势。经过数百次测试后,聚合的写吞吐量继续下降,而群集使用的容量达到了惊人的90%。
从这一点出发,为了达到我们的目标,即存储十亿个对象,我们需要更多的可用容量,因此我们删除/重新平衡了大于64KB的旧对象。
众所周知,通常随着总体消耗的增加,存储系统的性能会逐渐下降。我们观察到与Ceph类似的行为,在大约90%的已用容量下,总吞吐量与我们最初开始时相比有所下降。因此,我们认为如果添加更多存储节点以保持较低的利用率,则性能可能不会像我们观察到的那样遭受损失。
另一个有趣的发现,我们发现Bluestore元数据频繁从NVMe到HDD溢出导致聚合性能下降。我们摄取了大约十亿个新对象,生成了许多Bluestore元数据。根据设计,Bluestore元数据存储在rocksDB中,建议将此分区存储在Flash介质上,在本例中,我们为每个OSD使用80GB NVMe分区,该分区共享在Bluestore rocksDB和WAL之间。
rocksDB在内部使用级别样式压缩,其中rocksDB中的文件被组织为多个级别。例如,Level-0(L0),Level-1(L1)等。级别0是特殊的,其将内存中的写缓冲区(内存表)刷新到文件,并且其中包含最新数据。较高的级别包含较旧的数据。
当L0文件达到特定阈值(可使用 level0_file_num_compaction_trigger进行配置)时,它们将合并到L1中。所有非0级都有目标大小。rocksDB的压缩目标是将每个级别的数据大小限制在目标范围内。将目标大小计算为级别基础大小x 10作为下一个级别乘数。因此,L0目标大小为(250MB),L1(250MB),L2(2,500MB),L3(25,000MB)等。
所有级别的目标大小的总和就是您需要的rocksDB存储总量。根据Bluestore配置的建议,rocksDB存储应使用闪存介质。如果我们没有为rocksDB提供足够的闪存容量来存储其Levels,rocksDB会将Levels数据溢出到速度较慢的设备(例如HDD)上。毕竟,数据必须存储在某个地方。
rocksDB元数据从闪存设备到HDD的这种溢出大大降低了性能。如图4所示,当我们将对象存储到系统中时,每个OSD溢出的元数据达到80GB以上。
因此,我们的假设是,Bluestore元数据从闪存介质到慢速介质的这种频繁溢出是我们案例中聚合性能下降的原因。
这样,如果您知道用例将涉及在Ceph集群上存储数十亿个对象,则可以通过对每个Ceph OSD使用适用于BlueStore(rocksDB)元数据的Ceph OSD使用较大的闪存分区来缓解性能影响,从而可以将其存储在闪存上访问rocksDB的L4文件。
正在上传…重新上传取消
图表3:对象计数与汇总写入吞吐量操作
正在上传…重新上传取消
图表4:Bluestore元数据溢出到慢速(HDD)设备上
其它发现
在本节中,我们希望涵盖我们的一些其他发现。
大规模删除对象
当集群的存储容量用尽时,除了删除存储在存储桶中的旧的大对象外,我们别无选择,并且有数百万个这样的对象。我们最初是从S3 API的DELETE方法开始的,但很快我们意识到它不适用于存储桶删除,因为必须删除存储桶中的所有对象,然后才能删除存储桶本身。
我们遇到的另一个S3 API限制是,每个API请求只能删除1K个对象。我们有数百个存储桶,每个存储桶都有100K个对象,因此使用S3 API DELETE方法删除数百万个对象对我们来说是不切实际的。
幸运的是,使用radosgw-admin CLI工具公开的本机RADOS网关API支持删除加载了对象的存储桶。通过使用本机RADOS网关API,我们花了几秒钟删除了数百万个对象。因此,对于任何规模的删除对象,Ceph的本地API都可以挽救。
修改 bluestore_min_alloc_size_hdd参数
该测试是在具有4 + 2配置的擦除编码池上完成的。因此,根据设计,每个64K有效负载都必须分成4个16KB的块。Bluestore使用的 bluestore_min_alloc_size_hdd参数表示为存储在Ceph Bluestore对象存储中的对象创建的Blob的最小大小,其默认值为64KB。因此在这种情况下,将为每个16KB EC块分配64KB空间,这将导致48KB的未使用空间开销,无法进一步利用。
因此,在进行10亿个对象摄取测试之后,我们决定将 bluestore_min_alloc_size_hdd 降低到18KB并重新测试。如图5所示,在将bluestore_min_alloc_size_hdd参数从64KB(默认值)降低到18KB之后,发现对象创建速率显著降低。因此,对于大于bluestore_min_alloc_size_hdd的对象,默认值似乎是最佳值,如果打算减少bluestore_min_alloc_size_hdd参数,则较小的对象还需要更多筛选。请注意,不能将bluestore_min_alloc_size_hdd设置为低于bdev_block_size(默认值为4096-4kB)。
正在上传…重新上传取消
图5:每分钟的物体摄取率
总结
在本文中,我们通过将十亿多个对象存储到Ceph集群中,展示了Ceph集群的健壮性和可伸缩性。我们了解了与群集相关联的各种性能特征,其中包括最大容量的群集,以及将bluestore元数据溢出到速度较慢的设备上如何提高性能,以及在设计大规模规模的Ceph群集时可以选择的缓解措施。
参考链接:
https://www.redhat.com/en/blog/red-hat-ceph-object-store-dell-emc-servers-part-1
https://www.redhat.com/en/blog/red-hat-ceph-storage-rgw-deployment-strategies-and-sizing-guidance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/achieving-maximum-performance-fixed-size-ceph-object-storage-cluster?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/ceph-rgw-dynamic-bucket-sharding-performance-investigation-and-guidance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/red-hat-ceph-storage-33-bluestore-compression-performance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/comparing-red-hat-ceph-storage-33-bluestorebeast-performance-red-hat-ceph-storage-20-filestorecivetweb?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/scaling-ceph-billion-objects-and-beyond?source=author&term=43551
![YumRepo Error: All mirror URLs are not using ftp, http[s] or file解决办法](https://img-blog.csdnimg.cn/f52718ef424445db87f2d099bcbefcee.png)




![PMP项目管理-[第五章]范围管理](https://img-blog.csdnimg.cn/4cfaa76a85e849cc8a1342f36915c990.png)