我们知道栈被操作系统安排在进程的高地址处,它是向下增长的。但这只是对栈相关知识的“浅尝辄止”。栈是每一个程序员都很熟悉的话题,但你敢说你真的完全了解它吗?我相信,你在工作中肯定遇到过栈溢出(StackOverflow)的错误,比如在写递归函数的时候,当漏掉退出条件,或者退出条件不小心写错了,就会出现栈溢出错误。我们也经常听说缓冲区溢出带来的严重的安全问题,这在日常的工作中都是要避免的。
我们继续深入探讨一下栈这个话题,我会带你基于“符合人的直观思维”,也就是函数的层面和 CPU 的机器指令层面,多角度来理解栈相关的概念。这样,你以后遇到与栈相关的问题的时候,才知道如何着手进行排查。
函数与栈帧
当我们在调用一个函数的时候,CPU 会在栈空间(这当然是线性空间的一部分)里开辟一小块区域,这个函数的局部变量都在这一小块区域里存活。当函数调用结束的时候,这一小块区域里的局部变量就会被回收。
这一小块区域很像一个框子,所以大家就命名它为 stack frame。frame 本意是框子的意思,在翻译的时候被译为帧,现在它的中文名字就是栈帧了。
所以,我们可以说,栈帧本质上是一个函数的活动记录。当某个函数正在执行时,它的活动记录就会存在,当函数执行结束时,活动记录也被销毁。
不过,你要注意的是,在一个函数执行的时候,它可以调用其他函数,这个时候它的栈帧还是存在的。例如,A 函数调用 B 函数,此时 A 的栈帧不会被销毁,而是会在 A 栈帧的下方,再去创建 B 函数的栈帧。只有当 B 函数执行完了,B 的栈帧也被销毁了,CPU 才会回到 A 的栈帧里继续执行。
我们举个例子说明一下,就很好理解了。你可以看一下这个代码:
1 #include <stdio.h>
2
3 void swap(int a, int b) {
4 int t = a;
5 a = b;
6 b = t;
7 }
8
9 void main() {
10 int a = 2;
11 int b = 3;
12 swap(a, b);
13 printf("a is %d, b is %d\n", a, b);
14 }你可以看到,在 swap 函数中,a 和 b 的值做了一次交换,但是在 main 函数里,打印 a和 b 的值,a 还是 2,b 还是 3。这是为什么呢?从栈帧的角度,这个问题就非常容易理解:

在 main 函数执行的时候,main 的栈帧里存在变量 a 和 b。当 main 在调用 swap 方法的时候,会在 main 的帧下面新建 swap 的栈帧。swap 的帧里也有局部变量 a 和 b,但是明显这个 a、b 与 main 函数里的 a、b 没有任何关系,不管对 swap 的帧里的 a/b 变量做任何操作都不会影响 main 函数的栈帧。
接下来,我们再通过一个递归的例子来加深对栈的理解。由于递归执行的过程会出现函数自己调用自己的情况,也就是说,一个函数会对应多个同时活跃的记录(即栈帧)。所以,理解了递归函数的执行过程,我们就能更加深刻地理解栈帧与函数的关系。
当我们在谈递归时,我们在谈什么
我们先看一下最经典的递归问题:汉诺塔。汉诺塔问题是这样描述的:有三根柱子,记为A、B、C,其中 A 柱子上有 n 个盘子,从上到下的编号依次为 1 到 n,且上面的盘子一定比下面的盘子小。要求一次只能移动一只盘子,且大的盘子不能压在小的盘子上,那么将所有盘子从 A 移到 C 总共需要多少步?
我们这里,重点来讲解递归程序执行的过程中,栈是怎么样变化的,这样可以帮助我们理解栈的基本工作原理。
你先看一下汉诺塔问题的求解程序:

这段代码可以打印出借由 B 柱子将 5 个盘子从 A 搬移到 C 的所有步骤。这个的核心是hanoi 函数,在深入分析代码的执行过程之前,我们可以先从符合直观思维的角度尝试理解 hanoi 函数。
hanoi 函数有四个参数。第一个 src 代表要搬的起始柱子(开始时是 A),第二个代表目标柱子(开始时是 C),第三个代表可以借用的中间的那个柱子(开始时是 B),第四个参数代表一共要搬的盘子总数(开始时是 5)。
代码的第 13 行的意义是,如果要从 A 搬 5 个盘子到 C,可以先将 4 个盘子搬到 B 上,然后第 14 行代表将第 5 个盘子从 A 搬到 C,第 15 行代表把 B 上面的 4 个盘子搬到 C 上去。第 8 行的判断是说当只搬一个盘子的时候,就可以直接调用 move 方法。
以上就是递归程序的设计思路。下面我们再具体分析这个代码的执行过程。为了简便起见,我们选择 n=3 进行分析。
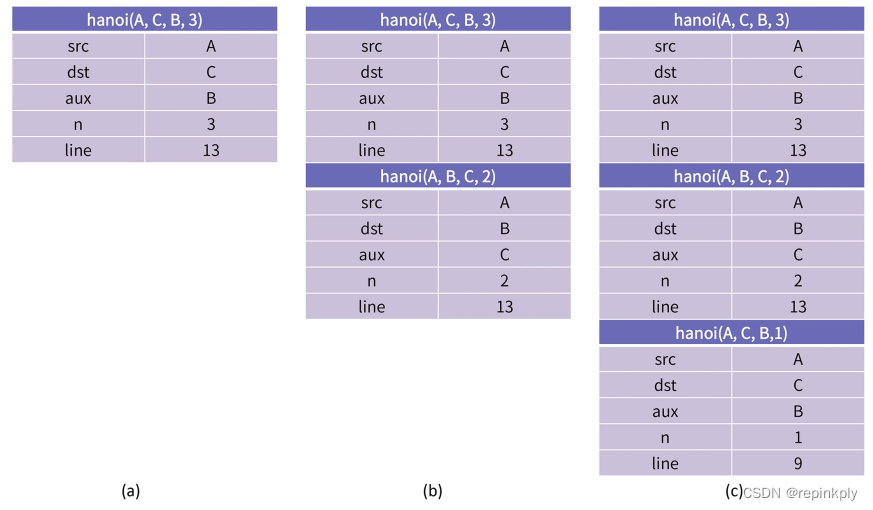
可以看到,当程序在执行 hanoi(A, C, B, 3) 时,CPU 会为其创建一个栈帧,这一帧里记录着变量 src、dst、aux 和 n。
此时 n 为 3,所以,代码可以执行到第 13 行,然后就会调用执行 hanoi(A, B, C, 2)。这代表着将 2 个盘子从 A 搬到 B,同样 CPU 也会为这次调用创建一个栈帧;当这一次调用执行到第 13 行时,会再调用执行 hanoi(A, C, B, 1),代表把一个盘子从 A 搬到 C。不过,由于这一次调用 n 为 1,所以会直接调用 move 函数,打印第一个步骤“把盘子 1 从 A 搬到 C”。
接下来,程序就会回到 hanoi(A, B, C, 2) 的栈帧,继续执行第 14 行,打印第二个步骤”把盘子 2 从 A 搬到 B”。然后再执行第 15 行,也就是执行 hanoi(C, B, A, 1)。这一步的栈帧变化,你可以看下面这张图。

我们看到,在调用 hanoi(C, B, A, 1) 的时候,由于 n 等于 1,所以就会打印第三个步骤“把盘子 1 从 C 搬到 B”,此时 hanoi(C, B, A, 1) 就执行完了。
那么接下来,程序就退回到 hanoi(A, B, C, 2) 的第 15 行的下一行继续执行,也就是函数的结束,这就意味着 hanoi(A, B, C, 2) 也执行完了。这个时候,程序就会回退到最高的一层 hanoi(A, C, B, 3) 的第 14 行继续执行。这一次就打印了第四个步骤“把盘子 3 从 A 搬到 C”,此时的栈帧如上图 (b) 所示。
然后,程序会执行第 15 行,再次进入递归调用,创建 hanoi(B, C, A, 2) 的栈帧。当它执行到第 13 行时,就会再创建 hanoi(B, A, C, 1) 的栈帧,此时栈的结构如上图(c)所示。由于 n 等于 1,这一次调用就会打印第五个步骤“把盘子 1 从 B 搬到 A”。
再接着就开始退栈了,回到 hanoi(B, C, A, 2) 的栈帧,继续执行第 14 行,打印第六个步骤“把盘子 2 从 B 搬到 C”。然后执行第 15 行,也就是 hanoi(A, C, B, 1),此时 n 等于1,直接打印第七个步骤“把盘子 1 从 A 搬到 C”。接下来就执行退栈,这一次每一个栈帧都执行到了最后一行,所以会一直退到 main 函数的栈帧中去。退栈的过程比较简单,你自己思考一下就好了。
这样我们就完成了一次汉诺塔的求解过程。在这个过程中呢,我们观察到,先创建的帧最后才销毁,后创建的帧最先被销毁,这就是先入后出的规律,也是程序执行时的活跃记录要被叫做栈的原因。
从指令的角度理解栈
好了,前面递归的例子,是从人的直观思维的角度去理解栈,但是在 CPU 层面,机器指令又是怎样去理解栈的呢?我们还是通过一个例子来考察一下:
int fac(int n) {
return n == 1 ? 1 : n * fac(n-1);
}这是一个使用递归的写法求阶乘的例子,源码是比较简单的,我们可以使用 gcc 对其进行编译,然后使用 objdump 对其反编译,观察它编译后的机器码。
# gcc -o fac fac.c
# objdump -d fac然后你可以得到以下输出:

我们来分析一下这段汇编代码。
第 1 行是将当前栈基址指针存到栈顶,第 2 行是把栈指针保存到栈基址寄存器,这两行的作用是把当前函数的栈帧创建在调用者的栈帧之下。保存调用者的栈基址是为了在 return时可以恢复这个寄存器。
第 3 行的作用呢,是把栈向下增长 0x10,这是为了给局部变量预留空间。从这里,你可以看出来运行 fac 函数要是消耗栈空间的。
试想一下,如果我们不加 n==1 的判断,那么 fac 函数将无法正常返回,会出现一直递归调用回不来的情况,这样栈上就会出现很多 fac 的帧栈,会造成栈空间耗尽,出现StackOverflow。这里的原理是,操作系统会在栈空间的尾部设置一个禁止读写的页,一旦栈增长到尾部,操作系统就可以通过中断探知程序在访问栈末端。
第 4 行是把变量 n 存到栈上。其中变量 n 一开始是存储在寄存器 edi 中的,存储的目标地址是栈基址加上 0x4 的位置,也就是这个函数栈帧的第一个局部变量的位置。变量 n 在寄存器 edi 中是 X86 的 ABI 决定的,第一个整型参数一定要使用 edi 来传递。
如果第 5 行的比较结果是不相等的,又会怎么办呢?那第 6 行就不会跳转,而是继续执行第 7 行。7、8、9 这三行的作用,就是把 n-1 送到 edi 寄存器中,也就是说以 n-1 为参数调用 fac 函数。这个时候,调用的返回值在 eax 中,第 11 行会把返回值与变量 n 相乘,结果仍然存储在 eax 中。然后程序就可以跳转到 0x400556 处结束这次调用。
理解了 fac 函数的汇编指令以后,我们再重点讨论 callq 指令。
执行 callq 指令时,CPU 会把 rip 寄存器中的内容,也就是 call 的下一条指令的地址放到栈上(在这个例子中就是 0x40054b),然后跳转到目标函数处执行。当目标函数执行完成后,会执行 ret 指令,这个指令会从栈上找到刚才存的那条指令,然后继续恢复执行。
栈空间中的 rbp、rsp,以及返回时所用的指令都是非常敏感的数据,一旦被破坏就会造成不可估量的损失。
不过,你在重现这个例子一定要注意,我们使用不同的优化等级,产生的汇编代码也是不同的。比如如果你用以下命令进行编译,得到的二进制文件中将不再使用 rbp 寄存器。
# gcc -O1 -o fac fac.c到这里,我们已经从人的大脑的理解角度和机器指令的角度,让你加深了对栈和栈帧的理解。
栈溢出
//未完待续.......
几乎所有的程序员都会遇到并发程序。因为多进程或者多线程程序可以并发执行,充分利用多 CPU 多核的计算资源来完成任务,会大大提升应用程序的性能。
所以,我相信你在工作中也遇到过多线程程序,但不知道你是否考虑过进程和线程是如何切换的呢?很多文章都介绍了,操作系统为了避免频繁进入内核态,会把很多工作都尽量放在用户态。那么你有没有仔细思考过内核态、用户态到底意味着什么呢?
要回答上面的问题,我们就要理解这些概念背后最重要的一个步骤:对执行单元的上下文环境进行切换。它就是由栈这个核心数据结构支撑的。
你在 C++ 中使用各种协程库,或者在Lua、Go 等语言中使用原生协程的时候,就能理解它们背后发生了什么,也可以帮你写出正确的 IO 程序。你还将深入理解操作系统用户态和内核态,这样,你在做架构的时候,就能正确评估操作系统进入内核态的开销是多少?
在讲解执行单元的切换与栈的关系之前,我们先来给出它的准确定义。
什么是执行单元
执行单元是指 CPU 调度和分派的基本单位,它是一个 CPU 能正常运行的基本单元。执行单元是可以停下来的,只要能把 CPU 状态(其实就是寄存器的值)全部保存起来,等到这个执行单元再被调度的时候,就把状态恢复过来就行了。我们把这种保存状态,挂起,恢复执行,恢复状态的完整过程,称为执行单元的调度 (Scheduling)。
具体来说,常见的执行单元有进程,线程和协程三种,接下来,我们详细说明这三种执行单元的区别和联系。我们先来比较进程和线程。
理解进程和线程
当运行一个可执行程序的时候,操作系统就会启动一个进程。进程会被操作系统管理和调度,被调度到的进程就可以独占 CPU 了。
CPU 就像是一个可以轮流使用的工作台,多个进程可以在工作台上工作,时间到了就会带着自己的工作离开工作台,换下一个进程上来工作。
进程有自己独立的内存空间和页表,以及文件表等等各种私有资源,如果使用多进程系统,让多个任务并发执行,那么它所占用的资源就会比较多。线程的出现解决了这个问题。
同一个进程中的线程则共享该进程的内存空间,文件表,文件描述符等资源,它与同一个进程的其他线程共享资源分配。除了共享的资源,每个线程也有自己的私有空间,这就是线程的栈。线程在执行函数调用的时候,会在自己的线程栈里创建函数栈帧。
根据上面所说的特点,人们常把进程看做是资源分配的单位,把线程才看成一个具体的执行实体。
由于线程的切换过程和进程的切换过程十分相似,我们这节课就只以进程的切换为重点进行讲解,请你一定要自己查找相关资料,对照进程切换的过程,去理解线程的切换过程。
理解协程
未完待续....
进程是怎么调度和切换的?
进程切换的原理其实与协程切换的原理大致相同,都是将上下文保存在特定的位置,切换到新的进程去执行。所不同的是,操作系统为我们提供了进程的创建、销毁、信号通信等基础设施,这使得程序员可以很方便地创建进程。如果一个进程 a 创建了另外一个进程b,则称 a 为父进程,b 为子进程。
我先带你通过下面这个例子,直观地感受多进程运行的情况:
#include <stdio.h>
#include <unistd.h>
int main(int argc,char* argv[]){
pid_t pid;
if(!(pid = fork())){
printf("I am child process\n");
exit(0);
}
else {
printf("I am father process\n");
wait(pid); //让父进程等待子进程退出
}
return 0;
}gcc编译运行结果如下所示:
I am father process
I am child process在这个结果里,我们可以看到,在 if 分支和 else 分支中的代码都被运行了。曾经有个笑话说,这个世界上最远的距离,不是你在天涯,我在海角,而是你在 if 里,我在 else 里。由此可见,这个笑话也并不正确,还是要看 if 条件里填的是什么。
在上面的代码中,fork 是一个系统调用,用于创建进程,如果其返回值为 0,则代表当前进程是子进程,如果其返回值不为 0,则代表当前进程是父进程,而这个返回值就是子进程的进程 ID。
我们看到,子进程在打印完一行语句后就调用 exit 退出执行了。父进程在打印完以后,并没有立即退出,而是调用 wait 函数等待子进程退出。由于进程的调度执行是操作系统负责的,具有很大的随机性,所以父进程和子进程谁先退出,我们并不能确定。为了避免子进程变成孤儿进程,我们采用了让父进程等待子进程退出的办法,就是对两个进程进行同步。
其实,这段程序最难理解的是第 6 行,为什么一次 fork 后,会有两种不同的返回值?这是因为 fork 方法本质上在系统里创建了两个栈,这两个栈一个是父进程的,一个是子进程的。创建的时候,子进程完全“继承”了父进程的所有数据,包括栈上的数据。父子进程栈的情况如下图所示:

只要有一个进程对栈进行修改,栈就会复制一份,然后父子进程各自持有一份。图中的黄色部分也是进程共用的,如果有一个进程修改它,也会复制一份副本,这种机制叫做写时复制。
接着,操作系统就会接管两个进程的调度。当父进程得到调度时,父进程的栈上是 fork 函数的 frame,当 CPU 执行 fork 的 ret 语句时,返回值就是子进程的 ID。
而当子进程得到调度时,rsp 这个栈指针就将会指向子进程的栈,子进程的栈上也同样是fork 函数的 frame,它也会执行一次 fork 的 ret 语句,其返回值是 0。
所以第 6 行虽然是同一个变量 pid,但实际上,它在子进程的 main 函数的栈帧里有一个副本,在父进程的栈帧里也有一个副本。从 fork 开始,父进程和子进程就已经分道扬镳了。你可以将进程栈的切换与协程栈的切换对比着进行学习。
我们通过一个例子展示了进程是如何创建的,并且分析了进程创建背后栈的变化过程。你可以看到,进程做为一种执行单元,它的切换还是要依赖于栈切换这个核心机制。
用户态和内核态是怎么切换的?
我们知道中断描述符表,可以用系统调用 write 这个例子,来展示如何通过软中断进入内核态。实际上,内核态和用户态的切换也依赖栈的切换。
操作系统内核在运行的时候,肯定也是需要栈的,这个栈称为内核栈,它与用户应用程序使用的用户态栈是不同的。只有高权限的内核代码才能访问它。而内核态与用户态的相互切换,其中最重要的一个步骤就是两个栈的切换。
中断发生时,CPU 根据需要跳转的特权级,去一个特定的结构中(不同的 CPU 会有所不同,比如 i386 就存在 TSS 中,但不管是什么 CPU,一定会有一个类似的结构),取得目标特权级所对应的 stack 段选择子和栈顶指针,并分别送入 ss 寄存器和 rsp 寄存器,这就完成了一次栈的切换。
然后,IP 寄存器跳入中断服务程序开始执行,中断服务程序会把当前 CPU 中的所有寄存器,也就是程序的上下文都保存到栈上,这就意味着用户态的 CPU 状态其实是由中断服务程序在系统栈上进行维护的。如下图所示:
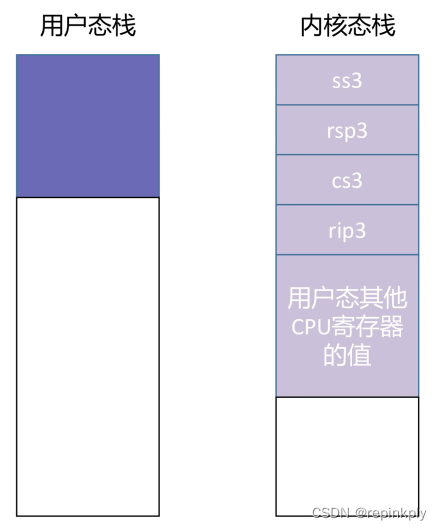
一般来说,当程序因为 call 指令或者 int 指令进行跳转的时候,只需要把下一条指令的地址放到栈上,供被调用者执行 ret 指令使用,这样可以便于返回到调用函数中继续执行。但上图中的内核态栈里有一点特殊之处,就是 CPU 自动地将用户态栈的段选择子 ss3,和栈顶指针 rsp3 都放到内核态栈里了。这里的数字 3 代表了 CPU 特权级,内核态是 0,用户态是 3。
当中断结束时,中断服务程序会从内核栈里将 CPU 寄存器的值全部恢复,最后再执行"iret"指令(注意不是 ret,而是 iret,这表示是从中断服务程序中返回)。而 iret 指令就会将 ss3/rsp3 都弹出栈,并且将这个值分别送到 ss 和 rsp 寄存器中。这样就完成了从内核栈到用户栈的一次切换。同时,内核栈的 ss0 和 rsp0 也会被保存到前文所说的一个特定的结构中,以供下次切换时使用。
小结
后续补充更多实例....






![中介者设计模式(Mediator Design Pattern)[论点:概念、组成角色、相关图示、示例代码、适用场景]](https://img-blog.csdnimg.cn/ddae50bee4ae49ada53a6dc54c3be8c4.png)