Python采集电商平台
- 写在前面
- 环境及模块
- 案例实现思路
- 代码展示
- 效果展示
- 最后
写在前面
这不是双十一快到了,为了以最优惠的价格买到自己想买的商品,我不惜用Python把ya ma xun 所有商品撸了一遍。
环境及模块
使用环境
python 3.8
pycharm 2021
模块及安装
requests # 数据请求模块 pip install requests
parsel # 解析数据 pip install parsel xpath css
案例实现思路
分析数据来源
静态数据:我们能够通过 右键点击查看网页源代码 找到的内容
动态数据:找不到的内容
当你不知道怎么区分的时候 直接用network
代码实现步骤
- 发送请求 通过代码的方式 去访问一下 上方的网址
- 获取数据
- 解析数据 从获取出来的数据当中提取我们需要的
- 保存数据
代码展示
# 网址我都屏蔽了,以免审核不过..
f = open('yamaxun.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['title', 'score', 'price', 'link', 'img_url'])
# 伪装
headers = {
# 用户身份信息
'Cookie': 'session-id=461-5432315-2651056; i18n-prefs=CNY; ubid-acbcn=460-4142230-3903418; csm-hit=tb:Y5HFFE1BM9655HPJMQX0+s-A96X9VP6NWER0K4SRXNF|1667650218841&t:1667650218841&adb:adblk_no; session-token="R+xUs8v/1RH9U8xjkIb6UNUS8yc/OinE8juA0eJPnO/+cTnMIPD81zAO3IRfcAEURcQkEbGFXpGLZKjqI0wLpOtgXzqiRwM/e7nxtYSlUxMdLnFkslL1xyWGjL+bvt3pCW3QlUub6KER8qGBe74quFjTvFoxAMKSP5zaM5G4oFCqYppJ1JLFWi7LQv/kN//k/pvPpKreZ4rIRU+A9L+83TO3ukoW6z3YkvIkDnaX4E0="; session-id-time=2082787201l',
# 防盗链
'Referer': 'https:///b?node=665002051',
# 浏览器的基本信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
for page in range(1, 400):
print(f"---正在采集第{page}页---")
url = f'https:///s?i=communications&rh=n%3A665002051&fs=true&page={page}&qid=1667650286&ref=sr_pg_{page}'
# 1. 发送请求
response = requests.get(url=url, headers=headers)
# 2. 获取数据
html_data = response.text
# 3. 解析数据
select = parsel.Selector(html_data)
divs = select.css('div.s-main-slot.s-result-list.s-search-results.sg-row>div')
# 每个商品的信息
# 二次提取每个商品信息里面的 字段
for div in divs[1: -3]:
# 提取标签属性内容
# ::attr(属性名称)
img_url = div.css('img.s-image::attr(src)').get()
# 提取标签文本内容
# <a>fhuiweaihfwjw</a> ::text
title = div.css('span.a-size-base-plus.a-color-base.a-text-normal::text').get()
score = div.css('span.a-icon-alt::text').get()
price = div.css('span.a-offscreen::text').get()
link = div.css('a.a-link-normal.s-no-outline::attr(href)').get()
print(title, score, price, link, img_url)
# 4. 保存数据
csv_writer.writerow([title, score, price, link, img_url])
完整代码文末名片领取,还有对应的视频讲解。
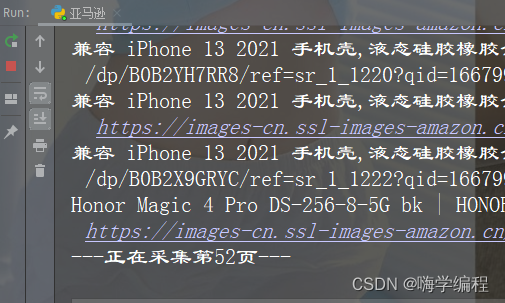
效果展示
我设置的是400页,就不展示这么多了,难等!

最后
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及源代码!
直接在文末名片自取!









好了,今天的分享到这里就结束了!



![[RCTF 2019]Nextphp](https://img-blog.csdnimg.cn/de9ea8cfa8cf49609a6ce3e0270606e3.png)