目录
火山模型
Tuple 数据结构设计
条件计算
Expr 和 Var
示例1 filter
示例2 join
示例3 index scan & index only scan
火山模型
执行器各个算子解耦合的基础。对于每个算子来说,只有三步:
1、向自己的孩子拿一个 tuple。即调用孩子节点的 Next 函数;
2、执行计算;
3、向上层返回一个 tuple。即当前节点 Next 函数的返回结果。
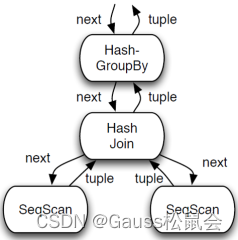
所以整个执行器的内核可以用下面这个伪代码来表达。
ExecutePlan
{
for (;;)
slot = ExecProcNode(planstate);
------->if (node->chgParam != NULL)
ExecReScan(node);
result= g_execProcFuncTable[index](node) // 表驱动,每个算子不同的执行函数
return result;
if (TupIsNull(slot)) {
ExecEarlyFreeBody(planstate);
break;
}
// 返回给前端
}这种模型的好处是:
-
设计简单,算子解耦,互相不依赖;
-
内存使用量小,没有物化的情况下,每次只消耗一个 tuple 的内存。
Tuple 数据结构设计
两个算子之间的传递的都是 tuple。所以 Tuple 数据结构是整个执行器的核心,也是执行器和存储引擎交互的数据结构。
先看下几个具体数据结构之间的关系(附上关键的变量,非全部)
// 存在磁盘上的数据结构,是 header + 数据 的一片连续内存。设计要求尽可能紧凑,节约存储空间。
// 只有事务信息等,其它比如长度、每一列起始地址等都不会直接存,而是算出来的。
HeapTupleHeaderData
t_xmin; // 事务信息
t_xmax;
t_cid;
t_ctid;
...
// 磁盘上的 Tuple 数据结构过于紧凑,不好用。所以设计了内存中一个 tuple 的对象,会存一些额外(冗余)的元数据信息方便处理。
// 数据和元数据可以不连续。这个数据结构一般是存储引擎内部用,比如可见性判断等。
HeapTupleData
t_len; // 数据长度
tupTableType;// store 类型
t_self; // ctid
t_tableOid;
...
HeapTupleHeader t_data; // tuple header data 的地址
// 可以理解为 Tuple 槽位,执行器用。存储引擎不关心具体每一列的内容,只关心事务、长度等公共信息。
// 而执行器可能需要访问每一列,所以在这里把 tuple 进一步拆解开。
TupleTableSlot
Tuple tts_tuple; // 物理 tuple 位置(HeapTupleData);虚拟 tuple 的话为 null。
TupleDesc tts_tupleDescriptor;
Buffer tts_buffer;
Datum* tts_values; // 数组,表示每一列的值(如果是 int 就是值,如果是 varchar 就是地址)
bool* tts_isnull; // 数组,表示每一列是否是 null
TableAmType tts_tupslotTableAm // 处理物理 tuple 的函数(astore 和 ustore 不同)以上图为例,最下层的 seqscan,会调用存储引擎的 heap_getnext 函数(astore)。
// 代码中用的函数指针,实际调用栈如下
ExecScanFetch
--->SeqNext
--------->seq_scan_getnext_template // 存储引擎入口
tuple = (Tuple)heap_getnext // 拿到 HeapTuple
// 组装TupleTableSlot,但是 attr 的值还没置上,得在 heap_slot_getattr 里设置。
heap_slot_store_heap_tuple(htup, slot, scan->rs_cbuf, false, false);
heap_getnext
---> heapgettup
HeapTuple tuple = &(scan->rs_ctup); // tuple 是 scan 结构体中的变量。
LockBuffer(scan->rs_base.rs_cbuf, BUFFER_LOCK_SHARE); // 锁住 buffer
dp = (Page)BufferGetPage(scan->rs_base.rs_cbuf);
lpp = HeapPageGetItemId(dp, line_off);
tuple->t_data = (HeapTupleHeader)PageGetItem((Page)dp, lpp); // t_data 的地址就是 buffer 中的地址
ItemPointerSet(&(tuple->t_self), page, line_off); // 设置 tuple 中的一些变量
valid = HeapTupleSatisfiesVisibility(tuple, snapshot, scan->rs_base.rs_cbuf); // 用作可见性判断
return &(scan->rs_ctup);
// 把物理 tuple 中的数据,复制到 tupleTableSlot 中。这里是 astore 的解析函数,ustore 不一样。
heap_slot_getattr
// 核心思想是利用 TupleDesc 知道表的定义,然后从0 开始一个 attr 一个 attr 地解析。
// 对于定长字段,直接按地址取值;对于变长字段,长度会存在原始的数据头中。
// 因此,之前的物理 tuple 不需要存长度这种信息;同时,也需要 tupleTableSlot 这样的变量来缓存具体数据的起始地址。以上就是存储引擎和执行引擎之间 tuple 怎么交互的。总结下就是存储引擎会把实际数据所在的地址传给上层,最后执行引擎拿到的结构体为TupleTableSlot。
所以,执行引擎只关心 TupleTableSlot 这一个结构体即可。
一个很自然的问题就是,如果算子之间的 Tuple 都是深拷贝传递,对于较大的 tuple 来说(包含 varchar 类型),性能很差。因此,PG 中的 tuple 分了4类(详见头文件tuptable.h):
-
第一类 tuple 是 Disk buffer page 上的 physical tuple,就是前文的 HeapTuple。Buffer 一定要 pin 住。这种 Tuple 可以直接根据头地址进行访问。
-
内存中的组装的tuple,格式和文件上 tuple 完全一样,也是进行过压缩。这种也算是 physical tuple,可以直接用地址。
-
Minimal physical tuple,也是内存中的,唯一区别在于没有系统列(xmin、xmax 等)。
-
virtual tuple,只记录每一个属性数据的地址,并没有深拷贝,而是直接通过地址来访问。现在约定的是,当一个算子向上层吐一个 tuple,直到它下次被调用时,该tuple所在的内存不会被释放。
对于查询来说,第一类和第四类最为常见。2、3两类会在物化的时候使用,比如 CTEScan、HashJoin 建立 hash 表的时候,相当于深拷贝。性能比较敏感的场合,尽量避免2、3类 tuple的使用。
slot 的创建一般通过 ExecAllocTableSlot、ExecSetSlotDescriptor 两个函数来分配内存和初始化信息。在执行器初始化阶段,每个算子会分配相应的 slot。
以上图为例,
-
SeqScan 算子有一个 tupleTableSlot,是一个 physical tuple,指向的是 Buffer 中的地址。
向上层返回自己的 tuple slot;
-
HashJoin 一个一个拿到 内表的 tuple slot,需要建立 hash 表,所以创建了一个 minimal physical tuple,复制内表的 tuple 内容;
-
Hash表建立后,HashJoin 算子然后一个一个拿到外表的 tuple slot,做 join 计算。
HashJoin 自己有一个 tuple slot,如果碰到匹配,则把自己的 tuple slot 设置成 virtual tuple,其中的 tts_values 指向的是孩子节点的 tuple 中的地址。
再向上返回。
其中,外表的内容指向的是 Buffer 上的physical tuple, 内表的内容指向的是 hash 表中的 minimal physical tuple;
-
当 HashJoin 被再次调用时,它会重置 tuple slot。因为是 virtual tuple,所以没做任何事情。然后 HashJoin 会调用 SeqScan 拿下一条tuple;
-
SeqScan 被再次调用时,也会重置 tuple slot。
因为是 physical tuple,它需要释放之前的 Buffer。
(当然,如果一直是同一个 Buffer 不会反复 pin/unpin,这是存储引擎的优化)。
条件计算
Expr 和 Var
执行器每个算子会对底下传上来的 tuple 进行计算和过滤。比如 NestLoop 需要计算内外表传上来的 tuple 是否满足 join 条件。
这时候需要引出第二个重要的概念,表达式的抽象。个人理解,任何对数据的获取操作都可以认为是表达式。
Var/Const 也是表达式的一种。Var 表示直接从 tuple 中获取数据,Const 表示的是直接获取一个常数。
每一个表达式会对应一个 ExprContext,ExprContext 中会记录计算所需要的所有数据,一般是孩子节点返回的 tuple。
表达式本身,在执行器中用 ExprState 来表示。里面重点是表达式的计算函数
// 因为当前执行模型中,每个算子最多只有两个孩子节点,所以下面三个变量用的最多。
struct ExprContext {
TupleTableSlot* ecxt_scantuple; // scan 算子会用到
TupleTableSlot* ecxt_innertuple; // 非 scan 算子如 join
TupleTableSlot* ecxt_outertuple;
...
}
// 表达式计算的结构体
struct ExprState {
Expr* expr; // 原始的表达式
ExprStateEvalFunc evalfunc; // 表达式对应的函数
}
// 执行器开始阶段,会通过优化器传过来的 Expr,初始化 ExprState 结构
ExecInitExpr {
case T_Var:
ExecInitExprVar
state = (ExprState *)makeNode(ExprState);
state->evalfunc = ExecEvalScalarVar; // 内部实现是直接去取对应 tuple slot 上的 attr
case T_OpExpr:
FuncExprState* fstate = makeNode(FuncExprState);
fstate->xprstate.evalfunc = (ExprStateEvalFunc)ExecEvalOper; // 内部实现是先递归调用 ExecEvalExpr, 获取参数列表,再调用 function
fstate->args = (List*)ExecInitExpr((Expr*)opexpr->args, parent);
}
总结下,ExprState 结构体表示表达式计算的逻辑,ExprContext结构体表示的是表达式计算要用到的数据。
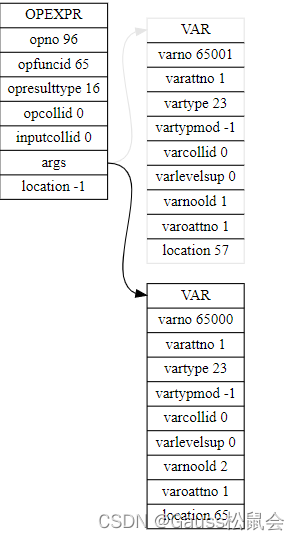
从 OpExpr 可以看出,ExprState 本身也是一棵树。一直递归调用 ExecEvalExpr 来获取最终的结果。
需要注意的是,执行树中除了叶子节点上的扫描节点,其它节点的数据都来源于孩子节点。
所以,这些计算节点上的 Var,不能直接指向某个 table,而是需要指向的是内表还是外表的 tuple slot。
因此,在优化器最后的阶段,set_plan_refs 函数中,会把中间节点的 Var 的 varno 改写成特定的值。
而 Var 的表达式处理函数 ExecEvalScalarVar 也是根据这个信息决定去找 ExprContext 中的 哪个 tuple slot。

表达式如下:
示例1 filter
以 SeqScan 为例,在优化器阶段, SeqScan 上会有一个 qual,表示过滤条件。在执行器阶段会生成一个对应的 ExprState,用于计算。
// 执行器初始化阶段,会根据优化器里的 Expr 构造 ExprState
ExecInitSeqScan
InitScanRelation
node->ps.qual = (List*)ExecInitQualWithTryCodeGen((Expr*)node->ps.plan->qual, (PlanState*)&node->ps, false);
// 执行阶段
ExecSeqScan
ExecScan
qual = node->ps.qual;
slot = ExecScanFetch(node, access_mtd, recheck_mtd); // 从存储引擎那里拿到 slot
econtext->ecxt_scantuple = slot; // 设置好 ExprContext
ExecNewQual(qual, econtext) // 调用 ExprState 进行计算
ret = ExecEvalExpr((ExprState*)qual, econtext, &isNull, NULL);
return DatumGetBool(ret);示例2 join
以 Nestloop 为例,优化器结束的时候,join 节点会有一个 joinqual 表示 join 条件。
ExecInitNestLoop
nlstate->js.joinqual = (List*)ExecInitQualWithTryCodeGen((Expr*)node->join.joinqual, (PlanState*)nlstate, false);
ExecNestLoop
// 拿到内外表的 tuple slot,设置在 ExprContext 上
econtext->ecxt_innertuple =ExecProcNode(inner_plan);
econtext->ecxt_outertuple = ExecProcNode(outer_plan);
List* joinqual = node->js.joinqual;
// 调用 ExprState 中的函数,如果符合 join 条件,则向上层返回一个 tuple。
if (ExecNewQual(joinqual, econtext)) {
result = ExecProject(node->js.ps.ps_ProjInfo, &is_done);
return result
}示例3 index scan & index only scan
# Index on t(a,b,c)
# select a,b,c from t where a = 1 and c = 1;
Index Only Scan using t_a_b_c_idx on t (cost=0.15..8.26 rows=1 width=12)
Index Cond: ((a = 1) AND (c = 1))
# select a,b,c from t where a = 1 and c <> 1;
Index Only Scan using t_a_b_c_idx on t (cost=0.15..32.35 rows=10 width=12)
Index Cond: (a = 1)
Filter: (c <> 1)
# select * from t where a = 1 and c <> 1 and d = 1;
Index Scan using t_a_b_c_idx on t (cost=0.15..32.36 rows=1 width=16)
Index Cond: (a = 1)
Filter: ((c <> 1) AND (d = 1))之前很多人搞不清楚这里面 index cond/ filter 是什么关系。但是,通过执行器源码很容易得知它们的用处。先看 IndexOnlyScan:
## 首先,通过 Explain 可以看出来,Index Cond 显示的是 plan->indexqual, Filter 显示的是 plan->qual。
optutil_explain_proc_node:
caesT_IndexOnlyScan:
optutil_explain_show_scan_qual(((IndexOnlyScan *)plan)->indexqual, "Index Cond", planstate, ancestors, es);
optutil_explain_show_scan_qual(plan->qual, "Filter", planstate, ancestors, es);
## 通过 Init 函数,发现 这两个 qual 分别被初始化为 Expr,赋给 ss.ps.qual 和 indexqual 上面。
ExecInitIndexOnlyScan
indexstate->ss.ps.qual = ExecInitExpr((Expr *) node->scan.plan.qual, (PlanState *) indexstate);
indexstate->indexqual = (List *) = ExecInitExpr((Expr *) node->indexqual,
// 用 indexqual 来做Scan 的key
ExecIndexBuildScanKeys((PlanState *) indexstate,
indexstate->ioss_RelationDesc,
node->indexqual....
## 在执行的时候发现,indexqual 在索引扫描内部使用, ps.qual 是用在扫描之后的 check 中。
ExecIndexOnlyScan
--->ExecScan
qual = node->ps.qual; // 注意,这里用的是 qual。
slot = ExecScanFetch(node, accessMtd, recheckMtd);
----> IndexOnlyNext
tid = index_getnext_tid(scandesc, direction) // 调用 btree 相关函数
// 用 IndexTuple 来填充 scan 的 slot (IndexScan是根据 tid 回表去 heap 上读取)
StoreIndexTuple(slot, scandesc->xs_itup, scandesc->xs_itupdesc);
// 用 qual 做过滤条件
if (!qual || ExecQual(qual, econtext, false))
返回 slot
btgettuple
_bt_steppage
_bt_readpage
_bt_checkkeys // 每个页面会挨个检查一下 ScanKey 的条件是否满足总结:
-
Index Cond 是用来做 btree 扫描的 key,定位到第一个 IndexTuple。存储引擎中用
-
之后索引扫描会顺着 btree 的链表扫描所有的叶子页面,对叶子页面上的每一个 tuple 用 ScanKey 检查是否满足条件,满足再返回
-
Filter 是在 执行器层用,针对 HeapTuple 再做一次过滤
-
IndexOnlyScan 和 Index Scan的唯一区别是,IndexOnlyScan 的HeapTuple是根据IndexTuple直接构建的,不需要回表,其它逻辑是一样。
-
所以理论上讲 IndexOnlyScan 不应该出现 filter,上述场景可能有改进空间。
openGauss: 一款高性能、高安全、高可靠的企业级开源关系型数据库。
🍒如果您觉得博主的文章还不错或者有帮助的话,请关注一下博主,如果三连收藏支持就更好啦!谢谢各位大佬给予的鼓励!