近期ChatGPT很火爆,功能很强大,其具有强大的逻辑推理能力和数据背景。但是如果我们想要使用ChatGPT聊一些它没有训练过的知识,或者我们自己的一些数据时,由于ChatGPT没有学习过这些知识,所以回答结果不准确。
下文就介绍一种基于llama-index和ChatGPT API实现的基于你自己提供的数据来定制私有对话机器人的方式。
探索方法
1、想要定制基于自己专属数据的机器人,首先想到的是fine-tunes微调的方式。用大量的数据对GPT模型进行微调来实现一个可以理解你提供文档的模型。但是,微调需要花费很多money,而且需要一个有实例的大数据集。也不可能在文件有变化时每次都进行微调。更关键的一点是,微调根本不可能让模型 “知道 “文档中的所有信息,而是要教给模型一种新的技能。因此,微调不是一个好办法。
2、将你的私有文本内容作为prompt的上下文对ChatGPT进行提问。但是openai api存在最大长度的限制,ChatGPT 3.5的最大token数为4096,如果超过长度限制,会直接对文档截断,存在上下文丢失的问题。并且api的调用费用和token长度成正比,tokens数太大,则每次调用的成本也会很高。
既然tokens有限制,那么有没有对文本内容进行预处理的工具呢,使不超过token数限制。llama-index就是一种这种工具,借助llama-index可以从文本中只提取出相关部分,然后将其反馈给prompt。
接下来我将给出一个使用llama-index和ChatGPT API基于自己的数据,实现问答聊天机器人的分步教程。
前期准备:
OpenAI API密钥,可以在https://platform.openai.com/account/api-keys查看。如果还没有申请,可以查阅资料申请OpenAI API的密钥。使用OpenAI API密钥可以与openai提供的各种模型进行交互。
一个文档资料数据库。llama-index支持许多不同的数据源,如API、PDF、文档、SQL 、Google Docs等。在本教程中,我们只使用一个简单的文本文件进行演示。
本地的Python环境或在线的Google Colab。本教程中使用本地的Python环境演示。
流程:
安装依赖:
pip install openai
pip install llama-indexfrom llama_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper,ServiceContext
from langchain import OpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'your openai api key'
data_directory_path = 'your txt data directory path'
index_cache_path = 'your index file path'
#构建索引
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 2000
max_chunk_overlap = 20
chunk_size_limit = 500
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=num_outputs))
# 按最大token数500来把原文档切分为多个小的chunk
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, chunk_size_limit=chunk_size_limit)
# 读取directory_path文件夹下的文档
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
# 保存索引
index.save_to_disk(index_cache_path)
return index
def chatbot(input_text):
# 加载索引
index = GPTSimpleVectorIndex.load_from_disk(index_cache_path)
response = index.query(input_text, response_mode="compact")
return response.response
if __name__ == "__main__":
#使用gradio创建可交互ui
iface = gr.Interface(fn=chatbot,
inputs=gr.inputs.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Text AI Chatbot")
index = construct_index(data_directory_path)
iface.launch(share=True)在construct_index方法中,使用llama_index的相关方法,读取data_directory_path路径下的txt文档,并生成索引文件存储在index_cache_path文件中。当执行此python文件时,会执行construct_index方法,在控制台中输出:
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total embedding token usage: 27740 tokens
Running on local URL: http://127.0.0.1:7860可以看到输出原文档有27740 tokens,这也是请求embedding接口的调用成本。此token是llama_index生成的,不会占用ChatGPT api的token。
然后在浏览器中输入控制台输出的url:http://127.0.0.1:7860。会展示gradio框架渲染的ui,如下所示:
在左侧输入What did the author do in 9th grade?,在右侧输出如下:
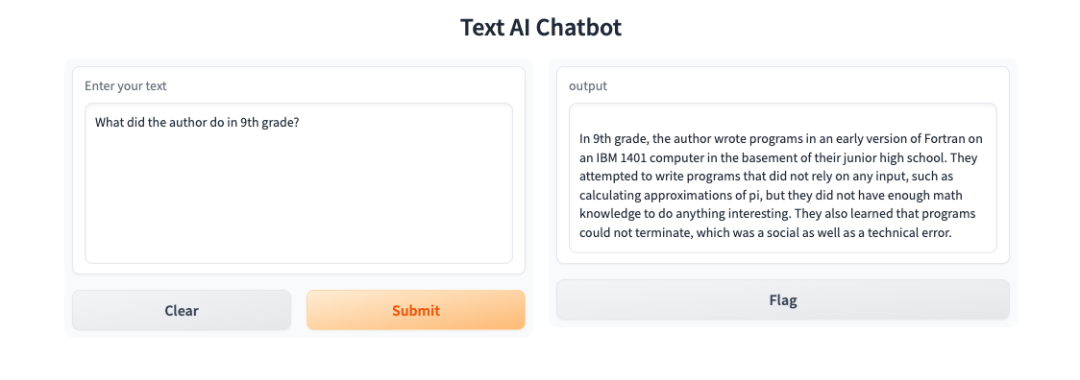
同时控制台输出
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 563 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 10 tokens使用OpenAI text-davinci-003模型花费的token为563 tokens。通过这种方法,原来接近28000 token的查询调用成本,被降到了500 tokens左右。
llama-index的工作原理如下:
创建文本块索引
找到最相关的文本块
使用相关的文本块向 GPT-3(或其他openai的模型) 提问
在调用query接口的时候,llama-index默认会构造如下的prompt:
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}\n"使用以上prompt请求openai 的模型时,模型根据我们提供的上下文和提出的问题,使用其逻辑推理能力得到我们想要的答案。
扩展:
上文展示了使用llama-index关联txt文本文档,使用ChatGPT模型的推理能力进行问答的方式。我们可以扩展一下其他的使用方式。
llama-index这个库不止能链接txt文本文档,也提供了大量各种类型的 DataConnector,既包括 PDF、ePub 这样的电子书格式,也包括 YouTube、Notion、MongoDB 这样外部的数据源、API 接入的数据,或者是本地数据库的数据。开源库(https://github.com/jerryjliu/llama_index/blob/main/gpt_index/readers/file/base.py)中可以看到内置支持的链接数据类型,也可以在 llamahub.ai (https://llamahub.ai/)看到社区开发出来的读取各种不同数据源格式的 DataConnector。
借助llama-index与pdf文档的链接,我们可以实现类似于chatpdf(https://www.chatpdf.com/ )的功能。也可以使用llama-index的ImageParser识别图片,与ChatGPT交流图片中的内容......。更多的使用场景等待你的发现与扩展。
总结:
在本文中,我们将ChatGPT与llama-index结合起来使用,建立一个文档问题问答的聊天机器人。虽然ChatGPT(和其他LLM)本身就很强大,但如果我们把它与其他工具、数据或流程结合起来,它的力量就会被大大放大。通过本文的介绍,希望你也能够将自己的数据集交给 AI 进行索引,获得一个专属于你自己的 AI机器人。
参考资源
https://github.com/jerryjliu/llama_index
https://zhuanlan.zhihu.com/p/613155165
https://www.wbolt.com/building-a-chatbot-based-on-documents-with-gpt.html
https://time.geekbang.org/column/article/645305
文中使用的文档是llama_index example的文档:https://github.com/jerryjliu/llama_index/blob/c811e2d4775b98f5a7cf82383c876018c4f27ec4/examples/paul_graham_essay/data/paul_graham_essay.txt
- END -
关于奇舞团
奇舞团是 360 集团最大的大前端团队,代表集团参与 W3C 和 ECMA 会员(TC39)工作。奇舞团非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。