欢迎关注博主 Mindtechnist 或加入【Linux C/C++/Python社区】一起探讨和分享Linux C/C++/Python/Shell编程、机器人技术、机器学习、机器视觉、嵌入式AI相关领域的知识和技术。
python正则表达式与re模块
- 正则表达式
- 元字符
- ① `.` 通配符
- ② `^`
- ③ `$`
- ④ `*`
- ⑤ `+`
- ⑥ `?`
- ⑦ `{}`
- ⑧ `[]`
- ⑨ `\` 转义符
- ⑩ `()` 分组
- ⑾ `|` 或
- re模块常用方法
专栏:《python从入门到实战》
正则表达式
正则表达式即字符串模糊匹配,用于处理字符串。就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,在Python中它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
- 普通字符:大多数字符和字母都会和自身匹配,即完全匹配(每个字符一对一匹配),比如find/findall等方法。
- 元字符:
. ^ $ * + ? { } [ ] | ( ) \,前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配。
元字符
① . 通配符
通配符可以匹配除了换行符\n之外的任何字符,一个点只能代表一个字符。

② ^
表示必须在开头才能匹配成功,要匹配的字符串必须在目标字符串开头 。
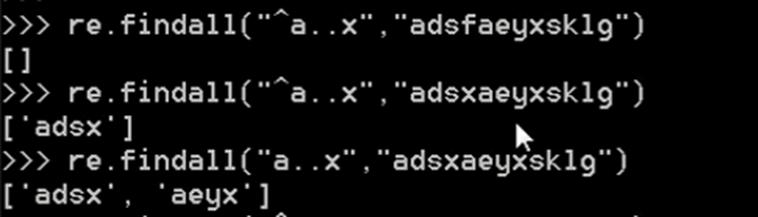
③ $
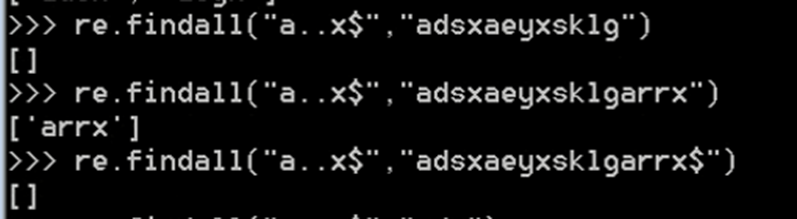
只有在结尾才能匹配成功,要匹配的字符串必须在目标字符串尾部。
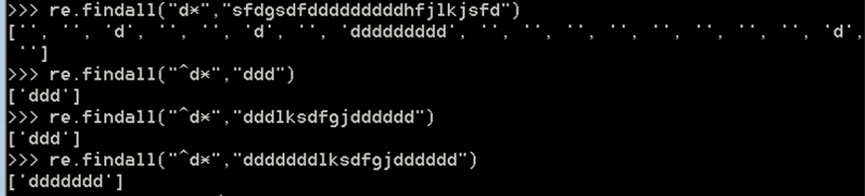
④ *
匹配重复的字符(任意个重复字符:0-无穷个),没有该字符表示匹配到0个,贪婪匹配 ,尽可能匹配多的,按最多的重复次数去匹配比如*虽然可以匹配0个,但是如果有3个重复的字符会按照3个去匹配,而不是0个(尽可能匹配多),仅匹配*前面的一个字符。
⑤ +
匹配重复字符(1-无穷个),至少要匹配到一个,也是贪婪匹配,仅匹配+前面的一个字符。
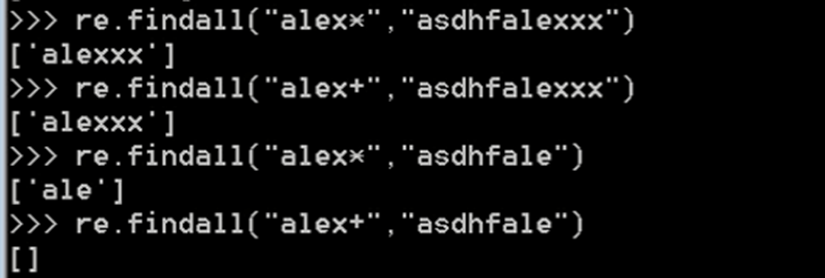
⑥ ?
匹配0或1次,贪婪匹配,仅匹配?前面的一个字符。

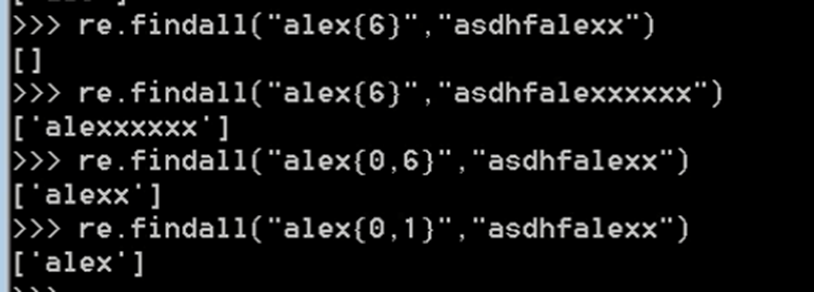
⑦ {}
自定义匹配次数 {0, }相当于* , {1, }相当于+ , {0, 1}相当于? , {6}表示匹配6次重复字符。

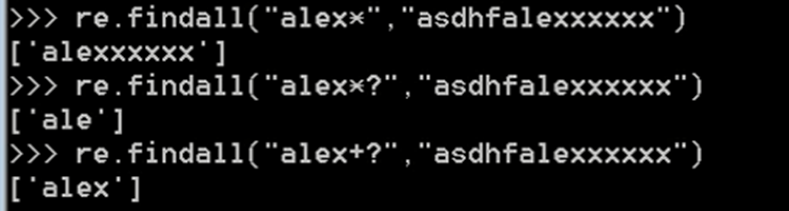
⑧ []
字符集,在字符集内都是普通字符,包括*?等都是普通字符,但是有3个字符是有特殊意义的 ^ - \ 。-表示范围,按ascii码的顺序排列的范围,[a-z]表示a到z所有的字符;^表示非,[^a-z]表示匹配不是a-z的字符;\是转义符,去除元字符的特殊功能或者给普通字符加上特殊功能。
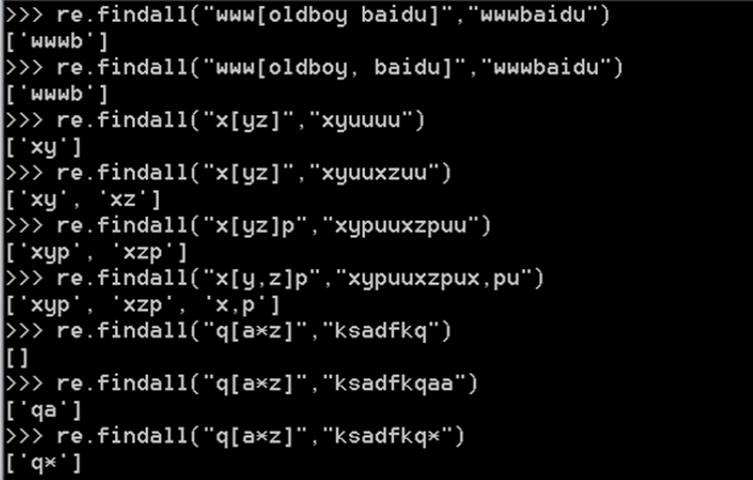
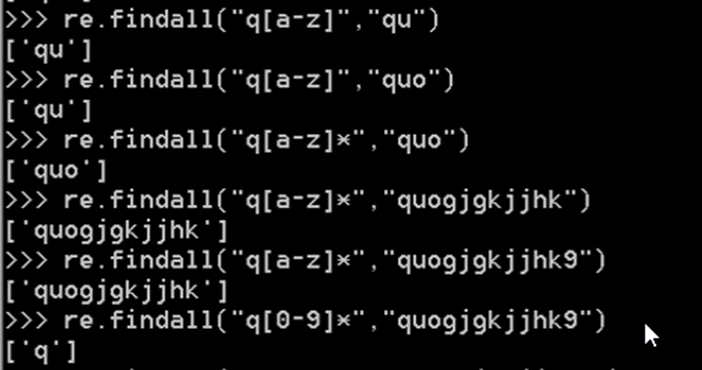
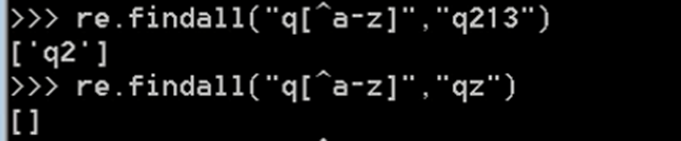
示例:
ret=re.findall('a[bc]d','acd')
print(ret)#['acd']
ret=re.findall('[a-z]','acd')
print(ret)#['a', 'c', 'd']
ret=re.findall('[.*+]','a.cd+')
print(ret)#['.', '+']
#在字符集里有功能的符号: - ^ \
ret=re.findall('[1-9]','45dha3')
print(ret)#['4', '5', '3']
ret=re.findall('[^ab]','45bdha3')
print(ret)#['4', '5', 'd', 'h', '3']
ret=re.findall('[\d]','45bdha3')
print(ret)#['4', '5', '3']
⑨ \ 转义符
反斜杠后边跟元字符去除特殊功能,比如\.,反斜杠后边跟普通字符实现特殊功能,比如\d。具体如下:
\d匹配任何十进制数,它相当于[0-9]。\D匹配任何非数字字符,它相当于[^0-9]。\s匹配任何空白字符,它相当于[ \t\n\r\f\v]。\S匹配任何非空白字符,它相当于[^ \t\n\r\f\v]。\w匹配任何字母数字字符,它相当于[a-z A-Z 0-9 _]。\W匹配任何非字母数字字符,它相当于[^a-zA-Z0-9_]。\b匹配一个特殊字符边界,比如空格&,#等。
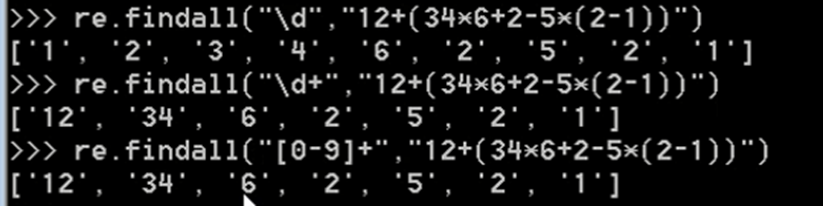
示例
import re
ret=re.findall('c\l','abc\le')
print(ret)#[]
ret=re.findall('c\\l','abc\le')
print(ret)#[]
ret=re.findall('c\\\\l','abc\le')
print(ret)#['c\\l']
ret=re.findall(r'c\\l','abc\le')
print(ret)#['c\\l']
特殊情况:python解释器遇上re转义符
m = re.findall('\bblow', 'blow')
print(m)
m = re.findall(r'\bblow', 'blow')
print(m)
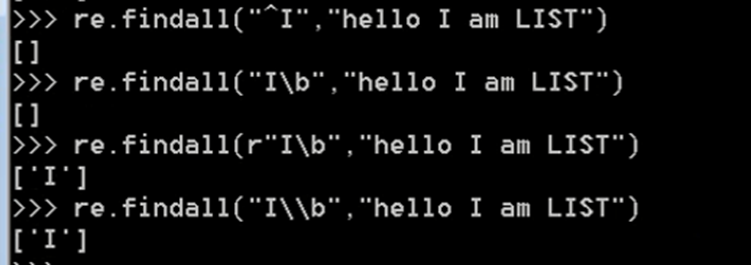
我们在终端或者PyCharm中写的程序都是由python解释器来执行的,在re语言中\b是可以代表空格的,这没问题,但是我们在re.findall(“I\b”, “h I am”)中使用\b的时候,这条语句是被python解释器执行的,而\b在python中本身就是有特殊含义的(python中\也是转义符),当python拿到这句话re.findall(“I\b”, “h I am”)的时候,它会把\b翻译成python中所代表的含义,然后把翻译后的内容扔到re模块中,所以,到了re模块后\b已经不是\b了,而是其它内容(python解释器翻译后的内容)。解决方法有:
re.findall(r“I\b”, “h I am”)r表示原生字符串,告诉python解释器不做任何转义,这样python解释器传给re模块的\b就是\b,python解释器这一层不会做任何操作;re.findall(“I\\b”, “h I am”)python解释器遇到\开始转义\\就是把\的转义功能去掉,变成一个普通字符\,这样python解释器传给re模块的也是\b本身。

re.findall(“a\\\\k”, “a\k”) 相当于 re.findall(r“a\k”, “a\k”) ,传给re的只有\\两个反斜杠,表示去除\的特殊含义,也就是匹配\k。
⑩ () 分组
m = re.findall(r'(ad)+', 'add')
print(m)
ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group())#23/com
print(ret.group('id'))#23

?P<name>表示把匹配的内容做一个分组叫name,我们可以通过name取值。
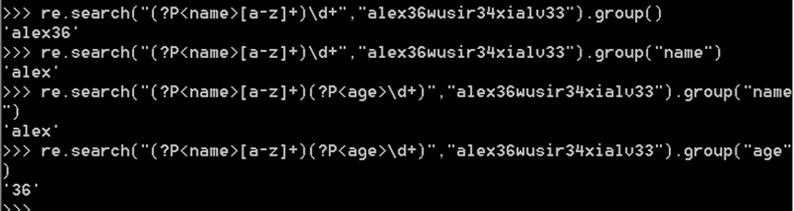
()是有优先级的,会优先返回分组内的字符串,可以通过?:去掉括号优先级。

⑾ | 或
re模块常用方法
导入模块
import re
1、 findall 匹配所有并返回为列表
返回所有满足匹配条件的结果,放在列表里。匹配所有,返回列表。
re.findall('a','alvin yuan')
2、 search 匹配第一个并返回对象
函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。匹配第一个,匹配成功返回对象,匹配失败返回None。
re.search('a','alvin yuan').group()

3、 match 仅匹配头部,并返回对象
re.match('a','abc').group() #同search,不过仅在字符串开始处进行匹配
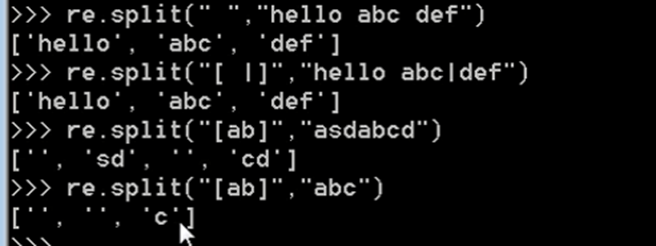
4、 split 分割字符串
ret=re.split('[ab]','abcd') #先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) #['', '', 'cd']
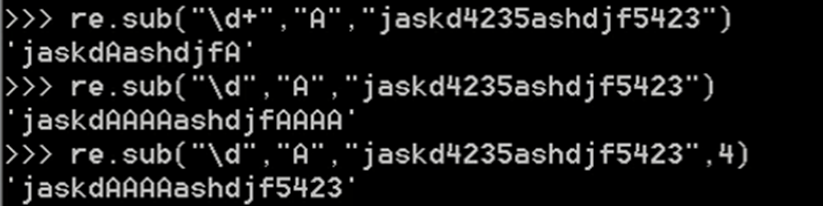
5、 sub 替换
ret=re.sub('\d','abc','alvin5yuan6',1) #仅匹配前1次
print(ret)#alvinabcyuan6
ret=re.subn('\d','abc','alvin5yuan6') #返回元组(匹配后字符串,匹配次数)
print(ret)#('alvinabcyuanabc', 2)

6、 compile 编译
obj=re.compile('\d{3}') #把规则提前编译好
ret=obj.search('abc123eeee')
print(ret.group())#123

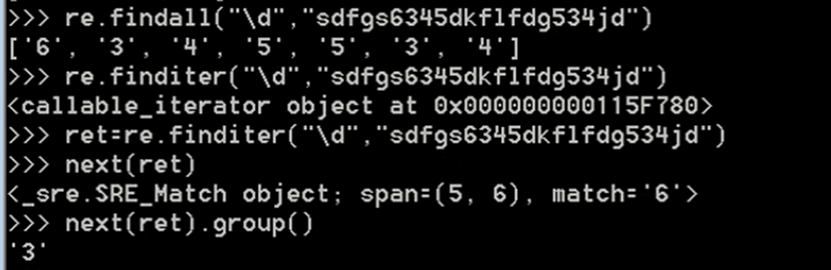
7、 finditer编译
import re
ret=re.finditer('\d','ds3sy4784a')
print(ret) #<callable_iterator object at 0x10195f940>
print(next(ret).group())
print(next(ret).group())
findall把所有结果放到一个列表中,finditer把结果放到一个迭代器中并返回一个迭代器对象,在大数据场景中,使用迭代器可以需要一条就处理一条,高效省内存。
注意事项
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)#['oldboy']
这是因为findall会优先把匹配结果分组里的内容返回,如果想要匹配结果,取消权限即可,在匹配规则中如果使用了分组,findall会优先把分组内的匹配内容返回出来,可通过?:去优先级来返回全部匹配结果。分组的符号()是有优先级的,括号内优先级高,通过?:就可以去掉()的优先级。
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)#['www.oldboy.com']