前人之述备矣
教程:Python虚拟环境+Scrapy+PyCharm 使用实例 - 知乎
注意:是cmd不是powershell,两者还是有区别的。 因为是本地的虚拟环境,用cmd激活环境并且安装相关的scrapy包,如果用powershell,在pycharm中显示不了安装的包。
PowerShell 与 cmd 有什么不同? - 知乎
如何快速打开cmd或powershell?
1.win+R打开“运行”,然后输入cmd或powershell,回车进入;
2.可在打开的文件夹内,直接在地址栏输入cmd或powershell,回车进入;
3.在Windows的搜索应用中输入cmd或powershell,回车进入。安装好之后检查:
正式开始:
scrapy startproject CodeSpider //创建一个项目
创建成功如下:
文件结构:


选择抓取页面:
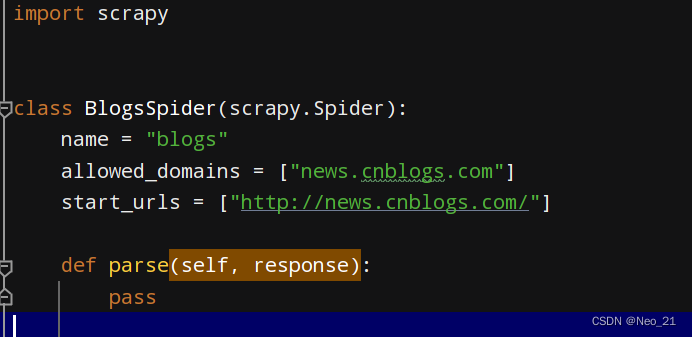
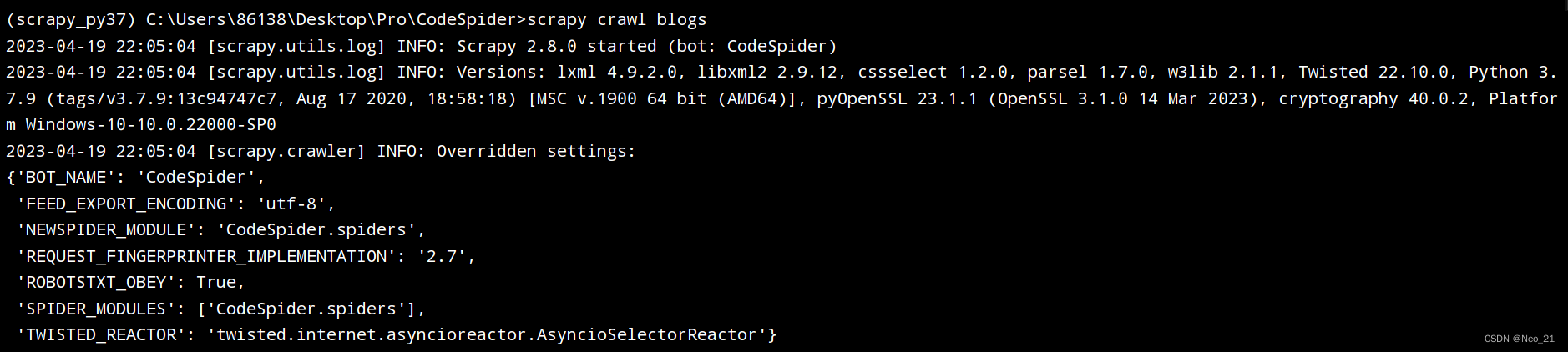
scrapy genspider blogs news.cnblogs.com
抓取模板,可以按照自己的需求修改模板。

需求分析:
采集静态数据,大部分网站都是动态的。
典型的分页数据:
采集详细信息:将所有页面采集下来-->详细信息:发布时间,内容,评论等
抓取所有文章的url.
scrapy调试:
- 在cmd中启动命令,不可调试:scrapy crawl blogs(name)
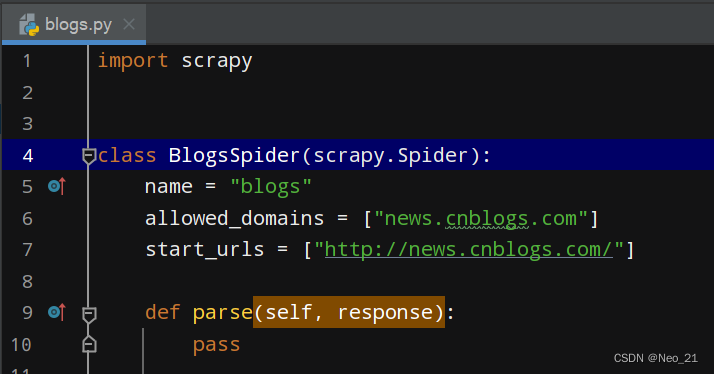
- 创建新的脚本进行调试:
在根目录文件夹中重新新建一个main文件,只要继承了crawl文件中的scrapy.Spider就可以
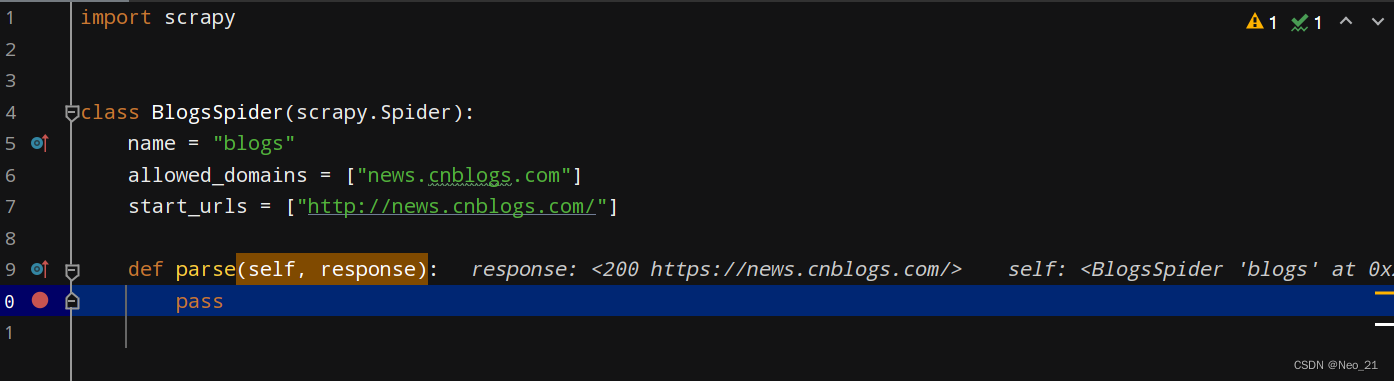
执行:
可以在断点之后看见response的信息,self和response:

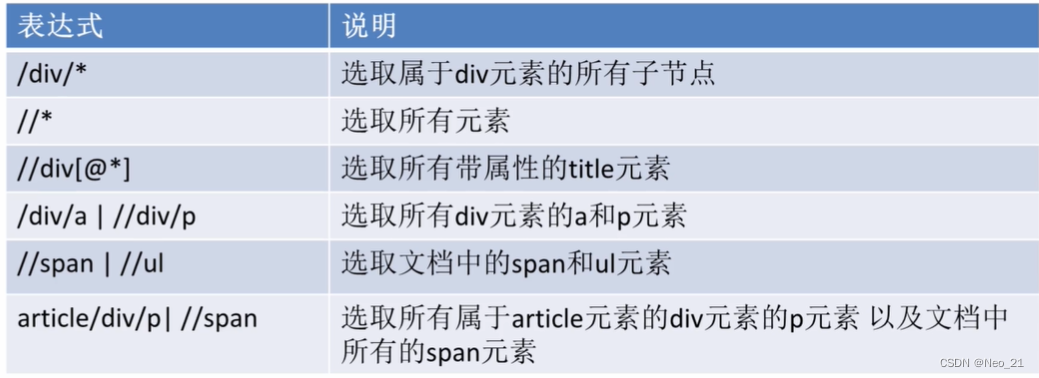
xpath解析:
独立的语法,与各种库不同,可以兼容各种库。
- xpath简介:学爬虫利器XPath,看这一篇就够了 - 知乎
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。

使用xpath提取想要的值:
response参数:使用xpath就可以提取

通过复制xpath:
缺点:如果数据刷新,无法提取到正确数据。
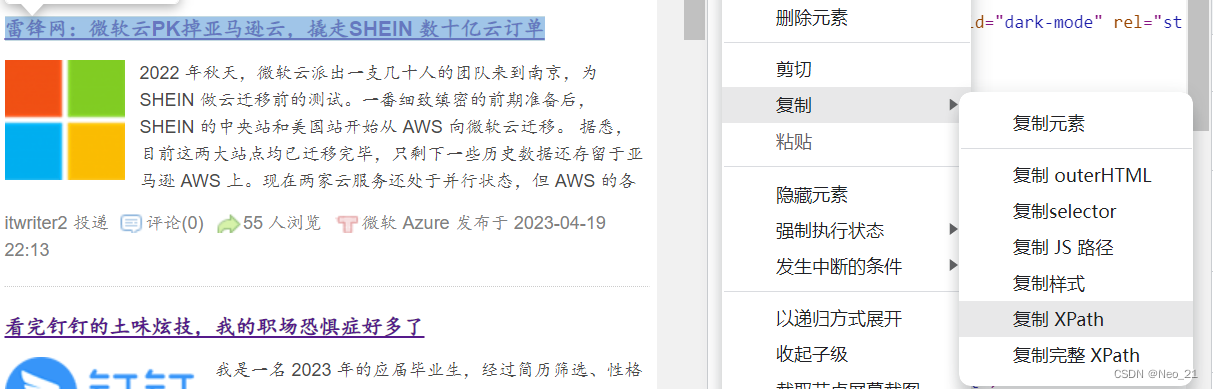
// *[ @ id = "entry_740378"] / div[2] / h2 / a提取出所有满足条件的:

使用特殊的设置,巧妙的xpath

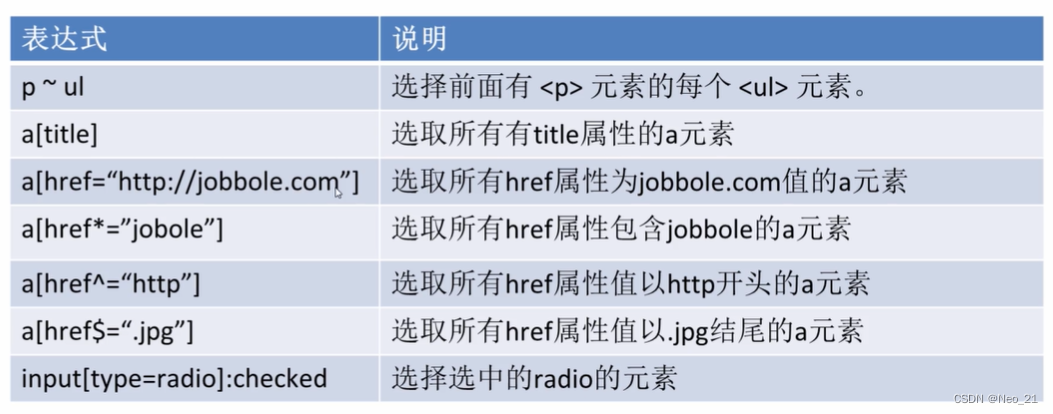
使用css选择器提取:
没有xpath强大,使用css样式选择,解析出合适的内容:如h2

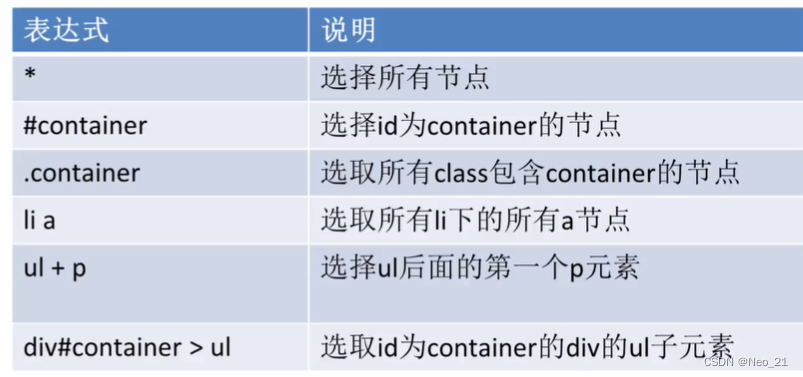
url = response.css('div#news_list h2 a::attr(href)').extract()
爬虫抓取过程:
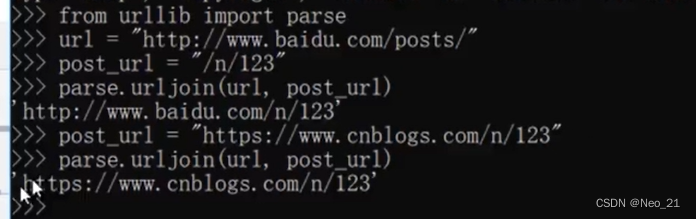
使用parse,做了很多处理,获取url.