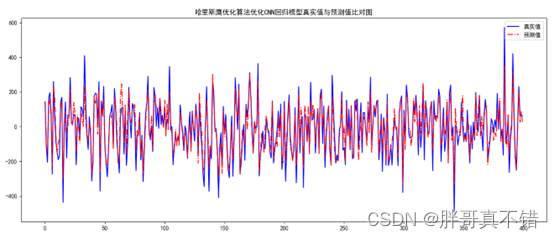
作品展示:

背景需求
3*4块运动拼图对幼儿有点难(不熟悉图案内容、拼图数量多)
1、选择幼儿相对熟悉的的字母(26个,基本满足28人)
2、拼图数量:2*3=6块
3、做的小一点,一张2份(含拼图和黏贴纸)
考虑到幼儿第一次做,字母图案不能太多(A-Z太多了,最后累的还是老师),所以选了ABCD四个字母,复制7套
A -D 图片拼图-华文彩云-CNKI
'''
项目:大写字母矢量图的2*3格拼图ABCD 1页两份
作者:阿夏
日期:2023年4月19日21:47
'''
nunu=int(input('生成多少人(28人)\n'))
# num=int(input('生成多少份(4 ABCD四个字母)\n'))
Number=int(input('随机抽取几个图片(6个)\n'))
print('----------第1步:19张大写字母PNG图片*每张图片切割12张----------------')
# 源代码: https://blog.csdn.net/qq_34777982/article/details/125019068?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-125019068-blog-129622294.235^v29^pc_relevant_default_base3&spm=1001.2101.3001.4242.2&utm_relevant_index=4
# Python 裁剪九宫格图片 —— 筑梦之路
import sys
import os
from PIL import Image
# 生成A-D的字母 只要四个,遍历7次
small = [chr(i) for i in range(ord('A'),ord('D')+1)]
print(small)
# ['A', 'B', 'C', 'D']
# 把文字转成图片
#载入必要的模块
import pygame
#pygame初始化
pygame.init()
for w in range(len(small)):
# 待转换文字
text = u" {} ".format(small[w])
#设置字体和字号
# font = pygame.font.SysFont('Arial Black', 2000)
font = pygame.font.SysFont('华光彩云_CNKI', 2000)
# Microsoft YaHei'
# Huhtikuu
# HGKY_CNKI
# 华文彩云_CNKI
#渲染图片,设置背景颜色和字体样式,前面的颜色是字体颜色
ftext = font.render(text, True,(220, 220, 220),(255, 255, 255))
# image = Image.new("RGB", (40, 40))
#保存图片
pygame.image.save(ftext, r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图0\{}-{}.jpg".format('%02d'%(w+1),small[w]))#图片保存地址
# 批量调整图片的大小
from PIL import Image
import os
# 原始文件夹路径
original_folder = "C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/大写字母拼图0"
# 保存的新文件夹路径
new_folder = "C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/大写字母拼图"
# 遍历原始文件夹中的图像
for filename in os.listdir(original_folder):
img = Image.open(os.path.join(original_folder, filename))
# 改变尺寸
img_resized = img.resize((400, 600)) #这里是你要转换的尺寸
# 保存到新文件夹
img_resized.save(os.path.join(new_folder, filename))
file_root = r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图" #要切的图片放的文件
fileList = []
n = 0
#读取文件列表
def read_bmp_file_list(path):
for root, dirs, files in os.walk(path, topdown=False):
for file in files:
fileList.append(os.path.join(root, file))
#开始切图
def qie_tu(file_path):
global n
im = Image.open(file_path)
# 图片的宽度和高度(原始图片大小1280 720)
img_size = im.size
print("j小图片宽度和高度分别是{}".format(img_size))
#切成512X512
x = 0
y = 0
w = 200 # 列几条?400/2
h = 200 # 行几条?600/3
for j in range(0,3):
for i in range(0,2):
#region = im.crop((x, y, x+w*i, y+h*j))
print(x+w*i, y+h*j,x+w*i+w, y+h*j+h)
region = im.crop((x+w*i, y+h*j,x+w*i+w, y+h*j+h))
#文件输出位置
region.save(r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图1\{name}.jpg".format(name='%03d'%n))
n=n+1
if __name__ == '__main__':
read_bmp_file_list(file_root)
for f in fileList:
qie_tu(f)
# print('----------第2步:读取图片,写入模板----------------')
import os
from PIL import Image
print('----------第1步:提取图片路径------------')
path=[]
pr="C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\大写字母拼图\\大写字母拼图1"
# 过滤:只保留png结尾的图片
imgs1=os.listdir(pr)
for img1 in imgs1:
if img1.endswith(".jpg"):
path.append(pr+'\\'+img1)
# 所有图片的路径
print(path)
# 216条路径(18张*12图)
print(imgs1)
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nnnnn in range(1,int(nunu/len(small))+1): # 循环7次1-7
for nn in range(0,int(len(small)/2)): #ABCD的长度
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图模板.docx')
# # 制作列表
# 从左边图列表和右边图列表中抽取图片(12张图片,可能5个向左、7个向右边)
# 24条里面0和12条是一组,2个里面随机抽1一个,1和13是一组,2个里面随机抽一个…… 抽出12个图片后
r=[]
c=[]
r.append(path[nn*12:nn*12+12]) # 连续12张图片、2份字母插入同一份A4
# r.append(path[nn*24:nn*24+24]) # 连续12张图片、2份字母插入同一份A4
# print(r)
# 再打乱顺序读取12个
for a in r:
for b in a:
c.append(b)
print(c)
figures1=random.sample(c[0:6],Number) # 前6张不重复打乱
figures2=random.sample(c[6:12],Number) # 后6张不重复打乱
# figures3=random.sample(c[12:18],Number) # 后6张不重复打乱
# figures4=random.sample(c[18:24],Number) # 后6张不重复打乱
# 12张不重复打乱图片合并
figures=figures1+figures2
# figures=figures1+figures2+figures3+figures4
print(figures)
for z in range(2): # 5行组合循环2次 每页两张表
# 单元格位置3*4格
bg=[]
for x in range(0,3): # 3行
for y in range(0,2): # 4列
ww='{}{}'.format(x,y)
bg.append(ww)
print(bg)
# bg=['00', '01', '10', '11', '20', '21', '03', '04', '13', '14', '23', '24']
table = doc.tables[z]
for t in range(len(bg)): # 02
pp=int(bg[t][0:1])
qq=int(bg[t][1:2])
# print(p)
k=figures[z*6:z*6+6][t]
print(pp,qq,k)
# 写入图片
run=doc.tables[z].cell(pp,qq).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(k),width=Cm(4.55),height=Cm(3.852))
# 单元格宽度4.65 3.94
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\零时Word\{}.docx'.format('%02d'%nnnnn*(nn+1)))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word/{}.docx".format('%02d'%nnnnn*(nn+1)) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word/{}.pdf".format('%02d'%nnnnn*(nn+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/(打印合集)大写字母拼图A4一页两份{}_{}个字母(2乘3张){}人共{}份).pdf".format(small,len(small),nunu,int(nunu/2)))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word') #递归删除文件夹,即:删除非空文件夹
运行过程:
打印结果:






担心孩子们做的太快,再准备打洞机和线段(做手签)

教学展示版

操作说明:
活动时间:2023年4月20日 8:20-8:50
人员:中6班 23人
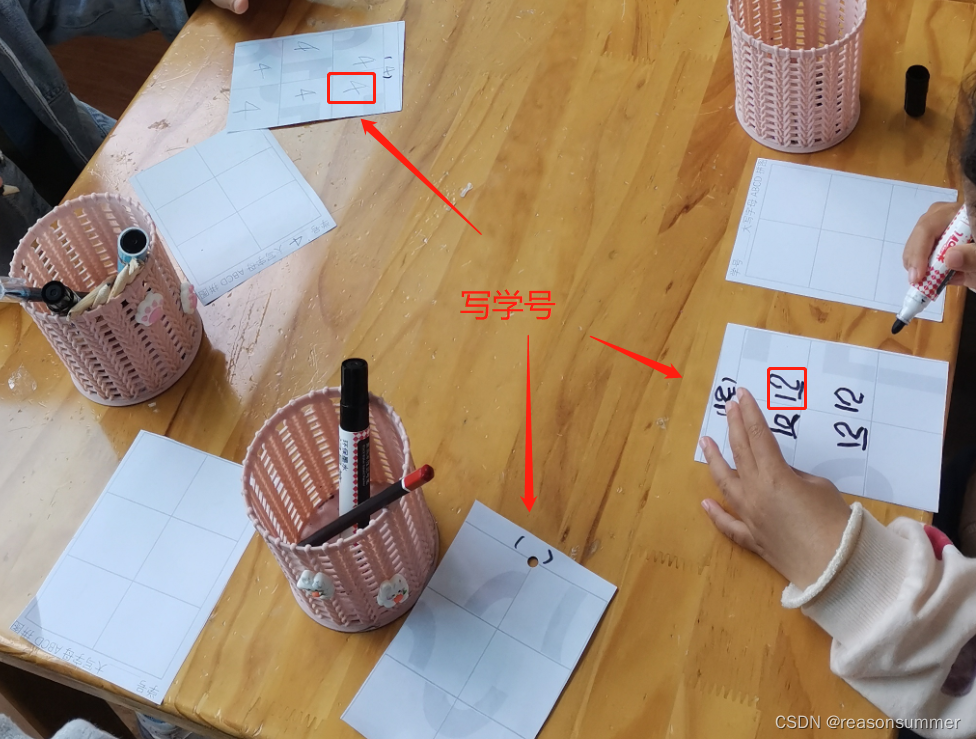
1、写大量学号(今天4月20日)

2、剪下卡片,摆好位置,再黏贴、勾边

幼儿操作照片







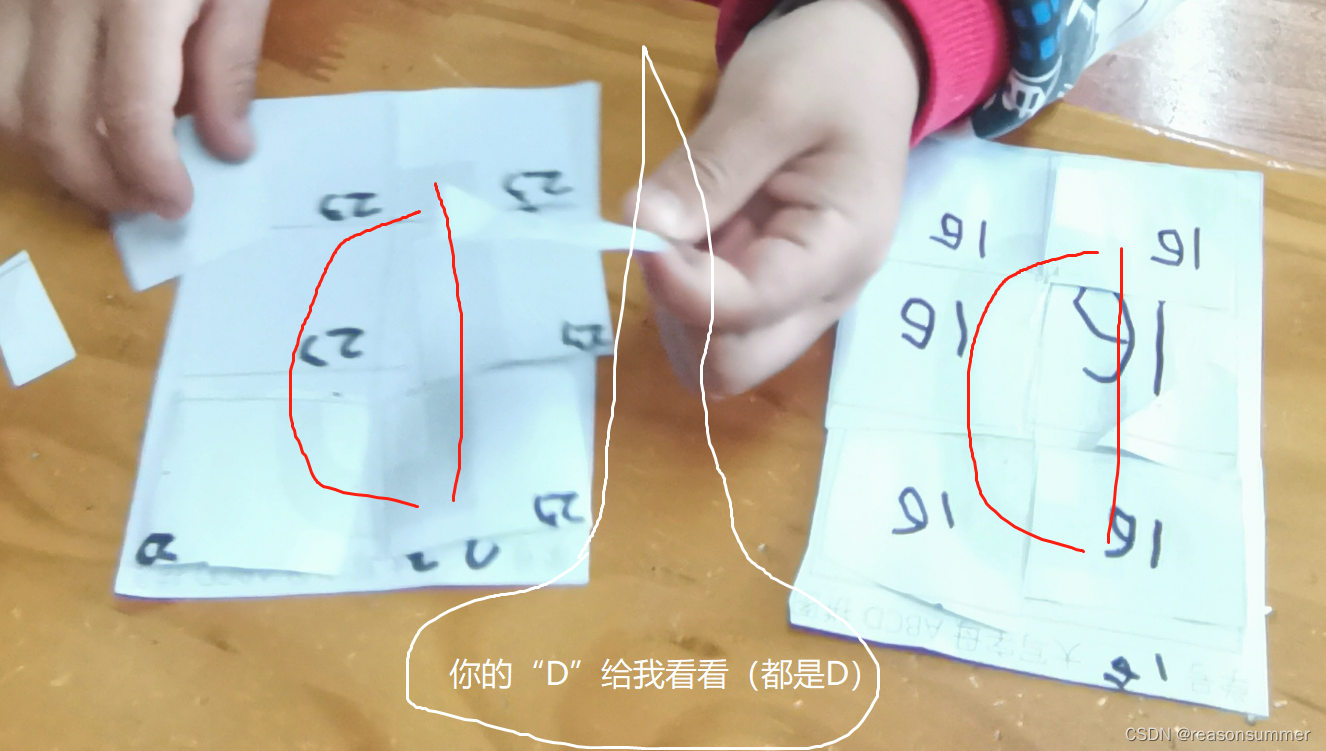


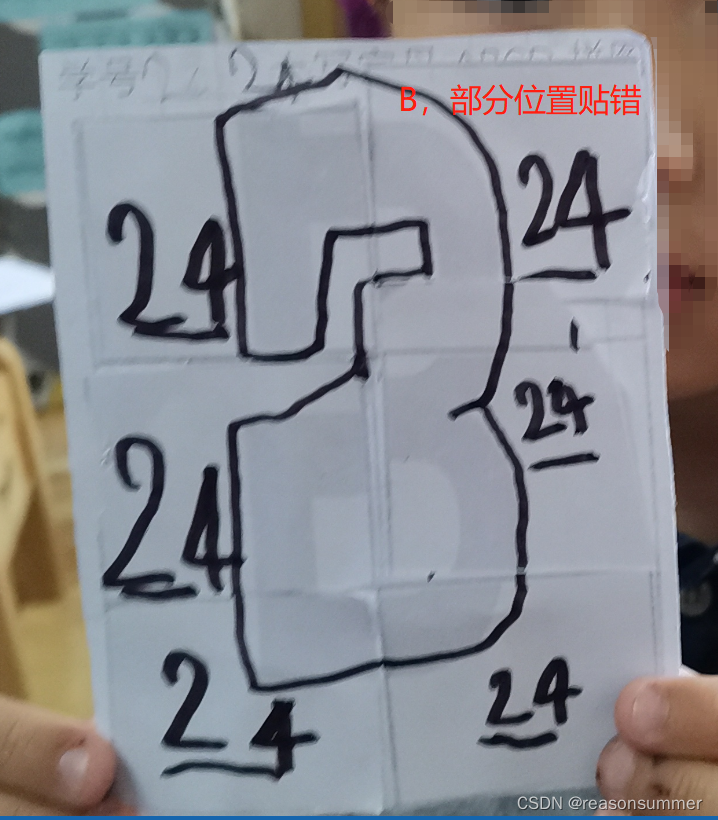

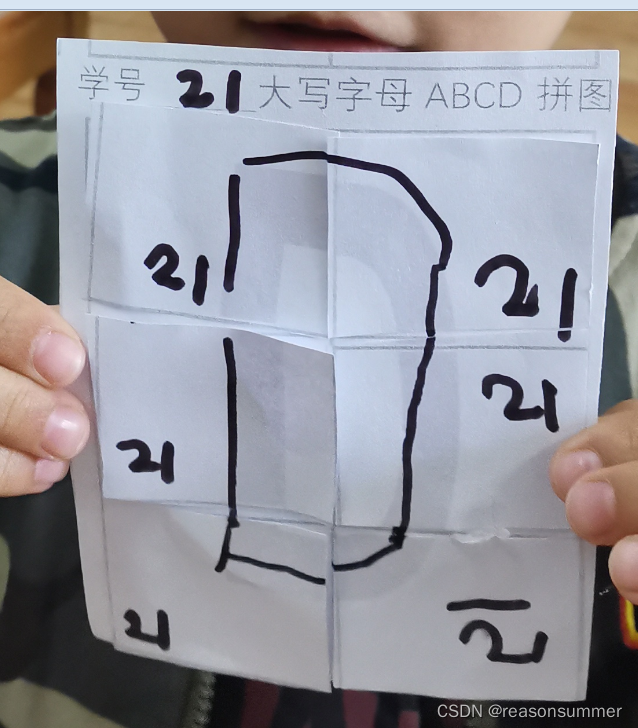



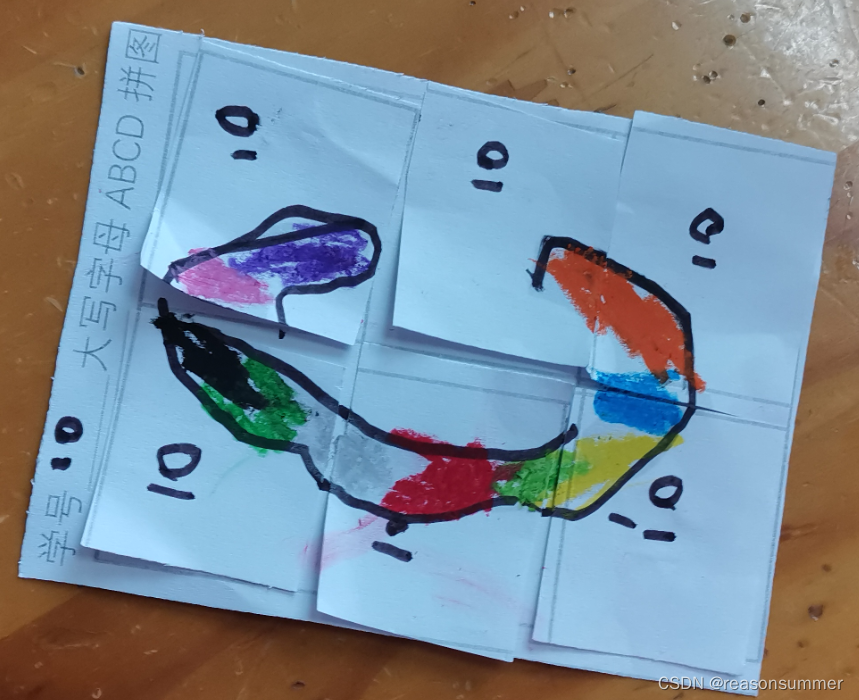

作品拍照及ABCD分类
A:4人、B:7人 C:5人、D:7人

优化思考:
0、半数孩子需要老师指点摆放。
活动中半数孩子无法正确拼图,都是3位老师指点的。因此没有时间让幼儿打洞和穿线练习。
所有幼儿都认真进行了6块卡片的学号书写(有2位孩子写了12张卡片,并把黏贴纸也剪掉了,教师又给了两张黏贴纸衬纸。)
1、字母的灰色调深。
便于幼儿看清楚图形(浅灰看不清楚)。但也不能太深(我还希望幼儿涂色、勾线),测试200、150、100三款色彩

2、模板顶部加括号,辨识卡片纸摆放方向
(没有括号,幼儿拿到纸片,会转动纸片,可能写的学号与图形不是统一方向。)

存在问题,幼儿要多剪一块顶部的白条。桌面还是有白纸垃圾。

PS:制作所有的A_Z的拼图卡片
A -Z 图片拼图-华文彩云-CNKI(后
续试试做完全不同的字母)
'''
项目:大写字母矢量图的2*3格拼图A -Z 26个字母 1页两份
作者:阿夏
日期:2023年4月19日21:47
'''
num=int(input('生成多少份(26字母)\n'))
Number=int(input('随机抽取几个图片(6个)\n'))
print('----------第1步:19张大写字母PNG图片*每张图片切割12张----------------')
# 源代码: https://blog.csdn.net/qq_34777982/article/details/125019068?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-125019068-blog-129622294.235^v29^pc_relevant_default_base3&spm=1001.2101.3001.4242.2&utm_relevant_index=4
# Python 裁剪九宫格图片 —— 筑梦之路
import sys
import os
from PIL import Image
# 生成A-Z的字母
small = [chr(i) for i in range(ord('A'),ord('Z')+1)]
print(small)
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
# 把文字转成图片
#载入必要的模块
import pygame
#pygame初始化
pygame.init()
for w in range(len(small)):
# 待转换文字
text = u" {} ".format(small[w])
#设置字体和字号
# font = pygame.font.SysFont('Arial Black', 1000)
font = pygame.font.SysFont('华文彩云', 3000)
# 华文彩云
# Microsoft YaHei'
#渲染图片,设置背景颜色和字体样式,前面的颜色是字体颜色
ftext = font.render(text, True,(200, 200, 200),(255, 255, 255))
# image = Image.new("RGB", (40, 40))
#保存图片
pygame.image.save(ftext, r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图0\{}-{}.jpg".format('%02d'%(w+1),small[w]))#图片保存地址
# 批量调整图片的大小
from PIL import Image
import os
# 原始文件夹路径
original_folder = "C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/大写字母拼图0"
# 保存的新文件夹路径
new_folder = "C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/大写字母拼图"
# 遍历原始文件夹中的图像
for filename in os.listdir(original_folder):
img = Image.open(os.path.join(original_folder, filename))
# 改变尺寸
img_resized = img.resize((400, 600)) #这里是你要转换的尺寸
# 保存到新文件夹
img_resized.save(os.path.join(new_folder, filename))
file_root = r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图" #要切的图片放的文件
fileList = []
n = 0
#读取文件列表
def read_bmp_file_list(path):
for root, dirs, files in os.walk(path, topdown=False):
for file in files:
fileList.append(os.path.join(root, file))
#开始切图
def qie_tu(file_path):
global n
im = Image.open(file_path)
# 图片的宽度和高度(原始图片大小1280 720)
img_size = im.size
print("j小图片宽度和高度分别是{}".format(img_size))
#切成512X512
x = 0
y = 0
w = 200 # 列几条?400/2
h = 200 # 行几条?600/3
for j in range(0,3):
for i in range(0,2):
#region = im.crop((x, y, x+w*i, y+h*j))
print(x+w*i, y+h*j,x+w*i+w, y+h*j+h)
region = im.crop((x+w*i, y+h*j,x+w*i+w, y+h*j+h))
#文件输出位置
region.save(r"C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图1\{name}.jpg".format(name='%03d'%n))
n=n+1
if __name__ == '__main__':
read_bmp_file_list(file_root)
for f in fileList:
qie_tu(f)
# print('----------第2步:读取图片,写入模板----------------')
import os
from PIL import Image
print('----------第1步:提取图片路径------------')
path=[]
pr="C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\大写字母拼图\\大写字母拼图1"
# 过滤:只保留png结尾的图片
imgs1=os.listdir(pr)
for img1 in imgs1:
if img1.endswith(".jpg"):
path.append(pr+'\\'+img1)
# 所有图片的路径
print(path)
# 216条路径(18张*12图)
print(imgs1)
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,int(num/2)): # 26份一页2份 0-13
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\大写字母拼图模板.docx')
# # 制作列表
# 从左边图列表和右边图列表中抽取图片(12张图片,可能5个向左、7个向右边)
# 24条里面0和12条是一组,2个里面随机抽1一个,1和13是一组,2个里面随机抽一个…… 抽出12个图片后
r=[]
c=[]
r.append(path[nn*12:nn*12+12]) # 连续12张图片、2份字母插入同一份A4
# r.append(path[nn*24:nn*24+24]) # 连续12张图片、2份字母插入同一份A4
# print(r)
# 再打乱顺序读取12个
for a in r:
for b in a:
c.append(b)
print(c)
figures1=random.sample(c[0:6],Number) # 前6张不重复打乱
figures2=random.sample(c[6:12],Number) # 后6张不重复打乱
# figures3=random.sample(c[12:18],Number) # 后6张不重复打乱
# figures4=random.sample(c[18:24],Number) # 后6张不重复打乱
# 12张不重复打乱图片合并
figures=figures1+figures2
# figures=figures1+figures2+figures3+figures4
print(figures)
for z in range(2): # 5行组合循环2次 每页两张表
# 单元格位置3*4格
bg=[]
for x in range(0,3): # 3行
for y in range(0,2): # 4列
ww='{}{}'.format(x,y)
bg.append(ww)
print(bg)
# bg=['00', '01', '10', '11', '20', '21', '03', '04', '13', '14', '23', '24']
table = doc.tables[z]
for t in range(len(bg)): # 02
pp=int(bg[t][0:1])
qq=int(bg[t][1:2])
# print(p)
k=figures[z*6:z*6+6][t]
print(pp,qq,k)
# 写入图片
run=doc.tables[z].cell(pp,qq).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(k),width=Cm(4.55),height=Cm(3.852))
# 单元格宽度4.65 3.94
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\大写字母拼图\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/(打印合集)大写字母拼图A4一页两份A-Z_26字母(2乘3张){}人共{}份).pdf".format(num,int(num/2)))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/大写字母拼图/零时Word') #递归删除文件夹,即:删除非空文件夹



![[mars3d] 学习](https://img-blog.csdnimg.cn/bc9c1465f3f2483a9b1c624de2524aff.png)