6.1 顺序消息
顺序消息是指消息的消费顺序和产生顺序相同,在有些业务逻辑下,必须保证顺序 。 比如订单的生成 、付款、发货,这 3 个消息必须按顺序处理才行。顺序消息分为全局顺序消息和部分顺序消息,全局顺序消息指某个 Topic 下的所有消息都要保证顺序;部分顺序消息只要保证每一组消息被顺序消费即可。比如上面订单消息的例子,只要保证 同一个订单 ID 的 三个消息能按顺序消费即可 。顺序消息发送 | RocketMQ (apache.org)![]() https://rocketmq.apache.org/zh/docs/4.x/producer/03message2/
https://rocketmq.apache.org/zh/docs/4.x/producer/03message2/
6.1.1 全局顺序消息
RocketMQ 在 默认情况下不保证顺序,比如创建一个 Topic ,默认八个写队列,八个读队列 。 这时候一条消息可能被写入任意一个队列里;在数据的读取过程中,可能有多个 Consumer ,每个 Consumer 也可能启动多个线程并行处理,所以消息被哪个 Consumer 消费,被消费的顺序和写人的顺序是否一致是不确定的。
要保证全局顺序消息, 需要先把 Topic 的读写队列数设置为 一,然后Producer 和 Consumer 的并发设置也要是一。 简单来说,为了保证整个 Topic 的全局消息有序,只能消除所有的并发处理,各部分都设置成单线程处理。 这时高并发、高吞吐量的功能完全用不上了 。
在实际应用中,更多的是像订单类消息那样,只需要部分有序即可 。 在这种情况下,我们经过合适的配置,依然可以利用 RocketMQ 高并发 、高吞吐量的能力 。
6.1.2 部分顺序消息
要保证部分消息有序,需要发送端和消费端配合处理。 在发送端,要做到把同一业务 ID 的消息发送到同一个 Message Queue ;在消费过程中,要做到从同一个 Message Queue 读取的消息不被并发处理,这样才能达到部分有序 。发送端使用 MessageQueueSelector 类来控制把消息发往哪个 MessageQueue。
消费端通过使用 MessageListenerOrderly 类 来解决单 Message Queue 的消息被并发处理的问题。
Consumer 使用 MessageListenerOrderly 的时候,下面四个 Consumer 的设置依旧可以使用: setConsumeThreadMin 、 setConsumeThreadMax 、 setPullBatchSize 、 setConsume-MessageBatchMaxSize 。 前两个参数设置 Consumer 的线程数, 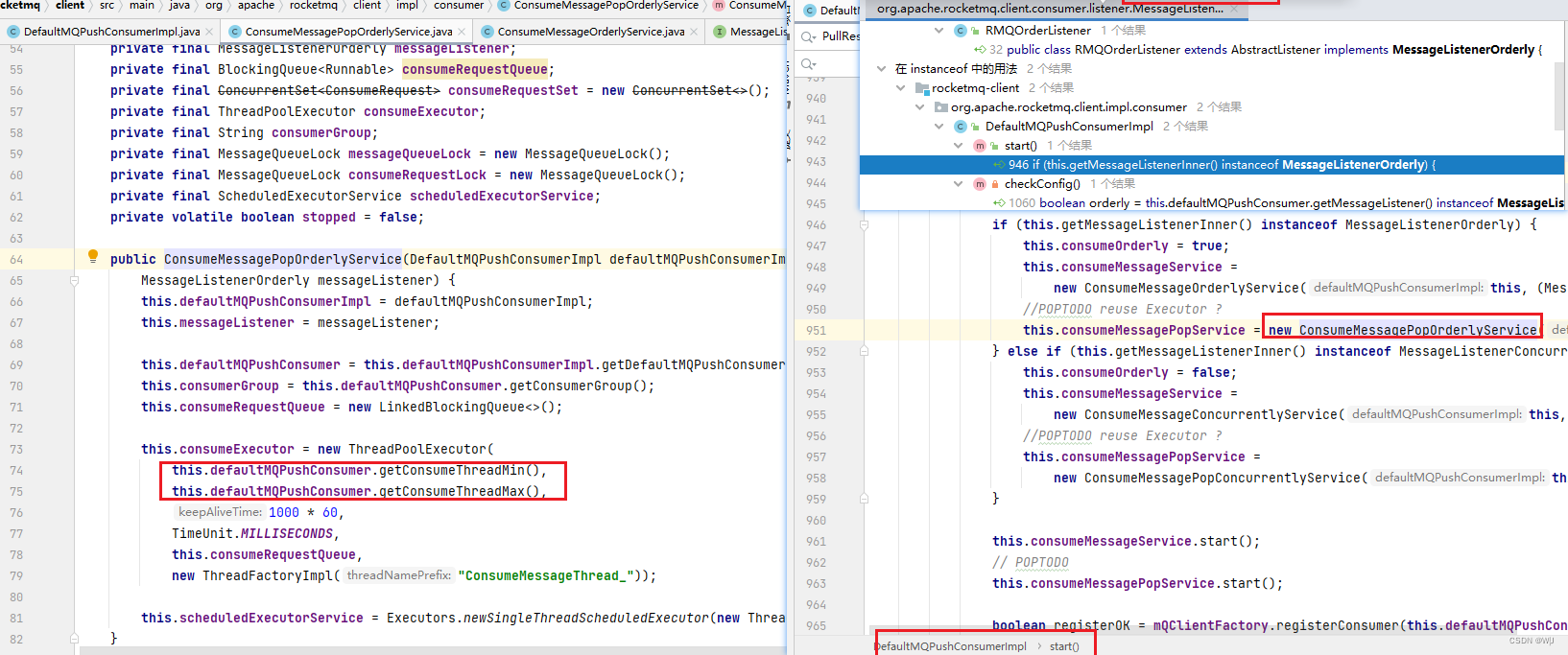 PullBatchSize 指的是一次从 Broker 的一个 Message Queue 获取消息的最大数量 ,默认值是 32, ConsumeMessage-BatchMaxSize 指的是这个 Consumer的 Executor (也就是调用 Message-Listener 处理的地方)一次传入的消息数(List<MessageExt> msgs 这个链表的最大长度),默认值是 1 。上述四个参数可以使用,说明 MessageListenerOrderly 并不是简单地禁止并发处理。 在 MessageListener-Orderly 的实现中,为每个 Consumer Queue 加个锁,消费每个消息前,需要先获得这个消息对应的 Consumer Queue 所对应的锁,这样保证了同一时间,同一个 Consumer Queue 的消息不被并发消费,但不同 Consumer Queue 的消息可以并发处理。
PullBatchSize 指的是一次从 Broker 的一个 Message Queue 获取消息的最大数量 ,默认值是 32, ConsumeMessage-BatchMaxSize 指的是这个 Consumer的 Executor (也就是调用 Message-Listener 处理的地方)一次传入的消息数(List<MessageExt> msgs 这个链表的最大长度),默认值是 1 。上述四个参数可以使用,说明 MessageListenerOrderly 并不是简单地禁止并发处理。 在 MessageListener-Orderly 的实现中,为每个 Consumer Queue 加个锁,消费每个消息前,需要先获得这个消息对应的 Consumer Queue 所对应的锁,这样保证了同一时间,同一个 Consumer Queue 的消息不被并发消费,但不同 Consumer Queue 的消息可以并发处理。

6.2 消息重复问题
对分布式消息队列来说,同时做到确保一定投递和不重复投递是很难的,也就是所谓的“有且仅有一次” 。 在鱼和熊掌不可兼得的情况下, RocketMQ 选择了确保一定投递,保证消息不丢失,但有可能造成消息重复。
消息重复一般情况下不会发生,但是如果消息量大,网络有波动,消息重复就是个大概率事件。 比如 Producer 有个函数 setRetryTimeWhenSendFailed, 设置在同步方式下自动重试的次数,默认值是 2 ,这样当第一次发送消息时,Broker 端接收到了消息但是没有正确返回发送成功的状态,就造成了消息重复。
解决消息重复有两种方法:第一种方法是保证消费逻辑的幕等性(多次调用和一次调用效果相同);另一种方法是维护一个已消费消息的记录,消费前查询这个消息是否被消费过。 这两种方法都需要使用者自己实现。
TODO
6.3 动态增减机器
一个消息队列集群由多台机器组成,持续稳定地提供服务,因为业务需求或硬件故障,经常需要增加l 或减少各个角色的机器,本节介绍如何在不影响服务稳定性的情况下动态地增减机器。
6.3.1 动态增减 NameServer
NameServer 是 RocketMQ 集群的协调者,集群的各个组件是通过NameServer 获取各种 属性和 地址信息的 。 主要功能包括两部分:一个各个 Broker 定期上报自己的状态信息到NameServer ;另一个是各个客户端 ,包括Producer 、 Consumer ,以及命令行工具,通过 NameServer 获取最新的状态信息 。 所以,在启动 Broker 、生产者和消费者之前,必须告诉它们 NameServer的地址,为了提高可靠性,建议启动多个 NameServer 。 NameServer 占用资源
不多,可以和 Broker 部署在同一台机器。 有多个 NameServer 后,减少某个NameServer 不会对其他组件产生影响 。
有四种种方式可设置 NameServer 的地址, ’ 下面按优先级由高到低依次介绍:
- 通过代码设置,比如在 Producer 中,通过 Producer.setNamesr Addr (”name-server 1-ip:port;name-server2-ip: port ”)来设 置。 在 mqadmin 命令行工具中,是通过-n name-server-ip1 :port;name-server-2:port 参数来设置的,如果自定义了命令行工具,也可以通过 defaultMQAdminExt.setNamesrvAddr(“name-server 1-ip:port;name-server2-ip: port ”)来设置
- 使用 Java 启动参数设置,对应的 option 是 rocketmq.namesrv.addr 。
- 通过 Linux 环境变量设置,在启动前设置变量: NAMESRV ADDR 。
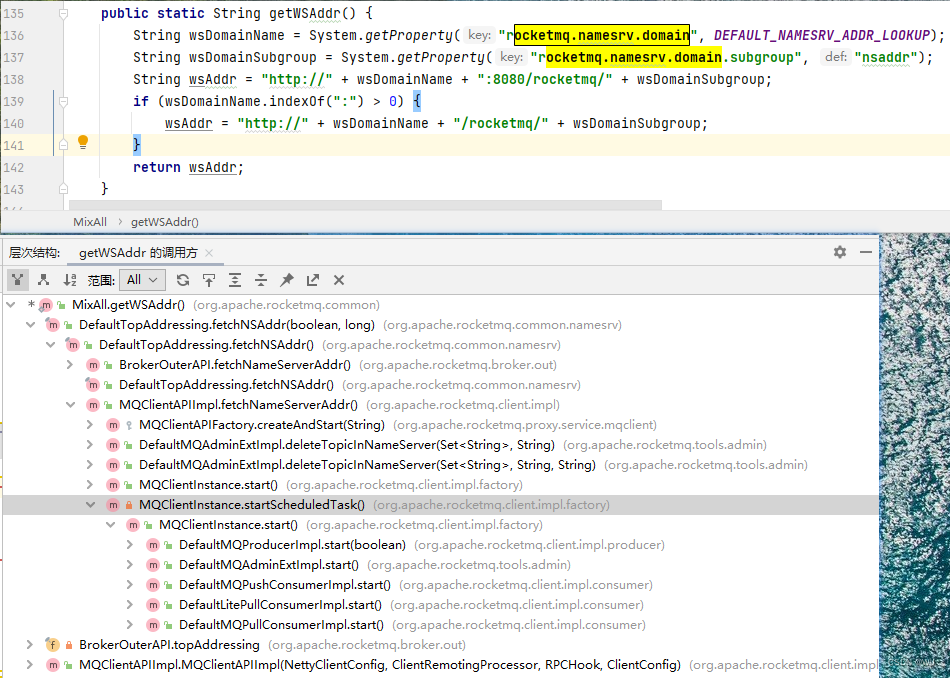
- 通过 HTTP 服务来设置,当上述方法都没有使用,程序会向 一个 HTTP地址发送请求来获取 NameServer 地址,默认的 URL 是 http://jmenv.tbsite.net: 8080/rocketmq/nsaddr (淘宝的测试地址),通过 rocketmq.namesrv.domain 参数来覆盖 jmenv.tbsite.net ;通过 rocketmq .namesrv.domain.subgroup 参数来覆盖nsaddr 。
第 4 种方式看似繁琐,但它是唯一支持动态增加 NameServer ,无须重启其他组件的方式。 使用这种方式后其他组件会每隔 2 分钟请求一次该 URL ,获取最新的 NameServer 地址 。
6.3.2 动态、增减 Broker
由于业务增长,需要对集群进行扩容的时候,可以动态增加 Broker 角色的机器。 只增加 Broker 不会对原有的 Topic 产生影响,原来创建好的 Topic 中数据的读写依然在原来的那些 Broker 上进行。
集群扩容后, 一是可以把新建的 Topic 指定到新的 Broker 机器上,均衡利用资源;另一种方式是通过 updateTopic 命令更改现有的 Topic 配置,在新加的 Broker 上创建新的队列 。 比如 TestTopic 是现有的一个 Topic ,因为数据量增大需要扩容,新增的一个 Broker 机器地址是 192 . 168.0.1:10911 ,这个时候执行下面的命令: sh ./bin/mqadmin updateTopic -b 192.168.0.1:10911 -t TestTopic -n 192.168.0.100:9876 ,结果是在新增的 Broker 机器上,为 TestTopic 新创建了 8
个读写队列 。
如果因为业务变动或者置换机器需要减少 Broker ,此时该如 何操作呢?减少 Broker 要看是否有持续运行的 Producer ,当一个 Topic 只有一个 MasterBroker ,停掉这个 Broker 后,消息的发送肯定会受到影响,需要在停止这个Broker 前,停止发送消息 。当某个 Topic 有多个 Master Broker ,停了其中一个,这时候是否会丢失消息呢?答案和 Producer 使用的发送消息的方式有关,如果使用同步方式 send ( msg )发送,在 DefaultMQProducer 内部有个自动重试逻辑,其中一个 Broker 停了,会自动向另一个 Broker 发消息,不会发生丢消息现象。 如果使用异步方式发送 send ( msg, callback ),或者用 sendOneWay 方式,会丢失切换过程中的消息 。 因为在异步和 sendOneWay 这两种发送方式下,Producer.setRetryTimesWhensendFailed 设置不起作用,发送失败不会重试。DefaultMQProducer 默认每 30 秒到 NameServer 请求最新的路由消息, Producer如果获取不到已停止的 Broker 下的队列信息,后续就自动不再向这些队列发送消息 。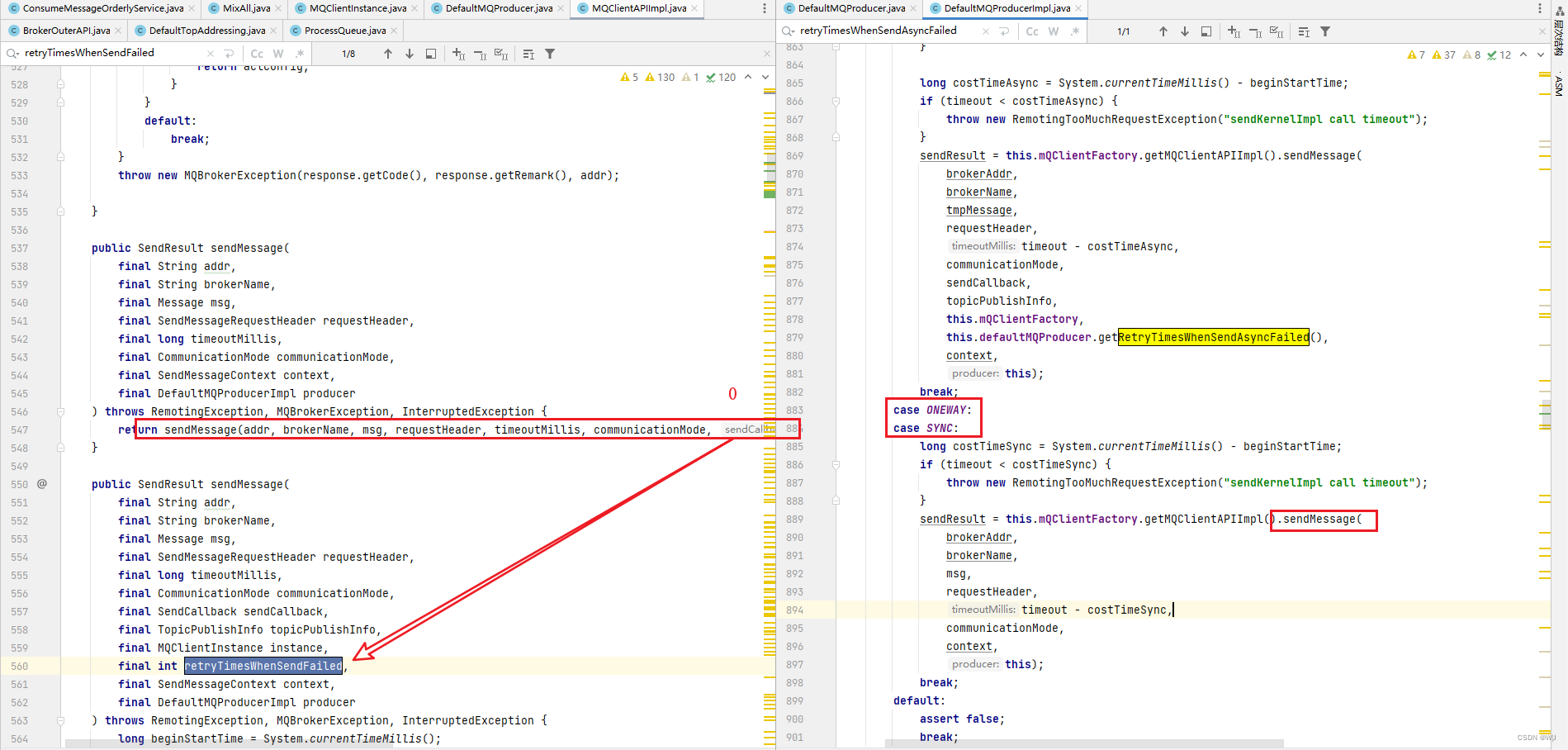
如果 Producer 程序能够暂停,在有一个 Master 和一个 Slave 的情况下也可以顺利切换。 可以关闭 Producer 后关闭 Master Broker ,这个时候所有的读取都会被定向到 Slave 机器,消费消息不受影响 。 把 Master Broker 机器置换完后,基于原来的数据启动这个 Master Broker ,然后再启动 Producer 程序正常发送消息 。
用 Linux 的 kill pid 命令就可以正确地关闭 Broker, BrokerController 下有个 shutdown 函数,这个函数被加到了 ShutdownHook 里,当用 Linux 的 kill 命令时(不能用 kill -9 ), shutdown 函数会先被执行。 也可以通过 RocketMQ 提供的工具( mqshutdown broker )来关闭 Broker ,它们的原理是一样的 。
6.4 各种故障对消息的影响
我们期望消息队列集群一直可靠稳定地运行,但有时候故障是难免的,本节我们列出可能的故障情况,看看如何处理:
1) Broker 正常关闭,启动;
2) Broker 异常 Crash ,然后启动;
3) OS Crash ,重启;
4 )机器断电,但能马上恢复供电;
5 )磁盘损坏;
6) CPU 、 主板、内存等关键设备损坏 。
假设现有的 RocketMQ 集群,每个 Topic 都配有多 Master 角色的 Broker 供写人,并且每个 Master 都至少有一个 Slave 机器(用两台物理机就可以实现上述配置),我们来看看在上述情况下消息的可靠性情况。
第 1 种情况属于可控的软件 问题,内存中的数据不会丢失 。 如果重启过程中有持续运行的 C onsumer, Master 机 器出故障后, Consumer 会自动 重连到对应的 Slave 机器,不会有消息丢失和偏差。 当 Master 角色的机器重启 以后, Co nsumer 又会重新连接到 Master 机器( 注意在启动 Mas ter 机器的时候,如果 Consumer 正在从 Slave 消费消息,不要停止 Consumer 。 假如此时先停止Consumer 后再启动 Master 机器,然后再启动 Consumer ,这个时候 Consumer
就会去读 Master 机器上已经滞后的 offset 值,造成消息大量重复) 。
如果第 1 种情况出现时有持续运行的 Producer , 一 台 Master 出故障后,Producer 只能向 Topic 下其他的 Master 机器发送消息,如果 Producer 采用同步发送方式,不会有消息丢失 。
第 三 3 、 4 种情况属于软件故障,内存的数据可能丢失,所 以刷盘策 略不同,造成的影 响也不 同,如果 Master 、 Slave 都配置成 SY?叫C FLUSH ,可以达到和第 l 种情况相同的效果。
第 5 ' 6 种情况属于硬件故障 ,发生第 5 ' 6 种情况的故障,原有机器的磁盘数据可能会丢失 。 如果 Master 和 Slave 机器间配置成同步复制方式,某一台机器发生 5 或 6 的故障,也可以达到消息不丢失的效果。 如果 Master 和 Slave机器间是异步复制,两次 Sync 间的消息会丢失 。
总的来说,当设置成:
1 )多 Master ,每个 Master 带有 Slave;
2 )主从之间设置成 SYNC_MASTER;
3 ) Producer 用同步方式写;
4 )刷盘策略设置成 SYNC_FLUSH 。
就可以消除单点依赖,即使某台机器出现极端故障也不会丢消息 。
6.5 消息优先级
有些场景,需要应用程序处理几种类型的消息,不同消息的优先级不同 。RocketMQ 是个先人先出的队列,不支持消息级别或者 Topic 级别的优先级。业务中简单的优先级需求,可以通过间接的方式解决,下面列举三种优先级相关需求的具体处理方法。
第一种是比较简单的情况,如果当前 Topic 里有多种相似类型的消息,比如类型 AA 、 AB 、 AC ,当 AB 、 AC 的消息量很大,但是处理速度比较慢的时候,队列里会有很多 AB 、 AC 类型的消息在等候处理,这个时候如果有少量 AA 类型的消息加人,就会排在 AB 、 AC 类型消息后面,需要等候很长时间才能被处理。
如果业务需要 AA 类型的消息被及时处理,可以把这三种相似类型的消息分拆到两个 Topic 里,比如 AA 类型的消息在一个单独的 Topic, AB 、 AC 类型的消息在另外一个 Topic 。 把消息分到两个 Topic 中以后,应用程序创建两个Consumer ,分别订阅不同的 Topic ,这样消息 AA 在单独的 Topic 里,不会因为 AB 、 AC 类型的消息太多而被长时间延时处理。
第二种情况和第一种情况类似,但是不用创建大量的 Topic 。举个实际应用场景:一个订单处理系统,接收从 100 家快递门店过来的请求,把这些请求通过 Producer 写人 RocketMQ ;订单处理程序通过 Consumer 从队列里读取消息并处理,每天最多处理 1 万单。 如果这 100 个快递门店中某几个门店订单量大增,比如门店一接了个大客户,一个上午就发出 2 万单消息请求,这样其他
的 99 家门店可能被迫等待门店一的 2 万单处理完,也就是两天后订单才能被处理,显然很不公平。
这时可以创建一 个 Topic , 设置 Topic 的 MessageQueue 数量超过 100 个,Producer 根据订单的门店号,把每个门店的订单写人 一 个 MessageQueue 。DefaultMQPushConsumer 默认是采用循环的方式逐个读取一个 Topic 的所有 MessageQueue ,这样如果某家门店订单 量 大增,这家门店对应的MessageQueue 消息数增多,等待时间增长,但不会造成其他家门店 等待时间增长 。
DefaultMQPushConsumer 默认的 pullBatchSize 是 32 ,也就是每次从某个MesageQueue 读取消息的时候,最多可以读 32 个。 在上面的场景中,为了更加公平,可以把 pullBatchSize 设置成 1 。
生产者添加MessageQueueSelector, 消费者一次拉取的消息减少
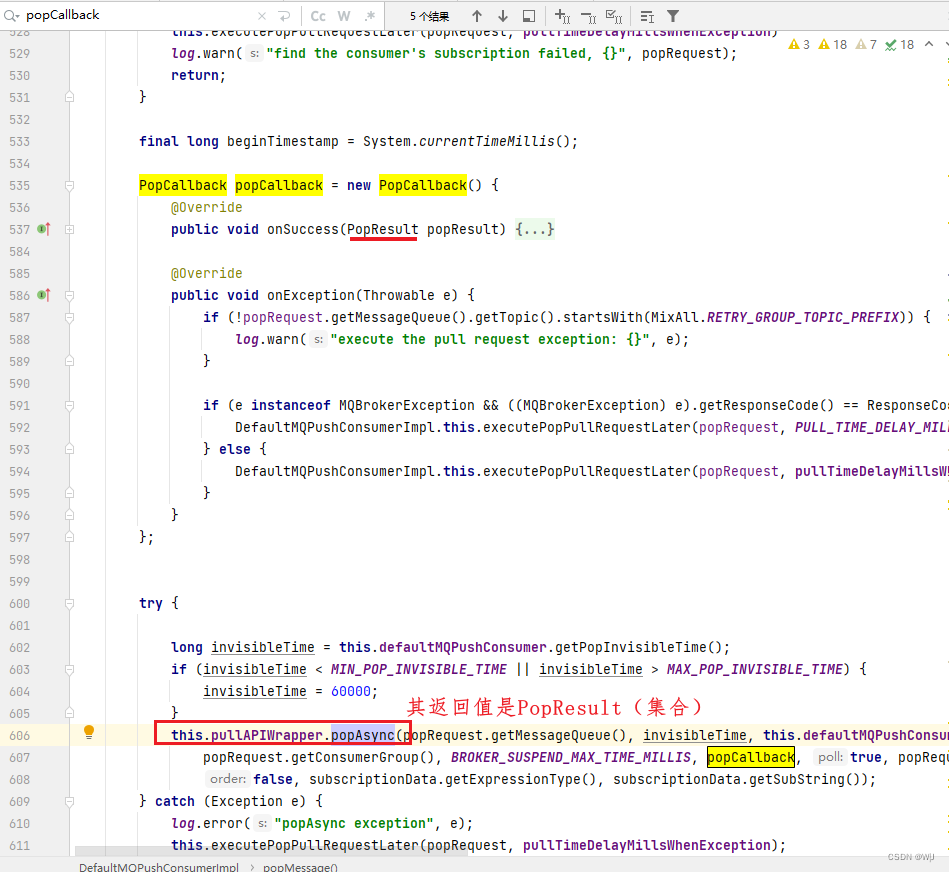
org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#popMessage L606
org.apache.rocketmq.client.impl.consumer.PullAPIWrapper#popAsync L390
org.apache.rocketmq.client.impl.MQClientAPIImpl#popMessageAsync
popCallback.onSuccess(popResult); L864
第三种情况是强优先级需求,上两种情况对消息的“优先级”要求不高,更像一个保证公平处理的机制,避免某类消息的增多阻塞其他类型的消息 。 现在有一个应用程序同时处理 TypeA 、 TypeB 、 TypeC 三类消息 。 TypeA 处于第一优先级,要确保只要有 TypeA 消息,必须优先处理; TypeB 处于第 二优先级; TypeC 处于第 三优先级。 对这种要求,或者逻辑更复杂的要求,就要用户自己编码实现优先级控制,如果上述的 三类消息在一个 Topic 里,可以使用 Pull Consumer ,自主控制 MessagQueue 的遍历,以及消息的读取;如果上述三类消息在三个 Topic 下,需要启动 三个 Consumer , 实现逻辑控制 三个Consumer 的消费 。
TODO 自定义 PullConsumer,实现优先队列