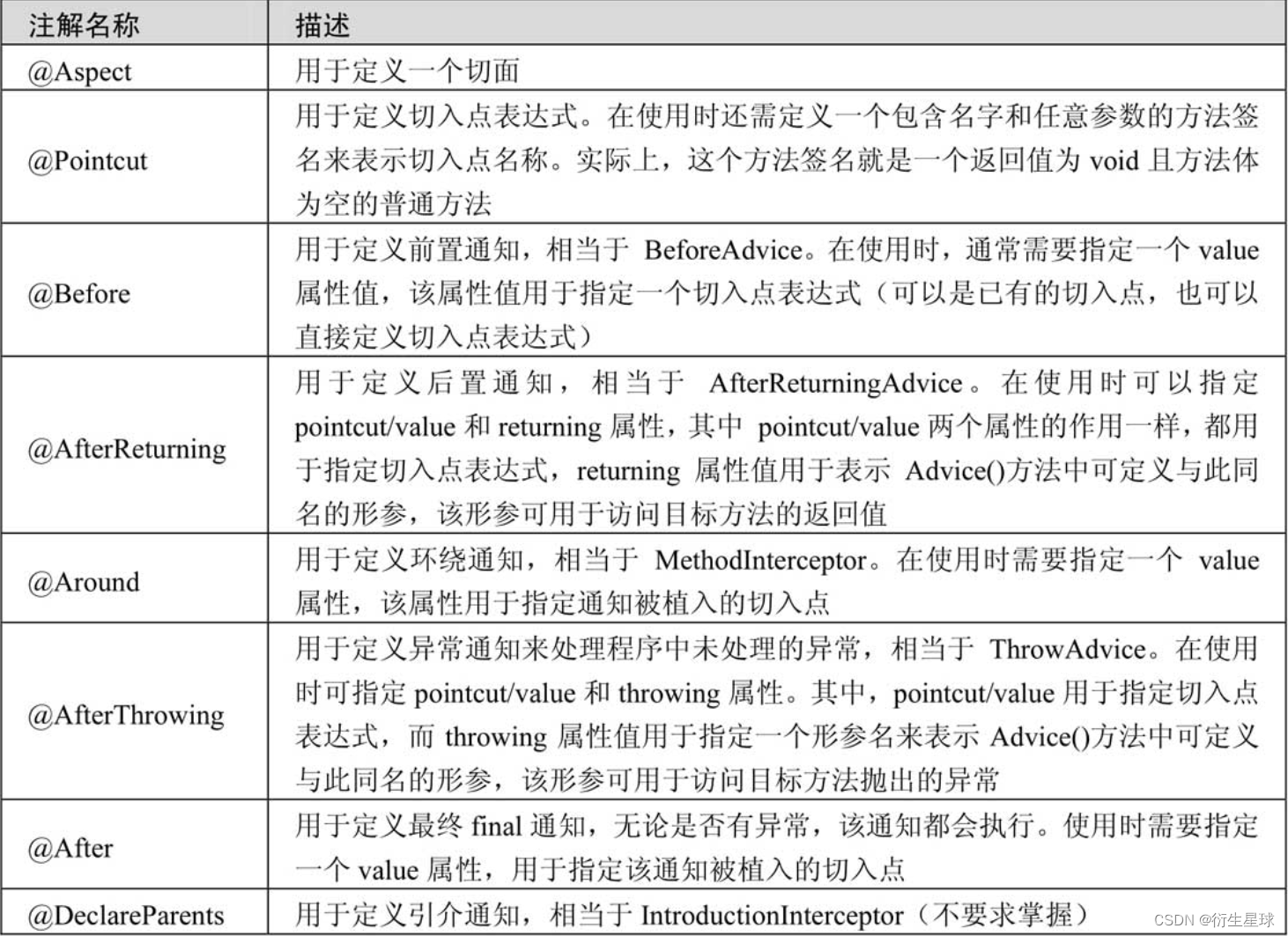
目录
字符串处理函数,strcpy,strcat
数组指针
函数缺省值
初始化列表编辑
友元函数
new与delete
静态成员变量
new与构造函数 delete与析构函数
拷贝构造函数的特点
常成员函数
初始化列表
编程题
字符串中找出连续最长的数字串
数组中超过一半的数
进制转换
统计回文
字符串处理函数,strcpy,strcat

strcpy(p,q):将q字符串中的内容拷贝到p所在的空间中,最后返回p;
注意:p的空间大小一定要能够村的下q中的字符综述,否则程序会崩溃。
strcat(p,q):将q字符串中的内容拼接在p字符串之后,最终返回p;
注意:p空间一定要能容纳下q拼接进来的字符。
解析:p1是一个数组,里面存放了abcd四个字符外加一个/0。p2是一个指针,"ABCD"是一块字符串常量,然而p2就指向了A字符。str是一个字符数组。
strcpy(str+2,strcat(p1+2,p2+1); 在这句表达式中,我们首先看strcat(p1+2,p2+1);
由上边strcat的作用可知此表达式是将p2+1(p2指向A,则p2+1往后偏移一个字符的长度,因此指向B)位置往后的字符串常量拼接在p1+2(p1是数组名,也就是首元素的地址,p1+2也就是p1数组中c的地址)上,并且返回p1+2。这一步下来之后,p1中的数据就变为了p1[15]="abcdBCD"。
然后再看strcpy这个函数,将p1+2位置往后的数据拷贝到str+2往后的数据上。得str[50]="xyabcdBCD"。
因此选择D选项。
数组指针

解析:在这个语句中,首先创建了一个二维数组 n,包含两个大小为 3 的一维数组。然后声明了一个指向包含三个 int 类型元素的一维数组的指针 p。
接着,将 p 指向 n 数组的第一个元素,即 p = &n[0];,这里可以简写成 p = n;,因为数组名 n 可以被解释为指向数组第一个元素的指针。
p[0][0]:
这样,指针 p 就指向了 n 数组的第一个元素,也就是第一个包含三个 int 类型元素的一维数组。因此,可以通过 p 访问 n 数组中的各个元素,比如 p[0][0] 就等于 n[0][0],p[1][2] 就等于 n[1][2]。
通过这种方式,可以使用指针更加灵活地访问数组元素,而不必关心数组的实际存储方式。
*(p[0]+1):
p[0]是指向二维数组中的第一个一维数组的第一个元素,p[0]+1是偏移了一个元素的大小,因此指向了第二个元素,*(p[0]+1)就是对此元素地址进行解引用得到的就是20;
(*p)[2]:
在这个语句中,(*p)[2] 表示 p 所指向的一维数组中第三个元素的值。由于 p 指向 n 数组的第一个元素,也就是第一个包含三个 int 类型元素的一维数组,因此 (*p)[2] 等价于 n[0][2],这个表达式的值为 30。
需要注意的是,这里的 (*p) 是用于解引用 p 指针所指向的一维数组的方式,它的优先级比 [] 运算符高。因此,(*p)[2] 表示先解引用 p 指针得到一个包含三个 int 类型元素的一维数组,再访问其中的第三个元素。
函数缺省值

解析:
A:函数带默认值的参数可以有很多个。
B:函数参数的默认值设定必须连续。
C:默认值可以设置,也可以不设置。
D:默认值设置的时候不能间断性的设置,一旦有一个参数设置了默认值,之后的所有参数都必须设置默认值,举例如下。


初始化列表
解析:
必须在初始化列表初始化的有:
1、const修饰的成员变量。
2、引用类型的成员变量。
3、类类型对象,该类没有默认的构造函数。
const修饰的成员变量
 注意:这里需要注意的是,在构造函数中,只有在初始化列表中初始化的数才叫做初始化。在别的地方只能算作赋值,而不是真正的初始化,因此const修饰的成员变量必须在初始化列表进行初始化。
注意:这里需要注意的是,在构造函数中,只有在初始化列表中初始化的数才叫做初始化。在别的地方只能算作赋值,而不是真正的初始化,因此const修饰的成员变量必须在初始化列表进行初始化。
引用类型的成员变量

类类型对象,该类没有默认的构造函数

因此,选择B选项。
友元函数

解析:
C++ 中的友元函数没有 this 指针。
友元函数是一种特殊的非成员函数,它被声明为某个类的友元函数,可以访问该类的私有成员。虽然友元函数可以访问该类的私有成员,但它并不属于该类的成员函数,它没有 this 指针。这是因为友元函数不属于该类,它是一个全局函数,没有访问该类对象的权限,因此也就没有 this 指针。
当我们在友元函数中访问该类的成员时,需要通过函数参数传递该类的对象,然后通过该对象访问其成员,而不是使用 this 指针。
D选项中,友元函数是没有this指针的,所以是错误的。选择D选项。
new与delete


其实new和delete的本质就是调用malloc和free。
由题可知, new了5个对象,因此要调用5次构造函数对申请的空间进行初始化,但是只delete了一次,所以只调用1次析构函数。选择A选项。
静态成员变量


A:可以再类内初始化。
B:可以使用类中的对象调用,只不过静态数据成员在类的所有对象之间共享。
C:受private修饰符的作用。
D:可以使用类名加作用域符直接调用。
MyClass::myStaticMember = 42; // 通过类名访问静态成员所以选择D选项。
new与构造函数 delete与析构函数

解析:我们在使用new的时候会调用类的构造函数来对申请的空间进行初始化,使用delete的时候会调用析构函数进行释放空间的资源。如果直接创建对象,将会自动调用构造函数和析构函数。那么如果我们吧析构函数设为私有,那么直接创建对象的时候会报错(因为无法调用析构函数),但是使用new创建的时候就不会报错(因为new只会调用构造函数而不会调用析构函数)。所以选择B选项。
拷贝构造函数的特点

A:拷贝构造函数没有返回值。
B:不是对某个对象的引用,而是同一类对象的引用。
C:最后一句,应该是作为该类的公共成员。
D:拷贝构造初始化函数作用就是将一个已知对象的数据成员值拷贝给正在创建的另一个同类的对象,而赋值运算符重载函数是讲一个已知对象赋值给已知对象。
因此选择D选项。
常成员函数

在函数声明或定义中,const 关键字通常用于修饰函数的参数或函数本身。在 void print() const 中,const 关键字修饰的是函数本身,表示该函数是一个常量成员函数。
常量成员函数表示该函数不会修改调用它的对象,因此可以被一个 const 对象(即对象被声明为 const)调用。在常量成员函数中,不允许修改对象的成员变量,也不允许调用非常量成员函数(因为非常量成员函数可能会修改对象)。
需要注意的是,常量成员函数的定义和声明中都需要加上 const 关键字。例如:
class MyClass {
public:
void print() const; // 声明常量成员函数
};
void MyClass::print() const { // 定义常量成员函数
// 函数实现
}
因此选择C选项。
初始化列表

在初始化列表中初始化成员的顺序:与该成员在初始化列表中出现的先后顺序没有关系,但与成员变量在类中生成的先后顺序有关。
因此无论输入都是a先调用Printer的构造函数,b后调用。
因此选择C选项。
编程题
字符串中找出连续最长的数字串
字符串中找出连续最长的数字串_牛客题霸_牛客网

定义三个string,遍历用str来接受字符串,然后遍历str。如果属于'0'到'9'就插入cur里面,利用ret来记录最长的串。
注意:我们在遍历的时候,判断条件一定要多写一位,因为只有这样才能把最后一个串给插入到cur中。具体看代码注释。
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str,cur,ret;
cin>>str;
// getline(cin,str);
// cout<<str<<endl;
int i=0;
//这里的for循环里面一定要多给一个值 如果最后一个字符串是最长的话
//只有多给了一个值才能把最长的那个字符串(刚好在str的最后一段)赋值给cur
for(i=0;i<=str.length();i++)
{
if(str[i]>='0'&& str[i]<='9')
{
cur+=str[i];
}
else
{
if(cur.size()>ret.size())
{
ret=cur;
}
else
{
cur.clear();
}
}
}
cout<<ret;
return 0;
}
// 64 位输出请用 printf("%lld")数组中超过一半的数
数组中出现次数超过一半的数字_牛客题霸_牛客网

抵消法:因为是找超过一半的数,那么我们遍历的时候遇到两个不相等的就给消去,最后剩下的肯定只有超过一半的那个数了。
排序比较法:由于是超过一半的数,那么我们给数组中的数据进行排序。超过一半的数的位置一定在中位数的位置。
抵消法
class Solution
{
public:
int MoreThanHalfNum_Solution(vector<int> numbers)
{
//首先记录第一个数,并将次数初始化为1
int result = numbers[0], times = 1;
// 从第二个数开始进行循环遍历
for (int i = 1; i < numbers.size(); i++)
{
// 次数不等于0,说明之前已经记录的有数据
if (times != 0)
{
// 所遍历的数据与前面的数据不相同时,次数减1
// 其实也就是删除两个不相同的值
if (numbers[i] != result)
{
times--;//遍历到不一样的就销毁一个times
}
// 如果相同,则加1
else
{
times++;
}
}
// 次数等于0,说明需要记录一个新的值,前面的值已经抵消完了
else
{
result = numbers[i];
times = 1;
}
}
// 最终没被抵消完的值就是我们需要的值
return result;
}
};
排序比较法
class Solution {
public:
int MoreThanHalfNum_Solution(vector<int> numbers)
{
//直接对numbers进行排序
sort(numbers.begin(), numbers.end());
// 取出中位数的下标
int muddle = numbers.size() / 2;
// 定义一个记录次数的变量
int count = 0;
// 利用范围for遍历numbers,计算出以中位数为下标数的次数
for (auto& e : numbers)
{
if (e == numbers[muddle])
count++;
}
// 如果次数大于中位数,就返回以中位数为下标的数
// 如果次数小于中位数,则返回0
return count > muddle ? numbers[muddle] : 0;
}
};
进制转换
进制转换_牛客题霸_牛客网

注意:
1、我们需要创建一个数组来记录"0123456789ABCDEF",然后通过下标来找对应的字符,原因是十六局进制的10对应的是A以此类推。
2、注意符号,如果我们需要处理的数是一个负数,那么注意符号的变化。
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
// 定义M和N
int M, N;
// 接受M和N
cin >> M >> N;
// 如果M是0的话,直接输出0,然后return 0 就行
if(M==0)
{
cout<<M<<endl;
return 0;
}
// 定义一个标志位,便于分清正负
int flag = 1;
// 如果M是负数,将标志位也改为负数
if (M < 0)
{
// 这里注意,要将M转化为正数,便于我们的计算,到最后再根据标志位转回来
M = -M;
flag = -flag;
}
// 定义两个string,注意由于十六进制9往后的数据用的是字母表示
// 所以我们需要定义一个数组来对这些字母进行存储,计算的时候便于遍历
string s, table = "0123456789ABCDEF";
// 开始遍历M
while (M)
{
// 把M模出来的数先插入s中
s += table[M % N];
M /= N;
}
// 若flag<0说明我们的M是一个负数,不要忘了加-号
if (flag < 0)
s += '-';
// 最后一步,将我们s中的数进行翻转,输出就是我们进制转换之后的数
reverse(s.begin(), s.end());
cout << s << endl;
return 0;
}统计回文
统计回文_牛客题霸_牛客网
我们需要str2插入在str1的每个字符的前后进行判断是否回文,具体看注释。
#include <iostream>
#include <string>
using namespace std;
// 判断字符串是否是回文串
bool ishw(const string &str)
{
size_t begin=0;
size_t end=str.size()-1;
while(begin<end)
{
if(str[begin]!=str[end])
return false;
begin++;
end--;
}
return true;
}
int main()
{
string str1,str2;
// 记录能构成回文串的个数
size_t count=0;
getline(cin,str1);
getline(cin,str2);
// 遍历待插入字符串中每个字符的前后位置
// 注意:第一个字符前的位置和最后一个字符后的位置也要考虑
// 这也是为啥判断条件是<=的原因
for(int i=0;i<=str1.size();i++)
{
// 千万要记住,我们不能直接使用str1
// 因为我们要多次插入,所以要使用一个额外的str来接受str1
string str=str1;
// 利用我们写的判断回文串函数进行判断,并且记录次数
if(ishw(str.insert(i,str2)))
count++;
}
cout<<count<<endl;
}
// 64 位输出请用 printf("%lld")