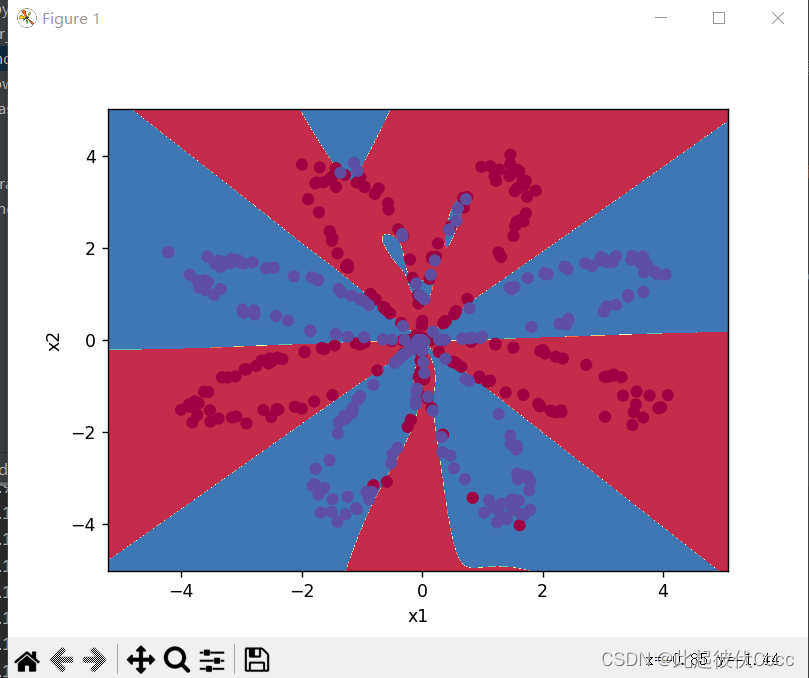
介绍
hashCode 中文‘散列码’,存在的意义是加快查找速率,可以在常数时间内进行寻址操作。
存在意义
它被定义在 Object 中,而 Object 类是一切类的父类,所以所有的方法都具有这个方法。
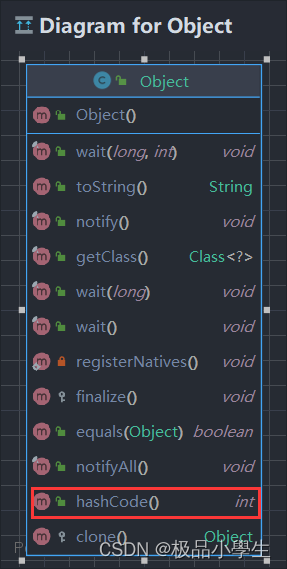
Java 中 hashCode 计算方式如下:
1. 将对象的存储地址转换成一个整数,这个整数被称为哈希码 (Hash Code),
2. 相同的对象应该具有相同的 hashCode,在重写 equals方法时,也必须重写 hashCode 方法。(这样的目的是为了保证 Set 集合的正确去重,以及获取正确的应该对应的 hashCode)
3. 如果是数组类型,在 jdk1.8 的 HotSpot JVM 中是通过对质数 31进行相乘的遍历相加操作来计算的。
public int hashCode() {
int h = 0;
for (int i = 0; i < length; i++) {
h = 31 * h + elementData[i].hashCode();
}
return h;
}
计算详细规则
首先我们要知道,在不同 JVM 中也就是不同的 jdk版本下,对 hashCode 的计算规则不同。
下面我们以 jdk1.8 的 HotSpot 进行讲解:
在HotSpot JVM中,hashCode()方法的实现方式取决于对象的具体类型。HotSpot JVM使用一种称为"Mark Word"的数据结构来存储对象的元数据信息,其中包括对象的哈希值。下面我们来看一下HotSpot JVM中hashCode()方法的实现方式。
1、普通对象:
对于普通对象,hashCode()方法的实现方式是将对象的内存地址转化为一个整数作为哈希值。这个内存地址通常是对象头中的Mark Word中存储的地址信息。具体实现代码如下:
public native int hashCode();
首先会从这个对象的存储地址的本身或者从中抽取的一部分作为初始哈希值,再对这个哈希值进行位运算或者加减乘除操作来使数值更加随机以及分散来减少哈希冲突来得到哈希值。
这里需要注意,在 HotSpot 中,对象内存地址由虚拟机来管理的,所以这个值是由操作系统以及硬件来共同计算出来的,是不可预知的因此,即使两个对象在代码中看起来完全相同,它们的内存地址也可能是不同的,因此它们的hashCode()方法生成的哈希值也会不同。所以我们需要重写 hashCode 方法。
2、对于数组对象,hashCode()方法的实现方式是根据数组元素的内容生成哈希值。具体实现代码如下:
public int hashCode() {
int h = 0;
for (int i = 0; i < length; i++) {
h = 31 * h + elementData[i].hashCode();
}
return h;
}
对数组中的每一个元素进行遍历获取其对应的哈希值进行相加操作,h 是初始哈希值。



![[pgrx开发postgresql数据库扩展]2.安装与开发环境的搭建](https://img-blog.csdnimg.cn/img_convert/5532f1f571da5d6ccc54a556a30a4d5f.webp?x-oss-process=image/format,png)