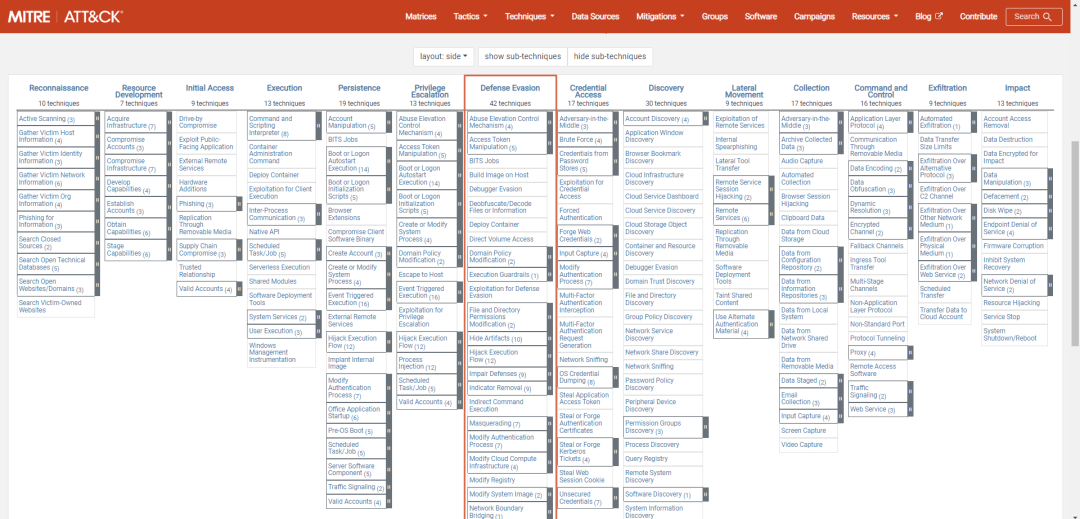
关键词:
零样本泛化能力模型
半监督
减少人工标注成本:
1、CVPR 2023 | 单阶段半监督目标检测SOTA:ARSL https://zhuanlan.zhihu.com/p/620076458
2、CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector https://zhuanlan.zhihu.com/p/620076458
通过实验发现,在具有大量类别的目标检测数据集LVIS、ImageNetBoxes和VisualGenome上,UniDetector表现出强大的零样本泛化能力(也就是数据集中参与训练的图像样本为0个),超过传统监督算法平均4%以上!而在另外13个具有不同场景的目标检测数据集上,UniDetector仅使用3%的训练数据就实现了最先进的性能!
3、最强Zero-Shot视觉应用:Grounding DINO + Segment Anything + Stable Diffusionhttps://zhuanlan.zhihu.com/p/620271321
最强的Zero-Shot检测器 使用这个部分进行数据标注
4、标注方式变化,不是人工画框这种方式,而是,通过语言描述,对数据进行,图像+文本,训练,训练最佳模型,也是可以的
ECCV2022 | RU&谷歌提出用CLIP进行zero-shot目标检测!
https://zhuanlan.zhihu.com/p/546614635
5、如何评价Meta/FAIR 最新工作Segment Anything?
这再次验证了data-centric AI是未来。读了下论文,模型没有什么特别之处,亮点在数据标注。我先介绍下什么是data-centric AI,再分析这篇论文。
GroundingDINO
https://www.zhihu.com/question/593888697/answer/2976688654?utm_id=0
以数据为中心的,+ 强化学习+反馈模型,自动标注数据,从提高数据标注和数量入手
6、目标检测创新:一种基于区域的半监督方法,部分标签即可
研究者们提出了一种基于区域的半监督算法,该算法可以自动识别包含未标记前景对象的区域
7、SegGPT:在上下文中分割一切
这不就是想要的数据标注能力吗,一个目标物体,找到大量未标记图片中的物体
和 SAM 相比,视觉模型的 In-context 能力是最大差异点 :
SegGPT “一通百通”:可使用一个或几个示例图片和对应的掩码即可分割大量测试图片。用户在画面上标注识别一类物体,即可批量化识别分割出其他所有同类物体,无论是在当前画面还是其他画面或视频环境中。
SAM“一触即通”:通过一个点、边界框或一句话,在待预测图片上给出交互提示,识别分割画面上的指定物体。
这也就意味着,SAM的精细标注能力,与SegGPT的批量化标注分割能力,还能进一步相结合,产生全新的CV应用。