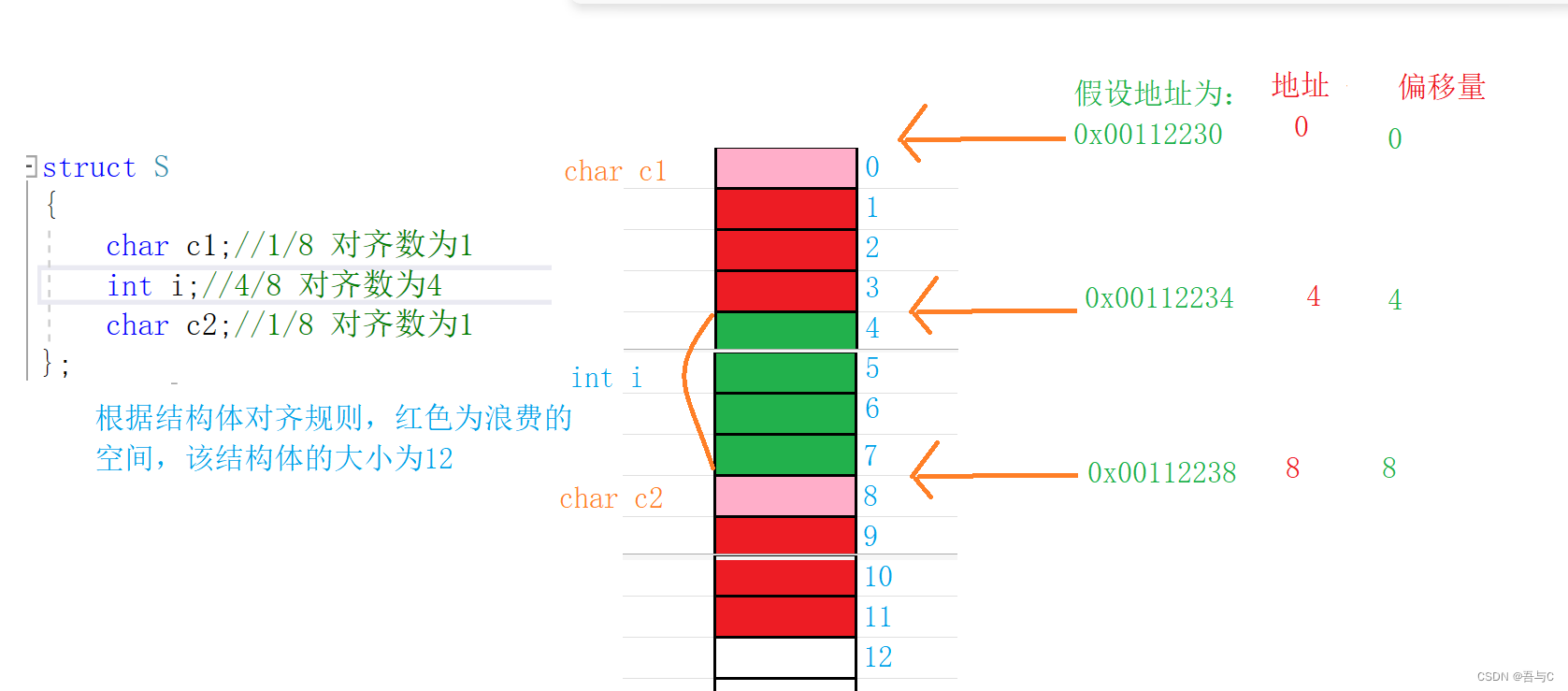
原文:Qt 5 and OpenCV 4 Computer Vision Projects
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、实时对象检测
在上一章中,我们了解了光学字符识别(OCR)技术。 我们借助 Tesseract 库和预训练的深度学习模型(EAST 模型)来识别扫描文档和照片中的文本,该模型已随 OpenCV 一起加载。 在本章中,我们将继续进行对象检测这一主题。 我们将讨论 OpenCV 以及其他库和框架提供的几种对象检测方法。
本章将涵盖以下主题:
- 训练和使用级联分类器检测对象
- 使用深度学习模型进行对象检测
技术要求
与前面的章节一样,要求读者至少安装版本 5 和 OpenCV 4.0.0 的 Qt。 具备一些有关 C++ 和 Qt 编程的基本知识也是一个基本要求。
尽管我们专注于 OpenCV 4.0.0,但在本章中还需要 OpenCV3.4.x。 您应该已经安装了多个版本的 OpenCV(4.0.0 和 3.4.5),才能与本章一起学习。 稍后我将解释原因。
由于我们将使用深度学习模型来检测对象,因此拥有深度学习知识也将有助于理解本章的内容。
本章的所有代码都可以在我们的代码库中找到。
观看以下视频,查看运行中的代码
使用 OpenCV 检测对象
OpenCV 中有许多方法可以进行对象检测。 这些方法可以分类如下:
- 基于颜色的算法,例如均值移位和连续自适应均值移位(CAMshift)
- 模板匹配
- 特征提取与匹配
- 人工神经网络(人工神经网络)
- 级联分类器
- 预先训练的深度学习模型
前三个是传统的对象检测方法,后三个是机器学习方法。
基于颜色的算法(例如均值偏移和 CAMshift)使用直方图和反投影图像以惊人的速度在图像中定位对象。 模板匹配方法将感兴趣的对象用作模板,并尝试通过扫描给定场景的图像来找到对象。 特征提取和匹配方法首先从感兴趣的对象和场景图像中提取所有特征,通常是边缘特征和角点特征,然后使用这些特征进行匹配以找到对象。 所有这些方法在简单和静态的场景中都能很好地工作,并且非常易于使用。 但是它们通常无法在复杂而动态的情况下正常工作。
ANN,级联分类器和深度学习方法被归类为机器学习方法。 他们都需要在使用之前训练模型。 借助 OpenCV 提供的功能,我们可以训练 ANN 模型或级联分类器模型,但目前尚无法使用 OpenCV 训练深度学习模型。 下表显示了这些方法是否可以与 OpenCV 库一起训练或使用,以及它们的表现(在查全率和准确率上)水平:
| 方法 | 可以由 OpenCV 训练 | 可以由 OpenCV 加载 | 效果 |
|---|---|---|---|
| 人工神经网络 | 是 | 是 | 中 |
| 级联分类器 | 是 | 是 | 中 |
| 深度学习模型 | 没有 | 是(多种格式) | 高 |
实际上,人工神经网络和深度学习都是神经网络。 它们之间的区别在于,ANN 模型具有简单的架构,并且只有很少的隐藏层,而深度学习模型可能具有复杂的架构(例如 LSTM,RNN,CNN 等)以及大量的隐藏层 。 在上个世纪,人们使用人工神经网络是因为它们没有足够的计算能力,因此不可能训练复杂的神经网络。 现在,由于过去十年中异构计算的发展,训练复杂的神经网络成为可能。 如今,我们使用深度学习模型是因为它们比简单的 ANN 模型具有更高的表现(在召回率和准确率方面)。
在本章中,我们将重点介绍级联分类器和深度学习方法。 尽管无法使用当前版本的 OpenCV 库训练深度学习模型,但将来可能会实现。
使用级联分类器检测对象
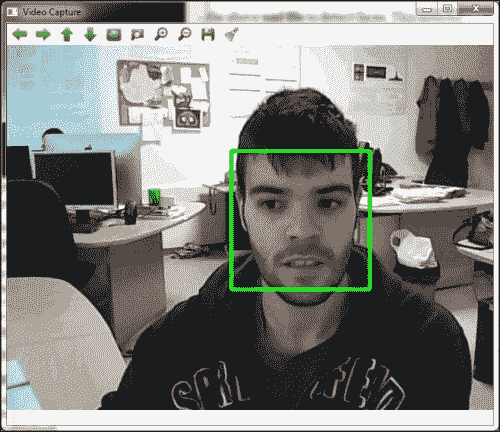
首先,让我们看看如何使用级联分类器检测对象。 实际上,本书已经使用了级联分类器。 在第 4 章,“面部表情”中,我们使用了预训练的级联分类器来实时检测面部。 我们使用的预训练级联分类器是 OpenCV 内置级联分类器之一,可以在 OpenCV 安装的数据目录中找到:
$ ls ~/programs/opencv/share/opencv4/haarcascades/
haarcascade_eye_tree_eyeglasses.xml haarcascade_lefteye_2splits.xml
haarcascade_eye.xml haarcascade_licence_plate_rus_16stages.xml
haarcascade_frontalcatface_extended.xml haarcascade_lowerbody.xml
haarcascade_frontalcatface.xml haarcascade_profileface.xml
haarcascade_frontalface_alt2.xml haarcascade_righteye_2splits.xml
haarcascade_frontalface_alt_tree.xml haarcascade_russian_plate_number.xml
haarcascade_frontalface_alt.xml haarcascade_smile.xml
haarcascade_frontalface_default.xml haarcascade_upperbody.xml
haarcascade_fullbody.xml
如您所见,haarcascade_frontalface_default.xml文件是我们在第 4 章,面对人脸中使用的文件。
在本章中,我们将尝试自己训练级联分类器。 在此之前,我们将首先构建一个应用来测试级联分类器。 我将这个应用称为 Detective。
该应用与我们在第 3 章,“家庭安全应用”(Gazer 应用)和第 4 章中内置的 FacesFaces(Facetious)应用非常相似 ,因此我们将通过应对其中一种应用来快速构建它。
您还记得我们在第 4 章,“人脸上的乐趣”开头所做的事情吗? 我们从第 3 章,“家庭安全应用”复制了 Gazer 应用,然后将其简化为一个基本应用,可以使用该应用播放网络摄像头中的视频供稿并拍照。 我们可以在这个页面上找到该提交的基本应用。 让我们将其复制到终端中:
$ pwd
/home/kdr2/Work/Books/Qt-5-and-OpenCV-4-Computer-Vision-Projects
$ git checkout 744d445
Note: checking out '744d445'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 744d445 Facetious: take photos
$ mkdir Chapter-06
# !!! you should copy it to a different dir
$ cp -r Chapter-04/Facetious Chapter-06/Detective
$ ls Chapter-06
Detective
$git checkout master
$ cd Chapter-06/Detective/
在我们的代码存储库中,我们签出到744d445提交,为此章创建一个新目录,然后将该版本的 Facetious 项目的源树复制到Chapter-06目录下一个名为Detective的新目录中。然后,我们切换回master分支。
在编写本书时,我已将基本应用复制到Chapter-06/Detective目录,因此在您阅读本书时该目录已经存在。 如果您按照说明进行编码,则可以将基本应用复制到另一个新目录并在该目录下工作。
获得基本应用后,我们对其进行一些小的更改:
- 将
Facetious.pro项目文件重命名为Detective.pro。 - 在以下文件中将单词 Facetious 更改为 Detective:
Detective.promain.cppmainwindow.cpputilities.cpp
好的,现在我们有一个基本的侦探应用。 此阶段中的所有更改都可以在这个页面的提交中找到。
接下来的事情是使用预训练的级联分类器检测某种对象。 这次,我们将使用 OpenCV 库中包含的haarcascade_frontalcatface_extended.xml文件来检测猫的脸。
首先,我们打开capture_thread.h文件以添加一些行:
class CaptureThread : public QThread
{
// ...
private:
// ...
void detectObjects(cv::Mat &frame);
private:
// ...
// object detection
cv::CascadeClassifier *classifier;
};
然后,在capture_thread.cpp文件中,我们实现detectObjects方法,如下所示:
void CaptureThread::detectObjects(cv::Mat &frame)
{
vector<cv::Rect> objects;
classifier->detectMultiScale(frame, objects, 1.3, 5);
cv::Scalar color = cv::Scalar(0, 0, 255); // red
// draw the circumscribe rectangles
for(size_t i = 0; i < objects.size(); i++) {
cv::rectangle(frame, objects[i], color, 2);
}
}
在这种方法中,我们通过调用级联分类器的detectMultiScale方法检测对象,然后在图像上绘制检测到的矩形,就像在第 4 章,“人脸上的乐趣”中所做的一样。
接下来,我们在run方法中实例化级联分类器,并在视频捕获无限循环中调用detectObjects方法:
void CaptureThread::run() {
// ...
classifier = new cv::CascadeClassifier(OPENCV_DATA_DIR \
"haarcascades/haarcascade_frontalcatface_extended.xml");
// ...
while(running) {
// ...
detectObjects(tmp_frame);
// ...
}
// ...
delete classifier;
classifier = nullptr;
running = false;
}
如您所见,在无限循环结束后,我们还将销毁级联分类器。
我们更新Detective.pro项目文件,将opencv_objdetect模块添加到链接选项,然后定义OPENCV_DATA_DIR宏:
# ...
unix: !mac {
INCLUDEPATH += /home/kdr2/programs/opencv/include/opencv4
LIBS += -L/home/kdr2/programs/opencv/lib -lopencv_core -lopencv_imgproc -lopencv_imgcodecs -lopencv_video -lopencv_videoio -lopencv_objdetect
}
# ...
DEFINES += OPENCV_DATA_DIR=\\\"/home/kdr2/programs/opencv/share/opencv4/\\\"
# ...
现在我们编译并运行该应用,打开相机,然后将一只猫放到相机的视线中:
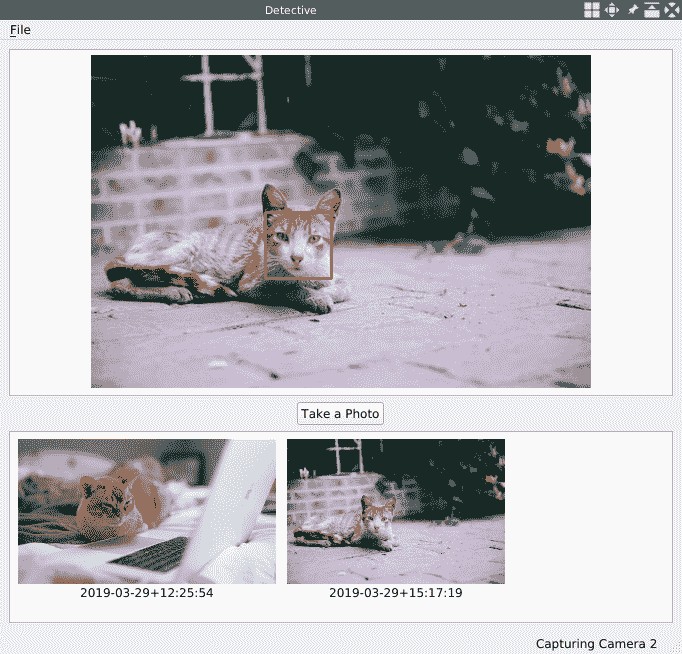
也许你没有猫。 不用担心 cv::VideoCapture类提供了许多其他测试应用的方法。
您可以找到猫的视频并将其放置在本地磁盘上,然后将其路径传递到cv::VideoCapture的结构,而不传递摄像机 ID(例如cv::VideoCapture cap("/home/kdr2/Videos/cats.mp4"))。 构造器还接受视频流的 URI,例如http://some.site.com/some-video.mp4或rtsp://user:password@192.168.1.100:554/camera/0?channel=1。
如果您有很多猫的图片,那也可以。 cv::VideoCapture类的构造器还接受由字符串表示的图像序列。 例如,如果将"image_%02d.jpg"字符串传递给构造器,则cv::VideoCapture实例将读取名称类似于image_00.jpg,image_01.jpg和image_02.jpg等的图像,然后逐一显示为视频帧。
好的,我们已经设置了 Detective 应用,以使用预训练的层叠分类器检测对象。 在下一节中,我们将尝试自己训练级联分类器。 当获得自训练的级联分类器文件时,我们可以将其路径传递给cv::CascadeClassifier类的构造器以加载它,并更改cv::VideoCapture的输入以对其进行测试。
训练级联分类器
OpenCV 提供了一些工具来训练级联分类器,但它们已从 4.0.0 版本中删除。 如我们所提到的,这种删除主要是由于深度学习方法的兴起。 深度学习方法成为现代方法,而其他方法(包括级联分类器)则成为了传统。 但是,世界上仍在使用许多级联分类器,在许多情况下,它们仍然是一个不错的选择。 这些工具可能有一天会重新添加。 您可以在这个页面上找到并参与有关此主题的讨论。
幸运的是,我们可以使用 OpenCV v3.4.x,它提供了这些工具来训练级联分类器。 由 v3.4 训练的结果级联分类器文件与 v4.0.x 兼容。 换句话说,我们可以使用 OpenCV v3.4.x 训练级联分类器,并将其与 OpenCV v4.0.x 一起使用。
首先,我们应该安装 OpenCVv3.4.x。 我们可以使用系统包管理器来安装它,例如yum或apt-get。 我们也可以从这里下载它并从源代码构建它。 如果决定从源代码构建它,请记住将-D BUILD_opencv_apps=yes选项传递给cmake命令。 否则,将无法构建训练工具。 安装后,我们可以在其二进制目录下找到许多可执行文件:
$ ls ~/programs/opencv-3.4.5/bin/
opencv_annotation opencv_createsamples
opencv_interactive-calibration opencv_traincascade
opencv_version opencv_visualisation
setup_vars_opencv3.sh
我们将用来训练级联分类器的工具是opencv_createsamples,opencv_traincascade,有时是opencv_annotation。
opencv_createsamples和opencv_annotation工具用于创建样本,opencv_traincascade工具用于使用创建的样本训练级联分类器。
在训练级联分类器之前,我们必须准备两种样本:正样本和负样本。 正样本应包含我们要检测的对象,而负样本应包含除我们要检测的对象以外的所有内容。 可以通过 OpenCV 提供的工具opencv_createsamples生成正样本。 没有任何工具可以生成负样本,因为负样本可以是任何不包含我们要检测的对象的任意图像。
我们如何准备或产生阳性样本? 让我们看一些例子。
禁止进入的交通标志
在此示例中,我们将训练级联分类器,该分类器将用于检测交通标志,即禁止进入标志:

首先要做的是准备负样本-背景图像。 如前所述,负样本可以是不包含感兴趣对象的任意图像,因此我们可以轻松地为此目的收集一些图像。 收集这些图像后,我们将其路径放在文本文件中。 在该文件中,路径以先列后行格式一个路径,并且该路径可以是绝对路径或相对路径。
在本章中,我们将交替使用短语负面样本图像和背景图像,因为它们在上下文中是相同的。
您可以从这里下载许多交通照片,并选择其中一些不包含任何禁止进入的照片用作背景图像的标志:

我们将它们放在名为background的文件夹中,并将它们的相对路径保存到名为bg.txt的文件中:
$ ls background/
traffic-sign-bg-0.png traffic-sign-bg-1.png traffic-sign-bg-2.png traffic-sign-bg-3.png
$ ls background/* > bg.txt
$ cat bg.txt
background/traffic-sign-bg-0.png
background/traffic-sign-bg-1.png
background/traffic-sign-bg-2.png
background/traffic-sign-bg-3.png
这些图像可以具有不同的大小。 但是它们都不应该小于训练窗口的大小。 通常,训练窗口的大小是我们感兴趣的对象的平均大小,即禁止进入标志的图像。 这是因为将从这些背景图像中获取具有训练窗口大小作为其维度的负样本。 如果背景图像小于示例图像,则无法执行此操作。
好,负片图像已准备就绪。 让我们继续进行阳性样本的制备。
如前所述,我们将使用opencv_createsamples工具生成正样本。 正样本将用于训练过程中,以告诉级联分类器感兴趣的对象实际是什么样。
为了创建阳性样本,我们将感兴趣的对象(非进入符号)保存为名为no-entry.png的文件,位于background文件夹和bg.txt文件所在的目录中。 然后我们按以下方式调用opencv_createsamples工具:
opencv_createsamples -vec samples.vec -img no-entry.png -bg bg.txt \
-num 200 -bgcolor 0 -bgthresh 20 -maxidev 30 \
-maxxangle 0.3 -maxyangle 0.3 -maxzangle 0.3 \
-w 32 -h 32
如您所见,在运行该工具时,我们提供了许多参数,这似乎很可怕。 但是不用担心。 我们将一一解释:
-vec参数用于指定我们要创建的正样本文件。 在本例中,我们使用samples.vec作为文件名。-img参数用于指定我们要检测的对象的图像。 该工具将使用它来生成阳性样本。 正如我们所提到的,在我们的例子中是no-entry.png。-bg参数用于指定背景图像的描述文件。 我们的是bg.txt,其中包含四个选定背景的相对路径。-num参数是要生成的正样本数。-bgcolor自变量用于指定感兴趣对象的图像的背景色。 背景色表示透明色,在生成样本时将被视为透明色。 我们在这里使用的感兴趣图像的背景是黑色,因此在这里使用零。 在某些情况下,例如,当图像上出现压缩伪像时,给定图像的背景色将具有多种颜色,而不是单一的颜色值。 为了应对这种情况,还有一个名为-bgthresh的参数指定背景的颜色容忍度。 如果指定此参数,则颜色在bgcolor - bgthresh和bgcolor + bgthresh之间的像素将被解释为透明的。- 正如我们提到的,
-bgthresh参数指定bgcolor的阈值。 -maxidev自变量用于设置生成样本时前景像素值的最大强度偏差。 值 30 表示前景像素的强度可以在其原始值 +30 和其原始值 -30 之间变化。-maxxangle,-maxyangle和-maxzangle自变量对应于创建新样本时,x,y和z方向所允许的最大可能旋转。 这些值以弧度为单位。 在这里,我们使用 0.3、0.3 和 0.3,因为交通标志通常不会在照片中剧烈旋转。-w和-h自变量定义了样本的宽度和高度。 我们都使用了 32,因为我们要寻找的对象是训练一个适合正方形的分类器。 这些相同的值将在以后训练分类器时使用。 另外,请注意,这将是稍后您训练有素的分类器中可检测到的最小大小。
命令返回后,将生成示例文件。 我们可以使用相同的工具来查看样本:
opencv_createsamples -vec samples.vec -show
如果运行此命令,将出现一个32 x 32大小的窗口,其中带有单个样本图像。 您可以按N查看下一个,或按Esc键退出。 这些阳性样本在我的计算机上如下所示:

好了,阳性样本已经准备好了。 让我们训练级联分类器:
mkdir -p classifier
opencv_traincascade -data classifier -numStages 10 -featureType HAAR \
-vec samples.vec -bg bg.txt \
-numPos 200 -numNeg 200 -h 32 -w 32
我们首先为输出文件创建一个新目录,然后使用许多参数调用opencv_traincascade工具:
-data参数指定输出目录。 训练有素的分类器和许多中间文件将放置在此目录中。 该工具不会为我们创建目录,因此我们应该像运行mkdir命令一样,在运行命令之前自行创建目录。-vec参数指定由opencv_createsamples工具创建的正样本文件。-bg参数用于指定背景描述文件,在本例中为bg.txt文件。-numPos参数指定在每个分类器阶段的训练过程中将使用多少阳性样本。-numNeg参数指定在每个分类器阶段的训练中将使用多少个负样本。-numStages参数指定将训练多少个级联阶段。-featureType参数指定特征的类型。 它的值可以是 HAAR 或 LBP。-w和-h自变量指定训练过程中使用的样本的宽度和高度(以像素为单位)。 这些值必须与我们使用opencv_createsamples工具生成的阳性样本的宽度和高度完全相同。
该命令的运行将花费几分钟到几小时。 一旦返回,我们将在用作-data参数值的目录(即classifier目录)中找到许多输出文件:
$ ls classifier/
cascade.xml stage10.xml stage5.xml stage9.xml
params.xml stage2.xml stage6.xml
stage0.xml stage3.xml stage7.xml
stage1.xml stage4.xml stage8.xml
让我们看看这些文件的用途:
params.xml文件包含用于训练分类器的参数。stage<NN>.xml文件是在每个训练阶段完成之后创建的检查点。 如果训练过程意外终止,则可以使用它们稍后重新开始训练。cascade.xml文件是经过训练的分类器,也是由训练工具创建的最后一个文件。
让我们现在测试我们新训练的级联分类器。 打开capture_thread.cpp文件,在run方法中找到创建分类器的行,然后将我们新训练的分类器文件的路径传递给它:
classifier = new cv::CascadeClassifier("../no-entry/classifier/cascade.xml");
在detectObjects方法中,当调用分类器的detectMultiScale方法时,我们将第四个参数minNeighbors更改为3。
好,一切都完成了。 让我们编译并运行该应用。 打开照相机; 您将看到一个这样的窗口:

如果您不方便使用计算机上的网络摄像头捕获包含禁止进入标志的视频,则可以从互联网上搜索并下载此类视频或某些图片,然后将其传递给cv::VideoCapture实例以执行测试。
我将训练该级联分类器所需的所有命令包装到一个外壳脚本中,并将其放入本书随附的代码存储库中的Chapter-06/no-entry目录中。 在我的计算机上的该目录中,还有一个名为cascade.xml的级联分类器文件。 请注意,您的训练结果可能与我的完全不同。 如果在同一环境中重新运行训练,我们甚至会得到不同的结果。 您可以摆弄对象图像,背景图像和训练参数,以自己找到可接受的输出。
在本小节中,我们训练交通标志的分类器,并使用交通标志的特定图像来生成正样本。 这种生成样本的方法非常适用于稳定的对象,例如固定的徽标或固定的交通标志。 但是,一旦给它一些刚度不高的物体(例如人或动物的脸),我们就会发现它是失败的。 在这种情况下,我们应该使用另一种方法来生成阳性样本。 在这种替代方法中,我们应该收集许多真实的对象图像,并使用opencv_annotation工具对其进行标注。 然后,我们可以使用opencv_createsamples工具从带标注的图像中创建正样本。 我们将在下一部分中尝试这种方法。
波士顿公牛队的人脸
在本小节中,我们将训练一个级联分类器,用于一个不太刚性的对象:狗脸。
我们将使用这个页面中的数据集。 该数据集包含 20,580 张狗的图像,分为 120 个类别,每个类别都是一个犬种。 让我们下载并解压缩图像的压缩包:
$ curl -O http://vision.stanford.edu/aditya86/ImageNetDogs/images.tar
$ tar xvf images.tar
# output omitted
$ ls Images/
n02085620-Chihuahua n02091635-otterhound
n02097298-Scotch_terrier n02104365-schipperke
n02109525-Saint_Bernard n02085782-Japanese_spaniel
# output truncated
我们将把波士顿公牛犬种的人脸作为目标。 Images/n02096585-Boston_bull目录中有 182 张波士顿公牛的图像。 与固定物体(例如交通标志)不同,我们找不到波士顿公牛队脸部的标准图片。 我们应该在刚刚选择的 182 张图像上标注狗的脸。 标注是使用 OpenCV v3.4.x 提供的opencv_annotation工具完成的:
rm positive -fr
cp -r Images/n02096585-Boston_bull positive
opencv_annotation --annotations=info.txt --images=positive
我们将包含波士顿牛市图像的目录复制到新的positive目录中,以明显方便地将它们用作正图像。 然后,我们使用两个参数调用opencv_annotation工具:
--annotations参数指定标注的输出文件。--images参数指定一个文件夹,其中包含我们要标注的图像。
调用opencv_annotation工具将打开一个窗口,显示需要标注的图像。 我们可以使用鼠标和键盘在图像上做标注:
- 左键单击鼠标以标记标注的起点。
- 移动鼠标。 您将看到一个矩形; 通过移动鼠标来调整此矩形以适合狗的脸。
- 当您得到适当的矩形时,停止移动鼠标,然后再次单击鼠标左键。 您将获得一个固定的红色矩形。
- 现在,您可以按键盘上的
D键删除矩形,或按C键确认矩形。 如果确认为矩形,它将变为绿色。 - 您可以重复这些步骤以在图像上标记多个矩形。
- 完成当前图像的标注后,请按键盘上的
N键以转到下一张图像。 - 您可以按
Esc退出该工具。
这是我标注狗脸时该工具的屏幕截图:

我们应该在 182 张图像中仔细标记所有的狗脸。 这将是一个繁琐的过程,因此我在代码存储库的Chapter-06/boston-bull目录中提供了标注过程的结果文件info.txt文件。 该文件的数据格式非常简单:
positive/n02096585_10380.jpg 1 7 4 342 326
positive/n02096585_11731.jpg 1 158 218 93 83
positive/n02096585_11776.jpg 2 47 196 104 120 377 76 93 98
positive/n02096585_1179.jpg 1 259 26 170 165
positive/n02096585_12825.jpg 0
positive/n02096585_11808.jpg 1 301 93 142 174
上面的列表是从info.txt文件中选取的一些行。 我们可以看到此文件的每一行都是单个图像的信息,并且该信息以PATH NUMBER_OF_RECT RECT0.x RECT0.y RECT0.width RECT0.height RECT1.x RECT1.y RECT1.width RECT1.height ...格式组织。
借助此标注信息文件,我们可以创建正样本:
opencv_createsamples -info info.txt -vec samples.vec -w 32 -h 32
如您所见,它比上次使用opencv_createsamples工具要简单。 我们不需要为其提供背景图像,感兴趣对象的图像以及使对象变形的最大角度。 只给它注解数据作为-info参数就足够了。
调用返回后,我们在samples.vec文件中获得了正样本。 同样,我们可以使用opencv_createsamples工具进行查看:
opencv_createsamples -vec samples.vec -show
您可以通过按键盘上的N在提示窗口中一一查看所有样本。 这些样本如下所示:

现在可以准备好阳性样本了,该准备背景图像了。 Briard 品种的狗与 Boston Bulls 有很大的不同,因此我决定将这些图像用作背景图像:
rm negative -fr
cp -r Images/n02105251-briard negative
ls negative/* >bg.txt
我们将目录Images/n02105251-briard复制到negative目录,并将该目录下所有图像的相对路径保存到bg.txt文件。 bg.txt文件只是我们的背景描述文件:
negative/n02105251_1201.jpg
negative/n02105251_1240.jpg
negative/n02105251_12.jpg
negative/n02105251_1382.jpg
negative/n02105251_1588.jpg
...
正样本和背景图像都已准备就绪,因此让我们训练分类器:
mkdir -p classifier
opencv_traincascade -data classifier -vec samples.vec -bg bg.txt \
-numPos 180 -numNeg 180 -h 32 -w 32
此步骤与我们训练分类器的禁止进入交通标志的步骤非常相似。 值得注意的是,我们在这里使用-numPos 180,因为在samples.vec文件中只有 183 个阳性样本。
训练过程完成后,我们将在classifier目录下获得训练后的分类器,作为cascade.xml文件。 让我们现在尝试这个新训练的分类器。
首先,我们以CaptureThread::run()方法加载它:
classifier = new cv::CascadeClassifier("../boston-bull/classifier/cascade.xml");
然后,在CaptureThread::detectObjects方法中将detectMultiScale调用的minNeighbors参数更改为5:
int minNeighbors = 5; // 3 for no-entry-sign; 5-for others.
classifier->detectMultiScale(frame, objects, 1.3, minNeighbors);
让我们编译并运行 Detective 应用,并在一些材料上测试我们的新分类器:

好,还不错,我们训练了两个级联分类器。 您可能对在训练过程中如何选择 HAAR 或 LBP 特征感到好奇,所以让我们更深入一些。
OpenCV 提供了一个名为opencv_visualisation的工具,以帮助我们可视化训练有素的级联。 有了它,我们可以看到在每个阶段选择的级联分类器具有哪些特征:
$ mkdir -p visualisation
$ opencv_visualisation --image=./test-visualisation.png \
--model=./classifier/cascade.xml \
--data=./visualisation/
我们创建一个新目录,并使用许多参数调用opencv_visualisation工具:
--image参数用于指定图像的路径。 该图像应该是感兴趣的图像,具有我们在创建样本和训练分类器时使用的尺寸,即,波士顿牛头犬脸的32 x 32图像。--model参数是新训练模型的路径。--data是输出目录。 它必须以斜杠(/)结尾,并且必须预先手动创建目录。
当此命令返回时,我们将在输出目录中获得许多图像和一个视频文件:
$ ls visualisation/
model_visualization.avi stage_14.png stage_1.png stage_7.png
stage_0.png stage_15.png stage_2.png stage_8.png
stage_10.png stage_16.png stage_3.png stage_9.png
stage_11.png stage_17.png stage_4.png
stage_12.png stage_18.png stage_5.png
stage_13.png stage_19.png stage_6.png
制作了一个名为model_visualization.avi的视频,用于每个阶段的特征可视化; 您可以播放它以查看级联分类器如何选择特征。 此外,输出目录中的每个阶段都有一个图像。 我们可以检查这些图像以查看特征选择。
我们用于训练该分类器的所有材料,以及经过处理的cascade.xml,都位于我们代码存储库中的Chapter-06/boston-bull目录中。 请随便摆弄它们。
使用深度学习模型检测对象
在上一节中,我们学习了如何训练和使用级联分类器来检测对象。 但是,与不断扩展的深度学习方法相比,在召回率和准确率方面都提供了较差的表现。 OpenCV 库已经开始转向深度学习方法。 在 3.x 版中,它引入了深度神经网络(DNN)模块,现在在最新版本 v4.x 中,我们可以加载多种格式的神经网络架构, 以及他们的预训练权重。 另外,正如我们提到的,在最新版本中不推荐使用用于训练级联分类器的工具。
在本节中,我们将继续进行深度学习方法,以了解如何使用 OpenCV 来检测对象是深度学习方法。 我们已经使用过这种方法。 在第 5 章,“光学字符识别”中,我们使用了预训练的 EAST 模型来检测照片上的文本区域。 这是使用 TensorFlow 框架开发和训练的深度学习模型。 除了由 TensorFlow 框架训练的 DNN 模型外,OpenCV 还支持来自许多其他框架的多种格式的模型:
- 来自 Caffe 而非 Caffe2 的
*.caffemodel格式, - TensorFlow 的
*.pb格式 - Torch 而非 PyTorch 的
*.t7或*.net格式 - Darknet 的
*.weights格式 - DLDT 中的
*.bin格式
如您所见,尽管 OpenCV 支持多种 DNN 模型,但是仍然有一些流行的深度学习框架不在前面的列表中;例如, PyTorch 框架,Caffe2 框架,MXNet 和 Microsoft 认知工具包(CNTK)。 幸运的是,存在一种称为开放式神经网络交换(ONNX)的格式,该格式由其社区开发和支持,并且 OpenCV 库现在可以加载此格式的模型 。
大多数流行的深度学习框架(包括我刚才提到的框架)也支持 ONNX 格式。 因此,如果您开发的 DNN 模型的框架不在 OpenCV 支持列表中,则可以将模型架构和经过训练的权重保存为 ONNX 格式。 然后它将与 OpenCV 库一起使用。
OpenCV 库本身不具备构建和训练 DNN 模型的能力,但是由于它可以加载和转发 DNN 模型,并且比其他深度学习框架具有更少的依赖关系,因此,部署 DNN 模型确实是一个很好的解决方案 。 OpenCV 团队和英特尔还创建并维护了其他一些专注于机器学习模型部署的项目,例如 DLDT 和 OpenVINO 项目。
如果我们无法使用 OpenCV 训练模型,我们如何获得可与 OpenCV 一起使用以检测对象的模型? 最简单的方法是找到一个预先训练的模型。 最受欢迎的深度学习框架都有一个model zoo,它收集了许多使用该框架构建和预训练的模型。 您可以在互联网上搜索框架名称以及关键字model zoo来找到它们。 这些是我发现的一些:
- TensorFlow
- Caffe
- Caffe2
- MXNet
另外,您可以在这里找到许多开源的预训练模型。
现在,让我们回到对象检测的主题。 通常,有三种基于深度学习的对象检测器:
- 基于 R-CNN 的检测器,包括 R-CNN,Fast R-CNN 和 Faster R-CNN
- 单发检测器(SSD)
- 只看一次(YOLO)
在基于区域特征的 CNN(R-CNN)中,我们首先需要使用一种算法,提出可能包含对象的候选边界框,然后将这些候选框发送到卷积神经网络(CNN)模型进行分类。 因此,这种检测器也称为两级检测器。 这种方法的问题是它非常慢并且不是端到端的深度学习对象检测器(因为我们需要在进入 CNN 模型之前搜索候选框并做一些其他工作)。 尽管 R-CNN 进行了两次改进(使用 Fast R-CNN 和 Faster R-CNN),即使在 GPU 上,这些方法仍然不够快。
R-CNN 方法使用两阶段策略,而 SSD 和 YOLO 方法使用一个阶段策略。 一阶段策略将对象检测视为回归问题,获取给定的输入图像,同时学习边界框坐标和相应的类标签概率。 通常,一级检测器的精度往往不如二级检测器,但要快得多。 例如,由这里引入的单阶段策略 YOLO 的著名实现在 GPU 上具有可飙升至 45 FPS 的性能,其中两级检测器可能仅具有 5-10 FPS 的性能。
在本节中,我们将使用预训练的 YOLOv3 检测器来检测对象。 在 COCO 数据集上训练了该模型; 它可以检测数百种对象。 要在 OpenCV 中使用此模型,我们首先应为其下载一些文件:
- 对象类名称的文本文件,位于这个页面
- 模型的配置文件,位于这个页面
- 模型的预训练权重,位于这个页面
现在,让我们将它们下载到我们的侦探应用的data子目录中:
$ pwd
/home/kdr2/Work/Books/Qt-5-and-OpenCV-4-Computer-Vision-Projects/Chapter-06/Detective
$ mkdir data
$ cd data/
$ curl -L -O https://raw.githubusercontent.com/pjreddie/darknet/master/data/coco.names
# output omitted
$ curl -L -O https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/yolov3.cfg
# output omitted
$ curl -L -O https://pjreddie.com/media/files/yolov3.weights
# output omitted
$ ls -l
total 242216
-rw-r--r-- 1 kdr2 kdr2 625 Apr 9 15:23 coco.names
-rw-r--r-- 1 kdr2 kdr2 8342 Apr 9 15:24 yolov3.cfg
-rw-r--r-- 1 kdr2 kdr2 248007048 Apr 9 15:49 yolov3.weights
准备好这三个文件后,我们可以在应用中加载模型。 首先,让我们打开capture_thread.h头文件以添加一些方法和字段:
// ...
#include "opencv2/dnn.hpp"
// ...
class CaptureThread : public QThread
{
// ...
private:
// ...
void detectObjectsDNN(cv::Mat &frame);
private:
// ...
cv::dnn::Net net;
vector<string> objectClasses;
};
首先,我们将添加include指令以包含opencv2/dnn.hpp头文件,因为我们将使用 DNN 模块。 这些是方法和字段:
- 方法
detectObjectsDNN用于使用 DNN 模型检测帧中的对象。 - 成员字段
cv::dnn::Net net是 DNN 模型实例。 - 成员字段
vector<string> objectClasses将保存 COCO 数据集中的对象的类名称。
让我们打开源代码capture_thread.cpp,以查看detectObjectsDNN方法的实现:
void CaptureThread::detectObjectsDNN(cv::Mat &frame)
{
int inputWidth = 416;
int inputHeight = 416;
if (net.empty()) {
// give the configuration and weight files for the model
string modelConfig = "data/yolov3.cfg";
string modelWeights = "data/yolov3.weights";
net = cv::dnn::readNetFromDarknet(modelConfig, modelWeights);
objectClasses.clear();
string name;
string namesFile = "data/coco.names";
ifstream ifs(namesFile.c_str());
while(getline(ifs, name)) objectClasses.push_back(name);
}
// more code here ...
}
在此方法的开头,我们为 YOLO 模型定义了输入图像的宽度和高度。 共有三个选项:320 x 320、416 x 416和608 x 608。在这里,我们选择416 x 416,所有输入图像都将调整为该尺寸。
我们检查net字段是否为空。 如果为空,则意味着我们尚未加载模型,因此我们使用模型配置文件和权重文件的路径调用cv::dnn::readNetFromDarknet函数以加载模型。
之后,我们通过创建ifstream的实例来打开data/coco.names文件。 如前所述,该文件包含 COCO 数据集中对象的所有类名称:
$ wc -l data/coco.names
80 data/coco.names
$ head data/coco.names
person
bicycle
car
motorbike
aeroplane
bus
train
truck
boat
traffic light
在 shell 命令和先前的输出中,我们可以看到总共有 80 个类名。 通过使用head命令查看前十个名称,我们也可以大致了解这些名称。 让我们继续我们的 C++ 代码。 我们逐行读取打开的文件,然后将读取的名称(即每一行)推送到成员字段objectClasses。 完成此操作后,objectClasses字段将保存所有 80 个名称。
好的,模型和类名都已加载。 接下来,我们应该转换输入图像并将其传递给 DNN 模型以进行正向传播以获得输出:
cv::Mat blob;
cv::dnn::blobFromImage(
frame, blob, 1 / 255.0,
cv::Size(inputWidth, inputHeight),
cv::Scalar(0, 0, 0), true, false);
net.setInput(blob);
// forward
vector<cv::Mat> outs;
net.forward(outs, getOutputsNames(net));
转换通过调用cv::dnn::blobFromImage方法完成。 这个调用有点复杂,所以让我们逐个分析参数:
- 第一个参数是输入图像。
- 第二个参数是输出图像。
- 第三个是每个像素值的比例因子。 我们在这里使用
1 / 255.0,因为模型要求像素值是0到1范围内的浮点数。 - 第四个参数是输出图像的空间大小; 我们在这里使用
416 x 416,以及我们定义的变量。 - 第五个参数是平均值,应该从每个图像中减去平均值,因为在训练模型时会使用该平均值。 YOLO 不执行均值减法,因此在此我们使用零。
- 下一个参数是我们是否要交换 R 和 B 通道。 这是我们必需的,因为 OpenCV 使用 BGR 格式,而 YOLO 使用 RGB 格式。
- 最后一个参数是我们是否要裁剪图像并进行中心裁剪。 在这种情况下,我们指定
false。
关键参数是比例因子(第三个)和均值(第五个)。 在转换中,首先从输入图像的每个像素中减去平均值,然后将像素乘以比例因子,即,将输出 BLOB 的像素计算为output_pixel = (input_pixel - mean) * scale_factor。
但是,我们如何知道应该为模型使用这两个参数的哪些值? 一些模型同时使用均值减法和像素缩放,一些模型仅使用均值减法而不使用像素缩放,而某些模型仅使用像素法缩放而不使用平均减法。 对于特定的模型,了解这些值的详细信息的唯一方法是阅读文档。
获取输入 BLOB 后,通过调用模型的setInput方法将其传递给 DNN 模型,然后对模型执行转发。 但是我们必须知道在执行前向传递时要通过转发获得哪些层。 这是通过名为getOutputsNames的辅助函数完成的,我们也在capture_thread.cpp源文件中实现了该函数:
vector<string> getOutputsNames(const cv::dnn::Net& net)
{
static vector<string> names;
vector<int> outLayers = net.getUnconnectedOutLayers();
vector<string> layersNames = net.getLayerNames();
names.resize(outLayers.size());
for (size_t i = 0; i < outLayers.size(); ++i)
names[i] = layersNames[outLayers[i] - 1];
return names;
}
DNN 模型的输出层的索引可以通过getUnconnectedOutLayers方法获得,而所有层的名称都可以通过getLayerNames方法获得。 如果我们监视getLayerNames方法的结果向量,则将在此 YOLO 模型中发现 254 层。 在我们的函数中,我们获得所有这 254 个名称,然后选择未连接输出层的索引所指示的名称。 实际上,此函数只是cv::dnn::Net.getUnconnectedOutLayersNames()方法的另一个版本。 在这里,我们使用自制版本来了解有关cv::dnn::Net类的更多信息。
让我们回到我们的detectObjectsDNN方法。 转发完成后,我们将在vector<cv::Mat> outs变量中获取输出层的数据。 所有信息(包括我们检测到的盒子中的对象,以及它们的置信度和类索引)都在此矩阵向量中。 我们在capture_thread.cpp源文件中编写了另一个辅助函数,以对向量进行解码以获得所需的所有信息:
void decodeOutLayers(
cv::Mat &frame, const vector<cv::Mat> &outs,
vector<int> &outClassIds,
vector<float> &outConfidences,
vector<cv::Rect> &outBoxes
)
{
float confThreshold = 0.5; // confidence threshold
float nmsThreshold = 0.4; // non-maximum suppression threshold
vector<int> classIds;
vector<float> confidences;
vector<cv::Rect> boxes;
// not finished, more code here ...
}
此函数将原点框架和输出层的数据作为其内部参数,并通过其外部参数返回检测到的对象框及其类索引和置信度。 在函数主体的开头,我们定义了几个变量,例如置信度阈值和非最大抑制阈值,以及在过滤之前检测到的所有对象的框信息。
然后,我们遍历输出层中的矩阵:
for (size_t i = 0; i < outs.size(); ++i) {
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols)
{
cv::Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
cv::Point classIdPoint;
double confidence;
// get the value and location of the maximum score
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold)
{
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.cols);
int height = (int)(data[3] * frame.rows);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
}
让我们以输出向量中的单个矩阵(即代码中的outs[i])为例。 矩阵中的每一行代表一个检测到的框。 每行包含(5 + x)元素,其中x是coco.names文件中类名称的数量,即 80,如上所述。
前四个元素表示框的center_x,center_y,width和height。 第五个元素表示边界框包围对象的置信度。 其余元素是与每个类别相关的置信度。 将该框分配给与该框的最高分数相对应的类别。
换句话说,row[i + 5]的值是该框是否包含objectClasses[i]类的对象的置信度。 因此,我们使用cv::minMaxLoc函数来获得最大的置信度及其位置(索引)。 然后,我们检查置信度是否大于定义的置信度阈值。 如果为true,则将框解码为cv::Rect,然后将框及其类索引和置信度推入boxes,classIds和confidences定义的变量。
下一步是将解码后的框和置信度传递给非最大抑制,以减少重叠框的数量。 未消除的框的索引将存储在cv::dnn::NMSBoxes函数的最后一个参数中,即indices变量:
// non maximum suppression
vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
outClassIds.push_back(classIds[idx]);
outBoxes.push_back(boxes[idx]);
outConfidences.push_back(confidences[idx]);
}
最后,我们迭代保留的索引,并将相应的框及其类索引和置信度推入外部参数。
decodeOutLayers函数完成后,让我们再次回到detectObjectsDNN方法。 通过调用新实现的decodeOutLayers函数,我们可以获得检测到的对象的所有信息。 现在让我们在原点框架上绘制它们:
for(size_t i = 0; i < outClassIds.size(); i ++) {
cv::rectangle(frame, outBoxes[i], cv::Scalar(0, 0, 255));
// get the label for the class name and its confidence
string label = objectClasses[outClassIds[i]];
label += cv::format(":%.2f", outConfidences[i]);
// display the label at the top of the bounding box
int baseLine;
cv::Size labelSize = cv::getTextSize(label,
cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int left = outBoxes[i].x, top = outBoxes[i].y;
top = max(top, labelSize.height);
cv::putText(frame, label, cv::Point(left, top),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(255,255,255));
}
使用前面的代码,我们绘制了检测到的对象的边界框。 然后在每个框的左上角绘制一个字符串,其中包含类名和相应检测到的对象的置信度。
至此,用 YOLO 检测物体的工作完成了。 但是,在编译和运行应用之前,还有几件事要做。
首先,在CaptureThread::run()方法中,将调用更改为detectObjects方法,该方法使用级联分类器来检测对我们新增方法detectObjectsDNN的调用的对象:
// detectObjects(tmp_frame);
detectObjectsDNN(tmp_frame);
其次,我们将opencv_dnn模块添加到Detective.pro项目文件中LIBS配置的末尾:
unix: !mac {
INCLUDEPATH += /home/kdr2/programs/opencv/include/opencv4
LIBS += -L/home/kdr2/programs/opencv/lib -lopencv_core -lopencv_imgproc -lopencv_imgcodecs -lopencv_video -lopencv_videoio -lopencv_objdetect -lopencv_dnn
}
现在,让我们编译并运行我们的应用以对其进行测试。 这是我通过相机观察桌面时的侦探应用的屏幕截图:

这是运动场景图像的屏幕截图:

如您所见,YOLO 在对象检测方面确实做得很好。 但是仍然有一些错误的预测。 在第一个屏幕截图中,YOLO 将我的 iPad 识别为 0.67 的笔记本电脑。 在第二张屏幕截图中,它以 0.62 的置信度将足球场识别为电视监视器。 为了消除这些错误的预测,我们可以将置信度阈值设置得更高一些,例如 0.70。 我将留给您摆弄参数。
值得注意的是,YOLO 模型有其缺点。 例如,它不能始终很好地处理小对象,尤其是不能处理紧密组合在一起的对象。 因此,如果您要处理小对象或组合在一起的对象的视频或图像,则 YOLO 不是最佳选择。
到目前为止,我们已经讨论了如何找到使用许多深度学习框架构建的预训练 DNN 模型,以及如何在 OpenCV 中使用它们。 但是,如果没有针对您的案例的预训练模型,例如,检测不在COCO数据集中的某种对象,该怎么办? 在这种情况下,您应该自己构建和训练 DNN 模型。 对于每个深度学习框架,都有一个有关如何在 MNIST 或 CIFAR-10/100 数据集上构建和训练模型的教程。 请遵循这些教程。 您将学习如何为您的用例训练 DNN 模型。 还有一个名为 Keras 的框架,该框架提供了用于构建,训练和运行 DNN 模型的高级 API。 它使用 TensorFlow,CNTK 和 Theano 作为其基础框架。 对于初学者来说,使用 Keras 提供的友好 API 也是一个不错的选择。 本书侧重于 OpenCV,而这些知识已超出其范围,因此我将把学习训练 DNN 模型的任务交给您。
关于实时
当我们处理视频时,无论是视频文件还是来自摄像机的实时视频源,我们都知道视频的帧频通常约为 24-30 FPS。 这意味着我们有 33-40 毫秒来处理每个帧。 如果我们花费的时间更多,则会从实时视频源中丢失一些帧,或者从视频文件中获得较慢的播放速度。
现在,让我们向应用中添加一些代码,以测量检测对象时每帧花费的时间。 首先,在Detective.pro项目文件中,添加一个新的宏定义:
DEFINES += TIME_MEASURE=1
我们将使用此宏来打开或关闭时间测量代码。 如果要关闭时间测量,只需将这一行注释掉,然后通过运行make clean && make命令重建应用。
然后,在CaptureThread::run方法的capture_thread.cpp文件中,我们在detectObjects或detectObjectsDNN方法的调用前后添加一些行:
#ifdef TIME_MEASURE
int64 t0 = cv::getTickCount();
#endif
detectObjects(tmp_frame);
// detectObjectsDNN(tmp_frame);
#ifdef TIME_MEASURE
int64 t1 = cv::getTickCount();
double t = (t1 - t0) * 1000 /cv::getTickFrequency();
qDebug() << "Detecting time on a single frame: " << t <<"ms";
#endif
在前面的代码中,cv::getTickCount函数返回从头开始的时钟周期数(系统启动的时间)。 我们在检测之前和之后两次调用它。 之后,使用t1 - t0表达式获取检测对象时的时钟周期。 由于cv::getTickFrequency()函数返回一秒内有多少个时钟周期,因此我们可以通过(t1 - t0) * 1000 /cv::getTickFrequency()将经过的时钟周期数转换为毫秒。 最后,我们通过qDebug()输出与时间使用相关的消息。
如果使用级联分类器方法编译并运行“侦探”应用,则会看到类似以下的消息:
Detecting time on a single frame: 72.5715 ms
Detecting time on a single frame: 71.7724 ms
Detecting time on a single frame: 73.8066 ms
Detecting time on a single frame: 71.7509 ms
Detecting time on a single frame: 70.5172 ms
Detecting time on a single frame: 70.5597 ms
如您所见,我在每个帧上花费了 70 毫秒以上。 该值应大于(33-40)。 就我而言,这主要是因为我的计算机中装有旧的 CPU,大约是十年前购买的,并且没有降低输入帧的分辨率。 为了优化这一点,我们可以使用功能更强大的 CPU,并将输入帧的大小调整为更小,更合适的大小。
在使用前面的代码来衡量 YOLO 方法使用的时间之前,让我们向CaptureThread::detectObjectsDNN方法中添加一些代码行:
// ...
net.forward(outs, getOutputsNames(net));
#ifdef TIME_MEASURE
vector<double> layersTimes;
double freq = cv::getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
qDebug() << "YOLO: Inference time on a single frame: " << t <<"ms";
#endif
在 DNN 模型上执行转发后,我们调用其getPerfPerofile方法来获取在前向传递中花费的时间。 然后我们将其转换为毫秒并打印。 通过这段代码,我们将获得两次:一次是调用detectObjectsDNN方法所花费的总时间;另一次是调用detectObjectsDNN方法所花费的总时间。 另一个是推理时间,即在前向传递上花费的时间。 如果从第一个中减去第二个,我们将得到花在 BLOB 准备和结果解码上的时间。
让我们在run方法中切换到 YOLO 方法并运行该应用:
YOLO: Inference time on a single frame: 2197.44 ms
Detecting time on a single frame: 2209.63 ms
YOLO: Inference time on a single frame: 2203.69 ms
Detecting time on a single frame: 2217.69 ms
YOLO: Inference time on a single frame: 2303.73 ms
Detecting time on a single frame: 2316.1 ms
YOLO: Inference time on a single frame: 2203.01 ms
Detecting time on a single frame: 2215.23 ms
哦,不,这太慢了。 但是我们说 YOLO 性能飙升至 45 FPS,这意味着它在每个帧上仅花费 22 毫秒。 为什么我们的结果慢 100 倍? 性能可能会飙升至 45 FPS,但这是在 GPU 而非 CPU 上测得的。 深度神经网络需要大规模的计算,这不适合在 CPU 上运行,但很适合在 GPU 上运行。 当前,将计算放到 GPU 上最成熟的解决方案是 CUDA 和 OpenCL,而 OpenCV 库的 DNN 模块目前仅支持 OpenCL 方法。
cv::dnn::Net类有两种方法来设置其后端和目标设备:
setPreferableBackend()setPreferableTarget()
如果您有 GPU,并且已正确安装 OpenCL 和 GPU 驱动程序,则可以使用-DWITH_OPENCL=ON标志构建 OpenCV 以启用 OpenCL 支持。 之后,您可以使用net.setPreferableTarget(cv::dnn::DNN_TARGET_OPENCL)使用 GPU 进行计算。 这将带来性能上的巨大改进。
总结
在本章中,我们创建了一个名为 Detective 的新应用,以使用不同的方法来检测对象。 首先,我们使用 OpenCV 内置的层叠分类器来检测猫的脸。 然后,我们学习了如何自己训练级联分类器。 我们训练了用于刚性物体(禁止进入的交通标志)的级联分类器和用于不太刚性物体(波士顿公牛队的脸)的级联分类器,然后在我们的应用中对此进行了测试。
我们转向了深度学习方法。 我们讨论了深度学习技术的不断扩展,介绍了许多框架,并了解了 DNN 模型可以使用两阶段检测器和一阶段检测器检测对象的不同方式。 我们结合了 OpenCV 库的 DNN 模块和预训练的 YOLOv3 模型来检测应用中的对象。
最后,我们简要讨论了实时性和检测器的性能。 我们了解了如何将计算移至 GPU,以实现性能的大幅提高。
在本章中,我们检测了多种对象。 在下一章中,我们将讨论如何借助计算机视觉技术来测量它们之间的距离。
问题
尝试这些问题以测试您对本章的了解:
- 当我们为波士顿公牛队的脸训练级联分类器时,我们自己在每个图像上标注了狗脸。 标注过程花费了我们很多时间。 在以下网站上有该数据集的注解数据包。 我们可以通过一段代码从此标注数据生成
info.txt文件吗? 我们该怎么做? - 尝试找到预训练的(快速/快速)R-CNN 模型和预训练的 SSD 模型。 运行它们,并将其性能与 YOLOv3 进行比较。
- 我们可以使用 YOLOv3 来检测某种对象,但不能检测所有 80 类对象吗?
七、实时汽车检测和距离测量
在上一章中,我们通过级联分类器方法和深度学习方法学习了如何使用 OpenCV 库检测对象。 在本章中,我们将讨论如何测量检测到的物体之间或感兴趣的物体与相机之间的距离。 我们将在新的应用中检测汽车,并测量汽车之间的距离以及汽车与摄像机之间的距离。
本章将涵盖以下主题:
- 使用带有 OpenCV 的 YOLOv3 模型检测汽车
- 测量不同视角距离的方法
- 在鸟瞰图中测量汽车之间的距离
- 在眼睛水平视图中测量汽车与摄像头之间的距离
技术要求
像前面的章节一样,您至少需要安装 Qt 版本 5 并安装 OpenCV 4.0.0。 也必须具有 C++ 和 Qt 编程的基本知识。
我们将使用深度学习模型 YOLOv3 来检测汽车,因此拥有深度学习知识也将有很大帮助。 由于我们在第 6 章,“实时对象检测”中介绍了深度学习模型,因此建议您先阅读本章之前的内容。
本章的所有代码都可以在本书的代码存储库中找到。
观看以下视频,查看运行中的代码
实时汽车检测
在测量物体之间的距离之前,我们必须检测出感兴趣的物体以找出它们的位置。 在本章中,我们决定测量汽车之间的距离,因此我们应该从检测汽车开始。 在上一章,第 6 章,“实时对象检测”中,我们学习了如何以多种方式检测对象,我们看到 YOLOv3 模型在准确率方面具有良好的表现, 幸运的是,car对象类在可可数据集(即coco.names文件)的类别列表中。 因此,我们将遵循该方法,并使用 YOLOv3 模型来检测汽车。
与前面几章一样,我们将通过复制我们已经完成的项目之一来创建本章的新项目。 这次,让我们复制上一章完成的 Detective 应用,作为本章的新项目。 我们将新项目命名为DiGauge,以表明该项目用于衡量检测到的对象之间的距离。 让我们直接进行复制:
$ pwd
/home/kdr2/Work/Books/Qt-5-and-OpenCV-4-Computer-Vision-Projects
$ mkdir Chapter-07
# !!! you should copy it to a different dir
$ cp -r Chapter-06/Detective Chapter-07/DiGauge
$ ls Chapter-07
DiGauge
$ cd Chapter-07/DiGauge/
如果您一直在进行,则应该将项目复制到Chapter-07以外的其他目录,因为DiGauge目录已经存在于我们代码存储库中的该文件夹中。
现在我们已经完成了复制,让我们进行一些重命名:
- 将
Detective.pro项目文件重命名为DiGauge.pro。 - 在该项目文件中将目标值从
Detective重命名为DiGauge。 - 在对
main.cpp源文件中的window.setWindowTitle的调用中,将Detective窗口标题更改为DiGauge。 - 将
mainwindow.cpp源文件中位于MainWindow::initUI方法中对mainStatusLabel->setText的调用中的状态栏上的文本从Detective is Ready更改为DiGauge is Ready。 - 在
utilities.cpp源文件中的Utilities::getDataPath方法中,对pictures_dir.mkpath和pictures_dir.absoluteFilePath的调用中,将Detective字符串更改为DiGauge。
至此,我们有了一个与侦探应用相同的新应用,除了名称和相对路径中的单词Detective。 UI 上的文本也已更改为DiGauge。 要看到这一点,我们可以编译并运行它。
可在以下提交中找到重命名中的更改集。 如果您对此完全感到困惑,请参考提交。
由于我们决定使用 YOLOv3 深度学习模型来检测汽车,因此,我们最好删除所有与级联分类器方法有关的代码,以使我们的项目代码简洁明了。 此步骤也非常简单:
-
在
DiGauge.pro项目文件中,我们在LIBS配置中删除了opencv_objdetect模块,因为在删除了使用级联分类器的代码之后,将不再使用该模块。 也可以删除DEFINES配置中定义的宏,因为我们也不会使用它们。 -
在
capture_thread.h文件中,我们从CaptureThread类中删除了void detectObjects(cv::Mat &frame)私有方法和cv::CascadeClassifier *classifier;字段。 -
最后,我们对
capture_thread.cpp源文件进行一些更改:
至此,我们有了一个仅使用 YOLOv3 模型检测对象的干净项目。 可以在这里找到该变更集。
现在,通过使用 YOLOv3 模型,我们的应用可以检测视频或图像中的所有 80 类对象。 但是,对于此应用,我们对所有这些类都不感兴趣-我们仅对汽车感兴趣。 让我们在coco.names文件中找到car类:
$ grep -Hn car data/coco.names
data/coco.names:3:car
data/coco.names:52:carrot
$
如我们所见,car类是coco.names文件中的第三行,因此它的类 ID 是2(具有从 0 开始的索引)。 让我们覆盖capture_thread.cpp源文件中的decodeOutLayers函数,以过滤掉除 ID 为2的类之外的所有类:
void decodeOutLayers(
cv::Mat &frame, const vector<cv::Mat> &outs,
vector<cv::Rect> &outBoxes
)
{
float confThreshold = 0.65; // confidence threshold
float nmsThreshold = 0.4; // non-maximum suppression threshold
// vector<int> classIds; // this line is removed!
// ...
}
让我们看一下我们在前面的代码中所做的更改:
-
对函数签名的更改:
outClassIds参数将不再有用,因为我们将仅检测一类对象,因此我们将其删除。outConfidences参数也将被删除,因为我们不在乎每个检测到的汽车的置信度。
-
对函数主体的更改:
confThreshold变量从0.5更改为0.65,以提高准确率。- 出于与删除
outClassIds参数相同的原因,还删除了用于存储检测到的对象的类 ID 的classIds局部变量。
然后,在通过调用cv::minMaxLoc函数获得类 ID 之后,在第二级for循环中处理检测到的对象的边界框时,我们检查类 ID 是否为2。 如果不是2,我们将忽略当前的边界框并转到下一个边界框:
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (classIdPoint.x != 2) // not a car!
continue;
最后,我们删除所有试图更新已删除的classIds,outClassIds和outConfidences变量的行。 现在,对decodeOutLayers函数的更改已完成,因此让我们继续调用decodeOutLayers的函数,即CaptureThread::detectObjectsDNN方法。
对于CaptureThread::detectObjectsDNN方法,我们只需要更新其主体的末端部分:
// remove the bounding boxes with low confidence
// vector<int> outClassIds; // removed!
// vector<float> outConfidences; // removed!
vector<cv::Rect> outBoxes;
// decodeOutLayers(frame, outs, outClassIds, outConfidences, outBoxes); // changed!
decodeOutLayers(frame, outs, outBoxes);
for(size_t i = 0; i < outBoxes.size(); i ++) {
cv::rectangle(frame, outBoxes[i], cv::Scalar(0, 0, 255));
}
如您所见,我们删除了类 ID 和与置信度相关的变量,并使用outBoxes变量作为其唯一的out参数调用了decodeOutLayers函数。 然后,我们遍历检测到的边界框并将其绘制为红色。
最后,我们已经完成了对 Detective 应用的重建,以便它是一个名为 DiGauge 的新应用,它可以使用 YOLOv3 深度学习模型来检测汽车。 让我们编译并运行它:
$ qmake
$ make
g++ -c -pipe -O2 -Wall #...
# output trucated
$ export LD_LIBRARY_PATH=/home/kdr2/programs/opencv/lib
$ ./DiGauge
不要忘记将与 YOLOV3 模型相关的文件(coco.names,yolov3.cfg和yolov3.weights)复制到我们项目的data子目录中,否则将无法成功加载模型。 如果您对如何获取这些文件有疑问,则应阅读第 6 章,“实时对象检测”。
应用启动后,如果您在其中有汽车的某些场景上对其进行测试,则会发现每个检测到的汽车都有一个红色边框:

现在我们可以检测到汽车了,让我们在下一部分中讨论如何测量它们之间的距离。
距离测量
在不同情况下,有许多方法可以测量或估计对象之间或对象与相机之间的距离。 例如,如果我们感兴趣的物体或我们的相机以已知且固定的速度运动,则通过运动检测和对象检测技术,我们可以轻松地在相机视图中估计物体之间的距离。 另外,如果我们使用立体声相机,则可以遵循这里来测量距离。
但是,对于我们的情况,我们只有一个固定位置的普通网络摄像头,那么如何测量与之的距离呢? 好吧,可以满足一些先决条件。
让我们先谈谈测量物体之间的距离。 这种情况下的先决条件是,我们应该将摄像机安装到固定位置,以便可以鸟瞰鸟瞰对象,并且必须有一个已知大小固定的对象,它将在相机的视线中用作参考。 让我们来看看用我的相机拍摄的照片:

在上一张照片中,我的桌子上有两个硬币。 硬币的直径为 25 毫米,该长度在照片中占据 128 个像素。 利用这些信息,我们可以测量两个硬币的距离(以像素为单位),即照片中的距离为 282 像素。 好吧,照片中 128 像素的长度在我的桌子上代表 25 毫米,那么 282 像素的长度代表多长时间? 非常简单:25 / 128 * 282 = 55.07毫米。 因此,在这种情况下,一旦检测到参考对象和要测量的距离的顶点,便可以通过简单的计算获得距离。 在下一部分的应用中,我们将使用这种简洁的方法来测量汽车之间的距离。
现在,让我们继续讨论测量目标物体和相机之间的距离的主题。 在这种情况下,先决条件是我们应该将摄像机安装到固定位置,以便可以在眼平视图中拍摄对象的视频,并且也必须有参考。 但是,这里的参考与鸟瞰情况有很大不同。 让我们看看为什么:

上图演示了我们在拍照时对象与相机之间的位置关系。 此处,F是相机的焦距,D0是相机与物体之间的距离。Hr是物体的高度,H0是相机镜头上物体图像的高度(以米为单位,而不是以像素为单位)。
由于图片中有两个明显相似的三角形,因此我们可以得到一些方程式:

上图中有很多方程式,所以让我们一一看一下:
- 第一个方程式来自三角形相似度。
- 从等式
(1),我们知道焦点F可以计算为等式(2)。 - 然后,如果将对象移动到另一个位置,并将距离标记为
D1,并将镜头上图像的高度标记为H1,则考虑到相机的焦距是固定值,我们将得到方程(3)。 - 如果我们将方程
(2)和方程(3)结合起来,我们将得到方程(4)。 - 从等式
(4),经过一些变换,我们可以得出距离D1,可以将其计算为等式(5)。 - 由于我们已经将
Hr的高度与实际物体进行了比较,因此H0和H1的值非常小,因此我们可以推测出这些值Hr-H0和Hr-H1的比值几乎相同。 这就是方程(6)所说的。 - 利用等式
(6),我们可以将等式(4)简化为等式(7)。
因此,无论以镜头上的米为单位还是照片上的像素为单位,H0/H1的值始终相同,我们可以更改H0和H1可以计算它们所占据的像素数,以便我们可以在数码照片中对其进行测量。
在这里,我们将以D0(以米为单位)和H0(以像素为单位)作为参考,这意味着在测量相机与物体之间的距离之前,必须先将其放在相机之前的某个位置,然后将其测量为D0并拍照。 然后,我们可以将照片中物体的高度记为H0,并将这些值用作参考值。 让我们看一个例子:

在上一张照片的左侧,我在离相机 230 厘米的桌子上放了一个文件夹,并拍摄了照片。 在此,它在垂直方向上占据 90 个像素。 然后,我将其移至距相机几厘米的位置,然后再次拍照。 这次,其高度为 174 像素。 我们可以将左侧的值用作参考值,即:
D0是 230 厘米H0是 90 像素H1为 174 像素
根据方程(7),我们可以将D1计算为H0 / H1 * D0 = 90 / 174 * 230 = 118.96 cm。 结果非常接近我从桌子上的直尺获得的值,即 120 厘米。
现在我们知道了如何测量物体之间或物体与相机之间距离的原理,让我们将其应用于 DiGauge 应用中。
测量汽车之间或汽车与相机之间的距离
有了我们在上一节中讨论的原理,让我们利用它们来测量应用中的距离。
正如我们之前提到的,我们将从两种不同的角度进行衡量。 首先,让我们看一下鸟瞰图。
鸟瞰汽车之间的距离
为了能够鸟瞰汽车,我将相机固定在办公室八层的窗户上,使其面向地面。 这是我从相机中获得的图片之一:

您会看到道路上的汽车从图片的左侧向右侧行驶。 这不是绝对的鸟瞰图,但是我们可以使用上一节中讨论的方法来估计汽车之间的距离。 让我们在我们的代码中做到这一点。
在capture_thread.cpp源文件中,我们将添加一个名为distanceBirdEye的新函数:
void distanceBirdEye(cv::Mat &frame, vector<cv::Rect> &cars)
{
// ...
}
它有两个参数:
- 视频中
cv::Mat类型的帧 - 给定帧中检测到的汽车的边界框的向量
我们将首先计算水平方向上边界框的距离(以像素为单位)。 但是,这些盒子在水平方向上可能部分重叠。 例如,在上一张照片中,左侧的两辆白色汽车在水平方向上几乎处于同一位置,显然,我们感兴趣的水平方向上它们之间的距离为零, 并且我们没有必要对其进行衡量。 因此,在计算任何两个给定框的每个距离之前,我们应该将在水平方向上重叠的框合并为一个框。
这是我们合并框的方法:
vector<int> length_of_cars;
vector<pair<int, int>> endpoints;
vector<pair<int, int>> cars_merged;
首先,在前面的代码中,我们声明变量:
length_of_cars变量是整数向量,将保留汽车的长度(以像素为单位),即边界框的宽度。endpoints变量将保留汽车两端的位置。 此变量是整数对的向量。 其中的每一对都是汽车的一端(前端或后端)。 如果是后端,则对为(X, 1),否则为(X, -1),其中X是端点的x坐标。cars_merged变量用于合并汽车后的汽车位置信息。 我们只关心它们在水平方向上的位置,因此我们使用对代替矩形来表示位置。 一对中的第一个元素是汽车的后端(在左侧),第二个元素是汽车的前端(在右侧)。
然后,我们遍历检测到的汽车的边界框以填充这三个向量:
for (auto car: cars) {
length_of_cars.push_back(car.width);
endpoints.push_back(make_pair(car.x, 1));
endpoints.push_back(make_pair(car.x + car.width, -1));
}
填充向量后,我们对长度的向量进行排序,并找到中位数作为int length变量。 稍后我们将使用该中值作为参考值之一:
sort(length_of_cars.begin(), length_of_cars.end());
int length = length_of_cars[cars.size() / 2];
现在,我们执行最后一步:
sort(
endpoints.begin(), endpoints.end(),
[](pair<int, int> a, pair<int, int> b) {
return a.first < b.first;
}
);
int flag = 0, start = 0;
for (auto ep: endpoints) {
flag += ep.second;
if (flag == 1 && start == 0) { // a start
start = ep.first;
} else if (flag == 0) { // an end
cars_merged.push_back(make_pair(start, ep.first));
start = 0;
}
}
在前面的代码中,我们按其中每个对的第一个元素对endpoints向量进行排序。 排序后,我们遍历已排序的endpoints以进行合并。 在迭代中,我们将对中的第二个整数添加到初始值为零的标志中,然后检查标志的值。 如果它是 1,并且我们还没有开始合并范围,则这是一个起点。 当标志减少到零时,我们得到范围的终点。 换句话说,我们从左到右遍历了汽车的所有端点。 当我们遇到汽车的后端点时,将其添加到标志中,当我们遇到汽车的前端点时,将其从标志中移开。 当标志从零变为 1 时,它是合并范围的起点;当标志从非零变为零时,它是合并范围的端点。
下图更详细地描述了该算法:

通过将起点和终点成对地推到cars_merged向量,我们将得到所有合并的框或合并的范围,因为我们只关心水平方向。
当我们谈到在鸟瞰图中测量距离时,我们说必须有一个固定且已知大小的参考物体,例如硬币。 但是在这种情况下,我们没有满足此条件的对象。 要解决此问题,我们将选择检测到的汽车长度的中位数,并假设其在现实世界中的长度为 5 米,并将其用作参考对象。 让我们看看如何使用此参考车计算合并范围之间的距离:
for (size_t i = 1; i < cars_merged.size(); i++) {
// head of car, start of spacing
int x1 = cars_merged[i - 1].second;
// end of another car, end of spacing
int x2 = cars_merged[i].first;
cv::line(frame, cv::Point(x1, 0), cv::Point(x1, frame.rows),
cv::Scalar(0, 255, 0), 2);
cv::line(frame, cv::Point(x2, 0), cv::Point(x2, frame.rows),
cv::Scalar(0, 0, 255), 2);
float distance = (x2 - x1) * (5.0 / length);
// TODO: show the distance ...
}
在前面的代码中,我们遍历合并的范围,找到范围的头部(车)和下一个范围的后端(车),然后在找到的两个点绘制绿色垂直线和红色垂直线 , 分别。
然后,我们使用(x2 - x1) * (5.0 / length)表达式计算两条垂直线之间的距离,其中5.0是常识上汽车的近似平均长度,length是我们在视频中检测到的汽车长度的中位数。
现在,让我们在框架上显示计算出的距离:
// display the label at the top of the bounding box
string label = cv::format("%.2f m", distance);
int baseLine;
cv::Size labelSize = cv::getTextSize(
label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int label_x = (x1 + x2) / 2 - (labelSize.width / 2);
cv::putText(
frame, label, cv::Point(label_x, 20),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(255, 255, 255));
前面的代码也位于for循环中。 在这里,我们格式化distance变量(它是字符串的浮点数)的格式,并用cv::getTextSize函数测量的文本大小将其绘制在框架的顶部和两行的中间。
至此,可以鸟瞰鸟瞰汽车之间的距离。 让我们在CaptureThread::detectObjectsDNN方法中调用它:
for(size_t i = 0; i < outBoxes.size(); i ++) {
cv::rectangle(frame, outBoxes[i], cv::Scalar(0, 0, 255));
}
distanceBirdEye(frame, outBoxes);
如您所见,在CaptureThread::detectObjectsDNN方法中绘制检测到的汽车的边界框后,我们直接使用边界框的框架和向量调用新添加的函数。 现在,让我们编译并启动我们的应用,然后打开相机以查看外观:

不出所料,我们在视频中发现了许多绿线和红线对,它们表示距离,并且距离的大约长度标记在视频的两线之间。
这种方法的重点是在鸟瞰图中查看感兴趣的对象并找到固定大小的参考对象。 在这里,我们使用经验值作为参考值,因为我们在现实世界中并不总是获得合适的参考对象。 我们使用汽车长度的中位数,因为可能有一半的汽车正在驶入或驶出摄像机的视线,这使得使用平均值不太合适。
我们已经成功地测量了鸟瞰视野中的汽车距离,因此让我们继续看一下如何应对眼高视野。
在眼睛水平视图中测量汽车与摄像头之间的距离
在前面的小节中,我们在鸟瞰图中测量了汽车之间的距离。 在本小节中,我们将测量汽车与摄像头之间的距离。
在这种情况下谈论距离测量时,我们了解到,在测量距离之前,必须将摄像机安装在固定位置,然后从中拍摄照片以获得两个参考值:
- 照片中对象的高度或宽度,以像素为单位。 我们将此值称为
H0或W0。 - 拍摄照片时相机与物体之间的距离。 我们将此值称为
D0。
下面的照片是从我的相机上拍摄的-这是我的车的照片:

这张照片的两个参考值如下:
W0 = 150 pixelsD0 = 10 meters
现在已经有了参考值,让我们开始在代码中进行距离测量。 首先,我们将添加一个名为distanceEyeLevel的新函数:
void distanceEyeLevel(cv::Mat &frame, vector<cv::Rect> &cars)
{
const float d0 = 1000.0f; // cm
const float w0 = 150.0f; // px
// ...
}
像distanceBirdEye函数一样,此函数也将视频帧和检测到的汽车的边界框作为其自变量。 在其主体的开头,我们定义了两个参考值。 然后,我们尝试找到感兴趣的汽车:
// find the target car: the most middle and biggest one
vector<cv::Rect> cars_in_middle;
vector<int> cars_area;
size_t target_idx = 0;
for (auto car: cars) {
if(car.x < frame.cols / 2 && (car.x + car.width) > frame.cols / 2) {
cars_in_middle.push_back(car);
int area = car.width * car.height;
cars_area.push_back(area);
if (area > cars_area[target_idx]) {
target_idx = cars_area.size() - 1;
}
}
}
if(cars_in_middle.size() <= target_idx) return;
考虑到视频中可能检测到不止一辆汽车,我们必须找出一种选择一辆汽车作为目标的方法。 在这里,我们选择了视图中间最大的视图。 为此,我们必须声明三个变量:
cars_in_middle是矩形的向量,该向量将容纳位于视图中间的汽车的边界框。cars_area是一个整数向量,用于将矩形的区域保存在cars_in_middle向量中。target_idx将是我们找到的目标汽车的索引。
我们遍历边界框并检查每个边界框。 如果它的左上角在视频的左侧,而它的右上角在视频的右侧,则说它在视频的中间。 然后,将其及其区域分别推入cars_in_middle向量和cars_area向量。 完成此操作后,我们检查我们刚刚按下的区域是否大于当前目标的区域。 如果为真,则将当前索引设置为目标索引。 迭代完成后,我们将在target_idx变量中获得目标汽车的索引。 然后,我们得到目标汽车的矩形以测量距离:
cv::Rect car = cars_in_middle[target_idx];
float distance = (w0 / car.width) * d0; // (w0 / w1) * d0
// display the label at the top-left corner of the bounding box
string label = cv::format("%.2f m", distance / 100);
int baseLine;
cv::Size labelSize = cv::getTextSize(
label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
cv::putText(frame, label, cv::Point(car.x, car.y + labelSize.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 255));
在前面的代码中,我们根据公式(7)找到矩形并使用(w0 / car.width) * d0表达式计算距离。 然后,将distance变量格式化为字符串,然后将其绘制在目标汽车左上角的边界框中。
最后,我们将对distanceBirdEye函数的调用更改为对CaptureThread::detectObjectsDNN方法中新添加的distanceEyeLevel函数的调用,然后再次编译并运行我们的应用。 看起来是这样的:

如您所见,我们在视频中检测到了多于一辆汽车,但是仅测量了中间一辆与摄像机之间的距离。 距离的长度以黄色文本标记在目标汽车边界框的左上角。
在查看模式之间切换
在前面的两个小节中,我们以两种模式测量距离:鸟瞰图和视平线图。 但是,在我们的 DiGauge 应用中,在这些模式之间切换的唯一方法是更改代码并重新编译应用。 显然,最终用户无法执行此操作。 为了向最终用户介绍此功能,我们将在应用中添加一个新菜单,使用户有机会在两种模式之间进行切换。 让我们开始编码。
首先,让我们在capture_thread.h文件中添加一些行:
class CaptureThread : public QThread
{
// ...
public:
// ...
enum ViewMode { BIRDEYE, EYELEVEL, };
void setViewMode(ViewMode m) {viewMode = m; };
// ...
private:
// ...
ViewMode viewMode;
};
在前面的代码中,我们定义了一个名为ViewMode的公共枚举,它具有两个值来表示两种视图模式,而该类型的私有成员字段则用于指示当前模式。 还有一个公共内联设置器来更新当前模式。
然后,在CaptureThread类的构造器中,在capture_thread.cpp文件中,我们初始化新添加的字段:
CaptureThread::CaptureThread(int camera, QMutex *lock):
running(false), cameraID(camera), videoPath(""), data_lock(lock)
{
frame_width = frame_height = 0;
taking_photo = false;
viewMode = BIRDEYE; // here
}
CaptureThread::CaptureThread(QString videoPath, QMutex *lock):
running(false), cameraID(-1), videoPath(videoPath), data_lock(lock)
{
frame_width = frame_height = 0;
taking_photo = false;
viewMode = BIRDEYE; // and here
}
在CaptureThread::detectObjectsDNN方法中,我们根据viewMode成员字段的值调用distanceBirdEye或distanceEyeLevel:
if (viewMode == BIRDEYE) {
distanceBirdEye(frame, outBoxes);
} else {
distanceEyeLevel(frame, outBoxes);
}
现在,让我们转到mainwindow.h头文件,向MainWindow类添加一些方法和字段:
class MainWindow : public QMainWindow
{
// ...
private slots:
// ...
void changeViewMode();
private:
// ...
QMenu *viewMenu;
QAction *birdEyeAction;
QAction *eyeLevelAction;
// ...
};
在此变更集中,我们向MainWindow类添加了QMenu和两个QAction,以及用于新添加动作的名为changeViewMode的插槽。 现在,让我们实例化mainwindow.cpp源文件中的菜单和操作。
在MainWindow::initUI()方法中,我们创建菜单:
// setup menubar
fileMenu = menuBar()->addMenu("&File");
viewMenu = menuBar()->addMenu("&View");
然后,在MainWindow::createActions方法中,我们实例化动作并将其添加到视图菜单中:
birdEyeAction = new QAction("Bird Eye View");
birdEyeAction->setCheckable(true);
viewMenu->addAction(birdEyeAction);
eyeLevelAction = new QAction("Eye Level View");
eyeLevelAction->setCheckable(true);
viewMenu->addAction(eyeLevelAction);
birdEyeAction->setChecked(true);
如您所见,这次与我们之前创建动作的时候有些不同。 创建动作实例后,我们将它们称为true的setCheckable方法。 这样可以检查动作,并且动作文本左侧的复选框将出现。 最后一行将动作状态birdEyeAction设置为选中。 然后,将动作的triggered信号连接到我们在同一方法中刚刚声明的广告位:
connect(birdEyeAction, SIGNAL(triggered(bool)), this, SLOT(changeViewMode()));
connect(eyeLevelAction, SIGNAL(triggered(bool)), this, SLOT(changeViewMode()));
现在,让我们看看该插槽是如何实现的:
void MainWindow::changeViewMode()
{
CaptureThread::ViewMode mode = CaptureThread::BIRDEYE;
QAction *active_action = qobject_cast<QAction*>(sender());
if(active_action == birdEyeAction) {
birdEyeAction->setChecked(true);
eyeLevelAction->setChecked(false);
mode = CaptureThread::BIRDEYE;
} else if (active_action == eyeLevelAction) {
eyeLevelAction->setChecked(true);
birdEyeAction->setChecked(false);
mode = CaptureThread::EYELEVEL;
}
if(capturer != nullptr) {
capturer->setViewMode(mode);
}
}
在此插槽中,我们获得了信号发送器,该信号发送器必须是两个新添加的动作之一,将发送器设置为选中状态,将另一个设置为未选中,然后根据选中的动作保存查看模式。 之后,我们检查捕获线程是否为空; 如果不是,我们通过调用setViewMode方法设置其查看模式。
我们需要做的最后一件事是在创建并启动新的捕获线程时重置这些操作的状态。 在MainWindow::openCamera方法主体的末尾,我们需要添加几行:
birdEyeAction->setChecked(true);
eyeLevelAction->setChecked(false);
现在,一切都已完成。 让我们编译并运行应用以测试新功能:

从前面的屏幕快照中可以看到,我们可以通过“视图”菜单切换视图模式,我们的 DiGauge 应用终于完成了。
总结
在本章中,我们计划使用 OpenCV 测量汽车之间或汽车与摄像机之间的距离。 首先,我们创建了一个名为 DiGauge 的新应用,通过取消在上一章中开发的 Detective 应用来从摄像机检测汽车。 然后,我们以两种视图模式(鸟瞰图和水平视图)讨论了计算机视觉域中距离测量的原理。 之后,我们在应用中的这两种视图模式中实现了距离测量功能,并在 UI 上添加了一个菜单,以在两种视图模式之间切换。
在下一章中,我们将介绍一种称为 OpenGL 的新技术,并了解如何在 Qt 中使用它以及如何在计算机视觉领域为我们提供帮助。
问题
尝试回答以下问题,以测试您对本章的了解:
- 在测量汽车之间的距离时,是否可以使用更好的参考对象?
八、OpenGL 图像高速过滤
在前面的章节中,我们学到了很多有关如何使用 OpenCV 处理图像和视频的知识。 这些过程大多数由 CPU 完成。 在本章中,我们将探索另一种处理图像的方法,即使用 OpenGL 将图像过滤从 CPU 移至图形处理单元(GPU)。
在许多类型的软件(例如 Google Chrome 浏览器)中,您可能会在“设置”页面上看到用于硬件加速或类似功能的选项。 通常,这些设置意味着将图形卡(或 GPU)用于渲染或计算。 这种使用另一个处理器而不是 CPU 进行计算或渲染的方法称为异构计算。 进行异构计算的方法有很多,包括 OpenCL,我们在第 6 章,“实时对象检测”中提到了这一点,而我们是在使用 OpenCV 及其 OpenCL 后端运行深度学习模型时 。 我们将在本章中介绍的 OpenGL 也是一种异构计算的方法,尽管它主要用于 3D 图形渲染。 在这里,我们将使用它来过滤 GPU 上的图像,而不是渲染 3D 图形。
本章将涵盖以下主题:
- OpenGL 简介
- 在 Qt 中使用 OpenGL
- 使用 OpenGL 在 GPU 上过滤图像
- 在 OpenCV 中使用 OpenGL
技术要求
必须具备 C 和 C++ 编程语言的基本知识才能遵循本章。 由于 OpenGL 将是本章的主要部分,因此对 OpenGL 的深入了解也将是一个很大的优势。
考虑到我们将 Qt 和 OpenCV 与 OpenGL 一起使用,至少要求读者以与前面各章相同的方式安装 Qt 5 和 OpenCV 4.0.0。
本章的所有代码都可以在我们的代码库中找到。
您可以观看以下视频以查看运行中的代码
你好 OpenGL
OpenGL 不是像 OpenCV 或 Qt 这样的典型编程库。 它的维护者 Khronos 组仅设计和定义 OpenGL 的 API 作为规范。 但是,它不负责执行。 相反,图形卡制造商应负责提供实现。 大多数制造商,例如英特尔,AMD 和 Nvidia,都在其显卡驱动程序中提供了实现。 在 Linux 上,有一个称为 Mesa 的 OpenGL 实现,如果图形卡驱动正确,它可以进行软件渲染,同时也支持硬件渲染。
如今,OpenGL 的学习曲线非常陡峭。 这是因为您需要了解异构架构和另一种编程语言,称为 OpenGL Shading Language,以及 C 和 C++。 在本章中,我们将使用新样式的 API 来渲染和过滤图像,该 API 是 OpenGL V4.0 中引入的,并已反向移植到 V3.3。 我们将从一个简单的示例开始,向 OpenGL 说“Hello”。
在开始示例之前,我们应该确保在我们的计算机上安装了 OpenGL 和一些帮助程序库。 在 Windows 上,如果您安装了用于图形卡的最新驱动程序,则还将安装 OpenGL 库。 在现代 MacOS 上,预先安装了 Apple 实现的 OpenGL 库。 在 Linux 上,我们可以使用 Mesa 实现或已安装图形卡的专有硬件驱动程序。 使用 Mesa 更容易,因为一旦安装了 Mesa 的运行时和开发包,我们将获得有效的 OpenGL 安装。
在使用 OpenGL 进行任何操作之前,我们必须创建一个 OpenGL 上下文进行操作,并创建一个与该上下文关联的窗口以显示渲染的图形。 这项工作通常取决于平台。 幸运的是,有许多库可以隐藏这些与平台有关的细节,并包装用于该用途的通用 API。 在这里,我们将使用 GLFW 和 GLEW 库。 GLFW 库将帮助我们创建 OpenGL 上下文和一个窗口来显示渲染的图形,而 GLEW 库将处理 OpenGL 标头和扩展名。 在类似 UNIX 的系统上,我们可以从源代码构建它们,也可以使用系统包管理器轻松地安装它们。 在 Windows 上,我们可以下载两个帮助程序库的官方网站上提供的二进制包以进行安装。
最后,在安装所有必备组件之后,我们可以启动Hello OpenGL示例。 编写 OpenGL 程序通常涉及以下步骤,如下所示:
- 创建上下文和窗口。
- 准备要绘制的对象的数据(以 3D 形式)。
- 通过调用一些 OpenGL API 将数据传递给 GPU。
- 调用绘图指令以告诉 GPU 绘制对象。 在绘制过程中,GPU 将对数据进行许多操作,并且可以通过使用 OpenGL 着色语言编写着色器来自定义这些操作。
- 编写将在 GPU 上运行的着色器,以操纵 GPU 上的数据。
让我们看一下如何在代码中执行这些步骤。 首先,我们创建一个名为main.c的源文件,然后添加基本的include指令和main函数,如下所示:
#include <stdio.h>
#include <GL/glew.h>
#include <GLFW/glfw3.h>
int main() {
return 0;
}
然后,正如我们提到的,第一步是创建 OpenGL 上下文和用于显示图形的窗口:
// init glfw and GL context
if (!glfwInit()) {
fprintf(stderr, "ERROR: could not start GLFW3\n");
return 1;
}
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); // 3.3 or 4.x
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
GLFWwindow *window = NULL;
window = glfwCreateWindow(640, 480, "Hello OpenGL", NULL, NULL);
if (!window) {
fprintf(stderr, "ERROR: could not open window with GLFW3\n");
glfwTerminate();
return 1;
}
glfwMakeContextCurrent(window);
在这段代码中,我们首先通过调用其glfwInit函数来初始化 GLFW 库。 然后,我们使用glfwWindowHint函数设置一些提示,如下所示:
GLFW_CONTEXT_VERSION_MAJOR和GLFW_CONTEXT_VERSION_MINOR用于指定 OpenGL 版本; 正如我们提到的,我们使用的是新样式的 API,该 API 是在 V4.0 中引入的,并已反向移植到 V3.3,因此,这里至少应使用 V3.3。GLFW_OPENGL_FORWARD_COMPAT将 OpenGL 前向兼容性设置为true。GLFW_OPENGL_PROFILE用于设置用于创建 OpenGL 上下文的配置文件。 通常,我们可以选择两个配置文件:核心配置文件和兼容性配置文件。 使用核心配置文件,只能使用新样式的 API,而使用兼容性配置文件,制造商可以提供对旧 API 和新 API 的支持。 但是,使用兼容性配置文件时,在某些实现上运行新版本的着色器时可能会出现一些故障。 因此,在这里,我们使用核心配置文件。
设置提示后,我们声明并创建窗口。 从glfwCreateWindow函数的参数中可以看到,新创建的窗口的宽度为 640 像素,高度为 480 像素,并以Hello OpenGL字符串作为标题。
与该窗口关联的 OpenGL 上下文也随该窗口一起创建。 我们调用glfwMakeContextCurrent函数将上下文设置为当前上下文。
之后,GLEW库也需要初始化:
// start GLEW extension handler
GLenum ret = glewInit();
if ( ret != GLEW_OK) {
fprintf(stderr, "Error: %s\n", glewGetErrorString(ret));
}
接下来,让我们转到第二步,准备要绘制的对象的数据。 我们在这里画一个三角形。 三角形是 OpenGL 中最原始的形状,因为我们在 OpenGL 中绘制的几乎所有东西都是由三角形组成的。 以下是三角形的数据:
GLfloat points[] = {+0.0f, +0.5f, +0.0f,
+0.5f, -0.5f, +0.0f,
-0.5f, -0.5f, +0.0f };
如您所见,数据是一个由 9 个元素组成的浮点数组。 也就是说,我们使用三个浮点数来描述 3D 空间中三角形的每个顶点,并且每个三角形有三个顶点。 在本书中,我们不会过多关注 3D 渲染,因此我们将每个顶点的z坐标设置为 0.0,以将三角形绘制为 2D 形状。
OpenGL 使用称为规范化设备坐标(NDC)的坐标系。 在该坐标系中,所有坐标都限制在 -1.0 和 1.0 的范围内。 如果对象的坐标超出此范围,则它们将不会显示在 OpenGL 视口中。 通过省略z轴,可以通过下图演示 OpenGL 的视口和给出的点(形成三角形):

顶点数据已准备就绪,现在我们应该将其传递到 GPU。 这是通过顶点缓冲对象(VBO)和顶点数组对象(VAO)完成的; 让我们看下面的代码:
// vbo
GLuint vbo;
glGenBuffers(1, &vbo);
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, 9 * sizeof(GLfloat), points, GL_STATIC_DRAW);
在前面的代码中,对glGenBuffers函数的调用将生成一个顶点缓冲区对象(第一个参数),并将对象的名称存储到vbo变量(第二个参数)中。 然后,我们调用glBindBuffer函数将顶点缓冲区对象绑定为GL_ARRAY_BUFFER类型的当前 OpenGL 上下文,这意味着该对象用于顶点属性的数据。 最后,我们调用glBufferData函数来创建数据存储,并使用当前绑定缓冲区的顶点数据对其进行初始化。 函数调用的最后一个参数告诉 OpenGL 我们的数据不会更改,这是优化的提示。
现在,我们已经将数据填充到顶点缓冲区对象中,但是该缓冲区在 GPU 上不可见。 为了使它在 GPU 上可见,我们应该引入一个顶点数组对象并放置一个指向其中缓冲区的指针:
GLuint vao;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 0, NULL);
与顶点缓冲区对象一样,顶点数组对象应在使用前生成并绑定。 之后,我们调用glEnableVertexAttribArray函数启用索引为0的通用顶点属性数组指针; 在顶点数组对象中。 您可以认为这是为我们在顶点数组对象中创建的顶点缓冲对象保留席位,席位号为0。 然后,我们调用glVertexAttribPointer函数,以使当前绑定的顶点缓冲对象位于相反的位置。 该函数接受许多参数,其签名如下:
void glVertexAttribPointer(
GLuint index,
GLint size,
GLenum type,
GLboolean normalized,
GLsizei stride,
const GLvoid * pointer
);
让我们一一探讨它们,如下所示:
index指定索引(或座位号)。size指定每个顶点属性的组件数; 每个顶点(或点)有三个浮点数,因此我们在此处使用3。type是缓冲区的元素类型或顶点属性的组成部分的数据类型。normalized指定在 GPU 上访问数据之前是否应通过 OpenGL 对我们的数据进行规范化。 在我们的例子中,我们使用规范化的数据(介于-1.0 和 1.0 之间),因此不需要再次进行规范化。stride是连续的通用顶点属性之间的偏移量。 我们在这里使用0来告诉 OpenGL 我们的数据紧密包装并且没有偏移量。pointer是缓冲区中第一个通用顶点属性的第一部分的偏移量。 我们使用NULL表示零偏移。
至此,我们已经通过使用顶点缓冲对象和顶点数组对象将顶点数据成功传递到了 GPU 上。 然后,数据将被发送到 OpenGL 的图形管道。 OpenGL 图形管线有几个阶段:接受我们的 3D 顶点,数据和一些其他数据,将它们转换为 2D 图形中的彩色像素,并将其显示在屏幕上。 GPU 具有大量处理器,可以在这些处理器上并行完成顶点的转换。 因此,通过使用 GPU,我们可以在处理图像或进行可并行化的数值计算时提高性能。
在继续之前,让我们先看一下 OpenGL 图形管线的各个阶段。 我们可以将其大致分为六个阶段,如下所示:
- 顶点着色器:此阶段将顶点属性数据(在我们的情况下,我们已经传递给 GPU)作为其输入,并给出每个顶点的位置作为其输出。 OpenGL 在此阶段没有提供默认的着色器程序,因此我们应该自己编写一个。
- 形状组装:此阶段用于组装形状;此阶段用于组装形状。 例如,生成顶点并将其定位。 这是一个可选阶段,对于我们来说,我们将忽略它。
- 几何着色器:此阶段用于生成或删除几何,它也是一个可选阶段,我们无需编写着色器程序。
- 栅格化:此阶段将 3D 形状(在 OpenGL 中主要是三角形)转换为 2D 像素。 此阶段不需要任何着色器程序。
- 片段着色器:此阶段用于着色光栅化阶段中的片段。 像顶点着色器阶段一样,OpenGL 在此阶段不提供默认的着色器程序,因此我们应该自己编写一个。
- 混合:此阶段在屏幕或帧缓冲区上渲染 2D 图形。
这六个阶段中的每个阶段都将其前一级的输出作为输入,并将输出提供给下一级。 此外,在某些阶段,我们可以或需要编写着色器程序来参与这项工作。 着色器程序是一段用 OpenGL 着色语言编写并在 GPU 上运行的代码。 它由 OpenGL 实现在我们的应用运行时中编译。 在前面的阶段列表中可以看到,至少有两个阶段,即顶点着色器和片段着色器,即使在最小的 OpenGL 应用中,也需要我们提供着色器程序。 这是 OpenGL 学习曲线中最陡峭的部分。 让我们检查一下这些着色器程序的外观:
// shader and shader program
GLuint vert_shader, frag_shader;
GLuint shader_prog;
const char *vertex_shader_code = "#version 330\n"
"layout (location = 0) in vec3 vp;"
"void main () {"
" gl_Position = vec4(vp, 1.0);"
"}";
const char *fragment_shader_code = "#version 330\n"
"out vec4 frag_colour;"
"void main () {"
" frag_colour = vec4(0.5, 1.0, 0.5, 1.0);"
"}";
vert_shader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vert_shader, 1, &vertex_shader_code, NULL);
glCompileShader(vert_shader);
frag_shader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(frag_shader, 1, &fragment_shader_code, NULL);
glCompileShader(frag_shader);
shader_prog = glCreateProgram();
glAttachShader(shader_prog, frag_shader);
glAttachShader(shader_prog, vert_shader);
glLinkProgram(shader_prog);
在这段代码中,我们首先定义三个变量:vert_shader和frag_shader用于相应阶段所需的着色器程序,shader_prog用于整个着色器程序,它将包含所有着色器程序的所有着色器程序。 阶段。 然后,将着色器程序作为字符串编写在代码中,我们将在后面解释。 接下来,我们通过调用glCreateShader函数并向其附加源字符串来创建每个着色器程序,然后对其进行编译。
准备好阶段的着色器程序之后,我们将创建整个着色器程序对象,将阶段着色器程序附加到该对象,然后链接该程序。 至此,整个着色器程序就可以使用了,我们可以调用glUseProgram来使用它。 我们将在解释着色器程序的代码之后再做。
现在,让我们看一下顶点着色器:
#version 330
layout (location = 0) in vec3 vp;
void main() {
gl_Position = vec4(vp, 1.0);
}
前面代码的第一行是版本提示,即,它指定 OpenGL 着色语言的版本。 在这里,我们使用版本 330,它对应于我们使用的 OpenGL 版本。
然后,在第二行中,声明输入数据的变量。 layout (location = 0)限定符指示此输入数据与当前绑定的顶点数组对象的索引0(或编号为0的座位)相关联。 另外,in关键字表示它是输入变量。 代表3浮点数向量的单词vec3是数据类型,vp是变量名。 在我们的例子中,vp将是我们存储在points变量中的一个顶点的坐标,并且这三个顶点将被分派到 GPU 上的三个不同处理器,因此这段代码的每个顶点将在这些处理器上并行运行。 如果只有一个输入数组,则可以在此着色器中省略layout限定符。
正确描述输入数据之后,我们定义main函数,该函数是程序的入口点,就像使用 C 编程语言一样。 在main函数中,我们从输入构造一个包含四个浮点数的向量,然后将其分配给gl_Position变量。 gl_Position变量是预定义的变量,它是下一阶段的输出,并表示顶点的位置。
该变量的类型为vec4,但不是vec3; 第四个组件名为w,而前三个组件为x,y和z,我们可以猜测。 w成分是一个因子,用于分解其他向量成分以使其均一; 在本例中,我们使用 1.0,因为我们的值已经是标准化值。
总而言之,我们的顶点着色器从顶点数组对象获取输入,并保持不变。
现在,让我们看一下片段着色器:
#version 330
out vec4 frag_colour;
void main () {
frag_colour = vec4(0.5, 1.0, 0.5, 1.0);
}
在此着色器中,我们使用vec4类型的out关键字定义一个输出变量,它以 RGBA 格式表示颜色。 然后,在main函数中,我们为输出变量分配恒定的颜色,即浅绿色。
现在,着色器程序已经准备就绪,让我们开始图形管道:
while (!glfwWindowShouldClose(window)) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glUseProgram(shader_prog);
glBindVertexArray(vao);
glDrawArrays(GL_TRIANGLES, 0, 3);
// update other events like input handling
glfwPollEvents();
// put the stuff we've been drawing onto the display
glfwSwapBuffers(window);
}
glfwTerminate();
在前面的代码中,除非关闭应用窗口,否则我们将连续运行代码块。 在代码块中,我们清除窗口上的位平面区域,然后使用我们创建的着色器程序并绑定顶点数组对象。 此操作将着色器程序和数组或缓冲区与当前 OpenGL 上下文连接。 接下来,我们调用glDrawArrays启动图形管道以绘制对象。 glDrawArrays函数的第一个参数是原始类型。 在这里,我们要绘制一个三角形,因此使用GL_TRIANGLES。 第二个参数是我们为顶点缓冲区对象启用的缓冲区索引,最后一个参数是我们要使用的顶点数。
至此,绘制三角形的工作已经完成,但是我们还有更多工作要做:我们调用glfwPollEvents函数以捕获发生在窗口上的事件,并通过窗口对象调用glfwSwapBuffers函数来显示我们绘制的图形。 我们需要后一个函数调用,因为 GLFW 库使用双缓冲区优化。
当用户关闭窗口时,我们将跳出代码块并启动对glfwTerminate函数的调用,以释放 GLFW 库分配的所有资源。 然后应用退出。
好的,让我们编译并运行该应用:
gcc -Wall -std=c99 -o main.exe main.c -lGLEW -lglfw -lGL -lm
./main.exe
您将看到以下绿色三角形:

如果使用 Windows,则可以使用gcc -Wall -std=c99 -o main.exe main.c libglew32.dll.a glfw3dll.a -lOpenGL32 -lglew32 -lglfw3 -lm命令在 MinGW 上编译应用。 不要忘记使用-I和-L选项指定 GLFW 和 GLEW 库的包含路径和库路径。
好的,我们的第一个 OpenGL 应用完成了。 但是,正如您所看到的,GLFW 并不是完整的 GUI 库,尤其是当我们将其与 Qt 库进行比较时,在本书中我们经常使用它。 GLFW 库可以创建窗口并捕获和响应 UI 事件,但是它没有很多小部件。 那么,如果我们在应用中同时需要 OpenGL 和一些小部件,会发生什么情况? 我们可以在 Qt 中使用 OpenGL 吗? 答案是肯定的,我们将在下一节中演示如何做到这一点。
Qt 中的 OpenGL
在早期,Qt 有一个名为OpenGL的模块,但是在 Qt 5.x 中,该模块已被弃用。 gui模块中加入了新版本的 OpenGL 支持函数。 如果您在 Qt 文档中搜索名称以QOpenGL开头的类,则会找到它们。 除了gui模块中的函数外,widgets模块中还有一个重要的类,名为QOpenGLWidget。 在本节中,我们将使用其中一些函数在 Qt 中使用 OpenGL 绘制一个三角形。
首先,让我们创建所需的 Qt 项目:
$ pwd
/home/kdr2/Work/Books/Qt5-And-OpenCV4-Computer-Vision-Projects/Chapter-08
$ mkdir QtGL
$ cd QtGL/
$ touch main.cpp
$ qmake -project
$ ls
QtGL.pro main.cpp
$
然后,我们将QtGL.pro项目文件的内容更改为以下内容:
TEMPLATE = app
TARGET = QtGL
QT += core gui widgets
INCLUDEPATH += .
DEFINES += QT_DEPRECATED_WARNINGS
# Input
HEADERS += glpanel.h
SOURCES += main.cpp glpanel.cpp
RESOURCES = shaders.qrc
这是指许多目前尚不存在的文件,但请不要担心-我们将在编译项目之前创建所有文件。
首先,我们将创建一个名为GLPanel的小部件类,以显示将在 OpenGL 上下文中绘制的图形。 我们用于准备数据以及绘制图形的代码也将在此类中。 让我们检查一下glpanel.h头文件中的GLPanel类的声明:
class GLPanel : public QOpenGLWidget, protected QOpenGLFunctions_4_2_Core
{
Q_OBJECT
public:
GLPanel(QWidget *parent = nullptr);
~GLPanel();
protected:
void initializeGL() override;
void paintGL() override;
void resizeGL(int w, int h) override;
private:
GLuint vbo;
GLuint vao;
GLuint shaderProg;
};
该类派生自两个类:QOpenGLWidget类和QOpenGLFunctions_4_2_Core类。
QOpenGLWidget类提供了三个必须在我们的类中实现的受保护的方法,如下所示:
initializeGL方法用于初始化; 例如,准备顶点数据,顶点缓冲区对象,数组缓冲区对象和着色器程序。paintGL方法用于绘图工作; 例如,在其中我们将调用glDrawArrays函数。resizeGL方法是在调整窗口小部件大小时将调用的函数。
QOpenGLFunctions_4_2_Core类包含许多函数,它们的名称与 Khronos 的 OpenGL V4.2 API 相似。 类名称中的4_2字符串指示我们正在使用的 OpenGL 版本,Core字符串告诉我们已使用 OpenGL 的核心配置文件。 我们从该类派生我们的类,以便我们可以使用具有相同名称的所有 OpenGL 函数,而在我们的类中没有任何前缀,尽管这些函数实际上是 Qt 提供的包装器。
让我们转到glpanel.cpp源文件以查看实现。 构造器和析构器非常简单,因此在此不再赘述。 首先,让我们看一下初始化方法void GLPanel::initializeGL():
void GLPanel::initializeGL()
{
initializeOpenGLFunctions();
// ... omit many lines
std::string vertex_shader_str = textContent(":/shaders/vertex.shader");
const char *vertex_shader_code = vertex_shader_str.data();
std::string fragment_shader_str = textContent(":/shaders/fragment.shader");
const char *fragment_shader_code = fragment_shader_str.data();
// ... omit many lines
}
此方法中的大多数代码是从上一部分的main函数复制而来的; 因此,我在这里省略了很多行,仅说明了相同点和不同点。 在这种方法中,我们准备了顶点数据,顶点缓冲对象和顶点数组对象。 将数据传递给 GPU; 并编写,编译和链接着色器程序。 除了vao,vbo和shaderProg是类成员而不是局部变量之外,该过程与前面的应用相同。
除此之外,我们在一开始就调用initializeOpenGLFunctions方法来初始化 OpenGL 函数包装器。 另一个区别是我们将着色器代码移到单独的文件中,以提高着色器程序的可维护性。 我们将文件放在名为shaders的子目录下,并在shaders.qrc Qt 资源文件中引用它们:
<!DOCTYPE RCC>
<RCC version="1.0">
<qresource>
<file>shaders/vertex.shader</file>
<file>shaders/fragment.shader</file>
</qresource>
</RCC>
然后,我们使用textContent函数加载这些文件的内容。 此函数也在glpanel.cpp文件中定义:
std::string textContent(QString path) {
QFile file(path);
file.open(QFile::ReadOnly | QFile::Text);
QTextStream in(&file);
return in.readAll().toStdString();
}
现在初始化已完成,让我们继续进行paintGL方法:
void GLPanel::paintGL()
{
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
glUseProgram(shaderProg);
glBindVertexArray(vao);
glDrawArrays(GL_TRIANGLES, 0, 3);
glFlush();
}
如您所见,在此方法中绘制三角形的所有操作与先前应用中的最后一个代码块完全相同。
最后,当调整窗口小部件的大小时,我们调整 OpenGL 视口的大小:
void GLPanel::resizeGL(int w, int h)
{
glViewport(0, 0, (GLsizei)w, (GLsizei)h);
}
至此,我们已经完成了GLPanel OpenGL 小部件,因此让我们在main.cpp文件中使用它:
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
QSurfaceFormat format = QSurfaceFormat::defaultFormat();
format.setProfile(QSurfaceFormat::CoreProfile);
format.setVersion(4, 2);
QSurfaceFormat::setDefaultFormat(format);
QMainWindow window;
window.setWindowTitle("QtGL");
window.resize(800, 600);
GLPanel *panel = new GLPanel(&window);
window.setCentralWidget(panel);
window.show();
return app.exec();
}
在main函数中,我们获取默认的QSurefaceFormat类型并更新与 OpenGL 相关的一些关键设置,如下所示:
- 将配置文件设置为核心配置文件。
- 由于我们使用
QOpenGLFunctions_4_2_Core类,因此将版本设置为 V4.2。
然后,我们创建主窗口和GLPanel类的实例,将GLPanel实例设置为主窗口的中央小部件,显示该窗口并执行该应用。 我们在 OpenGL 中的第一个 Qt 应用已经完成,因此您现在可以编译并运行它。 但是,您可能会发现与前面的示例中的窗口没有什么不同。 是的,我们向您展示了如何在 Qt 项目中使用 OpenGL,但没有向您展示如何制作具有许多小部件的复杂应用。 由于在前几章中我们已经学到了很多有关如何使用 Qt 构建复杂的 GUI 应用的知识,并且现在有了 OpenGL 小部件,因此您可以尝试自己开发具有 OpenGL 功能的复杂 Qt 应用。 在下一节中,我们将更深入地研究 OpenGL,以探索如何使用 OpenGL 过滤图像。
除了QOpenGLFunctions_*类中的 OpenGL API 函数外,Qt 还为 OpenGL 中的概念包装了许多其他类。 例如,QOpenGLBuffer类用于顶点缓冲区对象,QOpenGLShaderProgram类型用于着色器程序,等等。 这些类的使用也非常方便,但与最新版本的 OpenGL 相比可能会(或将会)落后一些。
使用 OpenGL 过滤图像
到目前为止,我们已经学习了如何在 OpenGL 中绘制一个简单的三角形。 在本节中,我们将学习如何绘制图像并使用 OpenGL 对其进行过滤。
我们将在 QtGL 项目的副本(即名为GLFilter的新项目)中进行此工作。 就像我们在前几章中所做的那样,该项目的创建仅涉及直接复制和一点重命名。 我在这里不再重复,所以请自己复制。
使用 OpenGL 绘制图像
为了在 OpenGL 视口上绘制图像,我们应该引入 OpenGL 的另一个概念-纹理。 OpenGL 中的纹理通常是 2D 图像,通常用于向对象(主要是三角形)添加视觉细节。
由于任何类型的数字图像通常都是矩形,因此我们应绘制两个三角形以组成图像的矩形,然后将图像加载为纹理并将其映射到矩形。
纹理使用的坐标系与绘制三角形时使用的 NDC 不同。 纹理坐标系的x和y(轴)都在0和1之间,即,左下角是(0, 0),右上角是(1, 1)。 因此,我们的顶点和坐标映射如下所示:

上图显示了我们将绘制的两个三角形之一,即右下角的三角形。 括号中的坐标为三角形顶点的坐标,方括号中的坐标为纹理的坐标。
如图所示,我们定义顶点属性数据如下:
GLfloat points[] = {
// first triangle
+1.0f, +1.0f, +0.0f, +1.0f, +1.0f, // top-right
+1.0f, -1.0f, +0.0f, +1.0f, +0.0f, // bottom-right
-1.0f, -1.0f, +0.0f, +0.0f, +0.0f, // bottom-left
// second triangle
-1.0f, -1.0f, +0.0f, +0.0f, +0.0f, // bottom-left
-1.0f, +1.0f, +0.0f, +0.0f, +1.0f, // top-left
+1.0f, +1.0f, +0.0f, +1.0f, +1.0f // top-right
};
如您所见,我们为两个三角形定义了六个顶点。 此外,每个顶点有五个浮点数-前三个是三角形顶点的坐标,而后两个是与顶点对应的纹理的坐标。
现在,让我们将数据传递到 GPU:
// VBA & VAO
glGenBuffers(1, &vbo);
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(points), points, GL_STATIC_DRAW);
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), NULL);
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(3 * sizeof(float)));
在前面的代码中,我们创建顶点缓冲区对象,将浮点数填充到其中,然后创建顶点数组对象。 在这里,与上一次在Hello OpenGL示例中绘制单个三角形时,将顶点缓冲区对象绑定到顶点数组对象相比,我们在顶点数组对象中启用了两个指针,但没有一个; 也就是说,我们在那里预留了两个席位。 第一个索引为0,用于三角形顶点的坐标。 第二个索引是1,用于将纹理坐标映射到顶点。
下图显示了缓冲区中三个顶点的数据布局以及我们如何在顶点数组对象中使用它:

我们将顶点的坐标用作索引为 0 的指针,如图所示,每个顶点的元素计数为 3,步幅为 20(5 * sizeof(float)),其偏移量为 0。这些是我们第一次调用glVertexAttribPointer函数时传递的参数。 对于纹理的坐标,元素数为 2,步幅为 20,偏移量为 12。使用这些数字,我们再次调用glVertexAttribPointer函数来设置数组指针。
好的,因此将顶点属性的数据传递到 GPU; 现在让我们演示如何将图像(或纹理)加载到 GPU 上:
// texture
glEnable(GL_TEXTURE_2D);
// 1\. read the image data
QImage img(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/qt5-opencv4-cv-proj/img/lizard.jpg");
img = img.convertToFormat(QImage::Format_RGB888).mirrored(false, true);
// 2\. generate texture
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGB,
img.width(), img.height(), 0, GL_RGB, GL_UNSIGNED_BYTE, img.bits());
glGenerateMipmap(GL_TEXTURE_2D);
在这段代码中,我们启用 OpenGL 的 2D 纹理功能,从 Qt 资源系统加载图像,然后将图像转换为 RGB 格式。 您可能会注意到,我们通过调用mirrored方法在垂直方向翻转图像。 这是因为 Qt 中的图像和 OpenGL 中的纹理使用不同的坐标系:(0, 0)是 Qt 图像中的左上角,而它是 OpenGL 纹理中的左下角。 换句话说,它们的y轴方向相反。
加载图像后,我们生成一个纹理对象,并将其名称保存到texture类成员,并将其绑定到当前 OpenGL 上下文。 然后,我们调用glTexImage2D函数将图像数据复制到 GPU 的纹理内存中。 这是此函数的签名:
void glTexImage2D(
GLenum target,
GLint level,
GLint internalformat,
GLsizei width,
GLsizei height,
GLint border,
GLenum format,
GLenum type,
const GLvoid * data
);
让我们检查一下此函数的参数,如下所示:
- 以
GL_TEXTURE_2D作为其值的target指定纹理目标。 OpenGL 还支持 1D 和 3D 纹理,因此我们使用此值来确保它是我们正在操作的当前绑定的 2D 纹理。 level是 mipmap 级别。 在 OpenGL 中,mipmap 是通过调整原始图像大小而生成的一系列不同大小的图像。 在该系列中,每个后续图像都是前一个图像的两倍。 自动选择了 mipmap 中的图像,以用于不同的对象大小,或特定对象位于不同位置时使用。 例如,如果物体在我们看来不远,则将使用较小的图像。 与动态调整纹理大小到适当大小相比,使用 mipmap 中预先计算的纹理可以减少计算并提高图像质量。 如果要手动操作 mipmap,则应使用非零值。 在这里,我们将使用 OpenGL 提供的函数来生成 mipmap,因此我们只需使用0即可。internalformat告诉 OpenGL 我们想以哪种格式存储纹理。我们的图像只有 RGB 值,因此我们也将存储带有 RGB 值的纹理。width和height是目标纹理的宽度和高度。 我们在这里使用图像的尺寸。border是没有意义的传统参数,应始终为0。format和type是源图像的格式和数据类型。data是指向实际图像数据的指针。
调用返回后,纹理数据已在 GPU 上准备就绪,然后调用glGenerateMipmap(GL_TEXTURE_2D)为当前绑定的 2D 纹理生成 mipmap。
至此,纹理已经准备就绪,让我们看一下着色器程序。 首先是顶点着色器,如下所示:
#version 420
layout (location = 0) in vec3 vertex;
layout (location = 1) in vec2 inTexCoord;
out vec2 texCoord;
void main()
{
gl_Position = vec4(vertex, 1.0);
texCoord = inTexCoord;
}
在此着色器中,两个输入变量(其位置为0和1)对应于我们在顶点数组对象中启用的两个指针,它们表示三角形顶点的坐标和纹理映射坐标。 在主函数中,我们通过将顶点分配给预定义变量gl_Position来设置顶点的位置。 然后,我们将纹理坐标传递给使用out关键字声明的输出变量。 这个输出变量将被传递给下一个着色器,即片段着色器。 以下是我们的片段着色器:
#version 420
in vec2 texCoord;
out vec4 frag_color;
uniform sampler2D theTexture;
void main()
{
frag_color = texture(theTexture, texCoord);
}
此片段着色器中有三个变量,如下所示:
in vec2 texCoord是来自顶点着色器的纹理坐标。out vec4 frag_color是输出变量,我们将对其进行更新以传递片段的颜色。uniform sampler2D theTexture是纹理。 它是uniform变量; 与in和out变量不同,可以在 OpenGL 图形管线的任何阶段的任何着色器中看到uniform变量。
在主函数中,我们使用内置的texture函数获取与给定纹理坐标texCoord对应的颜色,并将其分配给输出变量。 从纹理中选择颜色的过程在 OpenGL 术语中称为纹理采样。
现在,着色器已准备就绪。 我们在初始化函数中要做的最后一件事是调整主窗口的大小以适合图像大小:
((QMainWindow*)this->parent())->resize(img.width(), img.height());
好的,现在让我们在GLPanel::paintGL方法中绘制对象:
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
glUseProgram(shaderProg);
glBindVertexArray(vao);
glBindTexture(GL_TEXTURE_2D, texture);
glDrawArrays(GL_TRIANGLES, 0, 6);
glFlush();
与上次绘制三角形相比,这里我们向glBindTexture添加了一个新函数调用,以将新创建的纹理绑定到当前 OpenGL 上下文,并使用6作为glDrawArrays函数的第三个参数, 因为我们要绘制两个三角形。
现在,该编译并运行我们的应用了。 如果一切顺利,您将看到 OpenGL 渲染的图像:

尽管在我们的代码中,我们从 Qt 资源系统加载了图像,但是我们可以在本地磁盘上加载任何图像-只需更改路径即可。
在片段着色器中过滤图像
在前面的小节中,我们使用 OpenGL 绘制了图像。 绘制图像时,我们从片段着色器的纹理(与原始图像具有相同的数据)中选择了颜色。 因此,如果我们在片段着色器中根据特定规则更改颜色,然后再将其散发出去,我们会得到修改后的图像吗?
按照这种想法,让我们在片段着色器程序中尝试一个简单的线性模糊过滤器。 下图显示了线性模糊过滤器的原理:

对于给定的像素,我们根据其周围像素的颜色确定其颜色。 在上图中,对于给定的像素,我们在其周围绘制5 x 5的正方形,并确保它是正方形的中心像素。 然后,我们对正方形中除中心像素本身以外的所有像素的颜色求和,求出平均值(通过将总和除以5 x 5 - 1),然后将平均值用作给定像素的颜色。 在这里,我们将平方称为过滤器核及其边长,即核大小5。
但是,我们这里有一个问题。 texCoord变量中存储的坐标是 0 到 1 之间的浮点数,而不是像素数。 在这样的范围内,我们无法直接确定核大小,因此我们需要知道纹理坐标系中一个像素代表多长时间。 这可以通过将 1.0 除以图像的宽度和高度来解决。 这样,我们将获得两个浮点数,它们在纹理坐标系中分别代表一个像素的宽度和一个像素的高度。 稍后,我们将两个数字存储在统一的两个元素向量中。 让我们更新片段着色器,如下所示:
#version 420
in vec2 texCoord;
out vec4 frag_color;
uniform sampler2D theTexture;
uniform vec2 pixelScale;
void main()
{
int kernel_size = 5;
vec4 color = vec4(0.0, 0.0, 0.0, 0.0);
for(int i = -(kernel_size / 2); i <= kernel_size / 2; i++) {
for(int j = -(kernel_size / 2); j <= kernel_size / 2; j++) {
if(i == 0 && j == 0) continue;
vec2 coord = vec2(texCoord.x + i * pixelScale.x, texCoord.y + i * pixelScale.y);
color = color + texture(theTexture, coord);
}
}
frag_color = color / (kernel_size * kernel_size - 1);
}
前面代码中的uniform vec2 pixelScale变量是我们刚刚讨论的比率数。 在主函数中,我们使用5作为核大小,计算出核正方形中像素的纹理坐标,拾取颜色,然后将它们汇总为两级嵌套for循环。 循环后,我们计算平均值并将其分配给输出变量。
下一步是将值设置为uniform vec2 pixelScale变量。 链接着色器程序后,可以通过GLPanel::initializeGL方法完成此操作:
// ...
glLinkProgram(shaderProg);
// scale ration
glUseProgram(shaderProg);
int pixel_scale_loc = glGetUniformLocation(shaderProg, "pixelScale");
glUniform2f(pixel_scale_loc, 1.0f / img.width(), 1.0f / img.height());
链接着色器程序后,我们在当前 OpenGL 上下文中激活(即使用)着色器程序,然后使用着色器程序和统一变量名称作为其参数调用glGetUniformLocation。 该调用将返回统一变量的位置。 在此位置,我们可以调用glUniform2f设置其值。 函数名称中的2f后缀表示两个浮点数,因此,我们将两个缩放比例传递给它。
至此,除一种情况外,我们的过滤器已基本完成。 考虑如果我们正在计算其颜色的给定像素位于图像边缘,将会发生什么情况。 换句话说,我们如何处理图像的边缘? 解决方法如下:
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_MIRRORED_REPEAT);
在GLPanel::initializeGL方法中将这两行添加到生成和绑定纹理的行旁边。 这些行设置纹理环绕的行为:GL_TEXTURE_WRAP_S用于水平方向,GL_TEXTURE_WRAP_T用于垂直方向。 我们将它们都设置为GL_MIRRORED_REPEAT,因此,如果我们使用小于 0 或大于 1 的坐标,则纹理图像的镜像重复将在那里进行采样。 换句话说,它具有与 OpenCV 库中的BORDER_REFLECT相同的效果,当我们调用cv::warpAffine函数时,该库将内插为fedcba|abcdefgh|hgfedcb。 例如,当我们访问坐标为(1, 1 + y)的点时,它返回点(x, 1 - y)的颜色。
现在,我们的线性模糊过滤器已经完成,因此让我们重新编译并运行我们的应用以查看效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9FYWbt2a-1681871222588)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/qt5-opencv4-cv-proj/img/2ff255f2-de2c-4a30-bdb0-190ae2be5413.png)]
好吧,它按预期工作。 为了更清楚地看到其效果,我们甚至可以仅模糊图像的一部分。 这是更新的片段着色器的main函数:
void main()
{
int kernel_size = 7;
vec4 color = vec4(0.0, 0.0, 0.0, 0.0);
if(texCoord.x > 0.5) {
for(int i = -(kernel_size / 2); i <= kernel_size / 2; i++) {
for(int j = -(kernel_size / 2); j <= kernel_size / 2; j++) {
if(i == 0 && j == 0) continue;
vec2 coord = vec2(texCoord.x + i * pixelScale.x, texCoord.y + i * pixelScale.y);
color = color + texture(theTexture, coord);
}
}
frag_color = color / (kernel_size * kernel_size - 1);
} else {
frag_color = texture(theTexture, texCoord);
}
}
在此版本中,我们仅模糊图像的右侧(即texCoord.x > 0.5的部分); 效果如下:

由于我们将所有资源都编译为可执行文件,因此我们需要在更新资源文件(包括着色器)后重新编译应用。
在本节中,我们在 GPU 上运行的片段着色器中实现一个简单的线性模糊过滤器。 如果您拥有不错的 GPU 并将其应用于大图像,则与在 CPU 上运行类似的过滤器相比,您将获得较大的性能提升。
由于我们可以访问纹理(或图像)的所有像素并确定片段着色器中渲染图像的所有像素的颜色,因此我们可以在着色器程序中实现任何过滤器。 您可以自己尝试使用高斯模糊过滤器。
保存过滤的图像
在前面的小节中,我们实现了模糊过滤器并成功地对其进行了模糊处理-模糊的图像在 OpenGL 视口上呈现。 那么,我们可以将生成的图像另存为本地磁盘上的文件吗? 当然; 让我们这样做如下:
void GLPanel::saveOutputImage(QString path)
{
QImage output(img.width(), img.height(), QImage::Format_RGB888);
glReadPixels(
0, 0, img.width(), img.height(), GL_RGB, GL_UNSIGNED_BYTE, output.bits());
output = output.mirrored(false, true);
output.save(path);
}
我们添加了一个新的GLPanel::saveOutputImage方法,该方法接受文件路径作为其参数来保存图像。 另一点值得注意的是,我们将原始图像QImage img从initializeGL方法中的局部变量更改为类成员,因为我们将在类范围内使用它。
在此新添加的方法中,我们定义了一个与原始图像具有相同尺寸的新QImage对象,然后调用glReadPixels函数以读取图像对象的前四个参数所描述的矩形中的数据。 然后,由于前面提到的坐标系不同,我们在垂直方向上翻转了图像。 最后,我们将图像保存到磁盘。
如果在paintGL方法的末尾调用此方法,则在屏幕上看到图像后将找到已保存的图像。
在 OpenCV 中使用 OpenGL
在上一节中,当我们加载源图像并将其翻转时,我们使用 Qt 进行工作。 也可以使用 OpenCV 库完成此工作:
img = cv::imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/qt5-opencv4-cv-proj/img/lizard.jpg");
cv::Mat tmp;
cv::flip(img, tmp, 0);
cvtColor(tmp, img, cv::COLOR_BGR2RGB);
// ...
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGB,
img.cols, img.rows, 0, GL_RGB, GL_UNSIGNED_BYTE, img.data);
// ...
同样,当保存结果图像时,我们可以这样做:
cv::Mat output(img.rows, img.cols, CV_8UC3);
glReadPixels(
0, 0, img.cols, img.rows, GL_RGB, GL_UNSIGNED_BYTE, output.data);
cv::Mat tmp;
cv::flip(output, tmp, 0);
cvtColor(tmp, output, cv::COLOR_RGB2BGR);
cv::imwrite(path.toStdString(), output);
QImage和cv::Mat都代表图像,因此很容易来回交换它们。
除了简单地使用cv::Mat类与纹理交换数据外,OpenCV 还具有创建 OpenGL 上下文的能力。 从源代码构建库时,需要使用-D WITH_OPENGL=on选项配置库。 启用 OpenGL 支持后,我们可以创建一个窗口(使用highgui模块),该窗口具有与之关联的 OpenGL 上下文:
cv::namedWindow("OpenGL", cv::WINDOW_OPENGL);
cv::resizeWindow("OpenGL", 640, 480);
这里的关键是cv::WINDOW_OPENGL标志; 设置此标志后,将创建一个 OpenGL 上下文并将其设置为当前上下文。 但是 OpenCV 没有提供选择我们要使用的 OpenGL 版本的方法,并且它并不总是使用计算机上可用的最新版本。
我在代码库的Chapter-08/CVGLContext目录中提供了一个绘制带有 OpenGL 上下文和 OpenCV highgui模块的三角形的示例,您可以参考它以了解更多信息。 OpenCV 库的核心模块提供了一个名称空间cv::ogl,其中包括许多用于与 OpenGL 进行互操作的功能。
但是,这些功能与 Qt 提供的 OpenGL 相关类具有相同的问题,也就是说,它们可能远远落后于最新的 OpenGL。 因此,在这里,我建议,如果要使用 OpenGL,请仅使用原始 OpenGL API,而不要使用任何包装。 大多数 OpenGL 实现都足够灵活,可以轻松地与通用库集成,并且您始终可以以这种方式使用最新的 API。
总结
OpenGL 是用于开发 2D 和 3D 图形应用的规范,并且具有许多实现。 在本章中,我们学到了很多东西,包括绘制诸如三角形的图元,将其与 Qt 库集成,使用纹理渲染图像以及在片段着色器中过滤图像。 此外,我们以非典型方式使用 OpenGL,也就是说,我们并未将其用于图形渲染,而是用于并行计算和处理 GPU 上的图像。
最后,我们学习了如何集成 OpenCV 和 OpenGL,并且在我看来,通过将这种方法与使用原始 OpenGL API 进行比较,这不是生产应用的推荐方法,但是可以在尝试时随意使用它。
在本章的最后,我们完成了本书。 我希望我们使用 Qt,OpenCV,Tesseract,许多 DNN 模型和 OpenGL 开发的所有项目都能使您更接近计算机视觉世界。
进一步阅读
OpenGL 除了本章介绍的内容以外,还有很多其他内容。 由于我们在本书中主要关注图像处理,因此仅展示了如何使用它来过滤图像。 如果您对 OpenGL 感兴趣,可以在其官方网站上找到更多资源。 互联网上也有许多很棒的教程,例如这里和这里。
如果您对主要用于 2D 和 3D 图形开发的 OpenGL 不太感兴趣,但是对异构计算感兴趣,则可以参考 OpenCL 或 CUDA。 OpenCL 与 OpenGL 非常相似; 它是 Khronos 组维护的规范。 此外,下一代 OpenGL 和 OpenCL 现在已合并为一个名为 Vulkan 的规范,因此 Vulkan 也是一个不错的选择。 CUDA 是 Nvidia 的异构计算专有解决方案,并且是该领域中最成熟的解决方案,因此,如果您拥有 Nvidia 显卡,则使用 CUDA 进行异构计算是最佳选择。
九、答案
第 1 章,构建图像查看器
- 我们使用消息框来告诉用户他们在尝试查看第一张图像之前的图像或最后一张图像之后的图像时已经在查看第一张或最后一张图像。 但是,还有另一种处理方法:当用户查看第一张图像时禁用
prevAction,而当用户查看最后一张图像时禁用nextAction。 我们该如何处理?
QAction类具有bool enabled属性,因此具有setEnabled(bool)方法,我们称其为启用或禁用prevImage和nextImage方法中的相应动作。
- 我们的菜单项或工具按钮上只有文字。 我们如何向他们添加图标图像?
QAction类具有QIcon icon属性,因此具有setIcon方法,您可以创建和设置操作图标。 要创建QIcon对象,请参考这里上的相应文档。
- 我们使用
QGraphicsView.scale放大或缩小图像视图。 图像视图如何旋转?
使用QGraphicsView.rotate方法。
moc有什么作用?SIGNAL和SLOT宏有什么作用?
moc命令是 Qt 元对象系统编译器。 它主要从包含QOBJECT宏的用户定义类中提取所有与元对象系统相关的信息,包括信号和时隙。 然后,它创建一个名称以moc_开头的 C++ 源文件来管理此元信息(主要是信号和插槽)。 它还提供了该文件中信号的实现。 SIGNAL和SLOT宏将其参数转换为字符串,该字符串可用于在由moc命令管理的元信息中找到相应的信号或时隙。
第 2 章,像专家一样编辑图像
- 我们如何知道 OpenCV 函数是否支持原地操作?
如本章所述,我们可以参考与该函数有关的正式文件。 如果文档规定它支持原地操作,则支持,否则,不支持。
- 如何将热键添加到我们作为插件添加的每个操作中?
我们可以向插件接口类添加一个新方法,该方法返回QList<QKeySequence>实例并在具体的插件类中实现。 加载插件时,我们调用该方法以获取快捷键序列,并将其设置为该插件操作的热键。
- 如何添加新操作以丢弃应用中当前图像中的所有更改?
首先,将QPixmap类型的类字段添加到MainWindow类中。 在编辑当前图像之前,我们将图像的副本保存到该字段。 然后,我们添加一个新动作和一个连接到该动作的新插槽。 在插槽中,我们将保存的图像设置为图形场景。
- 如何使用 OpenCV 调整图像大小?
为此,可以在以下链接中找到其函数。
第 3 章,家庭安全应用
- 我们可以从视频文件而不是从摄像机检测运动吗? 如何实现的?
我们可以。 只需使用视频文件路径来构造VideoCapture实例。 可以在这个页面上找到更多详细信息。
- 我们可以在不同于视频捕获线程的线程中执行运动检测工作吗? 如果是这样,这怎么可能?
是。 但是我们应该使用多种同步机制来确保数据安全。 另外,如果我们将帧分派到不同的线程,则必须确保将结果帧发送回并即将显示时,它们的顺序也正确。
- IFTTT 允许您在发送的通知中包括图像-当通过 IFTTT 的此功能向您的手机发送通知时,我们如何发送检测到的运动图像?
首先,在 IFTTT 上创建小程序时,选择从 IFTTT 应用发送丰富通知作为that服务。 然后,当检测到运动时,我们将帧作为图像上传到诸如 imgur 之类的位置,并获取其 URL。 然后,将图像 URL 作为参数发布到 IFTTT Webhook,并使用该 URL 作为富格式通知中的图像 URL,该格式可以在其主体中包含图像 URL。
第 4 章,人脸上的乐趣
- LBP 级联分类器可以用来自己检测人脸吗?
是。 只需使用 OpenCV 内置的lbpcascades/lbpcascade_frontalface_improved.xml分类器数据文件。
- 还有许多其他算法可用于检测 OpenCV 库中的人脸标志。 其中大多数可以在这个页面中找到。 自己尝试一下。
可以通过以下链接使用不同的函数,创建不同的算法实例。 所有这些算法都与本章中使用的 API 具有相同的 API,因此您只需更改它们的创建语句即可轻松尝试这些算法。
- 如何将彩色装饰物应用到脸上?
在我们的项目中,视频帧和装饰物均为BGR格式,没有 alpha 通道。 考虑到装饰物有白色背景,我们可以使用cv::threshold函数先生成一个遮罩。 遮罩是二进制图像,背景为白色,前景(装饰的一部分)为黑色。 然后,我们可以使用以下代码来应用装饰:
frame(rec) &= mask;
ornament &= ^mask;
frame(rec) |= ornament;
第 5 章,光学字符识别
- Tesseract 如何识别非英语语言的字符?
初始化TessBaseAPI实例时,请指定相应的语言名称。
- 当我们使用 EAST 模型检测文本区域时,检测到的区域实际上是旋转的矩形,而我们只是使用其边界矩形。 这总是对的吗? 如果没有,该如何纠正?
是正确的,但这不是最佳方法。 我们可以将旋转矩形的边界框中的区域复制到新图像,然后旋转并裁剪它们以将旋转矩形转换为规则矩形。 之后,通常通过将生成的规则矩形发送到 Tesseract 来提取文本,通常将获得更好的输出。
- 尝试找出一种方法,允许用户在从屏幕捕获图像时拖动鼠标后调整所选区域。
通常的方法是在选定区域的边界矩形的顶点和侧面上插入八个手柄,然后用户可以拖动这些手柄以调整选定区域。 这可以通过扩展我们的ScreenCapturer类的paintEvent和mouse*Event方法来完成。 在paintEvent方法中,我们绘制选择矩形及其句柄。 在mouse*Event方法中,我们检查是否在手柄上按下了鼠标,然后通过拖动鼠标重新绘制选择矩形。
第 6 章,实时对象检测
- 当我们针对波士顿公牛的脸部训练级联分类器时,我们会在每个图像上自行标注狗的脸部。 标注过程非常耗时。 网站上有该数据集的标注数据压缩包。 是否可以使用一段代码从此标注数据生成
info.txt文件? 如何才能做到这一点?
该压缩文件中的标注数据与狗的身体有关,而不与狗的脸有关。 因此,我们不能使用它来训练狗脸的分类器。 但是,如果您想为狗的全身训练分类器,这会有所帮助。 该压缩文件中的数据以 XML 格式存储,标注矩形是具有//annotation/object/bndbox路径的节点,我们可以轻松提取该路径。
- 尝试找到预训练的(快速/快速)R-CNN 模型和预训练的 SSD 模型,运行它们,然后将其性能与 YOLOv3 进行比较。
以下列表提供了一些 Faster R-CNN 和 SSD 模型。 如果您对它们之一感兴趣,请自己进行测试:
- 我们可以使用 YOLOv3 来检测某种对象,但不是全部 80 类对象吗?
是的,您可以根据特定的类 ID 过滤结果。 在第 7 章,“实时汽车检测和距离测量”中,我们采用了这种方法来检测汽车,请仅参考该章。
第 7 章,实时汽车检测和距离测量
- 测量汽车之间的距离时是否有更好的参考对象?
可可数据集中有许多类,其中对象通常具有固定位置; 例如,交通信号灯,消防栓和停车标志。 我们可以在相机视图中找到其中一些,选择其中任意两个,测量它们之间的距离,然后将所选对象及其距离用作参考。