原文:Learning Image Processing with OpenCV
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、计算摄影
计算摄影是指使您能够扩展数字摄影的典型功能的技术。 这可能包括硬件附加组件或修改,但主要指基于软件的技术。 这些技术可能会产生“传统”数码相机无法获得的输出图像。 本章介绍了 OpenCV 中用于计算摄影的一些鲜为人知的技术:高动态范围成像,无缝克隆,脱色和非照片级渲染。 这三个位于库的photo模块中。 注意,在前面的章节中已经考虑了该模块内部的其他技术(修复和去噪)。
高动态范围图像
我们处理的典型图像每像素有 8 位(BPP)。 彩色图像还使用 8 位表示每个通道的值,即红色,绿色和蓝色。 这意味着仅使用 256 个不同的强度值。 在数字成像的整个历史中,这个 8 BPP 的限制一直盛行。 但是,很明显,自然界中的光并不只有 256 个不同的水平。 因此,我们应该考虑这种离散化是理想的还是足够的。 例如,已知人眼可以捕获更高的动态范围(最暗和最亮之间的亮度级别数),估计在 1 亿到 1 亿个亮度级别之间。 在只有 256 个光照级别的情况下,有些情况下明亮的光线看起来过度曝光或饱和,而黑暗的场景只是被捕获为黑色。
有些相机可以捕获超过 8 BPP 的图像。 但是,创建高动态范围图像的最常见方法是使用 8 BPP 相机并拍摄具有不同曝光值的图像。 当我们这样做时,动态范围有限的问题显而易见。 例如,考虑下图:

用六个不同的曝光值拍摄的场景
注意
左上方的图像大部分为黑色,但窗口详细信息可见。 相反,右下角的图像显示了房间的细节,但窗口的细节几乎看不见。
我们可以使用现代智能手机相机以不同的曝光水平拍摄照片。 例如,对于 iPhone 和 iPad,从 iOS 8 开始,使用本机相机应用更改曝光非常容易。 触摸屏幕,将出现一个黄色框,侧面带有一个小太阳。 向上或向下滑动可以更改曝光(请参见以下屏幕截图)。
注意
曝光级别的范围非常大,因此我们可能不得不重复多次滑动手势。
如果您使用的是 iOS 的早期版本,则可以下载相机应用,例如 Camera+,这些应用可让您专注于特定点并更改曝光。
对于 Android,可以在 Google Play 上使用大量相机应用来调整曝光度。 一个例子是 Camera FV-5,它具有免费和付费版本。
提示
如果使用手持设备捕获图像,请确保该设备是静态的。 实际上,您可能会使用三脚架。 否则,具有不同曝光度的图像将无法对齐。 同样,移动的被摄体将不可避免地产生鬼影。 在大多数情况下,低,中和高曝光量的三张图像就足够了。

使用 iPhone 5S 中的本机摄像头应用进行曝光控制
智能手机和桌子很方便,可以拍摄许多曝光不同的图像。 要创建 HDR 图像,我们需要知道每个捕获图像的曝光(或快门)时间(原因请参见以下部分)。 并非所有应用都允许您手动控制(甚至查看)此功能(iOS 8 本机应用则不允许)。 在撰写本文时,至少有两个免费的应用允许 iOS 版使用:Manually 和 ManualShot。 在 Android 中,免费的 Camera FV-5 可让您控制和查看曝光时间。 请注意,F/Stop 和 ISO 是控制曝光的其他两个参数。
捕获的图像可以传输到开发计算机,并用于创建 HDR 图像。
注意
从 iOS 7 开始,本机相机应用具有 HDR 模式,可自动快速捕获三幅图像,每幅图像具有不同的曝光度。 这些图像也会自动组合为单个(有时更好)的图像。
创建 HDR 图像
我们如何将多张(例如三张)曝光图像合成为 HDR 图像? 如果我们仅考虑一个通道和一个给定的像素,则必须在较大的输出范围(例如 16 bpp)中将这三个像素值(每个曝光级别一个)映射到单个值。 这种映射并不容易。 首先,我们必须考虑像素强度是传感器辐照度(入射在相机传感器上的光量)的(粗略)度量。 数码相机以非线性方式测量辐照度。 相机具有非线性响应函数,可以将辐照度转换为像素强度值,范围为 0 到 255。 为了将这些值映射到更大的离散值集,我们必须估计摄像机的响应函数(即,响应范围在 0 到 255 之间)。
我们如何估计相机响应函数? 我们从像素本身做到这一点! 响应函数是每个颜色通道的 Sigmoid 曲线,可以根据像素进行估计(如果有 3 个像素曝光,则每个颜色通道的曲线上有 3 个点)。 由于这非常耗时,因此通常选择一组随机像素。
只剩下一件事了。 我们之前曾讨论过估计辐照度和像素强度之间的关系。 我们如何知道辐照度? 传感器的辐照度与曝光时间(或等效地,快门速度)成正比。 这就是我们需要曝光时间的原因!
最后,将 HDR 图像计算为从每次曝光的像素中恢复的辐照度值的加权和。 请注意,此图像无法在范围有限的常规屏幕上显示。
注意
关于高动态范围成像的一本好书是 Reinhard 等人的《高动态范围成像:获取,显示和基于图像的照明》,Morgan Kaufmann Pub。 该书随附 DVD,其中包含不同 HDR 格式的图像。
范例
OpenCV(仅从 3.0 版开始)提供了从一组以不同曝光拍摄的图像中创建 HDR 图像的函数。 甚至还有一个名为hdr_imaging的教程示例,该示例从图像文件中读取图像文件和曝光时间列表,并创建 HDR 图像。
注意
为了运行hdr_imaging教程,您将需要使用列表下载所需的图像文件和文本文件。 您可以从这个页面下载它们。
CalibrateDebevec和MergeDebevec类实现 Debevec 的方法来估计相机响应函数并将曝光分别合并为 HDR 图像。createHDR示例之后的向您展示了如何使用这两个类:
#include <opencv2/photo.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int, char** argv)
{
vector<Mat> images;
vector<float> times;
// Load images and exposures...
Mat img1 = imread("1div66.jpg");
if (img1.empty())
{
cout << "Error! Input image cannot be read...\n";
return -1;
}
Mat img2 = imread("1div32.jpg");
Mat img3 = imread("1div12.jpg");
images.push_back(img1);
images.push_back(img2);
images.push_back(img3);
times.push_back((float)1/66);
times.push_back((float)1/32);
times.push_back((float)1/12);
// Estimate camera response...
Mat response;
Ptr<CalibrateDebevec> calibrate = createCalibrateDebevec();
calibrate->process(images, response, times);
// Show the estimated camera response function...
cout << response;
// Create and write the HDR image...
Mat hdr;
Ptr<MergeDebevec> merge_debevec = createMergeDebevec();
merge_debevec->process(images, hdr, times, response);
imwrite("hdr.hdr", hdr);
cout << "\nDone. Press any key to exit...\n";
waitKey(); // Wait for key press
return 0;
}
该示例使用三个杯子的图像(这些图像以及本书随附的代码均可用)。 图像是使用 ManualShot 拍摄的前面提到的应用,使用的曝光时间为 1/66、1/32 和 1/12 秒; 请参考下图:

示例中用作输入的三个图像
请注意,createCalibrateDebevec方法在 STL 向量中期望图像和曝光时间(STL 是一种有用的常用函数和标准 C++ 中可用的数据结构的库)。 相机响应函数以 256 个实值向量的形式给出。 这表示像素值和辐照度之间的映射。 实际上,它是一个256 x 3的矩阵(三个颜色通道中的每个颜色通道一列)。 下图显示了示例给出的响应:
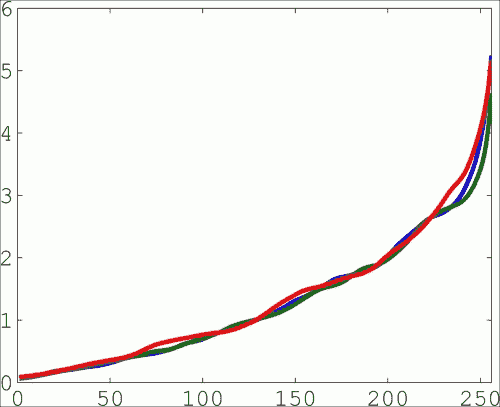
估计的 RGB 相机响应函数
提示
代码的cout部分以 MATLAB 和 Octave(两种用于数值计算的包)使用的格式显示矩阵。 复制输出中的矩阵并将其粘贴到 MATLAB/Octave 中以进行显示很简单。
生成的 HDR 图像以无损 RGBE 格式存储。 此图像格式使用每个颜色通道一个字节,再加上一个字节作为共享指数。 格式使用与浮点数表示法相同的原理:共享指数允许您表示更大范围的值。 RGBE 图像使用.hdr扩展名。 请注意,由于它是无损图像格式,因此.hdr文件相对较大。 在此示例中,RGB 输入图像分别为 1224 x 1632(每个 100 至 200 KB),而输出.hdr文件占用 5.9 MB。
该示例使用 Debevec 和 Malik 的方法,但是 OpenCV 还基于 Robertson 的方法提供了另一个校准函数。 校准和合并函数均可用,即createCalibrateRobertson和MergeRobertson。
注意
有关其他函数及其背后原理的更多信息,请参见这个页面。
最后,请注意示例不会显示结果图像。 HDR 图像无法在常规屏幕中显示,因此我们需要执行另一步,称为色调映射。
色调映射
当要显示高动态范围图像时,信息可能会丢失。 这是由于,因为计算机屏幕的对比度也很有限,而且打印材料通常也限制为 256 色。 当我们具有高动态范围的图像时,有必要将强度映射到一组有限的值。 这称为色调映射。
为了提供逼真的输出,仅将 HDR 图像值缩放到显示设备的缩小范围是不够的。 缩放通常会产生缺乏细节(对比度)的图像,从而消除了原始场景内容。 最终,色调映射算法旨在提供视觉上看起来类似于原始场景的输出(即类似于人类在查看场景时所看到的输出)。 已经提出了各种音调映射算法,并且仍然是广泛研究的问题。 以下代码行可以将色调映射应用于上一个示例中获得的 HDR 图像:
Mat ldr;
Ptr<TonemapDurand> tonemap = createTonemapDurand(2.2f);
tonemap->process(hdr, ldr); // ldr is a floating point image with
ldr=ldr*255; // values in interval [0..1]
imshow("LDR", ldr);
该方法由 Durand 和 Dorsey 于 2002 年提出。构造器实际上接受许多影响输出的参数。 下图显示了输出。 请注意,此图像不一定比三个原始图像中的任何一个都要好:

音调输出
OpenCV 中提供了其他三种音调映射算法:createTonemapDrago,createTonemapReinhard和createTonemapMantiuk。
可以使用 MATLAB 显示 HDR 图像(RGBE 格式,即扩展名为.hdr的文件)。 它只需要三行代码:
hdr=hdrread('hdr.hdr');
rgb=tonemap(hdr);
imshow(rgb);
注意
pfstools 是命令行工具的开源套件,用于读取,写入和渲染 HDR 图像。 该套件可以读取.hdr和其他格式,其中包括许多相机校准和色调映射算法。 Luminance HDR 是基于 pfstools 的免费 GUI 软件。
对齐
用多张曝光图像拍摄的场景必须是静态的。 摄像机也必须是静态的。 即使满足两个条件,也建议执行对齐过程。
OpenCV 提供了 G. Ward 在 2003 年提出的图像对齐算法。主要函数createAlignMTB采用定义最大位移的输入参数(实际上,每个尺寸的最大位移以 2 为底的对数)。 在上一示例中估计摄像机响应函数之前,应插入以下几行:
vector<Mat> images_(images);
Ptr<AlignMTB> align=createAlignMTB(4);// 4=max 16 pixel shift
align->process(images_, images);
曝光融合
我们也可以使用相机响应校准(即曝光时间)或中间 HDR 图像,将具有多次曝光的图像组合在一起。 这称为曝光融合。 该方法由 Mertens 等人在 2007 年提出。以下几行执行曝光融合(images是输入图像的 STL 向量;请参见前面的示例):
Mat fusion;
Ptr<MergeMertens> merge_mertens = createMergeMertens();
merge_mertens->process(images, fusion); // fusion is a
fusion=fusion*255; // float. point image w. values in [0..1]
imwrite("fusion.png", fusion);
下图显示了结果:

曝光融合
无缝克隆
在无缝克隆中,我们通常要在源图像中剪切一个对象/人并将其插入目标图像。 当然,这可以通过简单地粘贴对象以简单的方式完成。 但是,这不会产生现实的效果。 参见下图,例如,我们想要将图像上半部分的船插入图像下半部分的海中:

克隆
从 OpenCV 3 开始,已有无缝克隆函数可用,其结果更为真实。 此函数称为seamlessClone,它使用 Perez 和 Gangnet 在 2003 年提出的方法。以下SeamlessCloning示例向您展示了如何使用它:
#include <opencv2/photo.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int, char** argv)
{
// Load and show images...
Mat source = imread("source1.png", IMREAD_COLOR);
Mat destination = imread("destination1.png", IMREAD_COLOR);
Mat mask = imread("mask.png", IMREAD_COLOR);
imshow("source", source);
imshow("mask", mask);
imshow("destination", destination);
Mat result;
Point p; // p will be near top right corner
p.x = (float)2*destination.size().width/3;
p.y = (float)destination.size().height/4;
seamlessClone(source, destination, mask, p, result, NORMAL_CLONE);
imshow("result", result);
cout << "\nDone. Press any key to exit...\n";
waitKey(); // Wait for key press
return 0;
}
这个例子很简单。 seamlessClone函数获取源图像,目标图像和遮罩图像以及目标图像中将插入裁剪对象的点(可以从这个页面)。 请参见下图的结果:
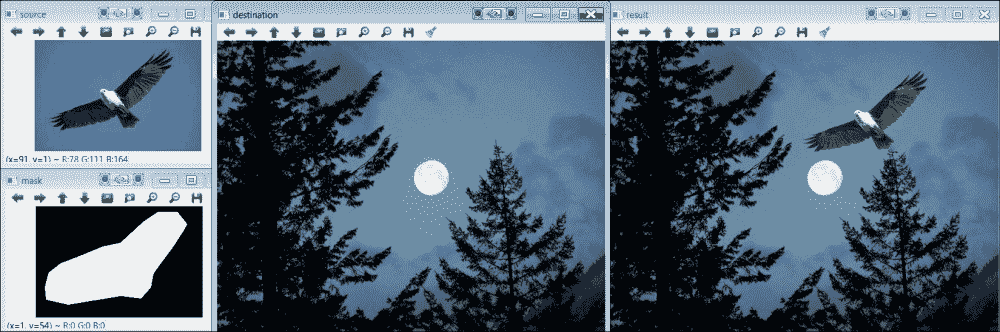
无缝克隆
seamlessClone的最后一个参数表示要使用的确切方法(可以使用三种方法产生不同的最终效果)。 另一方面,库提供以下相关函数:
| 函数 | 效果 |
|---|---|
colorChange | 将源图像的三个颜色通道中的每个乘以一个因子,仅在遮罩给定的区域中应用乘法 |
illuminationChange | 仅在遮罩指定的区域内更改源图像的照度 |
textureFlattening | 仅在遮罩指定的区域中洗掉源图像中的纹理 |
与seamlessClone相反,这三个函数仅接受源图像和遮罩图像。
脱色
脱色是将彩色图像转换为灰度的过程。 有了这个定义,读者可能会问,我们是否已经有了灰度转换? 是的,灰度转换是 OpenCV 和任何图像处理库中的基本例程。 标准转换基于 R,G 和 B 通道的线性组合。 问题在于这种转换可能会产生原始图像中的对比度丢失的图像。 原因是两种不同的颜色(在原始图像中被视为对比度)可能最终被映射到相同的灰度值。 考虑将 A 和 B 这两种颜色转换为灰度。 假设 B 是 R 和 G 通道中 A 的变体:
A = (R, G, B) => G = (R + G + B) / 3
B = (R-x, G + x, B) => G = (R-x + G + x + B) / 3 = (R + G + B) / 3
即使它们被认为是截然不同的,两种颜色 A 和 B 也被映射为相同的灰度值! 以下脱色示例的图像显示如下:
#include <opencv2/photo.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int, char** argv)
{
// Load and show images...
Mat source = imread("color_image_3.png", IMREAD_COLOR);
imshow("source", source);
// first compute and show standard grayscale conversion...
Mat grayscale = Mat(source.size(),CV_8UC1);
cvtColor(source, grayscale, COLOR_BGR2GRAY);
imshow("grayscale",grayscale);
// now compute and show decolorization...
Mat decolorized = Mat(source.size(),CV_8UC1);
Mat dummy = Mat(source.size(),CV_8UC3);
decolor(source,decolorized,dummy);
imshow("decolorized",decolorized);
cout << "\nDone. Press any key to exit...\n";
waitKey(); // Wait for key press
return 0;
}
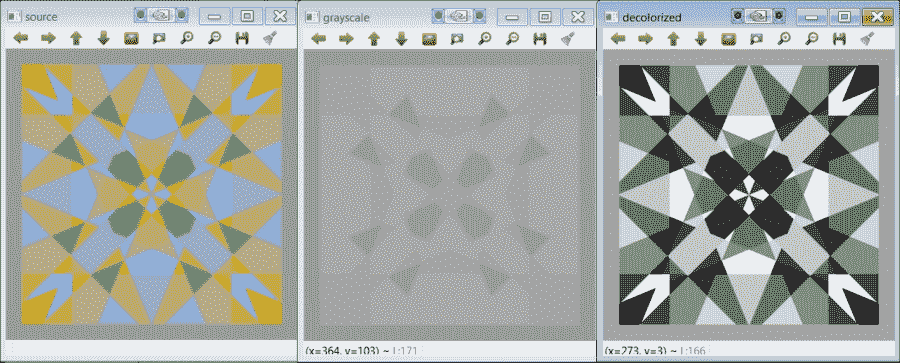
脱色示例输出
这个例子很简单。 读取图像并显示标准灰度转换的结果后,它使用decolor函数执行脱色。 所使用的图像(color_image_3.png文件)包含在 opencv_extra 存储库中,位于这个页面。
注意
该示例中使用的图像实际上是一个极端的情况。 选择其颜色是为了使标准灰度输出相当均匀。
非真实感渲染
作为photo模块的的一部分,提供了四个函数,这些函数可以转换输入图像,从而产生不真实但仍具有艺术感的输出。 这些函数非常易于使用,OpenCV(npr_demo)中包含一个很好的示例。 为了说明的目的,在这里我们为您提供一个表格,让您掌握每个函数的效果。 看一下下面的fruits.jpg输入图像,包含在 OpenCV 中:

输入参考图像
效果是:
| 函数 | 影响 |
|---|---|
edgePreservingFilter | 平滑是一种方便且经常使用的过滤器。 此函数在保留对象边缘细节的同时执行平滑处理。 |
 | |
detailEnhance | 增强图像中的细节 |
 | |
pencilSketch | 输入图像的铅笔状线条图版本 |
 | |
stylization | 水彩效果 |
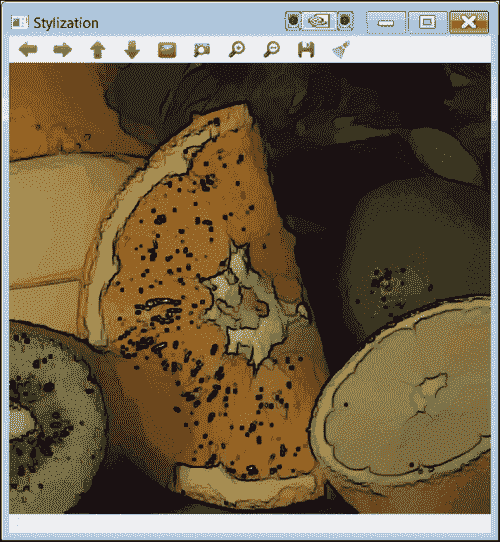 |
总结
在本章中,您学习了什么是计算摄影以及 OpenCV 3 中可用的相关功能。我们解释了photo模块中最重要的函数,但请注意,在此模块中还考虑了该模块的其他功能(修复和降噪) 前几章。 计算摄影是一个快速发展的领域,与计算机图形学有着紧密的联系。 因此,预计 OpenCV 的此模块将在将来的版本中增加。
下一章将讨论我们尚未考虑的重要方面:时间。 解释的许多功能都需要花费大量时间来计算结果。 下一章将向您展示如何使用现代硬件进行处理。
七、加速图像处理
本章使用通用图形处理单元(GPGPU)或简称为 GPU 进行并行处理来加速图像处理任务。 GPU 本质上是专用于图形处理或浮点运算的协处理器,旨在提高视频游戏和交互式 3D 图形等应用的性能。 在 GPU 中执行图形处理时,CPU 可以专用于其他计算(例如游戏中的人工智能部分)。 每个 GPU 都配备了数百个简单的处理内核,这些内核可对(通常)浮点数的数百个“简单”数学运算进行大规模并行执行。
CPU 似乎已达到其速度和热功率极限。 用多个 CPU 构建计算机已成为一个复杂的问题。 这就是 GPU 发挥作用的地方。 GPU 处理是一种新的计算范例,它使用 GPU 来提高计算性能。 GPU 最初实现了某些称为图形基元的并行操作,这些并行操作已针对图形处理进行了优化。 抗锯齿是 3D 图形处理最常见的原语之一,它使图形的边缘具有更逼真的外观。 其他图元是矩形,三角形,圆形和弧形的图形。 GPU 当前包含数百个通用处理功能,它们的功能远远超过渲染图形。 特别是,它们在可以并行执行的任务中非常有价值,许多计算机视觉算法就是这种情况。
OpenCV 库包括对 OpenCL 和 CUDA GPU 架构的支持。 CUDA 实现了许多算法。 但是,它仅适用于 NVIDIA 图形卡。 CUDA 是由 NVIDIA 创建并由其产生的 GPU 实现的并行计算平台和编程模型。 本章重点介绍 OpenCL 架构,因为它受到更多设备的支持,甚至包括在某些 NVIDIA 图形卡中。
开放计算语言(OpenCL)是框架,可编写可在连接到主机处理器(CPU)的 CPU 或 GPU 上执行的程序。 它定义了一种类似于 C 的语言来编写称为内核的函数,这些函数在计算设备上执行。 使用 OpenCL,内核可以在与 CPU 或 GPU 并行的所有或许多单个处理元素(PE)上运行。
此外,OpenCL 定义了应用编程接口(API),该接口允许在主机(CPU)上运行的程序在计算机设备上启动内核并管理它们的设备存储器,(至少在概念上)与主机存储器分开。 OpenCL 程序旨在在运行时进行编译,以便使用 OpenCL 的应用可在各种主机设备的实现之间移植。 OpenCL 还是非盈利技术联盟 Khronos Group 维护的开放标准。
OpenCV 包含一组类和函数,这些类和函数使用 OpenCL 来实现和加速 OpenCV 功能。 OpenCV 当前提供一个透明的 API,该 API 可以将其原始 API 与 OpenCL 加速的编程统一起来。 因此,您只需要编写一次代码。 有一个新的统一数据结构(UMat),在需要且可能时处理向 GPU 的数据传输。
OpenCV 中对 OpenCL 的支持是为了易于使用而设计的,不需要任何 OpenCL 知识。 在最低程度上,它可以看作是一组加速,在使用现代 CPU 和 GPU 设备时可以利用强大的计算能力。
要正确运行 OpenCL 程序,OpenCL 运行时应由设备供应商提供,通常以设备驱动程序的形式提供。 另外,要将 OpenCV 与 OpenCL 一起使用,需要兼容的 SDK。 当前,有五个可用的 OpenCL SDK:
- AMD APP SDK:此 SDK 在 CPU 和 GPU(例如 X86 + SSE2(或更高)CPU 和 AMD Fusion,AMD Radeon,AMD Mobility 和 ATI FirePro GPU)上支持 OpenCL。
- Intel SDK:此 SDK 在 Intel Core 处理器和 Intel HD GPU(例如 Intel + SSE4.1,SSE4.2 或 AVX,Intel Core i7,i5 和 i3( 第 1 代,第 2 代和第 3 代),Intel HD Graphics,Intel Core 2 Solo(Duo Quad 和 Extreme)和 Intel Xeon CPU。
- IBM OpenCL 开发套件:此 SDK 在 AMD 服务器(例如 IBM Power,IBM PERCS 和 IBM BladeCenter)上支持 OpenCL。
- IBM OpenCL 通用运行时:此 SDK 在 CPU 和 GPU(例如 X86 + SSE2(或更高版本) CPU 和 AMD Fusion and Raedon,NVIDIA Ion,NVIDIA GeForce 和 NVIDIA)上支持 OpenCV Quadro GPU。
- Nvidia OpenCL 驱动程序和工具:此 SDK 在某些 Nvidia 图形设备(例如 NVIDIA Tesla,NVIDIA GeForce,NVIDIA Ion 和 NVIDIA Quadro GPU)上支持 OpenCL。
安装了 OpenCL 的 OpenCV
第 1 章,“处理图像和视频文件”中已经介绍了安装步骤,还需要一些其他步骤来包含 OpenCL。 下节介绍了新需要的软件。
在 Windows 上使用 OpenCL 编译和安装 OpenCV 有一些新要求:
-
支持 OpenCL 的 GPU 或 CPU:这是最重要的要求。 请注意,OpenCL 支持许多计算设备,但不是全部。 您可以检查图形卡或处理器是否与 OpenCL 兼容。 本章将用于 AMD FirePro W5000 GPU 的 AMD APP SDK 用于执行示例。
注意
-
编译器:具有 OpenCL 的 OpenCV 与 Microsoft 和 MinGW 编译器兼容。 可以安装免费的 Visual Studio Express 版本。 但是,如果选择 Microsoft 编译 OpenCV,则建议至少使用 Visual Studio 2012。 但是,本章使用 MinGW 编译器。
-
AMD APP SDK:此 SDK 是一组高级软件技术,使我们能够使用兼容的计算设备来执行和加速除图形之外的许多应用。 该 SDK 可在以下位置获得。本章使用 SDK 的 2.9 版(适用于 64 位 Windows)。 您可以在以下屏幕截图中看到安装进度。
注意
如果此步骤失败,则可能需要更新图形卡的控制器。 可在这个页面上获得 AMD 控制器。
安装 AMD APP SDK
-
OpenCL BLAS:基本线性代数子例程(BLAS)是一组开源数学库,用于在 AMD 设备上进行并行处理。 可以从这个页面下载。 本章使用 Windows 32/64 位的 1.1 BLAS 版本,并且可以在以下屏幕截图(左侧)中看到安装进度。
-
OpenCL FFT:快速傅立叶变换(FFT)是许多图像处理算法需要的非常有用的功能。 因此,此功能可在 AMD 设备上实现并行处理。 可以从与前面相同的 URL 下载。 本章使用 Windows 32/64 位的 1.1 FFT 版本,并且可以在以下屏幕截图(右侧)中看到安装进度:
为 OpenCL 安装 BLAS 和 FFT
-
用于 C++ 编译器的 Qt 库:在本章中,使用 Qt 库的 MinGW 二进制文件通过 OpenCL 编译 OpenCV。 另一种选择是安装最新版本的 Qt 并使用 Visual C++ 编译器。 您可以选择 Qt 版本和使用的编译器。 通过位于
C:\Qt\Qt5.3.1的MaintenanceTool.exe应用,包管理器可用于下载其他 Qt 版本。 本章使用 Qt(5.3.1)和 MinGW(4.8.2)32 位来使用 OpenCL 编译 OpenCV。
当满足之前的要求时,您可以使用 CMake 生成新的构建配置。 该过程与第一章中介绍的典型安装在某些方面有所不同。 差异在此列表中说明:
-
为项目选择生成器时,可以选择与计算机中已安装环境相对应的编译器版本。 本章使用 MinGW 使用 OpenCL 编译 OpenCV,然后选择
MinGW Makefiles选项,并指定本机编译器。 以下屏幕截图显示了此选择: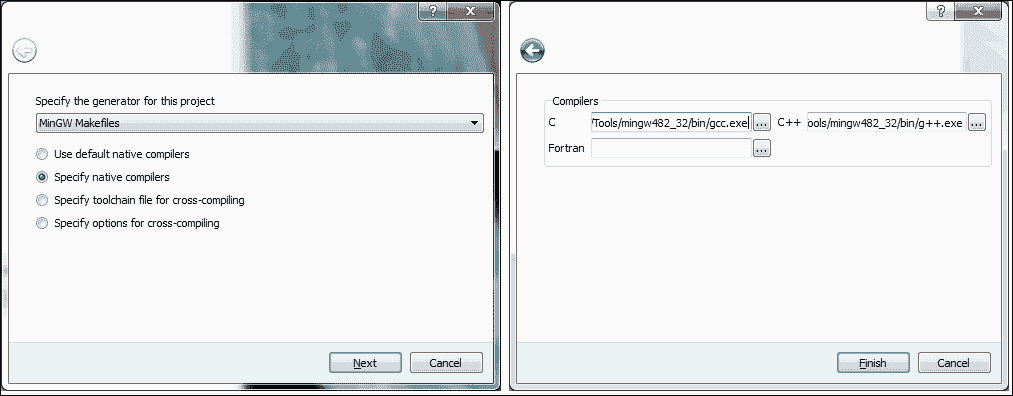
CMake 选择生成器项目
-
以下屏幕截图中显示的选项是构建带有 OpenCL 项目的 OpenCV 所必需的。 必须启用
WITH_OPENCL,WITH_OPENCLAMDBLAS和WITH_OPENCLAMDFFT选项。 必须在CLAMDBLAS_INCLUDE_DIR,CLAMDBLAS_ROOT_DIR,CLAMDFFT_INCLUDE_DIR和CLAMDFFT_ROOT_DIR上引入 BLAS 和 FFT 路径。 此外,如第 1 章“处理图像和视频文件”中所示,您将需要启用WITH_QT并禁用WITH_IPP选项。 也建议启用BUILD_EXAMPLES。 以下屏幕截图显示了在构建配置中选择的主要选项: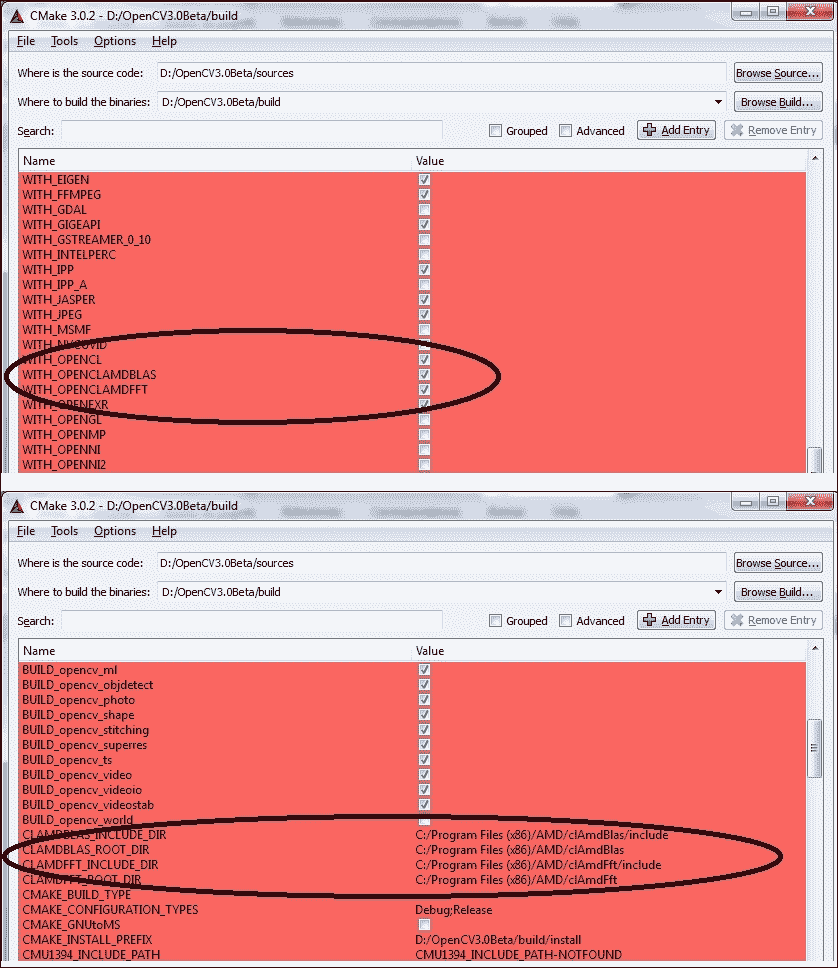
CMake 选择主要选项
最后,要使用 OpenCL 项目构建 OpenCV,必须编译先前生成的 CMake 项目。 该项目是为 MinGW 生成的,因此,需要 MinGW 编译器来构建此项目。 首先,使用 Windows 控制台选择[opencv_build]/文件夹,然后执行以下操作:
./mingw32-make.exe -j 4 install
-j 4参数是我们要用于编译并行化的系统核心 CPU 的数量。
现在可以使用带有 OpenCL 项目的 OpenCV。 新二进制文件的路径必须添加到系统路径,在这种情况下为[opencv_build]/install/x64/mingw/bin。
注意
不要忘记从路径环境变量中删除旧的 OpenCV 二进制文件。
使用 OpenCL 安装 OpenCV 的快速方法
可以通过以下步骤总结安装过程:
- 下载并安装 AMD APP SDK,该软件可从这个页面获得。
- 下载并安装 BLAS 和 FFT AMD,它们可从这个页面。
- 使用 CMake 配置 OpenCV 构建。 启用
WITH_OPENCL,WITH_OPENCLAMDBLAS,WITH_QT和Build_EXAMPLESWITH_OPENCLAMDFFT选项。 禁用WITH_IPP选项。 最后,介绍CLAMDBLAS_INCLUDE_DIR,CLAMDBLAS_ROOT_DIR,CLAMDFFT_INCLUDE_DIR和CLAMDFFT_ROOT_DIR上的 BLAS 和 FFT 路径。 - 用
mingw32-make.exe编译 OpenCV 项目。 - 最后,修改路径环境变量以更新 OpenCV
bin目录(例如[opencv_build]/install/x64/mingw/bin)。
检查 GPU 使用情况
在 Windows 平台上使用 GPU 时,没有应用可以测量其使用情况。 使用 GPU 的原因有两个:
- 可以知道您是否正确使用了 GPU
- 您可以监控 GPU 使用率
为此,市场上有一些应用。 本章使用 AMD 系统监视器检查 GPU 的使用情况。 此应用监视 CPU,内存 RAM 和 GPU 的使用情况。 请参考以下屏幕截图:
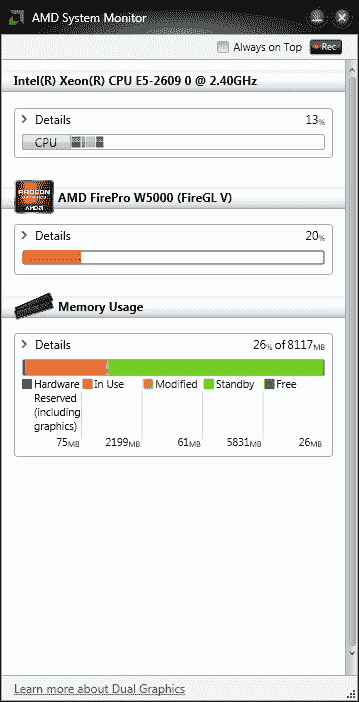
AMD 系统监视器可监视 CPU,GPU 和内存 RAM 的使用情况
注意
可以从这个页面下载 Microsoft System Monitor (32 或 64 位)。
加速您自己的功能
在本节中,有使用 OpenCV 和 OpenCL 的三个示例。 第一个示例使您可以检查已安装的 SDK 是否可用,并获取有关支持 OpenCL 的计算设备的有用信息。 第二个示例分别显示使用 CPU 和 GPU 编程的同一程序的两个版本。 最后一个示例是检测和标记人脸的完整程序。 另外,执行计算比较。
检查您的 OpenCL
以下是一个简单的程序,用于检查您的 SDK 和可用的计算设备。 该示例是,称为checkOpenCL。它允许您使用 OpenCV 的 OCL 模块显示计算机设备:
#include <opencv2/opencv.hpp>
#include <opencv2/core/ocl.hpp>
using namespace std;
using namespace cv;
using namespace cv::ocl;
int main()
{
vector<ocl::PlatformInfo> info;
getPlatfomsInfo(info);
PlatformInfo sdk = info.at(0);
if (sdk.deviceNumber()<1)
return -1;
cout << "******SDK*******" << endl;
cout << "Name: " <<sdk.name()<< endl;
cout << "Vendor: " <<sdk.vendor()<< endl;
cout << "Version: " <<sdk.version()<< endl;
cout << "Number of devices: " <<sdk.deviceNumber()<< endl;
for (int i=0; i<sdk.deviceNumber(); i++){
Device device;
sdk.getDevice(device, i);
cout << "\n\n*********************\n Device " << i+1 << endl;
cout << "Vendor ID: " <<device.vendorID()<< endl;
cout << "Vendor name: " <<device.vendorName()<< endl;
cout << "Name: " <<device.name()<< endl;
cout << "Driver version: " <<device.driverVersion()<< endl;
if (device.isAMD()) cout << "Is an AMD device" << endl;
if (device.isIntel()) cout << "Is a Intel device" << endl;
cout << "Global Memory size: " <<device.globalMemSize()<< endl;
cout << "Memory cache size: " <<device.globalMemCacheSize()<< endl;
cout << "Memory cache type: " <<device.globalMemCacheType()<< endl;
cout << "Local Memory size: " <<device.localMemSize()<< endl;
cout << "Local Memory type: " <<device.localMemType()<< endl;
cout << "Max Clock frequency: " <<device.maxClockFrequency()<< endl;
}
return 0;
}
代码说明
本示例显示安装的 SDK 和与 OpenCL 兼容的可用计算设备。 首先,包含core/ocl.hpp标头,并声明cv::ocl命名空间。
使用getPlatfomsInfo(info)方法获取有关计算机中可用 SDK 的信息。 该信息存储在vector<ocl::PlatformInfo> info向量中,并通过PlatformInfo sdk = info.at(0)选择。 然后,将显示有关您的 SDK 的主要信息,例如名称,供应商,SDK 版本以及与 OpenCL 兼容的计算设备的数量。
最后,对于每个兼容设备,其信息都是通过sdk.getDevice(device, i)方法获得的。 现在可以显示有关每个计算设备的不同信息,例如供应商 ID,供应商名称,驱动程序版本,全局内存大小,内存缓存大小等。
下面的屏幕截图显示了该示例对所用计算机的结果:
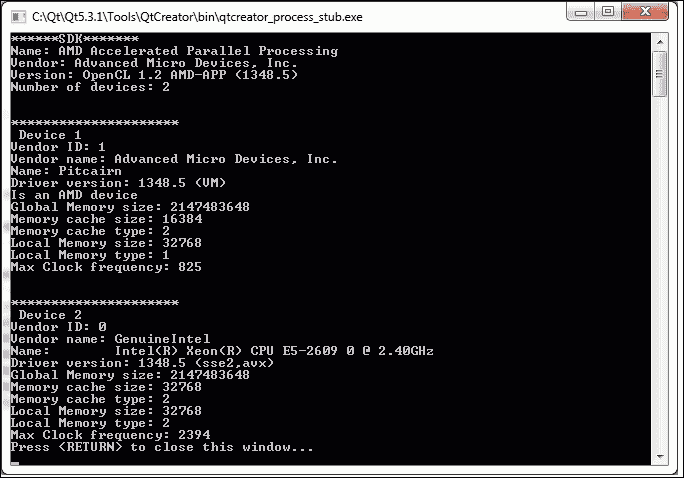
有关使用的 SDK 和兼容的计算设备的信息
您的第一个基于 GPU 的程序
在下面的代码中,显示了同一程序的两个版本:一个仅使用 CPU(本机)执行计算,另一个使用 GPU(带有 OpenCL)。 这两个示例分别称为calculateEdgesCPU和calculateEdgesGPU,使您可以观察 CPU 和 GPU 版本之间的差异。
首先显示计算边缘 CPU 示例:
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(int argc, char * argv[])
{
if (argc < 2)
{
cout << "./calculateEdgesCPU <image>" << endl;
return -1;
}
Mat cpuFrame = imread(argv[1]);
Mat cpuBW, cpuBlur, cpuEdges;
namedWindow("Canny Edges CPU",1);
cvtColor(cpuFrame, cpuBW, COLOR_BGR2GRAY);
GaussianBlur(cpuBW, cpuBlur, Size(1,1), 1.5, 1.5);
Canny(cpuBlur, cpuEdges, 50, 100, 3);
imshow("Canny Edges CPU", cpuEdges);
waitKey();
return 0;
}
现在,显示计算边缘 GPU 示例:
#include "opencv2/opencv.hpp"
#include "opencv2/core/ocl.hpp"
using namespace std;
using namespace cv;
using namespace cv::ocl;
int main(int argc, char * argv[])
{
if (argc < 2)
{
cout << "./calculateEdgesGPU <image>" << endl;
return -1;
}
setUseOpenCL(true);
Mat cpuFrame = imread(argv[1]);
UMat gpuFrame, gpuBW, gpuBlur, gpuEdges;
cpuFrame.copyTo(gpuFrame);
namedWindow("Canny Edges GPU",1);
cvtColor(gpuFrame, gpuBW, COLOR_BGR2GRAY);
GaussianBlur(gpuBW, gpuBlur, Size(1,1), 1.5, 1.5);
Canny(gpuBlur, gpuEdges, 50, 100, 3);
imshow("Canny Edges GPU", gpuEdges);
waitKey();
return 0;
}
代码说明
这两个示例获得相同的结果,如以下屏幕截图所示。 他们从标准命令行输入参数读取图像。 然后,将图像转换为灰度,并应用高斯模糊和 Canny 过滤器功能。
在第二个示例中,使用 GPU 需要一些区别。 首先,必须使用setUseOpenCL(true)方法激活 OpenCL。 其次,统一矩阵(UMat)用于在 GPU(UMat gpuFrame, gpuBW, gpuBlur, gpuEdges)中分配内存。 第三,使用cpuFrame.copyTo(gpuFrame)方法将输入图像从 RAM 复制到 GPU 内存。 现在,使用这些功能时,如果它们具有 OpenCL 实现,则这些功能将在 GPU 上执行。 如果其中一些功能没有 OpenCL 实现,则正常功能将在 CPU 上执行。 在此示例中,使用 GPU 编程(第二示例)的时间要好 10 倍:

前两个示例的结果
实时
GPU 处理的主要优点之一是以更快的方式执行计算。 速度的提高使您可以在实时应用中执行繁重的计算算法,例如立体视觉,行人检测,光流或人脸检测。 以下detectFaces示例向您展示了一种用于检测摄像机面部的应用。 此示例还允许您在 CPU 或 GPU 处理之间进行选择,以比较计算时间。
在 OpenCV 示例([opencv_source_code]/samples/cpp/facedetect.cpp)中,可以找到相关的人脸检测器示例。 对于以下detectFaces示例,detectFace.pro项目需要以下库:-lopencv_core300,-opencv_imgproc300,-lopencv_highgui300,-lopencv_videoio300和lopencv_objdetct300。
detectFaces示例使用 OpenCV 的ocl模块:
#include <opencv2/core/core.hpp>
#include <opencv2/core/ocl.hpp>
#include <opencv2/objdetect.hpp>
#include <opencv2/videoio.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
#include <stdio.h>
using namespace std;
using namespace cv;
using namespace cv::ocl;
int main(int argc, char * argv[])
{
// 1- Set the initial parameters
// Vector to store the faces
vector<Rect> faces;
CascadeClassifier face_cascade;
String face_cascade_name = argv[2];
int face_size = 30;
double scale_factor = 1.1;
int min_neighbours = 2;
VideoCapture cap(0);
UMat frame, frameGray;
bool finish = false;
// 2- Load the file xml to use the classifier
if (!face_cascade.load(face_cascade_name))
{
cout << "Cannot load the face xml!" << endl;
return -1;
}
namedWindow("Video Capture");
// 3- Select between the CPU or GPU processing
if (argc < 2)
{
cout << "./detectFaces [CPU/GPU | C/G]" << endl;
cout << "Trying to use GPU..." << endl;
setUseOpenCL(true);
}
else
{
cout << "./detectFaces trying to use " << argv[1] << endl;
if(argv[1][0] == 'C')
// Trying to use the CPU processing
setUseOpenCL(false);
else
// Trying to use the GPU processing
setUseOpenCL(true);
}
Rect r;
double start_time, finish_time, start_total_time, finish_total_time;
int counter = 0;
// 4- Detect the faces for each image capture
start_total_time = getTickCount();
while (!finish)
{
start_time = getTickCount();
cap >> frame;
if (frame.empty())
{
cout << "No capture frame --> finish" << endl;
break;
}
cvtColor(frame, frameGray, COLOR_BGR2GRAY);
equalizeHist(frameGray,frameGray);
// Detect the faces
face_cascade.detectMultiScale(frameGray, faces, scale_factor, min_neighbours, 0|CASCADE_SCALE_IMAGE, Size(face_size,face_size));
// For each detected face
for (int f = 0; f <faces.size(); f++)
{
r = faces[f];
// Draw a rectangle over the face
rectangle(frame, Point(r.x, r.y), Point(r.x + r.width, r.y + r.height), Scalar(0,255,0), 3);
}
// Show the results
imshow("Video Capture",frame);
// Calculate the time processing
finish_time = getTickCount();
cout << "Time per frame: " << (finish_time - start_time)/getTickFrequency() << " secs" << endl;
counter++;
// Press Esc key to finish
if(waitKey(1) == 27) finish = true;
}
finish_total_time = getTickCount();
cout << "Average time per frame: " << ((finish_total_time - start_total_time)/getTickFrequency())/counter << " secs" << endl;
return 0;
}
代码说明
第一步,设置初始参数,例如使用分类器检测面部的 xml 文件(String face_cascade_name argv[2]),每个检测到的面部的最小尺寸(face_size=30),比例因子(scale_factor = 1.1 ),以及在真正例和假正面检测之间进行权衡的最小邻居数(min_neighbours = 2)。 您还可以看到 CPU 和 GPU 源代码之间更重要的区别。 您只需要使用统一矩阵(UMat frame, frameGray)。
注意
[opencv_source_code]/data/haarcascades/文件夹中还有其他可用的 xml 文件,用于检测不同的身体部位,例如眼睛,下半身,微笑等。
第二步,使用前面的 xml 文件创建检测器以检测面部。 该检测器基于基于 Haar 特征的分类器,这是 Paul Viola 和 Michael Jones 提出的一种有效的对象检测方法。 该分类器具有高精度的人脸检测。 此步骤使用face_cascade.load( face_cascade_name)方法加载 xml 文件。
注意
您可以在这个页面上找到有关 Paul Viola 和 Michael Jones 方法的更多详细信息。
第三步,您可以在 CPU 或 GPU 处理(分别为setUseOpenCL(false)或setUseOpenCL(true))之间进行选择。 本示例使用标准命令行输入参数(argv[1])进行选择。 用户可以从 Windows 控制台执行以下操作,以分别在 CPU 或 GPU 处理以及分类器路径之间进行选择:
<bin_dir>/detectFaces CPU pathClassifier
<bin_dir>/detectFaces GPU pathClassifier
如果用户未引入输入参数,则使用 GPU 处理。
第四步为从摄像机捕获的每个图像检测面部。 在此之前,每个捕获的图像都将转换为灰度(cvtColor(frame, frameGray, COLOR_BGR2GRAY))并对其直方图进行均衡(equalizeHist(frameGray, frameGray))。 然后,使用创建的人脸检测器,使用face_cascade.detectMultiScale(frameGray, faces, scale_factor, min_neighbours, 0|CASCADE_SCALE_IMAGE, Size(face_size,face_size))多尺度检测方法在当前帧中搜索不同的面部。 最后,在每个检测到的面部上绘制一个绿色矩形,然后将其显示。 以下屏幕截图显示了此示例运行的屏幕截图:
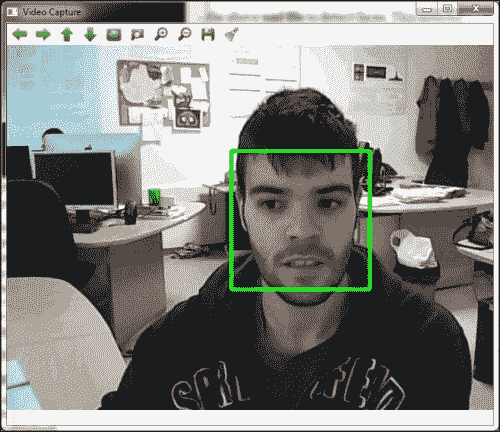
前面的例子检测人脸
性能
在前面的示例中,计算了计算时间以比较 CPU 和 GPU 处理。 获得每帧的平均处理时间。
选择 GPU 编程的一大优势是性能。 因此,前面的示例计算时间测量值,以比较相对于 CPU 版本获得的加速比。 时间使用getTickCount()方法存储在程序的开头。 之后,在程序结束时,再次使用相同的函数来估计时间。 存储计数器以也知道迭代次数。 最后,计算每帧的平均处理时间。 前面的示例使用 GPU 时每帧的平均处理时间为 0.057 秒(或 17.5 FPS),而使用 CPU 的相同示例时,每帧的平均处理时间为每帧 0.335 秒(或 2.9 FPS)。 总之,速度增量为6x。 此增量非常重要,尤其是当您只需要更改几行代码时。 但是,有可能实现更高的速度增加速率,这与问题甚至内核的设计有关。
总结
在本章中,您学习了如何在计算机上安装带有 OpenCL 的 OpenCV 以及如何使用与 OpenCL 兼容的最新 OpenCV 版本的计算机设备开发应用。
第一部分说明 OpenCL 是什么以及可用的 SDK。 请记住,取决于您的计算设备,您将需要特定的 SDK 才能与 OpenCL 一起正常使用。 在第二部分中,说明了使用 OpenCL 安装 OpenCV 的安装过程,并使用了 AMD APP SDK。 在上一节中,有三个使用 GPU 编程的示例(第二个示例也具有 CPU 版本以便进行比较)。 此外,在最后一节中,在 CPU 和 GPU 处理之间进行了计算比较,显示 GPU 比 CPU 版本快六倍。