目录
开发环境
数据描述
功能需求
数据准备
统计计算
Hbase
Hive
分析数据
开发环境
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:spark-shell
数据描述
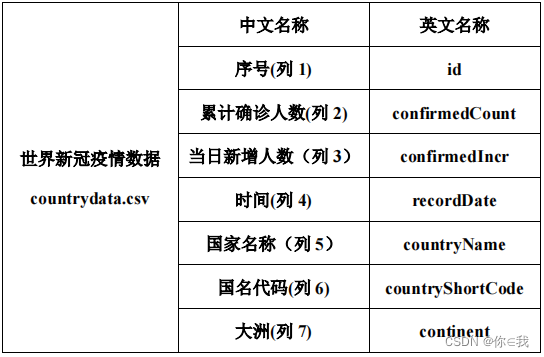
countrydata.csv 是世界新冠疫情数,数据中记录了从疫情开始至 7 月 2 日,以国家为单位的每日新冠疫情感染人数的数据统计。字段说明如下:
功能需求
数据准备
请在 HDFS 中创建目录/app/data/exam,并将 countrydata.csv 传到该目录。
hdfs dfs -mkdir -p /app/data/exam
hdfs dfs -put ./countrydata.csv /app/data/exam
统计计算
在 Spark-Shell 中,加载 HDFS 文件系统 countrydata.csv 文件,并使用 RDD 完成以下统计计算。
scala> val fileRdd = sc.textFile("/app/data/exam/countrydata.csv")
scala> val yqRdd = fileRdd.map(x=>x.split(","))①统计每个国家在数据截止统计时的累计确诊人数。
方法一:
scala> yqRdd.map(x=>(x(4),x(1).toInt)).reduceByKey((v1,v2)=>math.max(v1,v2))
.foreach(println)方法二:
scala>yqRdd.map(x=>(x(4),x(3),x(1).toInt)).groupBy(x=>x._1)
.mapValues(x=>x.toList.sortBy(it=>(0-it._2.toLong)).max)
.map(x=>(x._1,x._2._3)).foreach(println)方法三:
yqRdd.map(x=>(x(4),x(1).toInt)).reduceByKey((v1,v2)=>{if(v1>v2) v1 else v2})
.foreach(println)②统计全世界在数据截止统计时的总感染人数。
方法一:
scala> yqRdd.map(x=>(x(4),x(1).toInt)).reduceByKey((v1,v2)=>math
.max(v1,v2)).map(x=>("all world",x._2)).reduceByKey(_+_).foreach(println)
(all world,10785407)方法二:
scala> yqRdd.map(x=>(x(4),x(1).toInt)).reduceByKey((v1,v2)=>math.max(v1,v2))
.reduce((x,y)=>("all world", x._2+y._2))
res16: (String, Int) = (all world,10785407)③统计每个大洲中每日新增确诊人数最多的国家及确诊人数,并输出 20200408 这一天各大洲当日新增确诊人数最多的国家及确诊人数。
scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4))))
.reduceByKey((x,y)=>if(x._2>y._2) x else y)
.filter(x=>x._1._2=="20200408").map(x=>(x._1._1,x._2._2,x._2._3,x._1._2))
.foreach(println)④统计每个大洲中每日累计确诊人数最多的国家及确诊人数,并输出 20200607 这一天各大洲当日累计确诊人数最多的国家及确诊人数。
scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4))))
.reduceByKey((x,y)=>if(x._1>y._1) x else y)
.filter(x=>x._1._2=="20200607").map(x=>(x._1._1,x._2._2,x._2._3,x._1._2))
.foreach(println)⑤统计每个大洲每月累计确诊人数,显示 202006 这个月每个大洲的累计确诊人数。
scala> yqRdd.map(x=>((x(3).substring(0,6),x(6)),x(2).toInt)).reduceByKey(_+_)
.filter(x=>x._1._1=="202006").foreach(println)
Hbase
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 covid19_world 表,使用大洲和统计日期的组合作为 RowKey(如“亚洲 20200520”),该表下有 1 个列族 record。record 列族用于统计疫情数据(每个大洲当日新增确诊人数最多的国家record:maxIncreaseCountry 及其新增确诊人数 record:maxIncreaseCount)
hbase(main):001:0> create 'exam:covid19_world','record'Hive
请在 Hive 中创建数据库 exam,在该数据库中创建外部表 ex_exam_record 指向 /app/data/exam 下的疫情数据 ;创建外部表 ex_exam_covid19_record 映射至 HBase 中的 exam:covid19_world 表的 record 列族
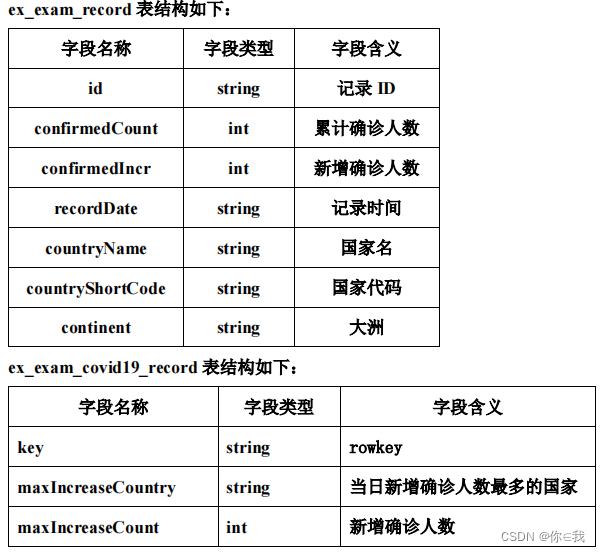
ex_exam_record 表
create external table ex_exam_record
(
id string,
confirmedCount int,
confirmedIncr int,
recordDate string,
countryName string,
countryShortCode string,
continent string
)
row format delimited fields terminated by ","
stored as textfile location "/app/data/exam";ex_exam_covid19_record 表
create external table ex_exam_covid19_record
(
key string,
maxIncreaseCountry string,
maxIncreaseCount int
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" =
":key,record:maxIncreaseCountry,record:maxIncreaseCount")
tblproperties ("hbase.table.name" = "exam:covid19_world");分析数据
使用 ex_exam_record 表中的数据
①统计每个大洲中每日新增确诊人数最多的国家,将 continent 和 recordDate 合并成 rowkey,并保存到 ex_exam_covid19_record 表中。
insert into ex_exam_covid19_record
select t.rowkey, t.countryName, t.confirmedIncr
from (select concat(continent, recordDate) rowkey,
countryName,
confirmedIncr,
row_number() over (partition by countryName order by confirmedIncr desc ) max
from ex_exam_record
group by concat(continent, recordDate), countryName, confirmedIncr) t
where t.max = 1;②完成统计后,在 HBase Shell 中遍历 exam:covid19_world 表中的前 20 条数据。
scan 'exam:covid19_world',{limit=>20}








![ChatGPT4写贪吃蛇游戏(Notion)[pygame的学习]](https://img-blog.csdnimg.cn/ca06a0cbd8214b4c83871f0e1999513c.png)