目录
0 环境准备
1 套路
2 并行执行内核设置
3 示例代码simpleTexture3D
4 参考链接
0 环境准备
1 套路
CUDA 编程模型是一个异构模型,其中同时使用 CPU 和 GPU。在 CUDA 中,主机是指 CPU 及其内存,而设备是指 GPU 及其内存。在主机上运行的代码可以管理主机和设备上的内存,还可以启动内核,内核是在设备上执行的功能。这些内核由许多 GPU 线程并行执行。
鉴于 CUDA 编程模型的异构性质,CUDA C 程序的典型操作顺序是:
- 声明并分配主机和设备内存。
- 初始化主机数据。
- 将数据从主机传输到设备。
- 执行一个或多个内核。
- 将结果从设备传输到主机。
2 并行执行内核设置
三重 V 形之间的信息是执行配置,它指示并行执行内核的设备线程数。在 CUDA 中,软件中有一个线程层次结构,它模仿线程处理器在 GPU 上的分组方式。在 CUDA 编程模型中,我们谈到启动带有线程块网格的内核。执行配置中的第一个参数指定网格中的线程块数,第二个参数指定线程块中的线程数。
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);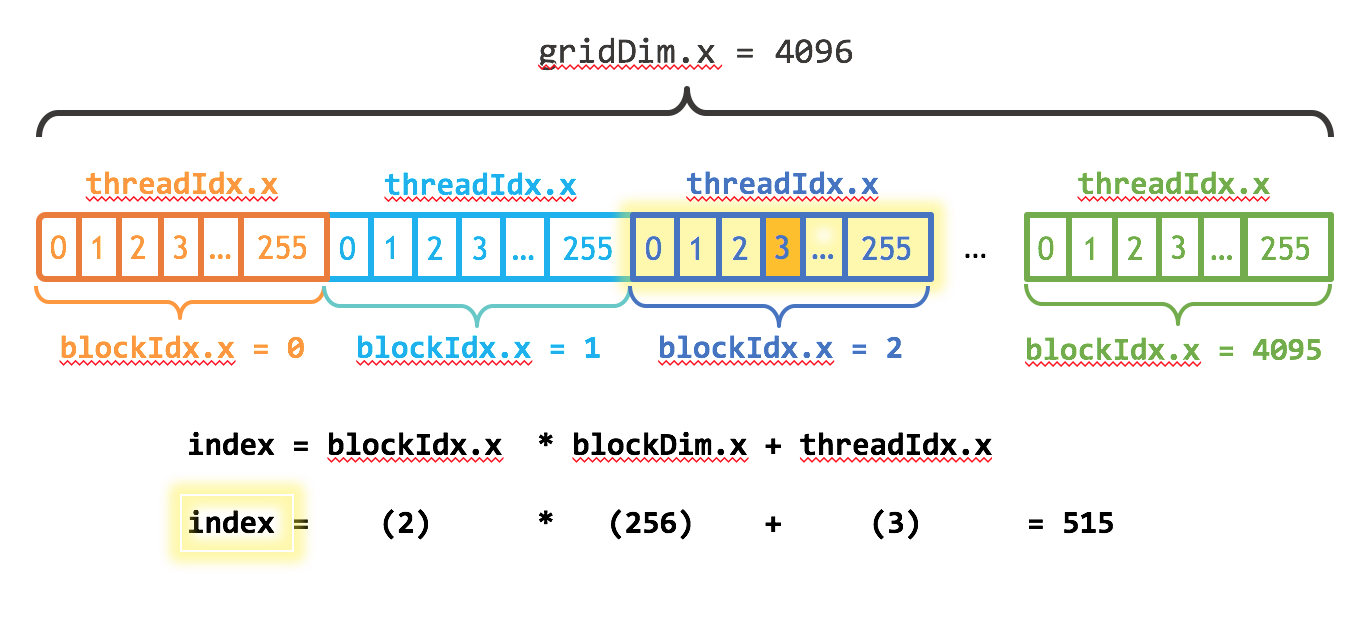
3 示例代码simpleTexture3D
/* Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of NVIDIA CORPORATION nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
* EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
* OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
/*
3D texture sample
This sample loads a 3D volume from disk and displays slices through it
using 3D texture lookups.
*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <helper_gl.h>
#if defined(__APPLE__) || defined(MACOSX)
#pragma clang diagnostic ignored "-Wdeprecated-declarations"
#include <GLUT/glut.h>
#ifndef glutCloseFunc
#define glutCloseFunc glutWMCloseFunc
#endif
#else
#include <GL/freeglut.h>
#endif
// includes, cuda
#include <vector_types.h>
#include <cuda_runtime.h>
#include <cuda_gl_interop.h>
// CUDA utilities and system includes
#include <helper_cuda.h>
#include <helper_functions.h>
#include <vector_types.h>
typedef unsigned int uint;
typedef unsigned char uchar;
#define MAX_EPSILON_ERROR 5.0f
#define THRESHOLD 0.15f
const char *sSDKsample = "simpleTexture3D";
const char *volumeFilename = "Bucky.raw";
const cudaExtent volumeSize = make_cudaExtent(32, 32, 32);
const uint width = 512, height = 512;
const dim3 blockSize(16, 16, 1);
const dim3 gridSize(width / blockSize.x, height / blockSize.y);
float w = 0.5; // texture coordinate in z
GLuint pbo; // OpenGL pixel buffer object
struct cudaGraphicsResource
*cuda_pbo_resource; // CUDA Graphics Resource (to transfer PBO)
bool linearFiltering = true;
bool animate = true;
StopWatchInterface *timer = NULL;
uint *d_output = NULL;
// Auto-Verification Code
const int frameCheckNumber = 4;
int fpsCount = 0; // FPS count for averaging
int fpsLimit = 1; // FPS limit for sampling
int g_Index = 0;
unsigned int frameCount = 0;
unsigned int g_TotalErrors = 0;
volatile int g_GraphicsMapFlag = 0;
int *pArgc = NULL;
char **pArgv = NULL;
#ifndef MAX
#define MAX(a, b) ((a > b) ? a : b)
#endif
extern "C" void cleanup();
extern "C" void setTextureFilterMode(bool bLinearFilter);
extern "C" void initCuda(const uchar *h_volume, cudaExtent volumeSize);
extern "C" void render_kernel(dim3 gridSize, dim3 blockSize, uint *d_output,
uint imageW, uint imageH, float w);
extern void cleanupCuda();
void loadVolumeData(char *exec_path);
void computeFPS() {
frameCount++;
fpsCount++;
if (fpsCount == fpsLimit) {
char fps[256];
float ifps = 1.f / (sdkGetAverageTimerValue(&timer) / 1000.f);
sprintf(fps, "%s: %3.1f fps", sSDKsample, ifps);
glutSetWindowTitle(fps);
fpsCount = 0;
fpsLimit = ftoi(MAX(1.0f, ifps));
sdkResetTimer(&timer);
}
}
// render image using CUDA
void render() {
// map PBO to get CUDA device pointer
g_GraphicsMapFlag++;
checkCudaErrors(cudaGraphicsMapResources(1, &cuda_pbo_resource, 0));
size_t num_bytes;
checkCudaErrors(cudaGraphicsResourceGetMappedPointer(
(void **)&d_output, &num_bytes, cuda_pbo_resource));
// printf("CUDA mapped PBO: May access %ld bytes\n", num_bytes);
// call CUDA kernel, writing results to PBO
render_kernel(gridSize, blockSize, d_output, width, height, w);
getLastCudaError("render_kernel failed");
if (g_GraphicsMapFlag) {
checkCudaErrors(cudaGraphicsUnmapResources(1, &cuda_pbo_resource, 0));
g_GraphicsMapFlag--;
}
}
// display results using OpenGL (called by GLUT)
void display() {
sdkStartTimer(&timer);
render();
// display results
glClear(GL_COLOR_BUFFER_BIT);
// draw image from PBO
glDisable(GL_DEPTH_TEST);
glRasterPos2i(0, 0);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER_ARB, pbo);
glDrawPixels(width, height, GL_RGBA, GL_UNSIGNED_BYTE, 0);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER_ARB, 0);
glutSwapBuffers();
glutReportErrors();
sdkStopTimer(&timer);
computeFPS();
}
void idle() {
if (animate) {
w += 0.01f;
glutPostRedisplay();
}
}
void keyboard(unsigned char key, int x, int y) {
switch (key) {
case 27:
#if defined(__APPLE__) || defined(MACOSX)
exit(EXIT_SUCCESS);
glutDestroyWindow(glutGetWindow());
return;
#else
glutDestroyWindow(glutGetWindow());
return;
#endif
case '=':
case '+':
w += 0.01f;
break;
case '-':
w -= 0.01f;
break;
case 'f':
linearFiltering = !linearFiltering;
setTextureFilterMode(linearFiltering);
break;
case ' ':
animate = !animate;
break;
default:
break;
}
glutPostRedisplay();
}
void reshape(int x, int y) {
glViewport(0, 0, x, y);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
glOrtho(0.0, 1.0, 0.0, 1.0, 0.0, 1.0);
}
void cleanup() {
sdkDeleteTimer(&timer);
// add extra check to unmap the resource before unregistering it
if (g_GraphicsMapFlag) {
checkCudaErrors(cudaGraphicsUnmapResources(1, &cuda_pbo_resource, 0));
g_GraphicsMapFlag--;
}
// unregister this buffer object from CUDA C
checkCudaErrors(cudaGraphicsUnregisterResource(cuda_pbo_resource));
glDeleteBuffers(1, &pbo);
cleanupCuda();
}
void initGLBuffers() {
// create pixel buffer object
glGenBuffers(1, &pbo);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER_ARB, pbo);
glBufferData(GL_PIXEL_UNPACK_BUFFER_ARB, width * height * sizeof(GLubyte) * 4,
0, GL_STREAM_DRAW_ARB);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER_ARB, 0);
// register this buffer object with CUDA
checkCudaErrors(cudaGraphicsGLRegisterBuffer(
&cuda_pbo_resource, pbo, cudaGraphicsMapFlagsWriteDiscard));
}
// Load raw data from disk
uchar *loadRawFile(const char *filename, size_t size) {
FILE *fp = fopen(filename, "rb");
if (!fp) {
fprintf(stderr, "Error opening file '%s'\n", filename);
return 0;
}
uchar *data = (uchar *)malloc(size);
size_t read = fread(data, 1, size, fp);
fclose(fp);
printf("Read '%s', %zu bytes\n", filename, read);
return data;
}
void initGL(int *argc, char **argv) {
// initialize GLUT callback functions
glutInit(argc, argv);
glutInitDisplayMode(GLUT_RGB | GLUT_DOUBLE);
glutInitWindowSize(width, height);
glutCreateWindow("CUDA 3D texture");
glutDisplayFunc(display);
glutKeyboardFunc(keyboard);
glutReshapeFunc(reshape);
glutIdleFunc(idle);
if (!isGLVersionSupported(2, 0) ||
!areGLExtensionsSupported("GL_ARB_pixel_buffer_object")) {
fprintf(stderr, "Required OpenGL extensions are missing.");
exit(EXIT_FAILURE);
}
}
void runAutoTest(const char *ref_file, char *exec_path) {
checkCudaErrors(
cudaMalloc((void **)&d_output, width * height * sizeof(GLubyte) * 4));
// render the volumeData
render_kernel(gridSize, blockSize, d_output, width, height, w);
checkCudaErrors(cudaDeviceSynchronize());
getLastCudaError("render_kernel failed");
void *h_output = malloc(width * height * sizeof(GLubyte) * 4);
checkCudaErrors(cudaMemcpy(h_output, d_output,
width * height * sizeof(GLubyte) * 4,
cudaMemcpyDeviceToHost));
sdkDumpBin(h_output, width * height * sizeof(GLubyte) * 4,
"simpleTexture3D.bin");
bool bTestResult = sdkCompareBin2BinFloat(
"simpleTexture3D.bin", sdkFindFilePath(ref_file, exec_path),
width * height, MAX_EPSILON_ERROR, THRESHOLD, exec_path);
checkCudaErrors(cudaFree(d_output));
free(h_output);
sdkStopTimer(&timer);
sdkDeleteTimer(&timer);
exit(bTestResult ? EXIT_SUCCESS : EXIT_FAILURE);
}
void loadVolumeData(char *exec_path) {
// load volume data
const char *path = sdkFindFilePath(volumeFilename, exec_path);
if (path == NULL) {
fprintf(stderr, "Error unable to find 3D Volume file: '%s'\n",
volumeFilename);
exit(EXIT_FAILURE);
}
size_t size = volumeSize.width * volumeSize.height * volumeSize.depth;
uchar *h_volume = loadRawFile(path, size);
initCuda(h_volume, volumeSize);
sdkCreateTimer(&timer);
free(h_volume);
}
// Program main
int main(int argc, char **argv) {
pArgc = &argc;
pArgv = argv;
char *ref_file = NULL;
#if defined(__linux__)
setenv("DISPLAY", ":0", 0);
#endif
printf("%s Starting...\n\n", sSDKsample);
if (checkCmdLineFlag(argc, (const char **)argv, "file")) {
fpsLimit = frameCheckNumber;
getCmdLineArgumentString(argc, (const char **)argv, "file", &ref_file);
}
// use command-line specified CUDA device, otherwise use device with highest
// Gflops/s
findCudaDevice(argc, (const char **)argv);
if (ref_file) {
loadVolumeData(argv[0]);
runAutoTest(ref_file, argv[0]);
} else {
initGL(&argc, argv);
// OpenGL buffers
initGLBuffers();
loadVolumeData(argv[0]);
}
printf(
"Press space to toggle animation\n"
"Press '+' and '-' to change displayed slice\n");
#if defined(__APPLE__) || defined(MACOSX)
atexit(cleanup);
#else
glutCloseFunc(cleanup);
#endif
glutMainLoop();
exit(EXIT_SUCCESS);
}
/* Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of NVIDIA CORPORATION nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
* EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
* OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#ifndef _SIMPLETEXTURE3D_KERNEL_CU_
#define _SIMPLETEXTURE3D_KERNEL_CU_
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <helper_cuda.h>
#include <helper_math.h>
typedef unsigned int uint;
typedef unsigned char uchar;
cudaArray *d_volumeArray = 0;
cudaTextureObject_t tex; // 3D texture
__global__ void d_render(uint *d_output, uint imageW, uint imageH, float w,
cudaTextureObject_t texObj) {
uint x = __umul24(blockIdx.x, blockDim.x) + threadIdx.x;
uint y = __umul24(blockIdx.y, blockDim.y) + threadIdx.y;
float u = x / (float)imageW;
float v = y / (float)imageH;
// read from 3D texture
float voxel = tex3D<float>(texObj, u, v, w);
if ((x < imageW) && (y < imageH)) {
// write output color
uint i = __umul24(y, imageW) + x;
d_output[i] = voxel * 255;
}
}
extern "C" void setTextureFilterMode(bool bLinearFilter) {
if (tex) {
checkCudaErrors(cudaDestroyTextureObject(tex));
}
cudaResourceDesc texRes;
memset(&texRes, 0, sizeof(cudaResourceDesc));
texRes.resType = cudaResourceTypeArray;
texRes.res.array.array = d_volumeArray;
cudaTextureDesc texDescr;
memset(&texDescr, 0, sizeof(cudaTextureDesc));
texDescr.normalizedCoords = true;
texDescr.filterMode =
bLinearFilter ? cudaFilterModeLinear : cudaFilterModePoint;
;
texDescr.addressMode[0] = cudaAddressModeWrap;
texDescr.addressMode[1] = cudaAddressModeWrap;
texDescr.addressMode[2] = cudaAddressModeWrap;
texDescr.readMode = cudaReadModeNormalizedFloat;
checkCudaErrors(cudaCreateTextureObject(&tex, &texRes, &texDescr, NULL));
}
extern "C" void initCuda(const uchar *h_volume, cudaExtent volumeSize) {
// create 3D array
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<uchar>();
checkCudaErrors(cudaMalloc3DArray(&d_volumeArray, &channelDesc, volumeSize));
// copy data to 3D array
cudaMemcpy3DParms copyParams = {0};
copyParams.srcPtr =
make_cudaPitchedPtr((void *)h_volume, volumeSize.width * sizeof(uchar),
volumeSize.width, volumeSize.height);
copyParams.dstArray = d_volumeArray;
copyParams.extent = volumeSize;
copyParams.kind = cudaMemcpyHostToDevice;
checkCudaErrors(cudaMemcpy3D(©Params));
cudaResourceDesc texRes;
memset(&texRes, 0, sizeof(cudaResourceDesc));
texRes.resType = cudaResourceTypeArray;
texRes.res.array.array = d_volumeArray;
cudaTextureDesc texDescr;
memset(&texDescr, 0, sizeof(cudaTextureDesc));
// access with normalized texture coordinates
texDescr.normalizedCoords = true;
// linear interpolation
texDescr.filterMode = cudaFilterModeLinear;
// wrap texture coordinates
texDescr.addressMode[0] = cudaAddressModeWrap;
texDescr.addressMode[1] = cudaAddressModeWrap;
texDescr.addressMode[2] = cudaAddressModeWrap;
texDescr.readMode = cudaReadModeNormalizedFloat;
checkCudaErrors(cudaCreateTextureObject(&tex, &texRes, &texDescr, NULL));
}
extern "C" void render_kernel(dim3 gridSize, dim3 blockSize, uint *d_output,
uint imageW, uint imageH, float w) {
d_render<<<gridSize, blockSize>>>(d_output, imageW, imageH, w, tex);
}
void cleanupCuda() {
if (tex) {
checkCudaErrors(cudaDestroyTextureObject(tex));
}
if (d_volumeArray) {
checkCudaErrors(cudaFreeArray(d_volumeArray));
}
}
#endif // #ifndef _SIMPLETEXTURE3D_KERNEL_CU_
4 参考链接
GitHub - NVIDIA/cuda-samples: Samples for CUDA Developers which demonstrates features in CUDA Toolkit
CUDA routines are functions that can be executed on the GPU using many threads in parallel1. There are many CUDA code samples included as part of the CUDA Toolkit to help you get started on writing CUDA C/C++ applications2. You can also find some easy introductions to CUDA C and C++ on the NVIDIA Technical Blog31.
GitHub - LitLeo/OpenCUDA
CUDA开发环境搭建 - 知乎 (zhihu.com)