文章目录
- 二叉搜索树的应用
- 搜索二叉树(KV模型)代码:
- 二叉搜索树的性能分析
二叉搜索树的应用
- K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。 - KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:
比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;
再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对
搜索二叉树(KV模型)代码:
由于我的上一篇文章详细介绍了K模型的书写,KV模型与K模型的代码书写方面是别无二致的,只需要对于增操作多加一个value值即可.
这里就直接贴上代码了,有不懂的部分请移步上一篇文章:
namespace key_value
{
#pragma once
// BinarySearchTree -- BSTree
// SearchBinaryTree
template<class K, class V>
struct BSTreeNode
{
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_left(nullptr)
, _right(nullptr)
, _key(key)
, _value(value)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;
public:
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key, value);
// 链接
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 删除
// 1、左为空
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
} // 2、右为空
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
else
{
// 找右树最小节点替代,也可以是左树最大节点替代
Node* pminRight = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
pminRight = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
if (pminRight->_left == minRight)
{
pminRight->_left = minRight->_right;
}
else
{
pminRight->_right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
protected:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
private:
Node* _root = nullptr;
};
}
二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
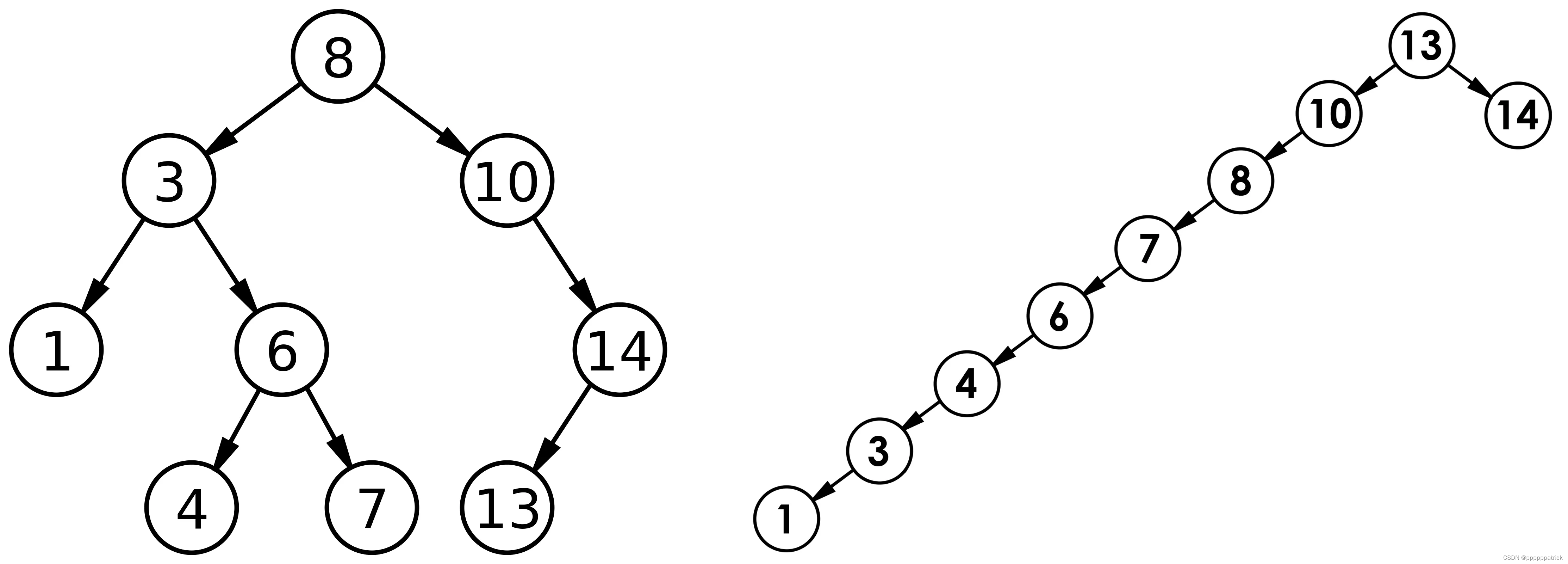
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:
l
o
g
2
N
log_2 N
log2N
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:
N
2
\frac{N}{2}
2N
问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,二叉搜索树的性能都能达到最优?那么我后续即将介绍的AVL树和红黑树就可以上场了。