解析基于Pytorch的残差神经网络(ResNet18模型),并使用数据集CIFAR10来进行预测与训练
1.0、什么是残差神经网络
注:本人才疏学浅,如有纰漏,请不吝赐教
残差神经网络其实是与卷积神经网络分不开的,我们知道卷积神经网络可以由很多个卷积层,激活层,池化层组成,多少个都没问题,但是随着层数增加,需要训练一轮的计算量也增加,这也不是最接受不了的,最无奈的是,随着层数增加,网络会呈现负优化,下面详解原因。
我们知道,卷积核作用是提取特征、训练卷积神经网络就是优化卷积核以减小预测值与真实值的差距,即:损失值。一个卷积核可以专注于提取一个特征,一般一个卷积层会有多个卷积核进行特征提取,如果是线性问题,我们其实只需要一层卷积就可以了,或者说大部分问题其实可以只使用一层卷积,然后不断的训练这层卷积中的卷积核,而我们之所以需要多层卷积,是希望后续的卷积层提取更高纬度的特征(这段理不理解无所谓,因为我也讲的不是很明白,或许后面我再更新)
但是随着卷积层的增加,我们一般层与层之间的输入会依赖于上一层的输出,但是捏,这样有个问题,如果上一层的输出没有有效的提取到特征,如:某个卷积核是用来判断图像中间是否为一条横线,但由于这个卷积核太差,不能提取到关于横线的特征,那么此卷积核的输出就废了,后面的卷积层再怎么根据这个输出进行卷也没啥用了,即此卷积核的输出为无效数据,那不g了、所以就想了一个办法:
假如现在有三层卷积:A,B,C、A层卷积后的输出为A1,B层会将A1作为输入进行卷积得到B1,但由于B1为无效数据,此时不能直接将B1作为输入放入C层,所以我们可以将A1与B1相加作为C层的输入,这样做的好处是,即使B1没多大用,但A1是有用的,这样C层的卷积还是能够获得一定的特征。
总的来说,残差神经网络相当于增加了每一个输出在后面卷积的权重
2.0、如何利用Pytorch编写一个残差神经网络
这里我以 ResNet18模型 为例,这个模型是Pytorch提供的一个残差神经网络模型,18可以简单理解为层数,数值越大层数越多,但是具体只什么层,我不清楚,,,
2.1、官网模型结构
我们可以使用如下代码获取官方给的模型(我们下面的下面会复现这个模型)
import torchvision
# True表示需不需要使用官方提供的模型参数、模型就相当于一个骨架,我们对模型进行训练得到的数据会反馈给模型,让模型由骨架转变为有五脏六腑的人类,,,模型参数就相当于五脏六腑、具体使用还要看是否符合你需要训练的数据集,如,如果都是对图片进行分类,那就可以为True
resnet = torchvision.models.resnet18(pretrained=True)
print(resnet)
运行代码我们会看到这样的输出:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
进程已结束,退出代码0
我们将其分割来看:
1、由一个开头的卷积层加上4个残差块已及最后一个全连接层组成
开头需要一个卷积层,是因为残差神经网络需要一个A1一样的输出作为后续的输入
全连接层是用来将数据变成一维,然后进行分类或者你需要的操作,,,(不理解也没关系,等下再洗将)
ResNet(
开始的卷积层
(layer1): Sequential()# 残差块
(layer2): Sequential()
(layer3): Sequential()
(layer4): Sequential()
全连接层
)
2.2、使用ResNet18模型处理CIFAR10训练集
CIFAR10训练集是啥,可以直接看我上一篇讲卷积神经网络的博客,里面有注释:博客
以下是数据集的官网解释:官网
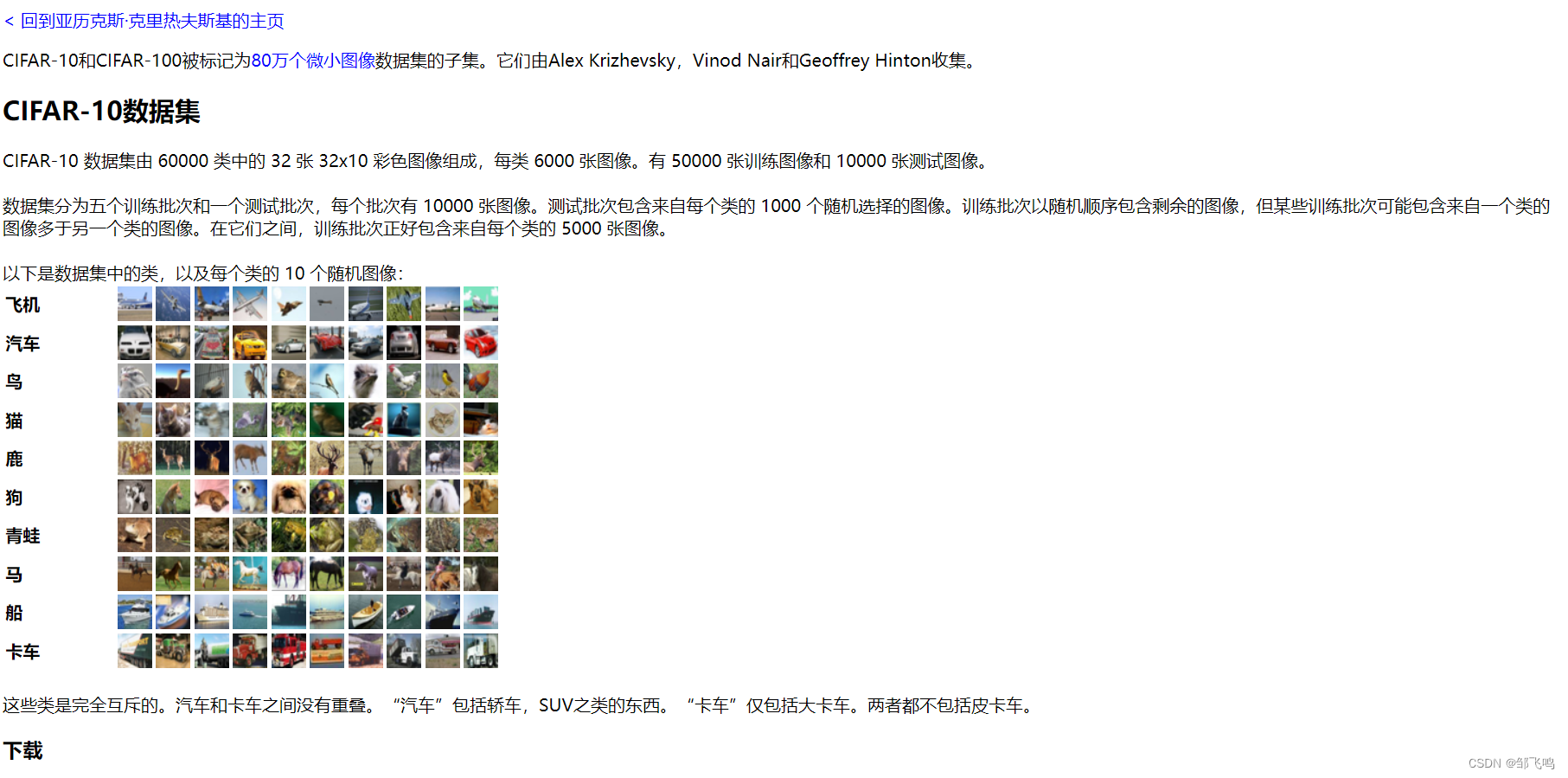
大体意思是图片是32X32大小的,通道数是3通道(即RGB三颜色),
代码编写步骤:
1、获取数据集、将数据集处理为模型需要的形式
2、创建残差神经网络模型
3、创建损失函数
4、创建优化器
5、训练:
1.读取一定数量的图片
2、将图片放入模型进行预测
3、将预测结果与真实值比较
4、梯度清零、反向传播
6、测试:
1.读取一定数量的图片
2、将图片放入模型进行预测
3、将预测结果取概率最高的作为输出并与真实值比较
4、获取所有比较结果就可以得出此轮预测的正确率
代码就不写了,因为与我的卷积神经网络的博客中一样,只是模型需要变成残差神经网络就行
我们具体看残差神经网络的模型是如何编写的:
1、编写残差块:你们可以将残差块比作一个个小的模型
分为定义与运行顺序:在__ init __()方法中会定义需要用到的东西,如卷积,池化,激活,归一化等等、在 forward(self, x):中会写明我们以怎样的顺序去运行卷积,池化,激活,归一化.
2、编写残差神经网络的模型
和残差块中差不多、就不重复写了
代码:
# 定义残差块==========================================================================
'''
stride:卷积核滑动步长,为1则输出特征图大小与输入一致,如果为2则输出特征图为原来一半,通道数为原来2倍(因为整体不变)
downsample=None:默认为None时表示不需要进行A1+B1作为C层输入的操作、这会发生在第一个残差块中
'''
class ResidualBlock(nn.Module):
def __init__(self, conv, bn, planes, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv # 就是一个卷积层,只不过由外部作为参数传入
self.bn1 = bn# 归一化,就是将里面的每一个值映射为0->1区间,为了防止过拟合,过拟合是啥呢,我也不太清楚,但是反应的结果就是训练时的损失值很小,但是测试时的损失值很大
self.relu = nn.ReLU(inplace=True)# 激活函数,也是一个映射,具体百度或者看我卷积神经网络的博客
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample# 外部会传入此参数,决定是否进行A1+B1作为C层输入的操作
self.stride = stride # 卷积核大小
def forward(self, x):
identity = x # 这里就相当于先吧A1存储,如果后续需要用到就使用
out = self.conv1(x) # 下面4步骤依次为:卷积、归一、激活、卷积、归一
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 然后判断需要需要进行A1+B1作为C层输入的操作、如果需要,因为x的值与最新的out维度大小啥的是不匹配的,需要加一些操作使其匹配
# 因为要将out向量与identity相加求和再传递给下一个残差块,但是out是经过卷积了,且第一次卷积,卷积核数为2,
# 即,经过第一次卷积后特征图大小减半,但由于全部特征图应该保持不变,所以我们将输入通道数由64变为128,
# 也因此、为了identity与out匹配,即也需要将identity从64的通道数变为128,故加此一层
if self.downsample is not None:
identity = self.downsample(x)
out = out + identity # 相当于 A1+B1
out = self.relu(out) # 激活
return out # 作为返回值,这样下一个残差块获得的输入就是 A1+B1 了
========================编写残差神经网络模型=========================================
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
'''
bias=False:偏置,此处表示不需要
num_classes=10:类别数
nn.ReLU(inplace=True):使用了inplace=True参数。这个参数的作用是直接在原有的张量上进行计算,而不是新创建一个张量。这样可以节省一定的内存空间,同时也可以提高计算效率。
'''
# 定义ResNet18模型
class ResNet18(nn.Module):
def __init__(self, num_classes=10):
super(ResNet18, self).__init__()
# 具体方法参数在卷积神经网络博客中有详细介绍,我这里只说为啥是这个值
# 因为图片是三通道,输出通道是64、然后将卷积核设置为7X7(它这里是简写),卷积核步长:2,将图片四周多加3块,变成35X35,这样更好提取边缘特征
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64) # 归一化 维度不变,变的只有里面的值
self.relu = nn.ReLU(inplace=True)
# 池化
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
# 64:通道数,2:残差块数量、blocks:只循环执行次数,为2时执行一次
self.layer1 = self._make_layer(planes=64, blocks=2)
self.layer2 = self._make_layer(planes=128, blocks=2, stride=2)
self.layer3 = self._make_layer(planes=256, blocks=2, stride=2)
self.layer4 = self._make_layer(planes=512, blocks=2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, planes, blocks, stride=1):
downsample = None # 先初始化
# 大致意思是,我们将第一个残差块不进行 A1+B1的操作,将后续的残差块进行,为啥我也不知道
if stride != 1 or planes != 64:
# 此处就是为 A1能够与B1相加做准备,将A1进行卷积与归一后其维度才与B1相同
downsample = nn.Sequential(
nn.Conv2d(int(planes/stride), planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes),
)
# 用来存储一个 self.layer1(x) 方法中需要多少个残差块,这由不同深度的残差神经网络去决定,这里是两个,固定一个加上通过变量blocks的值去决定是否还加,这样写也就是为了扩展性,不这样写也行
layers = []
'''
参数为啥要这样写 nn.Conv2d(int(planes/stride), planes, kernel_size=3, stride=stride
正常情况下,如果stride=1,那么通道数应该是输入多少输出就是多少,但由于stride有等于2的情况,所以我们在初始通道数需要进行除法,但是除法后值是浮点数,而参数需要整型,所以使用int(),而且我这里这样写是为了迎合:
self.layer1 = self._make_layer(planes=64, blocks=2)
即我们开始定义的输入,因为planes变量是作为输出的定义,所以我们需要计算输入值、当输入变成:
self.layer2 = self._make_layer(planes=128, blocks=2, stride=2)
时,为了保证输入是输出的一半,所以这样写、也可以自己改
'''
layers.append(ResidualBlock(nn.Conv2d(int(planes/stride), planes, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(planes), planes, 1, downsample))
for i in range(1, blocks):
layers.append(ResidualBlock(nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(planes), planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# # 全局平均池化层、它的作用是将每个特征图上的所有元素取平均,得到一个指定大小的输出。在 ResNet18 中,该池化层的输出大小为 。(batch_size, 512, 1, 1)用于最终的分类任务
x = self.avgpool(x)
# # 作用是将张量 沿着第 1 个维度进行压平,即将 转换为一个 1 维张量,
x = torch.flatten(x, 1)
# # 这里对应模型的 self.fc = nn.Linear(512, num_classes),就是将一维向量经过映射缩小到 10,因为CIFAR10是个10分类问题
x = self.fc(x)
return x
然后、将此模型替代我上一篇卷积神经网络中的模型,进行训练与测试:
结果:
可以看到,只经过700次训练就有50%的正确率
PyDev console: starting.
Python 3.9.16 (main, Mar 8 2023, 10:39:24) [MSC v.1916 64 bit (AMD64)] on win32
runfile('C:\\Users\\11606\\PycharmProjects\\pythonProject\\src\\train.py', wdir='C:\\Users\\11606\\PycharmProjects\\pythonProject\\src')
Files already downloaded and verified
Files already downloaded and verified
训练数据集长度:50000
测试数据集长度:10000
ResNet18(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResidualBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResidualBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResidualBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
----------第 0 轮训练开始
训练次数:100,loss:1.7689638137817383
训练次数:200,loss:1.4394694566726685
训练次数:300,loss:1.338126301765442
训练次数:400,loss:1.412974238395691
训练次数:500,loss:1.241265892982483
训练次数:600,loss:1.250759482383728
训练次数:700,loss:1.3602595329284668
整体测试集上的Loss:226.82027339935303
整体测试集上的正确率:0.505899965763092
模型已保存
----------第 1 轮训练开始
训练次数:800,loss:1.1243025064468384