原文:OpenCV 3 Computer Vision with Python Cookbook
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、线性代数
本章包含以下方面的秘籍:
- 正交 Procrustes 问题
- 秩约束矩阵近似
- 主成分分析
- 线性方程组的求解系统(包括欠定和超定)
- 求解多项式方程
- 使用单纯形法进行线性规划
介绍
变量之间的线性相关性是所有可能选项中最简单的。 从近似和几何任务到数据压缩,相机校准和机器学习,它可以在许多应用中找到。 但是,尽管它很简单,但是当现实世界的影响发挥作用时,事情就会变得复杂。 从传感器收集的所有数据都包含一部分噪声,这可能导致线性方程组具有不稳定的解。 计算机视觉问题通常需要求解线性方程组。 即使在许多 OpenCV 函数中,这些线性方程也是隐藏的。 可以肯定的是,您将在计算机视觉应用中面对它们。 本章中的秘籍将使您熟悉线性代数的方法,这些方法可能有用并且实际上已在计算机视觉中使用。
正交 Procrustes 问题
最初,这个问题对寻找两个矩阵之间的正交变换的方式提出了质疑。 也许这与实际的计算机视觉应用无关,但是当您考虑到一组点确实是矩阵时,这种感觉可能会改变。 相机校准,刚体转换,摄影测量问题以及许多其他任务都需要解决正交 Procrustes 问题。 在本秘籍中,我们找到了估计点集旋转这一简单任务的解决方案,并研究了噪声输入数据如何影响我们的解决方案。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成初始点集。 然后通过将旋转矩阵应用于初始点来创建一组旋转点。 此外,向旋转点添加一部分噪声:
pts = np.random.multivariate_normal([150, 300], [[1024, 512], [512, 1024]], 50)
rmat = cv2.getRotationMatrix2D((0, 0), 30, 1)[:, :2]
rpts = np.matmul(pts, rmat.transpose())
rpts_noise = rpts + np.random.multivariate_normal([0, 0], [[200, 0], [0, 200]], len(pts))
- 使用奇异值分解(SVD)解决正交 Procrustes 问题,并获得旋转矩阵的估计值:
M = np.matmul(pts.transpose(), rpts_noise)
sigma, u, v_t = cv2.SVDecomp(M)
rmat_est = np.matmul(v_t, u).transpose()
- 现在我们可以使用估计的旋转矩阵来找出我们的估计有多好。 为此,请计算反向旋转矩阵,然后将我们先前旋转的点乘以该矩阵。 然后,计算有噪声和无噪声的旋转点之间,旋转的反向点与初始反向点之间以及原始旋转矩阵及其估计值之间的欧几里得距离(L2):
res, rmat_inv = cv2.invert(rmat_est)
assert res != 0
pts_est = np.matmul(rpts, rmat_inv.transpose())
rpts_err = cv2.norm(rpts, rpts_noise, cv2.NORM_L2)
pts_err = cv2.norm(pts_est, pts, cv2.NORM_L2)
rmat_err = cv2.norm(rmat, rmat_est, cv2.NORM_L2)
- 显示我们的数据,将初始点显示为绿色圆圈,将旋转点显示为黄色圆圈,将反向点显示为白色细圆圈,将具有噪声的旋转点显示为红色细圆圈。 然后,打印有关点和矩阵之间的 L2 差的信息,并显示结果图像:
def draw_pts(image, points, color, thickness=cv2.FILLED):
for pt in points:
cv2.circle(img, tuple([int(x) for x in pt]), 10, color, thickness)
img = np.zeros([512, 512, 3])
draw_pts(img, pts, (0, 255, 0))
draw_pts(img, pts_est, (255, 255, 255), 2)
draw_pts(img, rpts, (0, 255, 255))
draw_pts(img, rpts_noise, (0, 0, 255), 2)
cv2.putText(img, 'R_points L2 diff: %.4f' % rpts_err, (5, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.putText(img, 'Points L2 diff: %.4f' % pts_err, (5, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.putText(img, 'R_matrices L2 diff: %.4f' % rmat_err, (5, 90), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.imshow('Points', img)
cv2.waitKey()
cv2.destroyAllWindows()
工作原理
为了找到正交 Procrustes 问题的解决方案,我们将 SVD 应用于两个矩阵的乘积:由初始点组成的矩阵和由旋转后的点组成的另一个矩阵。 每个矩阵中的行是对应点的(x,y)坐标。 SVD 方法是众所周知的,可以使噪声结果稳定。 cv2.SVDecomp是在 OpenCV 中实现 SVD 的函数。 它接受一个矩阵(MxN)进行分解并返回三个矩阵。 返回的第一个矩阵是大小为MxN的矩形对角矩阵,对角线上的正数称为奇异值。 第二矩阵和第三矩阵分别是左奇异向量矩阵和右奇异向量矩阵的共轭转置。
SVD 是线性代数中非常方便的工具。 它能够产生可靠的解决方案,因此在许多不同的任务中经常使用。 我们不会深入研究 SVD 的理论,因为它是一个独立且确实是广泛的主题。 但是,我们将在本章后面的其他秘籍中了解此过程。
让我们还回顾一下前面代码中的 OpenCV 的另一个函数。 本书以前没有提到cv2.getRotationMatrix2D函数。 它为给定的旋转中心和角度以及比例尺计算仿射变换矩阵。 参数按以下顺序排列:旋转中心(格式为(x,y),旋转角度(以度为单位),比例。 返回的值是2x3仿射变换矩阵。
cv2.invert找到给定一个矩阵的伪逆矩阵。 此函数接受要求逆的矩阵,并选择接受结果和求逆方法标志的矩阵。 默认情况下,该标志设置为cv2.DECOMP_LU,它将应用 LU 分解来查找结果。 另外,cv2.DECOMP_SVD和cv2.DECOMP_CHOLESKY也可以作为选项使用; 第一个使用 SVD 查找伪逆矩阵(是,这是 SVD 的另一个应用),第二个使用 Cholesky 分解实现相同的目的。 该函数返回两个对象,一个float值和所得的倒置矩阵。 如果第一个返回值为 0,则输入矩阵为奇数。 在这种情况下,cv2.DECOMP_LU和cv2.DECOMP_CHOLESKY无法产生结果,但是cv2.DECOMP_SVD计算伪逆矩阵。
从当前秘籍启动代码的结果是,您将获得与以下内容类似的结果:
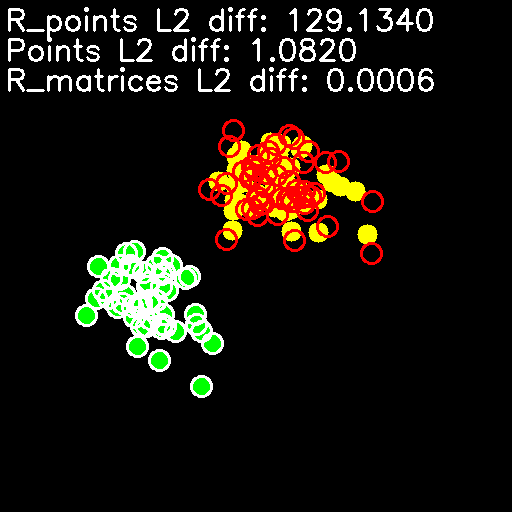
如您所见,尽管添加噪声前后的点之间的差异相对较大,但初始点和估计点与旋转矩阵之间的差异很小。
如果您对 SVD 的理论感兴趣,那么此 Wikipedia 页面是一个不错的起点。
秩约束矩阵近似
在本秘籍中,您将学习如何计算秩相关矩阵近似值。 该问题被表述为优化问题。 给定一个输入矩阵,目的是找到它的近似值,在该近似值下,使用 Frobenius 范数测量拟合,并且输出矩阵的秩不应大于给定值。 除其他领域外,此功能还用于数据压缩和机器学习。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成一个随机矩阵:
A = np.random.randn(10, 10)
- 计算 SVD:
w, u, v_t = cv2.SVDecomp(A)
- 计算秩约束矩阵近似值:
RANK = 5
w[RANK:,0] = 0
B = u @ np.diag(w[:,0]) @ v_t
- 检查结果:
print('Rank before:', np.linalg.matrix_rank(A))
print('Rank after:', np.linalg.matrix_rank(B))
print('Norm before:', cv2.norm(A))
print('Norm after:', cv2.norm(B))
工作原理
Eckart-Young-Mirsky 定理指出,可以通过计算 SVD(使用cv2.SVDecomp函数)并构造一个近似值(最小的奇异值设置为零)来解决问题,因此近似值等级不大于所需的值。 值。
输出如下所示:
Rank before: 10
Rank after: 5
Norm before: 9.923378133354824
Norm after: 9.511025831320431
主成分分析
主成分分析(PCA)旨在确定维度在数据中的重要性并建立新的基础。 在这个新的基础上,选择的方向要与其他方向具有最大的独立性。 由于具有最大的独立性,我们可以了解哪些数据维度承载更多信息,哪些数据维度承载较少。 PCA 用于许多应用,主要用于数据分析和数据压缩,但也可以用于计算机视觉。 例如,确定并跟踪物体的方向。 此秘籍将向您展示如何在 OpenCV 中进行操作。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入我们需要的模块:
import cv2
import numpy as np
- 定义将 PCA 应用于轮廓点并确定新基础的函数:
def contours_pca(contours):
# join all contours points into the single matrix and remove unit dimensions
cnt_pts = np.vstack(contours).squeeze().astype(np.float32)
mean, eigvec = cv2.PCACompute(cnt_pts, None)
center = mean.squeeze().astype(np.int32)
delta = (150*eigvec).astype(np.int32)
return center, delta
- 定义一个函数,该函数显示将 PCA 应用于轮廓点的结果:
def draw_pca_results(image, contours, center, delta):
cv2.drawContours(image, contours, -1, (255, 255, 0))
cv2.line(image, tuple((center + delta[0])),
tuple((center - delta[0])),
(0, 255, 0), 2)
cv2.line(image, tuple((center + delta[1])),
tuple((center - delta[1])),
(0, 0, 255), 2)
cv2.circle(image, tuple(center), 20, (0, 255, 255), 2)
- 打开视频并逐帧分析。 对于每个框架,找到轮廓并将 PCA 应用于找到的轮廓。 然后,显示结果:
cap = cv2.VideoCapture("../data/opencv_logo.mp4")
while True:
status_cap, frame = cap.read()
if not status_cap:
break
frame = cv2.resize(frame, (0, 0), frame, 0.5, 0.5)
edges = cv2.Canny(frame, 250, 150)
_, contours, _ = cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(contours):
center, delta = contours_pca(contours)
draw_pca_results(frame, contours, center, delta)
cv2.imshow('PCA', frame)
if cv2.waitKey(100) == 27:
break
cv2.destroyAllWindows()
工作原理
使用 PCA 跟踪对象方向的主要思想是在旋转过程中对象不会发生变化。 因为它是同一对象,但方向不同,所以它具有自己的基础,并且该基础与对象一起旋转。 因此,我们需要在每时每刻确定这个基础,以找到物体的方向。 如果我们有正确的数据要分析,PCA 可以找到这样的基础。 让我们使用对象轮廓的点。 当然,它们在旋转过程中会更改其绝对位置,但会与对象一起旋转。 在每个方向上,轮廓的点都沿最大方向变化。 而且由于旋转不会使轮廓倾斜或扭曲,因此这些方向随对象旋转。
顾名思义,cv2.PCACompute实现了 PCA。 它找到数据协方差矩阵的特征向量和特征值。 此函数有两个重载。 我们在前面的代码中使用的第一个选项接受一个要分析的数据矩阵,一个预先计算的平均值,一个写计算出的特征向量的矩阵以及一些要返回的向量。 最后两个参数是可选的,可以省略(在这种情况下,将返回所有向量)。 同样,如果没有预先计算的平均值,则可以将第二个参数设置为“无”。 在这种情况下,该函数也会计算平均值。 数据矩阵通常是一组样本。 每个样本具有多个维度D,并且总体上有N个样本。 在这种情况下,数据矩阵必须为NxD,N行也必须为NxD,并且每一行都是一个单独的样本。
如前所述,cv2.PCACompute存在第二个过载。 如前所述,它接受要分析的数据矩阵,并将预先计算的平均值作为前两个参数。 第三和第四参数是保留方差与存储计算向量的对象的比率。 该比率通过其方差确定要返回的向量数,比率越不平衡,保留的向量数就越大。 此参数允许您不固定向量的数量,而只保留方差最大的向量。
代码执行的结果是,您将获得类似于以下内容的图像:

线性方程组的求解系统(包括欠定和超定)
在本秘籍中,您将学习如何使用 OpenCV 求解线性方程组。 此功能是许多计算机视觉和机器学习算法的关键构建块。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成线性方程组:
N = 10
A = np.random.randn(N,N)
while np.linalg.matrix_rank(A) < N:
A = np.random.randn(N,N)
x = np.random.randn(N,1)
b = A @ x
- 求解线性方程组:
ok, x_est = cv2.solve(A, b)
print('Solved:', ok)
if ok:
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
- 构造一个超定线性方程组:
N = 10
A = np.random.randn(N*2,N)
while np.linalg.matrix_rank(A) < N:
A = np.random.randn(N*2,N)
x = np.random.randn(N,1)
b = A @ x
- 求解超定线性方程组:
ok, x_est = cv2.solve(A, b, flags=cv2.DECOMP_NORMAL)
print('\nSolved overdetermined system:', ok)
if ok:
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
- 构建一个不确定的线性方程组系统,该系统具有多个解决方案:
N = 10
A = np.random.randn(N,N*2)
x = np.random.randn(N*2,1)
b = A @ x
- 解决欠定线性方程组。 查找具有最小规范的解决方案:
w, u, v_t = cv2.SVDecomp(A, flags=cv2.SVD_FULL_UV)
mask = w > 1e-6
w[mask] = 1 / w[mask]
w_pinv = np.zeros((A.shape[1], A.shape[0]))
w_pinv[:N,:N] = np.diag(w[:,0])
A_pinv = v_t.T @ w_pinv @ u.T
x_est = A_pinv @ b
print('\nSolved underdetermined system')
print('Residual:', cv2.norm(b - A @ x_est))
print('Relative error:', cv2.norm(x_est - x) / cv2.norm(x))
工作原理
线性方程组可以使用 OpenCV 的cv2.solve函数求解。 它接受一个系数矩阵,系统的右侧和可选标志,然后返回一个解决方案(准确地说是成功指标和解决方案向量)。 如您在第一个示例中所看到的,它可用于解决具有独特解决方案的系统。
您可以指定cv2.DECOMP_NORMAL标志,在这种情况下,将构建内部标准化的线性方程组。 这可以用来解决带有一个或没有解的超定系统,在后一种情况下,返回最小二乘问题的解。
一个欠定的线性方程组没有或有多个解。 在前面的代码中,我们构建了具有多个解决方案的系统。 可以使用 Moore-Penrose 逆(代码中的A_pinv)找到具有最小范数的解。 由于存在多种解决方案,相对于我们用来生成系统右侧的解决方案,我们发现的解决方案可能会有更多错误。
这是预期输出的示例:
Solved: True
Residual: 2.7194799110210367e-15
Relative error: 1.1308382847616332e-15
Solved overdetermined system: True
Residual: 4.418021593470969e-15
Relative error: 5.810798787243048e-16
Solved underdetermined system
Residual: 9.296750665059115e-15
Relative error: 0.7288729621745673
求解多项式方程
在本秘籍中,您将学习如何使用 OpenCV 求解多项式方程。 这样的问题可能出现在诸如机器学习,计算代数和信号处理等领域。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 生成四次多项式方程:
N = 4
coeffs = np.random.randn(N+1,1)
- 找到复数域中的所有根:
retval, roots = cv2.solvePoly(coeffs)
- 检查根:
for i in range(N):
print('Root', roots[i],'residual:',
np.abs(np.polyval(coeffs[::-1], roots[i][0][0]+1j*roots[i][0][1])))
工作原理
度为n的多项式方程在复数域中始终具有n根(但是其中一些可以重复)。 使用cv2.solvePoly函数可以找到所有解决方案。 它采用方程系数并返回所有根。
这是预期输出的示例:
Root [[ 0.0494519 1.12199842]] residual: [ 1.50920942e-16]
Root [[-0.17045556 0\. ]] residual: [ 0.]
Root [[ 0.0494519 -1.12199842]] residual: [ 1.50920942e-16]
Root [[-8.1939051 0\. ]] residual: [ 1.80133686e-14]
使用单纯形法的线性规划
在本秘籍中,我们考虑优化问题的一种特殊情况,即线性约束问题。 这些任务意味着您需要考虑一组线性约束来优化(最大化或最小化)正变量的线性组合。 线性规划在计算机视觉中没有众所周知的直接应用,但是您可能会在以后遇到它。 因此,让我们看看如何使用 OpenCV 处理线性规划问题。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入模块:
import cv2
import numpy as np
- 为函数创建一个线性约束矩阵和权重,我们将对其进行优化:
m = 10
n = 10
constraints_mat = np.random.randn(m, n+1)
weights = np.random.randn(1, n)
- 通过调用
cv2.solveLP将单纯形方法应用于任务。 然后,解析结果:
solution = np.array((n, 1), np.float32)
res = cv2.solveLP(weights, constrains_mat, solution)
if res == cv2.SOLVELP_SINGLE:
print('The problem has the one solution')
elif res == cv2.SOLVELP_MULTI:
print('The problem has the multiple solutions')
elif res == cv2.SOLVELP_UNBOUNDED:
print('The solution is unbounded')
elif res == cv2.SOLVELP_UNFEASIBLE:
print('The problem doesnt\'t have any solutions')
工作原理
cv2.solveLP接受三个参数:函数的权重,线性约束矩阵和用于保存结果的 NumPy 数组对象。 权重由浮点值向量(N, 1)或(1, N)表示。 该向量的长度也意味着优化参数的数量。 线性约束矩阵是(M, N + 1)NumPy 数组,其中最后一列包含每个约束和每一行的常数项,最后一个元素除外,最后一个元素为相应的参数包含系数。 最后一个参数旨在存储解决方案(如果存在)。
通常,线性规划问题有四种可能的结果,它们可能只有一个解决方案,很多解决方案(在一定范围内),或者根本没有确定的解决方案。 在后一种情况下,问题可能是无限的或不可行的。 对于所有这四个结果,cv2.solveLP返回相应的值:cv2.SOLVELP_SINGLE,cv2.SOLVELP_MULTI,cv2.SOLVELP_UNBOUNDED或v2.SOLVELP_UNFEASIBLE。
七、检测器和描述符
本章包含以下方面的秘籍:
- 在图像中找到角点-Harris 和 FAST
- 选择图像中的良好角点来跟踪
- 绘制关键点,描述符和匹配项
- 检测尺度不变关键点
- 计算图像关键点的描述符-SURF,BRIEF 和 ORB
- 查找描述符之间对应关系的匹配技术
- 寻找可靠的匹配 - 交叉检查和比率测试
- 基于模型的匹配过滤 - RANSAC
- 用于构造全局图像描述符的 BoW 模型
介绍
可以根据比较图像中的区域来制定检测和跟踪任务。 如果我们能够在图像中找到特殊点并为这些点建立描述符,则可以比较描述符并得出有关图像中对象相似性的结论。 在计算机视觉中,这些特殊点称为关键点,但是围绕此概念出现了一些问题:如何在图像中找到真正的特殊位置? 您如何计算健壮且唯一的描述符? 您如何快速准确地比较这些描述符? 本章将解决所有这些查询,并引导您完成所有步骤,从找到关键点到使用 OpenCV 进行比较。
在图像中找到角点 - Harris 和 FAST
一个角可以认为是两个边的交集。 图像中角点的数学定义是不同的,但是反映了相同的想法。 角点是具有以下属性的点:沿任何方向移动该点都会导致该点的较小邻域发生变化。 例如,如果我们在图像的均匀区域上获取一个点,则移动该点不会改变附近的本地窗口中的任何内容。 边缘上的点不属于平原区域,并且又具有方向,其移动不影响该点的局部区域:这些是沿边缘的运动。 只有角对于所有方向都对移动敏感,因此,它们是跟踪或比较对象的良好候选者。 在本秘籍中,我们将学习如何使用 OpenCV 中的两种方法在图像上找到角点。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0 版(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载图像并使用
cv2.cornerHarris查找其角点:
img = cv2.imread('../data/scenetext01.jpg', cv2.IMREAD_COLOR)
corners = cv2.cornerHarris(cv2.cvtColor(img, cv2.COLOR_BGR2GRAY), 2, 3, 0.04)
- 处理并显示结果:
corners = cv2.dilate(corners, None)
show_img = np.copy(img)
show_img[corners>0.01*corners.max()]=[0,0,255]
corners = cv2.normalize(corners, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
show_img = np.hstack((show_img, cv2.cvtColor(corners, cv2.COLOR_GRAY2BGR)))
cv2.imshow('Harris corner detector', show_img)
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()
- 创建一个
FAST检测器并将其应用于图像:
fast = cv2.FastFeatureDetector_create(30, True, cv2.FAST_FEATURE_DETECTOR_TYPE_9_16)
kp = fast.detect(img)
- 绘制结果并显示图像:
show_img = np.copy(img)
for p in cv2.KeyPoint.convert(kp):
cv2.circle(show_img, tuple(p), 2, (0, 255, 0), cv2.FILLED)
cv2.imshow('FAST corner detector', show_img)
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()
- 禁用非最大抑制,获取角点并显示结果:
fast.setNonmaxSuppression(False)
kp = fast.detect(img)
for p in cv2.KeyPoint.convert(kp):
cv2.circle(show_img, tuple(p), 2, (0, 255, 0), cv2.FILLED)
cv2.imshow('FAST corner detector', show_img)
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()
工作原理
cv2.cornerHarris是 OpenCV 的函数,其名称如下实现了Harris角点检测器。 它包含六个参数:前四个参数是必需的,后两个参数具有默认值。 参数如下:
- 单通道 8 位或浮点图像,在其上要检测角点
- 邻域窗口的大小:应将其设置为大于 1 的较小值
- 计算导数的窗口大小:应将其设置为奇数
- 角点检测器的灵敏度系数:通常设置为 0.04
- 您可以在其中存储结果的对象
- 边界外推法
边界外推法确定图像扩展的方式。 可以将其设置为一堆值(cv2.BORDER_CONSTANT,cv2.BORDER_REPLICATE等),默认情况下使用cv2.BORDER_REFLECT_101。 cv2.cornerHarris调用的结果是Harris量度的映射。 值较高的点更有可能成为好角。 启动与Harris角点检测器相关的代码的结果是,您将获得与以下图像类似的图像(图像的左侧是角点可视化,而右侧是Harris量度图):

我们在此秘籍中应用的另一种方法是来自加速段测试的特征(FAST)检测器。 它还以另一种方式在图像上找到角点。 它考虑每个点周围的一个圆并计算该圆的一些统计量。 让我们了解如何使用 FAST。
首先,我们需要使用cv2.FastFeatureDetector_create创建一个检测器。 该函数接受整数阈值,启用非最大抑制的标志以及确定相邻区域的大小和点数阈值的模式。 所有这些参数都可以稍后使用cv2.FastFeatureDetector类的相应方法(在先前代码中为setNonmaxSuppression)进行修改。
要在初始化后使用检测器,我们需要调用cv2.FastFeatureDetector.detect函数。 它拍摄一个单通道图像并返回cv2.KeyPoint对象的列表。 可以通过cv2.KeyPoint.convert将该列表转换为 numpy 数组。 结果数组中的每个元素都是角点。
执行与 FAST 检测器相关的代码将显示以下图像(启用了用于非最大抑制的左侧图像,禁用了用于非最大抑制的右侧图像):

选择图像中的良好角点来跟踪
在本秘籍中,您将学习如何检测图像中的关键点并应用简单的后处理试探法,以提高检测到的关键点的整体质量,例如摆脱关键点群集并删除相对较弱的关键点。 此功能在诸如对象跟踪和视频稳定之类的计算机视觉任务中很有用,因为提高检测到的关键点的质量会影响相应算法的最终质量。
准备
在继续此秘籍之前,您需要安装 OpenCV 3.0 版(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import matplotlib.pyplot as plt
- 加载测试图像:
img = cv2.imread('../data/Lena.png', cv2.IMREAD_GRAYSCALE)
- 找到良好的关键点:
corners = cv2.goodFeaturesToTrack(img, 100, 0.05, 10)
- 可视化结果:
for c in corners:
x, y = c[0]
cv2.circle(img, (x, y), 5, 255, -1)
plt.figure(figsize=(10, 10))
plt.imshow(img, cmap='gray')
plt.tight_layout()
plt.show()
工作原理
在此示例中,我们使用了 OpenCV 函数cv2.goodFeaturesToTrack。 此函数检测关键点并实现启发式列表,以通过选择良好的关键点的子集来提高诸如对象跟踪之类的计算机视觉任务的关键点的整体质量。 此函数确保关键点之间的距离不会太近,最小距离由minDistance参数调节。 qualityLevel参数调节相对于最强的关键点而言哪些关键点被认为是弱的,并将哪些关键点从最初检测到的关键点中删除。 该函数还具有参数maxCorners,这是检测到的关键点的最大数量。
预期输出如下:

绘制关键点,描述符和匹配项
找到关键点之后,您无疑想要查看这些关键点在原始图像中的位置。 OpenCV 是显示关键点和其他相关信息的便捷方法。 此外,您可以轻松地绘制来自不同图像的关键点之间的对应关系。 此秘籍告诉您如何可视化关键点以及匹配结果。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
import random
- 加载图像,在其中找到 FAST 关键点,并使用随机值填充每个关键点的大小和方向:
img = cv2.imread('../data/scenetext01.jpg', cv2.IMREAD_COLOR)
fast = cv2.FastFeatureDetector_create(160, True, cv2.FAST_FEATURE_DETECTOR_TYPE_9_16)
keyPoints = fast.detect(img)
for kp in keyPoints:
kp.size = 100*random.random()
kp.angle = 360*random.random()
matches = []
for i in range(len(keyPoints)):
matches.append(cv2.DMatch(i, i, 1))
- 画出关键点:
show_img = cv2.drawKeypoints(img, keyPoints, None, (255, 0, 255))
cv2.imshow('Keypoints', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
- 可视化有关关键点的大小和方向信息:
show_img = cv2.drawKeypoints(img, keyPoints, None, (0, 255, 0),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('Keypoints', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
- 显示关键点的匹配结果:
show_img = cv2.drawMatches(img, keyPoints, img, keyPoints, matches, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('Matches', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
工作原理
要显示关键点,您需要使用cv2.drawKeypoints。 此函数将源图像,关键点列表,目标图像,颜色和标志作为参数。 在最简单的情况下,您只需要通过前三个即可。 源图像用作背景,但此函数不会更改它,结果将被放置在目标图像中。 关键点列表是一个对象,由关键点检测器返回,因此您可以将该列表直接传递给cv2.drawKeypoints函数,而无需进行任何处理。 颜色只是绘图颜色。 最后一个参数flags允许您控制绘图模式-默认情况下,它具有cv2.DRAW_MATCHES_FLAGS_DEFAULT值,在这种情况下,关键点显示为相同直径的普通圆。 此标志的第二个选项是cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS。 在这种情况下,这些点将被绘制为具有不同直径的圆,并且方向也将显示为从圆心开始的一条线。 绘制的关键点直径显示了邻域,该邻域用于计算关键点; 方向会显示关键点的特定方向(如果关键点有此方向)。 cv2.drawKeypoints返回带有绘制关键点的结果图像。
cv2.drawMatches可帮助您显示关键点匹配过程之后各点之间的对应关系。 该函数的参数为:第一幅图像及其关键点列表,第二幅图像及其关键点,这些关键点的匹配结果列表,目标图像,用于绘制对应关系的颜色,用于绘制没有关键点的颜色匹配项,用于绘制匹配项的遮罩和一个标志。 通常,在关键点检测和匹配之后,您具有前五个参数的值。 默认情况下,匹配点和不匹配点(单个)的颜色是随机生成的,但是您可以使用任何值进行设置。 匹配的掩码是值的列表,其中非零值表示应显示对应的匹配(具有相同的索引)。 默认情况下,遮罩为空,并绘制所有匹配项。 最后一个参数控制要显示的关键点的模式。 可以将其设置为cv2.DRAW_MATCHES_FLAGS_DEFAULT或cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,并可选地与cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS值共轭。
前两个值与cv2.drawKeypoints函数具有相同的含义。 最终值cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS允许您不显示不匹配的关键点。
通过执行代码,您将获得与以下图像类似的图像:

检测尺度不变关键点
现实世界中的物体在移动,这使得将它们与以前的外观进行精确比较变得更加困难。 当它们接近相机时,物体会变大。 为了应对这种情况,我们应该能够检测对对象的大小差异不敏感的关键点。 尺度不变特征变换(SIFT)描述符专门设计用于处理不同的对象尺度,并为对象找到相同的特征,无论它们的大小如何。 此秘籍向您展示如何使用 OpenCV 中的 SIFT 实现。
准备
在继续此秘籍之前,您需要安装带有 Contrib 模块的 OpenCV 3.0 版(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块并加载图像:
import cv2
import numpy as np
img0 = cv2.imread('../data/Lena.png', cv2.IMREAD_COLOR)
img1 = cv2.imread('../data/Lena_rotated.png', cv2.IMREAD_COLOR)
img1 = cv2.resize(img1, None, fx=0.75, fy=0.75)
img1 = np.pad(img1, ((64,)*2, (64,)*2, (0,)*2), 'constant', constant_values=0)
imgs_list = [img0, img1]
- 创建一个 SIFT 关键点检测器:
detector = cv2.xfeatures2d.SIFT_create(50)
- 检测每个图像中的关键点,可视化这些关键点并显示结果:
for i in range(len(imgs_list)):
keypoints, descriptors = detector.detectAndCompute(imgs_list[i], None)
imgs_list[i] = cv2.drawKeypoints(imgs_list[i], keypoints, None, (0, 255, 0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('SIFT keypoints', np.hstack(imgs_list))
cv2.waitKey()
cv2.destroyAllWindows()
工作原理
要创建 SIFT 关键点检测器的实例,您需要使用cv2.xfeatures2d.SIFT_create函数。 它的所有参数都有默认值,参数本身是:查找和返回的关键点数量,要使用的比例金字塔中的级别数量,用于调整算法灵敏度的两个阈值以及用于平滑图片的σ方差 。 所有参数都很重要,但首先可能需要调整的是关键点的数量和σ。 最后一个控制您不关心的对象的最大尺寸,这对于消除图像中的噪点和细小的细节很有用。
通过完成秘籍中的代码后,您将获得类似于以下内容的图像:

如您所见,尽管右侧图像稍微倾斜并且尺寸小于右侧图像,但在图像中仍可以找到相同的关键点配置。 这是 SIFT 描述符的关键功能。
计算图像关键点的描述符 - SURF,BRIEF 和 ORB
在先前的秘籍中,我们研究了几种在图像中找到关键点的方法。 基本上,关键点只是特殊区域的位置。 但是,我们如何区分这些位置呢? 当我们要跟踪一系列帧中的对象时,在很多情况下都会出现此问题,尤其是在视频处理中。 该秘籍涵盖了表征关键点邻域的一些有效方法,换句话说,就是计算关键点描述符。
准备
在继续此秘籍之前,您需要安装带有 Contrib 模块的 OpenCV 3.0 版(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入我们需要的模块并加载图像:
import cv2
import numpy as np
img = cv2.imread('../data/scenetext01.jpg', cv2.IMREAD_COLOR)
- 创建一个 SURF 特征检测器并调整其一些参数。 然后,将其应用于加载的图像并显示结果:
surf = cv2.xfeatures2d.SURF_create(10000)
surf.setExtended(True)
surf.setNOctaves(3)
surf.setNOctaveLayers(10)
surf.setUpright(False)
keyPoints, descriptors = surf.detectAndCompute(img, None)
show_img = cv2.drawKeypoints(img, keyPoints, None, (255, 0, 0),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('SURF descriptors', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
- 创建一个 BRIEF 关键点描述符并将其应用于 SURF 关键点。 之后,显示结果的关键点:
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(32, True)
keyPoints, descriptors = brief.compute(img, keyPoints)
show_img = cv2.drawKeypoints(img, keyPoints, None, (0, 255, 0),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('BRIEF descriptors', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
- 初始化 ORB 特征检测器。 此后,检测关键点并计算图像的描述符。 然后,在图像中绘制关键点:
orb = cv2.ORB_create()
orb.setMaxFeatures(200)
keyPoints = orb.detect(img, None)
keyPoints, descriptors = orb.compute(img, keyPoints)
show_img = cv2.drawKeypoints(img, keyPoints, None, (0, 0, 255),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('ORB descriptors', show_img)
cv2.waitKey()
cv2.destroyAllWindows()
工作原理
先前使用的所有关键点描述符均实现cv2.Feature2D接口,并具有相同的使用方式。 所有这些都需要首先创建描述符对象。 然后,就有可能设置或调整所创建描述符的某些参数。 值得一提的是,描述符具有算法参数的默认值,并且这些选择的默认值在许多情况下都能很好地工作。 准备使用描述符时,应使用detect,compute和detectAndCompute方法来检索指定图像的关键点和/或描述符。
要创建 SURF 描述符,您需要调用cv2.xfeatures2d.SURF_create函数。 它需要大量的参数,但是幸运的是所有参数都有默认值。 此函数返回初始化的 SURF 描述符对象。 要将其应用于图像,可以通过调用detectAndCompute函数找到关键点及其描述符。 您需要将输入图像传递给此函数,输入图像遮罩(如果没有提供遮罩,则可以设置为None),用于存储计算的描述符的对象以及用于标识是否应使用预先计算的关键点的标志。 该函数为每个返回的关键点返回关键点列表和描述符列表。
要创建一个简短的描述符,您需要使用cv2.BriefDescriptorExtractor_create函数。 该函数将算法的参数作为参数,并返回一个初始化的描述符对象。 BRIEF 描述符无法检测关键点,因此仅实现compute方法,该方法返回输入图像和先前检测到的关键点的描述符。
可以使用cv2.ORB_create函数创建 ORB 关键点检测器。 同样,此函数对该算法的参数采用了一系列具体细节,并返回了一个已构造且可立即使用的对象。
秘籍中的代码产生以下图像:

查找描述符之间对应关系的匹配技术
我们想在检测和跟踪任务中找到关键点之间的对应关系,但是我们无法比较这些点本身。 相反,我们应该处理关键点描述符。 关键点描述符是专门开发的,以便可以对其进行比较。 此秘籍向您展示 OpenCV 的方法,用于比较描述符并使用各种匹配技术建立描述符之间的对应关系。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 定义一个处理视频文件的函数。 此函数获取每一帧,并与该帧的关键点和之前的 40 帧匹配:
def video_keypoints(matcher, cap=cv2.VideoCapture("../data/traffic.mp4"),
detector=cv2.ORB_create(40)):
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
while True:
status_cap, frame = cap.read()
frame = cv2.resize(frame, (0, 0), fx=0.5, fy=0.5)
if not status_cap:
break
if (cap.get(cv2.CAP_PROP_POS_FRAMES) - 1) % 40 == 0:
key_frame = np.copy(frame)
key_points_1, descriptors_1 = detector.detectAndCompute(frame, None)
else:
key_points_2, descriptors_2 = detector.detectAndCompute(frame, None)
matches = matcher.match(descriptors_2, descriptors_1)
frame = cv2.drawMatches(frame, key_points_2, key_frame, key_points_1,
matches, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS |
cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Keypoints matching', frame)
if cv2.waitKey(300) == 27:
break
cv2.destroyAllWindows()
- 将帧与暴力匹配进行比较:
bf_matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING2, True)
video_keypoints(bf_matcher)
- 将 KD 树索引应用于 SURF 描述符:
flann_kd_matcher = cv2.FlannBasedMatcher()
video_keypoints(flann_kd_matcher, detector=cv2.xfeatures2d.SURF_create(20000))
- 对二进制 ORB 特征使用局部敏感哈希(LSH):
FLANN_INDEX_LSH = 6
index_params = dict(algorithm=FLANN_INDEX_LSH, table_number=20, key_size=15, multi_probe_level=2)
search_params = dict(checks=10)
flann_kd_matcher = cv2.FlannBasedMatcher(index_params, search_params)
video_keypoints(flann_kd_matcher)
- 使用复合 KD 树和 K 均值索引算法重新运行该过程:
FLANN_INDEX_COMPOSITE = 3
index_params = dict(algorithm=FLANN_INDEX_COMPOSITE, trees=16)
search_params = dict(checks=10)
flann_kd_matcher = cv2.FlannBasedMatcher(index_params, search_params)
video_keypoints(flann_kd_matcher, detector=cv2.xfeatures2d.SURF_create(20000))
工作原理
OpenCV 支持许多不同的匹配类型。 所有这些都使用cv2.DescriptorMatcher接口实现,因此任何类型的匹配器都支持相同的方法和相同的使用场景。 匹配器用法有两种类型:检测模式和跟踪模式。 从技术上讲,这两种模式之间没有太大区别,因为在两种情况下,我们都需要有两组描述符来匹配它们。 问题是我们是否将第一个集合上载一次,然后与另一个集合进行比较,还是每次将两个描述符集传递给匹配函数。 要上传描述符集,您需要使用cv2.DescriptorMatcher.add函数,该函数仅接受您的描述符列表。 在完成描述符的添加后,在某些情况下,您需要调用cv2.DescriptorMatcher.train方法来告知匹配程序有关描述符的句柄,并为匹配过程做准备。
cv2.DescriptorMatcher有几种执行匹配的方法,并且所有这些方法都有检测和跟踪模式的重载。 cv2.DescriptorMatcher.match用于获取描述符之间的单个最佳对应关系。 cv2.DescriptorMatcher.knnMatch和cv2.DescriptorMatcher.radiusMatch返回多个描述符之间的最佳对应关系。
查找最佳描述符匹配的最简单,最明显的方法是只比较所有可能的对,然后选择最佳的。 不用说,这种方法非常慢。 但是,如果您决定使用它(例如,作为参考),则需要调用cv2.BFMatcher_create函数。 它采用一种距离度量进行描述符比较,并启用交叉检查标志。
要创建更智能,更快的匹配器,您需要调用cv2.FlannBasedMatcher。 默认情况下,它将使用默认参数创建 KD 树索引。 要创建其他类型的匹配器并设置其参数,您需要为cv2.FlannBasedMatcher函数传递两个字典。 首先,字典描述了索引描述符及其参数的算法。 第二个参数描述了寻找最佳匹配的过程。
启动代码后,您将获得类似于以下内容的图像:

寻找可靠的匹配 - 交叉检查和比率测试
在本秘籍中,您将学习如何使用交叉检查和比率测试来匹配过滤器关键点。 这些技术可用于过滤不良匹配并改善已建立通信的整体质量。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import matplotlib.pyplot as plt
- 加载测试图像:
img0 = cv2.imread('../data/Lena.png', cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('../data/Lena_rotated.png', cv2.IMREAD_GRAYSCALE)
- 创建检测器,检测关键点和计算机描述符:
detector = cv2.ORB_create(100)
kps0, fea0 = detector.detectAndCompute(img0, None)
kps1, fea1 = detector.detectAndCompute(img1, None)
- 使用
k = 2创建 K 最近邻描述符匹配器,然后从左到右查找匹配项,反之亦然:
matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING, False)
matches01 = matcher.knnMatch(fea0, fea1, k=2)
matches10 = matcher.knnMatch(fea1, fea0, k=2)
- 使用比率测试创建用于过滤器匹配的函数,并过滤所有匹配项:
def ratio_test(matches, ratio_thr):
good_matches = []
for m in matches:
ratio = m[0].distance / m[1].distance
if ratio < ratio_thr:
good_matches.append(m[0])
return good_matches
RATIO_THR = 0.7 # Lower values mean more aggressive filtering.
good_matches01 = ratio_test(matches01, RATIO_THR)
good_matches10 = ratio_test(matches10, RATIO_THR)
- 进行交叉检查匹配测试-只保留从左到右和从右到左列表中都存在的那些:
good_matches10_ = {(m.trainIdx, m.queryIdx) for m in good_matches10}
final_matches = [m for m in good_matches01 if (m.queryIdx, m.trainIdx)
in good_matches10_]
- 可视化结果:
dbg_img = cv2.drawMatches(img0, kps0, img1, kps1, final_matches, None)
plt.figure()
plt.imshow(dbg_img[:,:,[2,1,0]])
plt.tight_layout()
plt.show()
工作原理
在此秘籍中,我们实现了两种启发式方法来过滤不良匹配。 第一个是比率测试。 它检查最佳匹配项是否明显好于次优匹配项。 通过比较匹配分数来执行检查。 使用cv2.BFMatcher类的knnMatch方法,找到每个关键点的两个最佳匹配。
第二种启发式方法是交叉检查测试。 对于A和B这两个图像,它检查A中关键点在B中找到的匹配项是否相同。 在A中找到了B中的关键点。 保留在两个方向上找到的对应关系,并删除其他对应关系。
以下是预期的输出:

基于模型的匹配过滤 - RANSAC
在本秘籍中,您将学习如何使用随机样本共识(RANSAC)算法在两个图像之间进行单应性转换的情况下,稳健地过滤两个图像中的关键点之间的匹配 。 此技术有助于过滤出不正确的匹配项,而仅在两个图像之间保留满足运动模型的匹配项。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
import matplotlib.pyplot as plt
- 加载测试图像:
img0 = cv2.imread('../data/Lena.png', cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('../data/Lena_rotated.png', cv2.IMREAD_GRAYSCALE)
- 检测关键点和计算机描述符:
detector = cv2.ORB_create(100)
kps0, fea0 = detector.detectAndCompute(img0, None)
kps1, fea1 = detector.detectAndCompute(img1, None)
matcher = cv2.BFMatcher_create(cv2.NORM_HAMMING, False)
matches = matcher.match(fea0, fea1)
- 将单应性模型牢固地拟合到找到的关键点对应关系中,并获得内部匹配的掩码:
pts0 = np.float32([kps0[m.queryIdx].pt for m in matches]).reshape(-1,2)
pts1 = np.float32([kps1[m.trainIdx].pt for m in matches]).reshape(-1,2)
H, mask = cv2.findHomography(pts0, pts1, cv2.RANSAC, 3.0)
- 可视化结果:
plt.figure()
plt.subplot(211)
plt.axis('off')
plt.title('all matches')
dbg_img = cv2.drawMatches(img0, kps0, img1, kps1, matches, None)
plt.imshow(dbg_img[:,:,[2,1,0]])
plt.subplot(212)
plt.axis('off')
plt.title('filtered matches')
dbg_img = cv2.drawMatches(img0, kps0, img1, kps1, [m for i,m in enumerate(matches) if mask[i]], None)
plt.imshow(dbg_img[:,:,[2,1,0]])
plt.tight_layout()
plt.show()
工作原理
在此秘籍中,我们使用鲁棒的 RANSAC 算法估计两个图像之间的单应性模型参数。 通过带有cv2.RANSAC参数的cv2.findHomography函数来完成。 该函数返回通过点对应关系以及 Inliers 遮罩估计的单应变换。 内线遮罩处理满足估计运动模型且具有足够低误差的对应关系。 在我们的情况下,误差被计算为匹配点和根据运动模型转换的相应点之间的欧几里得距离。
以下是预期的输出:

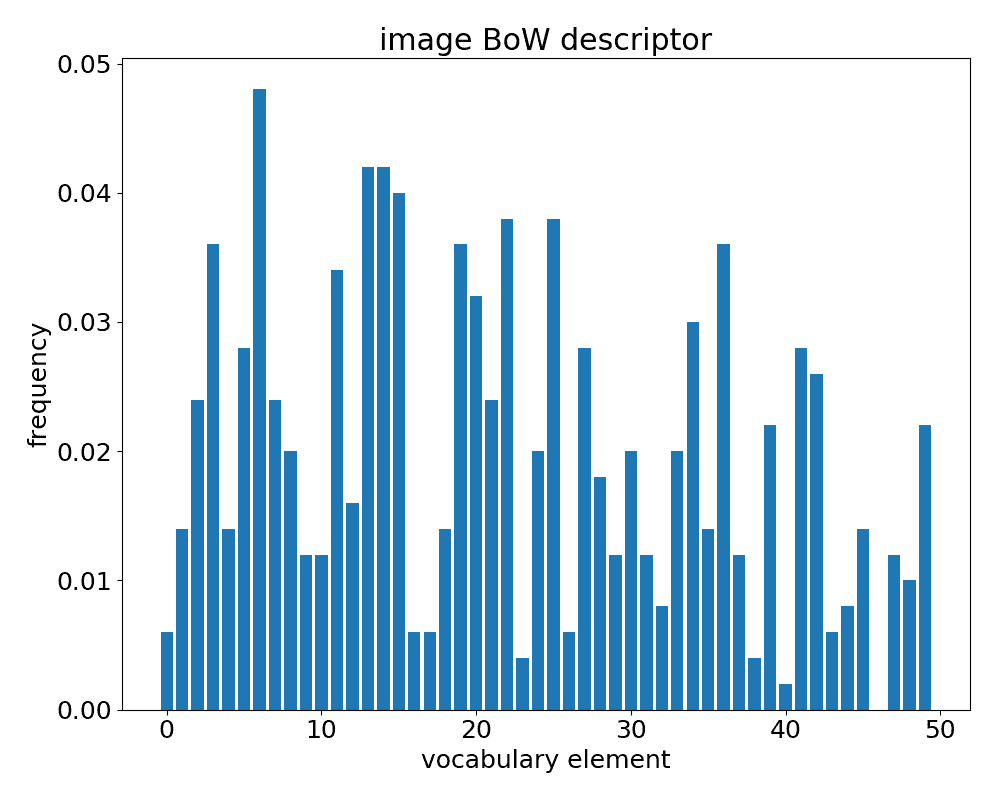
用于构造全局图像描述符的 BoW 模型
在本秘籍中,您将学习如何应用词袋(BoW)模型来计算全局图像描述符。 该技术可用于构建机器学习模型以解决图像分类问题。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
操作步骤
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
import matplotlib.pyplot as plt
- 加载两个训练图像:
img0 = cv2.imread('../data/people.jpg', cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('../data/face.jpeg', cv2.IMREAD_GRAYSCALE)
- 检测每个训练图像的关键点和计算机描述符:
detector = cv2.ORB_create(500)
_, fea0 = detector.detectAndCompute(img0, None)
_, fea1 = detector.detectAndCompute(img1, None)
descr_type = fea0.dtype
- 构造 BoW 词汇表:
bow_trainer = cv2.BOWKMeansTrainer(50)
bow_trainer.add(np.float32(fea0))
bow_trainer.add(np.float32(fea1))
vocab = bow_trainer.cluster().astype(descr_type))
- 创建一个用于计算全局图像 BoW 描述符的对象:
bow_descr = cv2.BOWImgDescriptorExtractor(detector, cv2.BFMatcher(cv2.NORM_HAMMING))
bow_descr.setVocabulary(vocab)
- 加载测试图像,找到关键点,然后计算全局图像描述符:
img = cv2.imread('../data/Lena.png', cv2.IMREAD_GRAYSCALE)
kps = detector.detect(img, None)
descr = bow_descr.compute(img, kps)
- 可视化描述符:
plt.figure(figsize=(10,8))
plt.title('image BoW descriptor')
plt.bar(np.arange(len(descr[0])), descr[0])
plt.xlabel('vocabulary element')
plt.ylabel('frequency')
plt.tight_layout()
plt.show()
工作原理
词袋模型分为两个阶段。 在训练阶段,我们会收集训练图像的本地图像描述符(在我们的示例中为img0和img1)并将它们聚集成词汇。 在第二阶段,将在输入图像中找到的本地描述符与词汇表所有单词进行比较,并列出每个单词出现的频率列表(例如,选择为最接近的单词) ),例如,频率向量,它形成了全局图像描述符。
以下是预期的输出:
八、图像和视频处理
本章包含以下方面的秘籍:
- 使用仿射和透视变换使图像变形
- 使用任意变换重新映射图像
- 使用 Lucas-Kanade 算法跟踪帧之间的关键点
- 背景减法
- 将许多图像拼接成全景图
- 使用非本地均值算法对照片降噪
- 构造 HDR 图像
- 通过图像修复消除照片中的缺陷
介绍
通过将一组图像作为一个整体而不是一堆单独的独立图像进行处理,计算机视觉算法可以实现更为出色的结果。 如果已知图像之间的相关性(可能是从不同角度拍摄的某些对象的视频文件中的帧序列),则可以利用它们。 本章使用的算法考虑了帧之间的关系。 这些算法包括背景减法,图像拼接,视频稳定,超重投影和构建 HDR 图像。
使用仿射和透视变换使图像变形
在本秘籍中,我们将介绍两种用于几何变换图像的主要方法:仿射和透视变形。 第一个用于删除简单的几何变换,例如旋转,缩放,平移及其组合,但是它不能将会聚的线变成平行的线。 在这里,透视变换开始起作用。 其目的是消除两条平行线在透视图中汇合时的透视变形。 让我们找出如何在 OpenCV 中使用所有这些转换。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块,打开输入图像,然后复制它:
import cv2
import numpy as np
img = cv2.imread('../data/circlesgrid.png', cv2.IMREAD_COLOR)
show_img = np.copy(img)
- 定义两个函数来实现点选择过程:
selected_pts = []
def mouse_callback(event, x, y, flags, param):
global selected_pts, show_img
if event == cv2.EVENT_LBUTTONUP:
selected_pts.append([x, y])
cv2.circle(show_img, (x, y), 10, (0, 255, 0), 3)
def select_points(image, points_num):
global selected_pts
selected_pts = []
cv2.namedWindow('image')
cv2.setMouseCallback('image', mouse_callback)
while True:
cv2.imshow('image', image)
k = cv2.waitKey(1)
if k == 27 or len(selected_pts) == points_num:
break
cv2.destroyAllWindows()
return np.array(selected_pts, dtype=np.float32)
- 选择图像中的三个点,使用
cv2.getAffineTransform计算仿射变换,然后使用cv2.warpAffine应用仿射变换。 然后,显示结果图像:
show_img = np.copy(img)
src_pts = select_points(show_img, 3)
dst_pts = np.array([[0, 240], [0, 0], [240, 0]], dtype=np.float32)
affine_m = cv2.getAffineTransform(src_pts, dst_pts)
unwarped_img = cv2.warpAffine(img, affine_m, (240, 240))
cv2.imshow('result', np.hstack((show_img, unwarped_img)))
k = cv2.waitKey()
cv2.destroyAllWindows()
- 找到一个仿射逆变换,将其应用并显示结果:
inv_affine = cv2.invertAffineTransform(affine_m)
warped_img = cv2.warpAffine(unwarped_img, inv_affine, (320, 240))
cv2.imshow('result', np.hstack((show_img, unwarped_img, warped_img)))
k = cv2.waitKey()
cv2.destroyAllWindows()
- 使用
cv2.getRotationMatrix2D创建一个旋转比例的仿射扭曲,并将其应用于图像:
rotation_mat = cv2.getRotationMatrix2D(tuple(src_pts[0]), 6, 1)
rotated_img = cv2.warpAffine(img, rotation_mat, (240, 240))
cv2.imshow('result', np.hstack((show_img, rotated_img)))
k = cv2.waitKey()
cv2.destroyAllWindows()
- 在图像中选择四个点,使用
cv2.getPerspectiveTransform创建透视变形矩阵,然后将其应用于图像并显示结果:
show_img = np.copy(img)
src_pts = select_points(show_img, 4)
dst_pts = np.array([[0, 240], [0, 0], [240, 0], [240, 240]], dtype=np.float32)
perspective_m = cv2.getPerspectiveTransform(src_pts, dst_pts)
unwarped_img = cv2.warpPerspective(img, perspective_m, (240, 240))
cv2.imshow('result', np.hstack((show_img, unwarped_img)))
k = cv2.waitKey()
cv2.destroyAllWindows()
这个怎么运作
仿射变换和透视图变换本质上都是矩阵乘法运算,其中元素的位置被某些扭曲矩阵重新映射。 因此,要应用变换,我们需要计算这样的翘曲矩阵。 对于仿射变换,可以使用cv2.getAffineTransform函数完成。 它以两组点作为参数:第一个点包含变换之前的三个点,第二个点包含变形后的三个对应点。 集合中点的顺序确实很重要,两个数组的点顺序应该相同。 要在透视扭曲的情况下创建变换矩阵,可以应用cv2.getPerspectiveTransform。
同样,它在扭曲前后接受两组点,但是点集的长度应为4。 这两个函数都返回转换矩阵,但是它们的形状不同:cv2.getAffineTransform计算2x3矩阵,cv2.getPerspectiveTransform计算3x3矩阵。
要应用计算的转换,我们需要调用相应的 OpenCV 函数。 为了进行仿射变形,使用了cv2.warpAffine。 它获取输入图像,2x3转换矩阵,输出图像大小,像素插值模式,边界外推模式和边界外推值。 cv2.warpPerspective用于应用透视变换。 其参数与cv2.warpAffine的含义相同。 唯一的区别是转换矩阵(第二个参数)必须为3x3。 这两个函数都返回变形的图像。
有两个与仿射变换相关的有用函数:cv2.invertAffineTransform和cv2.getRotationMatrix2D。 第一种是在您进行仿射变换并且需要获得逆仿射(也就是仿射)时使用。 它采用此现有的仿射变换并返回反变换。 cv2.getRotationMatrix2D不太通用,但经常用于仿射变换-缩放旋转。 此函数采用以下参数:(x,y)格式的旋转中心点,旋转角度和比例因子,并返回2x3仿射变换矩阵。 该矩阵可用作cv2.warpAffine中的相应参数。
启动代码后,您将获得类似于以下内容的图像:

图中的第一行是具有三个选定点及其对应的仿射变换的输入图像。 第二行是逆变换和带比例变换的旋转的结果; 第三行包含具有四个选定点的输入图像,是透视变换的结果。
使用任意变换重新映射图像
在本秘籍中,您将学习如何使用每像素映射来变换图像。 这是一项非常通用的功能,已在许多计算机视觉应用中使用,例如图像拼接,相机帧不失真以及许多其他功能。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import math
import cv2
import numpy as np
- 加载测试图像:
img = cv2.imread('../data/Lena.png')
- 准备每个像素的变换图:
xmap = np.zeros((img.shape[1], img.shape[0]), np.float32)
ymap = np.zeros((img.shape[1], img.shape[0]), np.float32)
for y in range(img.shape[0]):
for x in range(img.shape[1]):
xmap[y,x] = x + 30 * math.cos(20 * x / img.shape[0])
ymap[y,x] = y + 30 * math.sin(20 * y / img.shape[1])
- 重新映射源图像:
remapped_img = cv2.remap(img, xmap, ymap, cv2.INTER_LINEAR, None, cv2.BORDER_REPLICATE)
- 可视化结果:
plt.figure(0)
plt.axis('off')
plt.imshow(remapped_img[:,:,[2,1,0]])
plt.show()
这个怎么运作
通用的逐像素转换是通过cv2.remap函数实现的。 它接受一个源图像和两个映射(可以作为具有两个通道的一个映射来传递),并返回转换后的图像。 该函数还接受指定必须执行像素值内插和外推的参数。 在我们的情况下,我们指定双线性插值,超出范围的值将替换为最近的(空间上)范围内的像素值。 该函数非常通用,通常用作许多计算机视觉应用的构建块。
以下是预期的结果:
使用 Lucas-Kanade 算法跟踪帧之间的关键点
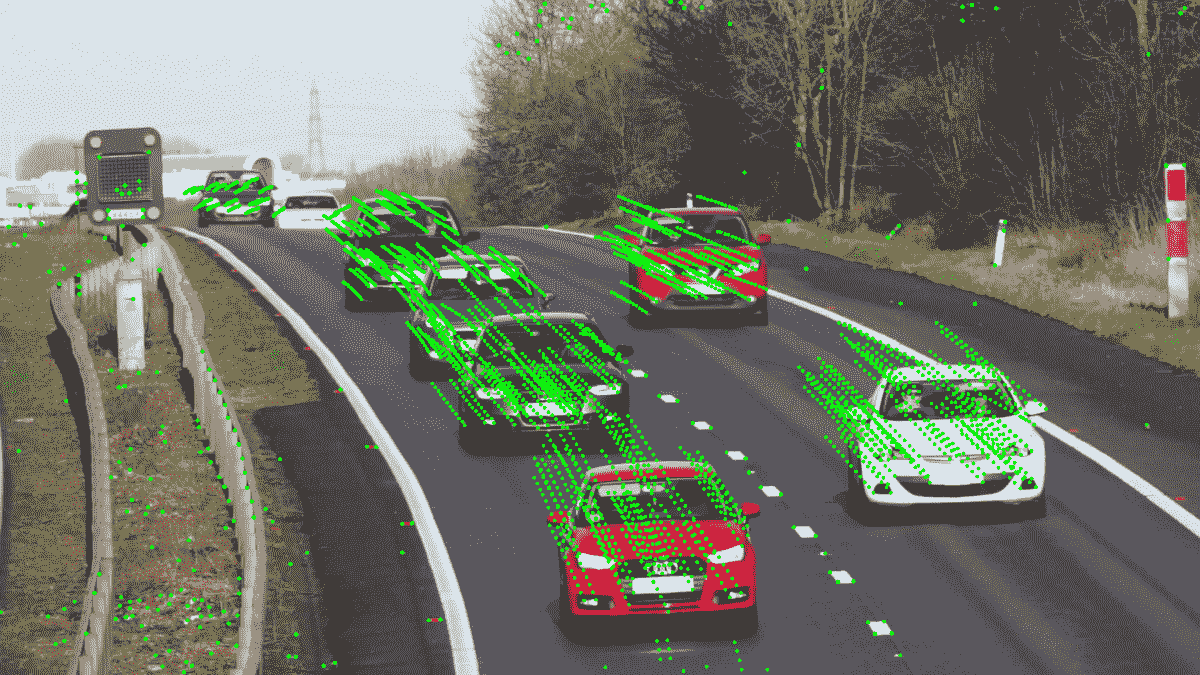
在本秘籍中,您将学习如何使用稀疏的 Lucas-Kanade 光流算法来跟踪视频中帧之间的关键点。 此功能在许多计算机视觉应用中很有用,例如对象跟踪和视频稳定化。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
- 打开测试视频并初始化辅助变量:
video = cv2.VideoCapture('../data/traffic.mp4')
prev_pts = None
prev_gray_frame = None
tracks = None
- 开始阅读视频中的帧,将每个图像转换为灰度:
while True:
retval, frame = video.read()
if not retval: break
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
- 使用稀疏的 Lucas-Kanade 光流算法跟踪上一帧的关键点,或者,如果您刚刚启动或按下
C,请检测关键点,以便在下一帧中可以跟踪一些内容:
if prev_pts is not None:
pts, status, errors = cv2.calcOpticalFlowPyrLK(
prev_gray_frame, gray_frame, prev_pts, None, winSize=(15,15), maxLevel=5,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
good_pts = pts[status == 1]
if tracks is None: tracks = good_pts
else: tracks = np.vstack((tracks, good_pts))
for p in tracks:
cv2.circle(frame, (p[0], p[1]), 3, (0, 255, 0), -1)
else:
pts = cv2.goodFeaturesToTrack(gray_frame, 500, 0.05, 10)
pts = pts.reshape(-1, 1, 2)
- 记住当前点和当前框架。 现在可视化结果并处理键盘输入:
prev_pts = pts
prev_gray_frame = gray_frame
cv2.imshow('frame', frame)
key = cv2.waitKey() & 0xff
if key == 27: break
if key == ord('c'):
tracks = None
prev_pts = None
- 关闭所有窗口:
cv2.destroyAllWindows()
这个怎么运作
在本秘籍中,我们打开一个视频,使用我们先前使用的cv2.goodFeaturesToTrack函数检测初始关键点,并使用稀疏的 Lucas-Kanade 光流算法开始跟踪点,该算法已在 OpenCV 中通过cv2.calcOpticalFlowPyrLK函数实现 。 OpenCV 实现了该算法的金字塔形式,这意味着首先在较小尺寸的图像中计算光流,然后在较大的图像中进行精修。 金字塔大小由maxLevel参数控制。 该函数还采用 Lucas-Kanade 算法的参数,例如窗口大小(winSize)和终止条件。 其他参数是前一帧和当前帧,以及来自前一帧的关键点。 这些函数返回当前帧中的跟踪点,成功标志数组和跟踪错误。
下图是积分跟踪结果的示例:
背景扣除
如果您有一个稳定场景的视频,其中有一些物体在四处移动,则可以将静止的背景与变化的前景分开。 在这里,我们将向您展示如何在 OpenCV 中进行操作。
准备
在继续此秘籍之前,您需要安装带有 Contrib 模块的 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 定义一个打开视频文件的函数,并对每个帧应用一些背景减影算法:
def split_image_fgbg(subtractor, open_sz=(0,0), close_sz=(0,0), show_bg=False, show_shdw=False):
kernel_open = kernel_close = None
if all(i > 0 for i in open_sz):
kernel_open = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, open_sz)
if all(i > 0 for i in close_sz):
kernel_close = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, close_sz)
cap = cv2.VideoCapture('../data/traffic.mp4')
while True:
status_cap, frame = cap.read()
if not status_cap:
break
frame = cv2.resize(frame, None, fx=0.5, fy=0.5)
fgmask = subtractor.apply(frame)
objects_mask = (fgmask == 255).astype(np.uint8)
shadows_mask = (fgmask == 127).astype(np.uint8)
if kernel_open is not None:
objects_mask = cv2.morphologyEx(objects_mask, cv2.MORPH_OPEN, kernel_open)
if kernel_close is not None:
objects_mask = cv2.morphologyEx(objects_mask, cv2.MORPH_CLOSE, kernel_close)
if kernel_open is not None:
shadows_mask = cv2.morphologyEx(shadows_mask, cv2.MORPH_CLOSE, kernel_open)
foreground = frame
foreground[objects_mask == 0] = 0
if show_shdw:
foreground[shadows_mask > 0] = (0, 255, 0)
cv2.imshow('foreground', foreground)
if show_bg:
background = fgbg.getBackgroundImage()
if background is not None:
cv2.imshow('background', background)
if cv2.waitKey(30) == 27:
break
cap.release()
cv2.destroyAllWindows()
- 将由 KadewTraKuPong 和 Bowden 创建的基于高斯混合的背景/前景分割算法应用于视频:
fgbg = cv2.bgsegm.createBackgroundSubtractorMOG()
split_image_fgbg(fgbg, (2, 2), (40, 40))
- 创建由 Zoran Zivkovic 开发的高斯混合分割算法的改进版本的实例:
fgbg = cv2.createBackgroundSubtractorMOG2()
split_image_fgbg(fgbg, (3, 3), (30, 30), True)
- 使用 Godbehere,Matsukawa 和 Goldberg 的背景减除算法创建背景遮罩:
fgbg = cv2.bgsegm.createBackgroundSubtractorGMG()
split_image_fgbg(fgbg, (5, 5), (25, 25))
- 根据 Sagi Zeevi 的建议,应用基于计数的背景减法算法:
fgbg = cv2.bgsegm.createBackgroundSubtractorCNT()
split_image_fgbg(fgbg, (5, 5), (15, 15), True)
- 使用基于最近邻方法的背景分割技术:
fgbg = cv2.createBackgroundSubtractorKNN()
split_image_fgbg(fgbg, (5, 5), (25, 25), True)
这个怎么运作
所有背景减法器都实现cv2.BackgroundSubtractor接口,因此它们都有一定的方法集:
cv2.BackgroundSubtractor.apply:获取分割遮罩cv2.BackgroundSubtractor.getBackgroundImage:检索背景图像
apply方法接受彩色图像作为参数并返回背景遮罩。 此遮罩通常包含三个值:0用于背景像素,255用于前景像素和127用于阴影像素。 阴影像素是背景中强度较低的像素。 值得一提的是,并非所有减法器都支持阴影像素分析。
getBackgroundImage返回背景图像,如果没有移动的物体,则应返回背景图像。 同样,只有少数减法器能够计算这样的图像。
毫不奇怪,所有减法算法都有内部参数。 幸运的是,这些参数中的许多都可以与默认值一起很好地工作。 历史参数是可以首先调整的参数之一。 基本上,这是减法器开始生成分段掩码之前需要分析的帧数。 因此,通常您会获得第一帧的完整背景遮罩。
您已经注意到,我们将形态学操作应用于运动对象遮罩。 由于几个原因,我们需要此步骤。 首先,运动物体的某些部分可能质地较差。 由于所有相邻像素都非常相似,因此很难检测运动。 第二个原因是我们的背景分割检测器不够理想。 错误地将移动物体的一部分标记为背景会导致错误。 应用形态学可以帮助我们使用先验信息,这些信息不能仍然是运动对象中的一部分。
上面的代码生成的图像类似于下图:

将许多图像拼接成全景图
OpenCV 有很多计算机视觉算法。 其中一些是低级的,而另一些则在特殊情况下使用。 但是有功能,可以使用日常应用将许多算法结合在一起。 这些管道之一是全景拼接。 这个相当复杂的过程可以在 OpenCV 中轻松完成,并得到不错的结果。 此秘籍向您展示如何使用 OpenCV 工具创建自己的全景图。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载我们将要合并为全景图的图像:
images = []
images.append(cv2.imread('../data/panorama/0.jpg', cv2.IMREAD_COLOR))
images.append(cv2.imread('../data/panorama/1.jpg', cv2.IMREAD_COLOR))
- 创建一个全景拼接器,将图像传递给它,然后解析结果:
stitcher = cv2.createStitcher()
ret, pano = stitcher.stitch(images)
if ret == cv2.STITCHER_OK:
cv2.imshow('panorama', pano)
cv2.waitKey()
cv2.destroyAllWindows()
else:
print('Error during stiching')
这个怎么运作
cv2.createStitcher建立了全景拼接算法的实例。 要将其应用于全景图创建,您需要调用其stitch方法。 此方法接受要组合的图像数组,并返回拼接结果状态以及全景图像。 状态可能具有以下值之一:
cv2.STITCHER_OKcv2.STITCHER_ERR_NEED_MORE_IMGScv2.STITCHER_ERR_HOMOGRAPHY_EST_FAILcv2.STITCHER_ERR_CAMERA_PARAMS_ADJUST_FAIL
第一个值表示成功创建了全景图。 其他值告诉您全景图尚未合成,并向您提示了可能的原因。
拼接成功与否取决于输入图像。 它们应该具有重叠的区域。 重叠的区域越多,算法就越容易匹配框架并将其正确映射到最终全景图。 另外,最好从旋转的相机拍摄照片。 相机的微小移动是可以的,但是是不希望的。
执行代码后,您将看到类似于下图的图像:

正如您在图中看到的,反射并没有破坏最终结果:该算法成功处理了这种情况。 由于图像具有大的重叠区域和许多具有丰富纹理的区域,因此可以实现此结果。 对于没有纹理的物体,反射可能会受到阻碍。
使用非本地均值算法的照片降噪
在本秘籍中,您将学习如何使用非局部均值算法消除图像中的噪点。 当照片受到过多噪点的影响时,此功能很有用,因此有必要将其删除以获得更好的图像。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
import matplotlib.pyplot as plt
- 加载测试图像:
img = cv2.imread('../data/Lena.png')
- 产生随机的高斯噪声:
noise = 30 * np.random.randn(*img.shape)
img = np.uint8(np.clip(img + noise, 0, 255))
- 使用非本地均值算法执行去噪:
denoised_nlm = cv2.fastNlMeansDenoisingColored(img, None, 10)
- 可视化结果:
plt.figure(0, figsize=(10,6))
plt.subplot(121)
plt.axis('off')
plt.title('original')
plt.imshow(img[:,:,[2,1,0]])
plt.subplot(122)
plt.axis('off')
plt.title('denoised')
plt.imshow(denoised_nlm[:,:,[2,1,0]])
plt.show()
这个怎么运作
非本地均值算法是通过 OpenCV 中的一系列函数实现的:cv2.fastNlMeansDenoising,cv2.fastNlMeansDenoisingColored,cv2.fastNlMeansMulti和cv2.fastNlMeansDenoisingColoredMulti。 这些函数可以拍摄一张图像或多张图像(灰度或彩色)。 在此秘籍中,我们使用了cv2.fastNlMeansDenoisingColored函数,该函数会拍摄一张 BGR 图像并返回去噪的图像。 该函数采用一些参数,其中参数h代表降噪强度; 较高的值可减少噪点,但图像更平滑。 其他参数指定非本地均值算法参数,例如模板模式大小和搜索窗口空间(相应命名)。
下图显示了预期的结果:

构造 HDR 图像
几乎所有现代相机甚至手机都具有神奇的 HDR 模式,它产生了真正的奇迹效果-照片中没有曝光不足或曝光过度的区域。 HDR(高动态范围),您可以在 OpenCV 中重现这样的结果! 本秘籍告诉您有关 HDR 成像功能以及如何正确使用它们的信息。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载图像和曝光时间:
imgs_names = ['33', '100', '179', '892', '1560', '2933']
exp_times = []
images = []
for name in imgs_names:
exp_times.append(1/float(name))
images.append(cv2.imread('../data/hdr/%s.jpg' % name, cv2.IMREAD_COLOR))
exp_times = np.array(exp_times).astype(np.float32)
- 恢复 CRF:
calibrate = cv2.createCalibrateDebevec()
response = calibrate.process(images, exp_times)
- 计算 HDR 图像:
merge_debevec = cv2.createMergeDebevec()
hdr = merge_debevec.process(images, exp_times, response)
- 将 HDR 图像转换为低动态范围(LDR)图像以能够显示它:
tonemap = cv2.createTonemapDurand(2.4)
ldr = tonemap.process(hdr)
ldr = cv2.normalize(ldr, None, 0, 1, cv2.NORM_MINMAX)
cv2.imshow('ldr', ldr)
cv2.waitKey()
cv2.destroyAllWindows()
- 应用此技术合并具有各种曝光度的图像:
merge_mertens = cv2.createMergeMertens()
fusion = merge_mertens.process(images)
fusion = cv2.normalize(fusion, None, 0, 1, cv2.NORM_MINMAX)
cv2.imshow('fusion', fusion)
cv2.waitKey()
cv2.destroyAllWindows()
这个怎么运作
首先,您需要具有一组已知曝光时间不同的图像。 现代相机将大量信息(包括曝光时间)存储在图像文件中,因此值得检查图像的属性。
计算 HDR 图像时,首先需要恢复 CRF(相机响应函数),这是每种颜色的实际强度与像素强度(在[0, 255]范围内)之间的映射。 通道。 通常它是非线性的,因此不可能简单地将不同曝光的图像组合在一起。 可以通过使用cv2.createCalibrateDebevec创建校准算法的实例来完成。 创建校准实例后,您需要调用其process方法并传递图像数组和曝光时间数组。 process方法返回摄像机的 CRF。
下一步是创建 HDR 图像。 为此,我们应该通过调用cv2.createMergeDebevec获得照片合并算法的实例。 构造对象时,我们需要调用其process方法并传递图像,曝光时间和 CRF 作为参数。 结果,我们获得了 HDR 图像,该图像无法用imshow显示,但是可以用imwrite以.hdr格式保存并在专用工具中查看。
现在我们需要显示我们的 HDR 图像。 为此,我们需要将其动态范围正确地压缩到 8 位。 此过程称为音调映射。 要执行此过程,您需要使用cv2.createTonemapDurand构建一个音调映射对象并调用其process函数。 此函数接受 HDR 图像并返回浮点图像。
还有另一种方法来合并具有不同曝光度的照片。 您需要使用cv2.createMergeMertens函数创建另一个算法实例。 生成的对象具有process方法,该方法合并了我们的图像-只需将它们作为参数传递即可。 函数工作的结果是合并图像。
从该秘籍启动代码后,您将看到类似于下图所示的图像:

图的第一行是两张具有不同曝光量的原始图像:左一张的曝光时间长,而右一张的曝光时间短。 结果,我们可以看到灯泡旁边的台灯标签和 QR 码。 最下面的行包含秘籍代码中两种方法的结果-在两种情况下,我们都可以看到所有详细信息。
通过图像修复消除照片中的缺陷
有时,照片图像有缺陷。 对于已扫描的旧照片尤其如此:它们可能有划痕,斑点和污点。 所有这些缺陷都会阻碍照片的欣赏。 根据其周围环境重建图像各部分的过程称为“修复”,而 OpenCV 具有此算法的实现。 在这里,我们将介绍利用此 OpenCV 功能的方法。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 定义一个封装掩码创建的类:
class MaskCreator:
def __init__(self, image, mask):
self.prev_pt = None
self.image = image
self.mask = mask
self.dirty = False
self.show()
cv2.setMouseCallback('mask', self.mouse_callback)
def show(self):
cv2.imshow('mask', self.image)
def mouse_callback(self, event, x, y, flags, param):
pt = (x, y)
if event == cv2.EVENT_LBUTTONDOWN:
self.prev_pt = pt
elif event == cv2.EVENT_LBUTTONUP:
self.prev_pt = None
if self.prev_pt and flags & cv2.EVENT_FLAG_LBUTTON:
cv2.line(self.image, self.prev_pt, pt, (127,)*3, 5)
cv2.line(self.mask, self.prev_pt, pt, 255, 5)
self.dirty = True
self.prev_pt = pt
self.show()
- 加载图像,创建其缺陷版本和遮罩,应用 Inpaint 算法,然后显示结果:
img = cv2.imread('../data/Lena.png')
defect_img = img.copy()
mask = np.zeros(img.shape[:2], np.uint8)
m_creator = MaskCreator(defect_img, mask)
while True:
k = cv2.waitKey()
if k == 27:
break
if k == ord('a'):
res_telea = cv2.inpaint(defect_img, mask, 3, cv2.INPAINT_TELEA)
res_ns = cv2.inpaint(defect_img, mask, 3, cv2.INPAINT_NS)
cv2.imshow('TELEA vs NS', np.hstack((res_telea, res_ns)))
if k == ord('c'):
defect_img[:] = img
mask[:] = 0
m_creator.show()
cv2.destroyAllWindows()
这个怎么运作
要在 OpenCV 中修复图像,需要使用cv2.inpaint函数。 它接受四个参数:
- 有缺陷的图像:它必须是 8 位彩色或灰度级图像
- 缺陷遮罩:它必须是 8 位单通道,并且必须与第一个参数中的图像大小相同
- 邻域半径:损坏的像素周围区域的大小,应在计算其颜色时使用
- 修复模式:修复算法的类型
缺陷遮罩应包含原始图像上像素的非零值,需要恢复该值。 邻域半径是在修复过程中考虑的算法周围的像素范围; 它应具有较小的值,以防止剧烈的模糊效果。 修复模式必须为以下值之一:cv2.INPAINT_TELEA或cv2.INPAINT_NS。 根据具体情况,一种算法可能会比另一种算法更好,反之亦然,因此最好比较两种算法的结果并选择最佳算法。 cv2.inpaint返回生成的修复图像。
启动代码后,您将看到类似的图像:

如上图所示,最容易修复的缺陷是很小或几乎没有纹理的区域,这不足为奇。 修复算法没有实现任何魔术,因此在图像的复杂部分中存在可见但有色的瑕疵。
九、多视图几何
本章涵盖以下秘籍:
- 针孔相机模型校准
- 鱼眼镜头模型校准
- 立体相机校准 - 外在性估计
- 失真点和不失真点
- 消除图像中的镜头失真效果
- 通过三角测量从两个观测值还原 3D 点
- 通过 PnP 算法找到相对的相机对象姿态
- 通过立体校正对齐两个视图
- 对极几何 - 计算基本和本质矩阵
- 将基本矩阵分解为旋转和平移
- 估计立体图像的视差图
- 特例 2 - 视图几何 - 估计单应变换
- 平面场景 - 将单应性分解为旋转和平移
- 旋转相机 CAS - 从单应性估计相机旋转
介绍
将 3D 场景投影到 2D 图像上(换句话说,使用照相机)可以消除有关场景对象离摄影师的距离的信息。 但是在某些情况下,可以还原 3D 信息。 这不仅需要了解有关对象或摄像机配置的信息,还需要具有摄像机的固有参数。 本章介绍了从相机校准到 3D 对象位置重建和深度图检索的所有 2D 图像获取 3D 信息的必要步骤。
针孔相机模型校准
针孔相机模型以及其他模型都是最简单的数学模型,但它可以应用于许多实际的摄影设备。 此秘籍告诉您如何校准相机,例如,找到其固有参数和失真系数。
准备
在继续此秘籍之前,您需要安装 OpenCV(3.3 版或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 从相机捕获帧,检测每个帧上的棋盘图案,并累积帧和角,直到我们有足够多的样本:
cap = cv2.VideoCapture(0)
pattern_size = (10, 7)
samples = []
while True:
ret, frame = cap.read()
if not ret:
break
res, corners = cv2.findChessboardCorners(frame, pattern_size)
img_show = np.copy(frame)
cv2.drawChessboardCorners(img_show, pattern_size, corners, res)
cv2.putText(img_show, 'Samples captured: %d' % len(samples), (0,
40),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)
cv2.imshow('chessboard', img_show)
wait_time = 0 if res else 30
k = cv2.waitKey(wait_time)
if k == ord('s') and res:
samples.append((cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY),
corners))
elif k == 27:
break
cap.release()
cv2.destroyAllWindows()
- 使用
cv2.cornerSubPix细化所有检测到的角点:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
for i in range(len(samples)):
img, corners = samples[i]
corners = cv2.cornerSubPix(img, corners, (10, 10), (-1,-1), criteria)
- 通过将所有精确的角点传递到
cv2.calibrateCamera来找到相机的固有参数:
pattern_points = np.zeros((np.prod(pattern_size), 3), np.float32)
pattern_points[:, :2] = np.indices(pattern_size).T.reshape(-1, 2)
images, corners = zip(*samples)
pattern_points = [pattern_points]*len(corners)
rms, camera_matrix, dist_coefs, rvecs, tvecs = \
cv2.calibrateCamera(pattern_points, corners, images[0].shape,
None, None)
np.save('camera_mat.npy', camera_matrix)
np.save('dist_coefs.npy', dist_coefs)
这个怎么运作
相机校准旨在找到两组固有参数:相机矩阵和失真系数。 相机矩阵确定 3D 点的坐标如何映射到图像中的无量纲像素坐标,但是实际的图像镜头也会使图像变形,因此直线会转变为曲线。 失真系数使您可以消除这种扭曲。
整个相机校准过程可以分为三个阶段:
- 收集大量数据,例如图像和检测到的棋盘图案
- 提炼棋盘边角坐标
- 优化相机参数以使其与观察到的变形和投影相匹配
为了收集用于相机校准的数据,您需要检测特定大小的棋盘图案,并累积成对的图像和找到的角点的坐标。 从第 4 章,“对象检测和机器学习”的“检测棋盘和圆形网格图案”,cv2.findChessboardCorners中可以知道,实现了棋盘角检测。 有关更多信息,请参见第 4 章“对象检测和机器学习”。 值得一提的是,棋盘上的角是由两个黑色正方形形成的角,在cv2.findChessboardCorners中传递的图案大小应与真实棋盘图案中的图案大小相同。 样本的数量及其沿视场的分布也非常重要。 在实际情况下,50 到 100 个样本就足够了。*
下一步是细化角的坐标。 由于cv2.findChessboardCorners不能给出非常准确的结果,因此需要此阶段,因此我们需要找到实际的角位置。 cv2.cornerSubPix以子像素精度为角坐标提供精度。 它接受以下参数:
- 灰度图像
- 检测到的角点的大致坐标
- 细化区域的大小以找到更准确的角点位置
- 细化区域中心的区域大小,可以忽略
- 停止提炼过程的标准
角的粗坐标是cv2.findChessboardCorners返回的坐标。 细化区域应较小,但应包括角点的实际位置; 否则,返回粗角。 要忽略的区域的大小应小于细化区域,并且可以通过传递(-1, -1)作为其值来禁用。 停止条件可以是以下类型之一cv2.TERM_CRITERIA_EPS或cv2.TERM_CRITERIA_MAX_ITER或两者的组合。 cv2.TERM_CRITERIA_EPS确定前一个和下一个角点位置的差异。 如果实际差异小于定义的差异,则将停止该过程。 cv2.TERM_CRITERIA_MAX_ITER确定最大迭代次数。 cv2.cornerSubPix返回相同数量的带有精确坐标的角。
一旦我们确定了角点的位置,就可以找到相机的参数了。 cv2.calibrateCamera解决了这个问题。 您需要向此函数传递一些参数,这些参数列出如下:
- 所有样本的对象点坐标
- 所有样本的角点坐标
- (宽度,高度)格式的图像形状
- 两个数组保存平移和旋转向量(可以设置为 None)
- 标志和停止条件(均具有默认值)
对象点是棋盘坐标系中棋盘角的 3D 坐标。 因为我们对每个帧使用相同的模式,所以角的 3D 坐标是相同的,并且因为我们使用等距分布的角,所以 3D 坐标也等距分布在平面上(所有点的z = 0)。 角点之间的实际距离无关紧要,因为摄影机会消除 z 坐标(物体距摄影机的距离),因此它可以是较小但更近的图案,也可以是较大但更远的图案-图像相同。 cv2.calibrateCamera返回五个值:所有样本的平均重投影误差,相机矩阵,失真系数,旋转和所有样本的平移向量。 重投影误差是图像中某个角与该角的 3D 点的投影之间的差。 理想情况下,角点的投影及其在图像中的原始位置应相同,但由于噪声而存在差异。 该差异以像素为单位。 该差异越小,校准效果越好。 相机矩阵的形状为3x3。 失真系数的数量取决于标记,默认情况下等于 5。
执行此代码后,您将看到以下图片:

鱼眼镜头模型校准
如果您的相机具有宽广的视角,并因此导致强烈的变形,则需要使用鱼眼镜头模型。 OpenCV 提供了与鱼眼镜头模型一起使用的功能。 让我们回顾一下如何在 OpenCV 中校准此类摄像机。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 从相机捕获帧,检测每个帧上的棋盘图案,并累积帧和角,直到我们有足够多的样本:
cap = cv2.VideoCapture(0)
pattern_size = (10, 7)
samples = []
while True:
ret, frame = cap.read()
if not ret:
break
res, corners = cv2.findChessboardCorners(frame, pattern_size)
img_show = np.copy(frame)
cv2.drawChessboardCorners(img_show, pattern_size, corners, res)
cv2.putText(img_show, 'Samples captured: %d' % len(samples), (0, 40),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)
cv2.imshow('chessboard', img_show)
wait_time = 0 if res else 30
k = cv2.waitKey(wait_time)
if k == ord('s') and res:
samples.append((cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY), corners))
elif k == 27:
break
cap.release()
cv2.destroyAllWindows()
- 使用
cv2.cornerSubPix细化所有检测到的角点:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
for i in range(len(samples)):
img, corners = samples[i]
corners = cv2.cornerSubPix(img, corners, (10, 10), (-1,-1), criteria)
- 导入必要的模块,打开输入图像,然后复制它:
pattern_points = np.zeros((1, np.prod(pattern_size), 3), np.float32)
pattern_points[0, :, :2] = np.indices(pattern_size).T.reshape(-1, 2)
images, corners = zip(*samples)
pattern_points = [pattern_points]*len(corners)
print(len(pattern_points), pattern_points[0].shape, pattern_points[0].dtype)
print(len(corners), corners[0].shape, corners[0].dtype)
rms, camera_matrix, dis t_coefs, rvecs, tvecs = \
cv2.fisheye.calibrate(pattern_points, corners, images[0].shape, None, None)
np.save('camera_mat.npy', camera_matrix)
np.save('dist_coefs.npy', dist_coefs)
这个怎么运作
鱼眼相机和针孔相机的相机校准程序基本相同,因此强烈建议使用“针孔相机模型校准”秘籍,因为针孔相机盒的所有主要步骤和建议都适用于鱼眼镜头
让我们回顾一下主要区别。 要校准鱼眼模型相机,您需要使用cv2.fisheye.calibrate函数。 它接受与cv2.calibrateCamera相同的参数,但是此函数仅支持其自己的标志值。 幸运的是,此参数具有默认值。
执行此代码的结果是,您将看到类似于以下图像:

立体相机校准 - 外在性估计
在本秘籍中,您将学习如何校准立体对,即使用校准图案的照片估计两个摄像机之间的相对旋转和平移。 在处理立体相机时,将使用此功能-您需要知道装备参数才能重建有关场景的 3D 信息。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import glob
import numpy as np
- 设置图案大小并准备带有图像的列表:
PATTERN_SIZE = (9, 6)
left_imgs = list(sorted(glob.glob('../data/stereo/case1/left*.png')))
right_imgs = list(sorted(glob.glob('../data/stereo/case1/right*.png')))
assert len(left_imgs) == len(right_imgs)
- 找到棋盘点:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
left_pts, right_pts = [], []
img_size = None
for left_img_path, right_img_path in zip(left_imgs, right_imgs):
left_img = cv2.imread(left_img_path, cv2.IMREAD_GRAYSCALE)
right_img = cv2.imread(right_img_path, cv2.IMREAD_GRAYSCALE)
if img_size is None:
img_size = (left_img.shape[1], left_img.shape[0])
res_left, corners_left = cv2.findChessboardCorners(left_img, PATTERN_SIZE)
res_right, corners_right = cv2.findChessboardCorners(right_img, PATTERN_SIZE)
corners_left = cv2.cornerSubPix(left_img, corners_left, (10, 10), (-1,-1),
criteria)
corners_right = cv2.cornerSubPix(right_img, corners_right, (10, 10), (-1,-1),
criteria)
left_pts.append(corners_left)
right_pts.append(corners_right)
- 准备校准图案点:
pattern_points = np.zeros((np.prod(PATTERN_SIZE), 3), np.float32)
pattern_points[:, :2] = np.indices(PATTERN_SIZE).T.reshape(-1, 2)
pattern_points = [pattern_points] * len(left_imgs)
- 估计立体对参数:
err, Kl, Dl, Kr, Dr, R, T, E, F = cv2.stereoCalibrate(
pattern_points, left_pts, right_pts, None, None, None, None, img_size, flags=0)
- 报告校准结果:
print('Left camera:')
print(Kl)
print('Left camera distortion:')
print(Dl)
print('Right camera:')
print(Kr)
print('Right camera distortion:')
print(Dr)
print('Rotation matrix:')
print(R)
print('Translation:')
print(T)
这个怎么运作
要使用 OpenCV 校准立体对,必须同时从两台摄像机捕获校准模式的几张照片。 在我们的案例中,我们使用了9x6的棋盘。 我们使用cv2.findChessboardCorners函数找到板的角,将用于相机参数估计。 我们还需要在其本地坐标系中的校准图案点。 由于我们知道模式的大小及其形状,因此可以显式构造点列表pattern_points。 请注意,此处使用的单位将用于两个摄像机之间的转换向量。
校准本身在cv2.stereoCalibrate函数中执行。 作为输入,它需要一个图像点列表和一个图案点列表。 您还可以为校准参数指定初始猜测,并指定要优化的参数以及要保持不变的参数。 该函数以像素,第一相机参数,第一相机失真系数,第二相机参数,第二相机失真系数,相机之间的旋转和平移以及基本矩阵和基本矩阵的形式返回校准误差。
以下是预期的输出:
Left camera:
[[ 534.36681752 0\. 341.45684657]
[ 0\. 534.29616718 235.72519106]
[ 0\. 0\. 1\. ]]
Left camera distortion:
[[ -2.79470900e-01 4.71876981e-02 1.39511507e-03 -1.64158448e-04
7.01729203e-02]]
Right camera:
[[ 537.88729748 0\. 327.29925115]
[ 0\. 537.43063947 250.10021993]
[ 0\. 0\. 1\. ]]
Right camera distortion:
[[-0.28990693 0.12537789 -0.00040656 0.00053461 -0.03844589]]
Rotation matrix:
[[ 0.99998995 0.00355598 0.00273003]
[-0.00354058 0.99997791 -0.00562461]
[-0.00274997 0.00561489 0.99998046]]
Translation:
[[-3.33161159]
[ 0.03706722]
[-0.00420814]]
失真点和非失真点
相机镜头会产生图像失真。 校准过程旨在查找这些变形的参数,以及将 3D 点投影到图像平面上的参数。 此秘籍告诉您如何应用相机矩阵和失真系数以获取未失真的图像点并将其失真。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载相机的相机矩阵和失真系数:
camera_matrix = np.load('../data/pinhole_calib/camera_mat.npy')
dist_coefs = np.load('../data/pinhole_calib/dist_coefs.npy')
- 打开相机拍摄的国际象棋棋盘的照片,然后找到并优化角点:
img = cv2.imread('../data/pinhole_calib/img_00.png')
pattern_size = (10, 7)
res, corners = cv2.findChessboardCorners(img, pattern_size)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
corners = cv2.cornerSubPix(cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),
corners, (10, 10), (-1,-1), criteria)
- 取消扭曲角的坐标并将其转换为 3D 点:
h_corners = cv2.undistortPoints(corners, camera_matrix, dist_coefs)
h_corners = np.c_[h_corners.squeeze(), np.ones(len(h_corners))]
- 将角点的 3D 坐标投影到图像上而不应用失真:
img_pts, _ = cv2.projectPoints(h_corners, (0, 0, 0), (0, 0, 0), camera_matrix, None)
for c in corners:
cv2.circle(img, tuple(c[0]), 10, (0, 255, 0), 2)
for c in img_pts.squeeze().astype(np.float32):
cv2.circle(img, tuple(c), 5, (0, 0, 255), 2)
cv2.imshow('undistorted corners', img)
cv2.waitKey()
cv2.destroyAllWindows()
- 将角点的 3D 坐标投影到图像上并应用镜头变形:
img_pts, _ = cv2.projectPoints(h_corners, (0, 0, 0), (0, 0, 0), camera_matrix, dist_coefs)
for c in img_pts.squeeze().astype(np.float32):
cv2.circle(img, tuple(c), 2, (255, 255, 0), 2)
cv2.imshow('reprojected corners', img)
cv2.waitKey()
cv2.destroyAllWindows()
这个怎么运作
cv2.undistortPoints查找图像中各点的同类坐标。 此函数消除了镜头变形并投影了点,使其处于无量纲坐标。 该函数接受以下参数:图像中的 2D 点数组,3x3相机矩阵,一组失真系数,用于存储结果的对象以及在立体视觉中使用的校正和投影矩阵,并且现在无所谓。 最后三个参数是可选的。 cv2.undistortPoints返回未失真和未投影点的集合。
cv2.undistortPoints返回的点是理想的-它们的坐标是无量纲的,并且不会因镜头而失真。 如果需要将它们投影回去,则需要将它们转换为 3D 点。 为此,我们只需要向每个点添加第三个Z坐标即可。 由于这些点的坐标是同质的,因此Z等于 1。
当我们拥有 3D 点并将其投影到图像上时,cv2.projectPoints开始起作用。 在一般情况下,此函数在某个坐标系中获取点的 3D 坐标,对其进行旋转和平移以获取相机坐标系中的坐标,然后应用相机矩阵和变形系数以找到这些点在图像平面上的投影 。
cv2.>projectPoints的参数包括:某些局部坐标系中的 3D 点数组,从局部坐标系到相机坐标系的转换的旋转和平移向量,3x3相机矩阵,失真系数数组,用于存储结果点的对象,用于存储 Jacobian 值的对象以及宽高比的值。 同样,最后三个参数是可选的,可以省略。 此函数返回 3D 点和 Jacobian 值的投影坐标和变形坐标。 如果要获取没有透镜变形的点的位置,则可以将None传递为变形系数数组的值。
执行此代码的结果是,您将看到类似于以下图像:

图中的绿色圆圈是棋盘角的原始位置。 红色的是角的投影坐标,但没有镜头失真。 浅蓝色点是变形后的投影坐标-它们正好在绿色圆圈的中心。 另外,您可能会注意到,绿色和浅蓝色的圆圈不是在直线上,而是红色的圆圈。 这是镜头变形的影响。 您也许还可以注意到,对于远离图像中心的角,红色和浅蓝色圆圈坐标之间的差异非常明显,尽管靠近图像中心的圆圈几乎相同。 这是由于镜头变形的程度而发生的,这取决于该点距镜头中心的距离。
消除图像中的镜头失真效果
如果需要从整个图像中消除镜头畸变的影响,则需要使用密集的重映射。 本质上,不失真算法以补偿镜头效果的方式扭曲和压缩图像,但是压缩会导致出现空白区域。 此秘籍告诉您如何使图像不失真并从未失真的图像中删除空白区域。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载同一相机拍摄的相机矩阵和畸变系数以及照片:
camera_matrix = np.load('../data/pinhole_calib/camera_mat.npy')
dist_coefs = np.load('../data/pinhole_calib/dist_coefs.npy')
img = cv2.imread('../data/pinhole_calib/img_00.png')
- 使用
cv2.undistort取消扭曲图像-图像中将出现空白区域:
ud_img = cv2.undistort(img, camera_matrix, dist_coefs)
cv2.imshow('undistorted image', ud_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 通过计算最佳相机矩阵并将其应用以获得没有黑色区域的未经失真的图像来消除空白区域:
opt_cam_mat, valid_roi = cv2.getOptimalNewCameraMatrix(camera_matrix, dist_coefs, img.shape[:2][::-1], 0)
ud_img = cv2.undistort(img, camera_matrix, dist_coefs, None, opt_cam_mat)
cv2.imshow('undistorted image', ud_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这个怎么运作
cv2.undistort消除图像中的镜头失真。 它采用以下参数:要失真的图像,相机矩阵,失真系数数组,存储未失真图像的对象以及最佳相机矩阵。 最后两个参数是可选的。 该函数返回未失真的图像。 如果错过了cv2.undistort的最后一个参数,则生成的图像将包含空白区域(黑色)。 最佳摄影机矩阵参数可让您获得没有这些伪影的图像,但是我们需要一种计算此最佳摄影机矩阵的方法,OpenCV 会为其提供服务。
cv2.getOptimalNewCameraMatrix创建最佳相机矩阵,以消除未失真图像上的黑色区域。 它需要相机矩阵,失真系数,(宽度,高度)格式的原始图像大小,alpha 因子,所得图像大小(同样的(宽度,高度)格式),以及设置摄像机的主要相机点在输出图像的中心的布尔标志。 最后两个参数是可选的。 alpha 因子是[0. 1]范围内的两倍,它表示删除空白区域的程度:0 表示完全删除,因此损失了一部分图像像素,而 1 表示保留了所有图像像素。 以及空白区域。 如果未设置输出图像尺寸,则将其设置为与输入图像的尺寸相同。
从秘籍启动代码后,您将看到类似于以下内容的图像:

如您所见,上面的图像在边框附近有黑色区域,下面的图像则没有。
通过三角测量从两个观测值来还原 3D 点
在本秘籍中,您将学习如何在两个视图中给定观察值来重建 3D 点坐标。 这是许多更高级别的 3D 重建算法和 SLAM 系统的基础。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块。
import cv2
import numpy as np
- 生成测试相机的投影矩阵:
P1 = np.eye(3, 4, dtype=np.float32)
P2 = np.eye(3, 4, dtype=np.float32)
P2[0, 3] = -1
- 生成测试点:
N = 5
points3d = np.empty((4, N), np.float32)
points3d[:3, :] = np.random.randn(3, N)
points3d[3, :] = 1
- 将 3D 点投影到两个视图中并添加噪点:
points1 = P1 @ points3d
points1 = points1[:2, :] / points1[2, :]
points1[:2, :] += np.random.randn(2, N) * 1e-2
points2 = P2 @ points3d
points2 = points2[:2, :] / points2[2, :]
points2[:2, :] += np.random.randn(2, N) * 1e-2
- 从嘈杂的观察中重建点:
points3d_reconstr = cv2.triangulatePoints(P1, P2, points1, points2)
points3d_reconstr /= points3d_reconstr[3, :]
- 打印结果:
print('Original points')
print(points3d[:3].T)
print('Reconstructed points')
print(points3d_reconstr[:3].T)
这个怎么运作
我们在 3D 空间中生成随机点,并将其投影到两个测试视图中。 然后,我们向这些观测值添加噪声,并使用 OpenCV 函数cv2.triangulatePoints重建 3D 点。 作为输入,该函数从两个摄像机和每个视图的摄像机投影矩阵(从世界坐标系到视图坐标系的投影映射)获取观测值。 它返回世界坐标系中的重建点。
以下是可能的结果:
Original points
[[ 0.48245686 -2.05779004 1.3458606 ]
[-0.18333936 -1.00662899 -0.46047512]
[-0.51193094 -0.54561883 0.20674749]
[ 1.05258393 -1.55241323 0.60368073]
[ 1.80103588 -0.83367926 -0.59293056]]
Reconstructed points
[[ 0.47777811 -2.05873108 1.3407315 ]
[-0.17389734 -0.99433696 -0.45361272]
[-0.51100874 -0.54552656 0.20692034]
[ 1.05780101 -1.54776227 0.60341281]
[ 1.81407869 -0.83914387 -0.59897166]]
通过 PnP 算法找到相对的相机对象姿态
相机会删除与要拍摄的物体有多远的信息。 它可能是一个很小但很近的物体,也可能是一个很大而又很远的物体(图像可能是相同的),但是通过知道物体的几何尺寸,我们可以计算出物体到相机的距离。 通常,我们对对象几何形状的了解是对象局部坐标系中某些 3D 点集的位置。 通常,我们不仅要知道相机和物体的局部坐标系之间的距离,而且要知道物体的方位。 使用 OpenCV 可以成功完成此任务。 如果我们知道对象的 3D 点及其在图像上的相应 2D 投影的配置,那么本秘籍将向您展示如何找到对象的 6 自由度(自由度)位置。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载相机矩阵,失真系数和相机拍摄的对象的照片:
camera_matrix = np.load('../data/pinhole_calib/camera_mat.npy')
dist_coefs = np.load('../data/pinhole_calib/dist_coefs.npy')
img = cv2.imread('../data/pinhole_calib/img_00.png')
- 检测图像中的对象点,在本例中为棋盘角:
pattern_size = (10, 7)
res, corners = cv2.findChessboardCorners(img, pattern_size)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
corners = cv2.cornerSubPix(cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),
corners, (10, 10), (-1,-1), criteria)
- 创建 3D 对象点的配置:
pattern_points = np.zeros((np.prod(pattern_size), 3), np.float32)
pattern_points[:, :2] = np.indices(pattern_size).T.reshape(-1, 2)
- 使用
cv2.solvePnP查找对象的位置和方向:
ret, rvec, tvec = cv2.solvePnP(pattern_points, corners, camera_matrix, dist_coefs,
None, None, False, cv2.SOLVEPNP_ITERATIVE)
- 通过应用找到的旋转和平移,将对象的点投影回图像。 绘制投影点:
img_points, _ = cv2.projectPoints(pattern_points, rvec, tvec, camera_matrix, dist_coefs)
for c in img_points.squeeze():
cv2.circle(img, tuple(c), 10, (0, 255, 0), 2)
cv2.imshow('points', img)
cv2.waitKey()
cv2.destroyAllWindows()
这个怎么运作
cv2.solvePnP能够通过对象在本地坐标系中的 3D 点及其在图像上的 2D 投影找到对象的平移和旋转。 它接受一组 3D 点,一组 2D 点,一个3x3相机矩阵,畸变系数,初始旋转和平移向量(可选),是否使用初始位置和方向的标记以及问题求解器的类型 。 前两个参数应包含相同数量的点。 求解器的类型可以是许多类型之一:cv2.SOLVEPNP_ITERATIVE,cv2.SOLVEPNP_EPNP和cv2.SOLVEPNP_DLS等。
默认情况下,使用cv2.SOLVEPNP_ITERATIVE,在很多情况下它都能获得不错的结果。 cv2.solvePnP返回三个值:成功标志,旋转向量和平移向量。 成功标志表示问题已正确解决。 平移向量的单位与对象的 3D 局部点相同。 旋转向量以 Rodrigues 形式返回:向量的方向表示对象绕其旋转的轴,向量的范数表示旋转角度。
从秘籍启动代码后,它将显示类似于以下内容的图像:

通过立体校正对齐两个视图
在本秘籍中,您将学习如何校正具有已知参数的使用立体摄像机拍摄的两个图像,使得对于(x[l], y[l]),右图中相应的对极线是y[r] = y[l],反之亦然。 这极大地简化了特征匹配和密集的立体估计算法。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
import matplotlib.pyplot as plt
- 加载立体相机校准参数:
data = np.load('../data/stereo/case1/stereo.npy').item()
Kl, Dl, Kr, Dr, R, T, img_size = data['Kl'], data['Dl'], data['Kr'], data['Dr'], \
data['R'], data['T'], data['img_size']
- 加载左右测试图像:
left_img = cv2.imread('../data/stereo/case1/left14.png')
right_img = cv2.imread('../data/stereo/case1/right14.png')
- 估计立体整流参数:
R1, R2, P1, P2, Q, validRoi1, validRoi2 = cv2.stereoRectify(Kl, Dl, Kr, Dr,
img_size, R, T)
- 准备立体整流变换图:
xmap1, ymap1 = cv2.initUndistortRectifyMap(Kl, Dl, R1, Kl, img_size, cv2.CV_32FC1)
xmap2, ymap2 = cv2.initUndistortRectifyMap(Kr, Dr, R2, Kr, img_size, cv2.CV_32FC1)
- 纠正图像:
left_img_rectified = cv2.remap(left_img, xmap1, ymap1, cv2.INTER_LINEAR)
right_img_rectified = cv2.remap(right_img, xmap2, ymap2, cv2.INTER_LINEAR)
- 可视化结果:
plt.figure(0, figsize=(12,10))
plt.subplot(221)
plt.title('left original')
plt.imshow(left_img, cmap='gray')
plt.subplot(222)
plt.title('right original')
plt.imshow(right_img, cmap='gray')
plt.subplot(223)
plt.title('left rectified')
plt.imshow(left_img_rectified, cmap='gray')
plt.subplot(224)
plt.title('right rectified')
plt.imshow(right_img_rectified, cmap='gray')
plt.tight_layout()
plt.show()
这个怎么运作
我们加载先前从文件中估计的立体装备参数。 校正过程本身估计这种相机变换,以使两个单独的图像平面之后变为同一平面。 这极大地简化了极线几何约束,并使所有其他与立体相关的算法的工作变得更加容易。
使用cv2.stereoRectify函数估计校正变换参数-它获取立体装备参数并返回校正参数:第一摄像机旋转,第二摄像机旋转,第一摄像机投影矩阵,第二摄像机投影矩阵,视差-深度映射矩阵,所有像素均有效的第一相机 ROI 和所有像素均有效的第二相机 ROI。
我们只使用前两个参数。 第一和第二摄像机旋转用于使用cv2.initUndistortRectifyMap函数构建每像素图的校正变换。 一次计算映射后,即可将其用于使用立体装备捕获的任何图像。
预期结果如下所示:

对极几何 - 计算基本和本质矩阵
在本秘籍中,您将学习如何计算基本矩阵和基本矩阵,即其中包含对极几何约束的矩阵。 这些矩阵可用于重建立体装备的外部参数以及其他两视图视觉算法。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载左/右图像点对应关系和各个相机校准参数:
data = np.load('../data/stereo/case1/stereo.npy').item()
Kl, Kr, Dl, Dr, left_pts, right_pts, E_from_stereo, F_from_stereo = \
data['Kl'], data['Kr'], data['Dl'], data['Dr'], \
data['left_pts'], data['right_pts'], data['E'], data['F']
- 将左右点列表堆叠到数组中:
left_pts = np.vstack(left_pts)
right_pts = np.vstack(right_pts)
- 消除镜头变形:
left_pts = cv2.undistortPoints(left_pts, Kl, Dl, P=Kl)
right_pts = cv2.undistortPoints(right_pts, Kr, Dr, P=Kr)
- 估计基本矩阵:
F, mask = cv2.findFundamentalMat(left_pts, right_pts, cv2.FM_LMEDS)
- 估计本质矩阵:
E = Kr.T @ F @ Kl
- 打印结果:
print('Fundamental matrix:')
print(F)
print('Essential matrix:')
print(E)
这个怎么运作
我们使用cv2.findFundamentalMat函数从左右图像点对应关系估计基本矩阵。 此函数支持几种不同的基本矩阵参数估计算法,例如cv2.FM_7POINT(7 点算法),cv2.FM_8POINT(8 点算法),cv2.FM_LMEDS(最低中值方法)和cv2.FM_RANSAC( 基于 RANSAC 的方法)。 两个可选参数指定基于 RANSAC 的估计算法的错误阈值,以及用于中位数最小和基于 RANSAC 的方法的置信度。
以下是预期结果:
Fundamental matrix:
[[ 1.60938825e-08 -2.23906409e-06 -2.53850603e-04]
[ 2.97226703e-06 -2.38236386e-07 -7.70276666e-02]
[ -2.55190056e-04 7.69760820e-02 1.00000000e+00]]
Essential matrix:
[[ 4.62585055e-03 -6.43487140e-01 -4.17486092e-01]
[ 8.53590806e-01 -6.84088948e-02 -4.08817705e+01]
[ 2.63679084e-01 4.07046349e+01 -2.20825664e-01]]
将基本矩阵分解为旋转和平移
在本秘籍中,您将学习如何将基本矩阵分解为两个假设,这些假设关于立体装备中两个摄像机之间的相对旋转和平移向量。 估计立体装备参数时使用此功能。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载预先计算的基本矩阵:
data = np.load('../data/stereo/case1/stereo.npy').item()
E = data['E']
- 将基本矩阵分解为两个可能的旋转和平移:
R1, R2, T = cv2.decomposeEssentialMat(E)
- 打印结果:
print('Rotation 1:')
print(R1)
print('Rotation 2:')
print(R2)
print('Translation:')
print(T)
这个怎么运作
我们使用 OpenCV cv2.decomposeEssentialMat函数,该函数将基本矩阵作为输入,并返回两个候选摄像机之间的旋转和一个转换向量候选。 请注意,由于翻译向量只能恢复到一定规模,因此以标准化形式(单位长度)返回。
以下是预期结果:
Rotation 1:
[[ 0.99981105 -0.01867927 0.00538031]
[-0.01870903 -0.99980965 0.00553437]
[ 0.00527591 -0.00563399 -0.99997021]]
Rotation 2:
[[ 0.99998995 0.00355598 0.00273003]
[-0.00354058 0.99997791 -0.00562461]
[-0.00274997 0.00561489 0.99998046]]
Translation:
[[ 0.99993732]
[-0.01112522]
[ 0.00126302]]
估计立体图像的视差图
在本秘籍中,您将学习如何从两个校正后的图像中计算视差图。 此功能在许多需要恢复场景深度信息的计算机视觉应用中很有用,例如,高级驾驶员辅助应用中的避免碰撞。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载左右校正图像:
left_img = cv2.imread('../data/stereo/left.png')
right_img = cv2.imread('../data/stereo/right.png')
- 使用立体块匹配算法计算视差图:
stereo_bm = cv2.StereoBM_create(32)
dispmap_bm = stereo_bm.compute(cv2.cvtColor(left_img, cv2.COLOR_BGR2GRAY),
cv2.cvtColor(right_img, cv2.COLOR_BGR2GRAY))
- 使用立体半全局块匹配算法计算视差图:
stereo_sgbm = cv2.StereoSGBM_create(0, 32)
dispmap_sgbm = stereo_sgbm.compute(left_img, right_img)
- 可视化结果:
plt.figure(figsize=(12,10))
plt.subplot(221)
plt.title('left')
plt.imshow(left_img[:,:,[2,1,0]])
plt.subplot(222)
plt.title('right')
plt.imshow(right_img[:,:,[2,1,0]])
plt.subplot(223)
plt.title('BM')
plt.imshow(dispmap_bm, cmap='gray')
plt.subplot(224)
plt.title('SGBM')
plt.imshow(dispmap_sgbm, cmap='gray')
plt.show()
这个怎么运作
我们使用两种不同的算法进行视差图计算-块匹配和半全局块匹配。 在使用cv2.StereoBM_create或cv2.StereoSGBM_create(在其中指定最大可能视差)实例化映射估计对象之后,我们调用compute方法,该方法将获取两张图像并返回视差图。
请注意,有必要将经过校正的图像作为compute方法的输入。 返回的视差图将包含每个像素的视差值,例如,对应于场景中同一点的左右图像点之间的像素水平偏移。 然后可以使用该偏移量还原 3D 中的实际点。
创建视差估计器时,您可以指定一些特定于所使用算法的参数。 有关更详细的描述,您可以参考 OpenCV 的文档。
OpenCV 中还有一个名为cudastereo的模块,该模块是通过 CUDA 支持构建的,该模块提供了更优化的立体算法。 您还可以在 OpenCV Contrib 存储库中检出stereo模块,该模块还包含一些其他算法。
预期结果如下所示:

特例 2 - 视图几何 - 估计单应变换
如果需要将点从一个平面投影到另一个平面,可以通过应用单应性矩阵来实现。 如果知道平面的对应变换,则可以使用此矩阵将点从一个平面投影到另一平面。 OpenCV 具有查找单应性矩阵的功能,此秘籍向您展示如何使用和应用它。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载相机矩阵,失真系数和相机拍摄的两帧:
camera_matrix = np.load('../data/pinhole_calib/camera_mat.npy')
dist_coefs = np.load('../data/pinhole_calib/dist_coefs.npy')
img_0 = cv2.imread('../data/pinhole_calib/img_00.png')
img_1 = cv2.imread('../data/pinhole_calib/img_10.png')
- 取消扭曲帧:
img_0 = cv2.undistort(img_0, camera_matrix, dist_coefs)
img_1 = cv2.undistort(img_1, camera_matrix, dist_coefs)
- 在两个图像上找到棋盘角:
pattern_size = (10, 7)
res_0, corners_0 = cv2.findChessboardCorners(img_0, pattern_size)
res_1, corners_1 = cv2.findChessboardCorners(img_1, pattern_size)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
corners_0 = cv2.cornerSubPix(cv2.cvtColor(img_0, cv2.COLOR_BGR2GRAY),
corners_0, (10, 10), (-1,-1), criteria)
corners_1 = cv2.cornerSubPix(cv2.cvtColor(img_1, cv2.COLOR_BGR2GRAY),
corners_1, (10, 10), (-1,-1), criteria)
- 在两个图像的点之间找到单应性:
H, mask = cv2.findHomography(corners_0, corners_1)
- 应用找到的单应性矩阵将点从第一张图像投影到第二张图像:
center_0 = np.mean(corners_0.squeeze(), 0)
center_0 = np.r_[center_0, 1]
center_1 = H @ center_0
center_1 = (center_1 / center_1[2]).astype(np.float32)
img_0 = cv2.circle(img_0, tuple(center_0[:2]), 10, (0, 255, 0), 3)
img_1 = cv2.circle(img_1, tuple(center_1[:2]), 10, (0, 0, 255), 3)
- 使用找到的单应性矩阵变换第一张图像并显示结果:
img_0_warped = cv2.warpPerspective(img_0, H, img_0.shape[:2][::-1])
cv2.imshow('homography', np.hstack((img_0, img_1, img_0_warped)))
cv2.waitKey()
cv2.destroyAllWindows()
这个怎么运作
为了能够将一个点从一个平面投影到另一个平面,首先需要计算单应矩阵。 可以使用cv2.findHomography执行。 此函数接受以下参数:
- 来自源(第一)平面的一组点
- 来自目标(第二个)平面的一组点
- 查找单应性的方法
- 过滤异常值的阈值
- 离群值的输出遮罩
- 最大迭代次数
- 置信度
除前两个参数外,所有参数均使用默认值。 方法参数描述应使用哪种算法计算单应性。 默认情况下,所有点都被使用,但是如果您的数据倾向于包含相当数量的离群值(噪声或误选点很大的点),则最好使用以下方法之一:cv2.RANSAC,cv2.LMEDS, 或cv2.RHO。 这些方法可以正确滤除异常值。 过滤离群值的阈值是以像素为单位的距离,该距离确定点的类型:离群值或离群值。 遮罩是一个对象,用于存储每个点的内部/外部类的值。 最大迭代次数和置信度确定了解决方案的正确性。 cv2.findHomography返回找到的单应性矩阵和点的掩码值。 还值得一提的是,您需要检查结果矩阵是否不是空对象,因为无法找到所有点集的解决方案。
找到单应性矩阵后,可以将其传递给cv2.warpPerspective并将其应用于图像投影。 也可以通过用单应性矩阵乘以点来投影点(请参见代码)。
最后,执行代码后,您将看到类似于以下图像:

平面场景 - 将单应性分解为旋转和平移
单应性矩阵可以分解为两个平面对象视图之间的相对平移和旋转向量。 此秘籍向您展示如何在 OpenCV 中进行操作。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载相机矩阵,畸变系数和同一平面对象(棋盘图案)的两张照片。 然后,取消扭曲照片:
camera_matrix = np.load('../data/pinhole_calib/camera_mat.npy')
dist_coefs = np.load('../data/pinhole_calib/dist_coefs.npy')
img_0 = cv2.imread('../data/pinhole_calib/img_00.png')
img_0 = cv2.undistort(img_0, camera_matrix, dist_coefs)
img_1 = cv2.imread('../data/pinhole_calib/img_10.png')
img_1 = cv2.undistort(img_1, camera_matrix, dist_coefs)
- 在两个图像中找到图案的角点:
pattern_size = (10, 7)
res_0, corners_0 = cv2.findChessboardCorners(img_0, pattern_size)
res_1, corners_1 = cv2.findChessboardCorners(img_1, pattern_size)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 1e-3)
corners_0 = cv2.cornerSubPix(cv2.cvtColor(img_0, cv2.COLOR_BGR2GRAY),
corners_0, (10, 10), (-1,-1), criteria)
corners_1 = cv2.cornerSubPix(cv2.cvtColor(img_1, cv2.COLOR_BGR2GRAY),
corners_1, (10, 10), (-1,-1), criteria)
- 找到从第一帧到第二帧的单应变换矩阵:
H, mask = cv2.findHomography(corners_0, corners_1)
- 找到我们估计的单应矩阵的可能平移和旋转:
ret, rmats, tvecs, normals = cv2.decomposeHomographyMat(H, camera_matrix)
这个怎么运作
cv2.decomposeHomographyMat将单应性矩阵分解为旋转和平移。 由于解决方案不是唯一的,因此该函数最多返回四组可能的平移,旋转和法向向量集。 cv2.decomposeHomographyMat接受3x3单应矩阵和 3x3 摄影机矩阵作为参数。 返回值为:找到的解的数量,3x3旋转矩阵的列表,平移向量的列表和法线向量的列表。 每个返回的列表包含与找到的解决方案数量一样多的元素。
旋转相机案例 - 从单应性估计相机旋转
在本秘籍中,您将学习如何从仅相对于其光学中心进行旋转运动的摄像机捕获的两个视图之间的单应变换中提取旋转。 例如,如果您需要估计两个视图之间的旋转,这非常有用,并且假设与场景点的距离相比平移可以忽略不计。 在风景照片拼接中通常就是这种情况。
准备
在继续此秘籍之前,您需要安装 OpenCV 版本 3.3(或更高版本)Python API 包。
怎么做
您需要完成以下步骤:
- 导入必要的模块:
import cv2
import numpy as np
- 加载预先计算的单应性和相机参数:
data = np.load('../data/rotational_homography.npy').item()
H, K = data['H'], data['K']
- 从单应性变换中考虑摄像机参数:
H_ = np.linalg.inv(K) @ H @ K
- 计算近似旋转矩阵:
w, u, vt = cv2.SVDecomp(H_)
R = u @ vt
if cv2.determinant(R) < 0:
R *= 1
- 将旋转矩阵转换为旋转向量:
rvec = cv2.Rodrigues(R)[0]
- 打印结果:
print('Rotation vector:')
print(rvec)
这个怎么运作
如果相机仅绕其光学中心旋转,则单应性变换的形式非常简单-它基本上是一个旋转矩阵,但由于单应性在图像像素空间中起作用,因此乘以了相机矩阵参数。 第一步,我们从单应性矩阵中剔除相机参数。 此后,它必须是旋转矩阵(按比例缩放)。 由于单应性参数中可能存在噪声,因此所得矩阵可能不是适当的旋转矩阵,例如行列式等于 1 的正交矩阵。 这就是为什么我们使用奇异值分解构造最接近(在 Frobenius 范数中)旋转矩阵的原因。
下面显示了预期的结果:
Rotation vector:
[[ 0.12439561]
[ 0.22688715]
[ 0.32641321]]