一、任务类型
我们在做项目的时候,都需要考虑当前的项目或者某一个功能主要的核心是什么?是CPU密集计算型,还是IO密集型任务。我们调整线程池中的线程数量的最主要的目的是为了充分并合理地使用 CPU 和内存等资源,从而最大限度地提高程序的性能。在实际工作中,我们需要根据任务类型的不同选择对应的策略。
1-1、CPU密集型任务
CPU密集型任务也叫计算密集型任务,比如加密、解密、压缩、计算等一系列需要大量耗费 CPU 资源的任务。对于这样的任务最佳的线程数为 CPU 核心数的 1~2 倍,如果设置过多的线程数,实际上并不会起到很好的效果。此时假设我们设置的线程数量是 CPU 核心数的 2 倍以上,因为计算任务非常重,会占用大量的 CPU 资源,所以这时 CPU 的每个核心工作基本都是满负荷的,而我们又设置了过多的线程,每个线程都想去利用 CPU 资源来执行自己的任务,这就会造成不必要的上下文切换,此时线程数的增多并没有让性能提升,反而由于线程数量过多会导致性能下降。
1-2、IO密集型任务
IO密集型任务,比如数据库、文件的读写,网络通信等任务,这种任务的特点是并不会特别消耗 CPU 资源,但是 IO 操作很耗时,总体会占用比较多的时间。对于这种任务最大线程数一般会大于 CPU 核心数很多倍,因为 IO 读写速度相比于 CPU 的速度而言是比较慢的,如果我们设置过少的线程数,就可能导致 CPU 资源的浪费。而如果我们设置更多的线程数,那么当一部分线程正在等待 IO 的时候,它们此时并不需要 CPU 来计算,那么另外的线程便可以利用 CPU 去执行其他的任务,互不影响,这样的话在工作队列中等待的任务就会减少,可以更好地利用资源。
1-3、线程数计算方法
《Java并发编程实战》的作者 Brain Goetz 推荐的计算方法:
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
通过这个公式,我们可以计算出一个合理的线程数量,如果任务的平均等待时间长,线程数就随之增加,而如果平均工作时间长,也就是对于我们上面的 CPU 密集型任务,线程数就随之减少。
太少的线程数会使得程序整体性能降低,而过多的线程也会消耗内存等其他资源,所以如果想要更准确的话,可以进行压测,监控 JVM 的线程情况以及 CPU 的负载情况,根据实际情况衡量应该创建的线程数,合理并充分利用资源。
1-4、算法示例
比如我们想计算1亿个数组内数字的和,应该怎么计算呢?
1-4-1、单线程计算
1、准备一个读取数组并计算的方法
通过下面的方法,就可以传入一个数组,同时传入开始计算的下标和结束计算的下标。然后通过for就可以依次获取数组中的值进行累加计算
/**
* 数组求和
* @param arr
* @param lo
* @param hi
* @return
*/
public static long sumRange(int[] arr, int lo, int hi) {
long result = 0;
for (int j = lo; j < hi; j++) {
result += arr[j];
}
return result;
}
2、准备一个生成1亿随机数的数组
通过如下方法,可以根据传入的值,生成对应大小的数组,然后生成随机数放入数组中。
public static int[] buildRandomIntArray(final int size) {
int[] arrayToCalculateSumOf = new int[size];
Random generator = new Random();
for (int i = 0; i < arrayToCalculateSumOf.length; i++) {
arrayToCalculateSumOf[i] = generator.nextInt(1000);
}
return arrayToCalculateSumOf;
}
3、调用测试方法进行计算
public class SumSequential {
public static long sum(int[] arr){
return SumUtils.sumRange(arr, 0, arr.length);
}
public static void main(String[] args) {
// 准备数组
int[] arr = Utils.buildRandomIntArray(100000000);
System.out.printf("The array length is: %d\n", arr.length);
Instant now = Instant.now();
//数组求和
long result = sum(arr);
System.out.println("执行时间:"+ Duration.between(now,Instant.now()).toMillis());
System.out.printf("The result is: %d\n", result);
}
}
执行结果:
如下是我电脑CPU的逻辑数量
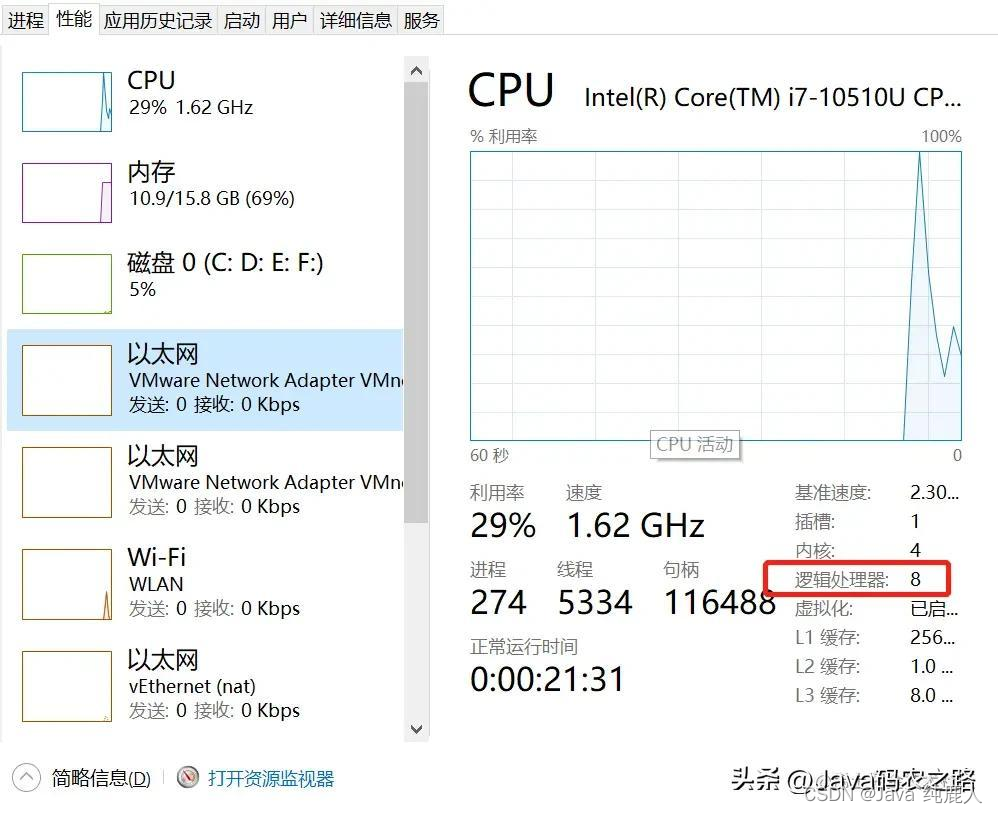
最终执行的时间为62ms,这个值也不是固定不变的
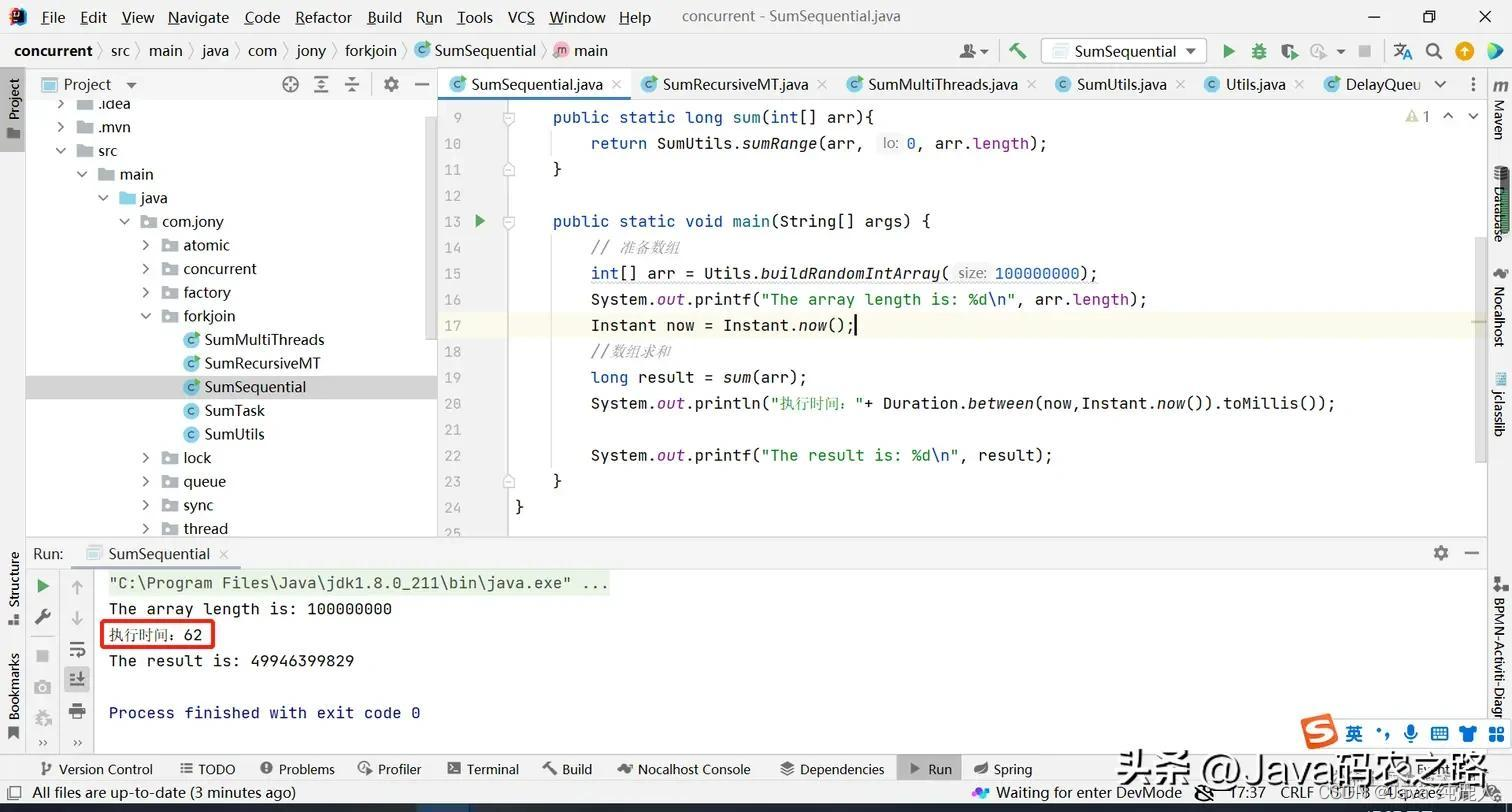
通过上面这种单线程计算大约时间为62ms,那有没有办法让计算提速呢?
1-4-2、多线程计算
利用多线程将任务拆分,最终再将拆分的结果再合并,这样理论上是不是就可以提高速度了?

使用多线程,我们就需要考虑使用线程池,这样可以一定程度上减少线程的创建和销毁带来的损耗
1、定义一个计算的任务,并实现Callable接口
计算方式,依然还是单线程的计算方式
public class SumTask implements Callable<Long> {
int lo;
int hi;
int[] arr;
public SumTask(int[] a, int l, int h) {
lo = l;
hi = h;
arr = a;
}
@Override
public Long call() { //override must have this type
//System.out.printf("The range is [%d - %d]\n", lo, hi);
long result = SumUtils.sumRange(arr, lo, hi);
return result;
}
}
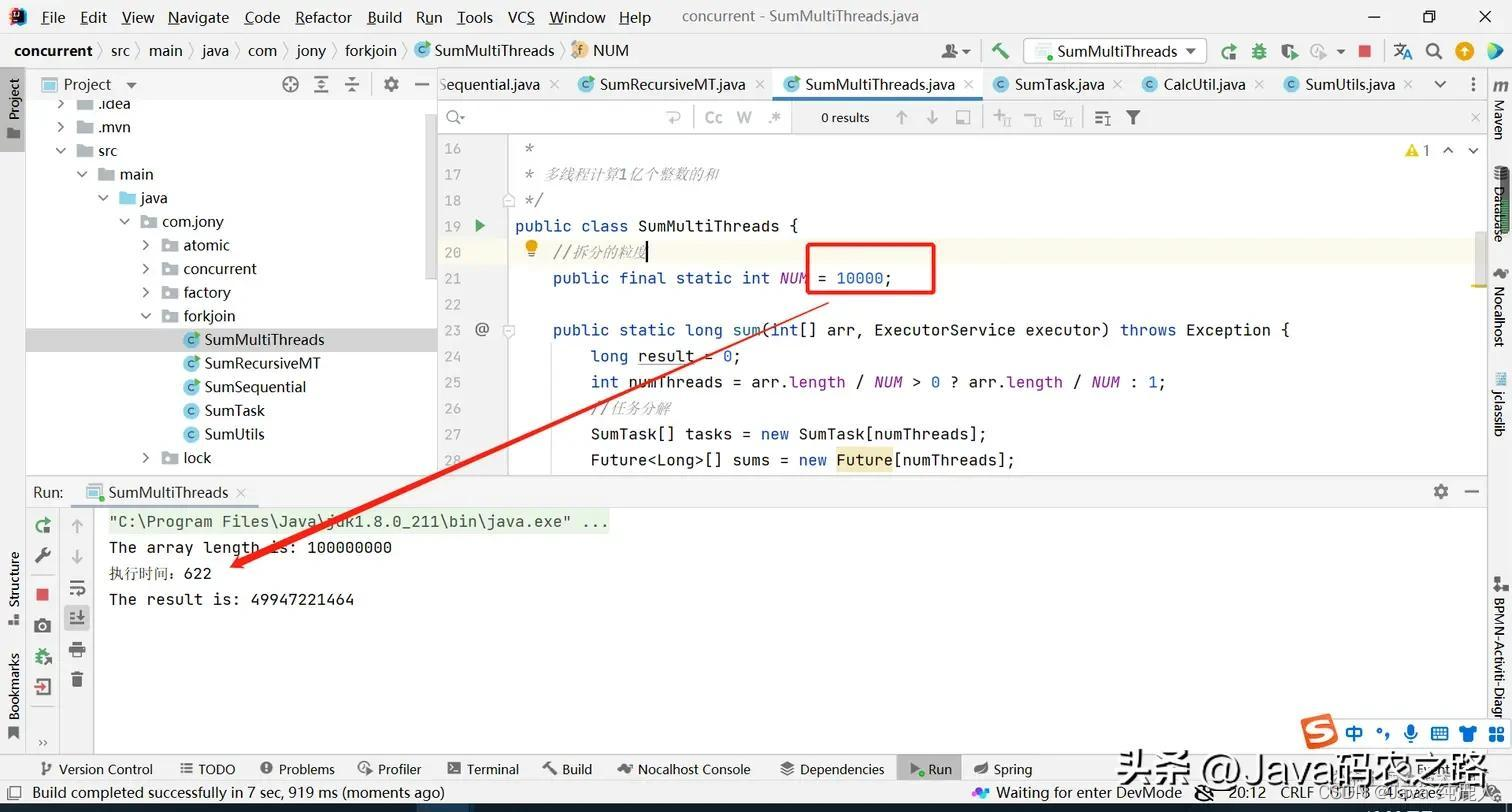
2、根据拆分粒度,将任务拆解,并用线程池计算,然后合并计算结果
将1亿的数组进行拆分,然后定义为子任务,然后通过线程池进行计算,合并结果
//拆分的粒度
public final static int NUM = 10000000;
public static long sum(int[] arr, ExecutorService executor) throws Exception {
long result = 0;
int numThreads = arr.length / NUM > 0 ? arr.length / NUM : 1;
//任务分解
SumTask[] tasks = new SumTask[numThreads];
Future<Long>[] sums = new Future[numThreads];
for (int i = 0; i < numThreads; i++) {
tasks[i] = new SumTask(arr, (i * NUM),
((i + 1) * NUM));
sums[i] = executor.submit(tasks[i]);
}
//结果合并
for (int i = 0; i < numThreads; i++) {
result += sums[i].get();
}
return result;
}
3、执行运算
根据拆分的粒度,构建线程池,然后调用计算方法
public static void main(String[] args) throws Exception {
// 准备数组
int[] arr = Utils.buildRandomIntArray(100000000);
//获取线程数
int numThreads = arr.length / NUM > 0 ? arr.length / NUM : 1;
System.out.printf("The array length is: %d\n", arr.length);
// 构建线程池
ExecutorService executor = Executors.newFixedThreadPool(numThreads);
//预热
//((ThreadPoolExecutor)executor).prestartAllCoreThreads();
Instant now = Instant.now();
// 数组求和
long result = sum(arr, executor);
System.out.println("执行时间:"+Duration.between(now,Instant.now()).toMillis());
System.out.printf("The result is: %d\n", result);
executor.shutdown();
}
执行结果:
如下结果不一定准确,我本地执行有时候也会超过单线程执行的时间。即使给线程池预热的情况下也是如此,那这是什么原因呢?
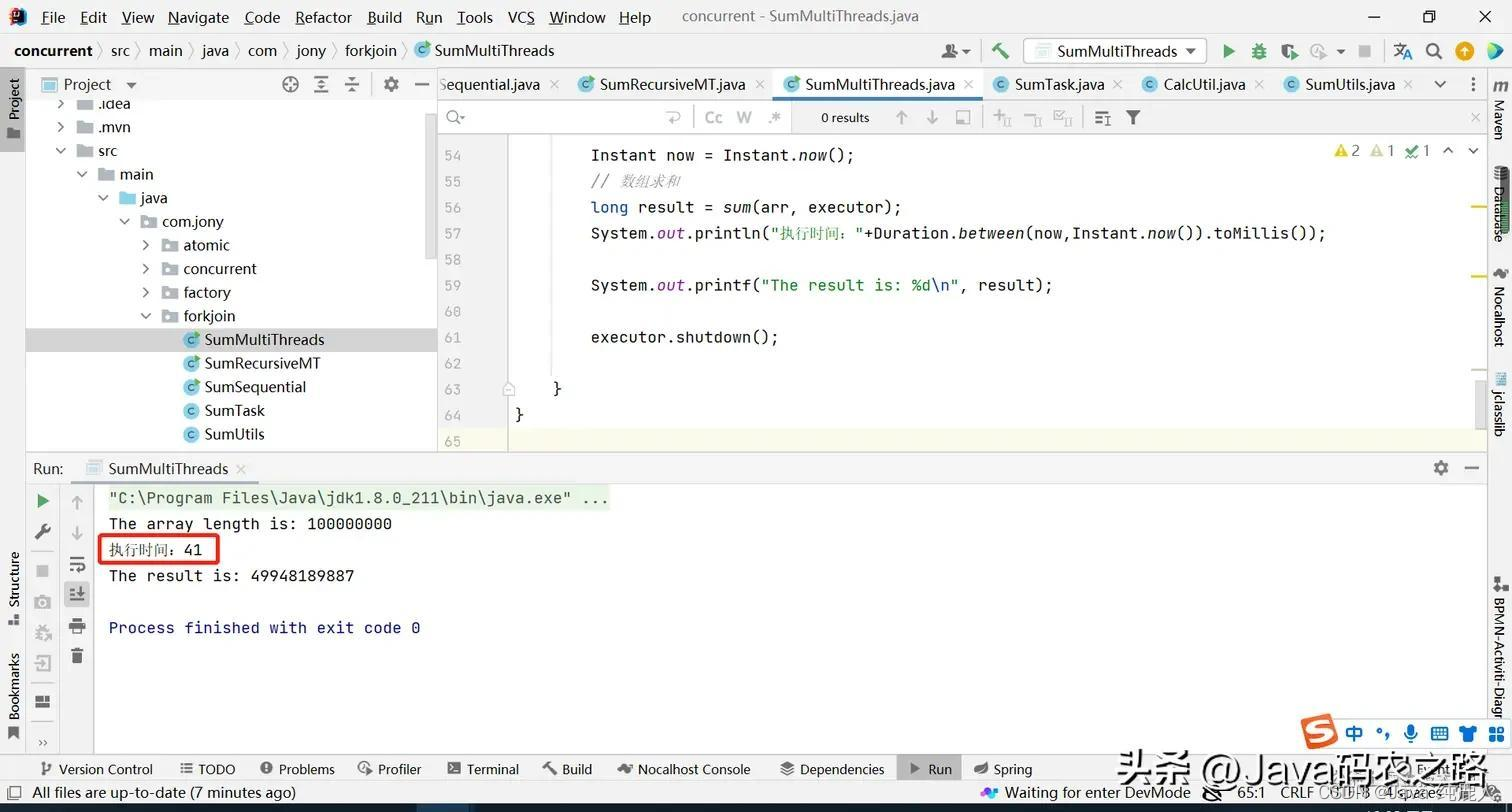
当粒度拆分到10000的时候,会发现执行时间更久了(线程的建立也是有损耗的,而且还涉及到上下文线程的切换),如下:
1-4-3、分治算法
分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。
分治算法的步骤如下:
- 分解:将要解决的问题划分成若干规模较小的同类问题;
- 求解:当子问题划分得足够小时,用较简单的方法解决;
- 合并:按原问题的要求,将子问题的解逐层合并构成原问题的解。
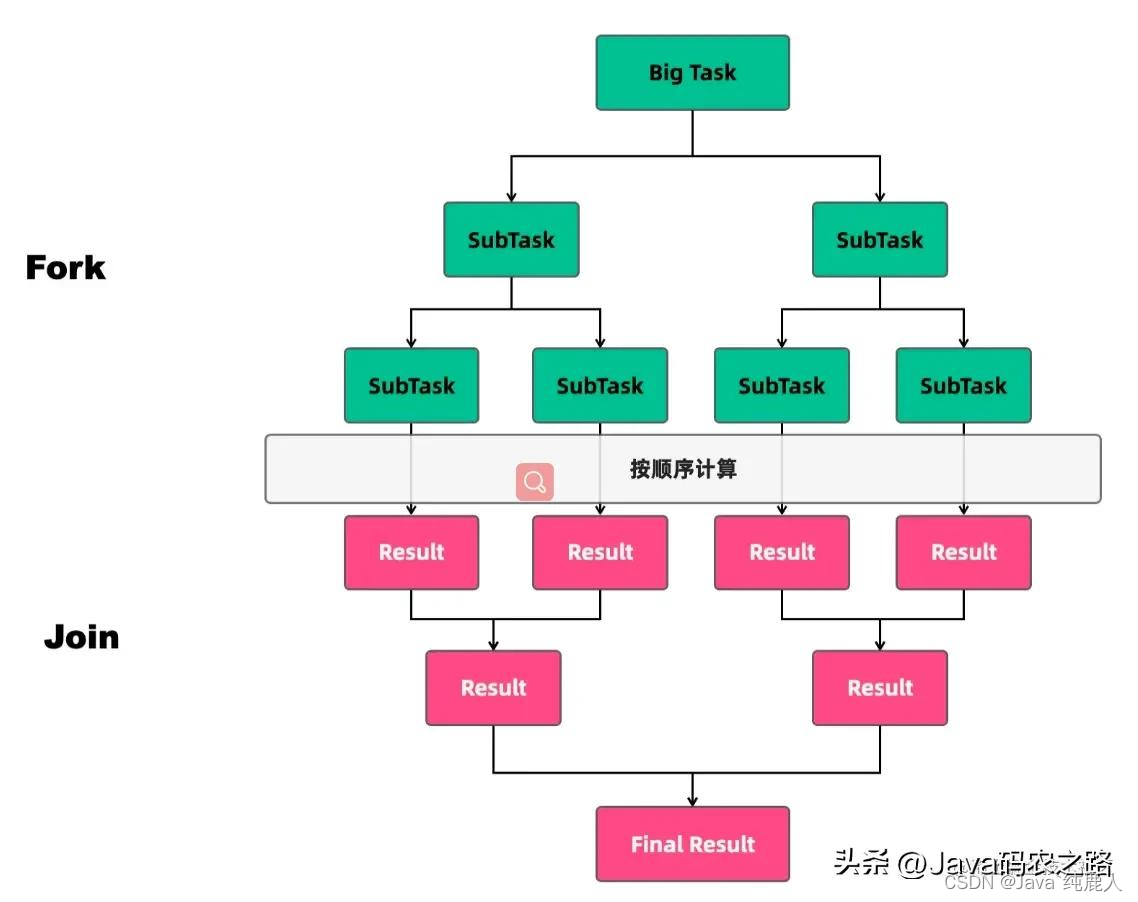
在分治法中,子问题一般是相互独立的,因此,经常通过递归调用算法来求解子问题
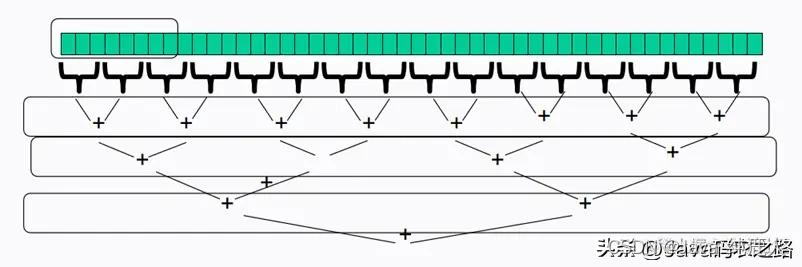
1、使用递归任务分解计算
主要思想就是将任务使用递归的方式进行拆解,最终再通过线程池进行计算,最终合并
public static class RecursiveSumTask implements Callable<Long> {
//拆分的粒度
public static final int SEQUENTIAL_CUTOFF = 100000;
int lo;
int hi;
int[] arr; // arguments
ExecutorService executorService;
RecursiveSumTask(ExecutorService executorService, int[] a, int l, int h) {
this.executorService = executorService;
this.arr = a;
this.lo = l;
this.hi = h;
}
@Override
public Long call() throws Exception {
System.out.format("%s range [%d-%d] begin to compute %n",
Thread.currentThread().getName(), lo, hi);
long result = 0;
//最小拆分的阈值
if (hi - lo <= SEQUENTIAL_CUTOFF) {
for (int i = lo; i < hi; i++) {
result += arr[i];
}
// System.out.format("%s range [%d-%d] begin to finished %n",
// Thread.currentThread().getName(), lo, hi);
} else {
RecursiveSumTask left = new RecursiveSumTask(
executorService, arr, lo, (hi + lo) / 2);
RecursiveSumTask right = new RecursiveSumTask(
executorService, arr, (hi + lo) / 2, hi);
Future<Long> lr = executorService.submit(left);
Future<Long> rr = executorService.submit(right);
result = lr.get() + rr.get();
// System.out.format("%s range [%d-%d] finished to compute %n",
// Thread.currentThread().getName(), lo, hi);
}
return result;
}
}
2、创建线程池、调用递归任务
public static long sum(int[] arr) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
//递归任务 求和
RecursiveSumTask task = new RecursiveSumTask(executorService, arr, 0, arr.length);
//返回结果
long result = executorService.submit(task).get();
executorService.shutdown();
return result;
}
3、执行计算
public static void main(String[] args) throws Exception {
//准备数组
int[] arr = Utils.buildRandomIntArray(100000000);
System.out.printf("The array length is: %d\n", arr.length);
Instant now = Instant.now();
//数组求和
long result = sum(arr);
System.out.println("执行时间:"+ Duration.between(now,Instant.now()).toMillis());
System.out.printf("The result is: %d\n", result);
}
执行结果
通过任务拆分 分治算法效果也还不错
1-4-3-1、应用场景
分治思想在很多领域都有广泛的应用,例如算法领域有分治算法(归并排序、快速排序都属于分治算法,二分法查找也是一种分治算法);大数据领域知名的计算框架 MapReduce 背后的思想也是分治。既然分治这种任务模型如此普遍,那 Java 显然也需要支持,Java 并发包里提供了一种叫做 Fork/Join 的并行计算框架,就是用来支持分治这种任务模型的。
1-4-3-2、饥饿死锁
上面需要注意的是,我们将粒度拆分为1千万,计算1亿也就是需要10个线程进行计算,如果使用固定大小的线程池,并且小于10个线程是什么样呢?
可以看到使用了newFixedThreadPool,设置了固定的核心线程数和最大线程数
ExecutorService executorService = Executors.newFixedThreadPool(8);
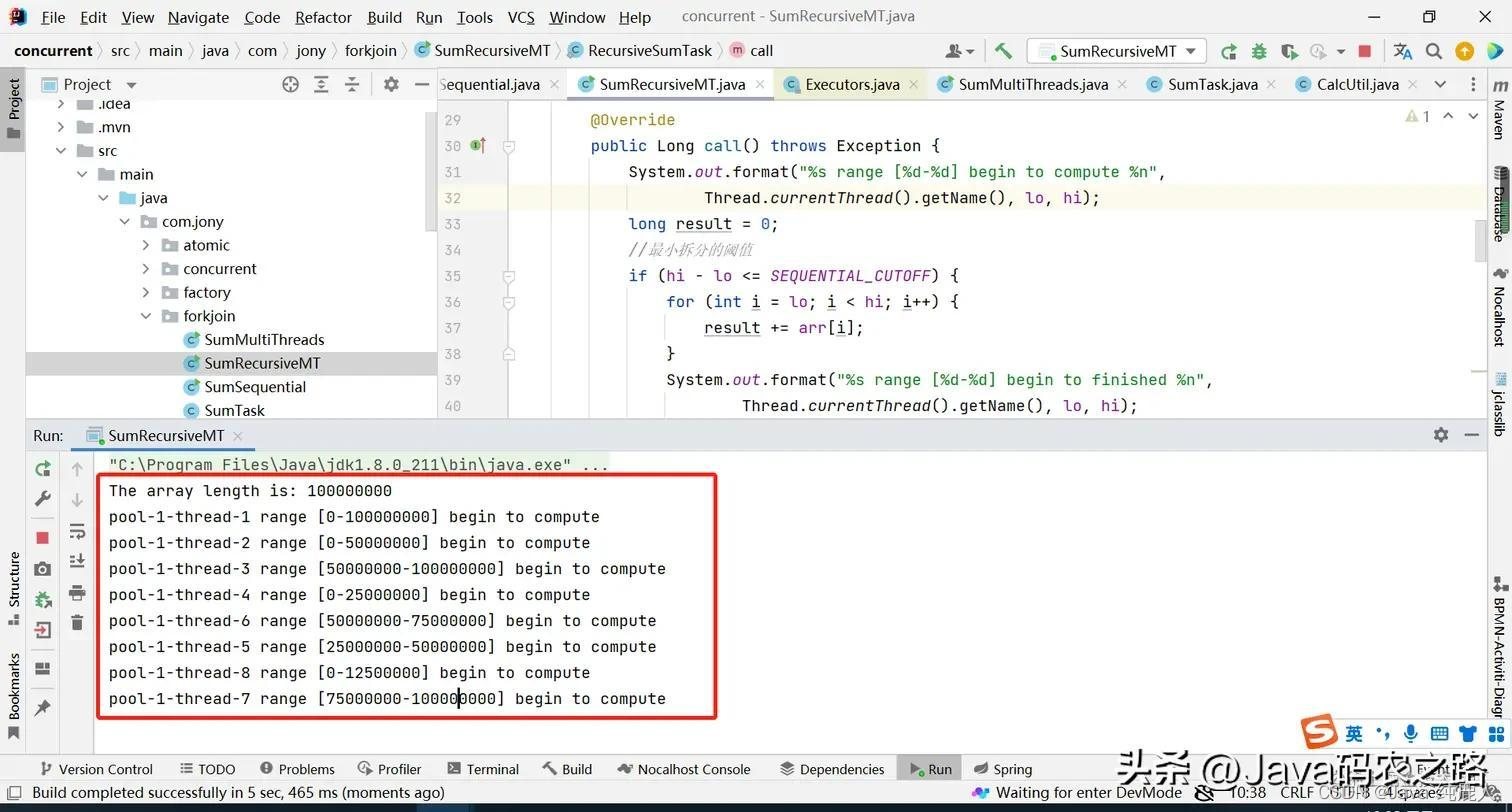
通过上图可以看到,因为设置了固定大小的线程池,我们的线程池都被任务拆分占据了,这样最终执行任务的时候,线程池已经无可用空闲的线程可以使用,这样就会造成饥饿死锁
使用线程池的时候建议根据实际场景然后使用ThreadPoolExcutor,使用符合当前业务场景的队列,创建线程池。
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5, 5, 1000, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
(r) -> new Thread(r, counter.addAndGet(1) + " 号 "),
new ThreadPoolExecutor.AbortPolicy());
1-5、小结
虽然理论上使用线程池的方式可以将任务拆解,但是也会因为多线程的情况下,程序在运行的时候,CPU会进行上线文切换,这样也会增加执行时间。
使用线程池主要目的线程的复用,我们上面的案例,执行了一个简单的逻辑计算,如果是执行一个复杂的逻辑计算,在定义了合适数量的线程池的情况下,会比单线程效率高。
使用分治算法,需要注意线程池的容量,防止造成饥饿死锁。